Elasticsearch 部署学习
文章目录
- Elasticsearch 部署学习
- 1. 单节点部署 elasticsearch
- 1.1 部署 jdk
- 1.2 下载 elasticsearch
- 1.3 上传文件并修改配置文件
- 1.4 启动
- 1.5 问题总结
- 1.6 浏览器验证
- 2. 集群部署 elasticsearch
- 3. 常用命令
- 4. Elasticsearch kibana安装
- :one: 参考部署文档
- :two: 下载对应版本的安装包
- :three: 修改配置文件
- :four: 启动 kibana
- :five: 注意
- :six: 浏览器访问
- 5. kibana 使用教程
Elasticsearch 部署学习
1. 单节点部署 elasticsearch
1.1 部署 jdk
安装ES之前先安装好jdk,可以简单实用如下命令:
yum install -y java-1.8.0-openjdk.x86_64
或者参考:https://blog.csdn.net/D1179869625/article/details/125491228?ops_request_misc=&request_id=de79eea3684a4ea28adfe9663c700ce2&biz_id=&utm_medium=distribute.pc_search_result.none-task-blog-2blogkoosearch~default-3-125491228-null-null.268v1control&utm_term=jdk&spm=1018.2226.3001.4450
官网下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html#jdk-7u80-oth-JPR
1.2 下载 elasticsearch
官网下载地址:https://www.elastic.co/cn/downloads/past-releases
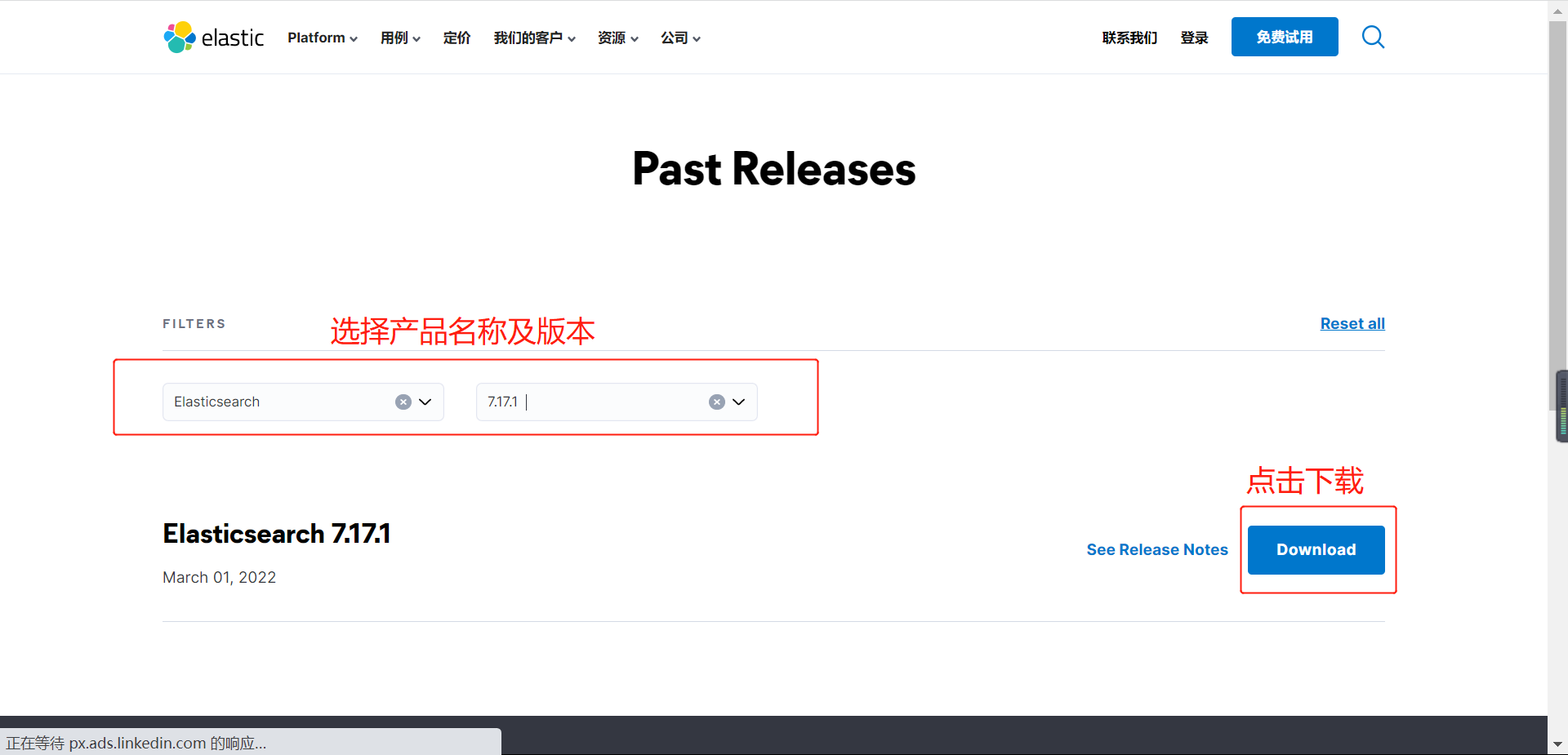
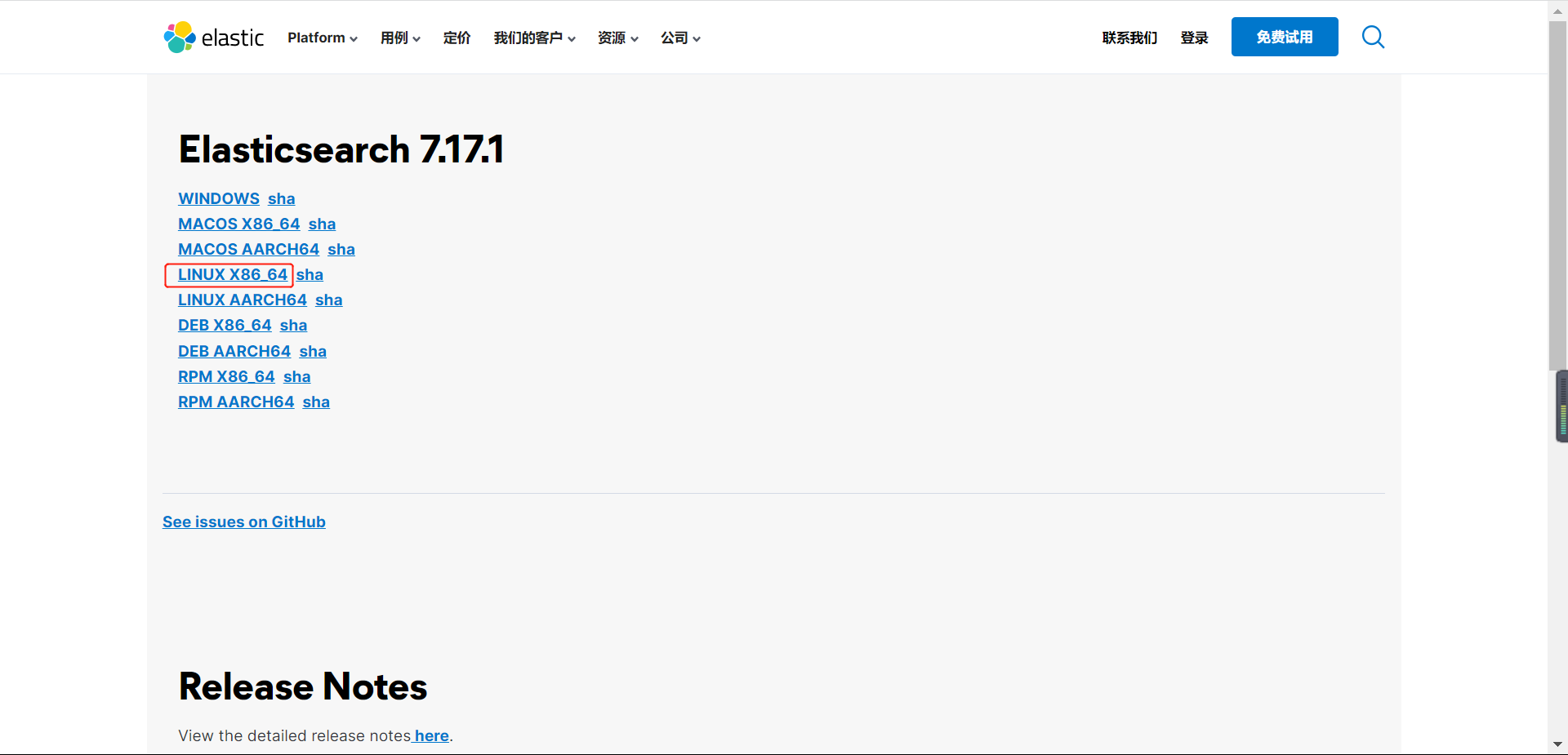
1.3 上传文件并修改配置文件
