扩散模型:DDPM代码的学习(基于minist数据集)
文章目录
- 序言
- 一参考资料
- ①代码来源
- ②相关概念理解
- ③公式推导及训练流程讲解
- ④搜索问题的网站
- ⑤模型运行的环境
- 二代码解读
- ①模型
- ②训练
- ③测试
- 三主要训练过程的解析
序言
本文主要对一个基于minist数据集搭建的DDPM模型代码中各个模块的含义进行解析,初步记录了自己了解扩散模型的一个过程,为后续的进一步学习打基础。文中的错误之处还望大家批评指正
一参考资料
①代码来源
参考的代码来源
②相关概念理解
超详细的扩散模型(Diffusion Models)原理+代码
③公式推导及训练流程讲解
DDPM1
DDPM2
④搜索问题的网站
geekgpt
此网站可以对代码进行注释,对公式推导的流程进行解释,利用的好可以帮助我们更好的理解我们所的遇到的大部分问题
⑤模型运行的环境
本文是在google drive的colab中运行的
colab的部署过程可以参考以下内容:Colab 实用教程
二代码解读
①模型
import os
import math
from abc import abstractmethodimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
def timestep_embedding(timesteps, dim, max_period=10000):"""Create sinusoidal timestep embeddings.Args:timesteps (Tensor): a 1-D Tensor of N indices, one per batch element. These may be fractional.dim (int): the dimension of the output.max_period (int, optional): controls the minimum frequency of the embeddings. Defaults to 10000.Returns:Tensor: an [N x dim] Tensor of positional embeddings."""# 计算嵌入向量的一半维度half = dim // 2# 计算频率,用来生成正弦和余弦成分freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(device=timesteps.device)# 计算角度参数,用于生成正弦和余弦成分#进行维度的扩充,将1*step转化为step*1 然后和1*half进行矩阵运算,将数据的维度扩充到了half维度(half为偶数)args = timesteps[:, None].float() * freqs[None]# 生成正弦和余弦成分,然后连接它们以形成嵌入向量embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)# 如果维度是奇数,添加一个额外的零维度if dim % 2:embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)# 返回时间步嵌入向量return embeddingclass TimestepBlock(nn.Module):"""Any module where forward() takes timestep embeddings as a second argument."""@abstractmethoddef forward(self, x, t):"""Apply the module to `x` given `t` timestep embeddings."""passclass TimestepEmbedSequential(nn.Sequential, TimestepBlock):"""A sequential module that passes timestep embeddings to the children that support it as an extra input."""def forward(self, x, t):for layer in self:if isinstance(layer, TimestepBlock):x = layer(x, t)else:x = layer(x)return x# layer 是 TimestepEmbedSequential 类中的每个子模块(layer)的引用。在这个循环中,我们遍历了 TimestepEmbedSequential 类中的每个子模块,并对其进行操作。如果子模块是 TimestepBlock 的实例,则调用其 forward() 方法,并将输入数据 x 和时间步骤嵌入向量 t 传递给它;否则,我们只是将输入数据 x 传递给子模块#参数channels指定了归一化层的通道数,而nn.GroupNorm的第一个参数32表示将输入数据的通道分成32个子组,每个子组内的特征将被独立地归一化,组归一化的主要作用是解决深度神经网络中的内部协变量偏移问题,提高模型的训练稳定性,使其更适合处理不同批量大小和高分辨率数据,同时也有助于模型的泛化能力。
def norm_layer(channels):return nn.GroupNorm(32, channels)class ResidualBlock(TimestepBlock):def __init__(self, in_channels, out_channels, time_channels, dropout):super().__init__()self.conv1 = nn.Sequential(norm_layer(in_channels),nn.SiLU(),nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))# pojection for time step embeddingself.time_emb = nn.Sequential(nn.SiLU(),nn.Linear(time_channels, out_channels))self.conv2 = nn.Sequential(norm_layer(out_channels),nn.SiLU(),nn.Dropout(p=dropout),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))if in_channels != out_channels:self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1)else:self.shortcut = nn.Identity()def forward(self, x, t):"""`x` has shape `[batch_size, in_dim, height, width]``t` has shape `[batch_size, time_dim]`"""h = self.conv1(x)# Add time step embeddingsh += self.time_emb(t)[:, :, None, None]h = self.conv2(h)return h + self.shortcut(x)class AttentionBlock(nn.Module):def __init__(self, channels, num_heads=1):"""Attention block with shortcutArgs:channels (int): channelsnum_heads (int, optional): attention heads. Defaults to 1."""super().__init__()self.num_heads = num_headsassert channels % num_heads == 0self.norm = norm_layer(channels)self.qkv = nn.Conv2d(channels, channels * 3, kernel_size=1, bias=False)self.proj = nn.Conv2d(channels, channels, kernel_size=1)def forward(self, x):B, C, H, W = x.shapeqkv = self.qkv(self.norm(x))#将模型的维度扩充3倍q, k, v = qkv.reshape(B*self.num_heads, -1, H*W).chunk(3, dim=1)scale = 1. / math.sqrt(math.sqrt(C // self.num_heads))# 计算了一个用于缩放注意力分数的标度因子(scaling factor)。这个标度因子通常用于控制注意力分数的大小,以避免过大的数值,有助于稳定训练过程attn = torch.einsum("bct,bcs->bts", q * scale, k * scale)#这一行代码执行了一个张量乘法操作,并计算了注意力分数(attention scores)attn = attn.softmax(dim=-1)#进行 softmax 归一化,以确保每个位置的分数都在 [0, 1] 范围内h = torch.einsum("bts,bcs->bct", attn, v)#torch.einsum 函数是一个强大的张量运算工具,它允许用户根据一种命名约定来指定张量的操作,以实现高效的张量操作和组合。它的基本语法是#result = torch.einsum("ij,jk->ik", A, B)#这将计算两个矩阵 A 和 B 的矩阵乘法。字符串 "ij,jk->ik" 描述了两个矩阵的操作,其中 "ij" 表示 A 的行和列,而 "jk" 表示 B 的行和列,最终得到一个矩阵#其中 attn 和 v 是输入张量,具有以下维度:#attn 的形状为 (batch_size, sequence_length, num_heads),#其中 batch_size 表示批处理大小,sequence_length 表示序列长度,num_heads 表示注意力头的数量。#v 的形状为 (batch_size, sequence_length, value_dim),其中 value_dim 表示每个注意力值的维度。#输出张量的形状为 (batch_size, sequence_length, value_dim),它表示了加权和的结果,其中每个元素#都是通过将 attn 中的权重应用到 v 中的相应部分来计算的。#这种操作通常用于多头注意力机制中,其中 attn 包含了注意力分数(或权重),v 包含了值,而输出则是根#据权重对值进行加权求和的结果。这有助于模型在自注意力机制中将不同的信息聚合到输出中。
