NebulaGraph实战:3-信息抽取构建知识图谱
自动信息抽取发展了几十年,虽然模型很多,但是泛化能力很难用满意来形容,直到LLM的诞生。虽然最终信息抽取质量部分还是需要专家审核,但是已经极大的提高了信息抽取的效率。因为传统方法需要大量时间来完成数据清洗、标注和训练,然后来实体抽取、实体属性抽取、实体关系抽取、事件抽取、实体链接和指代消解等等。现在有了LLM,可以实现Zero/One/Few-Shot信息抽取构建知识图谱。
一.ChatIE实现过程
ChatIE本质上是将零样本IE任务转变为一个两阶段框架的多轮问答问题(使用的ChatGPT,也可以修改为ChatGLM2),问题是第一阶段和第二阶段如何设计?本质上还是Prompt的设计。接下来都是以RE(关系抽取)为例进行说明,NER(命名实体识别)和EE(事件抽取)以此类推。下面看一个例子,如下所示:

df_ret = {'chinese': {'所属专辑': ['歌曲', '音乐专辑'], '成立日期': ['机构', 'Date'], '海拔': ['地点', 'Number'], '官方语言': ['国家', '语言'], '占地面积': ['机构', 'Number'], '父亲': ['人物', '人物'], '歌手': ['歌曲', '人物'], '制片人': ['影视作品', '人物'], '导演': ['影视作品', '人物'], '首都': ['国家', '城市'], '主演': ['影视作品', '人物'], '董事长': ['企业', '人物'], '祖籍': ['人物', '地点'], '妻子': ['人物', '人物'], '母亲': ['人物', '人物'], '气候': ['行政区', '气候'], '面积': ['行政区', 'Number'], '主角': ['文学作品', '人物'], '邮政编码': ['行政区', 'Text'], '简称': ['机构', 'Text'], '出品公司': ['影视作品', '企业'], '注册资本': ['企业', 'Number'], '编剧': ['影视作品', '人物'], '创始人': ['企业', '人物'], '毕业院校': ['人物', '学校'], '国籍': ['人物', '国家'], '专业代码': ['学科专业', 'Text'], '朝代': ['历史人物', 'Text'], '作者': ['图书作品', '人物'], '作词': ['歌曲', '人物'], '所在城市': ['景点', '城市'], '嘉宾': ['电视综艺', '人物'], '总部地点': ['企业', '地点'], '人口数量': ['行政区', 'Number'], '代言人': ['企业/品牌', '人物'], '改编自': ['影视作品', '作品'], '校长': ['学校', '人物'], '丈夫': ['人物', '人物'], '主持人': ['电视综艺', '人物'], '主题曲': ['影视作品', '歌曲'], '修业年限': ['学科专业', 'Number'], '作曲': ['歌曲', '人物'], '号': ['历史人物', 'Text'], '上映时间': ['影视作品', 'Date'], '票房': ['影视作品', 'Number'], '饰演': ['娱乐人物', '人物'], '配音': ['娱乐人物', '人物'], '获奖': ['娱乐人物', '奖项']}
}
1.第一阶段
第一阶段的模板,如下所示:
re_s1_p = {'chinese': '''给定的句子为:"{}"\n\n给定关系列表:{}\n\n在这个句子中,可能包含了哪些关系?\n请给出关系列表中的关系。\n如果不存在则回答:无\n按照元组形式回复,如 (关系1, 关系2, ……):''',
}
2.第二阶段
第二段的模板,如下所示:
re_s2_p = {'chinese': '''根据给定的句子,两个实体的类型分别为({},{})且之间的关系为{},请找出这两个实体,如果有多组,则按组全部列出。\n如果不存在则回答:无\n按照表格形式回复,表格有两列且表头为({},{}):''',
}
ChatIE通过两阶段的ChatGPT多轮问答来解决Zero-Shot信息抽取构建知识图谱。但有个问题是可能或一定会出现错误关系抽取,这该如何办呢?工程有个解决方案就是引入多个裁判,比如ChatGPT是一个裁判,文心一言是一个裁判,BERT实体关系抽取是一个裁判,规则实体关系抽取是一个裁判。可根据知识精度要求,比如4个裁判都一致了,才会自动更新到知识库中,否则需要人工来审核实体关系抽取是否正确。知识图谱自动化更新是一个工程活,需要一个人工审核的功能,来确保模型识别不一致时的最终审核。
3.测试效果
ChatIE在不同任务(RE、NER和EE)和不同数据集上的测试效果,如下所示:

