多綫程之python爬蟲構建
目录
- 多綫程
- 定義
- 簡介
- 原理
- 优点
- 缺点
- 优势
- 代碼框架實現
- 導包
- 打印類
- 爬蟲類
- 構造方法
- 獲取代理
- 設置headers
- 獲取新session
- 獲取源代碼
- 解析網頁
- 解析子頁面
- 保存數據
- 綫程任務
- 得到url
- 啓動多綫程爬蟲
- 總結
多綫程
以下定義來自百度百科,看看就好沒仔細寫
定義
多线程(multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理或同时多线程处理器。在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理”
簡介
在计算机编程中,一个基本的概念就是同时对多个任务加以控制。许多程序设计问题都要求程序能够停下手头的工作,改为处理其他一些问题,再返回主进程。可以通过多种途径达到这个目的。最开始的时候,那些掌握机器低级语言的程序员编写一些“中断服务例程”,主进程的暂停是通过硬件级的中断实现的。尽管这是一种有用的方法,但编出的程序很难移植,由此造成了另一类的代价高昂问题。中断对那些实时性很强的任务来说是很有必要的。但对于其他许多问题,只要求将问题划分进入独立运行的程序片断中,使整个程序能更迅速地响应用户的请求。
最开始,线程只是用于分配单个处理器的处理时间的一种工具。但假如操作系统本身支持多个处理器,那么每个线程都可分配给一个不同的处理器,真正进入“并行运算”状态。从程序设计语言的角度看,多线程操作最有价值的特性之一就是程序员不必关心到底使用了多少个处理器。程序在逻辑意义上被分割为数个线程;假如机器本身安装了多个处理器,那么程序会运行得更快,毋需作出任何特殊的调校。根据前面的论述,大家可能感觉线程处理非常简单。但必须注意一个问题:共享资源!如果有多个线程同时运行,而且它们试图访问相同的资源,就会遇到一个问题。举个例子来说,两个线程不能将信息同时发送给一台打印机。为解决这个问题,对那些可共享的资源来说(比如打印机),它们在使用期间必须进入锁定状态。所以一个线程可将资源锁定,在完成了它的任务后,再解开(释放)这个锁,使其他线程可以接着使用同样的资源 。
线程是进程中的一部分,也是进程的的实际运作单位,它也是操作系统中的最小运算调度单位。进程中的一个单一顺序的控制流就是一条线程,多个线程可以在一个进程中并发。可以使用多线程技术来提高运行效率。
多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的
原理
实现多线程是采用一种并发执行机制。
并发执行机制原理:简单地说就是把一个处理器划分为若干个短的时间片,每个时间片依次轮流地执行处理各个应用程序,由于一个时间片很短,相对于一个应用程序来说,就好像是处理器在为自己单独服务一样,从而达到多个应用程序在同时进行的效果。
多线程就是把操作系统中的这种并发执行机制原理运用在一个程序中,把一个程序划分为若干个子任务,多个子任务并发执行,每一个任务就是一个线程。这就是多线程程序。
多线程技术不但可以提高交互式,而且能够更加高效、便捷地进行控制。在对多线程应用的时候,可以使程序响应速度得到提高,从而实现速度化、高效化的特点。另外,多线程技术存在的缺点也比较明显,需要等待比较长的时间之外,还会在一定程度上使程序运行速度降低,使工作效率受到一定的影响,从而对资源造成了浪费。
具體可以查看操作系統的知識
优点
- 使用线程可以把占据时间长的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度 。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下可以释放一些珍贵的资源如内存占用等。
- 多线程技术在IOS软件开发中也有举足轻重的作用。
缺点
- 如果有大量的线程,会影响性能,因为操作系统需要在它们之间切换
- 更多的线程需要更多的内存空间
- 线程可能会给程序带来更多“bug”,因此要小心使用
- 线程的中止需要考虑其对程序运行的影响
- 通常块模型数据是在多个线程间共享的,需要防止线程死锁情况的发生。
优势
多进程程序结构和多线程程序结构有很大的不同,多线程程序结构相对于多进程程序结构有以下的优势:
- 方便的通信和数据交换
线程间有方便的通信和数据交换机制。对于不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。 - 更高效地利用CPU
使用多线程可以加快应用程序的响应。这对图形界面的程序尤其有意义,当一个操作耗时很长时,整个系统都会等待这个操作,此时程序不会响应键盘、鼠标、菜单的操作,而使用多线程技术,将耗时长的操作置于一个新的线程,就可以避免这种尴尬的情况。
同时,多线程使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
代碼框架實現
導包
import random # 隨機
