深度学习-Python调用ONNX模型
目录
ONNX模型使用流程
获取ONNX模型方法
使用ONNX模型
手动编写ONNX模型
Python调用ONNX模型
常见错误
错误raise ValueError...:
错误:Load model model.onnx failed
错误:'CUDAExecutionProvider' is not in available provider
错误:ONNXRuntimeError
错误:'CUDAExecutionProvider' is not in available provider
ONNX模型使用流程
ONNX(Open Neural Network Exchange)是一种开放的、跨平台的深度学习模型格式和编译器,可以帮助用户在不同的深度学习框架中转换和部署模型。下面介绍ONNX如何使用的流程:
-
导出模型:在训练好深度学习模型后,通过ONNX的支持的框架,比如PyTorch、TensorFlow等将模型导出为ONNX格式。
-
加载模型:使用ONNX的支持库,比如ONNX Runtime,加载ONNX文件格式的模型。
-
部署模型:通过ONNX Runtime在不同的硬件设备上运行模型,支持常见的CPU、GPU、FPGA等。
-
进行推理:将输入数据加载到模型中,进行推理或分类任务,输出结果。
ONNX还有其他的特点,比如具有可扩展性、良好的跨平台支持、对多种硬件设备的支持等。因此,ONNX是一种强大的深度学习模型转换和部署工具,可以大大加速深度学习模型的开发和部署过程。
获取ONNX模型方法
获取ONNX模型有以下几种方法:
1. 使用ONNX标准工具导出已有的深度学习模型
许多深度学习框架都支持直接导出ONNX格式的模型,如PyTorch、TensorFlow、Keras等。可参考相应框架的文档,使用ONNX标准工具将模型导出为ONNX格式。
2. 使用第三方工具转换
也可以使用一些第三方工具将已有的模型进行转换,例如mmcv中的convert_to_onnx.py工具。
3. 手动编写ONNX模型
如果没有原始模型或无法导出,则需要手动编写ONNX模型。ONNX模型由计算图和模型参数组成。计算图用于定义模型结构和计算流程,可以使用ONNX工具或第三方工具进行编写,也可以手动编写。模型参数用于定义模型权重,可以使用Python脚本或其他工具进行生成或导入。
总之,获取ONNX模型的方法取决于具体情况,不同场景下合适的方法也会有所不同。
使用ONNX模型
手动编写ONNX模型
手动编写ONNX模型需要了解ONNX模型的结构和语法,以及具体深度学习框架的计算图结构和权重参数格式。
以下是一个手动编写的简单ONNX模型例子,用于对一维张量进行线性变换和ReLU激活:
import onnx
import numpy as np
from onnx import numpy_helper
from onnx import helper# 定义输入张量
input_tensor = helper.make_tensor_value_info('input', onnx.TensorProto.FLOAT, [1, 10])# 定义权重张量
weight = np.random.rand(10, 5).astype(np.float32)
weight_initializer = numpy_helper.from_array(weight, 'weight')# 定义偏置张量
bias = np.random.rand(5).astype(np.float32)
bias_initializer = numpy_helper.from_array(bias, 'bias')# 定义节点1:矩阵乘法
matmul_node = helper.make_node('MatMul',inputs=['input', 'weight'],outputs=['matmul_output']
)# 定义节点2:加法
add_node = helper.make_node('Add',inputs=['matmul_output', 'bias'],outputs=['add_output']
)# 定义节点3:ReLU激活
relu_node = helper.make_node('Relu',inputs=['add_output'],outputs=['output']
)# 定义计算图
graph_def = helper.make_graph([matmul_node, add_node, relu_node],'test-model',[input_tensor],[helper.make_tensor_value_info('output', onnx.TensorProto.FLOAT, [1, 5])],initializer=[weight_initializer, bias_initializer]
)# 定义模型
model_def = helper.make_model(graph_def,producer_name='my-model',opset_imports=[helper.make_opsetid('', 12)]
)# 保存模型
onnx.save(model_def, 'test-model.onnx')
此例中,通过手动定义输入张量、权重张量、偏置张量和节点(矩阵乘法、加法、ReLU激活)构建了一个简单的计算图,并通过ONNX工具生成了ONNX格式的模型文件test-model.onnx。可以使用ONNX工具或特定框架工具加载此模型进行推理。
Python调用ONNX模型
下面以使用Python调用ONNX模型为例子,具体步骤如下:
- 安装ONNX Runtime库
- 加载ONNX模型
- 准备输入数据
- 进行推理
import onnxruntime
import numpy as np
import onnxruntime as ortmodel_path = 'test-model.onnx'providers = ['CPUExecutionProvider']
