MySQL表的增删改查(进阶)
一 、数据库约束
NOT NULL - 指示某列不能存储 NULL 值。
UNIQUE - 保证某列的每行必须有唯一的值。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。
确保某列(或两个列多个列的结合)有唯一标识,
有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。
对于MySQL数据库,对CHECK子句进行分析,
但是忽略 CHECK子句。
1. NULL约束
创建表时,可以指定某列不为空:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (id INT NOT NULL,sn INT,name VARCHAR(20), qq_mail VARCHAR(20)
);
2. UNIQUE: 唯一约束
指定sn列为唯一的、不重复的:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student; CREATE TABLE student (id INT NOT NULL,sn INT UNIQUE,name VARCHAR(20), qq_mail VARCHAR(20)
);
3. DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (id INT NOT NULL,sn INT UNIQUE,name VARCHAR(20) DEFAULT 'unkown', qq_mail VARCHAR(20)
);
4. PRIMARY KEY:主键约束
指定id列为主键:
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (id INT NOT NULL PRIMARY KEY, sn INT UNIQUE,name VARCHAR(20) DEFAULT 'unkown', qq_mail VARCHAR(20)
);--对于整数类型的主键,常配搭自增长auto_increment来使用。
--插入数据对应字段不给值时,使用最大值+1。-- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL id INT PRIMARY KEY auto_increment,
5. FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
创建班级表classes,id为主键:-- 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (id INT PRIMARY KEY auto_increment,name VARCHAR(20),`desc` VARCHAR(100)
);--创建学生表student,一个学生对应一个班级,一个班级对应多个学生。
--使用id为主键, classes_id为外键,关联班级表id-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (id INT PRIMARY KEY auto_increment,sn INT UNIQUE,name VARCHAR(20) DEFAULT 'unkown',qq_mail VARCHAR(20),classes_id int,FOREIGN KEY (classes_id) REFERENCES classes(id) );
6. CHECK约束(了解)
MySQL使用时不报错,但忽略该约束:
drop table if exists test_user; create table test_user (id int,name varchar(20),sex varchar(1),check (sex ='男' or sex='女')
);
二 、 新增
插入查询结果
--创建一张用户表,设计有name姓名、email邮箱、sex性别、mobile手机号字段。
--需要把已有的 学生数据复制进来,可以复制的字段为name、qq_mail-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (id INT primary key auto_increment, name VARCHAR(20) comment '姓名', age INT comment '年龄',email VARCHAR(20) comment '邮箱', sex varchar(1) comment '性别', mobile varchar(20) comment '手机号'
);-- 将学生表中的所有数据复制到用户表
insert into test_user(name, email) select name, qq_mail from student;
三 、查询
1. 聚合查询
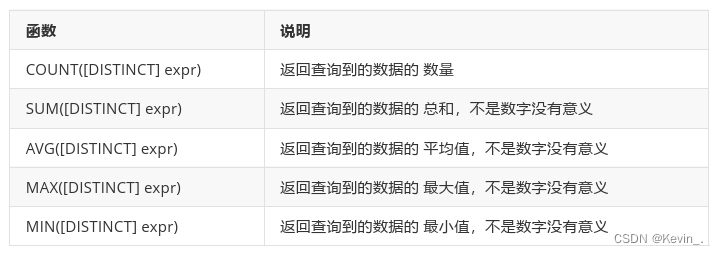
-- 统计班级共有多少同学
SELECT COUNT(*) FROM student;
SELECT COUNT(0) FROM student;-- 统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果
SELECT COUNT(qq_mail) FROM student;-- 统计数学成绩总分
SELECT SUM(math) FROM exam_result;-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;-- 统计平均总分
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;-- 返回英语最高分
SELECT MAX(english) FROM exam_result;-- 返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;- GROUP BY子句 & HAVING
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。
需要满足:使用 GROUP BY 进行分组查 询时,SELECT 指定的字段必须是“分组依据字段”,
其他字段若想出现在SELECT 中则必须包含在聚合函 数中。
案例:
准备测试表及数据:
