知识图谱实战导论:从什么是KG到LLM与KG/DB的结合实战
前言
本文侧重讲解:
- 什么是知识图谱
- LLM与langchain/数据库/知识图谱的结合应用
比如,虽说基于知识图谱的问答 早在2019年之前就有很多研究了,但谁会想到今年KBQA因为LLM如此突飞猛进呢
第一部分 知识图谱入门导论
//待更..
第二部分 LLM与知识图谱的结合
2.1 LLM为何要与知识图谱相结合
通过本文之前或本博客内之前的内容可知,由于大部分LLM都是基于过去互联网旧的预训练语料训练、推理而来,由此会引发两大问题
- 无法获取最新的知识,为解决这个问题,ChatGPT plus版一开始是通过引入bing搜索这个插件去获取最新知识(不过 现因商业问题而暂时下架),而ChatGPT的竞品Claude则通过更新其预训练的数据 比如2013年的数据
- 面对少部分专业性比较强的问题,没法更好的回答,有时推理时会犯一些事实性的知识错误
面对第二个问题,我们在上文已经展示了可以通过与langchain结合搭建本地知识库的办法解决,此外,还可以考虑让LLM与知识图谱结合
- 知识图谱能以三元组(即头实体、关系、尾实体)的形式存储结构化知识,因此知识图谱是一种结构化和决断性的知识表征形式,例子包括 Wikidata、YAGO 和 NELL
- 知识图谱能提供准确、明确的知识,且还具有很棒的符号推理能力,这能生成可解释的结果
- 知识图谱还能随着新知识的持续输入而积极演进。当然 知识图谱本身也有其不足,比如泛化能力不足
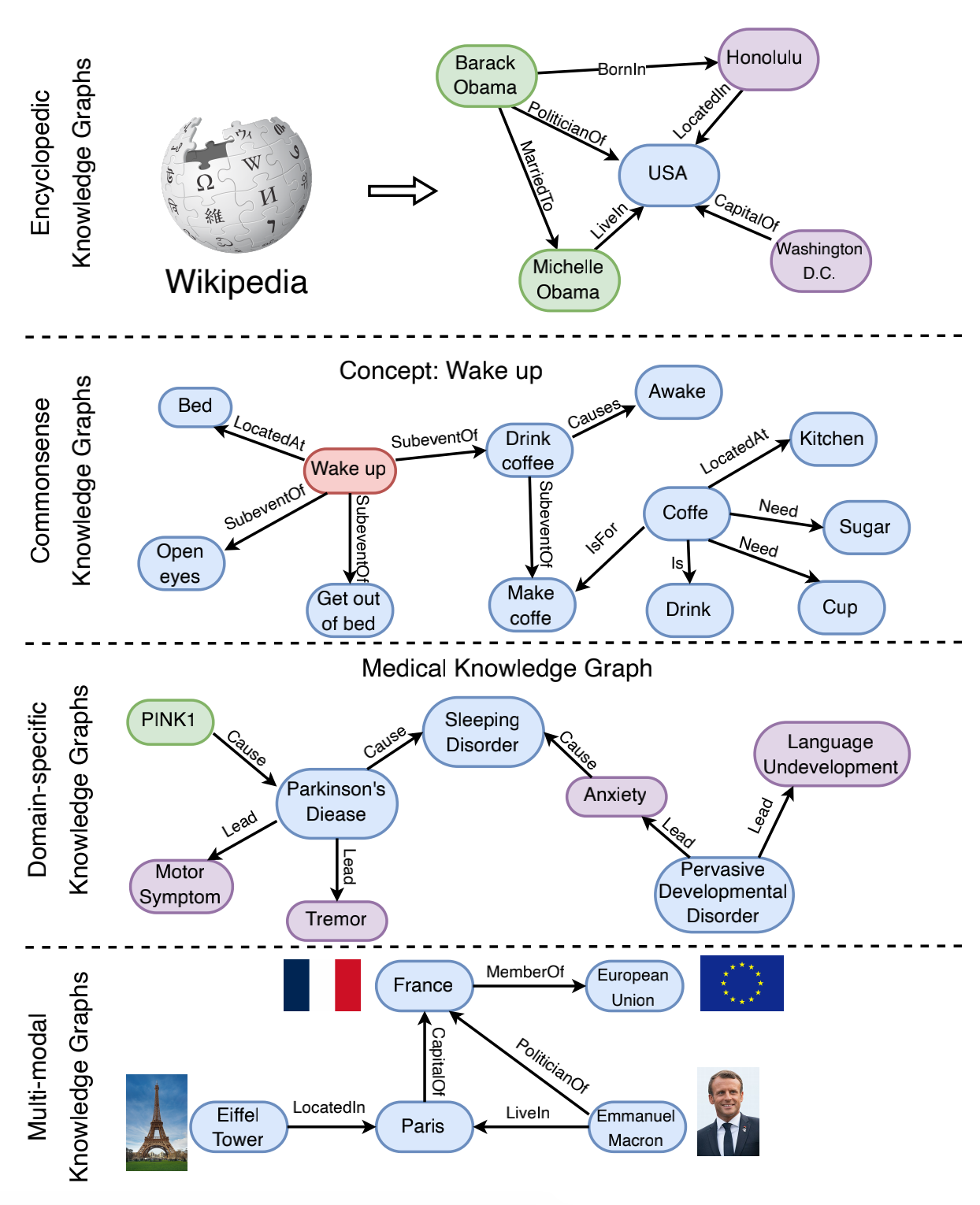