二.使用ChatGLM2来信息抽取[1]
这部分替换ChatGPT为ChatGLM2来做多轮问答。ChatGLM2进行金融知识抽取实践中,在ChatGLM前置了两轮对话达到了较好的效果,具体代码实现参考[9]。基本思路是加载ChatGLM2模型,然后初始化Prompt(分类和信息抽取),最后根据输入和模型完成推理过程。简单理解,整体思路是通过Few-Shot信息抽取构建知识图谱。
(1)加载ChatGLM2模型
tokenizer = AutoTokenizer.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True) # 指定使用的tokenizer
model = AutoModel.from_pretrained(r"L:/20230713_HuggingFaceModel/chatglm2-6b", trust_remote_code=True).half().cuda() # 指定使用的model
model = model.eval() # 指定model为eval模式
(2)初始化Prompt
def init_prompts():"""初始化前置prompt,便于模型做 incontext learning。"""class_list = list(class_examples.keys()) # 获取分类的类别,class_list = ['基金', '股票']cls_pre_history = [(f'现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。',f'好的。')]for _type, exmpale in class_examples.items(): # 遍历分类的类别和例子cls_pre_history.append((f'“{exmpale}”是 {class_list} 里的什么类别?', _type)) # 拼接前置promptie_pre_history = [("现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中三元组,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多个值之间用','分隔。",'好的,请输入您的句子。')]for _type, example_list in ie_examples.items(): # 遍历分类的类别和例子for example in example_list: # 遍历例子sentence = example['content'] # 获取句子properties_str = ', '.join(schema[_type]) # 拼接schemaschema_str_list = f'“{_type}”({properties_str})' # 拼接schemasentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置promptie_pre_history.append(( # 拼接前置promptf'{sentence_with_prompt}',f"{json.dumps(example['answers'], ensure_ascii=False)}"))return {'ie_pre_history': ie_pre_history, 'cls_pre_history': cls_pre_history} # 返回前置prompt
custom_settings数据结构中的内容如下所示:

(3)根据输入和模型完成推理过程
def inference(sentences: list,custom_settings: dict):"""推理函数。Args:sentences (List[str]): 待抽取的句子。custom_settings (dict): 初始设定,包含人为给定的few-shot example。"""for sentence in sentences: # 遍历句子with console.status("[bold bright_green] Model Inference..."): # 显示推理中sentence_with_cls_prompt = CLS_PATTERN.format(sentence) # 拼接前置promptcls_res, _ = model.chat(tokenizer, sentence_with_cls_prompt, history=custom_settings['cls_pre_history']) # 推理if cls_res not in schema: # 如果推理结果不在schema中,报错并退出print(f'The type model inferenced {cls_res} which is not in schema dict, exited.')exit()properties_str = ', '.join(schema[cls_res]) # 拼接schemaschema_str_list = f'“{cls_res}”({properties_str})' # 拼接schemasentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list) # 拼接前置promptie_res, _ = model.chat(tokenizer, sentence_with_ie_prompt, history=custom_settings['ie_pre_history']) # 推理ie_res = clean_response(ie_res) # 后处理print(f'>>> [bold bright_red]sentence: {sentence}') # 打印句子print(f'>>> [bold bright_green]inference answer: ') # 打印推理结果print(ie_res) # 打印推理结果
如果实体关系抽取搞定了,那么自动更新到NebulaGraph就比较简单了,可参考NebulaGraph实战:2-NebulaGraph手工和Python操作。
参考文献:
[1]利用ChatGLM构建知识图谱:https://discuss.nebula-graph.com.cn/t/topic/13029