import queue # 隊列
import threading # 綫程
import time # 時間
import requests # http請求
from bs4 import BeautifulSoup # 靚湯解析
import pandas as pd # 數據解析
打印類
讓打印的信息有顔色,具體可以看我另一篇文章:print打印設置字體顔色
class BCOLOR:def __init__(self):self.HEADER = '\033[95m'self.OKBLUE = '\033[94m'self.OKGREEN = '\033[92m'self.ERROR = '\033[31m'self.WARNING = '\033[93m'self.FAIL = '\033[91m'self.ENDC = '\033[0m'self.BOLD = '\033[1m'self.UNDERLINE = '\033[4m'def yellow(self, s: str):print(self.WARNING + s + self.ENDC)def blue(self, s: str):print(self.OKBLUE + s + self.ENDC)def green(self, s: str):print(self.OKGREEN + s + self.ENDC)def red(self, s: str):print(self.ERROR + s + self.ENDC)
爬蟲類
這個案例啓用5個綫程
構造方法
bprint = BCOLOR()
threadNum = 5 # 綫程數量
totalNum = 0class Spider:def __init__(self):self.urlQueue = queue.Queue()self.proxies = self.getProxies()
urlQueue = queue.Queue() 建一個隊列來保存需要爬取的所有ur,每個綫程都有這裏取一條,利用了隊列先進先出的特點l
self.proxies = self.getProxies() 得到代理的ip,不用代理也行但是速度快不用代理容易被封ip,但是使用代理需謹慎
獲取代理
非必須操作,看個人選擇
def getProxies(self):pUrl = 'https://api.asdas.com/ip/get' # 這個url是假的,使用自己買的代理ip接口params = {'appKey': '','appSecret': ''}while True:res = requests.get(pUrl, headers=self.getHeaders(), params=params).json()code = res.get('code')if code == 200:ip = res['data'][0].get('ip')port = res['data'][0].get('port')proxies = {"http": f"http://{ip}:{port}","https": f"https://{ip}:{port}",}print(proxies)return proxies
也可以采用自己去爬一些免費代理建立代理詞,但是免費不太穩定可能隨時就失效了
設置headers
def getHeaders(self):user_agent_list = ["Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/61.0","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)","Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",]headers = {'User-Agent': random.choice(user_agent_list),}return headers
其實隨便設一個ua就好了沒必要隨機拿一個,有ua就行了。現在可能都不咋檢查ua了,畢竟服務器檢測同一個ip發過來ua能有多不一樣。
如果不設置ua的話,原來的ua是python-requests/2.28.1,極有可能遇到反爬,可能會報錯,狀態碼403或者418,418就是那個我是一個茶壺,有興趣可以去搜一下梗。
這裏大概説一下:
这个代码是在1998年作为传统的IETF April Fools‘ jokes被定义的在RFC2324,超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现。RFC指定了这个代码应该是由茶罐返回给速溶咖啡。
这当然是一个玩笑,甚至连这个RFC的内容都是从歌词里引用过来的。原文如下:
The HTCPCP server is a teapot; the resulting entity body may be short and stout.
