读书笔记:多Transformer的双向编码器表示法(Bert)-2
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第2章 了解Bert模型(掩码语言模型构建和下句预测)
文本嵌入模型Bert,在许多自然语言处理任务上表现优秀,本节主要包括:
- 了解Bert,及与其他嵌入模型的区别;
- 分析Bert工作原理和基础配置;
- 两个任务场景:掩码语言模型构建和下句预测;
- Bert训练过程;
Bert基本理念
问答任务、文本生成、句子分类的自然语言处理任务重都有良好表现,其成功在于它是基于上下文的嵌入模型(有别于通过建立词在语言空间中的向量映射的模型);
有上下文嵌入模型 vs 无上下文嵌入模型
- 对于一词多义,同一个词的词嵌入,在不同场景(这里指上下文)中应不同;
- 如果是无上下文嵌入的话,那么词嵌入就会相同;
而Bert就是一个基于上下文的模型,先理解语境(Bert会将词与句子中的所有单词联系起来),然后根据上下文生成该词的嵌入值;
BERT是基于Transformer模型的,可以把BERT看做是只有编码器的Transformer;
我们已经知道Transformer编码器会输出句子中每个词的特征值,且Transformer编码器是双向的,它可以从两个方向读取一个句子;
一个句子送入编码器,编码器就会利用多头注意力层来理解每个单词在句中的上下文,并输出特征值;每个单词的特征向量大小是前馈网络层的大小(即隐藏神经元的个数),假设是768,那么每个单词的特征向量大小也是768,这个768同样也应该是用于生成QKV矩阵的权重矩阵中权重向量的维度;
Bert的两种标准配置:
- BERT-base
- BERT-large
BERT-base:
- L:由12层编码器叠加;
- A:
每层编码器都使用12个注意力头; - H:隐藏神经元数量768;
- 其总参数量达到1.1亿个;
BERT-large:
- L:24
- A:16
- H:1024
- 网络参数量达3.4亿个;
其他的一些小型配置:
- BERT-tiny:L=2、H=128
- BERT-mini:L=4、H=256
- BERT-small:L=4、H=512
- BERT-medium:L=8、H=512
更小配置的BERT可以适配到更有限的资源,但标准BERT可以得到更准确的结果;
BERT 模型预训练
对模型m使用一个大型数据集针对某个具体任务进行训练,并保存训练模型;再对一个新任务,使用已经训练过的模型权重来初始化m(不使用随机初始化从头训练),并根据新任务调整(微调)其权重;
BERT模型在一个巨大的语料库上针对两个特定任务进行预训练:掩码语言模型构建、下句预测;训练得到的模型,在一个新任务中,比如问答任务,载入预训练参数,微调权重即可;
WordPiece:
一种特殊的词元分析器,遵循子词词元化规律;
示例:Let us start pretraining the model,使用WordPiece标记的结果为:
tokens = [let, us, start, pre, ##train, ##ing, the, model]
具体过程:
- 检查该词是否存在于词表中,在则作为一个标记;
- 不在,则继续分成子词,检查子词是否在词表中,在则作为一个标记;
- 不在则继续分割子词;
- 通过这种方式不断进行拆分,检查子词是否在词表中,直到字母级别(无法再分),这在处理未登录词时是有效的;
BERT词表有3万个标记,本例中词表中没有pretraining这个词,因此将该词进行拆分,##表示该词是一个子词,其前面还有其他的词;
对输入数据的处理:
在将数据输入BERT前,需要使用3个嵌入层将输入转换为嵌入:标记嵌入层、分段嵌入层、位置嵌入层;
标记嵌入层:
- 对于一个文本段落,添加
[CLS]标记到第一个分词并掩码后的句子开头(只在第一个开头加); - 添加
[SEP]标记到每个分词并掩码后的句子末尾(每一句结尾都要加); [CLS]用于分类任务,[SEP]表示每个句子结束;- 使用标记嵌入层将标记后的文本转换为嵌入,注意标记嵌入的值将通过训练学习获得的;
分段嵌入层:
- 用来区分两个给定的句子;
- 分段嵌入层只输出EA或EB,即如果输入的标记属于句子A,那么该标记将被映射到嵌入EA;
如果只有一个句子,句子的所有标记都将被映射到嵌入EA;
位置嵌入层:
- 用来获得句子中每个标记的位置嵌入的;
| 输入 | [CLS] | Pairs | is | a | city | [SEP] | I | love | it | [SEP] |
|---|---|---|---|---|---|---|---|---|---|---|
| +标记嵌入 | E[CLS] | EPairs | Eis | Ea | Ecity | E[SEP] | EI | Elove | Eit | E[SEP] |