[2]ChatGPT+SmartKG 3分钟生成"哈利波特"知识图谱:https://www.msn.cn/zh-cn/news/technology/chatgpt-smartkg-3分钟生成-哈利波特-知识图谱/ar-AA17ykNr
[3]ChatIE:https://github.com/cocacola-lab/ChatIE
[4]ChatIE:http://124.221.16.143:5000/
[5]financial_chatglm_KG:https://github.com/zhuojianc/financial_chatglm_KG
[6]Creating a Knowledge Graph From Video Transcripts With ChatGPT 4:https://neo4j.com/developer-blog/chatgpt-4-knowledge-graph-from-video-transcripts/
[7]GPT4IE:https://github.com/cocacola-lab/GPT4IE
[8]GPT4IE:http://124.221.16.143:8080/
[9]https://github.com/ai408/nlp-engineering/blob/main/20230917_NLP工程化公众号文章\NebulaGraph教程\NebulaGraph实战:3-信息抽取构建知识图谱
相关文章:
NebulaGraph实战:3-信息抽取构建知识图谱
自动信息抽取发展了几十年,虽然模型很多,但是泛化能力很难用满意来形容,直到LLM的诞生。虽然最终信息抽取质量部分还是需要专家审核,但是已经极大的提高了信息抽取的效率。因为传统方法需要大量时间来完成数据清洗、标注和训练&am…...
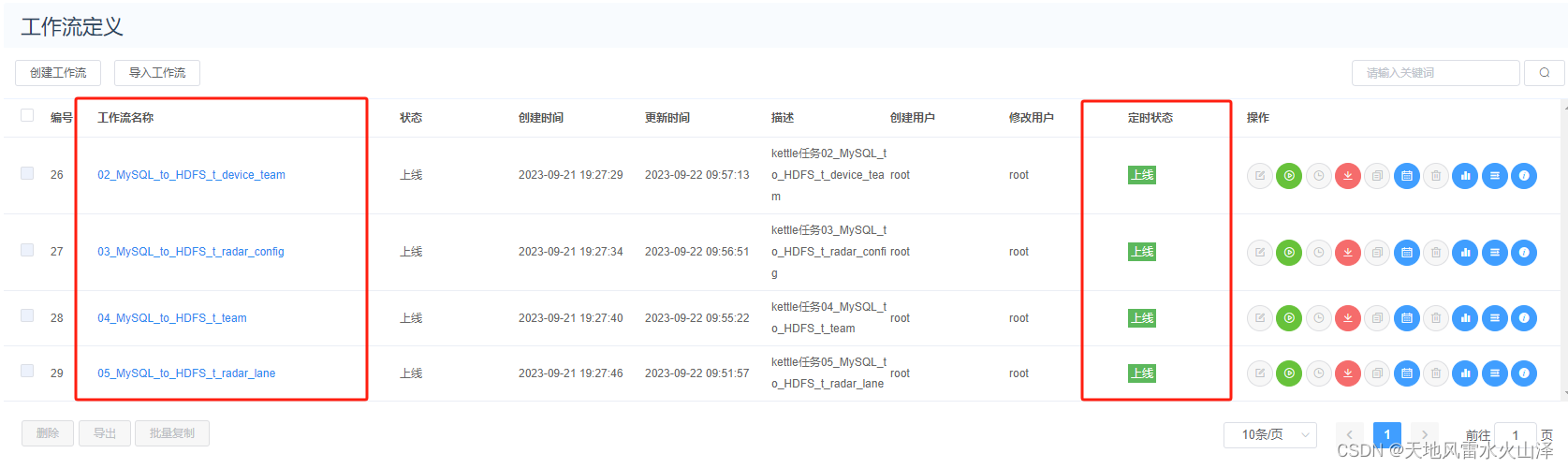
一百八十二、大数据离线数仓完整流程——步骤一、用Kettle从Kafka、MySQL等数据源采集数据然后写入HDFS
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、项目背景 项目行业属于交通行业,因此数据具有很…...
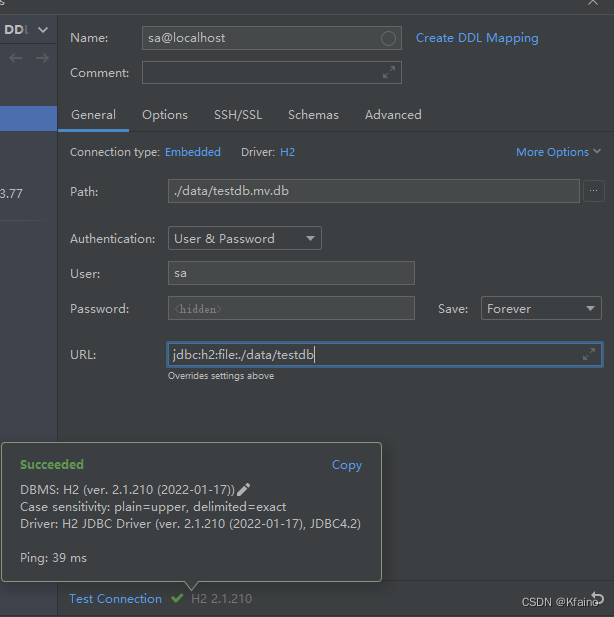
工具篇 | H2数据库的使用和入门
引言 1.1 H2数据库概述 1.1.1 定义和特点 H2数据库是一款以 Java编写的轻量级关系型数据库。由于其小巧、灵活并且易于集成,H2经常被用作开发和测试环境中的便利数据库解决方案。除此之外,H2也适合作为生产环境中的嵌入式数据库。它不仅支持标准的SQL…...
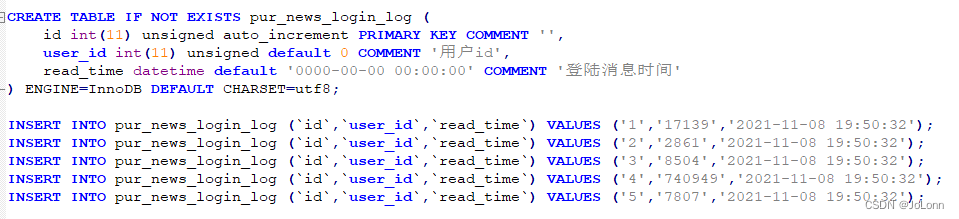
PHP脚本导出MySQL数据库
背景:有时候需要同步数据库的表结构和部分数据,同步全表数据非常大,也不适合。还有一个种办法是使用数据库的dump命令执行备份,无法进入服务器?没有权限怎么办? 这里只要能访问服务器中的 information_sch…...