根据所存储信息的不同,现有的知识图谱可分为四大类:百科知识型知识图谱、常识型知识图谱、特定领域型知识图谱、多模态知识图谱
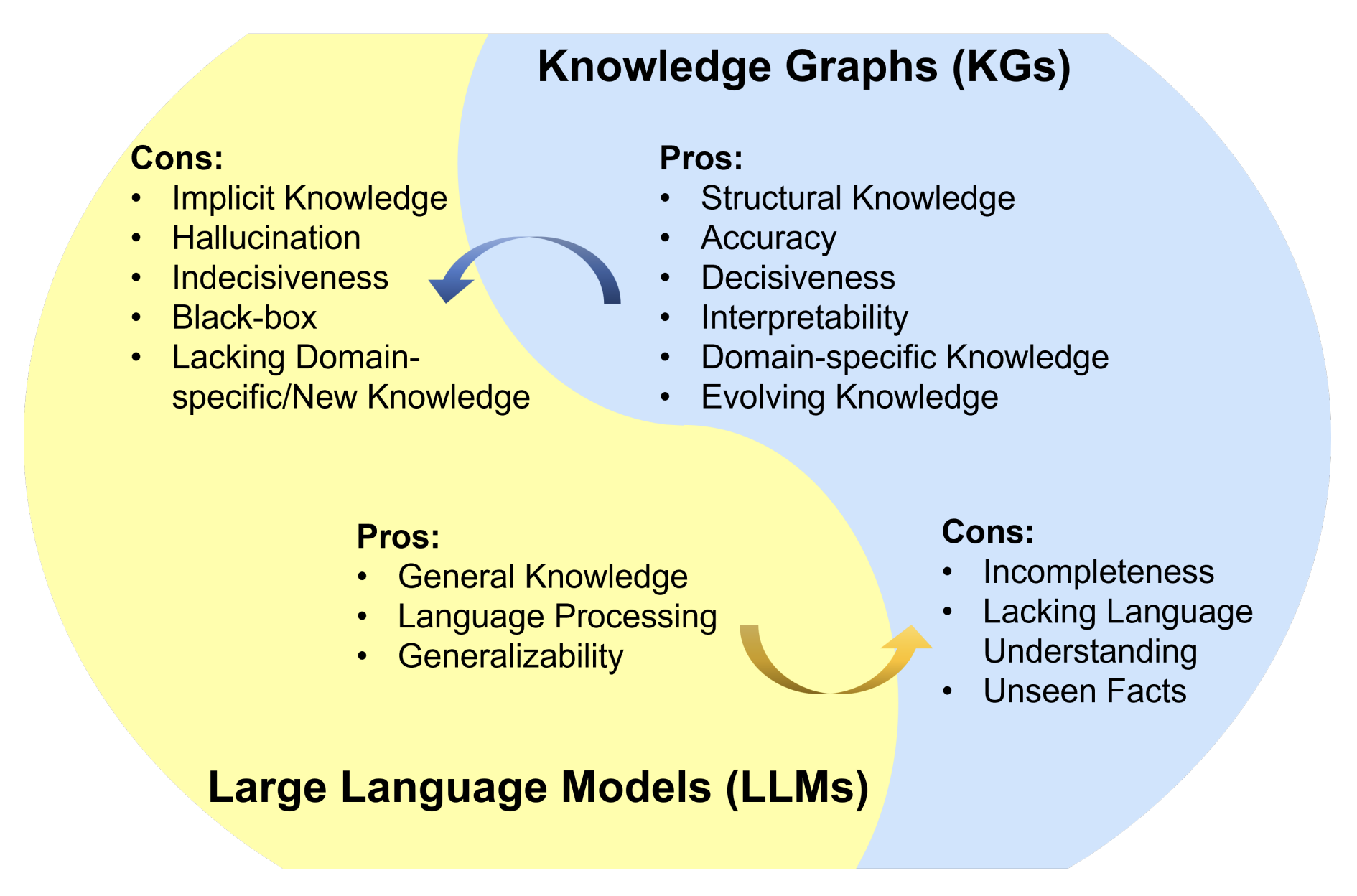
而下图总结了 LLM 和知识图谱各自的优缺点
而实际上,LLM与知识图谱可以互相促进、增强彼此
- 如果用知识图谱增强 LLM,那么知识图谱不仅能被集成到 LLM 的预训练和推理阶段,从而用来提供外部知识,还能被用来分析 LLM 以提供可解释性
- 而在用 LLM 来增强知识图谱方面,LLM 已被用于多种与知识图谱相关的应用,比如知识图谱嵌入、知识图谱补全、知识图谱构建、知识图谱到文本的生成、知识图谱问答。LLM 能够提升知识图谱的性能并助益其应用
总之,在 LLM 与知识图谱协同的相关研究中,研究者将 LLM 和知识图谱的优点融合,让它们在知识表征和推理方面的能力得以互相促进
2.2 用知识图谱增强 LLM的预训练、推理、可解释性
今年6月份,一篇论文《Unifying Large Language Models and Knowledge Graphs: A Roadmap》指出,用知识图谱增强 LLM具体的方式有几种
- 一是使用知识图谱增强 LLM 预训练,其目的是在预训练阶段将知识注入到 LLM 中
- 二是使用知识图谱增强 LLM 推理,这能让 LLM 在生成句子时考虑到最新知识
- 三是使用知识图谱增强 LLM 可解释性,从而让我们更好地理解 LLM 的行为
下表总结了用知识图谱增强 LLM 的典型方法