#用于执行多头注意力操作,将注意力权重应用于值并计算加权h = h.reshape(B, -1, H, W)h = self.proj(h)return h + x# 定义一个名为Upsample的自定义神经网络模块
class Upsample(nn.Module):def __init__(self, channels, use_conv):super().__init__()# 初始化函数,接受两个参数:channels表示输入通道数,use_conv表示是否使用卷积层# 将use_conv标记存储在模块中,以便后续的操作可以根据该标记来选择不同的处理方式self.use_conv = use_conv # 如果use_conv为True,即选择使用卷积层if use_conv:# 创建一个卷积层,输入通道数和输出通道数都为channels# 使用3x3的卷积核(kernel_size=3),并在输入周围填充1个像素(padding=1)self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1)# 定义模块的前向传播函数,接受输入张量x作为参数def forward(self, x):# 使用F.interpolate函数对输入张量x进行上采样# 上采样的尺度因子为2(scale_factor=2)(将原图像的每个维度放大2倍),采用最近邻插值方式(mode="nearest")x = F.interpolate(x, scale_factor=2, mode="nearest")# 如果use_conv为True,即选择使用卷积层if self.use_conv:# 将上采样后的张量x输入到卷积层self.conv中进行卷积操作x = self.conv(x)# 返回处理后的张量x作为模块的输出return xclass Downsample(nn.Module):
#上采样和下采样的初始化都是输入通道数,和是否用卷积,如果不用卷积那么就用池化层进行下采样,如果用卷积,那么就用卷积核,步长为2去达到下采样的效果def __init__(self, channels, use_conv):super().__init__()self.use_conv = use_convif use_conv:self.op = nn.Conv2d(channels, channels, kernel_size=3, stride=2, padding=1)else:#利用平均池化层将数据缩小为原来的1/2self.op = nn.AvgPool2d(stride=2)def forward(self, x):return self.op(x)class UNetModel(nn.Module):"""The full UNet model with attention and timestep embedding"""def __init__(self,in_channels=3, # 输入通道数,默认为3(适用于RGB图像)model_channels=128, # 模型通道数,默认为128out_channels=3, # 输出通道数,默认为3(适用于RGB图像)num_res_blocks=2, # 残差块的数量,默认为2attention_resolutions=(8, 16), # 注意力分辨率的元组,默认为(8, 16)dropout=0, # Dropout概率,默认为0(不使用Dropout)channel_mult=(1, 2, 2, 2), # 通道倍增因子的元组,默认为(1, 2, 2, 2)conv_resample=True, # 是否使用卷积重采样,默认为Truenum_heads=4 # 注意力头的数量,默认为4):super().__init__()# 初始化模型的各种参数self.in_channels = in_channelsself.model_channels = model_channelsself.out_channels = out_channelsself.num_res_blocks = num_res_blocksself.attention_resolutions = attention_resolutionsself.dropout = dropoutself.channel_mult = channel_multself.conv_resample = conv_resampleself.num_heads = num_heads# 时间嵌入(用于处理时间信息的嵌入)time_embed_dim = model_channels * 4self.time_embed = nn.Sequential(nn.Linear(model_channels, time_embed_dim),nn.SiLU(),nn.Linear(time_embed_dim, time_embed_dim),)# 下采样块#所有的模块都是先定义,然后通过迭代的方式往模块里面加东西self.down_blocks = nn.ModuleList([TimestepEmbedSequential(nn.Conv2d(in_channels, model_channels, kernel_size=3, padding=1))])down_block_chans = [model_channels] # 存储下采样块每一阶段的通道数ch = model_channels # 当前通道数初始化为模型通道数 初始为128ds = 1 # 下采样的倍数,初始值为1# 遍历不同阶段的下采样块#channel_mult模块为(1,2,2,2),下采样块每层的块数for level, mult in enumerate(channel_mult):#num_res_blocks为残差块的数量,表示每块需要的残差快的数量for _ in range(num_res_blocks):layers = [#ch为输入通道数,mult * model_channels为需要输出的维度数,time_embed_dim为时间嵌入的维度ResidualBlock(ch, mult * model_channels, time_embed_dim, dropout)#初始化剩余块,让我们后续能用forward函数将时间嵌入到x中]ch = mult * model_channels#ds为一个值,一开始为1,然后每次乘以2,这里如果ds为8或者16时需要加上一个注意力模块if ds in attention_resolutions:layers.append(AttentionBlock(ch, num_heads=num_heads))#将加入了残差快和注意力块的层加入下采样块当中self.down_blocks.append(TimestepEmbedSequential(*layers))#记录每一层采样的通道数down_block_chans.append(ch)if level != len(channel_mult) - 1: # 最后一个阶段不使用下采样#这里由于之前的ch*2 所以,下采样后又恢复到了 ch,所以,我们在下采样通道中加入的chself.down_blocks.append(TimestepEmbedSequential(Downsample(ch, conv_resample)))down_block_chans.append(ch)ds *= 2#整个流程的格式变换,128,128,64;256,256,128;256,256;# 中间块#中间块就是一个残差块+注意力块+残差块self.middle_block = TimestepEmbedSequential(ResidualBlock(ch, ch, time_embed_dim, dropout),AttentionBlock(ch, num_heads=num_heads),ResidualBlock(ch, ch, time_embed_dim, dropout))# 上采样块self.up_blocks = nn.ModuleList([])#反过来计算通道的情况(2,2,2,1)for level, mult in list(enumerate(channel_mult))[::-1]:#反向时残差块的数目为3for i in range(num_res_blocks + 1):layers = [ResidualBlock(ch + down_block_chans.pop(),model_channels * mult,time_embed_dim,dropout)]ch = model_channels * multif ds in attention_resolutions:layers.append(AttentionBlock(ch, num_heads=num_heads))#如果level不为0,并且,i为2时(最后一块时),进行上采样if level and i == num_res_blocks:layers.append(Upsample(ch, conv_resample))ds //= 2self.up_blocks.append(TimestepEmbedSequential(*layers))# 输出层#只是一个正则化,激活后的再一次不改变通道数的卷积self.out = nn.Sequential(norm_layer(ch),nn.SiLU(),nn.Conv2d(model_channels, out_channels, kernel_size=3, padding=1),)def forward(self, x, timesteps):"""Apply the model to an input batch.Args:x (Tensor): [N x C x H x W]timesteps (Tensor): a 1-D batch of timesteps.Returns:Tensor: [N x C x ...]"""