生成随机单据号
背景:全局生成4位字符2222-9ZZ9 实现方式: 使用redis的原子自增 google的retry保证,生成4位数 1、pom <dependency><groupId>com.github.rholder</groupId><artifactId>guava-retrying</artifactId><v…...

【计算机网络笔记五】应用层(二)HTTP报文
HTTP 报文格式 HTTP 协议的请求报文和响应报文的结构基本相同,由四部分组成: ① 起始行(start line):描述请求或响应的基本信息;② 头部字段集合(header):使用 key-valu…...
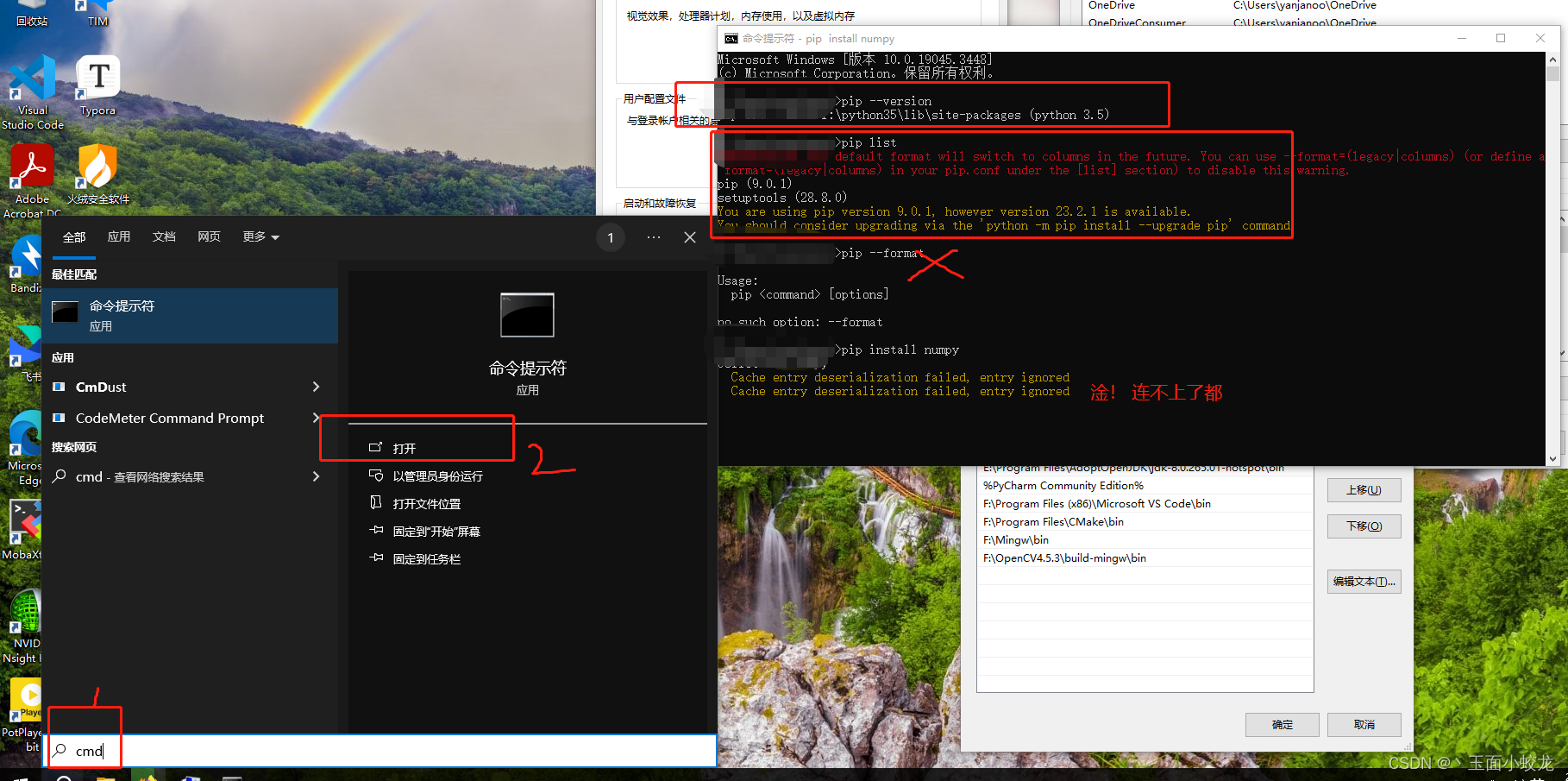
安装Python3.x--Windows
1 下载安装包 确定安装是干什么,要下哪个版本(如果是配置项目环境,最好按项目需求的版本来装) 1.1 官网链接 https://www.python.org 最新版本 指定版本 2 安装说明 点击下载exe,运行自定义安装路径,下…...