2.2.1 使用知识图谱增强 LLM 预训练
现有的 LLM 主要依靠在大规模语料库上执行自监督训练。尽管这些模型在下游任务上表现卓越,它们却缺少与现实世界相关的实际知识。在将知识图谱整合进 LLM 方面,之前的研究可以分为三类:
- 将知识图谱整合进训练目标
如下图所示,通过文本 - 知识对齐损失将知识图谱信息注入到 LLM 的训练目标中,其中 h 表示 LLM 生成的隐含表征
- 将知识图谱整合进 LLM 的输入
如下图所示,使用图结构将知识图谱信息注入到 LLM 的输入中
- 将知识图谱整合进附加的融合模块
如下图所示,即通过附加的融合模块将知识图谱整合到 LLM 中
2.2.2 用知识图谱增强 LLM 推理
上文的方法可以有效地将知识与LLM中的文本表示进行融合。但是,真实世界的知识会变化,这些方法的局限是它们不允许更新已整合的知识,除非对模型重新训练。因此在推理时,它们可能无法很好地泛化用于未见过的知识(比如ChatGPT的预训练数据便截止到的2021年9月份,为解决这个知识更新的问题,它曾借助接入外部插件bing搜索去解决)
所以,相当多的研究致力于保持知识空间和文本空间的分离,并在推理时注入知识。这些方法主要关注的是问答QA任务,因为问答既需要模型捕获文本语义,还需要捕获最新的现实世界知识,比如
- 融合动态知识图谱用于LLM推理
具体而言,一种直接的方法是利用双塔架构,其中一个分离的模块处理文本输入,另一个处理相关的知识图谱输入。然而,这种方法缺乏文本和知识之间的交互
因此,KagNet建议首先对输入的KG进行编码,然后增强输入的文本表示。相比之下,MHGRN使用输入文本的最终LLM输出来指导推理
再比如,JointLK提出了一个框架,通过LM-to-KG和KG-to- lm双向注意机制,在文本输入中的任何tokens和任何KG实体之间进行细粒度交互(JointLK then proposes a framework with fine-grainedinteraction between any tokens in the textual inputs and anyKG entities through LM-to-KG and KG-to-LM bi-directionalattention mechanism)
如下图所示,在所有文本标记和KG实体上计算成对点积分数,分别计算双向注意分数(pairwise dot-product scores are calculated over all textual tokens and KGentities, the bi-directional attentive scores are computed sep-arately)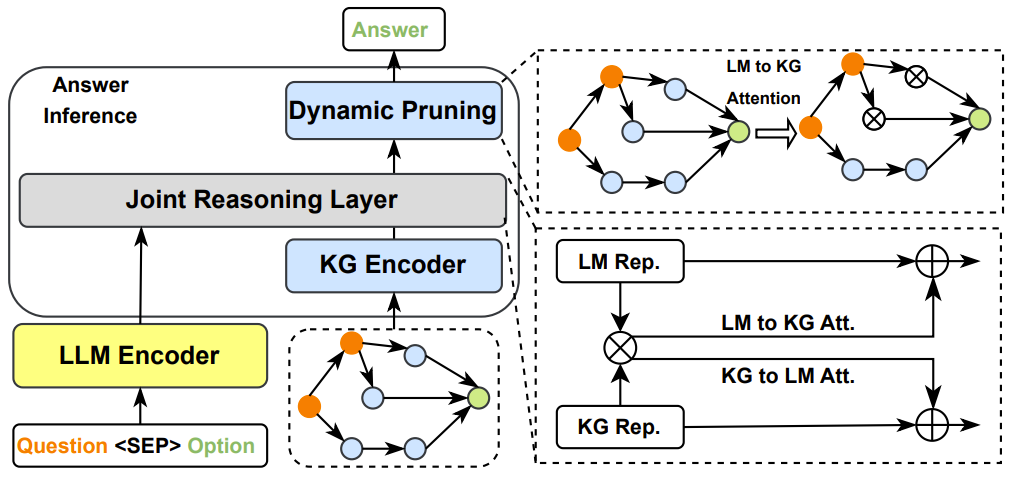
- 通过检索外部知识来增强 LLM 生成
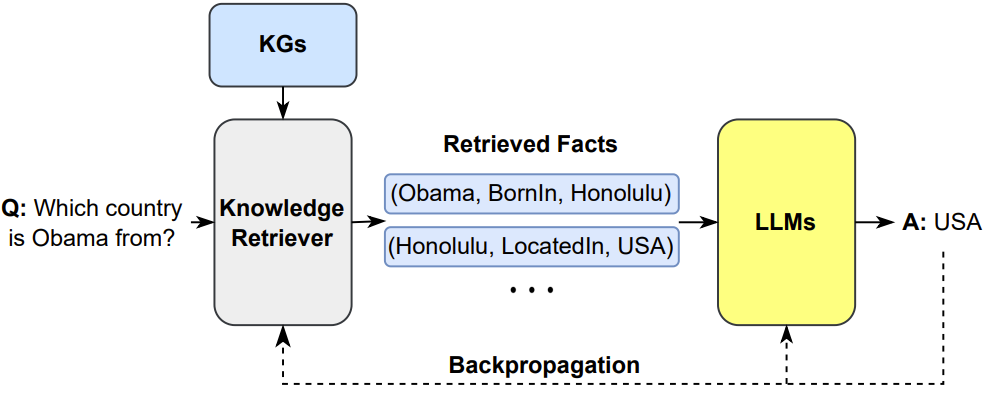
更多细节在我司的langchain实战课程上见
2.2.3 用知识图谱增强 LLM 可解释性
// 待更..
2.3 用LLM增强知识图谱
// 待更..
2.4 LLM与知识图谱的协同
// 待更..
2.5 LLM结合KG的项目实战:知识抽取KnowLM
KnowLM是一个结合LLM能力的知识抽取项目,其基于llama 13b利用自己的数据+公开数据对模型做了pretrain,然后在pretrain model之上用指令语料做了lora微调,最终可以达到的效果如下图所示 (图源),当面对同一个输入input时,在分别给定4种不同指令任务instruction时,KnowLM可以分别得到对应的输出output