#记录每次下采样得到结果,用于后面上采样的copy and crophs = []# 时间步嵌入#利用timesteps参数,计算时间步的嵌入#首先用timestep_embedding,将时间序列timesteps(1*n)转化为(n*model_channels)#然后用time_embed将之前的n*model_channels转化为 n*time_embed_dim(也就是原来的mocel_channels*4)emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))#最终得到一个时间步嵌入的矩阵# 下采样阶段h = xfor module in self.down_blocks:#每次用时间步嵌入的矩阵信息emb,更新并记录每次的hh = module(h, emb)hs.append(h)# 中间阶段h = self.middle_block(h, emb)# 上采样阶段for module in self.up_blocks:cat_in = torch.cat([h, hs.pop()], dim=1)h = module(cat_in, emb)return self.out(h)#线性β,只是等距的值
def linear_beta_schedule(timesteps):"""beta schedule"""scale = 1000 / timestepsbeta_start = scale * 0.0001beta_end = scale * 0.02#等距生成timesteps个数值,作为β的取值return torch.linspace(beta_start, beta_end, timesteps, dtype=torch.float64)#实现了一个余弦学习率调度
#timesteps: 这是一个整数参数,指定生成渐变序列的时间步数。
#s: 这是余弦调度的一个超参数,控制余弦曲线的形状。默认值为0.008。
def cosine_beta_schedule(timesteps, s=0.008):"""cosine scheduleas proposed in https://arxiv.org/abs/2102.09672"""steps = timesteps + 1x = torch.linspace(0, timesteps, steps, dtype=torch.float64)#alphas_cumprod: 这个步骤计算了一个余弦曲线的累积乘积,并且通过缩放将其限制在0到1之间。这个曲线的形状由s参数控制。alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * math.pi * 0.5) ** 2alphas_cumprod = alphas_cumprod / alphas_cumprod[0]#betas: 计算了渐变的beta值序列,通过计算相邻时间步的alphas_cumprod之间的差异。betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])#最后,将beta值序列裁剪到区间[0, 0.999]之间,以确保其在有效范围内。return torch.clip(betas, 0, 0.999)class GaussianDiffusion:def __init__(self,timesteps=1000, # 初始化函数,设置默认时间步数为1000beta_schedule='linear' # 初始化函数,设置默认的beta调度为'linear'):self.timesteps = timesteps # 存储时间步数# 根据选择的beta调度类型,生成beta值的序列if beta_schedule == 'linear':betas = linear_beta_schedule(timesteps)elif beta_schedule == 'cosine':betas = cosine_beta_schedule(timesteps)else:raise ValueError(f'unknown beta schedule {beta_schedule}')self.betas = betas # 存储beta值序列# 计算alpha值(1 - beta)和alpha的累积乘积(1,2,3)变为(1,2,6)self.alphas = 1. - self.betasself.alphas_cumprod = torch.cumprod(self.alphas, axis=0)#F.pad(a,b,c)函数,在a向量的最前面和最后面分别添加b个c元素self.alphas_cumprod_prev = F.pad(self.alphas_cumprod[:-1], (1, 0), value=1.)#这个操作的目的通常是为了在某些计算中需要使用 self.alphas_cumprod_prev 作为一个与 self.alphas_cumprod 相关的中间变量。在这种情况下,添加一个1作为起始值可以确保计算的正确性。# calculations for diffusion q(x_t | x_{t-1}) and others#计算一些用于不同公式的其他变量self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - self.alphas_cumprod)self.log_one_minus_alphas_cumprod = torch.log(1.0 - self.alphas_cumprod)self.sqrt_recip_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod)self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod - 1)# calculations for posterior q(x_{t-1} | x_t, x_0)self.posterior_variance = (self.betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))# below: log calculation clipped because the posterior variance is 0 at the beginning# of the diffusion chain#用于存储后验分布的对数方差self.posterior_log_variance_clipped = torch.log(self.posterior_variance.clamp(min =1e-20))#后验均值的系数1self.posterior_mean_coef1 = (self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod))#后验均值的系数2self.posterior_mean_coef2 = ((1.0 - self.alphas_cumprod_prev)* torch.sqrt(self.alphas)/ (1.0 - self.alphas_cumprod))def _extract(self, a, t, x_shape):# 辅助函数:从a中提取与时间步t对应的参数# get the param of given timestep tbatch_size = t.shape[0]out = a.to(t.device).gather(0, t).float()#将输出的out的形状改为只有batch_size,其余维度都为1out = out.reshape(batch_size, *((1,) * (len(x_shape) - 1)))return outdef q_sample(self, x_start, t, noise=None):# forward diffusion (using the nice property): q(x_t | x_0)if noise is None:noise = torch.randn_like(x_start)#获得第t步的参数数据sqrt_alphas_cumprod_t = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape)sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)#然后和随机产生的噪声进行按比例拟合达到加噪的效果return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noisedef q_mean_variance(self, x_start, t):# Get the mean and variance of q(x_t | x_0).