ort_session = ort.InferenceSession(model_path, providers=providers)# ort_session = onnxruntime.InferenceSession('test-model.onnx', providers=['CPUExecutionProvider', 'CUDAExecutionProvider'])batch_size = 1
input_size = 10 # set input size to 10input_data = np.random.rand(batch_size, input_size).astype(np.float32)
input_data = input_data.reshape(batch_size, input_size) # reshape input_data to (batch_size, 10)# batch_size = 1
# input_size = 784 # assuming you have a model that takes 784 inputs
#
# input_data = np.random.rand(batch_size, input_size).astype(np.float32)output = ort_session.run(None, {'input': input_data})[0]print(output)执行结果:
[[2.5079055 3.4431007 2.5739892 2.332235 1.9329181]]
在这个例子中,我们使用Python调用ONNX Runtime库来加载ONNX模型,并使用随机生成的输入数据进行推理。在ONNX模型的输入中,我们以字典的形式传递输入数据。推理的结果是一个输出数组,这是由ONNX模型定义的。
这就是Python调用深度学习模型ONNX的基本步骤,可以根据具体的模型和任务,在此基础上进行调整和扩展。
常见错误
错误raise ValueError...:
raise ValueError(
ValueError: This ORT build has ['AzureExecutionProvider', 'CPUExecutionProvider'] enabled. Since ORT 1.9, you are required to explicitly set the providers parameter when instantiating InferenceSession. For example, onnxruntime.InferenceSession(..., providers=['AzureExecutionProvider', 'CPUExecutionProvider'], ...)解决方法
该错误是由于在ORT 1.9版本中,调用InferenceSession时必须显式地设置providers参数来指定要使用的执行提供程序,否则会引发此错误。
要解决此错误,您需要在调用InferenceSession时设置providers参数。例如,如果您要使用CPUExecutionProvider和CUDAExecutionProvider,请按以下方式调用InferenceSession:
import onnxruntimesession = onnxruntime.InferenceSession('model.onnx', providers=['CPUExecutionProvider', 'CUDAExecutionProvider'])
在这里,我们将providers参数设置为包含CPUExecutionProvider和CUDAExecutionProvider的列表。根据您的需求,您可以选择其他ExecutionProvider。
请注意,如果您在调用InferenceSession时不设置providers参数,将会发生上述错误,即使您在构建模型时已经定义了ExecutionProvider。
错误:Load model model.onnx failed
onnxruntime.capi.onnxruntime_pybind11_state.NoSuchFile: [ONNXRuntimeError] : 3 : NO_SUCHFILE : Load model from model.onnx failed:Load model model.onnx failed. File doesn't exist
该错误提示 ONNXRuntimeError:3:NO_SUCHFILE,是由于onnxruntime无法在指定路径中找到模型文件model.onnx,因此无法加载模型。
要解决此错误,您需要检查以下几点:
-
检查您提供的文件路径是否正确。
请确保您提供的文件路径是正确的,并且包含文件名和后缀名,例如'model.onnx'。
-
检查文件名是否正确。
请确保文件名拼写正确,并且大小写正确。
-
检查文件是否存在。
请确保指定路径中包含该文件。您可以通过在Python中运行以下代码进行检查:
import os.pathmodel_path = 'model.onnx' exists = os.path.isfile(model_path) if not exists:print('Model file not found:', model_path) -
检查文件路径是否有权限访问。
如果您使用的是Windows,则可能需要以管理员身份运行命令提示符或PyCharm。如果您使用的是Linux或macOS,则需要检查文件路径是否有正确的权限。
通过以上步骤排查未能加载模型的原因,并进行相应的修正即可解决此错误。
错误:'CUDAExecutionProvider' is not in available provider
UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names.Available providers: 'AzureExecutionProvider, CPUExecutionProvider'warnings.warn(
Traceback (most recent call last):File "D:\code\AutoTest\common\onnx\testOnnx.py", line 13, in <module>input_data = np.random.rand(batch_size, input_size).astype(np.float32)^^^^^^^^^^