| +分段嵌入 | EA | EA | EA | EA | EA | EA | EB | EB | EB | EB |
| +位置嵌入 | E0 | E1 | E2 | E3 | E4 | E5 | E6 | E7 | E8 | E9 |
现在就可以将结果送入BERT了;
预训练策略
BERT模型在一个巨大的语料库上针对两个特定任务进行预训练:
- 掩码语言模型构建
- 下句预测
语言模型构建:
语言模型构建任务是指通过训练模型来预测一连串单词的下一个单词,可以把语言模型分两类:
- 自动回归式语言模型
- 自动编码式语言模型
自动回归式语言模型有以下两种方法:
- 正向(从左到右)预测;
- 反向(从右到左)预测;
举例:Pairs is a city. I love it.
- 将city用空白代替,如果使用正向预测,那么模型就会从左到右读取所有单词,直到空白处,然后进行预测;
- 若使用反向预测,那么模型就会从右到左完成这个过程;
自动回归式语言模型本质上是单向的,它只能沿着一个方向阅读句子;
自动编码式语言模型:自动编码式语言模型是双向的,可以同时利用正向预测和反向预测的优势,预测时同时从两个方向阅读句子;这样能更清晰地理解句子,能输出更好的结果;
掩码语言模型构建:
BERT是自动编码式语言模型,在掩码语言模型构建任务中,给定一个输入句,随机掩盖其中15%的单词,并训练模型来预测被掩盖的单词;
工作原理:
- 依旧用之前例句,使用
[MASK]替换了city,就可以训练BERT模型来预测被掩盖的词;
这里会引入一个小问题:
- BERT预训练模型是通过预测
[MASK]来训练BERT,但在下游任务微调时,输入中不会有任何[MASK]标记,这将导致BERT的预训练方式和用于微调的方式不匹配;
解决办法是使用80-10-10规则:
- 对于随机覆盖的15%标记,再做如下处理;
- 在80%的情况下,使用
[MASK]标记来替换实际词标记; - 10%的数据,使用一个随机标记(随机词)来替换实际词标记;
- 剩余10%的数据,不做任何改变;
在分词和掩码后,将标记列表送入标记嵌入层、分段嵌入层和位置嵌入层,得到嵌入向量;再将嵌入向量送入BERT,BERT将输出每个标记的特征向量
| 输入 | [CLS] | Pairs | is | a | city | [SEP] | I | love | it | [SEP] |
|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | [CLS] | Pairs | is | a | [MASK] | [SEP] | I | love | it | [SEP] |
| +标记嵌入 | E[CLS] | EPairs | Eis | Ea | Ecity | E[SEP] | EI | Elove | Eit | E[SEP] |
| +分段嵌入 | EA | EA | EA | EA | EA | EA | EB | EB | EB | EB |
| +位置嵌入 | E0 | E1 | E2 | E3 | E4 | E5 | E6 | E7 | E8 | E9 |
| 输出标记 | R[CLS] | RPairs | Ris | Ra | Rcity | R[SEP] | RI | Rlove | Rit | R[SEP] |
若使用BERT-base配置,12层编码器、12个注意力头、768个隐藏神经元,输出的每个标记的特征向量大小也是768;
那么如何使用这些特征向量来预测被掩盖的词呢?
- 将BERT计算的 被掩盖的词的特征向量
R[MASK]送入使用softmax激活函数的前馈网络层,输出词表中所有单词为掩盖单词的概率; - 通过多次训练迭代,更新优化BERT的前馈网络层和编码器层权重,使之最优,这样模型才能返回正确的概率;
掩码语言模型构建任务也被称为完形填空任务;除了对输入标记进行掩码处理,还可以使用另一种方法,即全词掩码;
全词掩码:
- 在全词掩盖中,如果子词被掩盖,那么该子词对应的单词也将被掩盖;
- 如果掩码率超过15%,那么可以忽略掩盖其他词;
下句预测:
下句预测(next sentence prediction)是一个用于训练BERT模型的策略,它是一个二分类任务;
在该任务重,我们想BERT模型提供两个句子,预测第二个句子是否是第一个句子的下一句;通过执行下句预测任务,BERT模型可以理解两个句子之间的关系;
可以从任何一个单一语言语料库中生成数据集:
- 从一个文档抽取任意两个连续句子,标为isNext;
- 从一个文档中抽取一个句子,并从一个随机文档中抽取另一个句子,标为notNext;
- 注意,要保证isNext类别与notNext类别数据各占50%;
输入句子对,预测标签;
具体过程:
- 使用wordpiece添加标记:
[CLS]第一个句子分词[SEP]第二个句子分词[SEP]; - 然后将标记送入 标记嵌入层、分段嵌入层和位置嵌入层,得到嵌入值;