坐标休斯顿,TDengine 受邀参与第九届石油天然气数字化大会
美国中部时间 9 月 14 日至 15 日,第九届石油天然气数字化大会在美国德克萨斯州-休斯顿-希尔顿美洲酒店举办。本次大会汇聚了数百名全球石油天然气技术高管及众多极具创新性的数据技术方案商,组织了上百场硬核演讲,技术专家与行业从业者共聚一…...
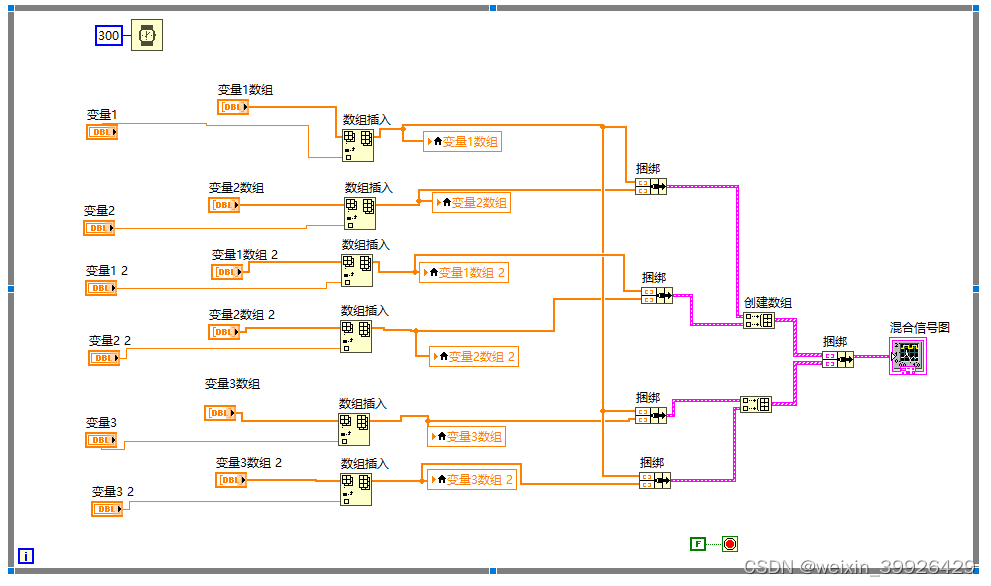
labview 混合信号图 多曲线分组
如果你遇到了混合信号图 多曲线分组显示的问题,本文能给你帮助。 在文章的最好,列出了参考程序下载链接。 一个混合信号图中可包含多个绘图区域。 但一个绘图区域仅能显示数字曲线或者模拟曲线之一,无法兼有二者。 以下显示的分两组&#…...
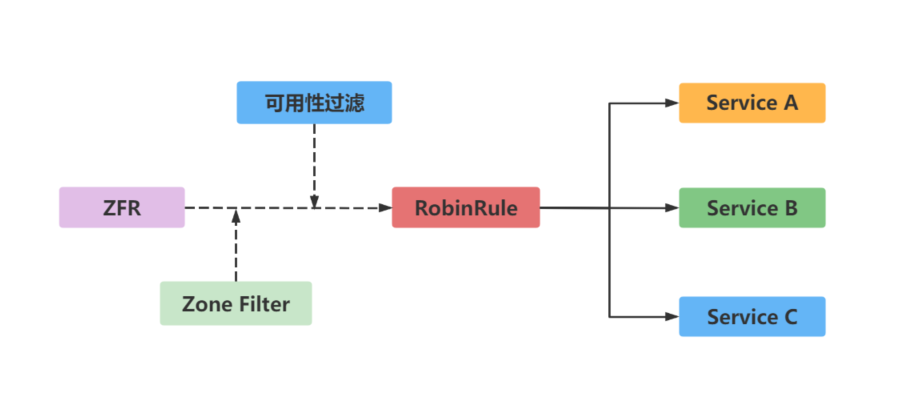
客户端负载均衡_负载均衡策略
以前的Ribbon有多种负载均衡策略 RandomRule - 随性而为 解释: 随机 RoundRobinRule - 按部就班 解释: 轮询 RetryRule - 卷土重来 解释: 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试。 Weigh…...
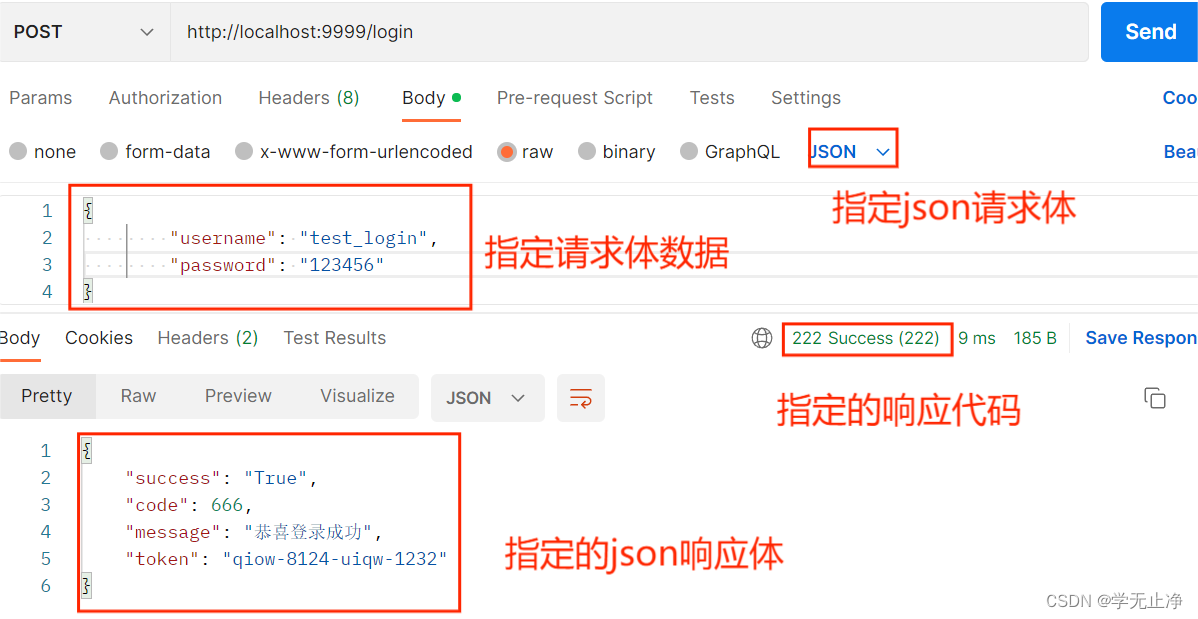
使用Python+Flask/Moco框架/Fiddler搭建简单的接口Mock服务
一、Mock测试 1、介绍 mock:就是对于一些难以构造的对象,使用虚拟的技术来实现测试的过程mock测试:在测试过程中,对于某些不容易构造或者不容易获取的对象,可以用一个虚拟的对象来代替的测试方法接口mock测试&#x…...

