Kubernetes中Pod的扩缩容介绍
Kubernetes中Pod的扩缩容介绍
在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需
要减少服务实例数量的场景。此时可以利用 Deployment/RC 的 Scale 机制来完成这些工作。
Kubernetes 对 Pod 的扩缩容操作提供了手动和自动两种模式,手动模式通过执行 kubectl scale 命令或通过
RESTful API 对一个 Deployment/RC 进行 Pod 副本数量的设置,即可一键完成。自动模式则需要用户根据某个性
能指标或者自定义业务指标,并指定 Pod 副本数量的范围,系统将自动在这个范围内根据性能指标的变化进行调
整。
1、手动扩缩容
下面以 Deployment nginx 为例进行手动扩缩容的演示。
配置文件 037-nginx-deployment.yaml 的内容为:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deployment
spec:replicas: 3selector:matchLabels:app: nginx-deploymenttemplate:metadata:labels:app: nginx-deploymentspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80
[root@master cha3]# kubectl create -f 037-nginx-deployment.yaml
deployment.apps/nginx-deployment created
已运行的 Pod 副本数量为3个:
[root@master cha3]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-5c5f6c4496-br6jv 1/1 Running 0 56s
nginx-deployment-5c5f6c4496-mr24j 1/1 Running 0 56s
nginx-deployment-5c5f6c4496-z8jh2 1/1 Running 0 56s
[root@master cha3]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 76s
[root@master cha3]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5c5f6c4496 3 3 3 79s
通过 kubectl scale 命令可以将 Pod 副本数量从初始的 3 个更新为 5 个:
[root@master cha3]# kubectl scale deployment nginx-deployment --replicas 5
deployment.apps/nginx-deployment scaled
[root@master cha3]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-5c5f6c4496-2565s 1/1 Running 0 40s
nginx-deployment-5c5f6c4496-b4d87 1/1 Running 0 40s
nginx-deployment-5c5f6c4496-br6jv 1/1 Running 0 3m34s
nginx-deployment-5c5f6c4496-mr24j 1/1 Running 0 3m34s
nginx-deployment-5c5f6c4496-z8jh2 1/1 Running 0 3m34s
将 --replicas 设置为比当前 Pod 副本数量更小的数字,系统将会杀掉一些运行中的 Pod,以实现应用集群缩容:
[root@master cha3]# kubectl scale deployment nginx-deployment --replicas=1
deployment.apps/nginx-deployment scaled
[root@master cha3]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-5c5f6c4496-br6jv 1/1 Running 0 4m18s
2、自动扩缩容机制
Kubernetes 从 1.1 版本开始,新增了名为 Horizontal Pod Autoscaler(HPA) 的控制器,用于实现基于 CPU使
用率进行自动 Pod 扩缩容的功能。HPA 控制器基于 Master 的 kube-controller-manager 服务启动参数
--horizontal-pod-autoscaler-sync-period 定义的探测周期(默认值为15s),周期性地监测目标 Pod 的资源
性能指标,并与 HPA 资源对象中的扩缩容条件进行对比,在满足条件时对 Pod 副本数量进行调整。
Kubernetes 在早期版本中,只能基于 Pod 的 CPU 使用率进行自动扩缩容操作,关于 CPU 使用率的数据来源于
Heapster 组件。Kubernetes 从 1.6 版本开始,引入了基于应用自定义性能指标的 HPA 机制,并在 1.9 版本之后
逐步成熟。本节对 Kubernetes 的 HPA 的原理和实践进行详细说明。
2.1 HPA的工作原理
Kubernetes 中的某个 Metrics Server( Heapster 或自定义 Metrics Server )持续采集所有 Pod 副本的指标数
据。HPA 控制器通过 Metrics Server 的 API ( Heapster 的 API 或聚合 API ) 获取这些数据,基于用户定义的扩缩
容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod
的副本控制器( Deployment、RC 或 ReplicaSet )发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。下图
描述了 HPA 体系中的关键组件和工作流程。