- 再将嵌入值送入BERT模型,得到每个标记的特征值;
- 根据特征值进行分类,只需
将[CLS]标记的特征值通过softmax激活函数将其送入前馈网络层,然后返回句子对分别是isNext和notNext的概率;
这里之所以只需要取
[CLS]标记的嵌入,是因为该标记基本上汇总了所有标记的特征,所以它可以表示句子的总特征;
同样需要通过多次训练迭代,更新优化BERT的前馈网络层和编码器层权重,使之最优,这样模型才能返回正确的概率;
预训练过程
BERT使用多伦多图书语料库(Toronto BookCorpus)和维基百科数据集进行预训练,我们已将了解了两种训练任务:掩码语言模型(完形填空)和下句预测任务,现在需要准本数据集;
- 从语料库中抽取两个句子A和B;
- 句子的标记数之和 应小于或等于
512; - 对两个句子进行采样时,需保证句子B作为句子A的下一句和非下一句比例为1比1;
- 使用wordpiece添加标记,将
[CLS]标记在第一句开头,将[SEP]标记在每句结尾; - 根据80-10-10规则,随机掩盖15%的标记;
- 然后将得到嵌入的标记送入BERT模型,并训练BERT模型预测被掩盖的标记,
同时对句子B是否是句子A的下一句进行分类;
BERT使用256个序列批量(Batchsize=256)进行100w步的训练,使用Adam优化器,lr=1e-4、β1=0.9、β2=0.999,预热步骤设置为1w;
关于预热步骤:我们知道在训练的初始阶段可以设置较高学习率,使最初迭代更快接近最优点,后续迭代中,则调低学习率使结果更加准确,因为在最初,权重值远离收敛值,较大幅度的lr变化是可接受的,但后续如果已经接近收敛值,仍采样相同的变化幅度,就容易错过收敛值,这就是学习率的调整策略;而预热步骤,是通过1w次迭代,将学习率由0线性的提高到1e-4,1w之后的迭代,再随着误差接近收敛,线性地降低学习率;
在训练中还对所有层使用了随机节点关闭(dropout),每层关闭节点概率为0.1,激活函数使用GeLU(即高斯误差线性单元Gaussian Error Linear Unit);
看着有点像relu,但是在小于0的一部分x轴的y值是较小的负值,实际曲线像一个对号;
预训练后,BERT模型就可以应用于各种任务;
几种子词词元化算法
子词词元化算法:BERT所使用的,在处理未登录词方面非常有效;
假设有一个训练数据集,更具它我们创建一张词表(分词 添加):
- 一般的词表(vocablary)由许多单词(标记)组成;
- 在对句子进行标记时,如遇到非词表单词,可使用标识未知单词的标记
<UNK>代替; - 为避免词表过大,可以通过子词词元化,将单词分成子词,将子词加入词表,子词在标识时需要在前面添加两个
#号,表示和前面的词相关联; - 子词词元化算法 可以决定哪些单词需要拆分,哪些不需要;
常见的三种子词词元化算法:
- 字节对编码 BPE
- 字节级字节对编码 BBPE,每个Unicode字节都被转换为1字节,一个字符可以有1~4个字节,然后使用字节对编码算法,使用字节级频繁对构建词表;在对语言环境下很有用;
- WordPiece,与字节对编码稍有不同:
- 字节对编码 从给定数据集中提取带有计数的单词,然后将其拆分成字符序列,再将具有高频率的符号进行合并;不断迭代具有高频率的符号对,直到满足词表的大小要求;
- 而在WordPiece中,不根据频率合并符号对,而是根据相似度合并符号对,合并具有高相似度的符号对,其相似度由在给定的数据集上训练的语言模型提供;
对于出现最频繁的符号对(合并),检查每个符号对的语言模型(在给定的训练集上训练)的相似度,合并相似度最大的符号对;
算法步骤:
- 从给定的数据集中提取单词并计算它们出现的次数;
- 确定词表大小;
- 将单词拆分成一个字符序列;
- 将字符序列中的所有非重复字符添加到词表中;
- 在给定的数据集(训练集)上构建语言模型;
- 选择合并具有最大相似度(基于上一步中的语言模型)的符号对;
- 重复上一步,直到达到所设定的词表大小;
词表构建后,就可以用来做文本标记。
相关文章:
读书笔记:多Transformer的双向编码器表示法(Bert)-2
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 第2章 了解Bert模型(掩码语言模型构建和下句预测) 文本嵌入模型Bert,在许多自然语言处理任务上表现优秀&#…...
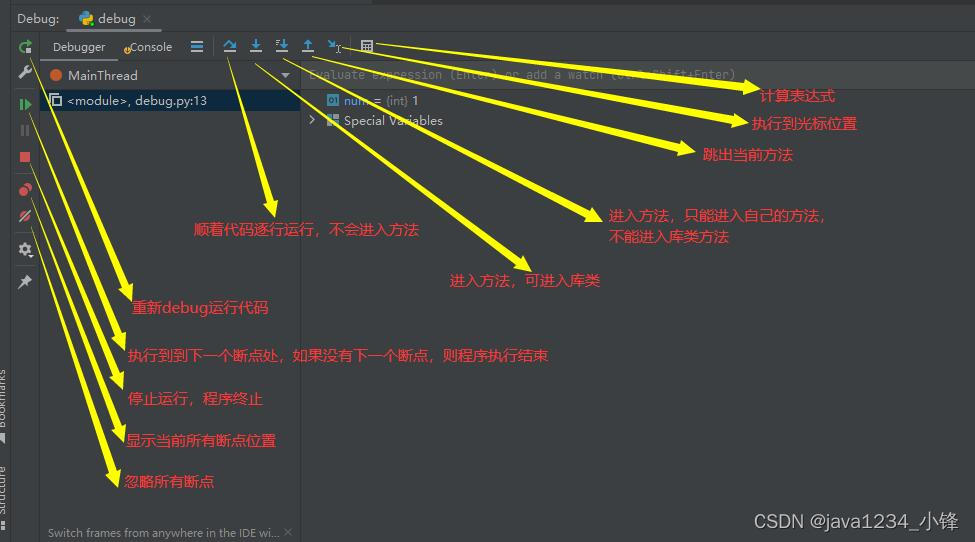
Python 基于PyCharm断点调试
视频版教程 Python3零基础7天入门实战视频教程 PyCharm Debug(断点调试)可以帮助开发者在代码运行时进行实时的调试和错误排查,提高代码开发效率和代码质量。 准备一段代码 def add(num1, num2):return num1 num2if __name__ __main__:f…...

