R语言贝叶斯非参数模型:密度估计、非参数化随机效应META分析心肌梗死数据...
全文链接:http://tecdat.cn/?p=23785
最近,我们使用贝叶斯非参数(BNP)混合模型进行马尔科夫链蒙特卡洛(MCMC)推断(点击文末“阅读原文”获取完整代码数据)。
概述
相关视频
在这篇文章中,我们通过展示如何使用具有不同内核的非参数混合模型进行密度估计。在后面的文章中,我们将采用参数化的广义线性混合模型,并展示如何切换到非参数化的随机效应表示,避免了正态分布的随机效应假设。
使用Dirichlet Process Mixture模型进行基本密度估计
提供了通过Dirichlet过程混合(DPM)模型进行非参数密度估计的机制(Ferguson, 1974; Lo, 1984; Escobar, 1994; Escobar and West, 1995)。对于一个独立和相同分布的样本  ,该模型的形式为
,该模型的形式为
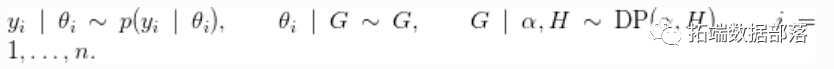
这个模型实现是灵活的,运行任意核的混合。 , 可以是共轭的,也可以是不共轭的(也是任意的)基度量
, 可以是共轭的,也可以是不共轭的(也是任意的)基度量 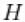 . 在共轭核/基数测量对的情况下,能够检测共轭的存在,并利用它来提高采样器的性能。
. 在共轭核/基数测量对的情况下,能够检测共轭的存在,并利用它来提高采样器的性能。
为了说明这些能力,我们考虑对R中提供的Faithful火山数据集的喷发间隔时间的概率密度函数进行估计。
data(faithful)
观测值  对应于数据框架的第二列,而
对应于数据框架的第二列,而  .
.
使用CRP表示法拟合高斯_location-scale_ 分布混合分布
模型说明
我们首先考虑用混合正态分布的_location-scale_Dirichlet过程s来拟合转换后的数据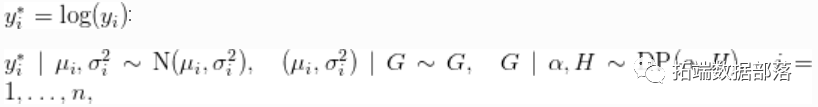
其中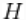 对应的是正态-逆伽马分布。这个模型可以解释为提供一个贝叶斯版本的核密度估计
对应的是正态-逆伽马分布。这个模型可以解释为提供一个贝叶斯版本的核密度估计 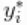 用于使用高斯核和自适应带宽。在数据的原始尺度上,这可以转化为一个自适应的对数高斯核密度估计。
用于使用高斯核和自适应带宽。在数据的原始尺度上,这可以转化为一个自适应的对数高斯核密度估计。
引入辅助变量 ,表明混合的哪个成分产生了每个观测值,并对随机量
,表明混合的哪个成分产生了每个观测值,并对随机量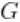 进行积分,我们得到模型的CRP表示(Blackwell and MacQueen, 1973)。
进行积分,我们得到模型的CRP表示(Blackwell and MacQueen, 1973)。
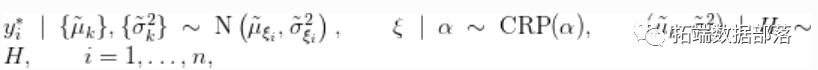
其中
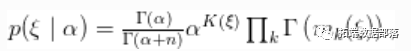
 是向量
是向量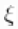 中唯一值的数量,
中唯一值的数量,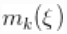 是第
是第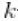 个唯一值在
个唯一值在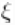 中出现的次数。这个说明清楚地表明,每个观测值都属于最多
中出现的次数。这个说明清楚地表明,每个观测值都属于最多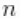 正态分布聚类中的任何一个,并且CRP分布与分区结构的先验分布相对应。
正态分布聚类中的任何一个,并且CRP分布与分区结构的先验分布相对应。
这个模型的说明是这样的
y\[i\] ~ dnorm(mu\[i\], var = s2\[i\])mu\[i\] <- muTilde\[xi\[i\]\]s2\[i\] <- s2Tilde\[xi\[i\]\]xi\[1:n\] ~ dCRP(alpha, size = n)muTilde\[i\] ~ dnorm(0, var = s2Tilde\[i\])s2Tilde\[i\] ~ dinvgamma(2, 1)alpha ~ dgamma(1, 1)请注意,在模型代码中,参数向量muTilde和s2Tilde的长度被设置为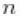 .我们这样做是因为目前的实现要求提前设置参数向量的长度,并且不允许它们的数量在迭代之间变化。因此,如果我们要确保算法总是按预期执行,我们需要在最坏的情况下工作,即有多少个成分就有多少个观测值的情况。但它的效率也有点低,无论是在内存需求方面(当
.我们这样做是因为目前的实现要求提前设置参数向量的长度,并且不允许它们的数量在迭代之间变化。因此,如果我们要确保算法总是按预期执行,我们需要在最坏的情况下工作,即有多少个成分就有多少个观测值的情况。但它的效率也有点低,无论是在内存需求方面(当 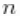 规模大时,需要维护大量未占用的成分)还是在计算负担方面(每次迭代都需要更新大量不需要后验推理的参数)。当我们在下面使用伽马分布的混合时,我们将展示一个能提高效率的计算捷径。
规模大时,需要维护大量未占用的成分)还是在计算负担方面(每次迭代都需要更新大量不需要后验推理的参数)。当我们在下面使用伽马分布的混合时,我们将展示一个能提高效率的计算捷径。
还需要注意的是,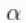 的值控制着我们先验预期的成分数量,
的值控制着我们先验预期的成分数量,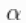 的值越大,对应于数据占据的成分数量越多。因此,通过指定一个
的值越大,对应于数据占据的成分数量越多。因此,通过指定一个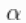 先验值,我们为模型增加了灵活性。对Gamma先验的特殊选择允许使用数据增强方案从相应的全条件分布中有效取样。也可以选择其他的先验,在这种情况下,这个参数
先验值,我们为模型增加了灵活性。对Gamma先验的特殊选择允许使用数据增强方案从相应的全条件分布中有效取样。也可以选择其他的先验,在这种情况下,这个参数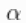 的默认采样是一个自适应的随机游走Metropolis-Hastings算法。
的默认采样是一个自适应的随机游走Metropolis-Hastings算法。
运行MCMC算法
下面的代码设置了数据和常数,初始化了参数,定义了模型对象,并建立和运行了MCMC算法。默认采样器是一个折叠的吉布斯采样器(Neal, 2000)。
# 模型数据
y = standlFaithful
# 模型常量
n = length(standlFaithful))
# 参数初始化
list(xi = sample(1:10, size=n, replace=TRUE),
# 创建和编译模型
Model(code, data, inits, consts)
##定义模型...
##建立模型...
##设置数据和初始值...
##在模型上运行计算(随后的任何错误报告可能只是反映了模型变量的缺失值)...
##检查模型的大小和尺寸......。
##模型构建完成。
## 编译完成。
#MCMC的配置、创建和编译
MCMC(conf)
## 编译......这可能需要一分钟
## 编译完成。