NameError: name 'batch_size' is not defined
解决方法
此错误具有两个独立的部分:
-
UserWarning:Specified provider 'CUDAExecutionProvider' is not in available provider names。
这意味着您正在尝试使用CUDAExecutionProvider,但是您的环境中可能没有安装或可用CUDAExecutionProvider。您可以尝试更改提供程序使用CPUExecutionProvider或AzureExecutionProvider。
在您的代码中,您可以这样设置提供程序:
import onnxruntime as rtproviders = ['CPUExecutionProvider'] # or ['AzureExecutionProvider'] session = rt.InferenceSession('model.onnx', providers) -
NameError:name 'batch_size' is not defined。
这意味着您在代码中使用了“batch_size”变量,但是在代码的上下文中未定义该变量。请确保您已经定义了batch_size变量并赋予其正确的值。
例如,您可以在代码中设置batch_size变量,如下所示:
import numpy as npbatch_size = 1 input_size = 784 # assuming you have a model that takes 784 inputsinput_data = np.random.rand(batch_size, input_size).astype(np.float32)
通过以上步骤排查未定义变量和可用提供程序的问题,并进行相应的修正即可解决此错误。
错误:ONNXRuntimeError
in runreturn self._sess.run(output_names, input_feed, run_options)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: input for the following indicesindex: 1 Got: 784 Expected: 10Please fix either the inputs or the model.
解决方法
此错误涉及到两个问题:
- UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names。 Available providers: 'AzureExecutionProvider, CPUExecutionProvider'。
这个问题在前一个错误中已经解释过了。请参考之前的解决方法。
- InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: input for the following indices index: 1 Got: 784 Expected: 10 Please fix either the inputs or the model。
这个错误意味着您提供的输入张量形状不正确,或者模型中期望的输入形状与提供的输入形状不匹配。
在您给出的代码中,您正在尝试将一个形状为(batch_size, 784)的输入张量提供给模型,但是模型期望输入张量的形状为(batch_size, 10)。 您需要更改输入张量的形状,以便它符合模型的输入形状。
例如,如果您的模型期望的输入形状是(batch_size, 10),您可以将示例代码中的input_size变量设置为10。 然后您可以在生成随机输入数据时,将生成的随机数重塑为(batch_size, 10)形状的张量。
具体而言,您可以在代码中添加以下行,将input_size变量设置为10,并将input_data变量重塑为(batch_size, 10)张量:
import numpy as npbatch_size = 1
input_size = 10 # set input size to 10input_data = np.random.rand(batch_size, input_size).astype(np.float32)
input_data = input_data.reshape(batch_size, input_size) # reshape input_data to (batch_size, 10)
这样,您就可以使用正确形状的输入张量来运行模型,避免了此错误。
错误:'CUDAExecutionProvider' is not in available provider
UserWarning: Specified provider 'CUDAExecutionProvider' is not in available provider names.Available providers: 'AzureExecutionProvider, CPUExecutionProvider'warnings.warn(
解决方法
这个警告通常意味着您指定了一个不存在的执行提供程序。在使用onnxruntime.InferenceSession()创建会话对象时,您可以指定要使用的执行提供程序列表。如果指定的执行提供程序不在可用提供程序列表中,则会出现上述警告。
如何解决这个问题取决于您的目标。如果您确信指定的执行提供程序可用,则可以无视警告。否则,可以从可用的提供程序列表中选择一个或多个提供程序,并在创建会话时将其作为提供程序参数传递。例如:
import onnxruntime as ortproviders = ['CPUExecutionProvider']
ort_session = ort.InferenceSession(model_path, providers=providers)
在这个示例中,我们将CPUExecutionProvider作为提供程序传递给onnxruntime.InferenceSession()。如果这个提供程序在可用的提供程序列表中,则不会出现警告。
相关文章:

