《Java8实战》
《Java实战》学习整理
文章目录
- 一、Lambda
- 1.1 基础概念
- 1.1.1 [Lambda表达式](https://baike.baidu.com/item/Lambda表达式/4585794?fromModule=lemma_inlink)定义
- 1.2 引入Lambda
- 1.3 Lambda
- 1.3.1 函数式接口
- 1.3.2 Lambda表达式:(参数) -> 表达式
- 1.3.3 在哪里使用Lambda表达式
- 1.3.4 函数描述符
- 1.3.5 类型推断
- 1.3. 6 使用局部变量
- 1.3.7 方法引用
- 1.3.8 复合Lambda表达式
- 二、Stream流
- 2.1 基础概念
- 2.2 中间操作 和 终端操作
- 2.2.1 中间操作
- 2.2.2 终端操作
- 2.2.3 设计模型:类似构建器模式
- 2.2.4 peek中间操作
- 2.3 使用流-筛选
- 2.3.1 filter
- 补充 Predicate
- 2.3.2 distinct
- 2.3.3 max 过滤留下属性值大的类
- 2.4 使用流-切片
- 2.4.1 takeWhile && dropWhile
- 2.5 使用流-映射
- 2.5.1 map
- 2.5.2 flatMap
- 2.6 使用流-查找和匹配
- 2.6.1 allMatch全部匹配
- 2.6.2 anyMatch任意匹配
- 2.6.3 findAny查找任意
- 2.6.4 findFirst 查找第一个
- 2.7 使用流-归约reduce
- 2.7.1 求和
- 2.7.2 max、min、count
- 2.7.3 concat合并多个流
- 2.8 使用流-归约 Collect
- 2.8.1 简介
- 2.8.2 归约和汇总-**LongSummaryStatistics**
- 2.8.3 连接字符串-join
- 2.8.4 归约 - reducing
- 2.8.5 分组- groupingBy
- 2.8.6 分区
- 2.8.7 list转为map: toMap(类似常用的toList)
- 三、Java8新增特性
- 3.1 Map相关
- 3.1.0 compute、computeIfAbsent、putIfAbsent、put
- 3.1.1 排序
- 3.1.2 计数
- 3.1.3 两个map合并-merge
- 3.1.4 其它
- 3.2 Optional
- 3.2.1 Optional简介
- 3.2.2 Optional常用方法
- 3.2.3 优雅的取值
- 3.2.4 注意事项:
- 3.3 时间类
- 3.3.1 Temporal实现类
- 3.3.2 ChronoUnit
- 3.3.3 Period 和 Duration
- 3.4 默认方法
- 3.4.1 简介
- 3.4.1 菱形问题:
- 四、CompletableFuture
- 4.1 简介
- 4.1.1 产生背景
- 4.1.2 概念
- 4.2 正确使用姿势
- 4.3 get方法和join方法区别
- 4.3.1 相同点:
- 4.3.2 区别:
- 4.4 实战
- 4.4.1 单个并发查询
- 4.4.2 两个参数都是集合,一起作为异步查询的入参,并发查询
- 4.4.3 List<ParamDTO> paramlist + Map<Integer,List<Service> > map一起并发查询
- map中key = 1,value = List<Service> serviceList1,serviceList1为sever1、sever2、key = 2,value = List<Service> serviceList2,serviceList为sever3
- 4.4.3 A和B任务二者之间并行查询 ,同时 A和B本身也要200批次、200批次的并行查询
- 4.4.4 将List<CompletableFuture<X>>转为CompletableFuture<List<T>> cf1
- 4.4.5 将List<CompletableFuture<Map<Long, Long>>> 变为 CompletableFuture*<*Map*<*Long, Long*>>* cf1
- 4.4.6 并发处理map的k-v,而非map.forEach((k,v) 串行处理
- 4.4.7 limit、offset并发查询
- 4.4.8 协同、转运、pc打标,并发mark,结果一起join
- 4.4.9 其他
- 4.5 Java9 CompletableFuture新特性
- 4.5.1 新增了orTimeOut方法
- 4.5.2 执行超时的时候,赋默认结果completeOnTimeOut
- 五、工具类(非Java8):
- 5.1 集合运算
- 5.2 集合深copy
- 5.3 线程安全的list:
- 5.4 list <==> Array
一、Lambda
1.1 基础概念
-
函数式编程 和 Lambda都是为Stream服务的
-
1.1.1 Lambda表达式定义
是一个匿名函数,即没有函数名的函数,函数/方法可以作为参数传递至另一个方法中
(int x) -> x+1 上述Lambda表达式,定义了这样一个匿名函数:调用时给定参数x就返回x+1值的函数 -
没有共享的可变数据,以及将方法\函数\行为,传递给其他方法的能力,这两点是函数式编程的基石。也构成了Stream的基础
1.2 引入Lambda
背景:
苹果集合,苹果有颜色、重量、是否售卖等三个属性。
现有集合,筛选出颜色是青苹果
@Data
@Accessors(chain = true)
public class Apple {private ColorEnum color;private Integer weight;private Boolean sell;}
1、第一次尝试:直接遍历集合
@Testpublic void t(){Apple apple1 = new Apple().setColor(ColorEnum.GREEN).setWeight(100).setSell(Boolean.TRUE);Apple apple2 = new Apple().setColor(ColorEnum.GREEN).setWeight(150).setSell(Boolean.TRUE);Apple apple3 = new Apple().setColor(ColorEnum.RED).setWeight(150).setSell(Boolean.TRUE);Apple apple4 = new Apple().setColor(ColorEnum.RED).setWeight(150).setSell(Boolean.FALSE);List<Apple> appleList = Lists.newArrayList(apple1, apple2, apple3, apple4);//下文都是使用这个苹果集合appleListList<Apple> filteredAppleList = filterGreen(appleList);}private List<Apple> filterfilterGreen(List<Apple> appleList) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (Objects.equals(apple.getColor(), ColorEnum.GREEN)) {result.add(apple);}}return result;}
-
缺点:
如果再要求筛选出红苹果,则还需要再写一个过滤方法
private List<Apple> filterfilterRed(List<Apple> appleList) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (Objects.equals(apple.getColor(), ColorEnum.RED)) {result.add(apple);}}return result;}
2、第二次尝试:把颜色作为方法入参,想要过滤啥颜色的就传递啥颜色
@Testpublic void t(){// 想要过滤啥颜色的,就传递啥颜色即可List<Apple> tempList = filterByColor(appleList, ColorEnum.GREEN);List<Apple> finalResult = filterByColor(tempList, ColorEnum.RED);}private List<Apple> filterByColor(List<Apple> appleList, ColorEnum colorEnum) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (Objects.equals(apple.getColor(), colorEnum)) {result.add(apple);}}return result;}
-
缺点:
如果我想按照重量进行过滤,顾虑出大于指定重量的苹果;或过滤出是否售卖的苹果,则还需要继续添加方法
3、第三次尝试:把苹果的所有属性都作为方法入参,想要过滤啥传递啥即可
@Testpublic void t(){List<Apple> tempList = filterByColor(appleList, ColorEnum.GREEN, 120, Boolean.TRUE);List<Apple> finalResult = filterByColor(tempList, ColorEnum.RED, 100 ,Boolean.FALSE);}private List<Apple> filterByColor(List<Apple> appleList, ColorEnum colorEnum, Integer weight, Boolean isSell) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (Objects.equals(apple.getColor(), colorEnum)&& apple.getWeight() > weight&& Objects.equals(apple.getSell(), isSell)) {result.add(apple);}}return result;}
-
缺点:
类属性很多时,方法入参变得复杂;同时,有的不需要根据类的属性进行过滤,则需要在方法中传递null值
4、第四次尝试:使用策略模式
定义接口和实现类,其中接口方法定义为:是否满足某种条件。实现类则分别为:是否为青色苹果、是否为红色苹果、是否售卖等
// 1.定义接口和判断方法
public interface ApplePredicate {/*** 判断是否满足某个行为* @param apple 苹果* @return 是否满足某个条件*/boolean judge(Apple apple);}// 2.1定义青苹果类
public class GreenApplePredicate implements ApplePredicate{@Overridepublic boolean judge(Apple apple) {return Objects.equals(apple.getColor(), ColorEnum.GREEN);}
}// 2.2定义红苹果类
public class RedApplePredicate implements ApplePredicate{@Overridepublic boolean judge(Apple apple) {return Objects.equals(apple.getColor(), ColorEnum.RED);}
}// 2.3定义重量类
public class WeightApplePredicate implements ApplePredicate{@Overridepublic boolean judge(Apple apple) {return apple.getWeight() > 150;}
}@Testpublic void t(){List<Apple> tempGreenList = filter(appleList, new GreenApplePredicate());List<Apple> tempRedList = filter(tempGreenList, new RedApplePredicate());List<Apple> result = filter(tempRedList, new WeightApplePredicate());}// 想要过滤什么属性,就传递对应的实现类对象即可private List<Apple> filter(List<Apple> appleList, ApplePredicate applePredicate) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (applePredicate.judge(apple)) {result.add(apple);}}return result;}
-
优点:策略模式,满足开闭原则
filter方法的具体内容,已经取决于传递的实现类对象了。只不过最重要的方法judge是被对象包裹了。可以通过lambda讲judge方法拿到外层,充当方法参数
-
缺点:需要写太多实现类,麻烦
5、第五次尝试:使用匿名内部类
@Testpublic void t(){List<Apple> tempGreenList = filter(appleList, new ApplePredicate() {@Overridepublic boolean judge(Apple apple) {return Objects.equals(apple.getColor(), ColorEnum.GREEN);}});List<Apple> tempRedList = filter(tempGreenList, new ApplePredicate() {@Overridepublic boolean judge(Apple apple) {return Objects.equals(apple.getColor(), ColorEnum.RED);}});List<Apple> result = filter(tempRedList, new ApplePredicate() {@Overridepublic boolean judge(Apple apple) {return apple.getWeight() > 150;}});}private List<Apple> filter(List<Apple> appleList, ApplePredicate applePredicate) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (applePredicate.judge(apple)) {result.add(apple);}}return result;}
- 优点:解决了类爆炸问题
- 缺点:还是需要写很多代码,笨重
6、第六次尝试:和匿名内部类一样,匿名函数(Lambda表达式)也可以作为参数,传递至方法
将filter方法传递参数,由对象引用变成函数引用。即将judge方法拿到外层
@Testpublic void t(){List<Apple> greenAppleList = filter(appleList, apple -> Objects.equals(apple.getColor(), ColorEnum.GREEN));List<Apple> redAppleList = filter(greenAppleList, apple -> Objects.equals(apple.getColor(), ColorEnum.RED));List<Apple> weightList = filter(redAppleList, apple -> apple.getWeight() > 150);List<Apple> result = filter(weightList, apple -> apple.getSell());}private List<Apple> filter(List<Apple> appleList, ApplePredicate applePredicate) {List<Apple> result = Lists.newArrayList();for (Apple apple : appleList) {if (applePredicate.judge(apple)) {result.add(apple);}}return result;}
- 优点:函数式编程,将行为/方法/函数 作为参数传递至方法。满足开闭原则,代码简洁
7、第七次尝试:将List抽象化,同时使用语法糖
public interface Predicate<T> {/*** 判断是否满足某个行为* @param e 苹果* @return 是否满足某个条件*/boolean judge(T e);}private <T> List<T> filter(List<T> list, Predicate<T> predicate) {List<T> result = Lists.newArrayList();for (T e : list) {if (predicate.judge(e)) {result.add(e);}}return result;}List<Apple> sellAppleList = filter(appleList, Apple::getSell);// 语法糖,取代 apple -> xxx形式List<Integer> numbers = Lists.newArrayList(1, 2, 3);List<Integer> result = filter(numbers, e -> e > 2);
- 优点:其他元素类类型的集合,也可以进行过滤。类型Stream流中的filter方法了
1.3 Lambda
1.3.1 函数式接口
- 仅定义了一个抽象方法(可以有许多默认方法)
- 常见的函数式接口:Runnable、Callable、Compator
- Lambda表达式就是函数式接口中抽象方法的具体实现的实例
1.3.2 Lambda表达式:(参数) -> 表达式
- 参数可以为空,返回值也可以为空
- 表达式的结果,就是返回值只是省略了return。
- 表达式多行,必须{} + return一起使用,void则直接return;
// 参数和返回值都为void
filter(numbers, () -> {System.out.println();return;});表达式为单行,则可以省略return 和 {}filter(numbers, () -> "");filter(numbers, () -> System.out.println());
1.3.3 在哪里使用Lambda表达式
当方法的入参为函数式接口时,可以使用Lambda表达式作为参数
| 使用案例 | Lambda表达式 | 函数式接口 | 函数描述符 | 函数式接口对应的抽象方法 | 备注 |
|---|---|---|---|---|---|
| 布尔表达式 | (List list )-> CollectionUtils.isEmpty(list)) | Predicate | T -> boolean | boolean test(T t) | |
| 消费一个对象,无返回 | (Apple a)-> System.out.println(a) | Consumer | T -> void | void accept(T t) | |
| 消费一个对象,有返回 | (Integer i)-> i + 1 | Function<T, R> | T -> R | R apply(T t) | |
| 创建对象 | ()-> new user(“mjp”) | Supplier | () -> T | T get() | 特例:T -> TUnaryOperator extends Function<T, T> |
| 两个入参 | BiPredicate<T, U>BiConsumer<T, U>BiFunction<T, U, R> | (T, U) -> boolean(T, U) -> void(T, U) -> R | 特例:(T,T) -> TBinaryOperator extends Function<T, T,T> |
1.3.4 函数描述符
-
函数式接口中抽象方法的签名,就是函数描述符
-
Lambda表达式的签名,要和函数式接口中抽象方法的签名一致。req、resp类型相同,否则类型检查不通过
1.3.5 类型推断
-
(Apple a) -> a.getWeight()
-
a -> a.getWeight(),这个明显就是T -> R,属于Function<T,R>函数式接口。
编译器就可以根据抽象方法的函数描述符知道Lambda表达式的签名,即输入为T,就可以在Lambda中省略标注参数类型
1.3. 6 使用局部变量
1、java8中的effective final
- 当你使用jdk7的时候,这样写,会报错,原因是a不是final的
int a = 10;
Runnable runnable = () -> System.out.println(a);
- 当你使用jdk8的时候,编译器自动帮你优化为,所以上述写法不会报错
final int a = 10;
Runnable runnable = () -> System.out.println(a);
- 为什么在匿名内部类| Lambda表达式中使用局部变量,局部变量必须是final修饰 或 是有效的final(要么是后续不再对此变量进行赋值)
这里我们拿lambda表达式举例
他们俩类似,区别是
1)匿名内部类:编译之后会产生一个单独的.class字节码文件
Lambda表达式:编译之后不会产生一个单独的.class字节码文件。对应的字节码会在运行的时候动态生成。
2) 匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。 Lambda表达式:只能是接口
- lambda表达式中使用的局部变量应该是final或者有效的final,也就是说,lambda 表达式只能引用标记了 final 的外层局部变量
- 为什么lambda使用的局部变量要是final修饰的
1)因为想让开发者明确:外部变量的值在lambda表达式中是无法被改变的,这一事实。所以开发者自然不会尝试在lambda中对局部变量进行改变
2)线程安全
- 局部变量x存在栈中
执行的时候在线程t1中。Lambda表达式在线程t2中(lambda并行流有自己的线程池)。若t2直接访问t1的局部变量x,则可能存在t1执行完x直接被释放了,t2访问不到的情况
-
所以,lambda线程访问的都是x的副本
-
如果局部变量x仅仅被赋值一次,则副本和基本变量没什么区别
-
但是若x后续再次被赋值,则可能导致t2访问的副本值 和 最新赋值的值不一样了。存在线程安全问题
-
实例变量(成员变量)则不存在这个问题,因为其存在于堆中,首先不会随着t1线程结束而结束,生命周期和对象实例相关;其次堆对于不同线程也是共享的
2、实战
Set<Long> buyByDimeSkuList = new HashSet<>();if () {//灰度查询buyByDimeSkuList = xxx; } else{buyByDimeSkuList = xxx;}// 4.过滤掉:1)档期预加工品、赠品 2)黑名单品 3)一毛购品sellOutProcessPlanDOList = sellOutProcessPlanDOList.stream().filter(sellOutPlan -> !buyByDimeSkuList.contains(sellOutPlan.getSkuId()))//filter这里会报错,原因buyByDimeSkuList不是final修饰的,而且编译机也无法effective final帮你加final//因为一旦帮你加上final了buyByDimeSkuList就你能再指向别的对象地址了// 所以这里只能再定义一个set变量,将buyByDimeSkuList赋值给他,编译器会帮忙声明为final的,这样在lambda中就可以使用这个新的变量了
1.3.7 方法引用
@Testpublic void t(){// 第一种:static方法的引用List<Integer> l1 = Lists.newArrayList("a", "b").stream().map(Integer::parseInt).collect(Collectors.toList());// 第二种,实例方法的引用List<Integer> l2 = Lists.newArrayList("a", "b").stream().map(String::length).collect(Collectors.toList());// 第三种,对象的方法引用this::xX// 第四种:构造函数引用ClassName::new}
::方法引用,即把这个方法parseInt()作为值传递给map方法。
map方法的参数是Function<T,R>对应的lambda为(String s) -> Integer,即s -> Integer
1.3.8 复合Lambda表达式
1、排序
- 正常升降
//根据Dict对象的sort字段降序排序
dictList.sort(Comparator.comparing(Dict::getSort).reversed());
//根据Dict对象的sort字段升序排序
dictList.sort(Comparator.comparing(Dict::getSort));
先按照字段A降序,当字段A值一样时,再按照字段B降序【需要保证,同一份数据每次排序后,数据顺序要一致】
List<SKUCategoryRuleDO> result = skuCategoryRuleDOS.stream().sorted(Comparator.comparing(SKUCategoryRuleDO::getSkuCategoryId).reversed().thenComparing(SKUCategoryRuleDO::getSkuTemperatureZone,Comparator.reverseOrder())).collect(Collectors.toList());//降-降List<SKUCategoryRuleDO> result = skuCategoryRuleDOS.stream().sorted(Comparator.comparing(SKUCategoryRuleDO::getSkuCategoryId).reversed().thenComparing(SKUCategoryRuleDO::getSkuTemperatureZone,Comparator.reverseOrder())).collect(Collectors.toList());
//当降序字段一样时,需要指定最终按照某个字段排序(否则每次查询出来展示的结果顺序不一样,可以用skuId或者主键id等)
skuCategoryRuleDOS = skuCategoryRuleDOS.stream().sorted(Comparator.comparing(SKUCategoryRuleDO::getSkuCategoryId).reversed().thenComparing(SKUCategoryRuleDO::getId, Comparator.reverseOrder())).collect(Collectors.toList());
参考:https://codeantenna.com/a/HD5Rqszcri
2、谓词复合
@Testpublic void t(){List<String> names = Arrays.asList("Java", "Scala", "C++", "Haskell", "Lisp","Hello","VersionJDK");Predicate<String> filterLengthLowThan5 = str -> {if (str.length() < 5) {return true;}return false;};Predicate<String> filterStartWithJ = str -> {if (str.startsWith("J")) {return true;}return false;};Predicate<String> filterEndWithK = str -> {if (str.endsWith("K")) {return true;}return false;};// 过滤出长度<5并且以J开头,或者以D结尾的单词List<String> result = names.stream().filter(filterLengthLowThan5.and(filterStartWithJ).or(filterEndWithK)).collect(Collectors.toList());System.out.println(result);//[Java, VersionJDK]}//补充negate()和and以及or不同,表示非,即返回一个Predicate的非
3、函数复合
List<Integer> list = Lists.newArrayList(1, 2, 3);Function<Integer, Integer> f1 = x -> x + 1;Function<Integer, Integer> f2 = x -> x * 2;Function<Integer, Integer> filter = f1.andThen(f2);List<Integer> result = list.stream().map(filter).collect(Collectors.toList());System.out.println(result);// 等价map.mapList<Integer> result2 = list.stream().map(f1).map(f2).collect(Collectors.toList());System.out.println(result2);
二、Stream流
2.1 基础概念
-
绝大数Java程序都仅仅使用了CPU中的一核,其它核都闲着。Stream支持并行处理多个数据。Stream库来选择底层最佳执行机制(类似数据库的查询)
-
没有共享的可变数据,以及将方法\函数\行为,传递给其他方法的能力,这两点是函数式编程的基石。也构成了Stream的基础
因为Stream中大多数方法(filter、map、sort)入参都是函数式接口
-
for-each循环一个个迭代元素,属于外部迭代【Collection更多是存储和访问元素】。stream属于内部迭代【元素计算】
-
流只能被消费一次
List<Integer> list = Lists.newArrayList(1, 2, 3);Stream<Integer> stream = list.stream();stream.forEach(System.out::println);stream.forEach(System.out::println);//java.lang.IllegalStateException: stream has already been operated upon or closed
1、创建流三种方式
-
最常见的list.stream
-
数组流Arrays.stream
-
多个集合,创建流Stream.of(list1, list2)
2、文件流
try (Stream<String> lines = Files.lines(Paths.get("/Users/majinpeng/Downloads/codebetter/src/main/resources/data.txt"), Charset.defaultCharset())){List<String> list = lines.map(line -> line.split(" ")).flatMap(Arrays::stream).collect(Collectors.toList());long count = list.stream().distinct().count();System.out.println(count);
} catch (Exception e){}
// File.lines方法返回执行文件中的各行构成的字符串流。
// 流 中的每个元素都是文件中的一行
// 通过扁平化流,可以算出文件中有多少个不同的单词
2.2 中间操作 和 终端操作
2.2.1 中间操作
1、中间操作filter、map、list、sort、distinct等方法返回值都是Stream,可以连城一条流水线
2、执行顺序
- limit会触发短路,即并非全部元素都取出来后,留下三个,而是取到三个满足的直接终止
- filter().map(),不是等filter全部处理完成再到map,而是一个元素经过filter再经过map,下一个元素通用先经过filter再经过map。filter和map合并到同一次遍历中了
2.2.2 终端操作
- 终端操作,触发流的执行,并关闭流。返回值不是流
2.2.3 设计模型:类似构建器模式
中间操作就是各种的set,终端操作就是build()方法
2.2.4 peek中间操作
在流的中间,在不改变流中T的数据类型情况下,对T进行操作赋值
给类属性赋值map的时候,map中的val是Obj,也需要中间赋值操作,这个时候就可以用peek对Obj的属性进行赋值
list.setMap(tempList.stream().peek(dto -> dto.setRdcPoiId(rdcPoiId)).collect(Collectors.toMap(DTO::getSkuId, Function.identity(), (s1, s2) -> s1)));
参考文档:https://segmentfault.com/a/1190000021112585
2.3 使用流-筛选
2.3.1 filter
List<Integer> list = Lists.newArrayList(1, 2, 3, 4, 5);Predicate<Integer> filter1 = i -> i > 1;Predicate<Integer> filter2 = i -> i > 2;Predicate<Integer> filter3 = i -> i > 3;List<Integer> result = list.stream().filter(filter1.and(filter2).or(filter3).negate()).collect(Collectors.toList());//去除key和val为null的entryMap<Long, Person> collect = map.entrySet().stream().filter(entry ->entry.getKey() !=null && entry.getValue()!= null).collect(Collectors.toMap(entry -> entry.getKey(),entry -> entry.getValue()));
补充 Predicate
List<String> names = Arrays.asList("Java", "Scala", "C++", "Haskell", "Lisp","Hello","opt");Predicate<String> filter1 = str -> {if (str.length() > 4) {return false;}return true;};Predicate<String> filter2 = str -> {if (str.startsWith("J") || str.endsWith("p")) {return false;}return true;};List<String> filteredNames = names.stream().filter(filter1.and(filter2)).collect(Collectors.toList());//C++、opt
1、参考文档:https://blog.csdn.net/qazzwx/article/details/107864622
2、实战1 - 销售进度
private Predicate<SellOutProcessPlanDO> getSaleProgressFilter(Integer saleProgress) {Predicate<SellOutProcessPlanDO> saleProgressFilter;if (Objects.nonNull(saleProgress) && saleProgress > 0) {saleProgressFilter = sellOutProcessPlanDO -> {Long maxSellQuantity = sellOutProcessPlanDO.getMaxSaleNum();BigDecimal lockQty = sellOutProcessPlanDO.getSalesVolume();if (Objects.isNull(maxSellQuantity) || maxSellQuantity == 0L|| lockQty == null || Objects.equals(lockQty, BigDecimal.ZERO)) {return false;}return lockQty.divide(BigDecimal.valueOf(maxSellQuantity), 3, RoundingMode.HALF_UP).multiply(BigDecimal.valueOf(100)).compareTo(BigDecimal.valueOf(saleProgress)) >= 0;};} else {saleProgressFilter = sellOutProcessPlanDO -> true;}return saleProgressFilter;}