1️⃣ 上传到指定目录下并解压
[root@node2 elasticsearch]# pwd
/data/elasticsearch
[root@node2 elasticsearch]# tar zxvf elasticsearch-7.17.1-linux-x86_64.tar.gz
2️⃣ 新建数据目录
[root@node2 elasticsearch]# cd elasticsearch-7.17.1
[root@node2 elasticsearch-7.17.1]# mkdir data
3️⃣ 修改 elasticsearch.yml 配置文件
# 修改 config 目录下的 elasticsearch.yml 文件
cluster.name #集群名称,各节点配成相同的集群名称。
node.name #节点名称,各节点配置不同。
node.master #指示某个节点是否符合成为主节点的条件。
node.data #指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data #数据存储目录。
path.logs #日志存储目录。
bootstrap.memory_lock #内存锁定,是否禁用交换。
bootstrap.system_call_filter #系统调用过滤器。
network.host #绑定节点IP。
http.port #rest api端口。
discovery.zen.ping.unicast.hosts #提供其他 Elasticsearch 服务节点的单点广播发现功能。(单机部署时如果使用 localhost ,日志会报错“拒绝连接”,修改为IP地址没有报错)
discovery.zen.minimum_master_nodes #集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout #节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries #节点发现重试次数。
http.cors.enabled #是否允许跨源 REST 请求,用于允许head插件访问ES。
http.cors.allow-origin #允许的源地址。