#x_start为需要输入的图像mean = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_startvariance = self._extract(1.0 - self.alphas_cumprod, t, x_start.shape)log_variance = self._extract(self.log_one_minus_alphas_cumprod, t, x_start.shape)return mean, variance, log_variancedef q_posterior_mean_variance(self, x_start, x_t, t):# Compute the mean and variance of the diffusion posterior: q(x_{t-1} | x_t, x_0)posterior_mean = (self._extract(self.posterior_mean_coef1, t, x_t.shape) * x_start+ self._extract(self.posterior_mean_coef2, t, x_t.shape) * x_t)posterior_variance = self._extract(self.posterior_variance, t, x_t.shape)posterior_log_variance_clipped = self._extract(self.posterior_log_variance_clipped, t, x_t.shape)return posterior_mean, posterior_variance, posterior_log_variance_clipped#反向预测,对于输入的x_t反向去噪noisedef predict_start_from_noise(self, x_t, t, noise):# compute x_0 from x_t and pred noise: the reverse of `q_sample`return (self._extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -self._extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise)#最终返回预测的均值,方差def p_mean_variance(self, model, x_t, t, clip_denoised=True):# compute predicted mean and variance of p(x_{t-1} | x_t)# predict noise using model#unet模块学习加入了时间t(这里的t为所有值为t的向量)信息的x_t,通过参数调整,最终变为我们的反向预测噪声pred_noise = model(x_t, t)# get the predicted x_0: different from the algorithm2 in the paper#从反向预测噪声和x_t预测我们的开始值(去噪)x_recon = self.predict_start_from_noise(x_t, t, pred_noise)#将 x_recon 张量中的元素限制在 -1.0 到 1.0 的范围内,任何小于 -1.0 的元素都被设置为 -1.0,任何大于 1.0 的元素都被设置为 1.0。if clip_denoised:x_recon = torch.clamp(x_recon, min=-1., max=1.)model_mean, posterior_variance, posterior_log_variance = self.q_posterior_mean_variance(x_recon, x_t, t)return model_mean, posterior_variance, posterior_log_variance@torch.no_grad()#从最后一步的随机噪声向前进行去噪采样def p_sample(self, model, x_t, t, clip_denoised=True):# denoise_step: sample x_{t-1} from x_t and pred_noise# predict mean and variancemodel_mean, _, model_log_variance = self.p_mean_variance(model, x_t, t, clip_denoised=clip_denoised)noise = torch.randn_like(x_t)# no noise when t == 0nonzero_mask = ((t != 0).float().view(-1, *([1] * (len(x_t.shape) - 1))))#判断t是否为0,是0则为0,非0则为1# compute x_{t-1}pred_img = model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noisereturn pred_img@torch.no_grad()def p_sample_loop(self, model, shape):# denoise: reverse diffusionbatch_size = shape[0]device = next(model.parameters()).device# start from pure noise (for each example in the batch)img = torch.randn(shape, device=device)imgs = []#tqdm是python中的一个库,用于创建进度条,以可视化地显示循环的进度。它可以帮助你了解循环还需要多长时间完成,特别是在处理大数据集或长时间运行的任务时非常有用。total是定义总的步数#采样传入的image为随机生成的噪声,也就代表了最后的x_t时的噪声for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):#torch.full((batch_size,), i)创建一个值都为i的向量img = self.p_sample(model, img, torch.full((batch_size,), i, device=device, dtype=torch.long))imgs.append(img.cpu().numpy())return imgs@torch.no_grad()def sample(self, model, image_size, batch_size=8, channels=3):# sample new imagesreturn self.p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))def train_losses(self, model, x_start, t):# compute train losses# generate random noise# 随机生成一个正态分布noise = torch.randn_like(x_start)# get x_t#输入的图像作为x_start,正太分布噪声采用我们自己随机生成的#通过前向加噪,对输入图像加入t时刻的噪声(前向加入噪的噪声作为基准噪声)x_noisy = self.q_sample(x_start, t, noise=noise)#通过unet,对前向生成的噪声和t,生成我们的预测噪声predicted_noise = model(x_noisy, t)#损失函数就是生成的噪声和预测的噪声进行损失的计算loss = F.mse_loss(noise, predicted_noise)return loss
看看效果
from PIL import Image
import requests
import matplotlib.pyplot as plt
from torchvision import datasets, transforms%matplotlib inline
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# image = Image.open("/data/000000039769.jpg")image_size = 128
transform = transforms.Compose([transforms.Resize(image_size),transforms.CenterCrop(image_size),transforms.PILToTensor(),transforms.ConvertImageDtype(torch.float),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])x_start = transform(image).unsqueeze(0)gaussian_diffusion = GaussianDiffusion(timesteps=500)plt.figure(figsize=(16, 8))
for idx, t in enumerate([0, 50, 100, 200, 499]):#根据x_start和t生成从0~t加噪后的结果x_noisy = gaussian_diffusion.q_sample(x_start, t=torch.tensor([t]))#squeeze(): 这是一个挤压操作,它用于去除输入张量 中维度为1的维度,以简化张量的形状#permute(1, 2, 0): 这是一个维度置换操作,将第一个维度移到最后一个维度#最后对每个张量+1然后乘以127.5(原来的数为-1~1,+1变为0~2,x127.5变为0~255)noisy_image = (x_noisy.squeeze().permute(1, 2, 0) + 1) * 127.5noisy_image = noisy_image.numpy().astype(np.uint8)plt.subplot(1, 5, 1 + idx)plt.imshow(noisy_image)plt.axis("off")plt.title(f"t={t}")