4、实战2-品类、温层
2.3.2 distinct
1、原理:是通过equals方法使得元素没有重复
List<Integer> skuIds = Lists.newArrayList(1, 2, 3, 4, 5, 1, 2);skuIds = skuIds.stream().filter(i -> i < 5).distinct().collect(Collectors.toList());System.out.println(skuIds);// 1,2,3,4
补充:
-
distinct最好在别的中间操作完成之后再使用
-
一般再查询的时候,最后在底层方法request中对skuId、supplierId等字段进行去重,不要相信调用方其可能传递重复值
2、自定义去重
- 根据类的三个属性作为唯一键,过滤相同唯一键的类
Set<OriginReturnSkuDO> skuDOSet = new TreeSet<>(Comparator.comparing(originReturnSkuDO ->(originReturnSkuDO.getSkuId() + "" + originReturnSkuDO.getPackKey() + "" + originReturnSkuDO.getTaskCode())));skuDOSet.addAll(afterFilterByTriggerGraySkus);//过滤这个listList<OriginReturnSkuDO> batchInsertSkuDOS = new ArrayList<>(skuDOSet);//得到新的list
- 根据类的某一个属性,进行过滤相同属性的类
List<MyUser> myUsers = Lists.newArrayList(myUser, myUser1, myUser2, myUser3, myUser4);
List<MyUser> res = myUsers.stream().filter(distinctByKey(MyUser::getSkuId)).collect(Collectors.toList());public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {Map<Object,Boolean> seen = new ConcurrentHashMap<>();return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
- 待插入db的数据 和 从db中查询出的数据进行去重,只insert db不存在的数据
private List<OriginReturnSkuDO> queryNotDuplicateReturnSku(List<OriginReturnSkuDO> batchInsertSkuDOS, OihReturnSkuMessage request) {List<OriginReturnSkuDO> removedDuplicateSkuDOs = new ArrayList<>();//01.查询db,可退sku信息OriginReturnSkuDOExample example = buildOriginReturnSkuDOExample(request.getTaskNo());List<OriginReturnSkuDO> dbReturnSkuDOList = originReturnSkuMapper.selectByExample(example);if (CollectionUtils.isNotEmpty(dbReturnSkuDOList)){dbReturnSkuDOList = dbReturnSkuDOList.stream().filter(Objects::nonNull).collect(Collectors.toList());}else {return batchInsertSkuDOS;}//02.根据db数据,过滤掉oih再次下发的相同sku数据Map<String,OriginReturnSkuDO> oihReturnSkuMap = new HashMap<>();Map<String,OriginReturnSkuDO> dbReturnSkuMap = new HashMap<>();batchInsertSkuDOS.forEach(originReturnSkuDO -> {String uniqueKey = originReturnSkuDO.getPackKey()+originReturnSkuDO.getSkuId()+originReturnSkuDO.getTaskCode();oihReturnSkuMap.put(uniqueKey, originReturnSkuDO);});dbReturnSkuDOList.forEach(originReturnSkuDO -> {String uniqueKey = originReturnSkuDO.getPackKey() + originReturnSkuDO.getSkuId()+originReturnSkuDO.getTaskCode();dbReturnSkuMap.put(uniqueKey,originReturnSkuDO);});Iterator<Map.Entry<String, OriginReturnSkuDO>> iterator = oihReturnSkuMap.entrySet().iterator();while(iterator.hasNext()){Map.Entry<String, OriginReturnSkuDO> entry = iterator.next();String uniqueKey = entry.getKey();if (Objects.nonNull(dbReturnSkuMap.get(uniqueKey))){//说明db中有这条数据了//过滤掉该条数据iterator.remove();log.warn("从oih获取到重复sku数据,uniqueKey:[{}]", GsonUtils.toJsonString(uniqueKey));}}//03.存过滤后的sku至listremovedDuplicateSkuDOs.addAll(oihReturnSkuMap.values());return removedDuplicateSkuDOs;}
2.3.3 max 过滤留下属性值大的类
属性值为"15:30"
@Testpublic void t() {User u1 = new User();u1.setLotCode("18");u1.setSkuId(1L);User u2 = new User();u2.setLotCode("12");u2.setSkuId(1L);User u3 = new User();u3.setLotCode("11");u3.setSkuId(2L);List<User> list = Lists.newArrayList(u1,u2,u3);Map<Long, User> map = list.stream().collect(Collectors.toMap(User::getSkuId, Function.identity(), BinaryOperator.maxBy(Comparator.comparingInt(value -> NumberUtils.toInt(value.getLotCode(), 0)))));List<User> users = Lists.newArrayList(map.values());System.out.println(users);//[User(skuId=1, lotCode=18, inBirthday=null), User(skuId=2, lotCode=11, inBirthday=null)]。u2和u1在比较过程中被过滤掉了BinaryOperator<String> maxLengthString = BinaryOperator.maxBy(Comparator.comparingInt(String::length));String s = maxLengthString.apply("wxx", "mjp23");System.out.println(s);//mjp23}//如果lotCode是18:30、14:00这种,则需要将:转为. 按照double值比较大小Map<Long, SellOutWarnAndStatusDTO> skuId2latestDtoMap = sellOutWarnAndStatusDtoList.stream().collect(Collectors.toMap(SellOutWarnAndStatusDTO::getSkuId, Function.identity(), BinaryOperator.maxBy(Comparator.comparingDouble(resolveLotCodeToDouble()))));return Lists.newArrayList(skuId2latestDtoMap.values());}private ToDoubleFunction<SellOutWarnAndStatusDTO> resolveLotCodeToDouble() {return value -> {// 14:00 -> 14.00String lotCode = value.getLotCode();String replaceLotCode = StringUtils.replace(lotCode, ":", ".");return NumberUtils.toDouble(replaceLotCode, 0D);};}
属性值为"15"
List<SellOutWarnSkuBO> newestLotCodeBOList = Lists.newArrayList();map.forEach((netPoiIdAndSkuIdAndWarnTypeStr, sellWarnOutBOSubList) ->{Optional<SellOutWarnSkuBO> warnSkuDOOptional = sellWarnOutBOSubList.stream().max(Comparator.comparingInt(sellWarnOutBO -> NumberUtils.toInt(sellWarnOutBO.getLotCode(), 0)));warnSkuDOOptional.ifPresent(newestLotCodeBOList::add);});
2.4 使用流-切片
List<Integer> skuIds = Lists.newArrayList(1, 2, 3, 4, 5, 1, 2);skuIds = skuIds.stream().filter(i -> {System.out.println(i);return i < 5;}).distinct().collect(Collectors.toList());
2.4.1 takeWhile && dropWhile
- filter需要遍历流中的所有数据,对每个元素进行操作
- takeWhile,先排序,然后在遇到第一个不满足的元素时就停止处理(短路)
List<Integer> skuIds = Lists.newArrayList(1, 2, 3, 4, 5, 1, 2);skuIds = skuIds.stream().takeWhile(i -> {System.out.println(i);return i < 5;}).distinct().collect(Collectors.toList());
- dropWhile,在遇到第一个表达式为true的元素时,则停止处理
2.5 使用流-映射
2.5.1 map
Stream map(Function<? super T, ? extends R> mapper)
1、这个入参Function函数会作用到每个元素上,使得元素从T -> R
2、map本身返回Stream
2.5.2 flatMap
Stream flatMap(Function<? super T, ? extends Stream<? extends R> > mapper)
- 这个入参Function函数会作用到每个元素上,使得元素从T -> Stream
- 所有flastMap的作用是:扁平化一个流。如果向拆分流元素且流元素支持再拆分(单词由单个字符组成,数组和集合由元素组成等),则可以使用flatMap
Stream<List> stream1,流中的每个元素都是一个list集合,则使用stream1.flatMap***(***List::stream)
Stream<String[]> stream2,流中的每个元素都是一个数组,则使用stream2.flatMap( Arrays::stream)
-
.collect(Collectors.toList())是将Stream 转换为List去除Stream
.flatMap()方法入参是Function为函数式接口T -> Stream,方法出参是Stream
1、对集合中元素去重
List<String> words = Lists.newArrayList("hello", "hello", "world");System.out.println(words.stream().distinct().collect(Collectors.toList()));//"hello", "world"
2、对集合每个元素中的具体单词去重,即结果为: h e l o w r d
- 无效代码1
List<String> words = Lists.newArrayList("hello", "hello", "world");List<String[]> result = words.stream().map(s -> s.split("")).distinct().collect(Collectors.toList());
这里的map是将Stream<String> 转换为 Stream<String[]>, 后者流中每个元素都是一个String数组,再distinct去重的时候,
对每个数组进行equals比较,地址肯定都不一样, 所以无法实现
- 无效代码2
List<String> words = Lists.newArrayList("hello", "world");
Stream<String[]> stream = words.stream().map(s -> s.split(""));// Arrays.stream方法,入参是T[] array, 出参是Stream<T>
// map的入参是String[],出参是Stream<String>
Stream<Stream<String>> stream1 = stream.map(strings -> Arrays.stream(strings));List<Stream<String>> result = stream1.distinct().collect(Collectors.toList());
- 有效代码flatMap
List<String> words = Lists.newArrayList("hello", "world");Stream<String[]> stream1 = words.stream().map(s -> s.split(""));// 这个Stream<T>每个元素都是一个数据,将数组再扁平化化,使用Arrays::stream函数// 如果T是list,则将集合再扁平化,使用Collection::streamStream<String> stream2 = stream1.flatMap(strings -> Arrays.stream(strings));List<String> result = stream2.distinct().collect(Collectors.toList());System.out.println(result);
3、给出[1,2]和[3,4]返回[ (1,3) ,(1,4) ,(2,3) ,(2,4) ]
// Stream<(1,3)>、Stream<(1,4)>、Stream<(2,3)>,Stream<(2,4)>
// i = 1时,Stream<(1,3)>、Stream<(1,4)> 即 T -> Stream<数组>,则使用flatMapList<int[]> result = list1.stream().flatMap(i1 -> {Stream<int[]> array = list2.stream().map(i2 -> new int[]{i1, i2});return array;}).collect(Collectors.toList());
4、给出[1,2]和[3,4]返回[ (1,3) ,(1,4) ,(2,3) ,(2,4) ],只返回总和能被3整除的数对
List<int[]> result = list1.stream().flatMap(i1 -> {Stream<int[]> array = list2.stream().filter(i2 -> (i1 + i2) % 3 == 0).map(i2 -> new int[]{i1, i2});return array;}).collect(Collectors.toList());
5、根据勾股定理,求出aa + bb = c*c,其中a、b均在(1,100)
[3,4,5]、[…]
List<int[]> result = IntStream.rangeClosed(1, 100).boxed().flatMap(a -> IntStream.rangeClosed(a, 100).boxed().filter(b -> Math.sqrt(a * a + b * b) % 1 == 0).map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)})).collect(Collectors.toList());result.forEach(ints -> System.out.println(Arrays.toString(ints)));// 等价// 01.创建Stream<Integer>流,元素从1-100Stream<Integer> integerStream1 = IntStream.rangeClosed(1, 100).boxed();// 02.遍历流元素Stream<int[]> stream2 = integerStream1.flatMap(a -> {// 03.创建Stream<Integer>流,元素从a-100Stream<Integer> integerStream2 = IntStream.rangeClosed(a, 100).boxed();// 04.给出a的值,根据勾股定理,可以确定b的值(过滤一部分b)Stream<Integer> tempStream = integerStream2.filter(b -> Math.sqrt(a * a + b * b) % 1 == 0);// 05.给出a的值,根据勾股定理,可以确定c的值,并构造出一组勾股值Stream<int[]> stream1 = tempStream.map(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)});return stream1;});// 06.转换为集合并打印List<int[]> collect1 = stream2.collect(Collectors.toList());collect1.forEach(ints -> System.out.println(Arrays.toString(ints)));// 补充: 也可以先直接根据 Math.sqrt(a * a + b * b)算出全部c以及全部组合,然后再过滤满足条件的c即arr[2] % 1 == 0
2.6 使用流-查找和匹配
终端操作
2.6.1 allMatch全部匹配
List<Integer> list1 = Lists.newArrayList(1, 2);boolean b = list1.stream().allMatch(i -> i > 1);System.out.println(b);//false
2.6.2 anyMatch任意匹配
List<Integer> list1 = Lists.newArrayList(1, 2);boolean b = list1.stream().anyMatch(i -> i > 1);System.out.println(b);//true
2.6.3 findAny查找任意
一般和其他流操作结合使用。比如:查找任意一个 > 1的数(先filter再findAny)
Optional<Integer> optional = list1.stream().filter(i -> i > 1).findAny();if (optional.isPresent()) {Integer i = optional.get();}
2.6.4 findFirst 查找第一个
- 一般和其他流操作结合使用。比如:查找第一个 > 1的数(先filter再findFirst)
- 如果不关心返回的元素是哪个,建议使用findAny。因为其在使用并行流的时候限制较少
// 找出第一个,平方后能被3整除的数
List<Integer> list1 = Lists.newArrayList(1, 2, 3, 4);Optional<Integer> optional = list1.stream().map(i -> i * i).filter(i -> i % 3 == 0).findFirst();if (optional.isPresent()) {Integer i = optional.get();//9}
2.7 使用流-归约reduce
把一个流中的元素组合起来
2.7.1 求和
1、reduce(初始值,BinaryOperator)
其中BinaryOperator用的Lambda将两个元素结合起来产生新值
Integer sum = list.stream().reduce(0, (a, b) -> a + b);
等价:语法糖
Integer sum = list.stream().reduce(0, Integer::sum);
补充:其它求和
long sum = list.stream().reduce(Integer::sum).orElse(0);//List<Integer>
return sellOutWarnCategoryCountDOS.stream().collect(Collectors.summingInt(SellOutWarnCategoryCountDO::getTodoSkuCount));
2、reduce(BinaryOperator):无初始值,返回Optional对象
Optional<Integer> sumOptional = list.stream().reduce((a, b) -> a + b);if (sumOptional.isPresent()) {Integer sum = sumOptional.get();}等价:语法糖Optional<Integer> sumOptional = list.stream().reduce(Integer::sum);if (sumOptional.isPresent()) {Integer sum = sumOptional.get();}
实战map-reduce
获取大仓对应的品类仓集合:Map<Long, List<Long>> return Lists.partition(rdcIds, 20).stream().map(subRdcIds -> CompletableFuture.supplyAsync(() -> queryCategoryWarehouseByRdc(subRdcIds),cQueryExecutor)).collect(toList()).stream().map(CompletableFuture::join).reduce((m1, m2) -> {m1.putAll(m2);return m1;}).orElse(Maps.newHashMap());//等价// 1.并发查询List<CompletableFuture<Map<Long, List<Long>>>> list1 = Lists.partition(rdcIds, 20).stream().map(subRdcIds -> CompletableFuture.supplyAsync(() -> queryCategoryWarehouseByRdc(subRdcIds), cQueryExecutor)).collect(toList());// 2.阻塞获取结果List<Map<Long, List<Long>>> list2 = list1.stream().map(mapCompletableFuture -> {return mapCompletableFuture.join();}).collect(toList());// 3.reduce【把一个流中的元素组合起来】Map<Long, List<Long>> result = list2.stream().reduce((map1, map2) -> {map1.putAll(map2);return map1;}).orElse(new HashMap<>());// 4.list<List<Integer>>同理,reduce中(collect1, collect2) -> collect1.addAll(collect2) return collect1
实战list-reduce
- eg1
int threshold = 200;return Lists.partition(skuIds, threshold).stream().map(skus -> {SdcTrusteeshipSkuDOExample example = new SdcTrusteeshipSkuDOExample();example.createCriteria().andSkuIdIn(skus).andSaleDayEqualTo(saleDay).andNetPoiIdEqualTo(netPoiId).andValidEqualTo(Boolean.TRUE);return example;}).map(example -> sdcTrusteeshipSkuMapper.selectByExample(example)).reduce((sdcTrusteeshipSkuDoList1, sdcTrusteeshipSkuDoList2) -> {sdcTrusteeshipSkuDoList1.addAll(sdcTrusteeshipSkuDoList2);return sdcTrusteeshipSkuDoList1;}).orElse(Lists.newArrayList());
- eg2
// 方式1,使用flatMapList<PoiBasicTInfo> res1 = Lists.partition(poiIds, POI_LIMIT_SIZE).stream().map(partPoiIds -> CompletableFuture.supplyAsync(() -> queryPoiInfoByPoiId(partPoiIds), cQueryExecutor)).collect(toList()).stream().map(CompletableFuture::join).flatMap(List::stream).collect(toList());
// 方式2,使用reduceList<PoiBasicTInfo> res = Lists.partition(poiIds, POI_LIMIT_SIZE).stream().map(partPoiIds -> CompletableFuture.supplyAsync(() -> queryPoiInfoByPoiId(partPoiIds), cQueryExecutor)).collect(toList()).stream().map(CompletableFuture::join).reduce(Collections.emptyList(), (l1, l2) -> {l1.addAll(l2);return l1;});
实战CompletableFuture-reduce
List<CompletableFuture<T>>, 集合中的每个元素都是 CompletableFutureList<CompletableFuture<List<Integer>>> tempList = Lists.partition(model.getSkuIdList(), LionUtil.batchQueryLockStatusSize()).stream().map(skus -> buildQueryLockStockStatusParam(model.getNetPoiId(), skus, model.getPickDate())).map(lockStatusParam -> CompletableFuture.supplyAsync(() ->stmLockMaxStockGateway.getLockStatus(lockStatusParam), queryLockStatusAndOrExecutor)).collect(Collectors.toList());CompletableFuture<List<Integer>> cf1 = tempList.stream().reduce(// 每个元素都是cf,cf,cf, cf之间可以通过thenCombine的形式聚合结果(fn1, fn2) -> fn1.thenCombine(fn2, (integers, integers2) -> Stream.of(integers, integers2).flatMap(Collection::stream).collect(Collectors.toList()))).orElse(CompletableFuture.completedFuture(Collections.emptyList()));
2.7.2 max、min、count
1、max
最大 List<Integer> list = Lists.newArrayList(1, 2, 3);Optional<Integer> optional = list.stream().reduce((a, b) -> a > b ? a : b);if (optional.isPresent()) {Integer max = optional.get();}// 等效Optional<Integer> optional = list.stream().max((a, b) -> a.compareTo(b));// 语法糖Optional<Integer> optional1 = list.stream().max(Integer::compareTo);
2、count
list.stream().count() ==> list.size()
2.7.3 concat合并多个流
https://www.leftso.com/blog/613.html
2.8 使用流-归约 Collect
2.8.1 简介
1、collect、Collector、Collectors
- collect是流的终端操作,类似reduce是归约操作,将流元素累积成一个汇总结果。collect方法的参数是Collector接口的具体实现
- Collector是一个普通接口
- Collectors是一个final类,提供了许多静态工厂方法返回值为Collector
2、收集器
- 作用:不同的收集器对流做不同的归约操作,主要三大功能:归约和汇总、分组、分区
- 创建:Collector接口的具体实现类、Collectors类的静态工厂方法创建Collectors.toList()、Collectors.groupingBy()等
2.8.2 归约和汇总-LongSummaryStatistics
1、个数、最大值、最小值、平均值、总和等
@Testpublic void t(){ArrayList<Integer> list = Lists.newArrayList(1, 2, 3, 4, 5);IntSummaryStatistics collect = list.stream().collect(Collectors.summarizingInt(Integer::intValue));System.out.println(collect);//IntSummaryStatistics{count=5, sum=15, min=1, average=3.000000, max=5}}
LongSummaryStatistics参考:https://juejin.cn/post/7119674659330588686
NumberUtils参考:https://www.jianshu.com/p/46472ab7246b
2.8.3 连接字符串-join
joining内部使用了StringBuilder来把字符串逐个加起来
MyUser myUser = new MyUser();myUser.setCwId(1L);myUser.setCwName("hello");MyUser myuser2 = new MyUser();myuser2.setCwId(1L);myuser2.setCwName("world");List<MyUser> myUsers = Lists.newArrayList(myUser, myuser2);String collect = myUsers.stream().map(MyUser::getCwName).collect(Collectors.joining(", "));//hello, world
2.8.4 归约 - reducing
MyUser u1 = new MyUser();u1.setAge(18);MyUser u2 = new MyUser();u2.setAge(28);ArrayList<MyUser> list = Lists.newArrayList(u1, u2);Integer sum = list.stream().map(MyUser::getAge).reduce(0, Integer::sum); //正常推荐map + reduceInteger sum2 = list.stream().collect(Collectors.reducing(0, MyUser::getAge, Integer::sum));IntStream intStream = list.stream().mapToInt(MyUser::getAge); int sum3 = intStream.sum(); //不拆箱推荐此种
2.8.5 分组- groupingBy
1、groupingBy(Function<? super T, ? extends K> func):方法入参为函数式接口Function,这里叫分类函数,可以将流中元素分为不同的组
- 按照性别分组
MyUser u1 = new MyUser();u1.setAge(10);u1.setName("zhangsan");u1.setSex(1);MyUser u2 = new MyUser();u2.setAge(40);u2.setName("lisi");u2.setSex(1);MyUser u3 = new MyUser();u3.setAge(50);u3.setName("lilei");u3.setSex(0);List<MyUser> list = Lists.newArrayList(u1,u2, u3);Map<Integer, List<MyUser>> map = list.stream().collect(groupingBy(MyUser::getSex));//{0=[MyUser(age=50, name=lilei, sex=0)], 1=[MyUser(age=10, name=zhangsan, sex=1), MyUser(age=40, name=lisi, sex=1)]}
- 按照年龄段,自定义分组。枚举青年【YONG:20 - 30】、中年【MIDDLE : 30 - 50】、老年【OLD:> 50】
@Getter
@AllArgsConstructor
public enum AgeEnum {YOUNG(1, "年轻人"),MIDDLE(2, "中年"),OLD(3, "老年");private final Integer code;private final String desc;
}List<MyUser> list = Lists.newArrayList(u1, u2, u3);Map<String, List<MyUser>> map = list.stream().collect(groupingBy(user -> {Integer age = user.getAge();if (age <= 30) {return AgeEnum.YOUNG.getDesc();} else if (age <= 50) {return AgeEnum.MIDDLE.getDesc();} else {return AgeEnum.OLD.getDesc();}}));System.out.println(map);
2、Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> func, Collector<? super T, A, D> c)