职员表,有id(主键)、name(姓名)、role(角色)、salary(薪水)create table emp(id int primary key auto_increment, name varchar(20) not null,role varchar(20) not null, salary numeric(11,2)
);insert into emp(name, role, salary) values ('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);查询每个角色的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用 HAVING显示平均工资低于1500的角色和它的平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role having avg(salary)<1500;
2. 联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。
多表查询是对多张表的数据取笛卡尔积:
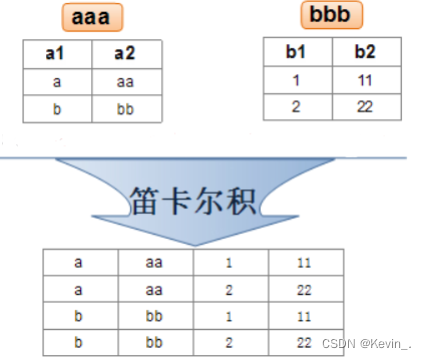
关联查询可以对关联表使用别名。
// 初始化测试数据:
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
- 内连接
// 语法
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
// 查询“许仙”同学的 成绩
select sco.score from student stu inner join score sco on stu.id=sco.student_id
and stu.name='许仙';
-- 或者
select sco.score from student stu, score sco where stu.id=sco.student_id and
stu.name='许仙';
// 查询所有同学的总成绩,及同学的个人信息:
-- 成绩表对学生表是多对1关系,查询总成绩是根据成绩表的同学id来进行分组的
SELECTstu.sn,stu.NAME,stu.qq_mail,sum( sco.score )
FROMstudent stuJOIN score sco ON stu.id = sco.student_id
GROUP BYsco.student_id;
// 查询所有同学的成绩,及同学的个人信息:
-- 查询出来的都是有成绩的同学,“老外学中文”同学 没有显示
select * from student stu join score sco on stu.id=sco.student_id;-- 学生表、成绩表、课程表3张表关联查询
SELECTstu.id,stu.sn,stu.NAME,stu.qq_mail,sco.score,sco.course_id,cou.NAME
FROMstudent stuJOIN score sco ON stu.id = sco.student_idJOIN course cou ON sco.course_id = cou.id
ORDER BYstu.id;
- 外连接
外连接分为左外连接和右外连接。
如果联合查询,左侧的表完全显示我们就说是左外连接;
右侧的表完全显示我们就说是右外连接。
// 语法:-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
// 查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示-- “老外学中文”同学 没有考试成绩,也显示出来了
select * from student stu left join score sco on stu.id=sco.student_id;
-- 对应的右外连接为:
select * from score sco right join student stu on stu.id=sco.student_id;-- 学生表、成绩表、课程表3张表关联查询
SELECTstu.id,stu.sn,stu.NAME,stu.qq_mail,sco.score,sco.course_id,cou.NAME
FROMstudent stuLEFT JOIN score sco ON stu.id = sco.student_idLEFT JOIN course cou ON sco.course_id = cou.id
ORDER BYstu.id;
- 自连接
自连接是指在同一张表连接自身进行查询。
// 显示所有“计算机原理”成绩比“Java”成绩高的成绩信息-- 先查询“计算机原理”和“Java”课程的id
select id,name from course where name='Java' or name='计算机原理';-- 再查询成绩表中,“计算机原理”成绩比“Java”成绩 好的信息
SELECTs1.*
FROMscore s1,score s2
WHEREs1.student_id = s2.student_id AND s1.score < s2.score AND s1.course_id = 1 AND s2.course_id = 3;-- 也可以使用join on 语句来进行自连接查询
SELECTs1.*
FROMscore s1JOIN score s2 ON s1.student_id = s2.student_id AND s1.score < s2.score AND s1.course_id = 1 AND s2.course_id = 3;// 以上查询只显示了成绩信息,并且是分布执行的。要显示学生及成绩信息,并在一条语句显示:SELECTstu.*,s1.score Java,s2.score 计算机原理
FROMscore s1JOIN score s2 ON s1.student_id = s2.student_idJOIN student stu ON s1.student_id = stu.idJOIN course c1 ON s1.course_id = c1.idJOIN course c2 ON s2.course_id = c2.id AND s1.score < s2.score AND c1.NAME = 'Java' AND c2.NAME = '计算机原理';
- 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。- 单行子查询:
返回一行记录的子查询。