下图展示了训练的整个流程和数据集构造。整个训练过程分为两个阶段:
- 全量预训练阶段,该阶段的目的是增强模型的中文能力和知识储备
- 使用LoRA的指令微调阶段,该阶段让模型能够理解人类的指令并输出合适的内容
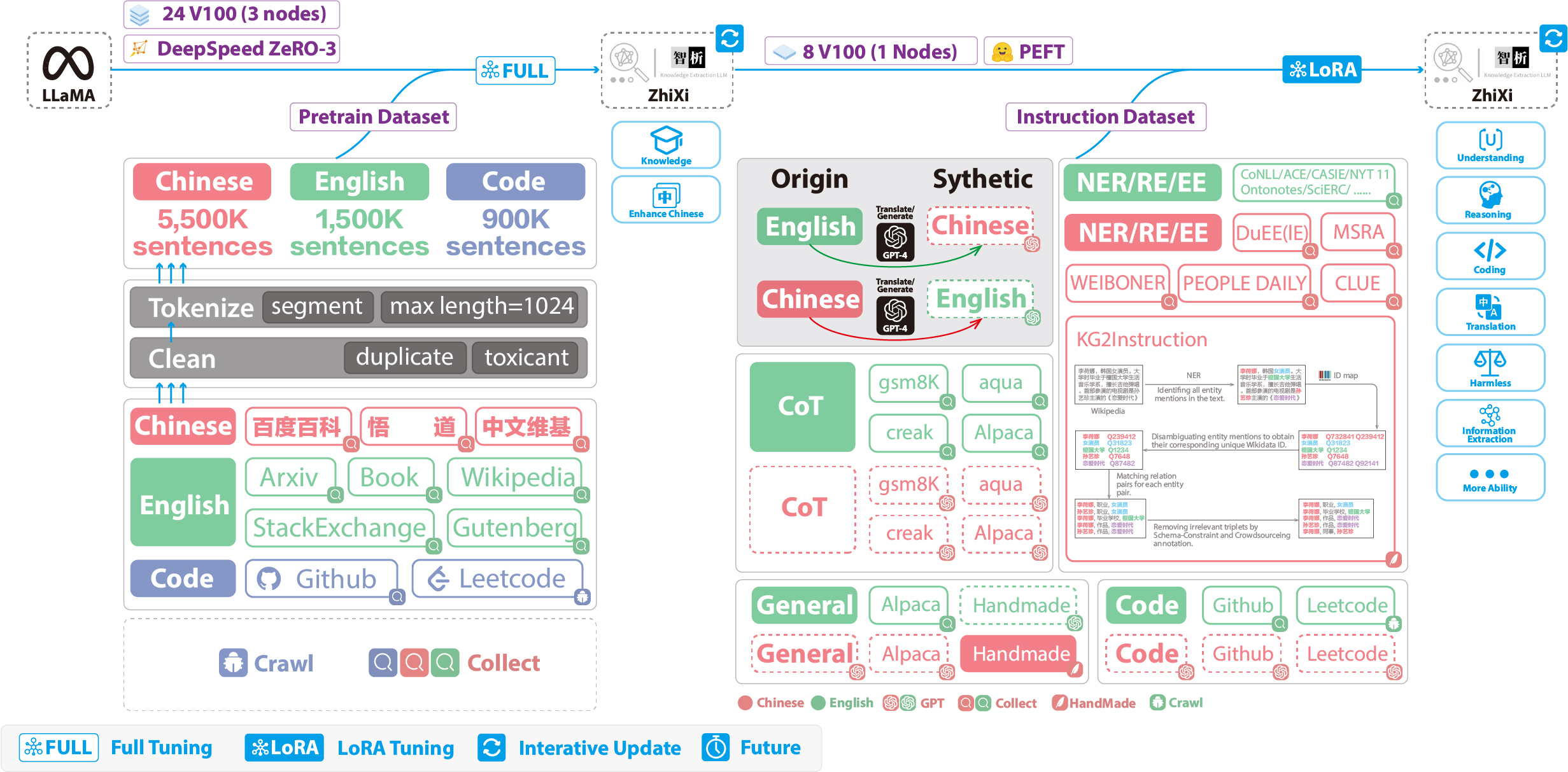
2.5.1 预训练数据集构建与训练过程
- 为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,他们并没有对词表进行扩增,而是搜集了中文语料、英文语料和代码语料,其中
中文语料来自于百度百科、悟道和中文维基百科
Pile数据集中的代码质量不高,他们去爬取了Github、Leetcode的代码数据,一部分用于预训练,另外一部分用于指令微调
对上面爬取到的数据集,他们使用了启发式的方法,剔除了数据集中有害的内容,此外,我们还剔除了重复的数据 - 详细的数据处理代码和训练代码、完整的训练脚本、详细的训练情况可以在./pretrain找到
在训练之前,首先需要对数据进行分词。他们设置的单个样本的最大长度是1024,而大多数的文档的长度都远远大于这个长度,因此需要对这些文档进行划分。设计了一个贪心算法来对文档进行切分,贪心的目标是在保证每个样本都是完整的句子、分割的段数尽可能少的前提下,尽可能保证每个样本的长度尽可能长
此外,由于数据源的多样性,设计了一套完整的数据预处理工具,可以对各个数据源进行处理然后合并
最后,由于数据量很大,如果直接将数据加载到内存,会导致硬件压力过大,于是他们参考了DeepSpeed-Megatron,使用mmap的方法对数据进行处理和加载,即将索引读入内存,需要的时候根据索引去硬盘查找
最后在5500K条中文样本、1500K条英文样本、900K条代码样本进行预训练。他们使用了transformers的trainer搭配Deepspeed ZeRO3 (实测使用ZeRO2在多机多卡场景的速度较慢),在3个Node(每个Node上为8张32GB V100卡)进行多机多卡训练。下表是训练速度:参数 值 micro batch size(单张卡的batch size大小) 20 gradient accumulation(梯度累积) 3 global batch size(一个step的、全局的batch size) 20*3*24=1440 一个step耗时 260s
2.5.2 指令微调数据集构建与指令微调训练过程
- 在目前千篇一律的模型中,除了要加入通用的能力(比如推理能力、代码能力等),还额外增加了信息抽取能力(包括
NER、RE、EE)。需要注意的是,由于许多开源的数据集,比如alpaca数据集CoT数据集代码数据集都是英文的,因此为了获得对应的中文数据集,对这些英文数据集使用GPT4进行翻译
有两种情况:
1. 直接对问题和答案进行成中文
2. 将英文问题输入给模型,让模型输出中文回答
对通用的数据集使用第二种情况,对于其他数据集如CoT数据集代码数据集使用第一种情况
对于信息抽取(IE)数据集,英文部分,使用CoNLLACECASIS等开源的IE数据集,构造相应的英文指令数据集。中文部分,不仅使用了开源的数据集如DuEE、PEOPLE DAILY、DuIE等,还采用了他们自己构造的KG2Instruction,构造相应的中文指令数据集
具体来说,KG2Instruction(InstructIE)是一个在中文维基百科和维基数据上通过远程监督获得的中文信息抽取数据集,涵盖广泛的领域以满足真实抽取需求
此外,他们额外手动构建了中文的通用数据集,使用第二种策略将其翻译成英文。最后我们的数据集分布如下:数据集类型 条数 COT(中英文) 202,333 通用数据集(中英文) 105,216 代码数据集(中英文) 44,688 英文指令抽取数据集 537,429 中文指令抽取数据集 486,768 - KG2Instruction及其他指令微调数据集
编辑
- 目前大多数的微调脚本都是基于alpaca-lora,因此此处不再赘述,另详细的指令微调训练参数、训练脚本可以在./finetune/lora找到
附录
- https://github.com/zjunlp/KnowLM
- https://github.com/kaixindelele/ChatSensitiveWords
利用LLM+敏感词库,来自动判别是否涉及敏感词 - https://github.com/XLabCU/gpt3-relationship-extraction-to-kg
- https://github.com/niris/KGExtract/blob/main/get_kg.py
- https://github.com/semantic-systems/coypu-LlamaKGQA/blob/main/knowledge_graph_coypu.py
- https://github.com/xixi019/coypu-LlamaKGQA
- https://github.com/jamesdouglaspearce/kg-llama-7b
- https://github.com/zhuojianc/financial_chatglm_KG
另外,这是:关于LLM与知识图谱的一席论文列表
第三部分 LLM与数据库的结合:DB-GPT
GitHub - eosphoros-ai/DB-GPT: Revolutionizing Database Interactions with Private LLM Technology
3.1 DB-GPT的架构:用私有化LLM技术定义数据库下一代交互方式
DB-GPT基于 FastChat 构建大模型运行环境,并提供 vicuna 作为基础的大语言模型。此外,通过LangChain提供私域知识库问答能力,且有统一的数据向量化存储与索引:提供一种统一的方式来存储和索引各种数据类型,同时支持插件模式,在设计上原生支持Auto-GPT插件,具备以下功能或能力
- 根据自然语言对话生成分析图表、生成SQL
- 与数据库元数据信息进行对话, 生成准确SQL语句
- 与数据对话, 直接查看执行结果
- 知识库管理(目前支持 txt, pdf, md, html, doc, ppt, and url)
- 根据知识库对话, 比如pdf、csv、txt、words等等
- 支持多种大语言模型, 当前已支持Vicuna(7b,13b), ChatGLM-6b(int4,int8), guanaco(7b,13b,33b), Gorilla(7b,13b), llama-2(7b,13b,70b), baichuan(7b,13b)
整个DB-GPT的架构,如下图所示(图源)