接下来首先对HPA能够管理的指标类型、扩缩容算法、HPA 对象的配置进行详细说明,然后通过一个完整的示例
对如何搭建和使用基于自定义指标的 HPA 体系进行说明。
2.2 指标的类型
Master 的 kube-controller-manager 服务持续监测目标 Pod 的某种性能指标,以计算是否需要调整副本数量。
目前 Kubernetes 支持的指标类型如下:
-
Pod 资源使用率:Pod 级别的性能指标,通常是一个比率值,例如 CPU 使用率。
-
Pod 自定义指标:Pod 级别的性能指标,通常是一个数值,例如接收的请求数量。
-
Object 自定义指标或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过
HTTP URL "/metrics"提供,或者使用外部服务提供的指标采集 URL。
Kubernetes 从 1.11 版本开始,弃用基于 Heapster 组件完成 Pod 的 CPU 使用率采集的机制,全面转向基于
Metrics Server 完成数据采集。Metrics Server 将采集到的 Pod 性能指标数据通过聚合API(Aggregated API) 如
metrics.k8s.io、custom.metrics.k8s.io 和 external.metrics.k8s.io提供给HPA控制器进行查询。
2.3 扩缩容算法详解
Autoscaler 控制器从聚合 API 获取到 Pod 性能指标数据之后,基于下面的算法计算出目标 Pod 副本数量,与当前
运行的 Pod 副本数量进行对比,决定是否需要进行扩缩容操作:
desiredReplicas=ceil[currentReplicas*(currentMetricValue/desiredMetricValue )]
即当前副本数×(当前指标值/期望的指标值),将结果向上取整。
以 CPU 请求数量为例,如果用户设置的期望指标值为 100m,当前实际使用的指标值为 200m,则计算得到期望
的 Pod 副本数量应为两个( 200/100=2 )。如果设置的期望指标值为 50m,计算结果为 0.5,则向上取整值为 1,
得到目标 Pod 副本数量应为 1 个。
当计算结果与 1 非常接近时,可以设置一个容忍度让系统不做扩缩容操作。容忍度通过
kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-tolerance 进行设置,默认值
为 0.1(即10%),表示基于上述算法得到的结果在 [-10%-+10%] 区间内,即 [0.9-1.1],控制器都不会进行扩缩容操
作。
也可以将期望指标值( desiredMetricValue )设置为指标的平均值类型,例如 targetAverageValue 或
targetAverageUtilization,此时当前指标值(currentMetricValue)的算法为所有 Pod 副本当前指标值的总
和除以 Pod 副本数量得到的平均值。
此外,存在几种 Pod 异常的情况,如下所述:
-
Pod 正在被删除(设置了删除时间戳):将不会计入目标 Pod 副本数量。
-
Pod 的当前指标值无法获得:本次探测不会将这个 Pod 纳入目标 Pod 副本数量,后续的探测会被重新纳入计
算范围。
-
如果指标类型是 CPU 使用率,则对于正在启动但是还未达到 Ready 状态的 Pod,也暂时不会纳入目标副本数
量范围。可以通过
kube-controller-manager服务的启动参数--horizontal-pod-autoscaler-initial-readiness-delay设置首次探测 Pod 是否 Ready 的延时时间,默认值为
30s。另一个启动参数--horizontal-pod-autoscaler-cpuinitialization-period设置首次采集 Pod 的 CPU 使用率的延时时间。
在计算当前指标值/期望的指标值 (currentMetricValue / desiredMetricValue) 时将不会包括上述这些异常
Pod。
当存在缺失指标的 Pod 时,系统将更保守地重新计算平均值。系统会假设这些 Pod 在需要缩容(Scale Down)时消
耗了期望指标值的100%,在需要扩容(Scale Up)时消耗了期望指标值的0%,这样可以抑制潜在的扩缩容操作。
此外,如果存在未达到 Ready 状态的 Pod,并且系统原本会在不考虑缺失指标或 NotReady 的 Pod 情况下进行扩
展,则系统仍然会保守地假设这些 Pod 消耗期望指标值的0%,从而进一步抑制扩容操作。
如果在 HorizontalPodAutoscaler 中设置了多个指标,系统就会对每个指标都执行上面的算法,在全部结果中
以期望副本数的最大值为最终结果。如果这些指标中的任意一个都无法转换为期望的副本数(例如无法获取指标的
值),系统就会跳过扩缩容操作。
最后,在 HPA 控制器执行扩缩容操作之前,系统会记录扩缩容建议信息(Scale Recommendation)。控制器会在
操作时间窗口(时间范围可以配置)中考虑所有的建议信息,并从中选择得分最高的建议。这个值可通过
kube-controller-manager 服务的启动参数
--horizontal-pod-autoscaler-downscale-stabilization-window 进行配置,默
认值为5min。这个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
2.4 HorizontalPodAutoscaler配置详解
Kubernetes 将 HorizontalPodAutoscaler 资源对象提供给用户来定义扩缩容的规则。
HorizontalPodAutoscaler 资源对象处于 Kubernetes 的 API 组 autoscaling 中,目前包括 v1 和 v2 两个版本。
其中 autoscaling/v1 仅支持基于 CPU 使用率的自动扩缩容,autoscaling/v2 则用于支持基于任意指标的自
动扩缩容配置,包括基于资源使用率、Pod 指标、其他指标等类型的指标数据,当前版本为
autoscaling/v2beta2。
下面对 HorizontalPodAutoscaler 的配置和用法进行说明。
(1)基于 autoscaling/v1 版本的 HorizontalPodAutoscaler 配置,仅可以设置 CPU 使用率。
配置文件 038-php-apache.yaml 的内容为:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10targetCPUUtilizationPercentage: 50
主要参数如下:
-
scaleTargetRef:目标作用对象,可以是 Deployment、ReplicationController 或 ReplicaSet。 -
targetCPUUtilizationPercentage:期望每个 Pod 的 CPU 使用率都为 50%,该使用率基于 Pod 设置的CPU Request 值进行计算,例如该值为 200m,那么系统将维持 Pod 的实际 CPU 使用值为 100m。
-
minReplicas和maxReplicas:Pod 副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个 Pod 的 CPU 使用率为 50%。
[root@master cha3]# kubectl create -f 038-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/50% 1 10 0 17s
为了使用 autoscaling/v1 版本的 HorizontalPodAutoscaler,需要预先安装 Heapster 组件或 Metrics
Server,用于采集 Pod 的 CPU 使用率。Heapster 从 Kubernetes 1.11 版本开始进入弃用阶段,本节不再对
Heapster 进行详细说明,本节主要对基于自定义指标进行自动扩缩容的设置进行说明。
(2)基于 autoscaling/v2beta2 的 HorizontalPodAutoscaler 配置。
配置文件 039-php-apache.yaml 的内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscalermetadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50
主要参数如下。
-
scaleTargetRef:目标作用对象,可以是 Deployment、ReplicationController 或 ReplicaSet。 -
minReplicas和maxReplicas:Pod 副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个 Pod 的 CPU 使用率为 50%。
-
metrics:目标指标值,在 metrics 中通过参数 type 定义指标的类型。通过参数 target 定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间)触发扩缩容操作。
[root@master cha3]# kubectl create -f 039-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/50% 1 10 0 5s
等价写法,配置文件 040-php-apache.yaml 的内容为:
# 版本要修改
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cpu# 整合在一起的写法targetAverageUtilization: 50
[root@master cha3]# kubectl create -f 040-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/50% 1 10 0 12s
可以将 metrics 中的 type(指标类型)设置为以下三种,可以设置一个或多个组合,如下所述。