我们可以从参数的后验分布中提取样本,并创建痕迹图、直方图和任何其他感兴趣的总结。例如,对于参数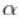 ,我们有。
,我们有。
# 参数的痕迹图
ts.plot(samples\[ , "alpha"\], xlab = "iteration", ylab = expression(alpha))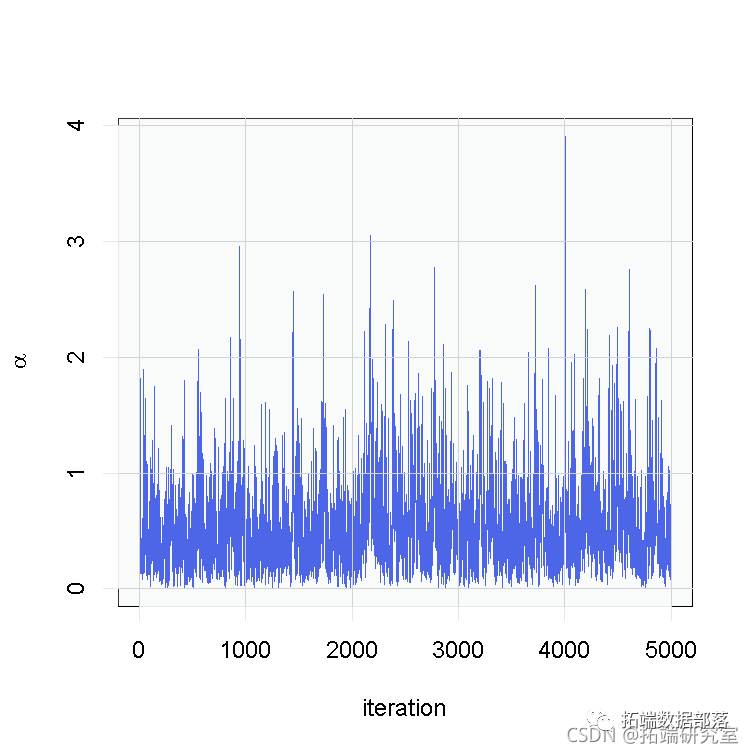
# 后验直方图
hist(samples\[ , "alpha"\], xlab = expression(alpha), main = "", ylab = "Frequency")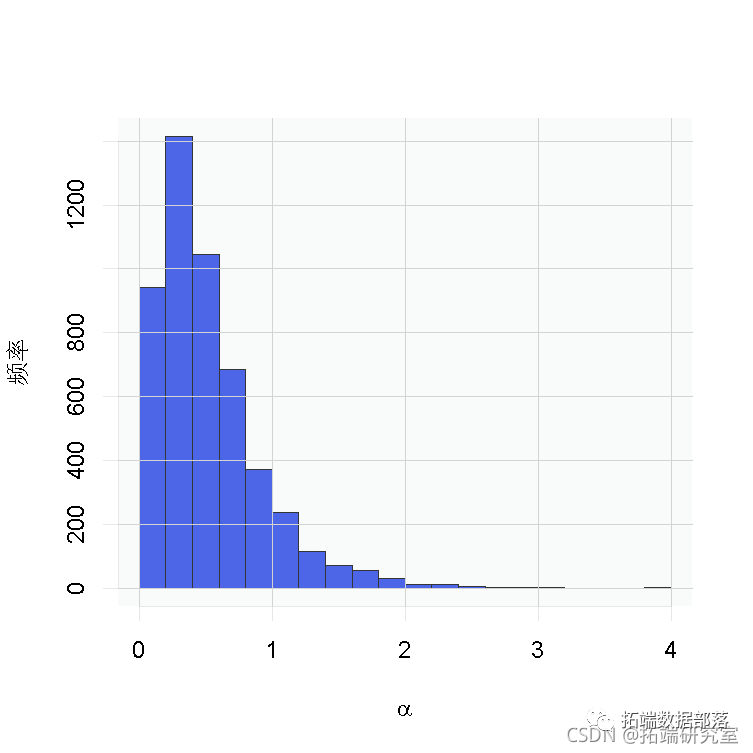