4️⃣ 修改系统配置文件
vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096

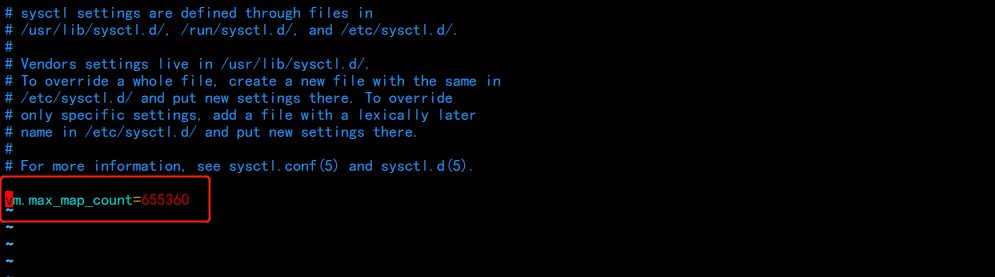
vim /etc/sysctl.conf
vm.max_map_count=655360# 修改完成执行命令生效
sysctl -p
1.4 启动
注:es 不允许使用 root 启动,所以需要新建用户
# 新建用户组
groupadd -g 988 elastic# 新建用户
useradd -u 988 -g 988 elastic# 查看新建用户信息
id elastic
uid=988(elastic) gid=988(elastic) 组=988(elastic)# 修改 elasticsearch 目录权限
cd /data
chown -R elastic:elastic elasticsearch
# 切换用户
su - elastic
# 后台启动
cd /data/elasticsearch/elasticsearch-7.17.1/bin
./elasticsearch -d
1.5 问题总结
1️⃣ 没有修改系统配置文件则会报错
现象:
[2023-06-19T19:11:29,573][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决方法:
vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096vim /etc/sysctl.conf
vm.max_map_count=655360# 修改完成执行命令生效
sysctl -p
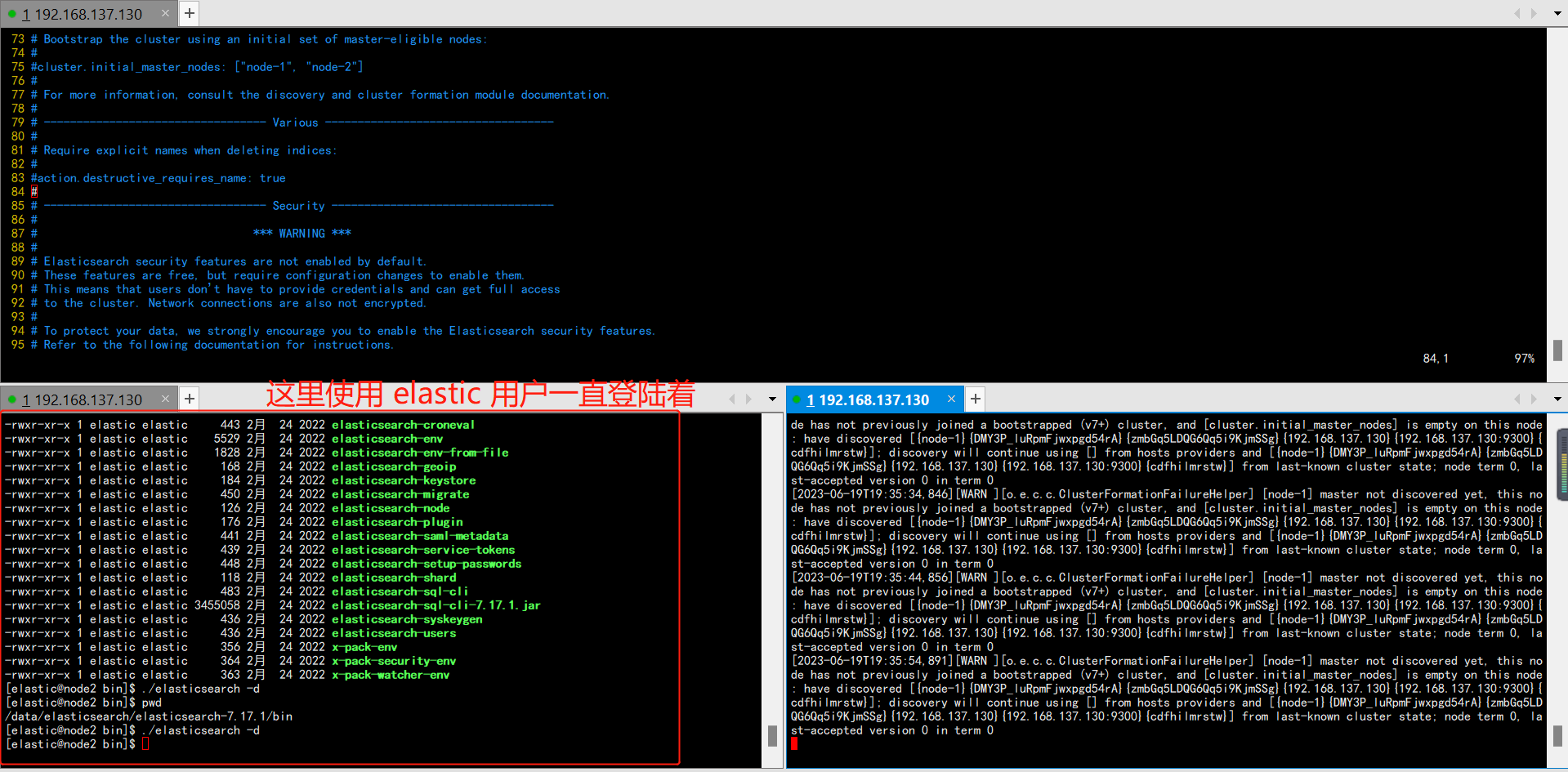
2️⃣ 当前操作是在多个窗口进行操作, 在一个窗口中一直使用 elastic 用户一直登陆着,在其他窗口中使用 root 修改完成配置文件之后,没有登出 elastic 普通用户,那么使用 elastic 用户在启动时仍然会报错,因为没有重新登陆则获取不到新修改的环境信息。
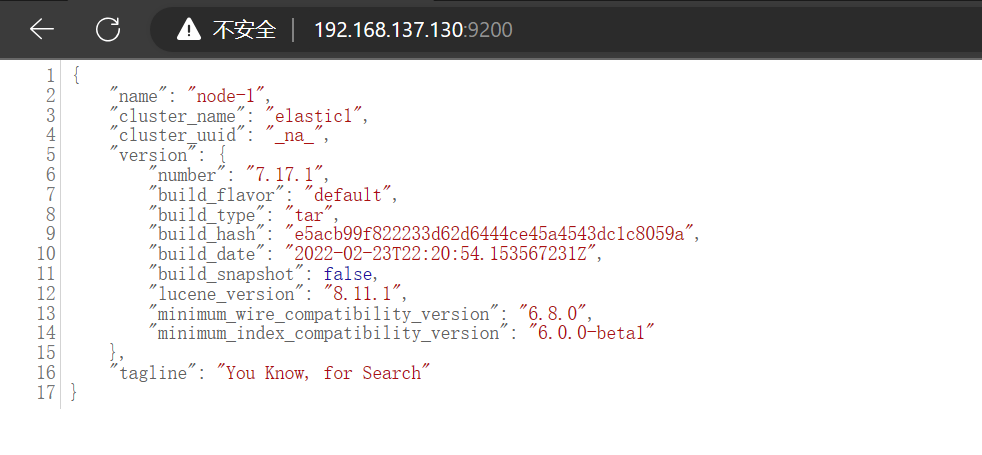
1.6 浏览器验证
浏览器输入:192.168.137.130:9200
2. 集群部署 elasticsearch
当前测试使用三台机器部署 es 集群
# 配置文件参数说明
# 集群名称,可以不用变,所有机器使用同一个名称
cluster.name: my-application# 每台机器使用不同的名称,其他机器可依次命名为(node-2,node-3)
node.name: node-1# data 数据目录
path.data: /home/softinstall/elasticsearch-5.2.2/data# log 日志目录
path.logs: /home/softinstall/elasticsearch-5.2.2/logs# ES默认bootstrap.system_call_filter为true进行检测,如果当前环境不支持SecComp则启动 es 会报错
bootstrap.memory_lock: false
bootstrap.system_call_filter: false# 这里填写当前主机的 IP
network.host: 192.168.18.128# 端口