【Vue】Mock.js介绍和使用与首页导航栏左侧菜单搭建
目录 一、Mock.js 1.1 mockjs介绍 1.2 mock.js安装与配置 1.2.1 安装mock.js 1.2.2 引入mock.js 1.3 mock.js的使用 1.3.1 准备模拟数据 1.3.2 定义拦截路由 1.3.3 测试 二、首页导航栏左侧菜单搭建 2.1 自定义界面组件 (完整代码) 2.2 配置路由 2.3 组件显示折叠和…...

离散小波变换(概念与应用)
目录 概念光伏功率预测中,如何用离散小波变换提取高频特征概念 为您简单地绘制一些示意图来描述离散小波变换的基本概念。但请注意,这只是一个简化的示意图,可能不能完全捕捉到所有的细节和特性。 首先,我将为您绘制一个简单的小波函数和尺度函数的图像。然后,我会提供一…...

代码随想录day49:动态规划part10
121.买卖股票的最佳时机 贪心: class Solution { public:int maxProfit(vector<int>& prices) {int low INT_MAX;int result 0;for (int i 0; i < prices.size(); i) {low min(low, prices[i]); // 取最左最小价格result max(result, prices[i…...

fofa搜索使用
fofa搜索使用 文章目录 fofa搜索使用网站fofa搜索语法多条件查询 网站fofa https://fofa.info/搜索语法 1.title”beijing”从标题中搜索“北京2.headerQ"thinkphp”从http响应头中搜索“thinkphp3.body”管理后台”从html正文中搜索“管理后台4.domain”163.com”从子域…...

husky+lint-staged+eslint+prettier+stylelint+commitlint
概念: husky,暴露出git的hook钩子,在这些钩子执行一些命令,lint-staged,只在git的暂存区有修改的文件进行lint操作,执行一些校验脚本eslint,prettier,styelint有npm包还有对应的scode插件,其中npm包是用于执行那些诸如入eslint --fix "src/**/*.{js,jsx,…}"的脚本命…...