3.2 DB-GPT的应用
通过QLoRA(4-bit级别的量化+LoRA)的方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
// 待更
更多课上见:七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
参考文献与推荐阅读
- LangChain 中文入门教程
- 大型语言模型与知识图谱协同研究综述:两大技术优势互补
- csunny/DB-GPT,DB-GPT 👏👏 0.3.8
- 关于KBQA的一系列论文:RUCAIBox / Awesome-KBQA
- 七月LLM与langchain/知识图谱/数据库的实战 [解决问题、实用为王]
相关文章:
知识图谱实战导论:从什么是KG到LLM与KG/DB的结合实战
前言 本文侧重讲解: 什么是知识图谱LLM与langchain/数据库/知识图谱的结合应用 比如,虽说基于知识图谱的问答 早在2019年之前就有很多研究了,但谁会想到今年KBQA因为LLM如此突飞猛进呢 第一部分 知识图谱入门导论 //待更.. 第二部分 LLM与…...

第5章 会话与会话技术
第5章 会话与会话技术 一. 单选题(共5题,50分)二. 判断题(共5题,50分) 一. 单选题(共5题,50分) (单选题) 阅读下面代码: Book book BookDB.getBook(id)…...
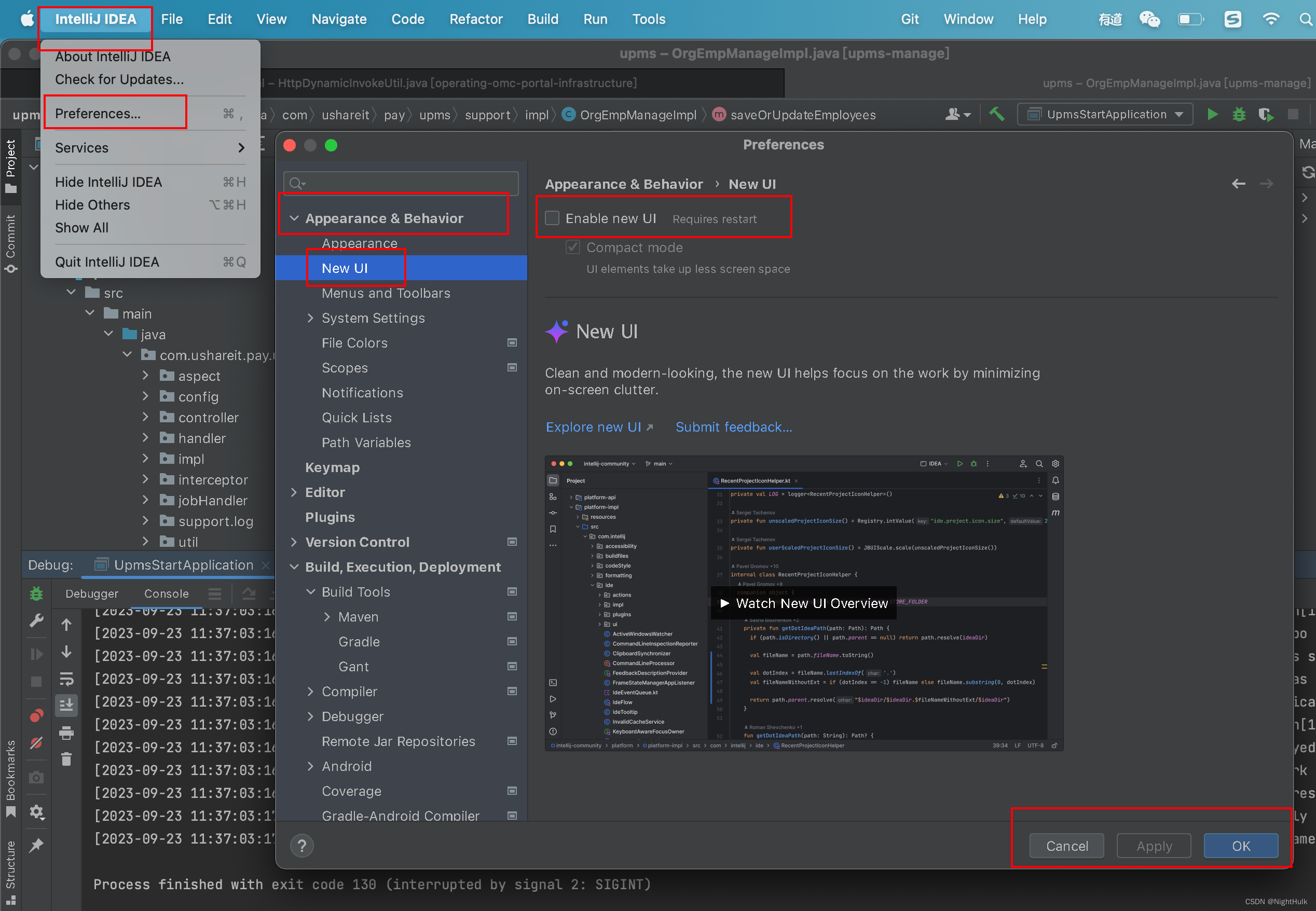
IDEA2023新UI回退老UI
idea2023年发布了新UI,如下所示 但是用起来真心不好用,各种位置也是错乱,用下面方法可以回退老UI...