(1)Resource:基于资源的指标值,可以设置的资源为 CPU 和内存。
(2)Pods:基于 Pod 的指标,系统将对全部 Pod 副本的指标值进行平均值计算。
(3)Object:基于某种资源对象(如Ingress)的指标或应用系统的任意自定义指标。
Resource 类型的指标可以设置 CPU 和内存。对于 CPU 使用率,在 target 参数中设置 averageUtilization 定义目
标平均 CPU 使用率。对于内存资源,在 target 参数中设置 AverageValue 定义目标平均内存使用值。指标数据可
以通过 API "metrics.k8s.io" 进行查询,要求预先启动 Metrics Server 服务。
target.type 的取值为:Utilization、AverageValue
target 对应的取值为:averageUtilization、averageValue
关于内存的配置,配置文件 041-php-apache.yaml 的内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: memorytarget:type: AverageValueaverageValue: 100Mi
[root@master cha3]# kubectl create -f 041-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/100Mi 1 10 0 6s
等价写法,配置文件 `` 的内容为:
# 版本要修改
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cpu# 整合在一起的写法targetAverageValue: 100Mi
[root@master cha3]# kubectl create -f 042-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/100Mi 1 10 0 13s
Pods 类型和 Object 类型都属于自定义指标类型,指标的数据通常需要搭建自定义 Metrics Server 和监控工具进
行采集和处理。指标数据可以通过 API "custom.metrics.k8s.io" 进行查询,要求预先启动自定义 Metrics
Server 服务。
类型为 Pods 的指标数据来源于 Pod 对象本身,其 target 指标类型只能使用 AverageValue。
配置文件 043-php-apache.yaml 的内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10 metrics:- type: Podspods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k
其中,设置 Pod 的指标名为 packets-per-second,在目标指标平均值为 1000 时触发扩缩容操作。
[root@master cha3]# kubectl create -f 043-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/1k 1 10 0 4s
类型为 Object 的指标数据来源于其他资源对象或任意自定义指标,其 target 指标类型可以使用 Value 或
AverageValue (根据Pod副本数计算平均值)进行设置。
下面对几种常见的自定义指标给出示例和说明:
例1,设置指标的名称为 requests-per-second,其值来源于 Ingress "main-route",将目标值(value)设置
为2000,即在Ingress的每秒请求数量达到2000个时触发扩缩容操作。
配置文件 044-php-apache.yaml 的文件内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10 metrics:- type: Objectobject:metric:name: requests-per-seconddescribedObject:apiVersion: extensions/v1beta1kind: Ingressname: main-routetarget:type: Valuevalue: 2k
[root@master cha3]# kubectl create -f 044-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/2k 1 10 0 4s
例2,设置指标的名称为 http_requests,并且该资源对象具有标签 verb=GET,在指标平均值达到500时触发
扩缩容操作。
配置文件 045-php-apache.yaml 的内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10 metrics:- type: Objectobject:metric:name: http_requestsselector: {matchLabels: {verb: GET}}describedObject:apiVersion: extensions/v1beta1kind: Ingressname: main-routetarget:type: AverageValuevalue: 500
[root@master cha3]# kubectl create -f 045-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/500 1 10 0 5s
还可以在同一个 HorizontalPodAutoscaler 资源对象中定义多个类型的指标,系统将针对每种类型的指标都计算
Pod 副本的目标数量,以最大值为准进行扩缩容操作。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50- type: Resourceresource:name: memorytarget:type: AverageValueaverageValue: 100Mi- type: Podspods:metric:name: packets-per-secondtarget:type: AverageValueaverageValue: 1k- type: Objectobject:metric:name: requests-per-seconddescribedObject:apiVersion: extensions/v1beta1kind: Ingressname: main-routetarget:type: Valuevalue: 10k
[root@master cha3]# kubectl create -f 046-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/100Mi, <unknown>/1k + 2 more... 1 10 0 4s
从 1.10 版本开始,Kubernetes 引入了对外部系统指标的支持。例如,用户使用了公有云服务商提供的消息服务
或外部负载均衡器,希望基于这些外部服务的性能指标(如消息服务的队列长度、负载均衡器的QPS)对自己部署在
Kubernetes 中的服务进行自动扩缩容操作。这时,就可以在 metrics 参数部分设置 type 为 External 来设置
自定义指标,然后就可以通过 API "external.metrics.k8s.io" 查询指标数据了。当然,这同样要求自定义
Metrics Server 服务已正常工作。
例3,设置指标的名称为 queue_messages_ready,具有 queue=worker_tasks 标签在目标指标平均值为30时
触发自动扩缩容操作。
配置文件 047-php-apache.yaml 的文件内容为:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: php-apache
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apacheminReplicas: 1maxReplicas: 10 metrics:- type: Externalexternal:metric:name: queue_messages_readyselector: {matchLabels: {queue: worker_tasks}}target:type: AverageValueaverageValue: 30
[root@master cha3]# kubectl create -f 047-php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
[root@master cha3]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache <unknown>/30 (avg) 1 10 0 4s
在使用外部服务的指标时,要安装、部署能够对接到 Kubernetes HPA 模型的监控系统,并且完全了解监控系统
采集这些指标的机制,后续的自动扩缩容操作才能完成。
Kubernetes 推荐尽量使用 type 为 Object 的 HPA 配置方式,这可以通过使用 Operator 模式,将外部指标通过
CRD(自定义资源)定义为API资源对象来实现。
相关文章:
Kubernetes中Pod的扩缩容介绍
Kubernetes中Pod的扩缩容介绍 在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需 要减少服务实例数量的场景。此时可以利用 Deployment/RC 的 Scale 机制来完成这些工作。 Kubernetes 对 Pod 的扩…...
vue点击pdf文件直接在浏览器中预览文件
好久没有更新文章了,说说为什么会有这篇文章呢,其实是应某个热线评论的要求出的,不过由于最近很长一段时间没打开csdn现在才看到,所以才会导致到现在才出。 先来看看封装完这个预览方法的使用,主打一个方便使用&#x…...