翻译成中文大概是,服务器是个茶壶,返回实体短又粗。short and stout 是一句歌词。
“我是一个茶壶,我啥也不知道,你别找我。”
“我是一个茶壶,我啥也不知道,你找咖啡壶去。”
“我是一个茶壶,我不是咖啡壶,不能当咖啡壶用。”
“我是一个茶壶,我不是咖啡壶,禁止当咖啡壶用。”
“我是一个茶壶,我不是咖啡壶,咖啡煮坏了你自己负责。”
“我是一个茶壶,暂时还不能当咖啡壶用。”
“我是一个茶壶,虽然也能煮咖啡,但由于某些原因暂时不能煮咖啡。”
可以看一下這個寫的,我是一個茶壺
獲取新session
def new_session(self):session = requests.session()url = 'https://www.scopus.com/'while True:try:session.get(url=url, headers=self.getHeaders(), proxies=self.proxies, timeout=(3.5, 7))bprint.yellow(s='new session')return sessionexcept:self.proxies = self.getProxies()bprint.yellow(s='network error')
獲取一個新的session,不管出現什麽異常就換代理,做的比較水,你也可以寫的細緻點
獲取源代碼
def get_html(self, session, url, flag):print(url)print('get_html')while True:try:res = session.get(url=url, headers=self.getHeaders(), proxies=self.proxies, timeout=(3.5, 7)).text# print(res)if flag in res:return session, ressession = self.new_session()bprint.red(s='error response')except:self.proxies = self.getProxies()bprint.yellow(s='network timeout')
這裏的flag 就是頁面源代碼的一段話,如果這段話在res裏證明確實爬到頁面源代碼了那就返回頁面頁面源代碼。這裏寫的簡單點就是不管什麽情況沒爬到就換一個session然後出異常就換代理
解析網頁
def analyze_out(self, session, res, dic: dict) -> list:"""bs解析html:param html::param excelData::return:"""print('start parse')bs = BeautifulSoup(res, "html.parser") # 生成靓汤对象解析tbody = bs.find_all(class_="searchArea") # 搜索区域data_list = []for tr in tbody:print(f'正在检查第 {tbody.index(tr) + 1} 条')# 這裏就是解析網頁,可以自己去補充,下面給一些示例提示....................th_input = tr.find('th').find('input')name = th_input.get('name')dic['name'] = nameflag = '<span class="titleText">'in_url = f'https://www.百度.com/in/' # 這裏也是假url需要換你自己的,這個就是有一個情況比如頁面内還嵌套一個鏈接你需要去解析子網頁session, res = self.get_html(session=session, url=in_url, flag=flag)dic = self.analyze_ins(res=res, dic=dic) # 這裏就是解析子頁面# print(dic)data_list.append(dic)print('over parse')return data_list
這個案例是拿BeautifulSoup解析頁面舉例,也可以使用xpath,re等
解析子頁面
def analyze_ins(self, res, dic: dict) -> dict:""" 解析子頁面 """bs = BeautifulSoup(res, "html.parser") # 生成靓汤对象解析title = bs.find(class_="titleText").text # 搜索区域dic['title '] = ''.join(title )return dic
這裏使用 ‘’.join(title ) 主要是爲了防止爬不到報錯,整個代碼我很少用try捕獲異常
保存數據
def saveMysql(self, dic: dict):這裏自己根據情況自己補充,我采用的是保存數據庫,想要保存csv還是什麽格式就導入相應的包
綫程任務