// 查询与“不想毕业” 同学的同班同学: select * from student where classes_id=(select classes_id from student where name='不想毕业');- 多行子查询:
返回多行记录的子查询。
// [NOT] IN关键字:// 查询“语文”或“英文”课程的成绩信息 -- 使用IN select * from score where course_id in (select id from course where name='语文' or name='英文');-- 使用 NOT IN select * from score where course_id not in (select id from course where name!='语文' and name!='英文');// 可以使用多列包含: -- 插入重复的分数:score, student_id, course_id列重复 insert into score(score, student_id, course_id) values -- 黑旋风李逵 (70.5, 1, 1),(98.5, 1, 3), -- 菩提老祖 (60, 2, 1);-- 查询重复的分数 SELECT* FROMscore WHERE( score, student_id, course_id ) IN ( SELECT score, student_id, course_id FROM score GROUP BY score, student_id, course_id HAVING count( 0 ) > 1 );// [NOT] EXISTS关键字:-- 使用 EXISTS select * from score sco where exists (select sco.id from course cou where (name='语文' or name='英文') and cou.id = sco.course_id);-- 使用 NOT EXISTS select * from score sco where not exists (select sco.id from course cou where (name!='语文' and name!='英文') and cou.id = sco.course_id);- 在from子句中使用子查询:
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
- 单行子查询:
// 查询所有比“中文系2019级3班”平均分高的成绩信息:
-- 获取“中文系2019级3班”的平均分,将其看作临时表
SELECTavg( sco.score ) score
FROMscore scoJOIN student stu ON sco.student_id = stu.idJOIN classes cls ON stu.classes_id = cls.id
WHEREcls.NAME = '中文系2019级3班';// 查询成绩表中,比以上临时表平均分高的成绩:SELECT*
FROMscore sco,(SELECTavg( sco.score ) score FROMscore scoJOIN student stu ON sco.student_id = stu.idJOIN classes cls ON stu.classes_id = cls.id WHEREcls.NAME = '中文系2019级3班' ) tmp
WHEREsco.score > tmp.score;
-
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。
使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。- union
该操作符用于取得两个结果集的并集。
当使用该操作符时,会自动去掉结果集中的重复行。// 查询id小于3,或者名字为“英文”的课程: select * from course where id<3 union select * from course where name='英文';-- 或者使用or来实现 select * from course where id<3 or name='英文';- union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
// 查询id小于3,或者名字为“Java”的课程-- 可以看到结果集中出现重复数据Java select * from course where id<3 union all select * from course where name='英文';
相关文章:
MySQL表的增删改查(进阶)
一 、数据库约束 NOT NULL - 指示某列不能存储 NULL 值。 UNIQUE - 保证某列的每行必须有唯一的值。 DEFAULT - 规定没有给列赋值时的默认值。 PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。 确保某列(或两个列多个列的结合)有唯一标识, 有…...

Greenplum实用工具-gpfdist
注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/utility_guide-ref-gpfdist.html 向Greenplum数据库段提供数据文件或从数据库段写入数据文件。 语法 gpfdist [-d <directory>] [-p <http_port>] [-P <last_http…...

axios和fetch的区别
axios和fetch都是用于发起HTTP请求的工具,但是它们有一些区别: 语法和用法:axios是一个基于Promise的HTTP客户端,具有更简洁和直观的语法,可以方便地发送GET、POST、PUT等各种请求,并提供了更多的请求配置选…...
HTML那些重要的知识点
文章目录 ⭐️写在前面的话⭐️一、HTML1.1 锚点链接跳转到当前页面的指定位置跳转到其他页面的指定位置 1.2 自定义列表1.3 表格的跨行跨列1.4 视频和音频内容1.5 页面结构规范1.6 ifram内联框架1.7 表单1.7.1 form标签1.7.2 原生表单部件1.7.3 下拉框1.7.4 文本域1.7.5 文件域…...
《优化接口设计的思路》系列:第四篇—接口的权限控制
系列文章导航 《优化接口设计的思路》系列:第一篇—接口参数的一些弯弯绕绕 《优化接口设计的思路》系列:第二篇—接口用户上下文的设计与实现 《优化接口设计的思路》系列:第三篇—留下用户调用接口的痕迹 《优化接口设计的思路》系列&#…...