http.port: 9200# 集群地址
discovery.zen.ping.unicast.hosts: ["192.168.18.128","192.168.18.129","192.168.18.130"]# master 的数量,可百度查看参数详细使用情况
discovery.zen.minimum_master_nodes: 2# 指定master机器的选项(个人理解就是重启之后 master 机器也只会在这两台机器中选择,配合上面 discovery.zen.minimum_master_nodes 参数使用)
cluster.initial_master_nodes: ["node-1", "node-2"]
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /data/elasticsearch/elasticsearch-7.17.1/data
#
# Path to log files:
#
path.logs: /data/elasticsearch/elasticsearch-7.17.1/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
network.host: 192.168.137.130
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["192.168.137.130","192.168.137.102","192.168.137.103"]
discovery.zen.minimum_master_nodes: 2
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
#
# ---------------------------------- Security ----------------------------------
#
# *** WARNING ***
#
# Elasticsearch security features are not enabled by default.
# These features are free, but require configuration changes to enable them.
# This means that users don’t have to provide credentials and can get full access
# to the cluster. Network connections are also not encrypted.
#
# To protect your data, we strongly encourage you to enable the Elasticsearch security features.
# Refer to the following documentation for instructions.
#
# https://www.elastic.co/guide/en/elasticsearch/reference/7.16/configuring-stack-security.html
启动三台机器,则会自动选举出 master
3. 常用命令
# 查看健康状态
http://ip:9200/_cat/health?v# 查看集群索引数