在这个模型下,对于一个新的观察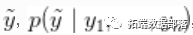 ,后验预测分布是最佳密度估计(在平方误差损失下)。这个估计的样本可以很容易地从我们的MCMC产生的样本中计算出来。
,后验预测分布是最佳密度估计(在平方误差损失下)。这个估计的样本可以很容易地从我们的MCMC产生的样本中计算出来。
# 参数的后验样本samples\[, "alpha"\]
# 平均值的后验样本samples\[, grep('muTilde', colnames(samples))\] # 聚类平均数的后验样本。
# 集群方差的后验样本
samples\[, grep('s2Tilde', colnames(samples))\] # 聚类成员的后验样本。
# 聚类成员关系的后验样本
samples \[, grep('xi', colnames(samples))\] # 聚类成员的后验样本。hist(y, freq = FALSE,xlab = "标准化对数尺度上的等待时间")
##对标准化对数网格的密度进行点式估计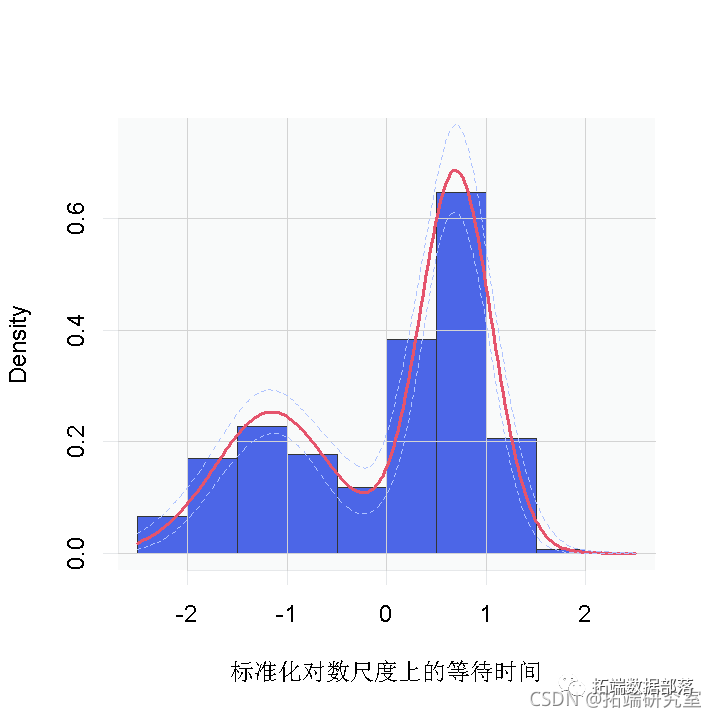
然而,回顾一下,这是对等待时间的对数的密度估计。为了获得原始尺度上的密度,我们需要对内核进行适当的转换。
standlGrid*sd(lFaithful) + mean(lFaithful) # 对数尺度上的网格hist(faithful$waiting, freq = FALSE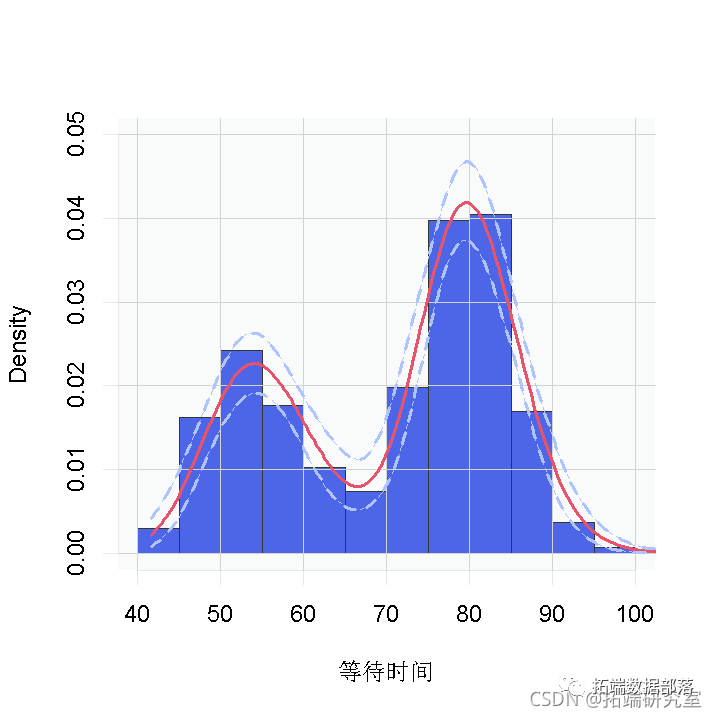
无论是哪种情况,都有明显的证据表明,数据中的等待时间有两个组成部分。
生成混合分布的样本
虽然混合分布的线性函数的后验分布的样本(比如上面的预测分布)可以直接从折叠采样器的实现中计算出来,但是对于非线性函数 的推断需要我们首先从混合分布中生成样本。我们可以从随机度量
的推断需要我们首先从混合分布中生成样本。我们可以从随机度量 中获得后验样本。需要注意的是,为了从
中获得后验样本。需要注意的是,为了从 ,得到后验样本,我们需要监控所有参与其计算的随机变量,即成员变量xi,聚类参数muTilde和s2Tilde,以及浓度参数alpha。
,得到后验样本,我们需要监控所有参与其计算的随机变量,即成员变量xi,聚类参数muTilde和s2Tilde,以及浓度参数alpha。
点击标题查阅往期内容

WINBUGS对随机波动率模型进行贝叶斯估计与比较

左右滑动查看更多
01
02
03

04
下面的代码从随机测量中生成后验样本。cMCMC对象包括模型和参数的后验样本。函数估计了一个截断水平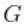 ,即truncG。后验样本是一个带
,即truncG。后验样本是一个带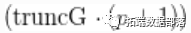 列的矩阵,其中参数分布
列的矩阵,其中参数分布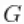 向量的维度(在本例中为
向量的维度(在本例中为 )。
)。
outputG <- getSamplesDPmeasure(cmcmc)下面的代码使用随机测量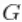 的后验样本来计算
的后验样本来计算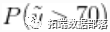 的后验样本。请注意,这些样本是基于转换后的模型计算的,大于70的值对应于上述定义的网格上大于0.035的值。
的后验样本。请注意,这些样本是基于转换后的模型计算的,大于70的值对应于上述定义的网格上大于0.035的值。
truncG <- outputG$trunc # G的截断水平probY70 <- rep(0, nrow(samples)) # P(y.tilde>70)的后验样本hist(probY70 )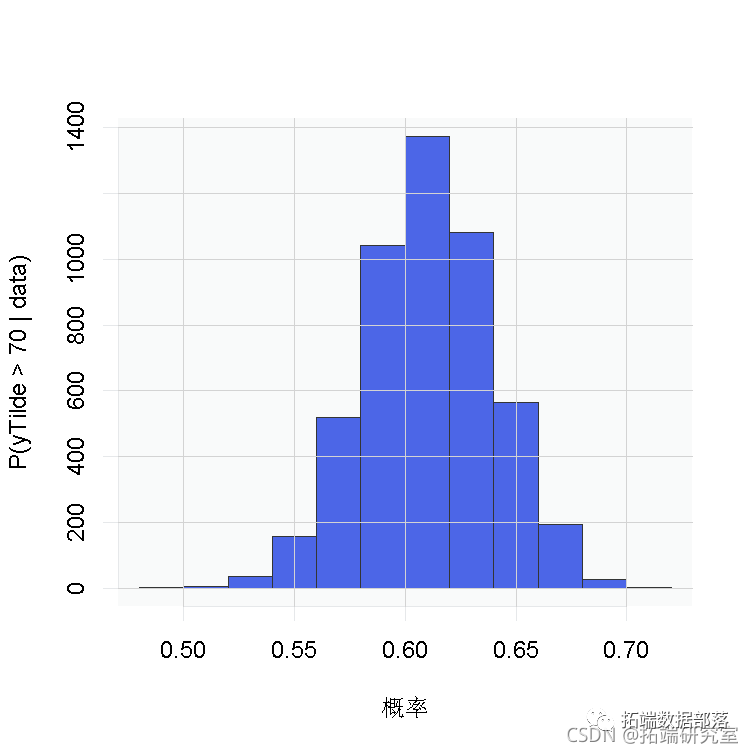
使用CRP表示法拟合伽马混合分布
不限于在DPM模型中使用高斯核。就Old Faithful数据而言,除了我们在上一节中介绍的对数尺度上的高斯核的混合分布外,还有一种选择是数据原始尺度上的伽马混合分布。
模型
在这种情况下,模型的形式为