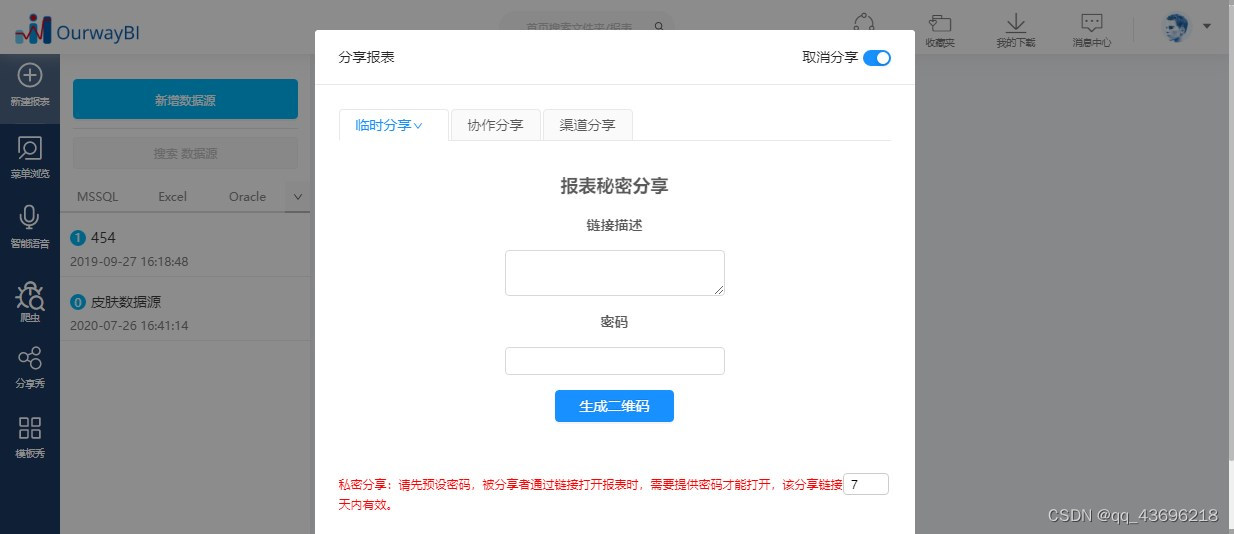
BI系统上的报表怎么导出来?附方法步骤
在BI系统上做好的数据可视化分析报表,怎么导出来给别人看?方法有二,分别是1使用报表分享功能,2使用报表导出功能。下面就以奥威BI系统为例,简明扼要地介绍这两个功能。 1、报表分享功能 作用: 让其他同事…...
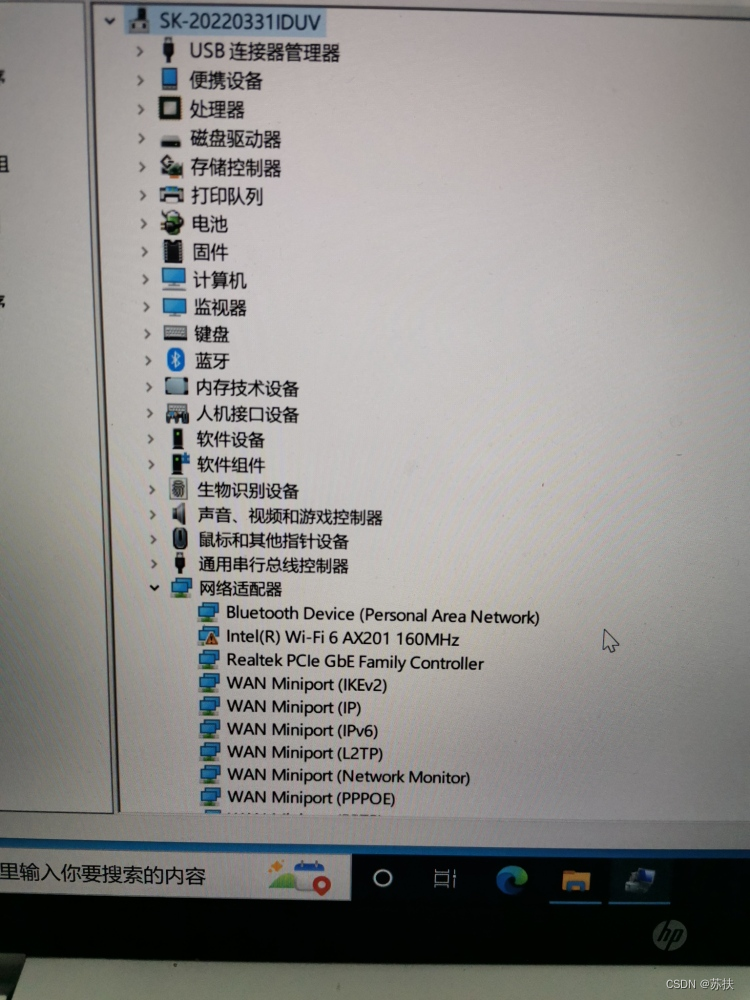
电脑WIFI突然消失
文章目录 1. 现象2. 解决办法1:重新启用无线网卡设置3. 解决办法2:更新无线网卡驱动4. 解决办法3:释放静电5. 解决办法4:拆机并重新插拔无线网卡 1. 现象 如下图:电脑在使用过程中WIFI消失 设备管理器中的无线网卡驱…...
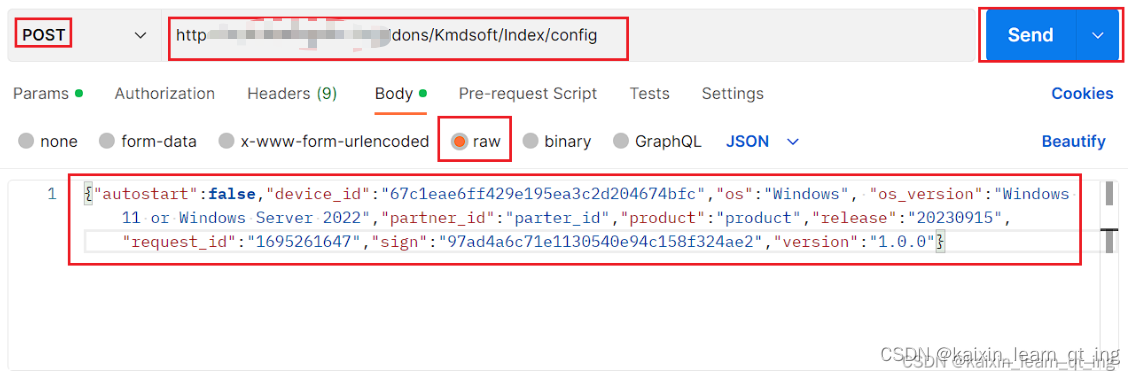
http的get与post
get方法: 这个网址可以获取配置信息(我把部分位置字符改了,现在打不开了,不然会被追责) http://softapi.s103.cn/addons/Kmdsoft/Index/config?productwxdk&partner_id111122&osWindows&os_version11&am…...

MySQL 8 和 MySQL 5.7 在自增计数上的区别
MySQL 8 和 MySQL 5.7 在自增计数上的区别 作者:Arunjith Aravindan 本文来源:Percona 博客,爱可生开源社区翻译。 本文约 900 字,预计阅读需要 2 分钟。 Auto-Increment 自增(Auto-Increment)计数功能可以…...