spring security auth2.0实现
OAuth 2.0 的认证/授权流程 jwt只是认证中的一步 4中角色 资源拥有者(resource owner)、客户端(client 第三方)、授权服务器(authorization server)和资源服务器(resource server)。…...
LOCK和MVCC)
MySQL(6)LOCK和MVCC
一、锁的分类 按照锁的属性:读锁、写锁、共享锁、排它锁、悲观锁、乐观锁 按照锁的范围:表锁、页锁、间隙锁、临键锁、行锁 按照锁的作用:意向锁、意向共享锁、意向排它锁、IS锁、IX锁 二、MySQL为什么要有锁 锁是计算机协调多个进程或线程并…...
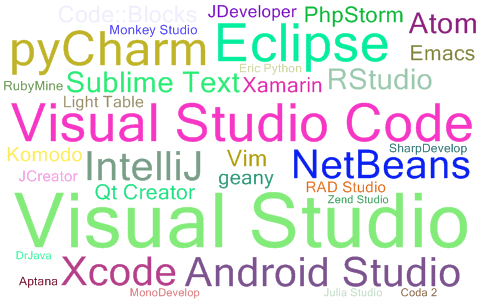
最新IDE流行度最新排名(每月更新)
2023年09月IDE流行度最新排名 顶级IDE排名是通过分析在谷歌上搜索IDE下载页面的频率而创建的 一个IDE被搜索的次数越多,这个IDE就被认为越受欢迎。原始数据来自谷歌Trends 如果您相信集体智慧,Top IDE索引可以帮助您决定在软件开发项目中使用哪个IDE …...