深度学习-Python调用ONNX模型
目录 ONNX模型使用流程 获取ONNX模型方法 使用ONNX模型 手动编写ONNX模型 Python调用ONNX模型 常见错误 错误raise ValueError...: 错误:Load model model.onnx failed 错误:CUDAExecutionProvider is not in available provider 错…...

[2023.09.24]: 今天差点又交白卷
今天周日,搞定了家里装修的一件事情,周末的事特别多,总算在10点的时候,解决了昨天那个输入焦点设置失败的问题。 在探索Rust编写基于web_sys的WebAssembly编辑器:挑战输入光标定位的实践中,我们总结了设置光…...

css,环形
思路: 1.先利用conic-gradient属性画一个圆,然后再叠加 效果图 <template><div class"ring"><div class"content"><slot></slot></div></div> </template> <script> import …...

php食堂点餐系统hsg5815ABA2程序-计算机毕业设计源码+数据库+lw文档+系统+部署
php食堂点餐系统hsg5815ABA2程序-(毕业设计毕设项目源代码课程设计程序设计指导xz2023) php食堂点餐系统hsg5815ABA2程序-计算机毕业设计源码数据库lw文档系统部署...
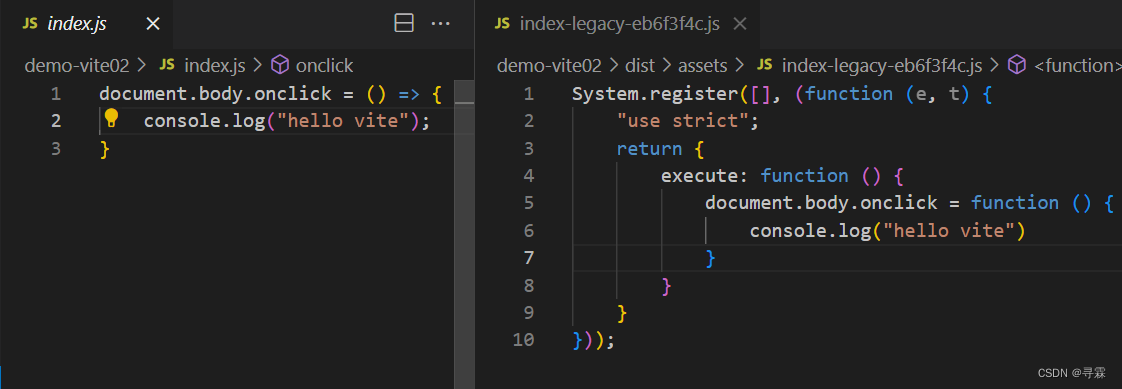
Vite打包时使用plugin解决浏览器兼容问题
一、安装Vite插件 在终端输入如下命令: npm add -D vitejs/plugin-legacy 二、配置config文件 在项目目录下创建vite.config.js文件夹,配置如下代码: import { defineConfig } from "vite"; import legacy from "vitejs/pl…...

java Excel 自用开发模板
下载导出 import com.hpay.admin.api.vo.Message; import com.hpay.admin.dubbo.IConfigDubboService; import com.hpay.admin.dubbo.IFileExportLogDubboService; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang.StringUtils; import org.apache.poi.hss…...

34.CSS魔线图标的悬停效果
效果 源码 index.html <!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Icon Fill Hover Effects</title> <link rel="stylesheet" h…...