②训练
准备数据集
batch_size = 64
timesteps = 500transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5])
])# use MNIST dataset
dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
模型
# define model and diffusion
device = "cuda" if torch.cuda.is_available() else "cpu"
#这里初始化unet模块,输入输出的channel为1.注意力模块这里没有加
model = UNetModel(in_channels=1,model_channels=96,out_channels=1,channel_mult=(1, 2, 2),attention_resolutions=[]
)
model.to(device)
#初始化高斯扩散模型(只初始化了需要迭代的步骤为500步),时间步默认为线性生成的时间步
gaussian_diffusion = GaussianDiffusion(timesteps=timesteps)
#优化器对unet模型的参数进行优化
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4)
开始训练
epochs = 10
for epoch in range(epochs):for step, (images, labels) in enumerate(train_loader):optimizer.zero_grad()batch_size = images.shape[0]images = images.to(device)# sample t uniformally for every example in the batch#随机生成batch_size个(0~timesteps)的t(对于每次训练数据,我们是随机对第其中一个t时刻的加噪过程进行训练和预测)t = torch.randint(0, timesteps, (batch_size,), device=device).long()#输入unet模型,样本图像,和t计算损失loss = gaussian_diffusion.train_losses(model, images, t)#先随机生成一个正太分布(作为我们的加噪的正太分布)#将输入的图像images作为x_start#通过前向加噪,对输入的图像加入t时刻的噪声(此时生成的噪声作为我们的基准噪声)#通过unet,输入上一步的基准噪声,和时间步t,我们进行对基准噪声的预测#损失函数计算的就是我们的预测噪声和基准噪声之间的差距,采用的是每个像素点的均方差的计算if step % 200 == 0:print("Loss:", loss.item())#每次训练模型都是让我们的unet模型的参数进行优化,让我们的unet模型最终可以根据给定一个加噪了t次后的图像,和t,去生成一个对于这个基准噪声的预测。(也就是,我们的unet模型能生成和加入的噪声十分相似的噪声)loss.backward()optimizer.step()
Loss: 1.2879185676574707
Loss: 0.05010918155312538
Loss: 0.037472739815711975
Loss: 0.03259456530213356
Loss: 0.03238191455602646
Loss: 0.03526081144809723
Loss: 0.019976193085312843
Loss: 0.026588361710309982
Loss: 0.02474384568631649
Loss: 0.025454936549067497
Loss: 0.01776018552482128
Loss: 0.028406977653503418
Loss: 0.026149388402700424
Loss: 0.023932695388793945
Loss: 0.0222737155854702
Loss: 0.025710856541991234
Loss: 0.026215054094791412
Loss: 0.02046349085867405
Loss: 0.02683963067829609
Loss: 0.023800114169716835
Loss: 0.024538405239582062
Loss: 0.021686285734176636
Loss: 0.019745750352740288
Loss: 0.02584003284573555
Loss: 0.026672476902604103
Loss: 0.023941144347190857
Loss: 0.03131483495235443
Loss: 0.018094774335622787
Loss: 0.025758417323231697
Loss: 0.025309113785624504
Loss: 0.0224548801779747
Loss: 0.021184200420975685
Loss: 0.01910235919058323
Loss: 0.024598510935902596
Loss: 0.024002162739634514
Loss: 0.0232978705316782
Loss: 0.016557812690734863
Loss: 0.019946767017245293
Loss: 0.020528556779026985
Loss: 0.01813691109418869
Loss: 0.020777976140379906
Loss: 0.021010225638747215
Loss: 0.02573891542851925
Loss: 0.02588081546127796
Loss: 0.016215061768889427
Loss: 0.025008078664541245
Loss: 0.01972994953393936
Loss: 0.021410418674349785
Loss: 0.024027982726693153
Loss: 0.021927889436483383
③测试
generated_images = gaussian_diffusion.sample(model, 28, batch_size=64, channels=1)
# generated_images: [timesteps, batch_size=64, channels=1, height=28, width=28]
sampling loop time step: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 500/500 [00:30<00:00, 16.61it/s]
# generate new images
fig = plt.figure(figsize=(12, 12), constrained_layout=True)
#并定义了一个网格布局,该布局包含 8 行和 8 列的子图
gs = fig.add_gridspec(8, 8)#[-1]表示生成图像的最后一个,也就是x0(最后生成的图片),将数组重新排列为8,8,28,28的形式
imgs = generated_images[-1].reshape(8, 8, 28, 28)
for n_row in range(8):for n_col in range(8):#将图像加入8*8网格对应的位置f_ax = fig.add_subplot(gs[n_row, n_col])#将图像的值变换到0~255进行可视化f_ax.imshow((imgs[n_row, n_col]+1.0) * 255 / 2, cmap="gray")f_ax.axis("off")