通讯网关软件012——利用CommGate X2OPC实现MS SQL数据写入OPC Server
本文推荐利用CommGate X2OPC实现从MS SQL服务器获取数据并写入OPC Server。CommGate X2OPC是宁波科安网信开发的网关软件,软件可以登录到网信智汇(http://wangxinzhihui.com)下载。 【案例】如下图所示,实现从MS SQL数据库获取数据并写入OPC Server。 【…...
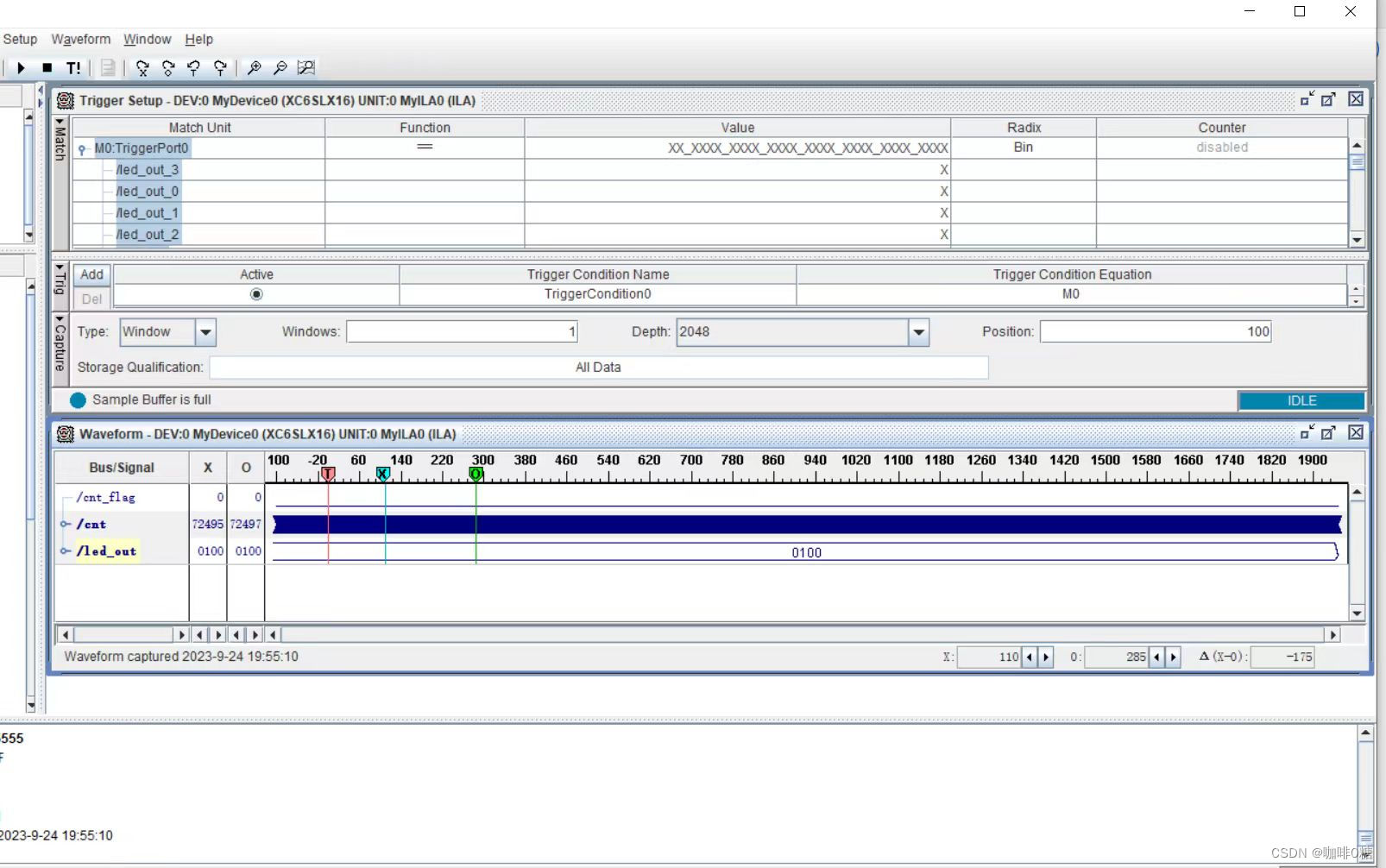
ISE_ChipScope Pro的使用
1.ChipScope Pro Core Inserter 使用流程 在之前以及编译好的流水灯实验上进行学习 ChipScope的使用。 一、新建一个ChipScope 核 点击Next,然后在下一个框中选择 Finish,你就会在项目菜单中看到有XX.cdc核文件。 二、对核文件进行设置 右键“Synthesize – XST” …...