I2C的上拉电阻如何计算?
说明: 1、本文只说明I2C上拉电阻的最小值如何计算。 2、I2C最小值和最大值计算的详细原理可以参考这篇文章:https://mp.weixin.qq.com/s/ZvJJ0rPRd_STULj8g1H81A。 3、I2C最小值的计算方式比较简单,在实际应用中计算出最小值,然后…...

Centos下安装 oracle11g 博客2
[oraclewangmengyuan database]$ ./runInstaller -silent -responseFile /home/oracle/database/response/db_install.rsp -ignorePrereq ./runInstaller -silent -responseFile /home/oracle/database/response/db_install.rsp -ignorePrereq 正在启动 Oracle Universal Insta…...

记一次逆向某医院挂号软件的经历
背景 最近家里娃需要挂专家号的儿保,奈何专家号实在过于抢手,身为程序员的我也没有其他的社会资源渠道可以去弄个号,只能发挥自己的技术力量来解决这个问题了。 出师不利 首先把应用安装到我已经 Root 过的 Pixel 3 上面,点击应…...
Canal实现Mysql数据同步至Redis、Elasticsearch
文章目录 1.Canal简介1.1 MySQL主备复制原理1.2 canal工作原理 2.开启MySQL Binlog3.安装Canal3.1 下载Canal3.2 修改配置文件3.3 启动和关闭 4.SpringCloud集成Canal4.1 Canal数据结构
Kafka的消息传递保证和一致性
前言 通过前面的文章,相信大家对Kafka有了一定的了解了,那接下来问题就来了,Kafka既然作为一个分布式的消息队列系统,那它会不会出现消息丢失或者重复消费的情况呢?今天咱们就来一探。 实现机制 Kafka采用了一系列机…...