其中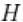 对应于两个独立Gamma分布的乘积。下面的代码提供了该模型。
对应于两个独立Gamma分布的乘积。下面的代码提供了该模型。
y\[i\] ~ dgamma(shape = beta\[i\], scale = lambda\[i\])beta\[i\] <- betaTilde\[xi\[i\]\]lambda\[i\] <- lambdaTilde\[xi\[i\]\]请注意,在这种情况下,向量beta和lambda的长度为 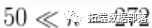 。这样做是为了减少与采样算法有关的计算和存储负担。你可以把这种方法看作是对过程的截断,只不过它可以被认为是*精确的截断。事实上,在CRP表示法下,只要采样器的成分数严格低于采样器每次迭代的参数向量的长度,使用长度短于样本中观察值的参数向量就会生成一个合适的算法。
。这样做是为了减少与采样算法有关的计算和存储负担。你可以把这种方法看作是对过程的截断,只不过它可以被认为是*精确的截断。事实上,在CRP表示法下,只要采样器的成分数严格低于采样器每次迭代的参数向量的长度,使用长度短于样本中观察值的参数向量就会生成一个合适的算法。
运行MCMC算法
下面的代码设置了模型数据和常数,初始化了参数,定义了模型对象,并建立和运行了Gamma混合分布的MCMC算法。请注意,在构建MCMC时,会产生一个关于聚类参数数量的警告信息。这是因为betaTilde和lambdaTilde的长度小于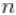 。另外,请注意,在执行过程中没有产生错误信息,这表明所需的集群数量未超过50个的上限。
。另外,请注意,在执行过程中没有产生错误信息,这表明所需的集群数量未超过50个的上限。
data <- list(y = waiting)
Model(code, data = data)cModel <- compilesamples <- runMCMC(cmcmc, niter = 7000, nburnin = 2000, setSeed = TRUE)在这种情况下,我们使用参数的后验样本来构建一个轨迹图,并估计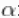 的后验分布。
的后验分布。
# 参数的后验样本的跟踪图
ts.plot(samples\[ , 'alpha'\], xlab = "iteration", ylab = expression(alpha))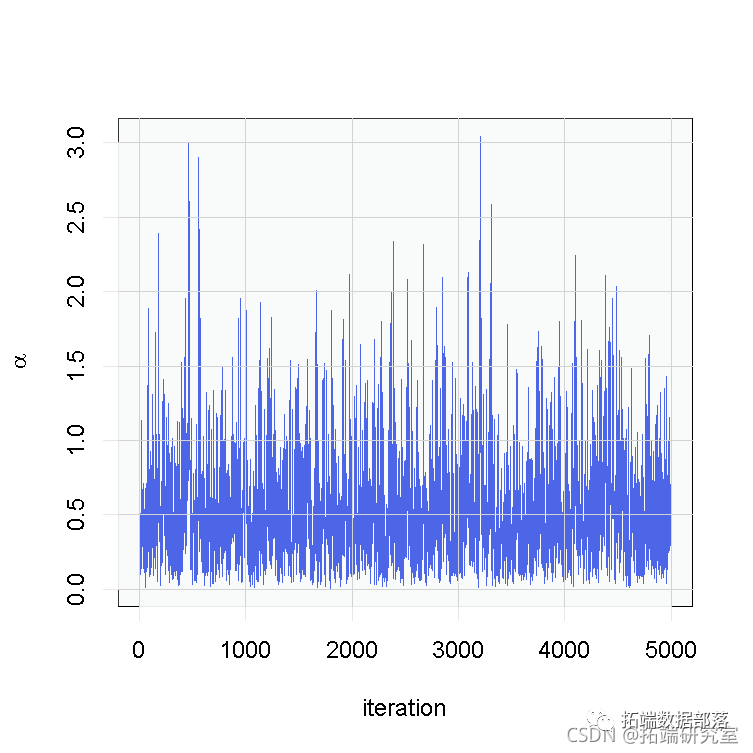
# 参数的后验样本的直方图
hist(samples\[, 'alpha'\])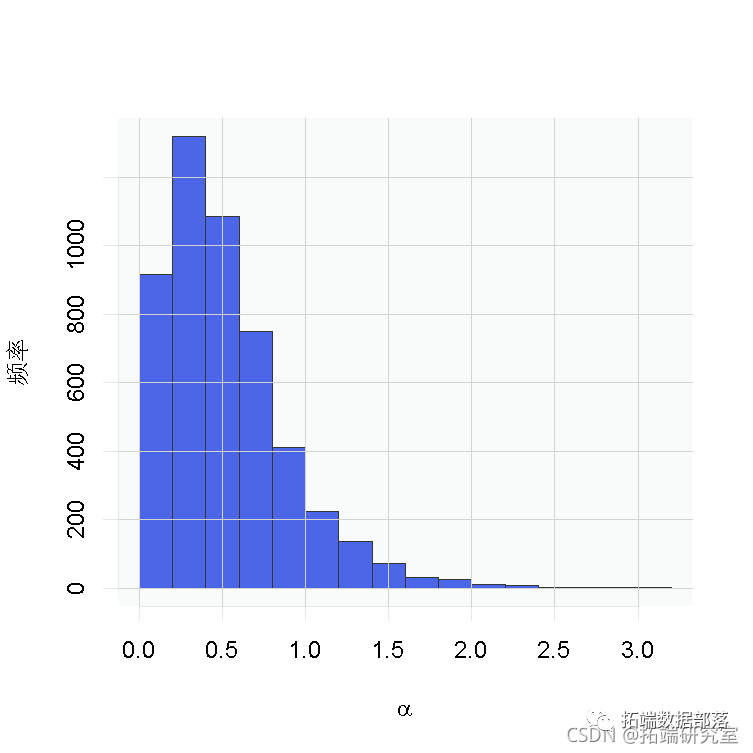
从混合分布中生成样本
和以前一样,我们从后验分布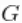 中获得样本。
中获得样本。
outputG <- getSamplesDPmeasure(cmcmc)我们使用这些样本来创建一个数据密度的估计值,以及一个95%置信带。
for(iter in seq_len)) {density\[iter, \] <- sapply(grid, function(x)sum( weightSamples\[iter, \] * dgamma)))
}hist(waiting, freq = FALSE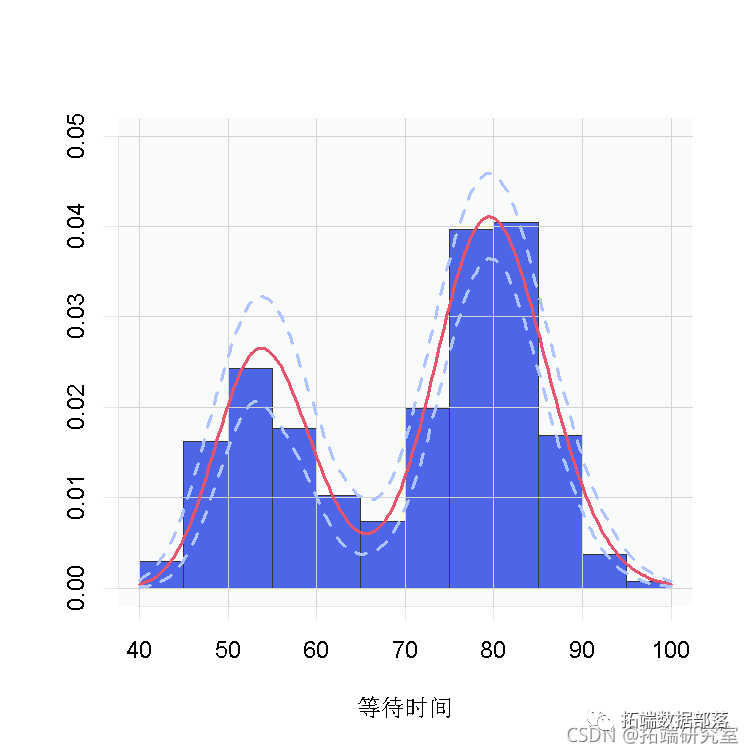
我们再次看到,数据的密度是双峰的,看起来与我们之前得到的数据非常相似。
使用stick-breaking 表示法拟合伽马DP混合分布
模型
Dirichlet过程混合物的另一种表示方法是使用随机分布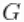 的stick-breaking表示(Sethuraman, 1994)。