北邮22级信通院数电:Verilog-FPGA(2)modelsim北邮信通专属下载、破解教程
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 目录 1.下载 2.解压打开 3.modelsim初安装 4.…...
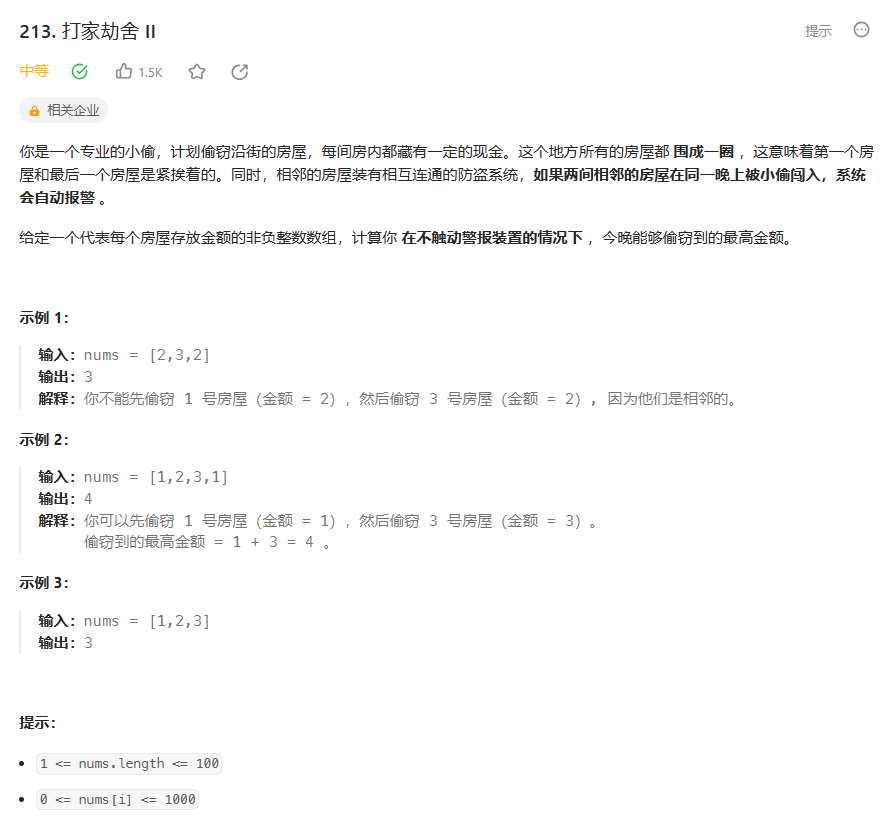
【力扣-每日一题】213. 打家劫舍 II
class Solution { public:int getMax(int n,vector<int> &nums){int a0,bnums[n],c0;for(int in1;i<nums.size()n-1;i){ //sizen-1,为0时,第一个可以偷,最后一个不能偷size-1;n为1时,最后一个可偷,计算…...
【PDF】pdf 学习之路
PDF 文件格式解析 https://www.cnblogs.com/theyangfan/p/17074647.html 权威的文档: 推荐第一个连接: PDF Explained (译作《PDF 解析》) | PDF-Explained《PDF 解析》https://zxyle.github.io/PDF-Explained/ https://zxyle…...