-
第一个入参为函数式接口Function,这里叫分类函数,可以将流中元素分为不同的组
-
第二个参数是Collector接口的实现类,也是一个收集器
作用:第二个收集器,通常对被参数一分到同一组中的所有元素再执行一次归约操作
-
场景:用于多级分组、分组后过滤、分组后再映射
a)过滤:
- 按照性别分组,每组人只要年龄小于35岁的(Collectors.filtering)
//{1=[MyUser(age=10, name=zhangsan, sex=1)]} 发现0对应的分组,因为没有符合的元素,导致key都没了Map<Integer, List<MyUser>> map1 = list.stream().filter(myUser -> myUser.getAge() < 35).collect(groupingBy(MyUser::getSex));//{0=[], 1=[MyUser(age=10, name=zhangsan, sex=1)]} 分组0没有元素,但是key还存在,其中filtering为Jdk9方法Map<Integer, List<MyUser>> map2 = list.stream().collect(groupingBy(MyUser::getSex,Collectors.filtering(user -> user.getAge() < 35),toList()));
- 每种性别中年龄最小的人
Map<Integer, Optional<MyUser>> map = list.stream().collect(groupingBy(MyUser::getSex,Collectors.minBy(Comparator.comparingInt(MyUser::getAge))));//{0=Optional[MyUser(age=40, name=lilei, sex=0)], 1=Optional[MyUser(age=10, name=zhangsan, sex=1)]}//去掉OptionalMap<Integer, MyUser> map = list.stream().collect(groupingBy(MyUser::getSex,Collectors.collectingAndThen(Collectors.minBy(Comparator.comparingInt(MyUser::getAge)),Optional::get)));
b)映射:按照性别分组,取每组人的姓名(Collectors.mapping)
// 3.按照性别分组,然后取姓名{0=[lilei], 1=[lisi, zhangsan]}Map<Integer, Set<String>> map3 = list.stream().collect(groupingBy(MyUser::getSex,mapping(MyUser::getName, Collectors.toSet())));
c)多级分组:不同性别、不同的年龄划分
List<MyUser> list = Lists.newArrayList(u1,u2, u3, u4);Map<Integer, Map<String, List<MyUser>>> map = list.stream().collect(groupingBy(MyUser::getSex,groupingBy(user -> {Integer age = user.getAge();if (age <= 30) {return AgeEnum.YOUNG.getDesc();} else if (age <= 50) {return AgeEnum.MIDDLE.getDesc();} else {return AgeEnum.OLD.getDesc();}})));
0={老年=[MyUser(age=100, name=hanmeimei, sex=0)], 中年=[MyUser(age=40, name=lilei, sex=0)]
},
1={年轻人=[MyUser(age=10, name=zhangsan, sex=1)], 中年=[MyUser(age=40, name=lisi, sex=1)]
}
d)子组收集器:不同性别、人数
List<MyUser> list = Lists.newArrayList(u1,u2, u3, u4);Map<Integer, Long> map = list.stream().collect(groupingBy(MyUser::getSex,Collectors.counting()));
3、Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> func ,Supplier mapFactory, Collector<? super T, A, D> downstream)
- 第二个参数是函数式接口【void -> T】,第一、三个入参同上
2.8.6 分区
1、定义:特殊的分组。分组可以分为年轻、中年、老年多个组,但是分区只能有两个组,越库(True)、非越库(False)
2、优势:结构紧凑、高效
3、实战
- 性别分区
Map<Boolean, List<MyUser>> map = list.stream().collect(Collectors.partitioningBy(user -> user.getSex().equals(1)//男性));
- 男性|女性 中年龄最大的
对分区后的每个区中的元素,再进行一收集
Map<Boolean, MyUser> map = list.stream().collect(Collectors.partitioningBy(user -> user.getSex().equals(1),Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(MyUser::getAge)),Optional::get)));
- 将数字按质量数和非质数分区
// 2-10的质数
Stream<Integer> stream = IntStream.rangeClosed(2, 10).boxed();Map<Boolean, List<Integer>> map = stream.collect(partitioningBy(n -> isPrime(n)));// {false=[4, 6, 8, 9, 10], true=[2, 3, 5, 7]}private boolean isPrime(Integer n) {IntStream range = IntStream.range(2, n); //从[2 ~ n-1]都无法被n整除,则n为质数return range.noneMatch(i -> n % i == 0); }
2.8.7 list转为map: toMap(类似常用的toList)
1、将list中对象的某两个属性,作为map的k-v
Map<Long, String> cwIdAndNameMap = cwInfoByCwIds.stream().collect(Collectors.toMap(Warehouse::getCwId, Warehouse::getName));
2、将list中对象的某些属性组成key,对象为val
Map<String, MyUser> map = list.stream().collect(Collectors.toMap(user -> buildKey(user),Function.identity() //表示T -> T,所以这里也可以写user -> user));将list<Obj>中Obj作为key,Obj中几个属性组成一个新的NewObj作为val
list.stream().collect(Collectors.toMap(Function.identity(), sellOutWarnSkuBo -> {LockStockRequest lockStockRequest = new LockStockRequest();lockStockRequest.setSkuId(sellOutWarnSkuBo.getSkuId());lockStockRequest.setPoiId(sellOutWarnSkuBo.getNetPoiId());return lockStockRequest;},(l1, l2) -> l1)); //如果需要第三个参数,则这种形式
三、Java8新增特性
3.1 Map相关
3.1.0 compute、computeIfAbsent、putIfAbsent、put
- put: 方法存储作用:没有key对应的val,则直接存;有key对应的val则覆盖
返回值:put返回旧值,如果没有则返回null
public void put() {Map<String, Integer> map = Maps.newHashMap();map.put("a",1);Integer b = map.put("b", 2);System.out.println(b);//nullInteger v = map.put("b",3); // 输出 2System.out.println(v);Integer v1 = map.put("c",4);System.out.println(v1); // 输出:NULL}
-
compute:方法存储作用同理put。存储返回值返回新值,如果没有则返回null
-
putIfAbsent
没有key对应的val,则直接存;有key对应的val则不存储
返回值:同put方法的返回旧值,没有返null
- computeIfAbsent
存在了就不添加,也就不覆盖了,还是原值,返回的就是原值。不存在时,添加,返回添加的值
Map<String, Integer> map = Maps.newHashMap();//存在时返回存在的值,不存在时返回新值map.put("a",1);map.put("b",2);Integer v = map.computeIfAbsent("b",k->3); // 输出 2System.out.println(v);Integer v1 = map.computeIfAbsent("c",k->4); // 输出 4System.out.println(v1);System.out.println(map);//{a=1, b=2, c=4}
3.1.1 排序
Map<String,Integer> result = new HashMap<>();Map<String,Integer> map = new HashMap<>();map.entrySet().stream().sorted(Map.Entry.comparingByKey()) //对key排序,还可以对val排序;也可以降序.forEachOrdered(e -> result.put(e.getKey(), e.getValue()));
// 注意:这里其实result已经按照key进行了排序,但是map在遍历的时候是随机的,所以遍历result的时候,结果看起来还是随机的
// 1.如果想让遍历的result也是有序的,则可以使用TreeMap、LinkedHashMap
// 2.如果只是想按照key正序遍历map,则可以直接在forEachOrdered里面获取k-v即可
3.1.2 计数
- computeIfAbsent:将相同的数存储到一个对应List集合中
- 存储:key不存在或为null,则存k-v。key存在则不存
- 返回值:如果 key 不存在或为null,则返回 本次存储的val; key 已经在,返回对应的 val
//场景:将相同的数存储到一个对应List集合中List<Integer> list = Lists.newArrayList(1,2,3,1,3,4,6,7,9,9,1,3,4,5);Map<Integer, List<Integer>> map = new HashMap<>();list.forEach(item -> {List<Integer> integerList = map.computeIfAbsent(item, key -> new ArrayList<>());integerList.add(item);});System.out.println(map);//{1=[1, 1, 1], 2=[2], 3=[3, 3, 3], 4=[4, 4], 5=[5], 6=[6], 7=[7], 9=[9, 9]}
- 线程安全的计算key出现的次数
AtomicLongMap<String> map = AtomicLongMap.create(); //线程安全,支持并发List<String> list = Lists.newArrayList("a", "a", "b", "c", "d", "d", "d");list.forEach(map::incrementAndGet);
这里使用AtomicLongMap的原因:https://blog.csdn.net/HEYUTAO007/article/details/61429454
import com.google.common.util.concurrent.AtomicLongMap;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.locks.ReentrantReadWriteLock;public class GuavaTest {//来自于Google的Guava项目AtomicLongMap<String> map = AtomicLongMap.create(); //线程安全,支持并发Map<String, Integer> map2 = new HashMap<String, Integer>(); //线程不安全Map<String, Integer> map3 = new HashMap<String, Integer>(); //线程不安全ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); //为map2增加并发锁Map<String, Integer> map4 = new ConcurrentHashMap<String, Integer>(); //线程安全,但也要注意使用方式private int taskCount = 100;CountDownLatch latch = new CountDownLatch(taskCount); //新建倒计时计数器,设置state为taskCount变量值public static void main(String[] args) {GuavaTest t = new GuavaTest();t.test();}private void test(){//启动线程for(int i=1; i<=taskCount; i++){Thread t = new Thread(new MyTask("key", 100));t.start();}try {//等待直到state值为0,再继续往下执行latch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("##### AtomicLongMap #####");for(String key : map.asMap().keySet()){System.out.println(key + ": " + map.get(key));}System.out.println("##### HashMap未加ReentrantReadWriteLock锁 #####");for(String key : map2.keySet()){System.out.println(key + ": " + map2.get(key));}System.out.println("##### HashMap加ReentrantReadWriteLock锁 #####");for(String key : map3.keySet()){System.out.println(key + ": " + map3.get(key));}System.out.println("##### ConcurrentHashMap #####");for(String key : map4.keySet()){System.out.println(key + ": " + map4.get(key));}}class MyTask implements Runnable{private String key;private int count = 0;public MyTask(String key, int count){this.key = key;this.count = count;}@Overridepublic void run() {try {for(int i=0; i<count; i++){map.incrementAndGet(key); //key值自增1后,返回该key的值if(map2.containsKey(key)){map2.put(key, map2.get(key)+1);}else{map2.put(key, 1);}//对map2添加写锁,可以解决线程并发问题lock.writeLock().lock();try{if(map3.containsKey(key)){map3.put(key, map3.get(key)+1);}else{map3.put(key, 1);}}catch(Exception ex){ex.printStackTrace();}finally{lock.writeLock().unlock();}//虽然ConcurrentHashMap是线程安全的,但是以下语句块不是整体同步,导致ConcurrentHashMap的使用存在并发问题if(map4.containsKey(key)){map4.put(key, map4.get(key)+1);}else{map4.put(key, 1);}//TimeUnit.MILLISECONDS.sleep(50); //线程休眠50毫秒}} catch (Exception e) {e.printStackTrace();} finally {latch.countDown(); //state值减1}}}}
3.1.3 两个map合并-merge
- putAll
Map<String, Integer> map = new HashMap<>();Map<String, Integer> map1 = new HashMap<>();map.put("tmac", 18);map.put("mjp", 40);map.put("wxx", 23);map1.put("wxx", 1);map1.putAll(map);
// 如果map 和 map1有相同的key,putAll的时候,不会覆盖
- merge
Map<Integer, String> map = new HashMap<>();Map<Integer, String> map1 = new HashMap<>();map.put(1,"mjp");map.put(2,"wxx");map1.put(1, "tmac");map.forEach((k, v) -> {map1.merge(k, v, (v1 , v2) -> v1 + "-" + v2);});
// map1 {1=tmac-mjp, 2=wxx}
3.1.4 其它
- map的key为不常见的类型时
Map<Byte, List<User>> map = list.stream().collect(Collectors.groupingBy(User::getTemperatureZone));
List<User> resList = map.get((byte)5);
错误:List<User> resList = map.get(5); ===== npe
3.2 Optional
3.2.1 Optional简介
- 作用:Optional 类的引入很好的解决空指针异常。
- Optional 是个容器:它可以保存类型T的值,或者仅仅保存null;Optinal类本质上是一个只能存放一个元素的不可变集合
- Optional.empty ()返回一个空的optional;
- Optional.of(value)返回一个包含了指定非null值的optional
3.2.2 Optional常用方法
点击展开内容
| 方法名称 | 作用 | eg | 备注 |
|---|---|---|---|
| empty() | 返回空的 Optional 实例 | Optional*<Integer>* optional = Optional.empty*();//Optional.emptyboolean present = o.isPresent()*;//false | Optional集合中有一个为Null的元素,则ifPresent返回false |
| ifPresent | 值存在则方法会返回true | Optional*<Integer>* optional2 = Optional.ofNullable*(1)*;//Optional[1] | Optional集合中有一个不为Null的元素1,则ifPresent返回true |
| ofNullable(T value) | 如果为非空,返回 Optional 描述的指定值,否则返回空的 Optional | Optional*<Integer>* optional2 = Optional.ofNullable*(null);//Optional.empty Optional<Integer>* optional3 = Optional.ofNullable*(3)*;//Optional[3] | |
| of(T value) | value不能为null,否则会npe | Optional.of*(null)*;//NPE | / |
| map | 如果调用方有值,则对其执行调用映射函数得到返回值。 如果返回值不为 null,则创建包含映射返回值的Optional作为map方法回值,调用方无值,否则返回空Optional。 | Optional*<Integer>* optional = Optional.ofNullable*(3);//Optional[3]optional有值,且map映射后的返回值也不为null,则最终返回:Optional[“0011”]Optional<String>* optionalByte = optional.map*(Integer::toBinaryString);Optional<Integer>* optional = Optional.ofNullable*(null);//Optional.emptyOptional<String>* optionalByte = optional.map*(Integer::toBinaryString)*; optional无值则返回Optional.empty | Optional*<Integer>* optional = Optional.ofNullable*(3);Optional<String>* result = optional.map*(null)*; 报错npe |
| orElse**(T other)** | 如果存在该值,返回值, 否则返回 other。 | Optional*<Integer>* optional = Optional.ofNullable*(1);//Optional[3] Integer result = optional.orElse(23); System.out.println(result);//1 Optional<Integer>* optional1 = Optional.empty*(); Integer result1 = optional1.orElse(23); System.out.println(result1)*;//23 |
3.2.3 优雅的取值
dto.setSupplierId(Optional.ofNullable(source.getVendorDTO()).map(VendorDTO::getVendorId).orElse(null))
3.2.4 注意事项:
- 不要给 Optional 变量赋值 null,否则违背了Optional的初衷
Optional<Integer> optional = Optional.empty();
Optional<String> result = optional.map(Integer::toBinaryString);//Optional.emptyOptional<Integer> optional = null;
Optional<String> result = optional.map(Integer::toBinaryString);
System.out.println(result);//npe
3.3 时间类
3.3.1 Temporal实现类
- 2022-12-14 07:14:41 ,对应LocalDateTime操作
- 2022-12-14,对应LocalDate操作
- 07:14:41,对应LocalTime操作
3.3.2 ChronoUnit
- 天数差:计算某天距某天,过了多少天
- 年差、小时差、分钟差等
long diffDays = ChronoUnit.DAYS.between(LocalDate.now(), LocalDate.of(2018, 10, 8));System.out.println(diffDays);//-1529long diffDays2 = ChronoUnit.DAYS.between(LocalDate.of(2018, 10, 8), LocalDate.now());System.out.println(diffDays2);//1529
3.3.3 Period 和 Duration
LocalDate startDate = LocalDate.of(2022, 12, 12);LocalDate endDate = LocalDate.of(2022, 11, 11);Period period = Period.between(endDate, startDate);int diffDays = period.getDays();System.out.println(diffDays);// 应该为31,这里为1天,因为Period无法处理跨越的天数差计算
使用参考:https://blog.csdn.net/neweastsun/article/details/88770592
3.4 默认方法
3.4.1 简介
背景:接口引入默认方法,可以让接口的实现类,自动的继承
eg:List接口的sort
注意:函数式接口,只是包含一个抽象方法,但是可以包含一个或多个默认方法
eg:Predicate接口中and、or默认方法
3.4.1 菱形问题:
1、问题描述:一个类同时继承了具有相同函数签名的两个方法
-
类可以实现多个接口,假如每个接口都有默认方法,则类可以从多个接口中继承他们的行为(默认方法)
假如不同接口的默认方法函数签名一样,则会出现二义性
-
与此同时,此类本身也可能定义了此相同签名的方法
-
与此同时,类也可能继承的父类,获取了此相同签名的方法
2、解决菱形问题
-
类中的方法优先级最高(类或者父类中声明的方法优先级高于默认方法)
-
其次,子接口的优先级高于父接口
-
最后如果还是无法判断,则类必须显式覆盖 和调用期望的方法,显式的选择使用哪一个默认方法的实现
C中覆盖方法,并显式的调用
public class C implements B,A {void hello(){B.super().hello();//java8引入的新语法,表示调用B接口中的hello方法}
}
3、特殊场景
-
如果D是抽象类,D中的方法是抽象方法,则C类就必须提供自己的hello方法
-
现在D调用hello()是调用A的方法;如果B也提供了一个默认的hello(),则使用B的;
-
如果B、C都提供了默认的hello(),则D就要显式的调用
-
如果B提供的不是默认hello(),而是一个abstract抽象hello(),D会调用子类接口C的抽象hello,故D需要需要为C的abstract抽象添加具体的实现代码,否则无法编译
四、CompletableFuture
4.1 简介
4.1.1 产生背景
- JDK5新增了Future接口,用于描述一个异步计算的结果。虽然 Future 以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的 CPU 资源,而且也不能及时地得到计算结果。
- Java8中,CompletableFuture提供了非常强大的Future的扩展功能(implement Future),可以帮助我们简化异步编程的复杂性,并且提供了函数式编程的能力,可以通过回调的方式处理计算结果,也提供了转换和组合 CompletableFuture 的方法。
4.1.2 概念
-
它实现了Future和CompletionStage接口
-
CompletionStage代表异步计算过程中的某一个阶段,一个阶段完成以后可能会触发另外一个阶段
-
一个阶段的计算执行可以是一个Function,Consumer或者Runnable。
比如:stage.thenApply(x -> square(x)).thenAccept(x -> System.out.print(x)).thenRun(() -> System.out.println())
-
一个阶段的执行可能是被单个阶段的完成触发,也可能是由多个阶段一起触发
4.2 正确使用姿势
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ApplicationLoader.class)
@Slf4j
public class BaseTest {/**** xxx(args):CompletableFeture,会把任务A和任务B,封装为一个任务,submit给默认线程池:ForkJoinPool* xxxAsync(args):任务A和任务B,是两个独立的异步任务,分别submit给默认线程池:ForkJoinPool,开启两个独立的thread执行* xxxAsync(args,executor):同上,只不过是自定义线程池*//*** 1、thenCompose : 连接* 等效方法:thenApply* 串行,A异步执行完,B才能执行。然后返回A、B执行结果给main* A厨师炒完番茄鸡蛋、B服务员再去拿米饭,main 吃饭*/@Testpublic void thenCompose() {System.out.println(Thread.currentThread().getName() + ":进入餐厅");System.out.println(Thread.currentThread().getName() + ":点了番茄炒蛋和米饭");CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":炒番茄鸡蛋");return "炒番茄鸡蛋";}).thenCompose(work1Return -> CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":拿米饭");return work1Return + "米饭";}));System.out.println(Thread.currentThread().getName() + ":王者荣耀");System.out.println(Thread.currentThread().getName() + String.format("%s", "开吃" + cf1.join()));}/*** 1、1 thenComposeAsync : 连接* 等效方法:thenApplyAsync* 串行,A异步执行完,B才能【异步】执行。然后返回A、B执行结果给main(A和B是两个异步任务,由两个独立的线程执行)* A厨师炒完番茄鸡蛋、B服务员再去拿米饭,main 吃饭*/@Testpublic void thenComposeAsync() {System.out.println(Thread.currentThread().getName() + ":进入餐厅");System.out.println(Thread.currentThread().getName() + ":点了番茄炒蛋和米饭");CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":炒番茄鸡蛋");return "炒番茄鸡蛋";}).thenComposeAsync(work1Return -> CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":拿米饭");return work1Return + "米饭";}));System.out.println(Thread.currentThread().getName() + ":王者荣耀");System.out.println(Thread.currentThread().getName() + String.format("%s", "开吃" + cf1.join()));}/*** 2、thenCombine:合并* A异步执行,同时B异步执行,A、B异步执行结束,将结果返回给main* A厨师炒菜,同时 B服务员蒸饭,AB结束,main吃饭* A计算商品件数,同时B计算商品价格,AB结束,计算GMV = A * B*/@Testpublic void thenCombine() {System.out.println(Thread.currentThread().getName() + ":进入餐厅");System.out.println(Thread.currentThread().getName() + ":点了番茄炒蛋和米饭");CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":炒番茄鸡蛋");return "炒番茄鸡蛋";}).thenCombine(CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":服务员做饭");return "蒸米饭";}), (dish, rich) -> {System.out.println(Thread.currentThread().getName() + ":菜饭都好了");return String.format("%s" + "%s", dish, rich);});System.out.println(Thread.currentThread().getName() + ":王者荣耀");System.out.println(Thread.currentThread().getName() + String.format("%s", "开吃" + cf1.join()));}/*** 3、applyToEither:获取最先完成的任务* 141先到就坐141,青卢线先到就坐青卢线。* A和B都是异步执行,谁先结束,就把谁的结果交给(赋值)applyToEither函数的第二个参数=>Function函数,* main就用Function返回结果,继续执行别的操作*/@Testpublic void applyToEither() {CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(1l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + ":141来了");return "141";}).applyToEither(CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(2l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + "青卢线来了");return "青卢线";}),firstCar -> firstCar);System.out.println(Thread.currentThread().getName() + String.format("坐"+"%s" +"回家" , cf1.join()));}/*** 1min内电话没人接,则挂断。有人接,则沟通*/@Testpublic void applyToEither2() {CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(60l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + "挂断");return "60s内没人接";}).applyToEither(CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(4l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + "接通了");return "沟通";}),res -> res);System.out.println(Thread.currentThread().getName() + String.format("本次call"+"%s" , cf1.join()));}/*** 4、exceptionally:处理任务异常(可在任意任务后加,不一定非在最后加)* 如果某个异步任务出了(你认为可能出的相应)异常,则可以在异步执行代码中throw,然后,在最后exceptionally处理对应异步任务的对应异常*/@Testpublic void exceptionally(){CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(1l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + ":141来了");return "141";}).applyToEither(CompletableFuture.supplyAsync(() -> {try {TimeUnit.SECONDS.sleep(2l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + "青卢线来了");return "青卢线";}), res -> {System.out.println(Thread.currentThread().getName() + ":" +res);if (res.startsWith("141")) {throw new RuntimeException("141堵死了不动了");}return res;}).exceptionally(e -> {System.out.println(Thread.currentThread().getName()+ e.getMessage());System.out.println(Thread.currentThread().getName()+ "叫车");return "taxi";});System.out.println(Thread.currentThread().getName() + String.format("坐"+"%s" +"回家" , cf1.join()));}@Testpublic void tt2() throws ExecutionException, InterruptedException {CompletableFuture<Void> cf1 = CompletableFuture.runAsync(() -> {System.out.println(Thread.currentThread().getName() + ":141-start");try {TimeUnit.SECONDS.sleep(1l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + ":141-end");});CompletableFuture<Void> cf2 = CompletableFuture.runAsync(() -> {System.out.println(Thread.currentThread().getName() + ":23-start");try {TimeUnit.SECONDS.sleep(5l);} catch (InterruptedException exception) {exception.printStackTrace();}System.out.println(Thread.currentThread().getName() + ":23-end");});cf1.runAfterEither(cf2,() -> System.out.println("all end")).thenRun(() ->{cf1.cancel(false);cf2.cancel(false);}).get();}/**** 5、runAsync和supplyAsync类似,只不过runAsync没有返回值*//**** 6、thenCompose == thenApply == thenAccept(需要前一个异步任务的返回结果,但是thenAccept连接方法中,无返回值)*//**** 7、thenCompose == == thenAccept(需要前一个异步任务的返回结果,但是thenAccept连接方法中,无返回值)* == thenRun(不需要前一个异步任务的返回结果,thenRun连接方法中,也无返回值)*//**** 8、thenCombine == thenAcceptBoth (任务A和任务B,合并执行结果,但是合并结果方法thenAcceptBoth中无返回值)* == runAfterBoth(不需要任务A和任务B的合并返回结果,runAfterBoth合并方法中,也无返回值)*//**** 9、applyToEither == acceptEither (得到任务A和任务B,最先执行完的任务的结果,acceptEither中无返回值)* == runAfterEither(不关心任务A和任务B谁先执行完,runAfterEither也无返回值)*//**** 10、exceptionally == handle (如果任务正常则返回正常结果、如果任务异常则返回异常结果。后面程序都会正常执行,有返回值)* == whenComplete(类型handle,但无返回值)*//**** 11、join:等待异步任务完成* allOf:将List<CompletableFuture> 看成是一个CompletableFeture* allOf(list<CompletableFuture> 每个异步任务都装到这个异步任务list中).join*//**** 12、thenRun:等待异步任务完成,异步任务可能有返回值,也可能没有*/