def thread_work(self, num):global totalNumprint('start')session = self.new_session()while True:if self.urlQueue.empty():breakurl = self.urlQueue.get()dic = {'name': '','name': '','name': '',.....需要爬取的數據,這裏以一個字典的方式接收,先讓每一個建設爲空字符串免得後面報錯}flag = '<title>百度一下,你就知道</title>' # 這個flag根據情況自己設置,這裏以百度爲例,源代碼裏一點有這句話,沒有這句話證明是被反爬收到一個js還是假的html之類,總之不是我們要的源代碼session, res = self.get_html(session=session, url=url, flag=flag)dics = self.analyze_out(session=session, res=res, dic=dic)with threading.Lock():''' 存数据库 '''for dic in dics:self.saveMysql(dic=dic)totalNum += 1bprint.green(s=f'thread: {num} finishNum: {totalNum} data:{dic}')
設一個死循環,如果隊列裏還有需要爬的url就繼續分配給綫程去爬取,如果隊列空了就結束
- urlQueue.empty(),判斷隊列是否爲空,返回布爾值
- urlQueue.get() 在隊列裏取一個url,先進先出
得到url
def getExcelData(self):print('start readExcel')raw_data = pd.read_excel(self.file, header=0, keep_default_na=False) # header=0表示第一行是表头,就自动去除了raw_list = raw_data.values.tolist()url_list = []for raw in raw_list:name = raw[1]url = f'https://www.百度.com/search/name={LastName}' # 這裏依舊是一個假url,就是提示一下怎麽構建url,根據個人情況修改url_list.append(url)print('over readExcel')return url_list
這裏因爲是爬取excel裏的地址所以才這樣,根據自己情況構建url隊列即可
這裏用的是pandas來讀取excel,也可以使用openpyxl,xlwt或者csv等等庫來讀寫excel
pd.read_excel(self.file, header=0, keep_default_na=False)
- header=0表示第一行是表头,就自动去除了;
- keep_default_na=False:假設表格中有一些空行還是空格什麽的不是設置這個則是為nal值,設置了這個為空字符串(即:‘’)
raw_data.values.tolist():將DataFrame類型轉換為list列表類型
啓動多綫程爬蟲
def run(self):start = time.perf_counter() # 記錄開始時間global threadNumbprint.green(s=f'program starts with {threadNum} threads')url_list = self.getExcelData() # 獲取url列表for url in url_list:self.urlQueue.put(url) # 將列表裏的url加入隊列threadList = []for i in range(threadNum):t = threading.Thread(target=self.thread_work, args=(i + 1,))threadList.append(t)t.start()for t in threadList:t.join()bprint.green(s='program finishs')end = time.perf_counter()print('Running time: %s Seconds' % (end - start)) # 打印執行時間
調用這個方法運行這個爬蟲類,具體多綫程的使用可以看我另一篇文章:demo
總結
這只是寫了一個大概的框架沒有具體實現一個案例,把單綫程爬蟲的邏輯在這裏面修改就可以啓用多綫程,理論上多綫程比單綫程快了幾十倍不止,因爲少了阻塞的問題有點像操作系統的流水綫。還有之所以這個案例不用多進程就是因爲多進程會變得亂序和消耗資源,多綫程至少總體沒那麽亂序。
相关文章:

多綫程之python爬蟲構建
目录多綫程定義簡介原理优点缺点优势代碼框架實現導包打印類爬蟲類構造方法獲取代理設置headers獲取新session獲取源代碼解析網頁解析子頁面保存數據綫程任務得到url啓動多綫程爬蟲總結多綫程 以下定義來自百度百科,看看就好沒仔細寫 定義 多线程(mul…...

【干货】Redis在Java开发中的基本使用和巧妙用法
Redis是一款高性能的内存数据结构存储系统,能够支持多种数据结构类型,如字符串、哈希、列表、集合、有序集合等,也能够支持高级功能,如事务、发布/订阅、Lua脚本等,具有高可用性、高并发性和可扩展性的优点。在Java开发…...

历时半年,我终于阿里上岸了,附面经和Java非科班学习心得
个人经历 本科双非化学,跨考了电子硕士,研究生依然双非。无互联网实习,无比赛无论文。(研究生研究方向是车辆电子和楼宇自动化,有自动化和高校实训讲师相关的实习经历) 21年11开始学Java准备秋招。 阿里上…...