排序算法二 归并排序和快速排序
目录 归并排序 快速排序 1 挖坑法编辑 2 Hoare法 快排的优化 快排的非递归方法 七大排序算法复杂度及稳定性分析 归并排序 归并排序是建立在归并操作上的一种有效的排序算法,将以有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,在使子序列段间有序.若将两…...

活动回顾 | 暴雨也无法阻挡的奔赴,2023 Meet TVM · 深圳站完美收官!
2023 Meet TVM 深圳站于 2023 年 9 月 16 日在腾讯大厦成功举办,百余名参与者亲临现场,聆听讲师们的精彩分享。 作者 | xixi 编辑 | 三羊 本文首发于 HyperAI 超神经微信公众平台~ **由 MLC.AI 社区和 HyperAI超神经主办,Openbayes贝式计算…...

JAVA_多线程的实现方式
线程的状态 方式一: public class Thread1 extends Thread {Overridepublic void run() {synchronized (this) {for (int i 0; i < 100; i) {System.out.println(getName() "" i);}}} } Thread1 thread1 new Thread1(); thread1.start(); 方式二…...
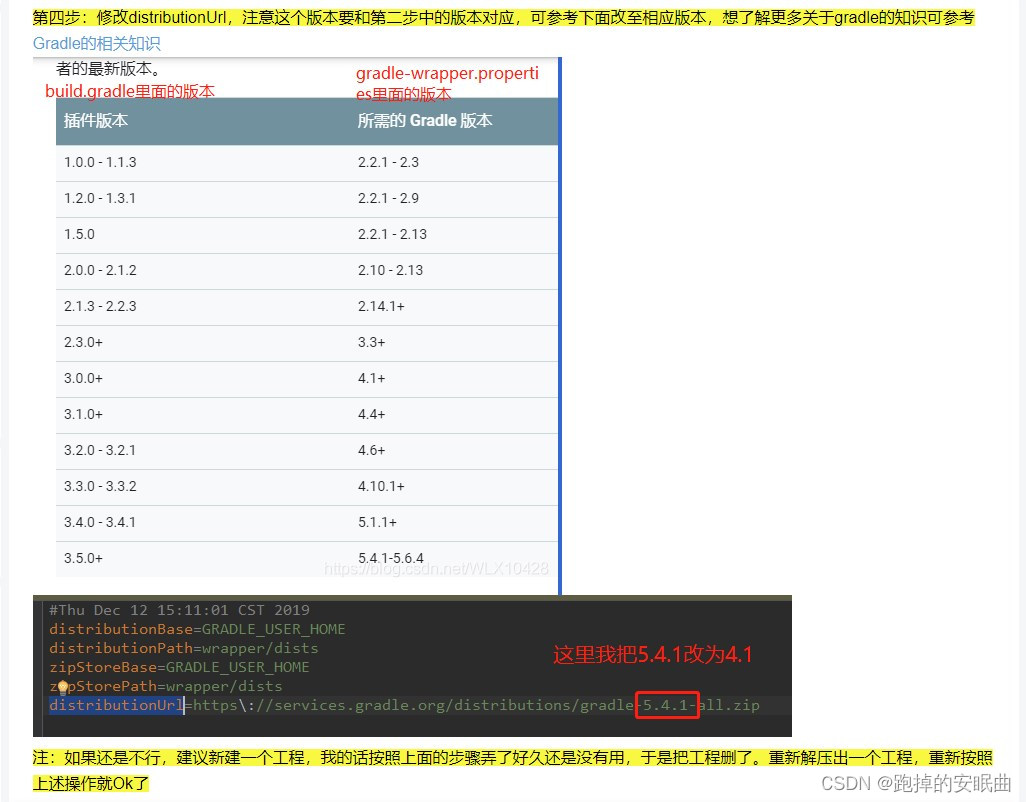
Android AndroidStudro版本gradle版本对应
详情网站:Android studio版本对用的gradle版本和插件版本(注意事项)...