}
4.3 get方法和join方法区别
4.3.1 相同点:
join()和get()方法都是用来获取CompletableFuture异步之后的返回值,都是waitingGet阻塞拿结果
4.3.2 区别:
- join()方法抛出的是uncheck异常(即未经检查的异常),不会强制开发者抛出,
public static void main(String[] args) { //2、这里不用throwsCompletableFuture<Integer> f1 = CompletableFuture.supplyAsync(() -> {int i =1/0;return 1;});CompletableFuture.allOf(f1).join(); //1、这里没有强制要求try-catch或者throwsSystem.out.println("CompletableFuture Test");}public static void main(String[] args) throws ExecutionException, InterruptedException {//2.要么这里throwsCompletableFuture<Integer> f1 = CompletableFuture.supplyAsync(() -> {int i =1/0;return 1;});f1.get();System.out.println("CompletableFuture Test");//1.要么这里try-catch}
4.4 实战
4.4.1 单个并发查询
【根据仓id查询仓名称。500个仓id,每次只能查询200个,并发查询】
List<PoiBasicTInfo> result = Lists.partition(poiIds, 200).stream().map(partPoiIds -> CompletableFuture.supplyAsync(() -> queryPoiInfoByPoiId(partPoiIds)//方法返回List<PoiBasicTInfo>, cQueryExecutor)).collect(Collectors.toList()).stream().map(CompletableFuture::join).flatMap(List::stream).collect(Collectors.toList());
4.4.2 两个参数都是集合,一起作为异步查询的入参,并发查询
skuIds:400个sku,200A、200B
pcIds:两个PC仓,id1,id2
skuId和pcId需要一起作为参数并发查询:即四种组合并发查询A1,A2,B1,B2
rpc查询结果返回List<ProcessPlanDto>List<ProcessPlanDto> result = Lists.partition(needFilterSkuIds, 200).stream().map(subNeedFilterSkuIds -> pcPoiIds.stream().map(pcId -> CompletableFuture.supplyAsync(() -> {try {return pcGateway.querySkuProcessPlan4Sku(pcId, subNeedFilterSkuIds, pickDate);} catch (Exception e) {log.error("STC列表,查询加工计划发生异常", e);}return new ArrayList<ProcessPlanDto>();}, pcAllocateSupplyTypeFilterExecutor)).collect(Collectors.toList())).flatMap(Collection::stream).collect(Collectors.toList()).stream().map(CompletableFuture::join).reduce((processPlanDtos, processPlanDtos2) -> {processPlanDtos.addAll(processPlanDtos2);return processPlanDtos;}).orElse(Lists.newArrayList());// 上面步骤解析Stream<List<CompletableFuture<List<ProcessPlanDto>>>> stream = Lists.partition(needFilterSkuIds, processPlanQueryThreshold).stream().map(needFilterSkus -> finalPcPoiIds.stream().map(pcId -> CompletableFuture.supplyAsync(() -> {try {return pcGateway.querySkuProcessPlan4Sku(pcId, needFilterSkus, pickDate);} catch (Exception e) {log.error("查询加工计划发生异常", e);}return new ArrayList<ProcessPlanDto>();}, pcAllocateSupplyTypeFilterExecutor)).collect(Collectors.toList()));Stream<CompletableFuture<List<ProcessPlanDto>>> stream1 = stream.flatMap(List::stream);Stream<List<ProcessPlanDto>> stream2 = stream1.map(CompletableFuture::join);List<ProcessPlanDto> res = stream2.flatMap(List::stream).collect(Collectors.toList());补充:这里,为了弱依赖pcGateway.querySkuProcessPlan4Sku,所以吃掉异步查询可能抛出来的异常
4.4.3 List paramlist + Map<Integer,List > map一起并发查询
1、数据结构:
-
paramlist为[仓1 + 400sku、仓2 + 400sku、-----]
-
map中key = 1,value = List serviceList1,serviceList1为sever1、sever2、key = 2,value = List serviceList2,serviceList为sever3
2、背景:map中所有key对应的所有service都要作用于paramlist,即key=1,对应的sever1 查询仓1 + 400sku 、sever1查询仓2 + 400sku、sever2查询仓1 + 400sku、sever2查询仓2 + 400sku
同时key=2,对应的sever3 查询仓1 + 400sku 、sever3查询仓2 + 400sku
3、目的:让他们全部并发查询
4、实现代码
map.forEach((key, serviceList) -> {paramlist.stream().map(param -> serviceList.stream().map(service -> CompletableFuture.runAsync(() -> service.doFunction(param), ownExecutor)).collect(Collectors.toList())).flatMap(Collection::stream).collect(Collectors.toList()).stream().map(CompletableFuture::join).collect(Collectors.toList());});
4.4.3 A和B任务二者之间并行查询 ,同时 A和B本身也要200批次、200批次的并行查询
任务A批量异步并行、任务B批量异步并行。A、B之间并行【A1和A2并行 (并行) B1和B2并行】
List<OverStockRiskTypeModel> totalList = Lists.newArrayList();CompletableFuture<Map<Long, LockStatusModel>> cf1 = Lists.partition(model.getSkuIdList(), 100).stream().map(skus -> buildQueryLockStockStatusParam(model.getNetPoiId(), skus, model.getPickDate())).map(lockStatusParam -> CompletableFuture.supplyAsync(() ->stmLockMaxStockGateway.getLockStatus(lockStatusParam), queryLockStatusAndOrExecutor))//方法返回<Map<Long, LockStatusModel>.collect(Collectors.toList()).stream().reduce((fn1, fn2) -> fn1.thenCombine(fn2, (m1, m2) -> {m1.putAll(m2);return m1;})).orElse(CompletableFuture.completedFuture(Maps.newHashMap()));CompletableFuture<Map<Long, Long>> cf2 = Lists.partition(model.getSkuIdList(),100).stream().map(skus -> buildQueryORParam(model.getPoiId(), skus, model.getPickDate())).map(inventoryPredictParam -> CompletableFuture.supplyAsync(() ->inventoryPredictGateway.getInventoryPredictOrQuantity(inventoryPredictParam), queryLockStatusAndOrExecutor))//方法返回Map<Long, Long>.collect(Collectors.toList()).stream().reduce((fn1, fn2) -> fn1.thenCombine(fn2, (m1, m2) -> {m1.putAll(m2);return m1;})).orElse(CompletableFuture.completedFuture(Maps.newHashMap()));allOf(cf1, cf2).thenAccept(v -> fillLockStatusAndOrQuantity(totalList, cf1.join(), cf2.join(), model.getNetPoiId())).join();
4.4.4 将List<CompletableFuture>转为CompletableFuture<List> cf1
场景:转换cf1,相同方式再转换cf2,想让cf1和cf2一起阻塞拿结果
1、封装方法
public static <T> CompletableFuture<List<T>> sequence2(List<CompletableFuture<T>> com, ExecutorService exec) {if(com.isEmpty()){throw new IllegalArgumentException();}Stream<? extends CompletableFuture<T>> stream = com.stream();CompletableFuture<List<T>> init = CompletableFuture.completedFuture(new ArrayList<T>());return stream.reduce(init, (ls, fut) -> ls.thenComposeAsync(x -> fut.thenApplyAsync(y -> {x.add(y);return x;},exec),exec), (a, b) -> a.thenCombineAsync(b,(ls1,ls2)-> {ls1.addAll(ls2);return ls1;},exec));
}
2、其他方式
//01.首先正常的使用CompletableFuture执行查询得到tempMap
List<CompletableFuture<Map<Long, Long>>> tempMap = Lists.partition(model.getSkuIdList(), LionUtil.batchQueryLockStatusSize()).stream().map(skus -> buildQueryLockStockStatusParam(model.getNetPoiId(), skus, model.getPickDate())).map(lockStatusParam -> CompletableFuture.supplyAsync(() ->stmLockMaxStockGateway.getLockStatus(lockStatusParam), queryLockStatusAndOrExecutor)).collect(Collectors.toList());//02.然后实现3.1.1的转换形式,形成cf1
CompletableFuture<Map<Long, LockStatusModel>> cf1 = tempMap.stream().reduce((fn1, fn2) -> fn1.thenCombineAsync(fn2, (m1, m2) -> {m1.putAll(m2);return m1;}, queryLockStatusAndOrExecutor)).orElse(CompletableFuture.completedFuture(Maps.newHashMap()));
//03.最后可以等待B的cf2一起执行join实现并发
fillLockStatusAndOrQuantity(totalList, cf1.join(), cf2.join());
4.4.5 将List<CompletableFuture<Map<Long, Long>>> 变为 CompletableFuture*<Map<Long, Long>>* cf1
1、封装方法
public static <T> CompletableFuture<List<T>> sequence2(List<CompletableFuture<T>> com, ExecutorService exec) {if(com.isEmpty()){throw new IllegalArgumentException();}Stream<? extends CompletableFuture<T>> stream = com.stream();CompletableFuture<List<T>> init = CompletableFuture.completedFuture(new ArrayList<T>());return stream.reduce(init, (ls, fut) -> ls.thenComposeAsync(x -> fut.thenApplyAsync(y -> {x.add(y);return x;},exec),exec), (a, b) -> a.thenCombineAsync(b,(ls1,ls2)-> {ls1.addAll(ls2);return ls1;},exec));
}
2、其他方式
//01.首先正常的使用CompletableFuture执行查询得到tempMap
List<CompletableFuture<Map<Long, Long>>> tempMap = Lists.partition(model.getSkuIdList(), LionUtil.batchQueryLockStatusSize()).stream().map(skus -> buildQueryLockStockStatusParam(model.getNetPoiId(), skus, model.getPickDate())).map(lockStatusParam -> CompletableFuture.supplyAsync(() ->stmLockMaxStockGateway.getLockStatus(lockStatusParam), queryLockStatusAndOrExecutor)).collect(Collectors.toList());//02.然后实现3.1.1的转换形式,形成cf1
CompletableFuture<Map<Long, LockStatusModel>> cf1 = tempMap.stream().reduce((fn1, fn2) -> fn1.thenCombineAsync(fn2, (m1, m2) -> {m1.putAll(m2);return m1;}, queryLockStatusAndOrExecutor)).orElse(CompletableFuture.completedFuture(Maps.newHashMap()));
//03.最后可以等待B的cf2一起执行join实现并发
fillLockStatusAndOrQuantity(totalList, cf1.join(), cf2.join());
4.4.6 并发处理map的k-v,而非map.forEach((k,v) 串行处理
Map<String, List<User>> map = new HashMap<>();User u1 = new User();u1.setAge(1);User u2 = new User();u2.setAge(2);map.put("mjp", Lists.newArrayList(u1, u2));User u3 = new User();u3.setAge(3);User u4 = new User();u4.setAge(4);map.put("wxx",Lists.newArrayList(u3, u4));List<CompletableFuture<List<Integer>>> list = map.entrySet().stream().map(entry -> CompletableFuture.supplyAsync(() ->func((entry)))).collect(Collectors.toList());CompletableFuture<List<Integer>> cf = list.stream().reduce((fn1, fn2) -> fn1.thenCombine(fn2,(integers, integers2) -> Stream.of(integers, integers2).flatMap(Collection::stream).collect(Collectors.toList()))).orElse(CompletableFuture.completedFuture(Collections.emptyList()));List<Integer> res = cf.join();}private List<Integer> func(Entry<String, List<User>> entry) {System.out.println(entry);return Lists.newArrayList(1);}
4.4.7 limit、offset并发查询
常规的并发查询,都是sku集合400个,200、200分批的查
这种场景是,limit、offset并发的查
// 查询档期商品Long limit = 200L;long threshold = 50000L;PageRequest pageRequest = request.getPageRequest();pageRequest.setLimit(limit);pageRequest.setOffset(0L);// 1.先rpc,0-200查询一次,看看总共的totalQuerySkuScheduleListResponse response = skuScheduleQueryGateway.querySkuScheduleList(request);Long total = response.getTotal();if (total <= limit) {return response.getSkuScheduleDTOList();}if (total >= threshold) {total = threshold;}// 2.total很多,则for循环,异步并发查询List<CompletableFuture<List<SkuScheduleDTO>>> scheduleCfList = Lists.newArrayList();for (long offset = limit; offset < total; offset += limit) {QuerySkuScheduleListRequest listRequest = copy(request);PageRequest pageRequest1 = listRequest.getPageRequest();pageRequest1.setLimit(limit);pageRequest1.setOffset(offset);// 3.虽然是for循环串行着查询,但是会异步去查询,不会耗时,直接进入下一个循环条件CompletableFuture<List<SkuScheduleDTO>> scheduleCf = CompletableFuture.supplyAsync(() -> {try {return skuScheduleQueryGateway.querySkuScheduleList(listRequest).getSkuScheduleDTOList();} catch (GatewayException e) {log.error("查询档期商品接口发生异常", e);}return new ArrayList<>();}, queryScheduleSkuExecutor);// 4.直接将异步任务添加进来,不需要再for循环中等待一个一个的串行查询scheduleCfList.add(scheduleCf);}// 5.在for循环外侧,一把拿到多有的并发查询结果List<SkuScheduleDTO> skuScheduleDtoList = scheduleCfList.stream().map(CompletableFuture::join).flatMap(Collection::stream).collect(Collectors.toList());
4.4.8 协同、转运、pc打标,并发mark,结果一起join
打标是并发执行,最终join可以串行执行
noDependencyQueryPredictUniteServiceList.stream().map(queryInventoryUniteBizService -> CompletableFuture.runAsync(() -> queryInventoryUniteBizService.mark(skuStockUpTypeMarkParam), supplyTypeFilterExecutor)).collect(Collectors.toList()).stream().map(CompletableFuture::join).collect(Collectors.toList());
4.4.9 其他
1、rpc结果是List,将其转换为List<CompletableFuture<Map<Long, Long>>> tempMap再转换为CompletableFuture*<Map<Long, Long>>* cf1
List<CompletableFuture<Map<Long, Long>>> futureList = Lists.partition(supplierSkuReservationReqDtos, 200).stream().map(//构造查询参数).map(req -> CompletableFuture.supplyAsync(() -> {Map<Long, Long> map = null;try {List<X> tempList = rpc(req);//rpc查询// 这里将rpc查询结果List<X>转换为Map<k,v>map = tempList.stream().collect(Collectors.toMap(X::getKey,X::getValue));} catch (Exception e) {log.error("StockService,查询直送算法发生异常", e);}if (MapUtils.isEmpty(map)) {map = Maps.newHashMap();}return map;}, getReservationIntransitQtyExecutor)).collect(Collectors.toList());Map<Long, Long> result = futureList.stream().map(CompletableFuture::join).reduce((map1, map2) -> {map1.putAll(map2);return map1;}).orElse(Maps.newHashMap());
2、创建CompletableFuture,不做任何处理,直接返回空结果,或者返回new的集合、map
CompletableFuture<Map<x, x>> signedWaitingInbound; = CompletableFuture.completedFuture(Maps.newHashMap());
3、直接结束CompletableFuture的异步查询方法:complete()
// 操作1,List<> skuScheduleDtoList
// 操作2
CompletableFuture< PoiRelationDTO> cf = 异步方法();// 当操作1的结果集合为空,则人为的结束异常方法
if (CollectionUtils.isEmpty(skuScheduleDtoList)) {resp.setCode(0);resp.setErrMsg("未查询到符合条件的档期商品");cf.complete(null);return resp;
}1、人为的结束异步方法是:cf.complete("Future's Result")
2、所有等待这个CompletableFuture 的客户端都将得到一个指定的结果,并且 completableFuture.complete() 之后的调用将被忽略。
4.5 Java9 CompletableFuture新特性
4.5.1 新增了orTimeOut方法
如果在指定时间内未执行完毕,就会抛出一个timeoutException
/*** 2、thenCombine:合并* A异步执行,同时B异步执行,A、B异步执行结束,将结果返回给main* A厨师炒菜,同时 B服务员蒸饭,AB结束,main吃饭*/@Testpublic void t() {System.out.println(Thread.currentThread().getName() + ":进入餐厅");System.out.println(Thread.currentThread().getName() + ":点了番茄炒蛋和米饭");CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":炒番茄鸡蛋");return "炒番茄鸡蛋";}).thenCombine(CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":服务员做饭");return "蒸米饭";}), (dish, rich) -> {System.out.println(Thread.currentThread().getName() + ":菜饭都好了");return String.format("%s" + "%s", dish, rich);}).orTimeout(3, TimeUnit.SECONDS);System.out.println(Thread.currentThread().getName() + ":王者荣耀");System.out.println(Thread.currentThread().getName() + String.format("%s", "开吃" + cf1.join()));}
4.5.2 执行超时的时候,赋默认结果completeOnTimeOut
/*** 2、thenCombine:合并* A异步执行,同时B异步执行,A、B异步执行结束,将结果返回给main* A厨师炒菜,同时 B服务员蒸饭,AB结束,main吃饭*/// 这里,如果A任务炒菜(炒番茄鸡蛋)超时了还未完成,则可以给A兜底(咸菜)@Testpublic void t() {System.out.println(Thread.currentThread().getName() + ":进入餐厅");System.out.println(Thread.currentThread().getName() + ":点了番茄炒蛋和米饭");CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":炒番茄鸡蛋");return "炒番茄鸡蛋";}).completeOnTimeOut("咸菜", 1, TimeUnit.SECONDS) // 这里要是任务A,1s还未完成,则直接返回"咸菜.thenCombine(CompletableFuture.supplyAsync(() -> {System.out.println(Thread.currentThread().getName() + ":服务员做饭");return "蒸米饭";}), (dish, rich) -> {System.out.println(Thread.currentThread().getName() + ":菜饭都好了");return String.format("%s" + "%s", dish, rich);}).orTimeout(3, TimeUnit.SECONDS);System.out.println(Thread.currentThread().getName() + ":王者荣耀");System.out.println(Thread.currentThread().getName() + String.format("%s", "开吃" + cf1.join()));}
五、工具类(非Java8):
5.1 集合运算
https://www.cxyzjd.com/article/liwgdx80204/91041273
https://blog.csdn.net/qq_46239275/article/details/121849257
判断两个集合是否有交集
List<Long> l1 = Lists.newArrayList(1L,2L,3L,4L,5L);List<Long> l2 = Lists.newArrayList(7L,6L,5L);System.out.println(CollectionUtils.retainAll(l1, l2).size());//size为0,就是没交集
5.2 集合深copy
深copy
5.3 线程安全的list:
Collections.synchronizedList使用方法
https://www.cnblogs.com/luojiabao/p/11308803.html
5.4 list <==> Array
int[] intArray = new int[]{1,2,3};List<Integer> list = Arrays.stream(intArray).boxed().collect(Collectors.toList());List<String> list = Lists.newArrayList("a", "b");String[] array = list.toArray(new String[0]); //RIGHT
参考:
1、https://www.bilibili.com/video/BV1Dv411A7BJ/?spm_id_from=333.337.search-card.all.click&vd_source=dba2a51a761b4fec8564e12aedf67f10
2、https://www.bilibili.com/video/BV1k64y1R7sA?p=7&vd_source=dba2a51a761b4fec8564e12aedf67f10
相关文章:

《Java8实战》
《Java实战》学习整理 文章目录 一、Lambda1.1 基础概念1.1.1 [Lambda表达式](https://baike.baidu.com/item/Lambda表达式/4585794?fromModulelemma_inlink)定义 1.2 引入Lambda1.3 Lambda1.3.1 函数式接口1.3.2 Lambda表达式:(参数) -> 表达式1.3.3 在哪里使…...
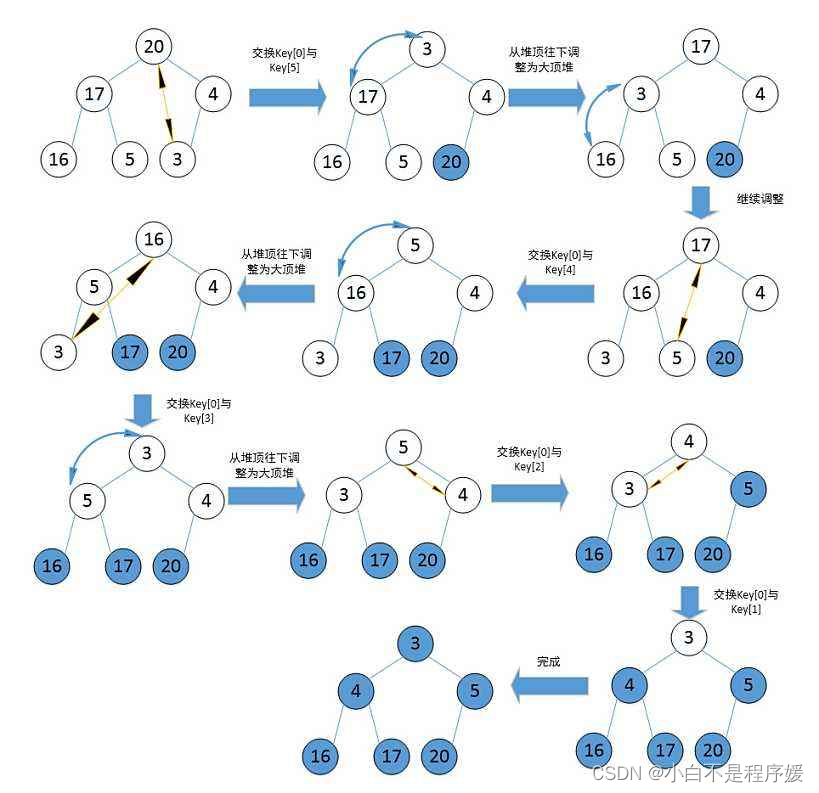
【初阶数据结构】——堆排序和TopK问题
个人主页 代码仓库 C语言专栏 初阶数据结构专栏 Linux专栏 接上篇二叉树和堆的引入 目录 前言 建堆 插入数据向上调整算法建堆 移动数据向上调整算法建堆 无序数组从H-1层向上移动的向下调整算法建堆 堆排序 TOP-K问题 前言 上篇文章详细讲解了堆,…...
LLM - 大模型速递 InternLM-20B 快速入门
目录 一.引言 二.模型简介 1.模型特性 2.模型评测 三.模型尝试 1.模型参数 2.generate 与 chat 3.模型微调 四.总结 一.引言 一早醒来国产开源大模型又添一员猛将,书生-浦语大模型 InternLM-20B 大模型发布并开源,这里字面翻译是实习生大模型&…...
探索AIGC人工智能(Midjourney篇)(四)
文章目录 Midjourney模特换装 Midjourney制作APP图标 Midjourney网页设计 Midjourney如何生成IP盲盒 Midjourney设计儿童节海报 Midjourney制作商用矢量插画 Midjourney设计徽章 Midjourney图片融合 Midjourney后缀参数 Midjourney模特换装 关键词生成模特照片 中国女性模特的…...