ArkUI实战,自定义饼状图组件PieChart
本节笔者带领读者实现一个饼状图 PieChart 组件,该组件是根据笔者之前封装的 MiniCanvas 实现的, PieChart 的最终演示效果如下图所示: 饼状图实现的拆分 根据上图的样式效果,实现一个饼状图,实质就是绘制一个个的实…...
工作实战之系统交互api调用认证设计
目录 前言 一、黄金段位接口交互 二、钻石段位接口交互设计 1.接口文档定义 2.工具类以及demo提供 a.调用方部分代码 b.被调用方 三.星耀段位接口访问设计 1.在钻石段位的基础上,进行sdk的封装 a.maven引入 b.sdk包含工具类 四.王者段位接口访问设计 1.开发详情 2.…...

学习系统编程No.5【虚拟地址空间】
引言: 北京时间:2023/2/22,离补考期末考试还有5天,不慌,刚午觉睡醒,闹钟2点20,拖到2点50,是近以来,唯一一次有一种睡不醒的感觉,但是现在却没有精神,因为听了…...
)
Linux常用指令(未完待续。。。)
* basename:只留下路径的“最后一部分” X、文件夹&目录操作 复制 :cp /xxx /xxx - a 该选项通常在拷贝目录时使用。它保留链接、文件属性,并递归地拷贝目录,其作用等于dpR选项的组合; - d 拷贝时保留链接&#…...

用D写裸机
原文 用D编写裸机RISC-V应用 这篇文章展示,如何用D编写,目标为RISC-VQEMU模拟器的程序裸机"你好".项目 为什么是D? 我最近一直在用C编写裸机代码,我有点对C缺乏特征感到沮丧.D引入了叫betterC的模式(基本上禁止了D运行时的所有语言功能).使得D裸机编程大致与C一…...

(二十五)、实现评论功能(5)【uniapp+uinicloud多用户社区博客实战项目(完整开发文档-从零到完整项目)】
1,实现二级回复的入库操作 1.1 两个子组件(comment-item和comment-frame)与父组件reply之间的属性传值 comment-item: props: {item: {type: Object,default () {return {}}}},comment-frame: props: {commentObj: {…...
【概念辨析】二维数组传参的几种可能性
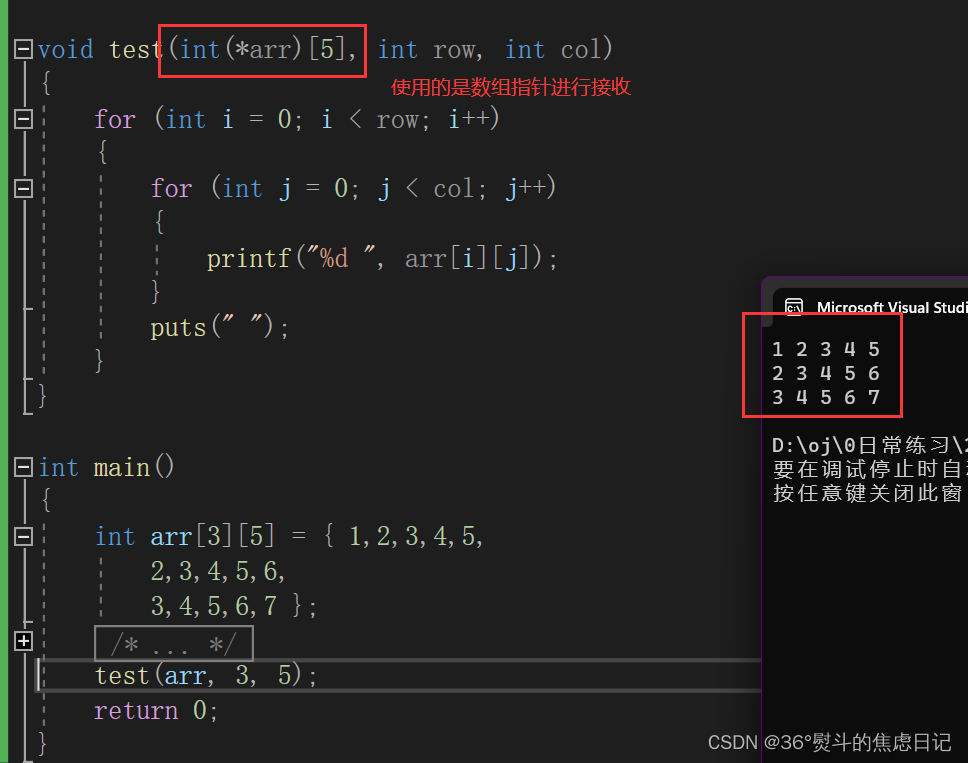
一、二维数组传参竟然不是用二级指针进行接收? 今天进行再一次的二级指针学习时,发现了一条以前没怎么注意过的知识点:二维数组进行传参只能用二维数组(不能省略列)进行接收或者是数组指针。 问题复现代码如下…...