http://ip:9200/_cat/indices?pretty# 查看索引中信息(sysnewses 为索引名)
http://ip:9200/sysnewses/_search# 集群所在磁盘的分配情况
http://ip:9200/_cat/allocation?v# 查看集群节点信息
http://ip:9200/_cat/nodes?v# 查看集群其他信息
http://ip:9200/_cat
4. Elasticsearch kibana安装
1️⃣ 参考部署文档
部署 elasticsearch kibana 参考 es 文档
https://www.elastic.co/guide/cn/kibana/current/setup.html
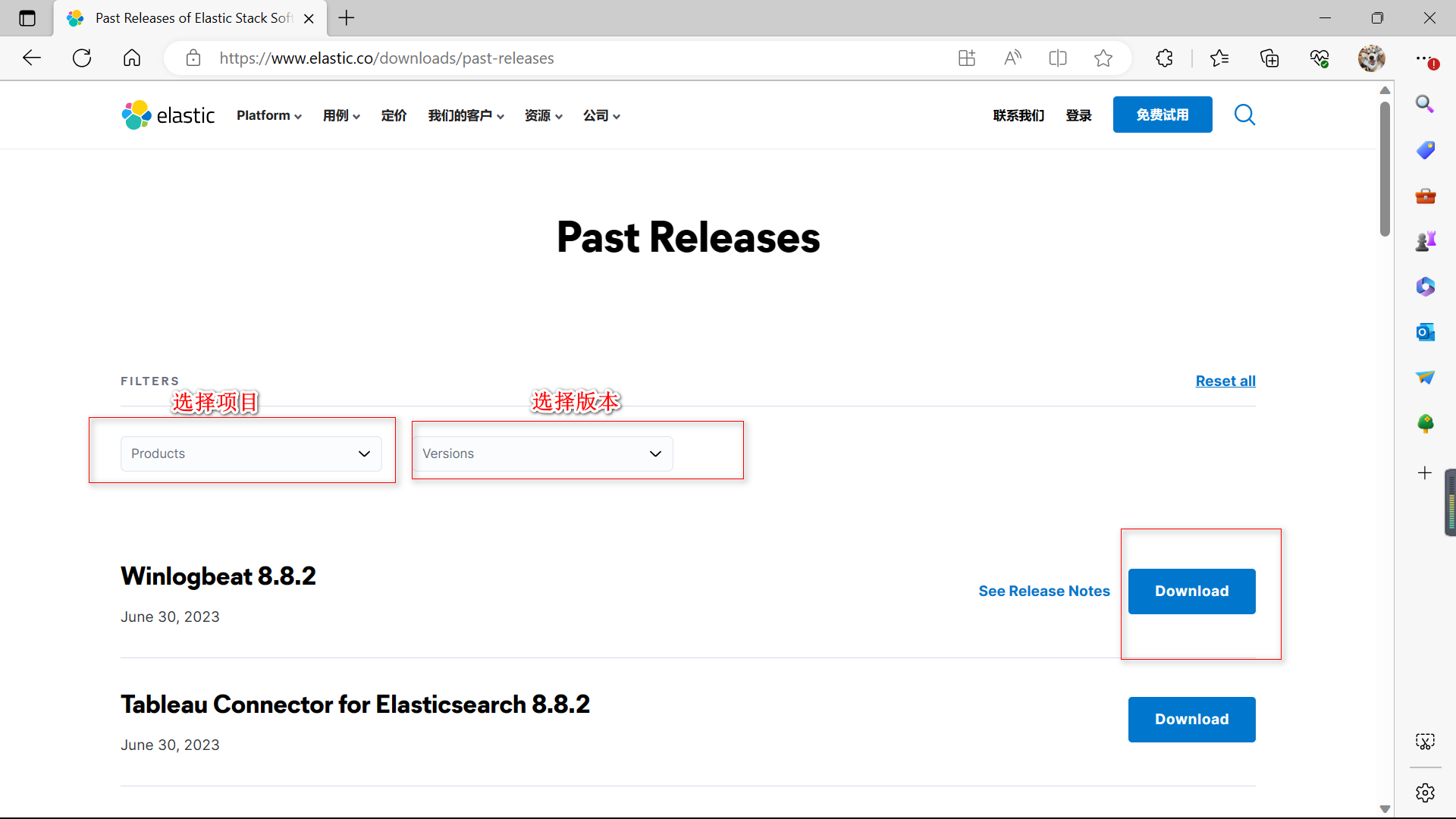
2️⃣ 下载对应版本的安装包
- 使用 Windows 下载
下载对应的版本
- 使用命令直接下载
# 下载指定版本
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.1-linux-x86_64.tar.gz# 比较 sha1sum 或 shasum 产生的 SHA 跟 发布 SHA是否一致。用于核实文件的完整性,通常在网络传输文件的过程中,可能造成文件丢失,所以可以用来检查文件传输是否完整。
sha1sum kibana-7.17.1-linux-x86_64.tar.gz
# 668b599ce30a89e936899ba73e5ebde5481d47c4 kibana-7.17.1-linux-x86_64.tar.gz# 解压
tar -xzf kibana-6.0.0-linux-x86_64.tar.gz
cd kibana/
3️⃣ 修改配置文件
vim /data/kibana-7.17.1-linux-x86_64/config# 默认值: 5601 Kibana 由后端服务器提供服务,该配置指定使用的端口号。
server.port: 5601
# 默认值: "localhost" 指定后端服务器的主机地址。
server.host: "192.168.137.130"
# 默认值: 1048576 服务器请求的最大负载,单位字节。
server.maxPayload: 1048576
# 默认值: "主机名" Kibana 实例对外展示的名称。
server.name: "demo-elastic"
# ES 集群地址
elasticsearch.hosts: ["http://192.168.137.130:9200"]
# 默认值: ".kibana" Kibana 使用 Elasticsearch 中的索引来存储保存的检索,可视化控件以及仪表板。如果没有索引,Kibana 会创建一个新的索引。
kibana.index: ".kibana"
# elasticsearch.requestTimeout setting 的值,等待 Elasticsearch 的响应时间。(这里设置的较大,机器性能不行,kibana启动较慢)
# 如果使用默认值,则启动时会报错,请求超时。
elasticsearch.pingTimeout: 12000
# 30000 等待后端或 Elasticsearch 的响应时间,单位微秒,该值必须为正整数。(这里设置的较大,机器性能不行,kibana启动较慢)
elasticsearch.requestTimeout: 120000