uni-app:跨页面传递数组
A页面: JSON.stringify() 是一个 JavaScript 内置的方法,用于将 JavaScript 对象或值转换为 JSON 字符串。 //查看详细信息 details(e){// console.log(e.currentTarget.dataset.id)var device JSON.stringify(e.currentTarget.dataset.id)uni.naviga…...

element 表格拖拽保存插件
这是以前看着一篇文章 1.下载包 npm install sortablejs --save 2.在页面中引入,或者全局引入 import Sortable from ‘sortablejs’ 3.在template中 <div id"second"><el-tableclass"threeTable":style"{height:tableData.len…...
通过内网穿透,在Windows 10系统下搭建个人《我的世界》服务器公网联机
文章目录 1. Java环境搭建2.安装我的世界Minecraft服务3. 启动我的世界服务4.局域网测试连接我的世界服务器5. 安装cpolar内网穿透6. 创建隧道映射内网端口7. 测试公网远程联机8. 配置固定TCP端口地址8.1 保留一个固定tcp地址8.2 配置固定tcp地址 9. 使用固定公网地址远程联机 …...
)
C++11异步任务轮子实现(header-only)
为什么写这个 C17异步任务需要future和promise配合使用,不是很喜欢那种语法。实现一个操作简洁的异步任务。 满足功能 异步任务超时控制get接口同步任务计时lambda回调任务重启 使用 #include "async_callback.h" #include <unistd.h> #includ…...