的stick-breaking表示(Sethuraman, 1994)。
引入辅助变量, 表明哪个成分产生了每个观测值,上一节讨论的Gamma密度的混合物的相应模型的形式为
表明哪个成分产生了每个观测值,上一节讨论的Gamma密度的混合物的相应模型的形式为
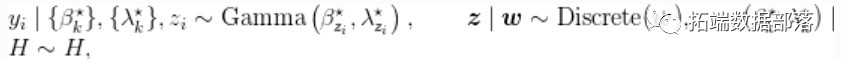
其中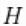 是两个独立Gamma分布的乘积。
是两个独立Gamma分布的乘积。
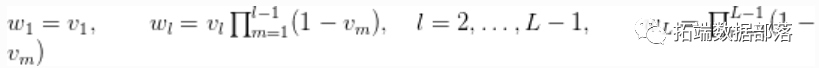
与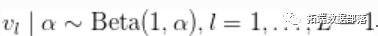 . 下面的代码提供了该模型说明。
. 下面的代码提供了该模型说明。
y\[i\] ~ dgamma(shape = beta\[i\], scale = lambda\[i\])beta\[i\] <- betaStar\[z\[i\]\]lambda\[i\] <- lambdaStar\[z\[i\]\]z\[i\] ~ dcat(w\[1:Trunc\])# stick-breaking v\[i\] ~ dbeta(1, alpha)w\[1:Trunc\] <- stick_breaking(v\[1:(Trunc-1)\]) # stick-breaking 权重betaStar\[i\] ~ dgamma(shape = 71, scale = 2)注意,截断水平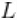 已被设置为Trunc值,该值将在函数的常数参数中定义。
已被设置为Trunc值,该值将在函数的常数参数中定义。
运行MCMC算法
下面的代码设置了模型数据和常量,初始化了参数,定义了模型对象,并建立和运行了Gamma混合分布的MCMC算法。当使用stick-breaking表示时,会指定一个分块Gibbs抽样器(Ishwaran, 2001; Ishwaran and James, 2002)。
data <- list(y = waiting)
consts <-length(waiting)
betaStar = rgammalambdaStar = rgammav = rbetaz = samplealpha = 1
compile(Model)MCMC(rModel, c("w", "betaStar", "lambdaStar", 'z', 'alpha'))
comp(mcmc )MCMC(cmcmc, niter = 24000)使用stick-breaking近似法会自动提供随机分布的近似值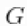 ,即
,即 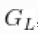 。下面的代码使用来自
。下面的代码使用来自 样本对象的后验样本计算后验样本,并从中计算出数据的密度估计。
样本对象的后验样本计算后验样本,并从中计算出数据的密度估计。
densitySamples\[i, \] <- sapply(grid, function(x) sum(weightSamples * dgamma(x, shape ,scale )))hist( waiting ylim=c(0,0.05),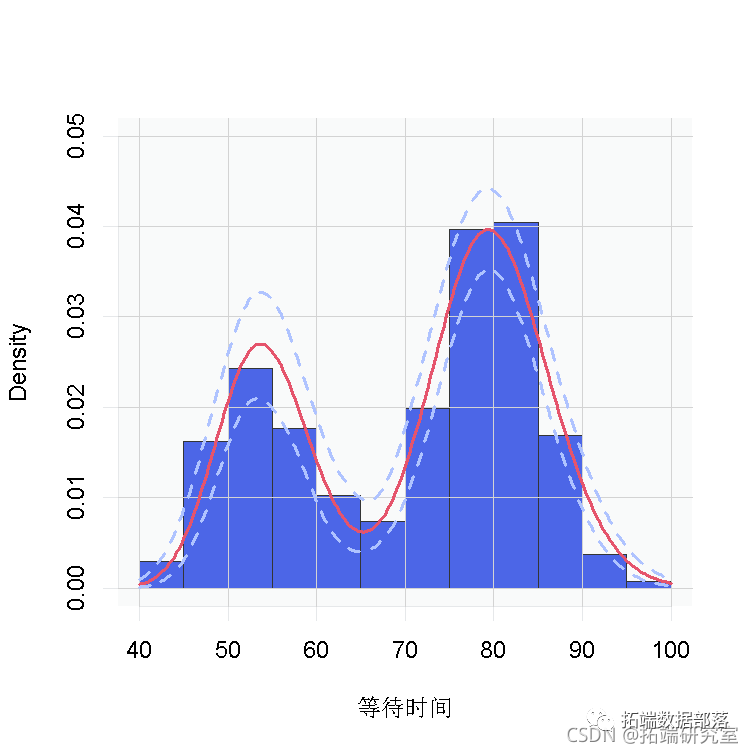
正如预期的那样,这个估计值看起来与我们通过CRP表示的过程获得的估计值相同。
贝叶斯非参数化:非参数化随机效应
我们将采用一个参数化的广义线性混合模型,并展示如何切换到非参数化的随机效应表示,避免了正态分布的随机效应假设。
心肌梗死(MIs)的参数化meta分析
我们将在对以前非常流行的糖尿病药物 "Avandia "的副作用进行meta分析的背景下,说明使用非参数混合模型对随机效应分布进行建模。我们分析的数据在引起对这种药物的安全性的严重质疑方面发挥了作用。问题是使用"Avandia "是否会增加心肌梗死(心脏病发作)的风险。,每项研究都有治疗和对照组。