ElasticSearch(三)
1.数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这些…...

【LinkedHashMap】146. LRU 缓存
146. LRU 缓存 解题思路 与普通的 HashMap 不同,LinkedHashMap 会保持元素的有序性。这可以在某些情况下提供更可预测的迭代顺序直接获取元素 因为使用到该元素 将该元素重新放入队尾 表示最近使用该元素写入元素,首先如果该元素原来存在 那么需要将ke…...
Opencv-python去图标与水印方案实践
RGB色彩模式是工业界的一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色ÿ…...

自己写过比较蠢的代码:从失败中学习的经验
文章目录 引言1. 代码没有注释2. 长函数和复杂逻辑3. 不恰当的变量名4. 重复的代码5. 不适当的异常处理6. 硬编码的敏感信息7. 没有单元测试结论 🎉 自己写过比较蠢的代码:从失败中学习的经验 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页&a…...
)
C语言 cortex-A7核 点LED灯 (附 汇编实现、使用C语言 循环实现、使用C语言 封装函数实现【重要、常用】)
1 汇编实现 text global _start start: ************** LED1点灯 ---> PE10 **************/ ************** RCC章节初始化 **************/ CC_INIT:1.使能GPIOE组控制器,通过RCC_MP_AHB4ENSETR寄存器设置GPIOE组使能0x50000A28[4] 1ldr r0,0x50000A28 准…...
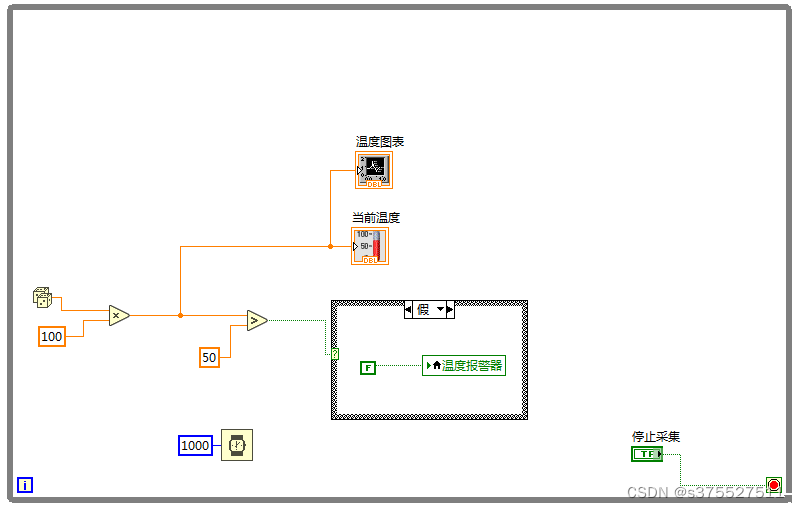
LABVIEW 实战案例1--温度报警系统
图1 温度报警系统前面板 图2 温度报警系统后面板...