Docker 部署 Firefly III 服务
拉取最新版本的 Firefly III 镜像: $ sudo docker pull fireflyiii/core:latest在本地预先创建好 upload 和 export 目录, 用于映射 Firefly III 容器内的 /var/www/html/storage/upload 和 /var/www/html/storage/export 目录。 使用以下命令来运行 Firefly III …...
配置OSPFv3基本功能 华为笔记
1.1 实验介绍 1.1.1 关于本实验 OSPF协议是为IP协议提供路由功能的路由协议。OSPFv2(OSPF版本2)是支持IPv4的路由协议,为了让OSPF协议支持IPv6,技术人员开发了OSPFv3(OSPF版本3)。 无论是OSPFv2还是OSPFv…...
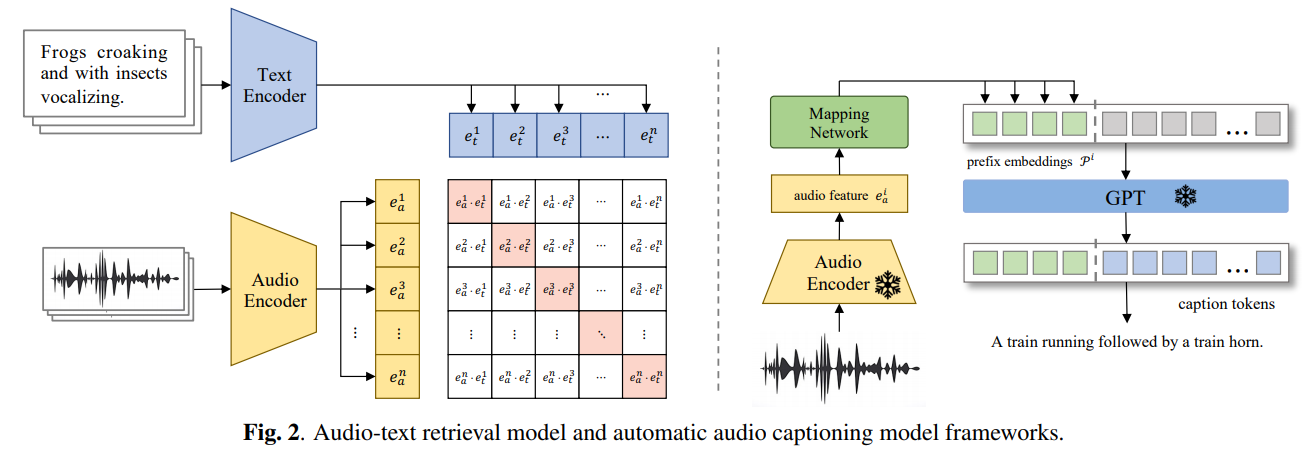
【AI视野·今日Sound 声学论文速览 第九期】Thu, 21 Sep 2023
AI视野今日CS.Sound 声学论文速览 Thu, 21 Sep 2023 Totally 1 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚Auto-ACD,大规模文本-音频数据集自动生成方法。 基于现有的大模型和api构建了一套大规模高质量的音频文本数据收集方法,…...

数据结构-----堆(完全二叉树)
目录 前言 一.堆 1.堆的概念 2.堆的存储方式 二.堆的操作方法 1.堆的结构体表示 2.数字交换接口函数 3.向上调整(难点) 4.向下调整(难点) 5.创建堆 6.堆的插入 7.判断空 8.堆的删除 9.获取堆的根(顶)元素 10.堆的遍历…...

set/multiset容器、map容器
目录 set/multiset容器 set基本概念 set大小和交换 set插入和删除 查找和统计 set和multiset的区别 改变set排序规则 set存放内置数据类型 set存放自定义数据类型 pair队组 map容器 map容器的基本概念 map构造和赋值 map大小和交换 map插入和删除 map查找和统计…...
)
Linux系统编程——总结初识Linux(常用命令、特点、常见操作系统)
文章目录 UNIX操作系统(了解)Linux操作系统主要特征Linux和unix的区别和联系什么是操作系统常见的操作系统Ubuntu操作系统Ubuntu安装linux下的目录的类型(掌握)shell指令shell指令的格式文件操作相关指令系统相关命令网络相关命令其他命令软件安装相关的…...

Js使用ffmpeg进行视频剪辑和画面截取
ffmpeg 使用场景是需要在web端进行视频的裁剪,包括使用 在线视频url 或 本地视频文件 的裁剪,以及对视频内容的截取等功能。 前端进行视频操作可能会导致性能下降,最好通过后端使用java,c进行处理,本文的案例是备选方…...