# Elasticsearch 等待分片响应时间,单位微秒,0即禁用(disabled)
elasticsearch.shardTimeout: 0
# 默认为 en ,修改为中文 zh-CN
i18n.locale: "zh-CN"
4️⃣ 启动 kibana
- 直接启动
# 进入到安装目录的 bin 目录下
cd /data/kibana-7.17.1-linux-x86_64/bin
# 直接前台启动./kibana
# 使用 Ctrl + c 则可以直接关闭
- 后台启动(推荐)
# 进入到安装目录的 bin 目录下
cd /data/kibana-7.17.1-linux-x86_64/bin
# 使用 nohup 命令后台启动
# 也可以将日志打印到指定路径下 nohup ./kibana > /data/kibana-7.17.1-linux-x86_64/logs/kibana.log 2>&1 &
nohup ./kibana &
- 关闭 kibana
ps -ef | grep node | grep -v grep
elastic 2077 1206 6 15:17 pts/0 00:01:24 ./../node/bin/node ./../src/cli/distkill -9 2077
5️⃣ 注意
- 将
elasticsearch.pingTimeout和elasticsearch.requestTimeout修改为较大的值,如是使用默认的参数3000则在启动时可能是因为机器性能问题导致报错FATAL TimeoutError: Request timed out“请求超时”- 注意修改
elasticsearch参数cluster.initial_master_nodes内容,如果这里没有配置,则会导致 ES 健康检查有问题,访问kibana时提示 “{“error”:{“root_cause”:[{“type”:“master_not_discovered_exception”,“reason”:null}],“type”:“master_not_discovered_exception”,“reason”:null},“status”:503}”
6️⃣ 浏览器访问
浏览器输入 kibana 的 ip:host 即可访问
在kibana6.7之后就开始支持中文,所以这里在配置文件中配置了 i18n.locale: “zh-CN” 参数,界面显示则为中文
5. kibana 使用教程
…未完待续
相关文章:
Elasticsearch 部署学习
文章目录 Elasticsearch 部署学习1. 单节点部署 elasticsearch1.1 部署 jdk1.2 下载 elasticsearch1.3 上传文件并修改配置文件1.4 启动1.5 问题总结1.6 浏览器验证 2. 集群部署 elasticsearch3. 常用命令4. Elasticsearch kibana安装:one: 参考部署文档:two: 下载对应版本的安…...
nodejs 如何在npm发布自己的包 <记录>
一、包结构 必要结构: 一个包对应一个文件夹(文件夹名不是包名,但最好与包名保持一致,包名以package.json中的name为主)包的入口文件index.js包的配置文件package.json包的说明文档README.md 二、需要说明的文件 1.配…...