可以看到我们的扩散模型生成的图像与minist数据集还是非常相似的
展示降噪的过程
# show the denoise steps
fig = plt.figure(figsize=(12, 12), constrained_layout=True)
gs = fig.add_gridspec(16, 16)#也就是我们生成的generated_images是一个多维的矩阵,step,batchsize,28,28,1 ; 然后我们需要对第i个step过程取其中的第n_row个图片,然后去展示这个去噪的过程
for n_row in range(16):for n_col in range(16):f_ax = fig.add_subplot(gs[n_row, n_col])#t_idx计算为第几步的噪声,从500开始到0t_idx = (timesteps // 16) * n_col if n_col < 15 else -1#n_now为第n个图像img = generated_images[t_idx][n_row].reshape(28, 28)f_ax.imshow((img+1.0) * 255 / 2, cmap="gray")f_ax.axis("off")

三主要训练过程的解析

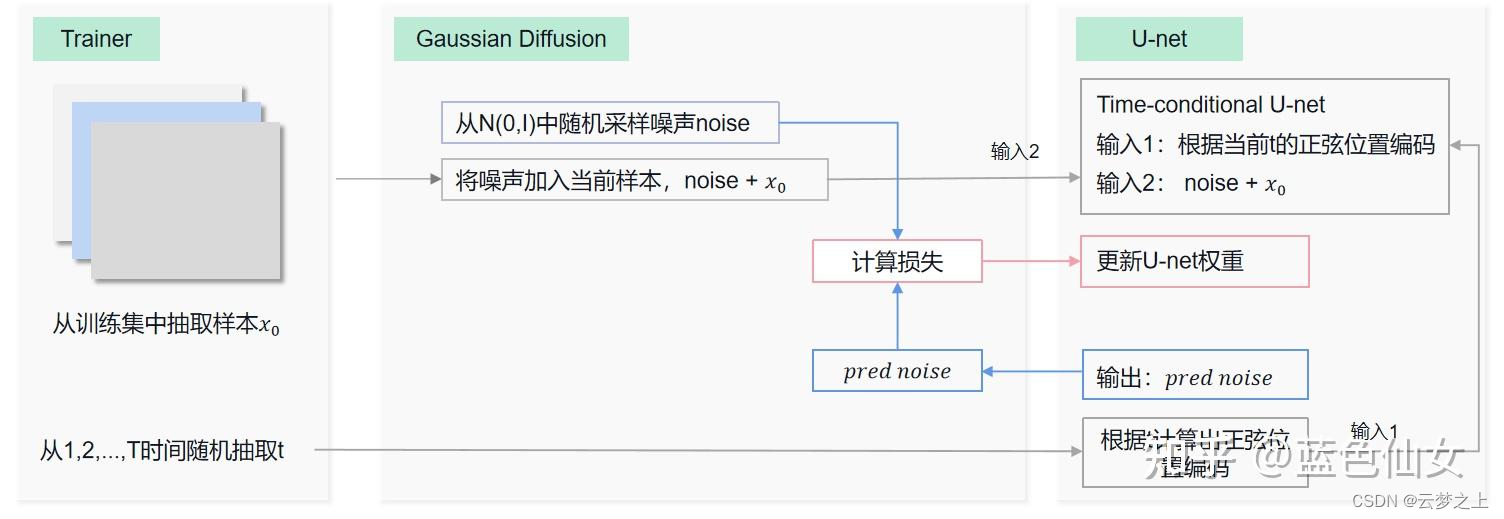

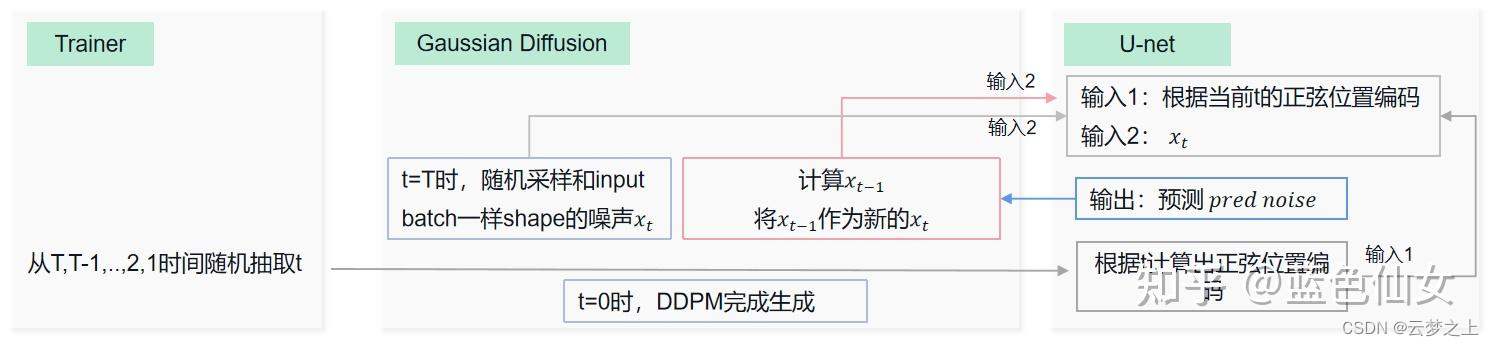
不好理解之处对于最后的sample阶段的取样过程,是如何从随机的噪声一步一步去噪恢复原图像的:
流程上讲:
如上图所示,每次第t时刻,我们首先将t时刻的噪声xt和t时刻位置的正弦编码输入unet网络,得到我们预测的噪声,然后经过对预测的噪声进行处理得到我们预测的均值和方差,然后通过参数重参化技巧,构建我们生成的预测去噪图像(这里我们每次得到的预测结果,是作为下一次新的t-1时刻的噪声xt-1),然后通过连续的迭代,最终生成初始x0时刻的图像(也就是我们最终的反向去噪图像)。
难点在于:
对于均值和方差的预测,以及预测图像的重构等过程的数学推导,可以先有个大概的印象,后续在慢慢攻克
相关文章:
扩散模型:DDPM代码的学习(基于minist数据集)
文章目录 序言一参考资料①代码来源②相关概念理解③公式推导及训练流程讲解④搜索问题的网站⑤模型运行的环境 二代码解读①模型②训练③测试 三主要训练过程的解析 序言 本文主要对一个基于minist数据集搭建的DDPM模型代码中各个模块的含义进行解析,初步记录了自…...