Linux基本命令,基础知识
进到当前用户目录:cd ~ 回到上级目录:cd .. 查看当前目录层级:pwd 创建目录:mkdir mkdir ruanjian4/linux/zqm41 -p级联创建文件夹(同时创建多个文件夹需要加-p) 查看详细信息:ls -l (即 ll) 查看所有详细信息:ls -al 隐藏文件是以.开头的 查看:l…...
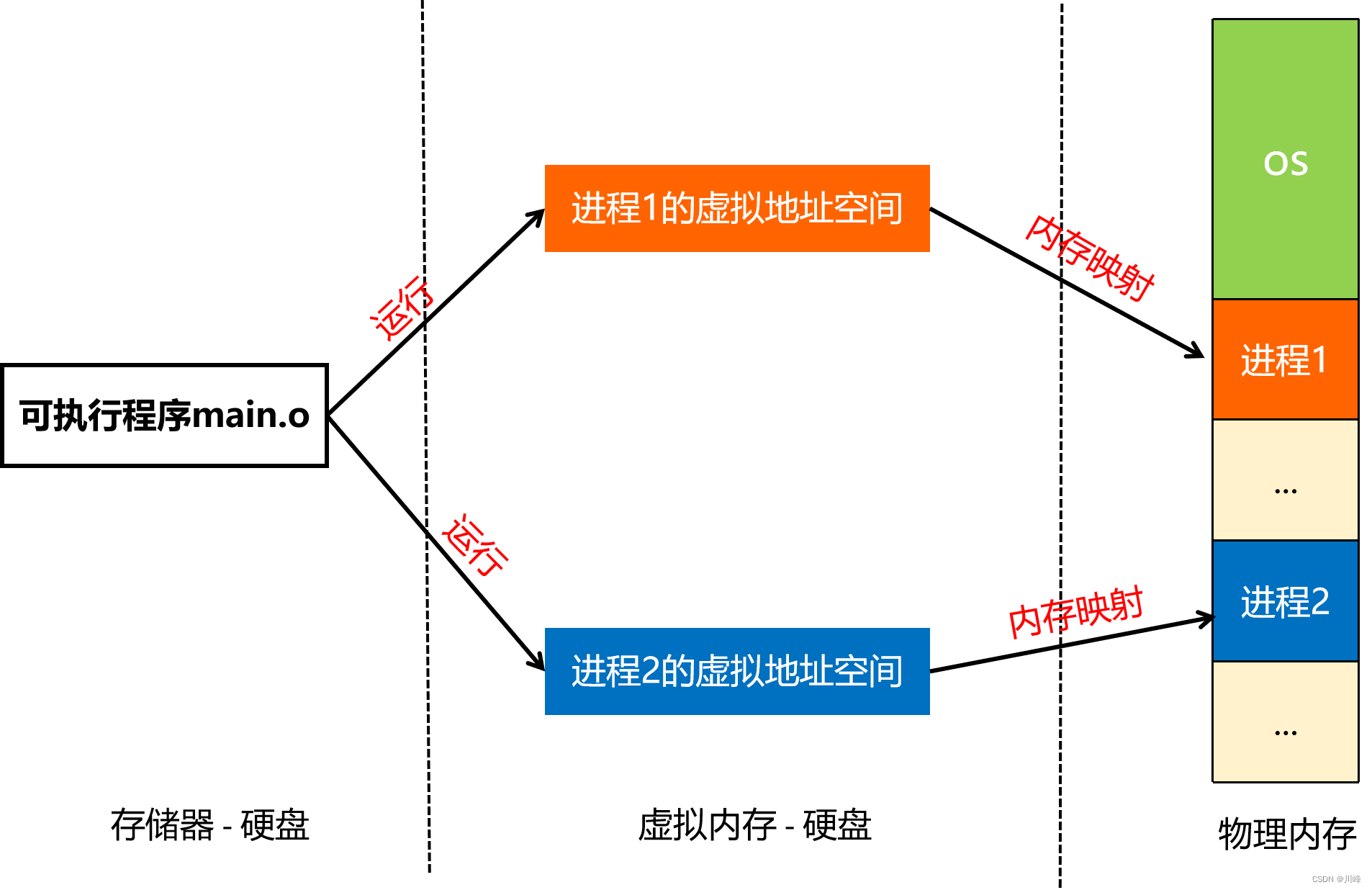
【Android知识笔记】进程通信(三)
在上一篇探索Binder通信原理时,提到了内存映射的概念,其核心是通过mmap函数,将一块 Linux 内核缓存区映射到一块物理内存(匿名文件),这块物理内存其实是作为Binder开辟的数据接收缓存区。这里有两个概念,需要理解清楚,那就是操作系统中的虚拟内存和物理内存,理解了这两…...