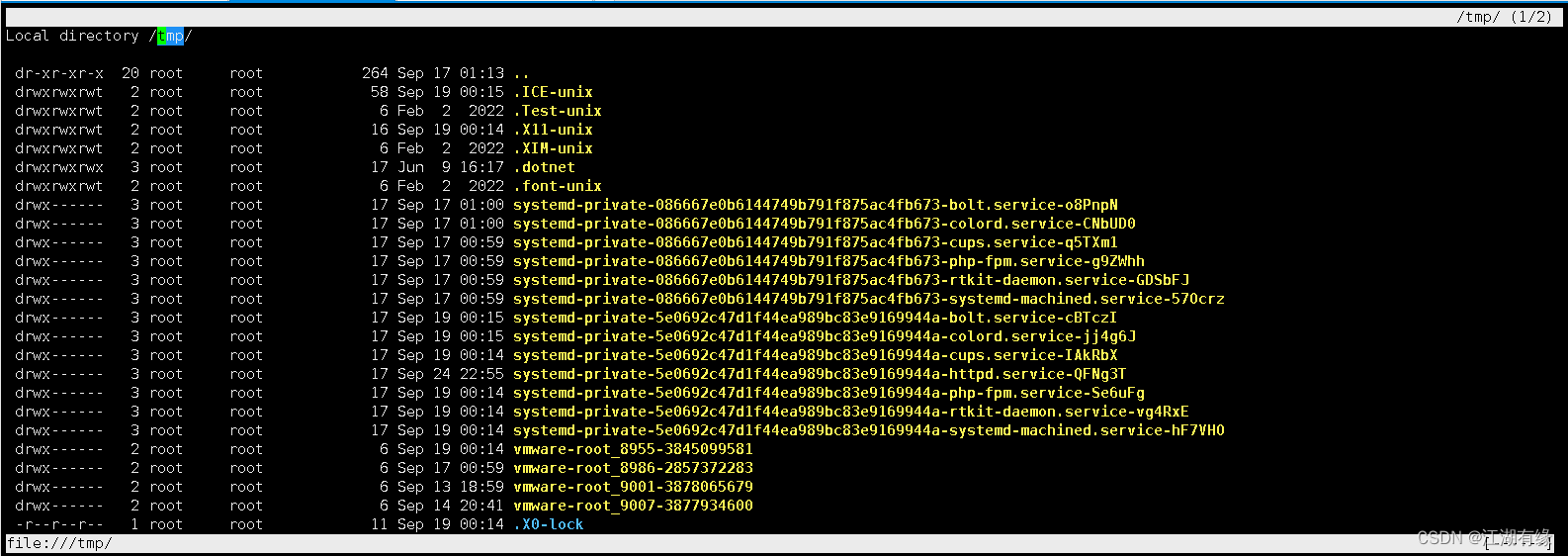
Linux系统之links和elinks命令的基本使用
Linux系统之links和elinks命令的基本使用 一、links与elinks命令介绍1. links命令简介2. elinks命令简介 二、links与elinks命令区别三、links命令选项解释四、links命令的基本使用1. links安装2. 查看links版本3. 图形模式打开网址4. 直接使用links命令5. 打印url版本到标准格…...
【00】FISCO BCOS区块链简介
官方文档:https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/introduction.html FISCO BCOS是由国内企业主导研发、对外开源、安全可控的企业级金融联盟链底层平台,由金链盟开源工作组协作打造,并于2017年正式对外开源。 F…...
NPDP产品经理认证怎么报名?考试难度大吗?
PMDA(Product Development and Management Association)是美国产品开发与管理协会,在中国由中国人才交流基金会培训中心举办NPDP(New Product Development Professional)考试,该考试是产品经理国际资格认证…...

免杀技术,你需要学习哪些内容
免杀技术,你需要学习哪些内容? 什么是免杀? 免杀是指通过各种技术手段使恶意软件或病毒能够逃避杀毒软件的检测和阻止,成功地感染目标系统。免杀技术是黑客和恶意软件开发者常用的手段之一,用于隐藏恶意代码并绕过安…...