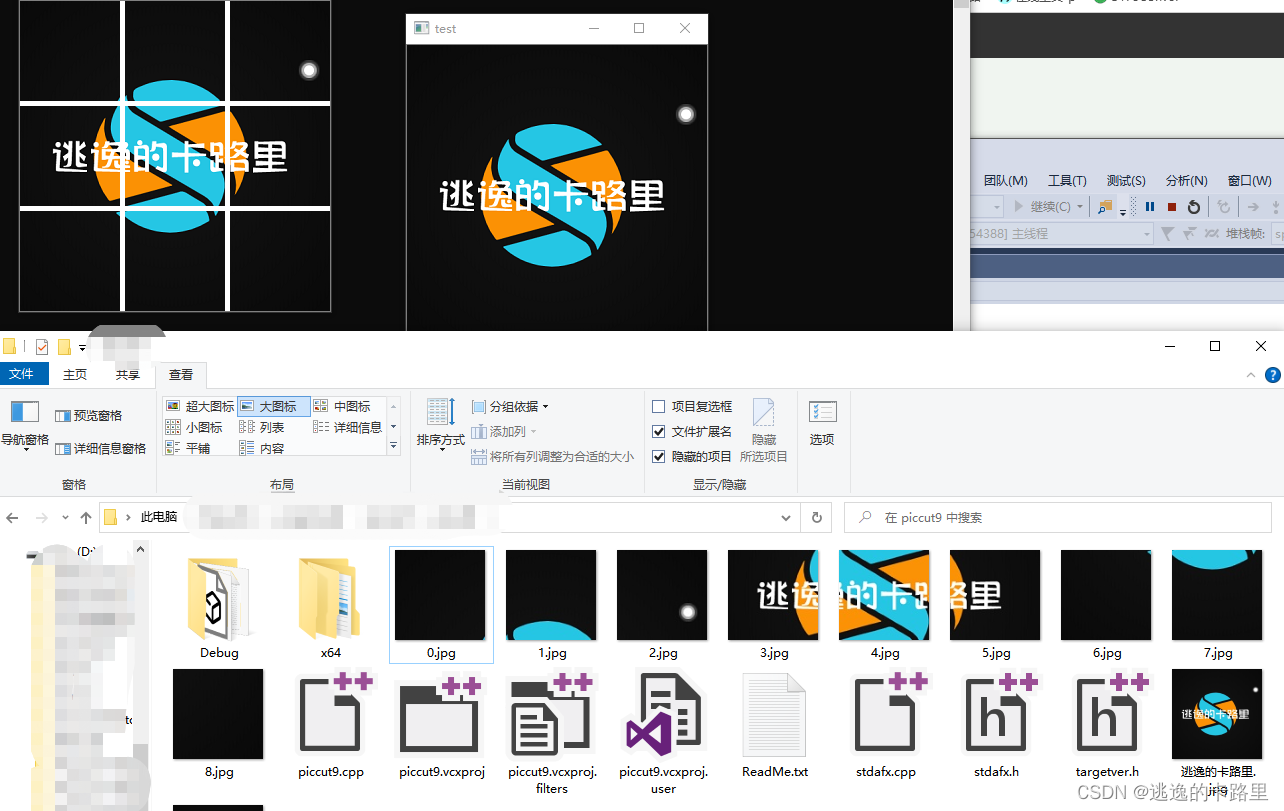
python和C++代码实现图片九宫格切图程序(附VS2015配置Opencv教程)
1、python代码实现图片分割成九宫格 需要包含的库,没有下载安装的,需要自己安装哦。 实现原理很简单,就是用PIL库不断画小区域,切下来存储成新的小图片。 假设每一个格子的宽和高分别是w、h,那么第row行(…...