【力扣】292. Nim 游戏
题目描述 你和你的朋友,两个人一起玩 Nim 游戏: 桌子上有一堆石头。你们轮流进行自己的回合, 你作为先手 。每一回合,轮到的人拿掉 1 - 3 块石头。拿掉最后一块石头的人就是获胜者。 假设你们每一步都是最优解。请编写一个函数…...
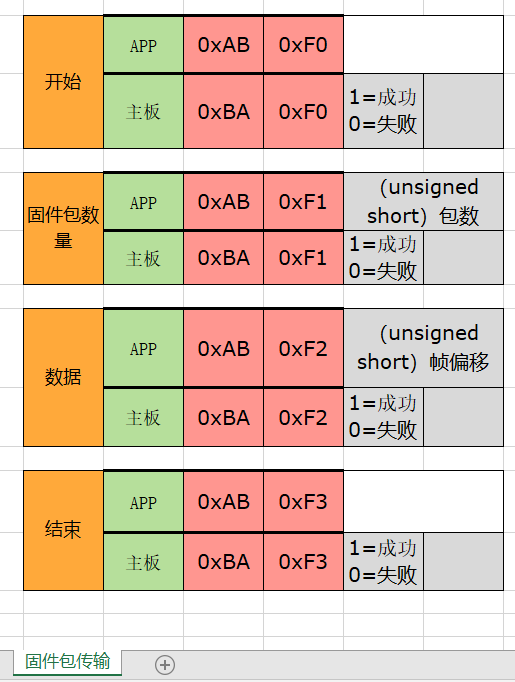
IAP固件升级分几步?(Qt上位机、)
前言 这周一直想做一个IAP固件升级的上位机,然后把升级流程全都搞懂 有纰漏请指出,转载请说明。 学习交流请发邮件 1280253714qq.com IAP原理 IAP的原理我就不多赘述了,这里贴上几位大佬的文章 STM32CubeIDE IAP原理讲解,及U…...
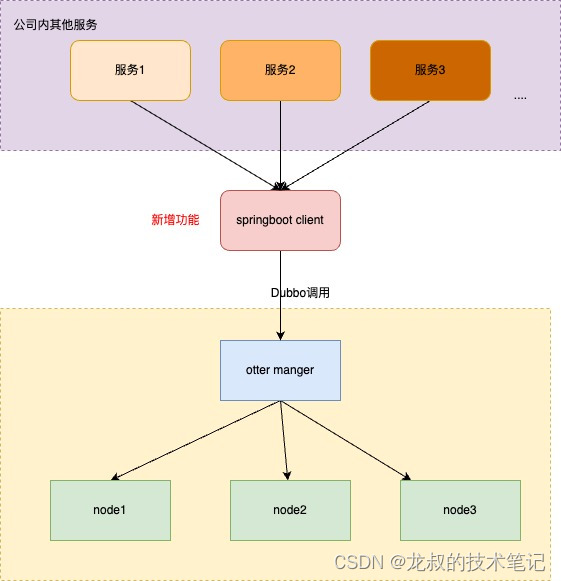
Otter改造 增加springboot模块和HTTP调用功能
环境搭建 & 打包 环境搭建: 进入 $otter_home/lib 目录执行:bash install.sh 打包: 进入$otter_home目录执行:mvn clean install -Dmaven.test.skip -Denvrelease发布包位置:$otter_home/target 项目背景 阿里…...
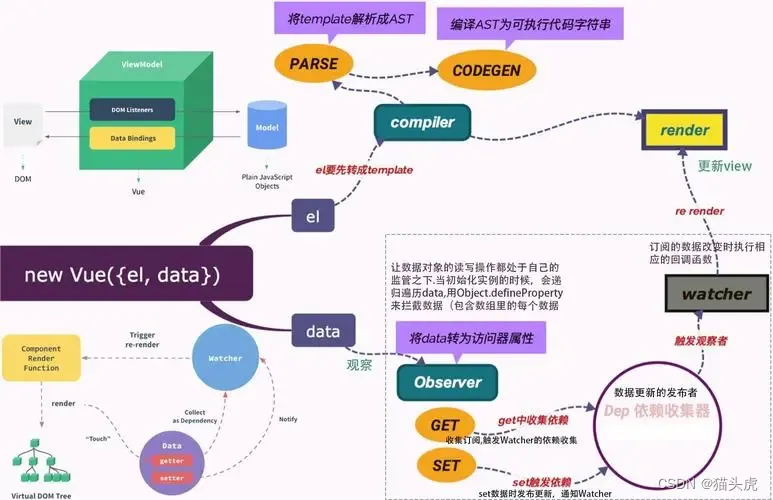
Vue.js vs React:哪一个更适合你的项目?
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
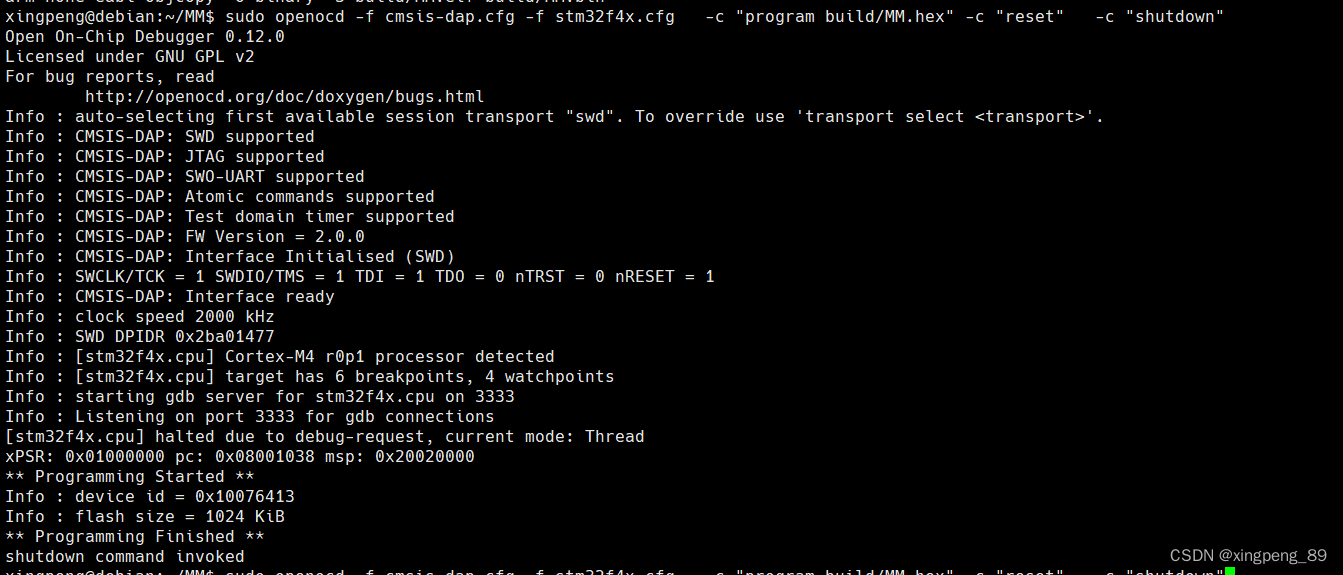
Debian环境下搭建STM32开发环境
1. 安装交叉编译工具,解压gcc-arm-none-eabi-10.3-2021.10-x86_64-linux.tar.bz2,并且把交叉编译环境添加到path路径。 2.安装下载工具驱动和下载工具 # 安装下载工具openocd sudo apt -y install openocd 3.下载测试 sudo openocd -f cmsis-dap.cfg -…...

如何防止商业秘密泄露(洞察眼MIT系统商业机密防泄密解决方案)
在当今的商业环境中,保护公司的商业秘密是至关重要的。商业秘密可能包括独特的业务流程、客户列表、研发成果、市场策略等,这些都是公司的核心竞争力。一旦这些信息被泄露,可能会对公司的生存和发展产生重大影响。本文将探讨如何通过使用洞察…...