移植RTOS的大体思路
最首先当然是去官网看看是不是已经支持目标芯片啦,没有的话,就需要自己手动移植了 获取源码 一般可以从rtos官网或者GitHub上获取源码 确认源码结构 这种有官方文档说明,需要修改的一般都是BSP和libcpu相关文件夹中的内容 CPU架构移植 …...

FPGA到底是什么?
首先只是凭自己浅略的了解,FPGA好像也是涉及到了开发板,单片机之类的东西,和嵌入式十分相似,但是比嵌入式更高级的东西。 肯定有很多小伙伴如我一样,只是听说过FPGA,听别人说的传呼其神,那么它到…...

算法-单词搜索 II
算法-单词搜索 II 1 题目概述 1.1 题目出处 https://leetcode.cn/problems/word-search-ii/description/?envTypestudy-plan-v2&envIdtop-interview-150 1.2 题目描述 2 DFS 2.1 解题思路 每个格子往上下左右四个方向DFS,拼接后的单词如果在答案集中&…...
怒刷LeetCode的第15天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:哈希表双向链表 方法二:TreeMap 方法三:双哈希表 第二题 题目来源 题目内容 解决方法 方法一:二分查找 方法二:线性搜索 方法三:Arrays类的b…...
Android开发MVP架构记录
Android开发MVP架构记录 安卓的MVP(Model-View-Presenter)架构是一种常见的软件设计模式,用于帮助开发者组织和分离应用程序的不同组成部分。MVP架构的目标是将应用程序的业务逻辑(Presenter)、用户界面(V…...

day2作业
1,输入两个数,完成两个数的加减乘除 #输入两个数,完成两个数的加减乘除 num1int(input("请输入第一个数:")) num2int(input("请输入第二个数:")) print(str(num1)str(num2)str(num1num2)) print(str(num1)-str(num2)str…...

Python办公自动化之Word
Python操作Word 1、Python操作Word概述2、写入Word2.1、标题2.2、章节与段落2.3、字体与引用2.4、项目列表2.5、分页2.6、表格2.7、图片3、读取Word3.1、读取文档3.2、读取表格4、将Word表格保存到Excel5、格式转换5.1、Doc转Docx5.2、Word转PDF1、Python操作Word概述 python-d…...
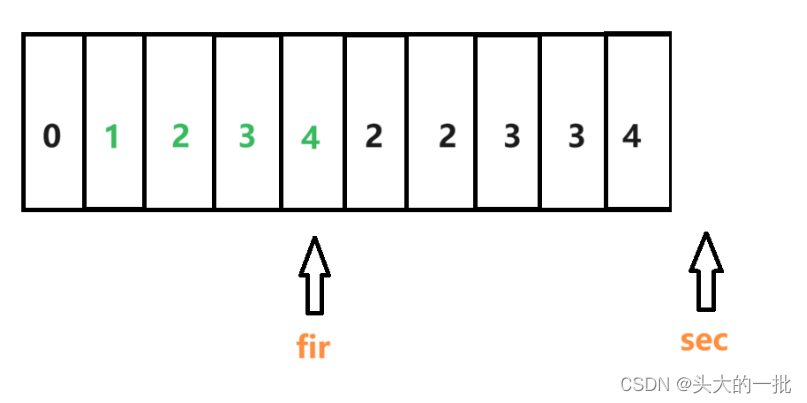
力扣26:删除有序数组中的重复项
26. 删除有序数组中的重复项 - 力扣(LeetCode) 题目: 给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 …...
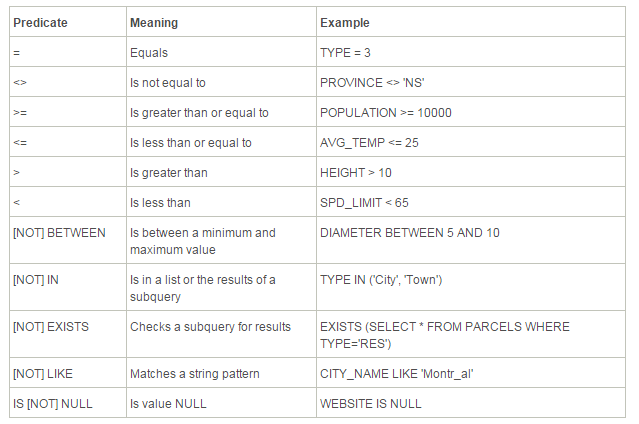
基于C#的AE二次开发之IQueryFilter接口、ISpatialFilter接口、IQueryDef 接口的查询接口的介绍
一、开发环境 开发环境为ArcGIS Engine 10.2与Visual studio2010。在使用ArcEngine查询进行查询的时候主要使用三种查询接口IQueryFilter(属性查询) 、ISpatialFilter(空间查询) 、IQueryDef (多表查询) 那…...

Oracle 11g RAC部署笔记
搭了三次才搭好,要记录一下。 1. Oracle 11g RAC部署的相关步骤以及需要的包,可以参考这里。 Oracle 11g RAC部署_12006142的技术博客_51CTO博客Oracle 11g RAC部署,Oracle11gRAC部署操作环境:CentOS7.4Oracle11.2.0.4一、主机网…...
)
Redis 字符串操作实战(全)
目录 SET 存入键值对 SETNX SETEX SETBIT SETRANGE MSET 批量存入键值对 MSETNX PSETEX BITCOUNT 计算值中1的数量 BITOP 与或非异或操作 DECR 减1 DECRBY APPEND 追加 INCR 自增 INCRBY INCRBYFLOAT GET 取值 GETBIT GETRANGE GETSET 取旧值赋新值 MGET …...

python LeetCode 88 刷题记录
题目 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并…...

基于 Socket 网络编程
基于 Socket 网络编程 前言一、基于Socket的网络通信传输(传输层)二、UDP 的数据报套接字编程1、UDP 套接字编程 API2、使用 UDP Socket 实现简单通信 三、TCP 流套接字编程1、TCP 流套接字编程 API2、使用 TCP Socket 实现简单通信3、使用 Tcp 协议进行…...