模型的制定
我们首先进行基于标准的广义线性混合模型(GLMM)的meta分析。向量n和x分别包含对照组的患者总数和每项研究中对照组的心肌梗死患者人数。同样,向量m和y包含接受药物的病人的类似信息。该模型的形式为

其中,随机效应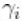 、遵循共同的正态分布
、遵循共同的正态分布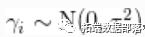 、
、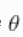 和
和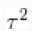 被合理地赋予非信息性先验。参数
被合理地赋予非信息性先验。参数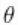 量化了对照组和治疗组之间的风险差异,而参数
量化了对照组和治疗组之间的风险差异,而参数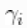 则量化了研究的具体变化。
则量化了研究的具体变化。
这个模型可以用以下代码指定。
y\[i\] ~ dbin(size = m\[i\], prob = q\[i\]) # 药物MIsx\[i\] ~ dbin(size = n\[i\], prob = p\[i\]) # 控制MIsq\[i\] <- expit(theta + gamma\[i\]) # 药物的对数指数p\[i\] <- expit(gamma\[i\]) #对照组对数gamma\[i\] ~ dnorm(mu, var = tau2) # 研究效果theta ~ dflat() # 药物的影响# 随机效应超参数mu ~ dnorm(0, 10)tau2 ~ dinvgamma(2, 1)运行MCMC
让我们来运行一个基本的MCMC。
MCMC(codeParam, data, inits,constants, monitors = c("mu", "tau2", "theta", "gamma")par(mfrow = c(1, 4)hist(gammaMn)
hist(samples\[1000, gammaCols)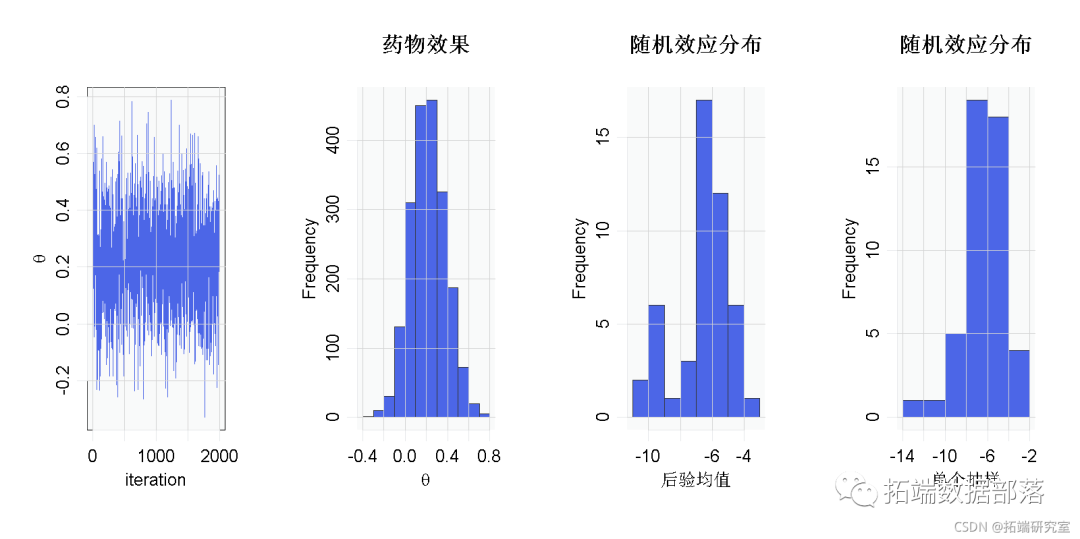
结果表明,对照组和治疗组之间存在着整体的风险差异。但是正态性假设呢?我们的结论对该假设是否稳健?也许随机效应的分布是偏斜的。
用于meta分析的基于DP的随机效应模型
模型
现在,我们对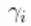 使用非参数分布。更具体地说,我们假设每个
使用非参数分布。更具体地说,我们假设每个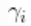 都是由位置尺度的正态混合分布产生的。
都是由位置尺度的正态混合分布产生的。
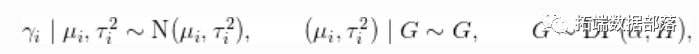
这种模型引起了随机效应之间的聚类。与密度估计问题的情况一样,DP先验允许数据决定分量的数量,从最少的一个分量(即简化为参数模型)到最多的分量,即每个观测值有一个分量。如果数据支持这种行为,这允许随机效应的分布是多模态的,大大增加了其灵活性。这个模型可以用以下代码指定。
y\[i\] ~ dbin(size = m\[i\], prob = q\[i\]) # 药物MIsx\[i\] ~ dbin(size = n\[i\], prob = p\[i\]) # MIsq\[i\] <- expit(theta + gamma\[i\]) # 药物的对数指数p\[i\] <- expit(gamma\[i\]) # 对照组对数值gamma\[i\] ~ dnorm(mu\[i\], var = tau2\[i\]) # 来自混合物的随机效应。mu\[i\]<- muTilde\[xi\[i\]\] # 来自聚类的随机效应的平均值 xi\[i\]tau2\[i\] <- tau2Tilde\[xi\[i\]\] # 来自群组xi\[i\]的随机效应变量# 从基础测量中提取混合成分参数muTilde\[i\] ~ dnorm(mu0, var = var0)tau2Tilde\[i\] ~ dinvgamma(a0, b0)# 用于将研究报告聚类为混合成分的CRPxi\[1:nStudies\] ~ dCRP(alpha, size = nStudies)# 超参数theta ~ dflat() # 药物的影响运行MCMC
以下代码对模型进行了编译,并对模型运行了一个压缩Gibbs抽样
inits <- list(gamma = rnorm(nStudies))MCMC(code = BNP, data = data)hist(samplesBNP\[, 'theta'\], xlab = expression(theta), main = 'avandia的影响')main = "随机效应分布")main = "随机效应分布")# 推断出了多少个混合成分?
xiRes <- samplesBNP\[, xiCols\].
主要推论似乎对原始的参数化假设很稳健。这可能是由于没有太多证据表明随机效应分布中缺乏正态性。
参考文献
Blackwell, D. and MacQueen, J. 1973. Ferguson distributions via Polya urn schemes. The Annals of Statistics 1:353-355.
Ferguson, T.S. 1974. Prior distribution on the spaces of probability measures. Annals of Statistics 2:615-629.
Lo, A.Y. 1984. On a class of Bayesian nonparametric estimates I: Density estimates. The Annals of Statistics 12:351-357.

点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言贝叶斯非参数模型:密度估计、非参数化随机效应META分析心肌梗死数据》。


点击标题查阅往期内容
R语言用贝叶斯线性回归、贝叶斯模型平均 (BMA)来预测工人工资
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
MATLAB随机森林优化贝叶斯预测分析汽车燃油经济性
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
使用贝叶斯层次模型进行空间数据分析
MCMC的rstan贝叶斯回归模型和标准线性回归模型比较
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
matlab贝叶斯隐马尔可夫hmm模型实现
贝叶斯线性回归和多元线性回归构建工资预测模型
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言STAN贝叶斯线性回归模型分析气候变化影响北半球海冰范围和可视化检查模型收敛性
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言JAGS贝叶斯回归模型分析博士生延期毕业完成论文时间
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
随机森林优化贝叶斯预测分析汽车燃油经济性
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
Python贝叶斯回归分析住房负担能力数据集
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python用PyMC3实现贝叶斯线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言贝叶斯线性回归和多元线性回归构建工资预测模型
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言stan进行基于贝叶斯推断的回归模型
R语言中RStan贝叶斯层次模型分析示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
视频:R语言中的Stan概率编程MCMC采样的贝叶斯模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计

![]()

相关文章:
R语言贝叶斯非参数模型:密度估计、非参数化随机效应META分析心肌梗死数据...
全文链接:http://tecdat.cn/?p23785 最近,我们使用贝叶斯非参数(BNP)混合模型进行马尔科夫链蒙特卡洛(MCMC)推断(点击文末“阅读原文”获取完整代码数据)。 概述 相关视频 在这篇文…...