小程序-uniapp:URL Link / 适用于在移动端 从短信、邮件、微信外网页 等场景打开小程序任意页面
一、背景介绍 小程序URL Scheme、URL Link是微信小程序后台生成的一种地址,适用于从短信、邮件、微信外网页 等场景打开小程序任意页面。所以,适用性极强。可与微信扫码携带参数跳转到小程序指定页面技术互补 若在微信外打开,用户可以在浏览…...

干货 | 基于在线监控数据的非现场监管问题识别模型研究
以下内容整理自2023年夏季学期大数据能力提升项目《大数据实践课》同学们所做的期末答辩汇报。 我们汇报的题目是基于在线监控数据的非现场监管问题识别模型研究,我们的汇报将从五个部分展开。首先是项目背景说明,该项目是为了遏制企业逃避监管行为的发生…...
Spring Cloud Alibaba Gateway 简单使用
文章目录 Spring Cloud Alibaba Gateway1.Gateway简介2. 流量网关和服务网关的区别3. Spring Cloud Gateway 网关的搭建3.1 Spring Cloud Gateway 配置项的说明3.2 依赖导入3.3 配置文件 Spring Cloud Alibaba Gateway 1.Gateway简介 Spring Cloud Gateway是一个基于Spring F…...

两种fifo实现方式的差异
减少数据通路翻转来降低功耗: 以FIFO (当容量较小而使用寄存器作为存储部分)设计为例,虽然理论上可以使用比较简单的数据表项逐次移位的方式,实现FIFO 的先入先出功能,但是却应该使用维护读写指针的方式(数据表项寄存器则不用移位)实现先入先出的功能。因为数据表项逐次…...
孜然单授权系统V1.0[免费使用]
您还在为授权系统用哪家而发愁?孜然单授权系统为您解决苦恼,本系统永久免费。 是的,还是那个孜然,消失了一年不是跑路了是没有空,但是这些都是无关紧要的,为大家带来的孜然单授权系统至上我最高的诚意&…...
-异常事件)
kubernetes问题(一)-异常事件
1 pod状态处于Evicted 0/1 现象: 1)kubectl get events发现“failed to garbage collect required amount of images”。 2)同时磁盘空间不足的节点有大量pod处于Evicted 0/1状态,但并未进行重新调度。 原因描述: …...
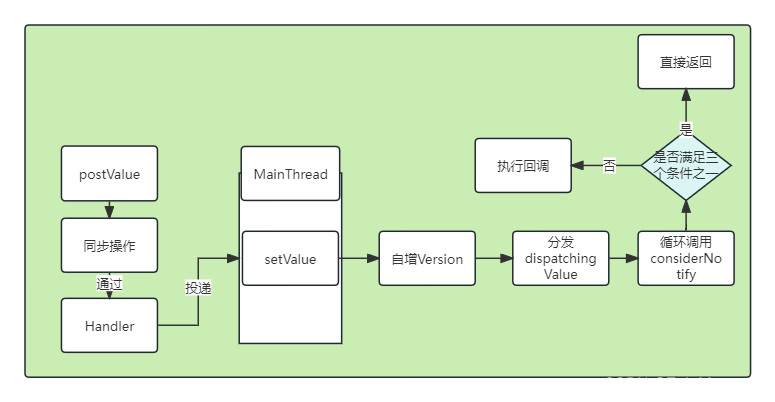
Android Jetpack组件架构 :LiveData的使用和原理
Android Jetpack组件架构: LiveDate的使用和原理 导言 继Lifecycle组件之后我们接下来要介绍的就是LiveDate组件,所谓LiveDate字面意思上就是有声明的数据,当数据有改动时该组件可以感知到这个操作并将该事件通知到其观察者,这样…...

【学习笔记】Prufer序列
Prufer序列 起源于对 C a y l e y Cayley Cayley定理的证明,但是其功能远不止于此 现在考虑将一棵n个节点的树与一个长度为n-2的prufer序列构造对应关系 T r e e − > P r u f e r : Tree->Prufer: Tree−>Prufer: ①从树上选择编号最小的叶子节点&#x…...
由于找不到msvcr110.dll的5种解决方法
在使用电脑的过程中,我们可能会遇到一些问题,比如打开软件时提示找不到 msvcr110.dll 文件丢失。这通常意味着该文件已被删除或损坏,导致程序无法正常运行。本文将介绍几种解决方案,帮助您解决这个问题。 首先,我们需…...

最长连续递增子序列
给定一个顺序存储的线性表,请设计一个算法查找该线性表中最长的连续递增子序列。例如,(1,9,2,5,7,3,4,6,8,0)中最长的递增子序列为(3,4,6,8)。 输入格式: 输入第1行给出正整数n(≤105);第2行给出n个整数,…...