Django — 会话
目录 一、Cookie1、介绍2、作用3、工作原理4、结构5、用途6、设置7、获取 二、Session1、介绍2、作用3、工作原理3、类型4、用途5、设置6、获取7、清空信息 三、Cookie 和 Session 的区别1、存储位置2、安全性3、数据大小4、跨页面共享5、生命周期6、实现机制7、适用场景 四、P…...
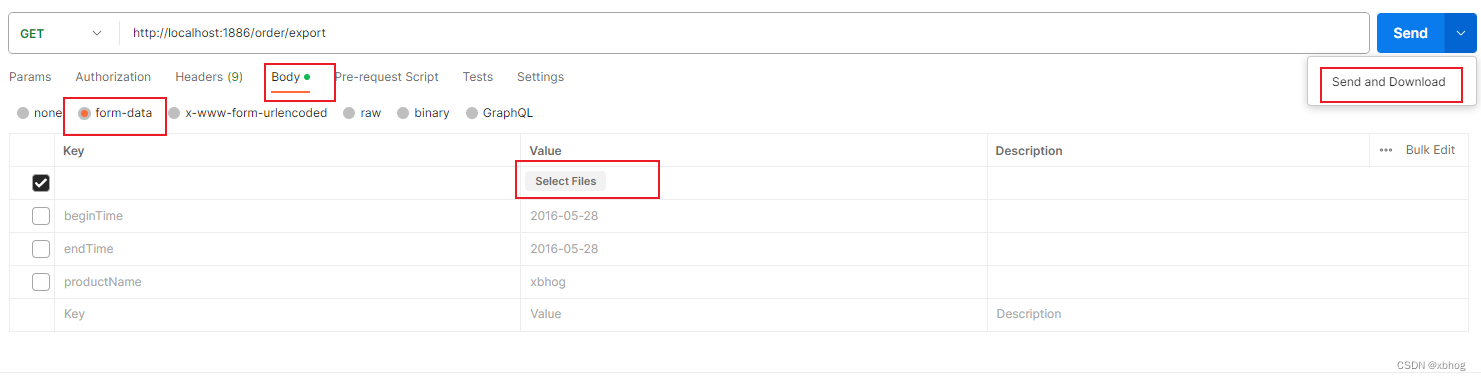
SpringBoot集成easypoi实现execl导出
<!--easypoi依赖,excel导入导出--><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-spring-boot-starter</artifactId><version>4.4.0</version></dependency>通过Exce注解设置标头名字和单…...

第9章 【MySQL】InnoDB的表空间
表空间 是一个抽象的概念,对于系统表空间来说,对应着文件系统中一个或多个实际文件;对于每个独立表空间来说,对应着文件系统中一个名为 表名.ibd 的实际文件。大家可以把表空间想象成被切分为许许多多个 页 的池子,当我…...

工作、生活常用免费api接口大全
手机号码归属地:提供三大运营商的手机号码归属地查询。全国快递物流查询:1.提供包括申通、顺丰、圆通、韵达、中通、汇通等600快递公司在内的快递物流单号查询。2.与官网实时同步更新。3.自动识别快递公司。IP归属地-IPv4区县级:根据IP地址查…...