在gazebo仿真环境中加载多个机器人
文章目录 前言一、基本概念1、xacro2、Gazebo 加载单个机器人模型 二、原先launch文件代码三、 修改launch文件加载多个机器人总结 前言 单个机器人的各项仿真实验都基本完成,也实现了远程控制,接下来主要对多机器人编队进行仿真实验,在进行…...

少有人走的路阅读笔记
前言 仅记录学习笔记,如有错误欢迎指正。 感受: 刚看完这本书,因为是很多天碎片化的时间看的,所以肯定对最新的内容印象较为深刻;作者是一个心理医生,从他的视角讲述了常人应该怎么样让自己的心灵心智更加…...

极简解析!IP计费的s5爬虫IP
大家好!今天我将为大家分享关于s5爬虫IP服务的知识。对于经常做爬虫的小伙伴来说,需要大量的爬虫IP支持爬虫业务,那么对于选择什么样的爬虫IP,我想我有很多发言权。 下面我们一起了解下IP计费的s5爬虫IP的知识,废话不…...

动静分离和前后端分离
动静分离和前后端分离 一、动静分离 侧重单体项目的静态资源分离 二、前后端分离 前后端完全分离...
【SpringBoot】集成SpringSecurity+JWT实现多服务单点登录,原来这么easy
Spring BootSpring SecurityJWT实现单点登录 源码 链接:https://pan.baidu.com/s/1EINPwP4or0Nuj8BOEPsIyw 提取码:kbue 一.概念 1.1.SSO 介绍: 单点登录(SingleSignOn,SSO),当用户在身份认证服务器上登录一次以…...
手把手教你使用PLSQL远程连接Oracle数据库【内网穿透】
文章目录 前言1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射 3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程Oracle 前言 Oracle,是甲骨文公司的一款关系…...

浅谈Deep Learning 与 Machine Learning 与Artificial Intelligence
文章目录 三者的联系与区别 三者的联系与区别 “Deep Learning is a kind of Machine Learning, and Machine Learning is a kind of Artificial Intelligence.” 人工智能(AI),机器学习(Machine Learning,简称ML&am…...
和 Node.js 说拜拜,Deno零配置解决方案
不知道大家注意没有,在我们启动各种类型的 Node repo 时,root 目录很快就会被配置文件塞满。例如,在最新版本的 Next.js 中,我们就有 next.config.js、eslintrc.json、tsconfig.json 和 package.json。而在样式那边,还…...
AxureRP制作静态站点发布互联网,实现公网访问【内网穿透】
AxureRP制作静态站点发布互联网,内网穿透实现公网访问 文章目录 AxureRP制作静态站点发布互联网,内网穿透实现公网访问前言1.在AxureRP中生成HTML文件2.配置IIS服务3.添加防火墙安全策略4.使用cpolar内网穿透实现公网访问4.1 登录cpolar web ui管理界面4…...

【好文推荐】openGauss 5.0.0 数据库安全——全密态探究
前言 写此文章的目的,主要是验证: openGauss 5.0.0 数据库能够实现哪种加密方式的全密态全密态数据库的特点 一、全密态介绍 全密态数据库意在解决数据全生命周期的隐私保护问题,使得系统无论在何种业务场景和环境下,数据在传…...

堆的介绍与堆的实现和调整
个人主页:Lei宝啊 愿所有美好如期而遇 目录 堆的介绍: 关于堆的实现及相关的其他问题: 堆的初始化: 堆的销毁: 插入建堆: 堆向上调整: 交换两个节点的值: 堆向下调整&a…...

【广州华锐互动】马属直肠检查3D虚拟仿真课件
随着科技的发展,医疗行业也在不断地进行创新。其中,广州华锐互动开发的马属直肠检查3D虚拟仿真课件,为医学教育和实践操作带来了新的可能性。它不仅可以帮助医生提高诊断准确率,还可以让医学生在没有真实病人的情况下进行实践操作…...

Nuxt 菜鸟入门学习笔记:路由
文章目录 路由 Routing页面 Pages导航 Navigation路由参数 Route Parameters路由中间件 Route Middleware路由验证 Route Validation Nuxt 官网地址: https://nuxt.com/ 路由 Routing Nuxt 的一个核心功能是文件系统路由器。pages/目录下的每个 Vue 文件都会创建一…...

C++基本语法和注释
C程序介绍 C 程序可以定义为对象的集合,这些对象通过调用彼此的方法进行交互。现在让我们简要地看一下什么是类、对象,方法、即时变量。 对象 - 对象具有状态和行为。例如:一只狗的状态 - 颜色、名称、品种,行为 - 摇动、叫唤、吃…...
CSRF攻击
防御策略 过滤判断换referer头,添加tocken令牌验证,白名单 CSRF攻击和XSS比较 相同点:都是欺骗用户 不同点: XSS有攻击特征,所有输入点都要考虑代码,单引号过滤 CSRF没有攻击特征,利用的点…...