Java学习星球,十月集训,五大赛道(文末送书)
目录 什么是知识星球?我的知识星球能为你提供什么?专属专栏《Java基础教程系列》内容概览:《Java高并发编程实战》、《MySQL 基础教程系列》内容概览:《微服务》、《Redis中间件》、《Dubbo高手之路》、《华为OD机试》内容概览&am…...
前端VUE---JS实现数据的模糊搜索
实现背景 因为后端实现人员列表返回,每次返回的数据量在100以内,要求前端自己进行模糊搜索 页面实现 因为是实时更新数据的,就不需要搜索和重置按钮了 代码 HTML <el-dialogtitle"团队人员详情":visible.sync"centerDi…...
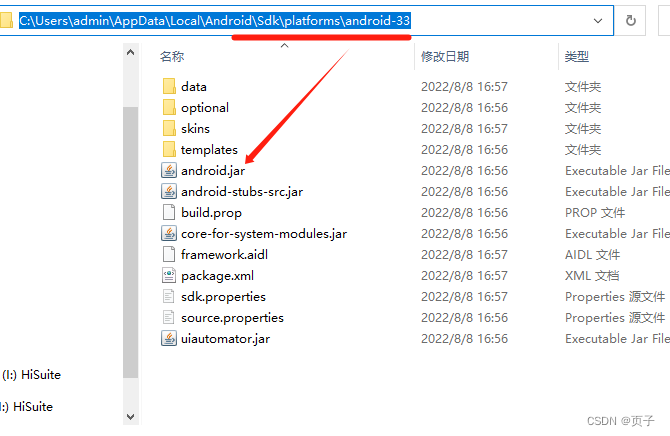
Android Studio 的android.jar文件在哪儿
一般在:C:\Users\admin\AppData\Local\Android\Sdk\platforms\android-33下(不一定是33,这个得看你Android Studio->app->builde.gradle的targetSdk是多少) 怎么找: 1.打开Android Studio 粘贴地址后࿰…...
Elasticsearch 部署学习
文章目录 Elasticsearch 部署学习1. 单节点部署 elasticsearch1.1 部署 jdk1.2 下载 elasticsearch1.3 上传文件并修改配置文件1.4 启动1.5 问题总结1.6 浏览器验证 2. 集群部署 elasticsearch3. 常用命令4. Elasticsearch kibana安装:one: 参考部署文档:two: 下载对应版本的安…...
nodejs 如何在npm发布自己的包 <记录>
一、包结构 必要结构: 一个包对应一个文件夹(文件夹名不是包名,但最好与包名保持一致,包名以package.json中的name为主)包的入口文件index.js包的配置文件package.json包的说明文档README.md 二、需要说明的文件 1.配…...

移植RTOS的大体思路
最首先当然是去官网看看是不是已经支持目标芯片啦,没有的话,就需要自己手动移植了 获取源码 一般可以从rtos官网或者GitHub上获取源码 确认源码结构 这种有官方文档说明,需要修改的一般都是BSP和libcpu相关文件夹中的内容 CPU架构移植 …...

FPGA到底是什么?
首先只是凭自己浅略的了解,FPGA好像也是涉及到了开发板,单片机之类的东西,和嵌入式十分相似,但是比嵌入式更高级的东西。 肯定有很多小伙伴如我一样,只是听说过FPGA,听别人说的传呼其神,那么它到…...

算法-单词搜索 II
算法-单词搜索 II 1 题目概述 1.1 题目出处 https://leetcode.cn/problems/word-search-ii/description/?envTypestudy-plan-v2&envIdtop-interview-150 1.2 题目描述 2 DFS 2.1 解题思路 每个格子往上下左右四个方向DFS,拼接后的单词如果在答案集中&…...
怒刷LeetCode的第15天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:哈希表双向链表 方法二:TreeMap 方法三:双哈希表 第二题 题目来源 题目内容 解决方法 方法一:二分查找 方法二:线性搜索 方法三:Arrays类的b…...

从B类到连续类:一篇讲透功放效率与带宽的“鱼与熊掌”兼得史
射频功率放大器的进化论:从B类到连续类的带宽革命 在无线通信技术狂飙突进的三十年里,有个看似矛盾的命题始终困扰着工程师:如何让功率放大器同时"吃得少"(高效率)和"干得多"(宽带宽&…...

从开发者视角看Taotoken文档与示例代码对降低接入门槛的帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从开发者视角看Taotoken文档与示例代码对降低接入门槛的帮助 作为一名经常需要集成不同AI模型服务的开发者,我经历过不…...

如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南
如何快速掌握哔哩下载姬Downkyi:面向新手的完整使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

Windows 环境 OpenClaw 部署详解|从安装到使用全流程
OpenClaw(小龙虾)Windows 一键部署教程|10 分钟搭建自动化数字员工 前言 OpenClaw(俗称小龙虾)是 2026 年热门的开源 AI 智能体,GitHub 星标突破 28 万,主打本地运行、低门槛、自动化执行。本…...

3步打造你的专属Minecraft领地世界:PlotSquared终极指南
3步打造你的专属Minecraft领地世界:PlotSquared终极指南 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared 还在为Minecraft服务器管理混乱而烦恼吗?想要创建一个…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

魔兽争霸3的现代重生:如何让经典游戏在你的电脑上焕发新生
魔兽争霸3的现代重生:如何让经典游戏在你的电脑上焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还记得那个充满激情的年代…...

C 读取RAW文件程序
C# 读取RAW文件程序 【下载地址】C读取RAW文件程序 本仓库提供了一个简单的C#程序,用于读取RAW文件。该程序已经过调试,确保功能正常运行。需要注意的是,此程序仅提供基本的RAW文件读取功能,不包含任何图像处理或转换功能 项目地…...

obamify跨平台兼容性解决方案:从桌面到Web的完美迁移指南
obamify跨平台兼容性解决方案:从桌面到Web的完美迁移指南 【免费下载链接】obamify revolutionary new technology that turns any image into obama 项目地址: https://gitcode.com/gh_mirrors/ob/obamify 想要在任何设备上将图片转换为奥巴马风格吗&#x…...