寻找单身狗
在一个数组中仅出现一次,其他数均出现两次,这个出现一次的数就被称为“单身狗“。 一.一个单身狗 我们知道异或运算操作符 ^ ,它的特点是对应二进制位相同为 0,相异为 1。 由此我们容易知道两个相同的数,进行异或运算得到的结果…...
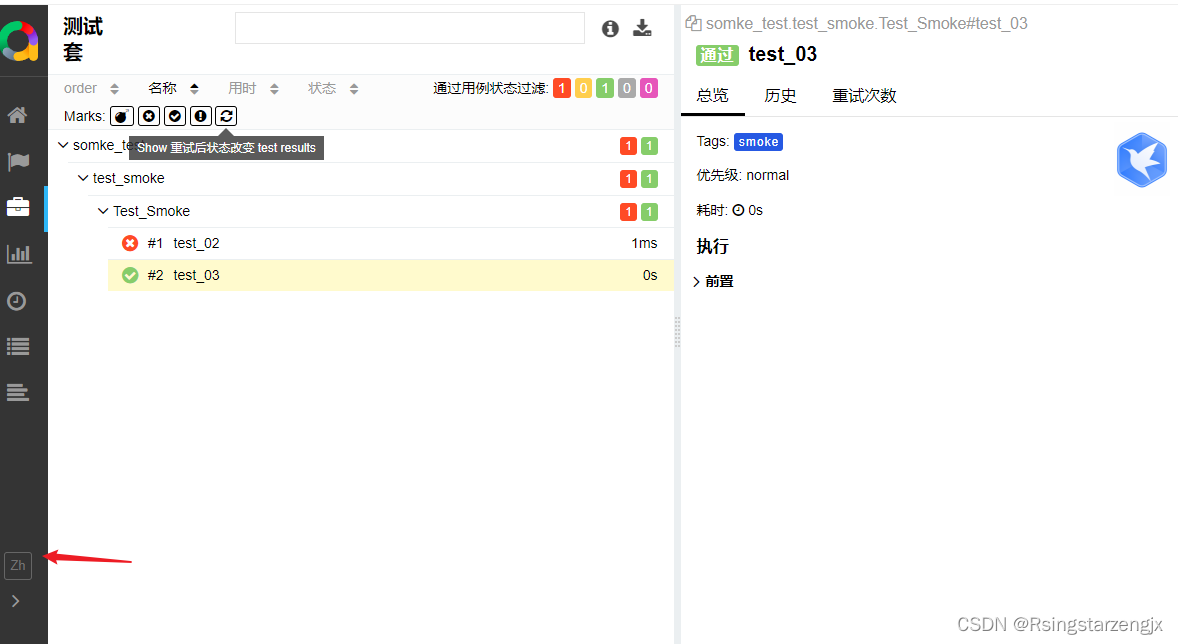
【pytest】 allure 生成报告
1. 下载地址 官方文档; Allure Framework 参考文档: 最全的PytestAllure使用教程,建议收藏 - 知乎 https://github.com/allure-framework 1.2安装Python依赖 windows:pip install allure-pytest 2. 脚本 用例 import pytest class …...

动态链接库搜索顺序
动态链接库搜索顺序 同一动态链接库 (DLL) 的多个版本通常存在于操作系统 (OS) 内的不同文件系统位置。 可以通过指定完整路径来控制从中加载任何给定 DLL 的特定位置。 但是,如果不使用该方法,则系统会在加载时搜索 DLL,如本主题中所述。 DL…...

【CAN、LIN通信的区分】
CAN和LIN是两种不同的通信协议,用于不同的应用场景。CAN(Controller Area Network)是一种高速、可靠、多节点的串行通信协议,主要用于汽车电子领域的高速数据传输和控制;而LIN(Local Interconnect Network&…...
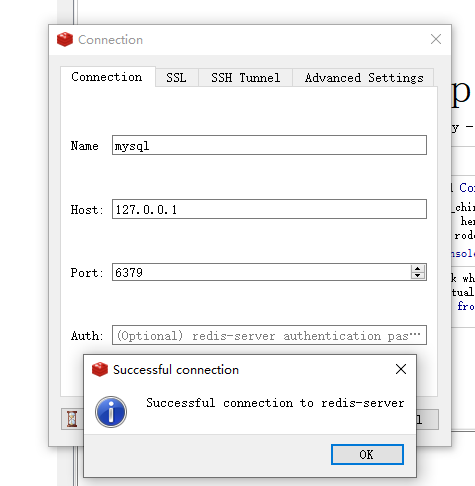
Redis环境配置
【Redis解压即可】链接:https://pan.baidu.com/s/1y4xVLF8-8PI8qrczbxde9w?pwd0122 提取码:0122 【Redis桌面工具】 链接:https://pan.baidu.com/s/1IlsUy9sMfh95dQPeeM_1Qg?pwd0122 提取码:0122 Redis安装步骤 1.先打开Redis…...
-采用std::vector对体对象的质心进行排序)
UG NX二次开发(C++)-采用std::vector对体对象的质心进行排序
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1、前言2、体对象质心结构体的构造3、采用NXOpen获取part中的所有体对象4、通过遍历体对象集合来实现std::vector<MyBody>的赋值5、对结构体排序6、调用的完整源代码7、生成dll并测试一、pan…...