【深度学习】优化器
1.什么是优化器 优化器是在深度学习的反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让目标函数不断逼近全局最小点。 2.优化器 2-1 BGD 批量梯度下降法,是梯度下…...
SpringBoot使用validator进行参数校验
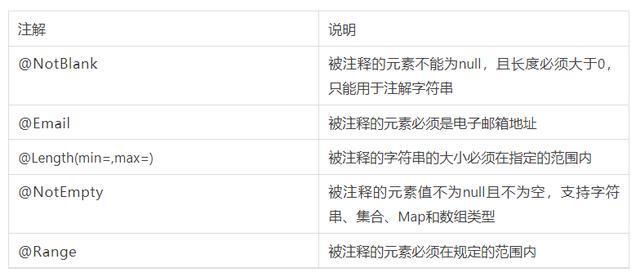
Validated、Valid和BindingResultBean Validation是Java定义的一套基于注解的数据校验规范,比如Null、NotNull、Pattern等,它们位于 javax.validation.constraints这个包下。hibernate validator是对这个规范的实现,并增加了一些其他校验注解…...
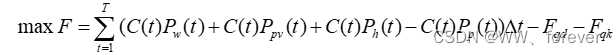
论文复现:风电、光伏与抽水蓄能电站互补调度运行(MATLAB-Yalmip全代码)
论文复现:风电、光伏与抽水蓄能电站互补调度运行(MATLAB-Yalmip全代码) 针对风电、光伏与抽水蓄能站互补运行的问题,已有大量通过启发式算法寻优的案例,但工程上更注重实用性和普适性。Yalmip工具箱则是一种基于MATLAB平台的优化软件工具箱,被广泛应用于工程界优化问题和…...
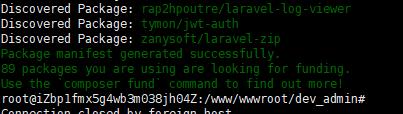
FastCGI sent in stderr: "PHP message: PHP Fatal error
服务器php7.2卸载安装7.4之后,打开网站一直无法访问,查看nginx错误日志发现一直报这个错误:2023/02/23 11:12:55 [error] 4735#0: *21 FastCGI sent in stderr: "PHP message: PHP Fatal error: Uncaught ReflectionException: Class translator does not exist in …...
)
【数字IC基础】跨时钟域(CDC,Clock Domain Crossing)
文章目录 一、什么是跨时钟域?二、跨时钟域传输的问题?2、1 亚稳态(单bit:两级D触发器(双DFF))2、2 数据收敛(多bit亚稳态)(格雷码编码、握手协议、异步FIFO、DMUX)2、3 多路扇出:(先同步后扇出)2、4 数据丢失(延长输入数据信号):类似脉冲展宽2、5 异步复位(…...

UNI-APP学习
uni-app的基本使用 uni-app介绍 官方网页 uni-app 是一个使用 Vue.js 开发所有前端应用的框架,开发者编写一套代码,可发布到iOS、Android、H5、以及各种小程序(微信/支付宝/百度/头条/QQ/钉钉)等多个平台。 即使不跨端…...