2023华为杯研究生数学建模竞赛选题建议+初步分析
如下为C君的2023华为杯研究生数学建模竞赛(研赛)选题建议初步分析 2023华为杯研究生数学建模竞赛(研赛)选题建议 提示:DS C君认为的难度:CE<D<F,开放度:CDE<F。 华为专项…...

多线程并发或线程安全问题如何解决
1、通过volatile关键字修饰变量,可以实现线程之间的可见性,避免变量脏读的出现,底层是通过限制jvm指令的重新排序实现的,适用于一个线程修改,多个线程读的场景。 2、通过synchronized锁(任意对象࿰…...
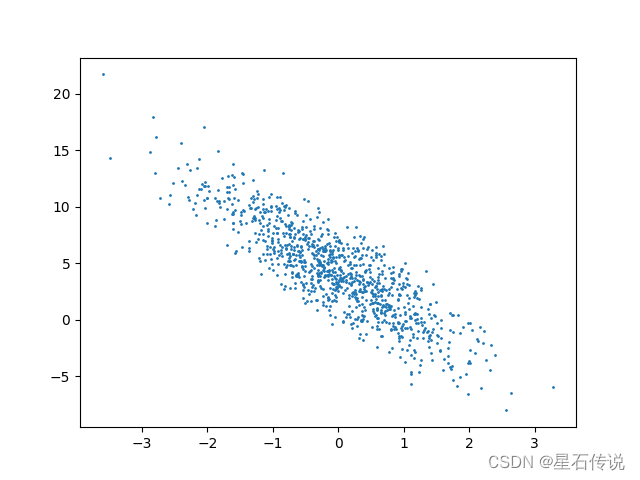
深度学习——线性神经网络一
深度学习——线性神经网络一 文章目录 前言一、线性回归1.1. 线性回归的基本元素1.1.1. 线性模型1.1.2. 损失函数1.1.3. 解析解1.1.4. 随机梯度下降1.1.5. 用模型进行预测 1.2. 向量化加速1.3. 正态分布与平方损失1.4. 从线性回归到深度网络 二、线性回归的从零开始实现2.1. 生…...
利用大模型知识图谱技术,告别繁重文案,实现非结构化数据高效管理
我,作为一名产品经理,对文案工作可以说是又爱又恨,爱的是文档作为嘴替,可以事事展开揉碎讲清道明;恨的是只有一个脑子一双手,想一边澄清需求一边推广宣传一边发布版本一边申报认证实在是分身乏术࿰…...