一点思考|关于「引领性研究」的一点感悟
前言:调研过这么多方向之后,对研究方向的产生与发展具备了一些自己的感悟,尤其是在AI安全领域。私认为,所谓有价值、有意义的研究,就是指在现实社会中能够产生波澜、为国家和社会产生一定效益的研究。 举例来说&#x…...

什么是HTTP/2?它与HTTP/1.1相比有什么改进?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ HTTP/2 简介⭐ 主要的改进和特点⭐ 总结⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端…...

IDEA
快捷键 好用的快捷键,可以使写代码变得更加便捷~ IntelliJ IDEA具有许多有用的快捷键,这些快捷键可以帮助开发人员更快速、高效地编写和管理代码。以下是一些常用的IntelliJ IDEA快捷键,这些快捷键在Java开发中特别有用: 基本编辑…...

C# 异步编程在 AI 应用中的最佳实践
一、引言 AI 应用开发中的异步需求 在当今的人工智能应用开发领域,异步编程已经成为不可或缺的核心技术。当我们与 AI 大模型进行交互时,网络请求的延迟、流式响应的处理、并发调用多个模型——这些场景无不对程序的响应能力和吞吐量提出了极高要求。传统的同步编程模式在面…...

洛雪音乐音源:全网无损音乐一键获取的完整指南
洛雪音乐音源:全网无损音乐一键获取的完整指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为音乐平台会员费烦恼吗?想要免费畅听全网无损音乐吗?洛雪音…...

Qt for Android串口通信实战:usb-serial-for-android库的完整集成指南
Qt for Android串口通信实战:usb-serial-for-android库的完整集成指南 在工业控制、物联网设备调试等场景中,串口通信仍然是设备间可靠数据传输的首选方案。当我们需要在Android设备上通过Qt框架实现串口通信时,却发现Qt官方并未提供原生的A…...

PT站一键转载脚本:100+站点支持,彻底告别手动转载烦恼
PT站一键转载脚本:100站点支持,彻底告别手动转载烦恼 【免费下载链接】auto_feed_js PT站一键转载脚本 项目地址: https://gitcode.com/gh_mirrors/au/auto_feed_js PT(Private Tracker)社区的资源分享一直是核心文化&…...

终极QMC音频解密指南:3分钟解锁QQ音乐加密文件
终极QMC音频解密指南:3分钟解锁QQ音乐加密文件 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的加密音频无法在车载音响、智能音箱上播放而烦…...

终极鼠标键盘录制自动化工具:5分钟快速上手KeymouseGo完整指南
终极鼠标键盘录制自动化工具:5分钟快速上手KeymouseGo完整指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo …...
)
别再为YOLO模型分发发愁了!PyInstaller打包保姆级教程(含UI、权重文件处理)
YOLO模型分发终极方案:PyInstaller全流程实战指南 当你的YOLO模型在本地运行得风生水起时,如何让没有技术背景的同事或客户也能轻松使用?传统方法往往需要对方安装Python环境、配置依赖库,这个过程足以劝退90%的非技术人员。本文…...

汇川PLC编写,设备状态机的实现以及实际案例使用,针对设备的多种状态进行区分,有单独状态和叠加...
汇川PLC编写,设备状态机的实现以及实际案例使用,针对设备的多种状态进行区分,有单独状态和叠加态的实现方式在工业自动化项目里,设备状态机就像给机器装了个智能开关板。最近调试包装产线时发现,设备动不动就卡在"…...

OpenClaw语音控制:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实现声控自动化
OpenClaw语音控制:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实现声控自动化 1. 为什么需要语音控制自动化 去年冬天的一个深夜,我在赶项目文档时突然冒出一个想法:如果能像科幻电影里那样,用语音指挥电脑完成重复性工作…...
)
保姆级教程:用华为ENSP模拟器搞定AC+AP直连式组网(Web界面全流程)
华为ENSP模拟器实战:从零搭建ACAP无线网络的全流程解析 第一次打开华为ENSP模拟器时,面对密密麻麻的图标和复杂的网络拓扑,很多初学者都会感到无从下手。特别是当需要配置AC控制器和AP接入点组成的无线网络时,Web界面里那些专业术…...