Windows所有的端口及端口对应的程序
Windows所有的端口及端口对应的程序 1.查询Windows的端口 在CMD窗口运行: netstat -ano 结果示例: 活动连接协议 本地地址 外部地址 状态 PIDTCP 0.0.0.0:135 0.0.0.0:0 LISTENING 1156T…...
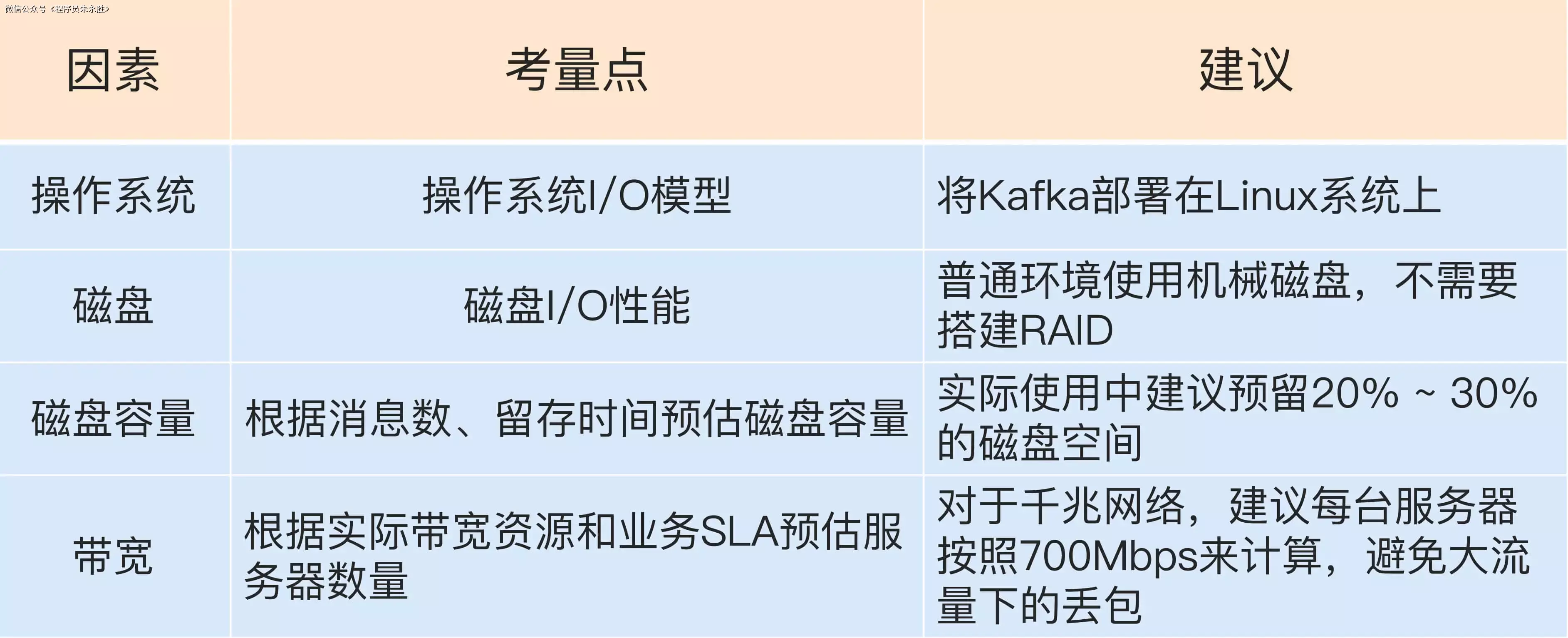
【Kafka系列】(二)Kafka的基本使用
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址[1] 文章更新计划[2] 系列文章地址[3] Kafka 线上集群部署方案怎么做 操作系统 先说结论,Kafka 部署在 Linux 上要比 Window…...
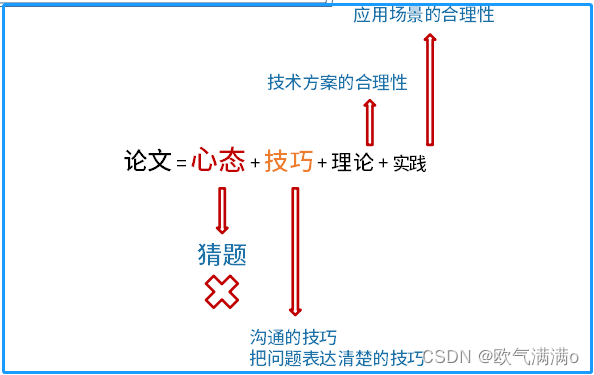
2023年下半年软考高级系统架构设计师论文指南(收藏)
由于今年下半年软考改为了机考,所以今年是看大家码字的速度了,但是好处还是有的,错了还能删除,之前纸质的 还有点不方便。 1、选择题目 (1)控制选题的时间。不要浪费太多时间在纠结选题上面。 ÿ…...

数据结构之【动态数组】
1. 线性表 概念:线性表是n个具有相同特性的数据元素的有限序列。 常见的线性表有:数组、链表、栈、队列、字符串…… 特点: 保存在这个结构中的元素都是相同的数据类型。元素之间线性排列,元素之间在逻辑上是连续的。 线性表…...
解答嵌入式和单片机的关系
嵌入式系统是一种特殊的计算机系统,用于特定任务或功能。而单片机则是嵌入式系统的核心部件之一,是一种在单个芯片上集成了处理器、内存、输入输出接口等功能的微控制器。刚刚好我这里有一套单片机保姆式教学,里面有编程教学、问题讲解、语言…...
利用Pycharm将python程序打包为exe文件(亲测可用)
最近做了一个关于py的小项目,对利用Pycharm将python文件打包为exe文件不是很熟悉,故学习记录之。 目录 一、下载pyinstaller库 二、打开Pycharm进行打包(不更改图标) 三、打开Pycharm进行打包(更改图标)…...