编译原理【运行时环境】—什么是活动记录、 活动记录与汇编代码的关系
系列文章戳这里👇 什么是上下文无关文法、最左推导和最右推导如何判断二义文法及消除文法二义性何时需要消除左递归什么是句柄、什么是自上而下、自下而上分析什么是LL(1)、LR(0)、LR(1)文法、LR分析表LR(0)、SLR(1)、LR(1)、LALR(1)文法之间的关系编译原理第三章习…...
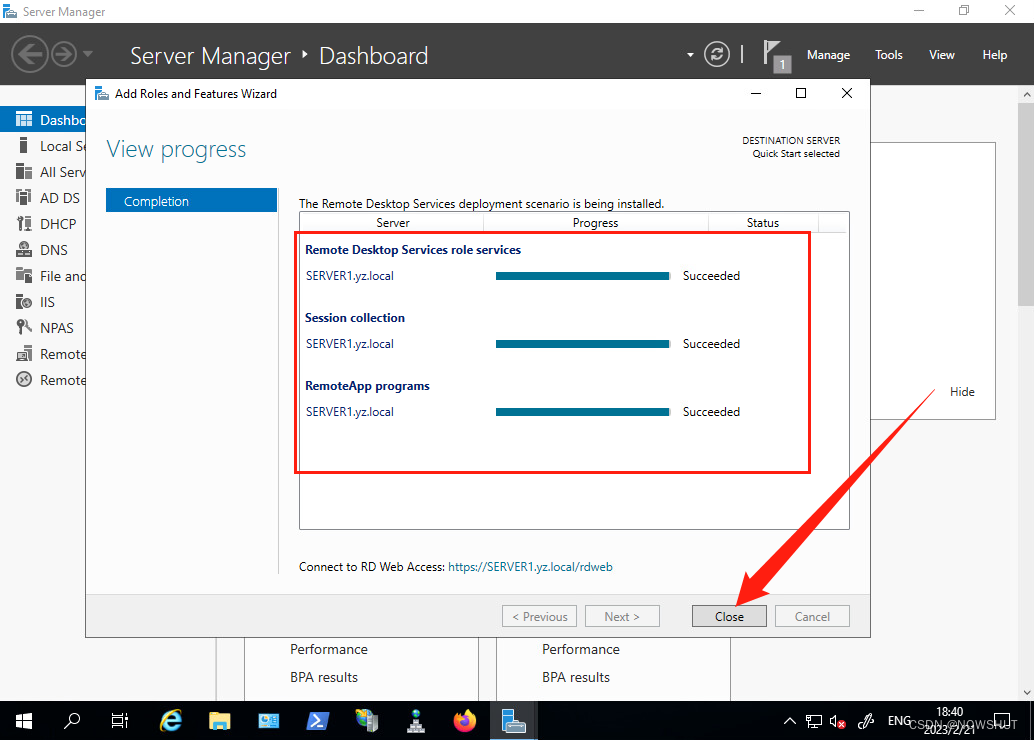
【Windows Server 2019】发布服务器 | 远程桌面服务的安装与配置 Ⅰ——理论,实验拓扑和安装基于RemoteAPP的RDS
目录1. 理论1.1 什么是远程桌面服务2. 实验拓扑2.1 拓扑说明3. 安装基于RemoteAPP的RDS1. 理论 1.1 什么是远程桌面服务 远程桌面服务 (RDS) 是一个卓越的平台,可以生成虚拟化解决方案来满足每个最终客户的需求,包括交付独立的虚拟化应用程序、提供安全…...
Bootstrap入门到精通(最全最详细)
文章目录前言一、Bootstrap是什么?二、Bootstrap安装方式一:将压缩包下载到本地引入使用方式二:使用Bootstrap官方cdn二.Bootstrap容器下面是屏幕宽度在不同大小时不同容器的显示状态三.Bootstrap栅格系统bootstrap网格系统有以下六个类网格系…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...