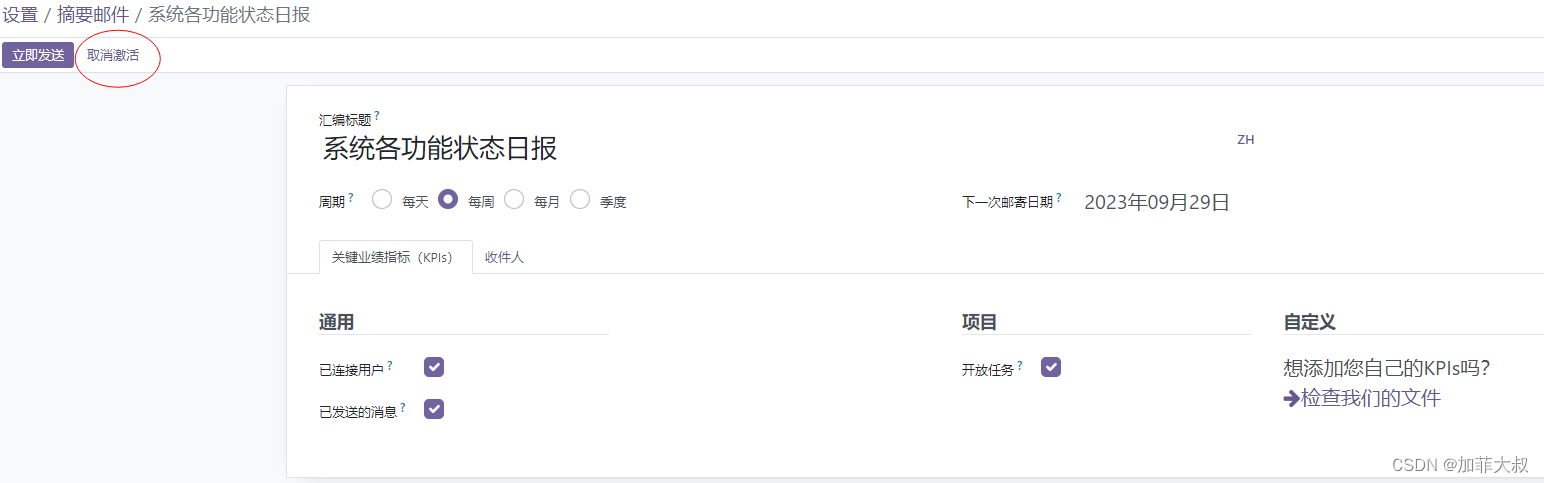
odoo16 取消“系统各功能状态日报”的邮件
odoo16默认情况下每周都会发送一个“系统各功能状态日报”的邮件,而且是所有人都发, 这个功能在哪配置呢? 今天研究了一下, 线索是“系统各功能状态日报”,先全文检索吧 #. module: digest #: model:digest.digest,na…...

[C++ 网络协议] Windows中的线程同步
目录 1. 用户模式(User mode)和内核模式(Kernal mode) 2. 用户模式的同步(CRITICAL_SECTION) 3. 内核模式同步 3.1 互斥量 3.2 信号量 3.3 事件对象 4. 实现Windows平台的多线程服务器端 1. 用户模式(User mode)和内核模式(Kernal mode) Windows操作系统的运行方式是“…...

JavaScript 基础第三天笔记
JavaScript 基础第三天笔记 if 多分支语句和 switch的区别: 共同点 都能实现多分支选择, 多选1大部分情况下可以互换 区别: switch…case语句通常处理case为比较确定值的情况,而if…else…语句更加灵活,通常用于范围…...

NebulaGraph实战:3-信息抽取构建知识图谱
自动信息抽取发展了几十年,虽然模型很多,但是泛化能力很难用满意来形容,直到LLM的诞生。虽然最终信息抽取质量部分还是需要专家审核,但是已经极大的提高了信息抽取的效率。因为传统方法需要大量时间来完成数据清洗、标注和训练&am…...
一百八十二、大数据离线数仓完整流程——步骤一、用Kettle从Kafka、MySQL等数据源采集数据然后写入HDFS
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、项目背景 项目行业属于交通行业,因此数据具有很…...
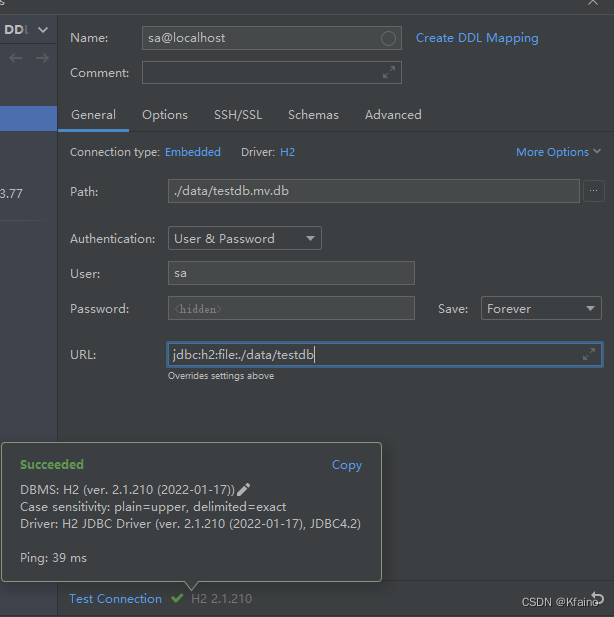
工具篇 | H2数据库的使用和入门
引言 1.1 H2数据库概述 1.1.1 定义和特点 H2数据库是一款以 Java编写的轻量级关系型数据库。由于其小巧、灵活并且易于集成,H2经常被用作开发和测试环境中的便利数据库解决方案。除此之外,H2也适合作为生产环境中的嵌入式数据库。它不仅支持标准的SQL…...