解决Vue设置图片的动态src不生效的问题
一、问题描述 在vue项目中,想要动态设置img的src时,此时发现图片会加载失败。在Vue代码中是这样写的: 在Vue的data中是这样写的: 我的图片在根目录下的static里面: 但是在页面上这个图片却无法加载出来。 二、解决方案…...

企业关键数据采集如何做
数据对于企业的重要性不言而喻,目前又处于大数据时代,企业对于数据的解读将是辅助决策最重要的一环。依据所掌握的数据信息,帮助企业做决策的优化。然而,在企业的关键数据采集并不是一项简单轻松的任务,他需要企业投入…...

抖音SEO矩阵系统源码开发搭建
1. 确定需求和功能:明确系统的主要目标和需要实现的功能,包括关键词研究、短视频制作、外链建设、数据分析、账号设置优化等方面。 2. 设计系统架构:根据需求和功能确定系统的架构,包括前端、后端、数据库等部分的设计࿰…...

RK3588 LGA核心板:高性能嵌入式开发的模块化解决方案
1. 项目概述:当旗舰SoC遇见极致封装最近在嵌入式圈子里,一个“小而强”的组合引起了我的注意:瑞芯微的旗舰级SoC RK3588,被塞进了一个极其紧凑的LGA封装里,做成了名为SOM-3588-LGA的核心板,并且已经现货发售…...

光谱分析避坑指南:为什么你的多项式拟合基线校正总是不准?
光谱分析避坑指南:为什么你的多项式拟合基线校正总是不准? 拉曼光谱和红外光谱分析中,基线漂移是困扰研究人员的常见问题。就像摄影师需要先调平三脚架才能拍出清晰照片一样,准确的光谱基线校正是后续定量分析的基石。然而在实际操…...

【锂离子电池组的被动式电池均衡】电池组由两个并联的串联电池组成,每个并联串联都包含四个串联电池,目标是通过在电阻器上放电高SOC电池,直到所有电池的SOC相等附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...

如何在Inkscape中实现专业级光学设计与光线追踪:矢量绘图软件的光学模拟完整指南
如何在Inkscape中实现专业级光学设计与光线追踪:矢量绘图软件的光学模拟完整指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-rayt…...

战略咨询全新定位:结合政策导向规划企业中长期路径
在新形势下、战略咨询的定位逐渐向结合国家政策导向转变和企业在制定中长期发展路径时、须关注政策变化市场动态。在这一背景下政策要素核心在于灵活应对外部环境,企业可以利用定期分析市场动态和政策影响,明确发展方向。结合实际案例与专家观点、这些方…...
)
【2026最新版Linux安装Mysql】CentOS 7 安装 MySQL 8.4.9 完整流程(RPM 手动安装+避坑+面试)
前言:本文记录在 CentOS 7 / RHEL 7 上,通过官网 RPM Bundle tar 包手动安装 MySQL 8.4.9(LTS) 的完整可复现流程。适合需要在老版本 CentOS 上部署 MySQL、为 Python/AI 后端或 Java 项目准备数据库环境的读者。读完可按步骤完成…...

三星固件下载终极指南:Bifrost跨平台工具完整使用手册
三星固件下载终极指南:Bifrost跨平台工具完整使用手册 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备找不到官方固件而烦恼吗&#x…...

我自己写的论文为什么被判 AI 率 60%?这款工具帮我降到 5% 通过 985 知网严查
我自己写的论文为什么被判 AI 率 60%?这款工具帮我降到 5% 通过 985 知网严查 我是 211 直博生、毕业论文 100% 自己手写、没用过任何 AI 工具。送学校知网 AIGC 检测——AI 率 60%,学校卡 15% 红线。我整个人懵了——明明没用 AI 写、为什么算法判我 AI…...

别再手动改端口了!用这个OrCAD小补丁,3分钟搞定原理图端口标准化
告别混乱设计:OrCAD端口标准化高效解决方案 在复杂的电子设计项目中,原理图的整洁与规范程度直接影响着团队协作效率和后期维护成本。当多位工程师共同参与同一项目时,端口类型和朝向的不统一往往成为困扰PCB设计团队的常见问题。这种看似微小…...

Milk-V Duo开发板深度评测:双核RISC-V Linux系统实战与性能优化
1. 开箱初印象:当“小钢炮”遇上“大算力”刚拿到Milk-V Duo开发板时,我承认我愣了一下。包装盒比常见的信用卡还要小一圈,第一反应是“这怕不是个配件或者核心模块吧?”直到拆开静电袋,这块精致得如同艺术品的开发板本…...