2023 “华为杯” 中国研究生数学建模竞赛(D题)深度剖析|数学建模完整代码+建模过程全解全析
问题一:区域碳排放量以及经济、人口、能源消费量的现状分析 思路: 定义碳排放量 Prediction 模型: CO2 P * (GDP/P) * (E/GDP) * (CO2/E) 其中: CO2:碳排放量 P:人口数量 GDP/P:人均GDP E/GDP:单位GDP能耗 CO2/E:单位能耗碳排放量 2.收集并统计相关…...
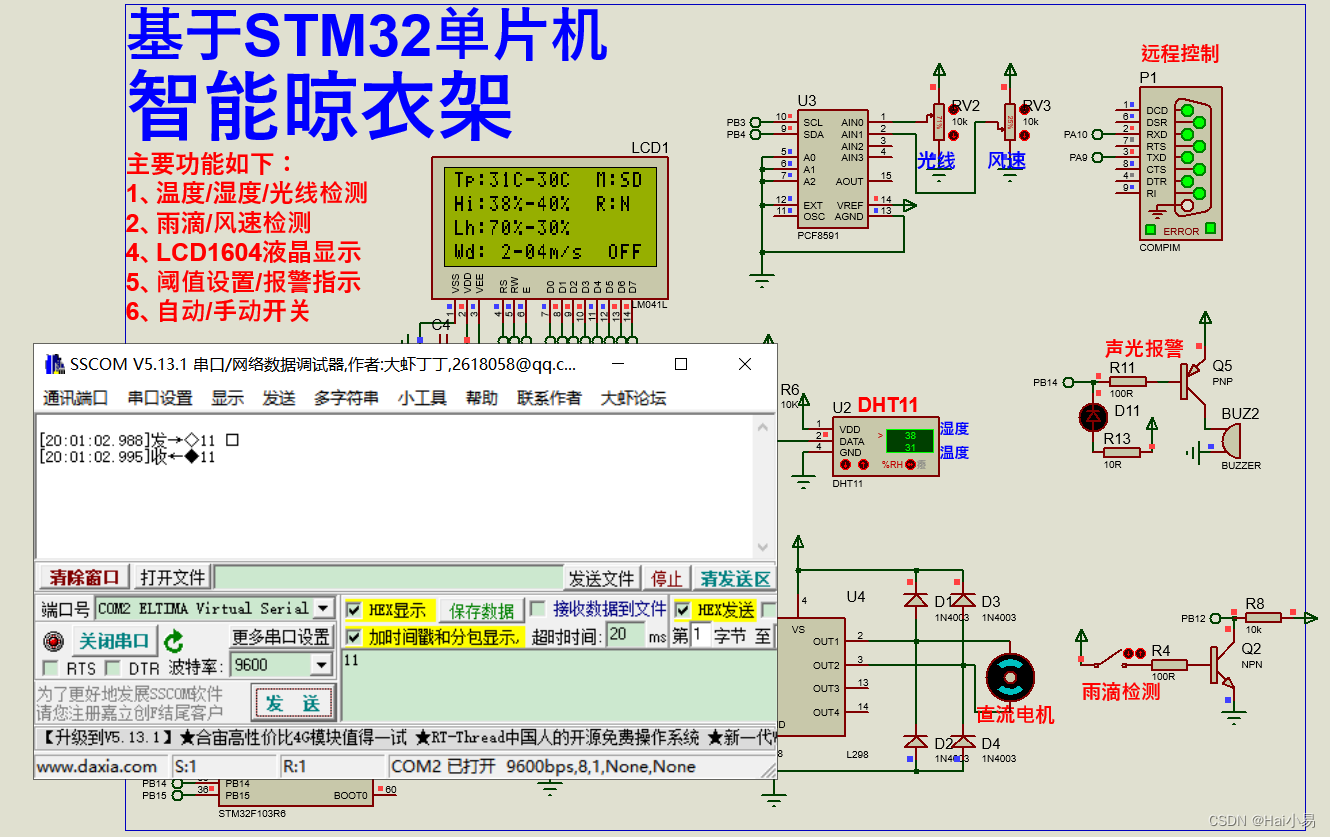
【Proteus仿真】【STM32单片机】基于单片机的智能晾衣架控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 系统运行后,LCD1604显示传感器检测的温湿度、光线强度和风速,工作模式,以及相应阈值,系统工作状态等;系统默认为自动模式, 可通过K4…...

C/C++代码静态检测工具PC-Lint常见错误总结
目录 1、PC-Lint 概述 2、PC-lint 常见错误列举 3、PC-Lint报告的语法错误 4、总结 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)https://blog.csdn.net/chenlycly/article/details/124272585C软件异常排查从入门到…...
概率深度学习建模数据不确定性
https://zhuanlan.zhihu.com/p/568912284理解论文 What uncertainties do we need in Bayesian deep learning for computer vision? (NeurIPS 2017) [1]中的数据不确定性建模,并给出公式推导。论文[1]指出不确定性uncertainty分为随机不确定性(aleator…...

3分钟免费加速GitHub:告别龟速下载的终极解决方案
3分钟免费加速GitHub:告别龟速下载的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的缓慢下…...

小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容
小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户…...

CGI Studio 3.11:AI驱动与安全合规的嵌入式HMI开发平台解析
1. 项目概述:为什么我们需要CGI Studio这样的HMI设计工具?在嵌入式系统开发领域,尤其是在汽车、工业和高端家电行业,图形用户界面的复杂度和美观度要求正以前所未有的速度提升。十年前,一个简单的单色LCD屏幕配上几个按…...

别再乱改usb_conf.h了!一文搞懂STM32 USB端点缓冲区PMA的分配原理
STM32 USB端点缓冲区PMA分配原理深度解析 第一次接触STM32 USB开发时,看到usb_conf.h里那些神秘的地址定义,你是否也曾一头雾水?为什么ENDP0_RXADDR有人设0x18,有人设0x40?这些数字背后隐藏着怎样的硬件机制࿱…...
)
Perplexity vs ChatGPT vs Claude:用户评论情感分析对比报告(NLP模型实测,含21项维度打分)
更多请点击: https://intelliparadigm.com 第一章:Perplexity用户评论汇总 主流平台用户反馈概览 Perplexity 作为以引用驱动、实时联网为特色的AI问答工具,近期在Reddit、Product Hunt及Twitter等平台收获大量真实用户评论。高频关键词包括…...

从理论到PCB:20dB耦合度的宽带定向耦合器设计全流程与性能测试
从理论到PCB:20dB耦合度的宽带定向耦合器设计全流程与性能测试 在射频电路设计中,定向耦合器作为关键的无源器件,其性能直接影响整个系统的信号监测、功率分配和反射测量精度。特别是工作于1-4GHz频段、耦合度为20dB的宽带定向耦合器…...

Win11安全中心总弹警告?手把手教你揪出并删除那个‘捣乱’的内存完整性不兼容驱动
Win11安全中心频繁弹窗?三步精准定位并清除内存完整性冲突驱动 每次开机右下角那个黄色三角警告图标是不是让你血压飙升?Windows安全中心反复提醒"内存完整性已关闭",点开一看又提示"驱动程序不兼容"。这种系统级的警告就…...

LinuxUDP丢包自动化巡检实践
LinuxUDP丢包自动化巡检实践这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在UDP丢包,重点讨论无连接流量、内核缓冲和应用接收能力。在真实生产环境中,UDP丢包相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、资源…...

2026年B站资源下载全攻略:3步学会用BiliTools高效保存视频
2026年B站资源下载全攻略:3步学会用BiliTools高效保存视频 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

从Harness走向Coordination,openJiuwen社区发布JiuwenSwarm,引领多智能体协作新范式
刚刚,华为支持的开源 AI Agent 平台社区 openJiuwen 发布并开源了 JiuwenSwarm。 这是一个面向多智能体协作的蜂群智能体。让多个 AI 智能体像蜂群一样高效协作、自主演进,正式按下 "群体智能" 的加速键,开启 AI 时代的 "养蜂…...