关于C#.Net网页跳转的7种方法
一、目前在ASP.NET中页面传值共有这么几种方式:1.Response.Redirect("http://www.hao123.com",false); 目标页面和原页面可以在2个服务器上,可输入网址或相对路径。后面的bool值为是否停止执行当前页。 跳转向新的页面,原窗口被代…...
使用acme.sh申请免费ssl证书(Cloudflare方式API自动验证增加DNS Record到期证书到期自动重新申请)
下载acme.sh curl https://get.acme.sh | sh -s emailmyexample.comcd ~/.acme.sh/获取Cloudflare密钥 Preferences | Cloudflare 登录选择账户详情选择API Token选择创建令牌选择区域DNS模板,并设置编辑写入权限生成并复制令牌备用回到首页概览界面下部获取账号…...

【C语言】进阶——结构体+枚举+联合
①前言: 在之前【C语言】初阶——结构体 ,简单介绍了结构体。而C语言中结构体的内容还有更深层次的内容。 一.结构体 结构体(struct)是由一系列具有相同类型或不同类型的数据项构成的数据集合,这些数据项称为结构体的成员。 1.结构体的声明 …...

Socket编程基础(1)
目录 预备知识 socket通信的本质 认识TCP协议和UDP协议 网络字节序 socket编程流程 socket编程时常见的函数 服务端绑定 整数IP和字符串IP 客户端套接字的创建和绑定 预备知识 理解源IP和目的IP 源IP指的是发送数据包的主机的IP地址,目的IP指的是接收数据包…...
无线通信——Mesh自组网的由来
阴差阳错找到了一个工作,是做无线通信的,因为无线设备采用Mesh,还没怎么接触过,网上搜索下发现Mesh的使用场景不多,大部分都是用在家里路由器上面。所以写了片关于Mesh网的文档。Mesh网可应用在无网络区域的地方&#…...

Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰 基础教程类,针对经常遇到 Claude Code 封号或 Tok…...
)
为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单)
更多请点击: https://codechina.net 第一章:为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单) 我们对127条在Perplexity平台中返回空结果、过时答案或完全偏离编程意图的用户Qu…...

别再只会F10/F11了!Qt Creator调试实战:用条件断点和数据断点精准定位UI卡顿
Qt Creator高级调试实战:用条件断点和数据断点精准解决UI卡顿问题 在开发数据密集型Qt应用程序时,最令人头疼的莫过于那些难以复现的UI卡顿问题。当用户抱怨"点击按钮后界面会冻结几秒"时,传统的逐行调试(F10/F11)往往如同大海捞针…...

Linux内核中断处理机制深度解析:中断嵌套与异常打断原理
1. 中断处理中的“打断”迷思:一个内核老兵的深度剖析在Linux内核开发与调试的深水区里,中断处理机制就像一把双刃剑,它赋予了系统响应外部事件的实时性,却也带来了复杂性与不确定性。其中,一个经典且常被误解的问题就…...

Google关键词能带来多少流量?大词和长尾词的真实流量比例
一家销售软件的公司耗费六个月将“CRM”排至谷歌首页第五名。该词每月产生50万次搜索。网页获得2100次点击。跳出率高达89%。停留时间仅12秒。投入资金4万美元。获得零份询盘。做“外贸企业定制管理软件”排名首页第一。此词汇每月搜索量150次。每月收获62次点击。停留时间4分3…...

OpenPnP玩家必看:深度解析松下DP102传感器与贴片机真空系统的联动原理与调优
OpenPnP系统集成实战:DP102负压传感器与真空控制回路的科学调优 在DIY贴片机的世界里,OpenPnP系统就像一位不知疲倦的指挥家,而DP102负压传感器则是这支精密乐队中的关键乐手。当吸嘴与元器件相遇的瞬间,背后是一场由气压数据驱动…...

【亲测免费】 提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐
提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐 【下载地址】AccessDatabaseEngine_X642010安装包 本仓库提供了一个名为 AccessDatabaseEngine_X64_2010.rar 的资源文件下载。该文件是 Microsoft Access 2010 数据库引擎的可再发行程序包,…...

Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时
更多请点击: https://codechina.net 第一章:Perplexity突然禁用Chrome扩展权限:技术团队未公开的5项合规改造倒计时,开发者窗口仅剩72小时 Perplexity AI 技术团队于 2024 年 6 月 18 日凌晨通过后台策略悄然撤销了所有第三方 Ch…...

如何快速安全弹出USB设备:Windows用户的完整USB设备管理工具指南
如何快速安全弹出USB设备:Windows用户的完整USB设备管理工具指南 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portab…...
)
蓝桥杯嵌入式备赛:手把手搞定AT24C02 EEPROM读写(附CubeMX配置与常见Bug修复)
蓝桥杯嵌入式竞赛实战:AT24C02 EEPROM高效读写全攻略 1. 赛前准备:理解I2C与EEPROM的核心机制 在蓝桥杯嵌入式竞赛中,AT24C02这类EEPROM器件常被用作非易失性存储解决方案。与常见Flash存储器不同,EEPROM支持字节级擦写…...