PHP脚本导出MySQL数据库
背景:有时候需要同步数据库的表结构和部分数据,同步全表数据非常大,也不适合。还有一个种办法是使用数据库的dump命令执行备份,无法进入服务器?没有权限怎么办? 这里只要能访问服务器中的 information_sch…...
—— 用C#构建2D躲避游戏的核心机制)
Godot实战(一)—— 用C#构建2D躲避游戏的核心机制
1. 环境准备与项目初始化 第一次打开Godot引擎时,那个简洁的界面可能会让你有点不知所措。别担心,我们一步步来。点击"New Project"按钮,给你的游戏项目起个名字,比如"DodgeTheCreeps"。建议专门创建一个空文…...

【亲测免费】 PLC1200四路抢答器程序:打造高效公平的抢答体验
PLC1200四路抢答器程序:打造高效公平的抢答体验 【下载地址】PLC1200四路抢答器程序 本仓库提供了一个完整的S7-1200四路抢答器程序,可以直接下载并使用。该程序适用于需要进行四路抢答的场景,如竞赛、培训等。程序经过精心设计和测试&#x…...

WorkshopDL:打破平台壁垒,免费获取Steam创意工坊模组的终极方案
WorkshopDL:打破平台壁垒,免费获取Steam创意工坊模组的终极方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic、GOG等平台购买的游戏无法使…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

从原理图到PCB的桥梁:手把手教你用Cadence导出STM32项目的网表与BOM清单
从原理图到PCB的桥梁:手把手教你用Cadence导出STM32项目的网表与BOM清单 在电子设计自动化(EDA)流程中,从原理图设计到PCB布局的过渡阶段往往是最容易被忽视却又至关重要的环节。许多工程师在完成精美的原理图后,常常因…...

DIY便携UV美甲灯:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么选择DIY一个便携UV美甲灯?如果你和我一样,是个喜欢自己动手做美甲,同时又对电子制作和3D打印有点“手痒”的爱好者,那你肯定对市面上那些笨重、必须插电的UV美甲灯感到过不满。它们要么像个小型烤箱…...

DIY USB-C扩展坞:从引脚连接到3D打印,打造开发板专属工作站
1. 项目概述与核心价值如果你和我一样,桌上常年堆着各种开发板,从Arduino Uno到最新的ESP32-S3,每次想插拔USB线调试或者充电,都得在一堆线缆里翻找,板子还容易滑来滑去,那这个项目就是为你准备的。今天我们…...

使用Nodejs快速将Taotoken大模型API集成到你的Web应用中
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js快速将Taotoken大模型API集成到你的Web应用中 基础教程类,面向全栈或前端开发者,讲解如何在Nod…...

【NotebookLM语言润色功能深度解密】:20年AI写作工具实战者亲授5大未公开润色技巧,92%用户忽略的语义校准开关在哪?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM语言润色功能全景认知 NotebookLM 是 Google 推出的基于用户自有文档的 AI 助手,其语言润色(Language Refinement)功能并非简单替换同义词,而是…...
)
告别原生标题栏!用Qt 6.x打造一个可拖拽、可美化的自定义标题栏(附完整源码)
Qt 6.x自定义标题栏实战:从零构建高颜值可拖拽界面组件 当你在开发一款专业级桌面应用时,系统默认的标题栏往往会成为整体UI设计的短板。不同操作系统下的标题栏风格各异,无法与应用主体保持视觉统一,更难以实现个性化的交互效果。…...