Java抽象类和普通类区别、 数组跟List的区别
抽象类 Java中的抽象类是一种特殊的类,它不能被实例化,只能被继承。抽象类通常用于定义一些通用的属性和方法,但是这些方法的具体实现需要在子类中完成。抽象类中可以包含抽象方法和非抽象方法。 抽象方法是一种没有实现的方法,…...

Leetcode.2522 将字符串分割成值不超过 K 的子字符串
题目链接 Leetcode.2522 将字符串分割成值不超过 K 的子字符串 rating : 1605 题目描述 给你一个字符串 s s s ,它每一位都是 1 1 1 到 9 9 9 之间的数字组成,同时给你一个整数 k k k 。 如果一个字符串 s s s 的分割满足以下条件,我们…...
)
成绩分析(蓝桥杯)
成绩分析 题目描述 小蓝给学生们组织了一场考试,卷面总分为 100 分,每个学生的得分都是一个 0 到 100 的整数。 请计算这次考试的最高分、最低分和平均分。 输入描述 输入的第一行包含一个整数 n (1≤n≤104 ),表示考试人数。 接下来 n 行…...
【多思路附源码持续更新】2023年华为杯(中国研究生数学建模)竞赛C题
赛题 若官网拥挤,数据集和赛题下载地址如下: https://download.csdn.net/download/weixin_47723732/88364777 历届优秀论文下载地址,可以做参考文章 https://download.csdn.net/download/weixin_47723732/88365222 论文万能模板下载地址 htt…...
)
基于STM32设计的校园一卡通(设计配套的手机APP)
一、功能介绍 【1】项目介绍 随着信息技术的不断发展,校园一卡通作为一种高效便捷的管理方式,已经得到了广泛的应用。而其核心部件——智能卡也被越来越多的使用者所熟知。 本文介绍的项目是基于STM32设计的校园一卡通消费系统,通过RC522模块实现对IC卡的读写操作,利用2…...
有了Spring为什么还需要SpringBoot呢
目录 一、Spring缺点分析 二、什么是Spring Boot 三、Spring Boot的核心功能 3.1 起步依赖 3.2 自动装配 一、Spring缺点分析 1. 配置文件和依赖太多了!!! spring是一个非常优秀的轻量级框架,以IOC(控制反转&…...

【记录】Python 之于 C/C++ 区别
记录本人在 Python 上经常写错的一些地方(C/C 写多了,再写 Python 有点切换不过来) 逻辑判断符号用 and、or、!可以直接 10 < num < 30 比较大小分支语句:if、elif、else使用 、-,Python 中不支持 、- - 这两个…...

【Vue-Element-Admin】dialog关闭回调事件
背景 点击导入按钮,调出导入弹窗,解析excel数据后,不点击【确认并导入】按钮,直接关闭弹窗,数据违背清理 实现 使用dialog的close回调函数,在el-dialog添加close,在methods中定义closeDialog…...

如何用dashdot打造高颜值服务器监控面板?完整配置教程
如何用dashdot打造高颜值服务器监控面板?完整配置教程 【免费下载链接】dashdot A simple, modern server dashboard, primarily used by smaller private servers 项目地址: https://gitcode.com/gh_mirrors/da/dashdot dashdot是一款现代化的服务器监控面板…...

高效处理海量数据——pandas分块读取与内存管理实战
1. 为什么需要分块读取千万级数据? 第一次处理千万级CSV文件时,我盯着16GB的硬盘文件发愁——128GB内存的服务器居然加载到一半就崩溃了。这种场景在金融交易记录、物联网传感器数据、用户行为日志分析中太常见了。pandas默认的read_csv()会一次性把数据…...

Blender 3MF插件全攻略:提升3D打印工作流效率的关键技术
Blender 3MF插件全攻略:提升3D打印工作流效率的关键技术 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 3MF格式作为3D打印领域的核心交换标准,正…...

通义千问1.8B-Chat快速上手:vLLM部署+Chainlit界面实战体验
通义千问1.8B-Chat快速上手:vLLM部署Chainlit界面实战体验 1. 开篇:为什么选择这个组合? 如果你正在寻找一个轻量级但性能不俗的中文对话模型,通义千问1.8B-Chat绝对值得一试。这个1.8B参数的模型在保持较小体积的同时ÿ…...

实测分享:用Miniconda-Python3.10镜像快速创建独立开发环境
实测分享:用Miniconda-Python3.10镜像快速创建独立开发环境 1. 为什么需要独立Python环境 在日常开发中,我们经常会遇到这样的困扰:不同项目依赖的Python包版本冲突,导致项目无法正常运行。比如项目A需要TensorFlow 2.4…...

OFA模型处理C语言文件读写操作生成的流程图描述
OFA模型处理C语言文件读写操作生成的流程图描述 最近在整理编程教学资料时,我遇到了一个挺有意思的需求:手头有一堆描述C语言文件读写操作的流程图,需要为每一张图配上清晰、准确的文字说明。这活儿听起来简单,做起来却挺费神&am…...

网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址
网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用…...

MAD与标准差:鲁棒统计中的抗噪利器
1. 为什么我们需要抗噪统计量? 在日常数据分析中,我们经常会遇到一些"不听话"的数据点。比如分析员工薪资时突然冒出几个高管的天价年薪,或者测量温度时混入几个明显错误的极端值。这时候如果直接用传统的标准差来计算离散程度&…...

Unity 2022 LTS 实战:用NavMesh Agent和OffMesh Link,5分钟搞定一个会‘跳’会‘绕’的智能敌人AI
Unity 2022 LTS 实战:用NavMesh Agent和OffMesh Link打造智能敌人AI 在3D动作游戏中,一个只会直线追击的敌人往往会让玩家感到乏味。想象一下,当玩家精心设计的陷阱被敌人轻松绕过,或是敌人突然从高处跳下发动突袭时,游…...

ADS差分传输线前仿真:从S参数模板到信号完整性快速评估
1. 差分传输线前仿真入门:为什么需要S参数模板? 刚入行那会儿,我最头疼的就是每次新项目都要从头搭建仿真环境。直到发现ADS里藏着现成的4端口S参数模板,工作效率直接翻倍。这就像做菜时有了预制高汤,不用再从熬骨头汤…...