题目 1062: 二级C语言-公约公倍
输入两个正整数m和n,求其最大公约数和最小公倍数。样例输入 2 3样例输出 1 6 这题一知半解的, 最小公倍数两数の积/最大公约数; 最大公约数通过迭代法求得(见其下), 作为a,b两数有一个属为有一个为0为无效数据时 《-----a%b等…...
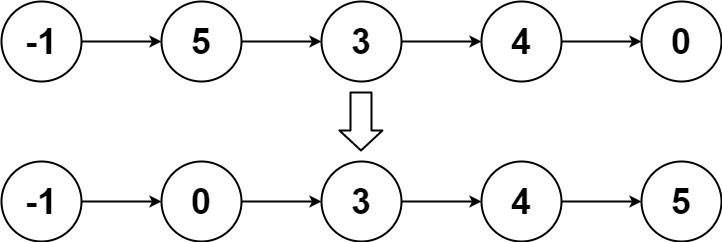
【Leetcode】148.排序链表
一、题目 1、题目描述 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例1: 输入:head = [4,2,1,3] 输出:[1,2,3,4]示例2: 输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]示例3: 输入:head = [] 输出:[]提示: 链表中节点的数目在范围 [0, 5 …...

用《斗破苍穹》的视角打开C#多线程开发1(斗帝之路)
Thread.Start() 是的,我就是乌坦城那个斗之气三段的落魄少爷,在我捡到那个色眯眯的老爷爷后,斗气终于开始增长了。在各种软磨硬泡下,我终于学会了我人生中的第一个黄阶斗技——吸掌。 using System.Threading;namespace Framewo…...

图像处理与计算机视觉--第三章-颜色与纹理分析-6问
图像处理与计算机视觉--第三章-颜色与纹理分析-6问 1.哪些因素决定物体颜色的感知? 对于物体颜色的感知,主要取决于以下三个因素: 1.照射到物体表面光波长的分布 2.物体表面如何反射照射光 3.传感器或者视觉细胞的敏感性 除了上述的三个因素之外,…...
vue重修002
文章目录 版权声明一 指令修饰符1. 什么是指令修饰符?2. 按键修饰符3. v-model修饰符4. 事件修饰符 二 v-bind对样式控制的增强-操作class1. 语法:2. 对象语法3. 数组语法4. 代码练习 三 京东秒杀-tab栏切换导航高亮四 v-bind对有样式控制的增强-操作sty…...

Java大文件分片上传完整实现教程
解决网络不稳定、服务器内存压力和用户体验差等问题是大文件分片上传的必要性。1. 分片上传允许在网络中断后只重传失败分片,提高成功率;2. 减少服务器单次处理的数据量,减少内存和i/o压力;3. 支持断点续传和秒传功能,…...

ESP32嵌入式Web文件管理器:支持SPIFFS/LittleFS/SD卡
1. EspWebFileManager 库概述EspWebFileManager 是一款专为 ESP32 平台设计的嵌入式 Web 文件管理中间件库,其核心目标是将本地文件系统操作能力通过轻量级 HTTP 服务暴露至浏览器端,实现免串口、免烧录工具的现场文件运维。该库并非独立文件系统驱动&am…...

5分钟搞定ECharts Tooltip显示问题:从滚动条到完美适配屏幕的保姆级教程
5分钟搞定ECharts Tooltip显示问题:从滚动条到完美适配屏幕的保姆级教程 第一次用ECharts做数据可视化时,Tooltip的显示问题简直让人抓狂——要么内容太长出现滚动条,要么直接冲出屏幕边界。作为过来人,我整理了这份实战指南&…...

信号分析避坑指南:MATLAB里算相位差,为什么你的结果总是不准?
MATLAB相位差计算避坑指南:从频谱泄漏到四象限陷阱的深度解析 在信号处理领域,相位差计算看似简单却暗藏玄机。许多工程师在使用MATLAB进行相位差分析时,经常会遇到结果跳变、误差过大甚至完全不符合预期的情况。这并非MATLAB的"bug&quo…...

千问3.5-27B效果展示:手写笔记图片→文字转录→知识点归类→复习卡片生成
千问3.5-27B效果展示:手写笔记图片→文字转录→知识点归类→复习卡片生成 1. 模型核心能力概览 Qwen3.5-27B作为一款视觉多模态理解模型,在知识处理领域展现出独特优势。它不仅能理解图片内容,还能对信息进行深度加工。本次重点展示其从手写…...

Anlogic FD工具深度体验:如何用eMCU软核实现SF1芯片的PSRAM控制器设计
Anlogic FD工具实战:基于eMCU软核的PSRAM控制器设计进阶指南 当FPGA工程师需要在资源受限的SF1芯片上实现高性能存储控制时,Anlogic Future Dynasty(FD)工具链中的eMCU软核与PSRAM控制器组合提供了绝佳的解决方案。不同于基础教程…...

Video2X:让你的老旧视频焕发新生的AI魔法工具
Video2X:让你的老旧视频焕发新生的AI魔法工具 【免费下载链接】video2x A lossless video/GIF/image upscaler achieved with waifu2x, Anime4K, SRMD and RealSR. Started in Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trending/vi/video…...

告别Keil:用VS Code + EIDE打造高效C51开发环境
1. 为什么我们要放弃Keil? 如果你接触过C51单片机开发,Keil μVision这个名字一定不会陌生。作为单片机开发领域的"老前辈",Keil几乎成了教学和入门的标准工具。但说实话,每次打开那个灰蒙蒙的界面,我都感觉…...

RAG技术:解锁大模型潜力,实现精准、可信赖的智能问答
RAG(检索增强生成)技术通过将大语言模型(LLM)与外部知识库结合,有效解决LLM知识静态、幻觉等问题,提升回答的准确性与可信度。RAG技术核心包括检索和生成两个阶段,通过优化文本分块、索引构建、…...

终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间?
终极美化指南:foobar2000如何通过foobox-cn打造你的专属音乐空间? 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 厌倦了千篇一律的音乐播放器界面?想让你的音乐体…...