云上亚运:所使用的高新技术,你知道吗?
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 前言 一.什么是云上亚运会 二.为什么要使用云…...

YA-Wiegand:轻量级事件驱动Wiegand协议解析库
1. 项目概述Yet Another Arduino Wiegand Library(以下简称 YA-Wiegand)是一个专为嵌入式平台设计的轻量级、事件驱动型 Wiegand 协议解析库。它并非简单封装硬件抽象层,而是聚焦于协议语义层的健壮性实现——在不依赖特定 MCU 外设ÿ…...

盘姬工具箱功能详解:百余款实用工具助力系统优化
盘姬工具箱最大的特点就是功能的全面性。 软件安装后即可直接使用,打开界面就能看到丰富多样的功能模块。 这些功能模块分类清晰,操作直观,即使是电脑新手也能快速上手。 从日常的小工具到高级的技术工具,盘姬工具箱几乎涵盖了…...

恒压供水系统:维纶通屏与S7 - 200程序的奇妙组合
恒压供水,维纶通屏+s7 200程序在自动化控制领域,恒压供水系统一直是一个经典应用。今天咱就来唠唠如何用维纶通屏搭配S7 - 200程序实现恒压供水。 一、恒压供水原理简介 恒压供水简单来说,就是不管用水量怎么变化,都能…...

HarmonyOS6 - RcNumberBox 三方库插件尺寸系统与按钮布局深度剖析
文章目录前言一、三档预设尺寸系统1.1 尺寸枚举与默认值1.2 尺寸计算方法解析1.3 尺寸对比示例二、两种按钮布局模式2.1 both 模式:经典三分布局2.2 right 模式:垂直叠放布局2.3 两种布局的 build 逻辑差异2.4 按钮显隐与控制开关三、边框与颜色的状态响…...
)
D3作业1-K8s 存储与服务实验手册(实验1-4)
前置准备:配置Harbor私有仓库 # 在k8s-harbor1上执行# 1. 下载镜像 docker pull registry.cn-hangzhou.aliyuncs.com/zhangshijie/nginx:1.22.0-alpine# 2. 打标签 docker tag registry.cn-hangzhou.aliyuncs.com/zhangshijie/nginx:1.22.0-alpine 192.168.44.104/library/ng…...
完整避坑流程)
SAP财务顾问必看:GGB1凭证替代实战指南,从配置到激活(OBBH)完整避坑流程
SAP财务顾问实战:GGB1凭证替代从配置到激活全流程解析 在SAP财务模块实施过程中,凭证字段的自动化处理一直是提升业务效率的关键环节。想象一下这样的场景:当财务人员录入供应商发票时,系统能自动根据预设规则填充付款条件&#x…...
)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例) 在AI技术快速落地的今天,将大模型能力集成到自己的应用中已成为开发者的刚需。MiniMax作为国内领先的大模型服务提供商,其API平台提供了对话…...

DFS实现回溯算法
在算法学习的过程中,深度优先搜索(DFS)和回溯算法可以说是每个程序员都必须掌握的经典内容。它们像是一对孪生兄弟,经常一起出现,解决各种组合、排列、搜索类问题。今天,我们就来深入探讨如何用DFS实现回溯…...

WebLaTex:革新学术写作体验的云端LaTeX解决方案
WebLaTex:革新学术写作体验的云端LaTeX解决方案 【免费下载链接】WebLaTex A complete alternative for Overleaf with VSCode Web Git Integration Copilot Grammar & Spell Checker Live Collaboration Support. Based on GitHub Codespace and Dev cont…...

Realistic Vision V5.1 虚拟摄影棚结合传统软件:生成素材导入PS进行后期合成
Realistic Vision V5.1 虚拟摄影棚结合传统软件:生成素材导入PS进行后期合成 你有没有遇到过这样的场景:脑子里有一个绝佳的创意画面,但要么找不到合适的模特和场景,要么拍摄成本高得吓人,要么就是后期修图修到天昏地…...