图像处理与计算机视觉--第四章-图像滤波与增强-第一部分
目录 1.灰度图亮度调整 2.图像模板匹配 3.图像裁剪处理 4.图像旋转处理 5.图像邻域与数据块处理 学习计算机视觉方向的几条经验: 1.学习计算机视觉一定不能操之过急,不然往往事倍功半! 2.静下心来,理解每一个函数/算法的过程和精髓&…...

【go】字符串切片与字符串出入数据库转化
文章目录 需求代码入库出库 需求 将请求数据存入数据库与从数据库读取数据返回在出库不使用反序列化情况下 请求结构体 type NoticegroupsCreateReq struct {Name string json:"name" binding:"required"UserIds []string json:"user_ids…...
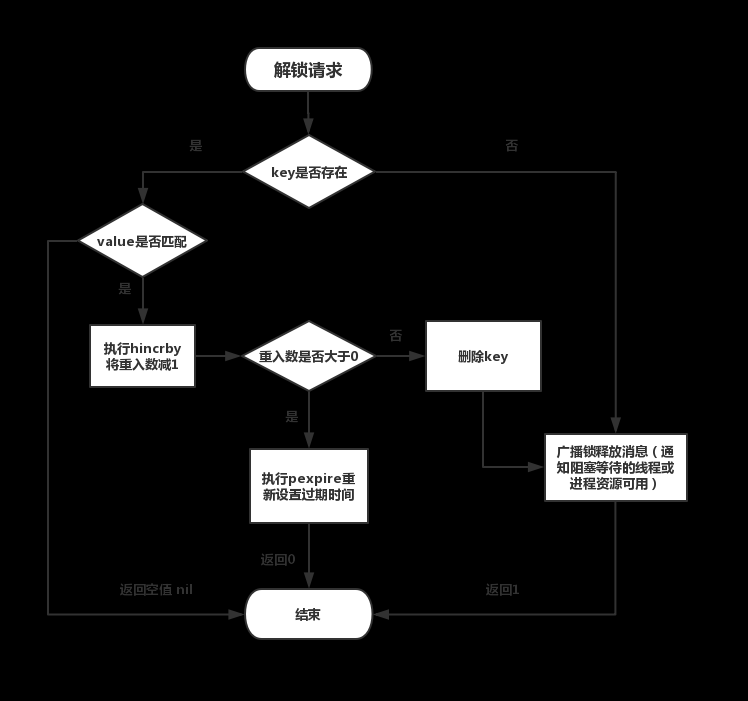
Redis中是如何实现分布式锁的?
分布式锁常见的三种实现方式: 数据库乐观锁; 基于Redis的分布式锁; 基于ZooKeeper的分布式锁。 本次面试考点是,你对Redis使用熟悉吗?Redis中是如何实现分布式锁的。 要点 Redis要实现分布式锁,以下条件应…...

似然和概率
前言 高斯在处理正态分布的首次提出似然,后来英国物理学家,费歇尔 概率是抛硬币之前,根据环境推断概率 似然则相反,根据结果推论环境 P是关于x的函数,比如x为正面朝上的结果,或者反面朝上的结果…...

Webpack优化实战:从配置到性能调优
Webpack优化实战:从配置到性能调优 大家好,我是蔓蔓。在大厂工作时,我负责过多个大型项目的Webpack配置和优化。今天我来和大家分享Webpack优化的实战技巧。 基础优化 合理配置mode // webpack.config.js module.exports {mode: process.env…...
)
【免费下载】 AD7124中文手册(非常完整)
AD7124中文手册(非常完整) 【下载地址】AD7124中文手册非常完整 AD7124-8是一款高性能模拟前端,设计用于在各种苛刻环境中实现精确的数据采集。这款芯片的特点在于其内置的高精度24位Σ-Δ模数转换器(ADC),能够灵活配置以支持8个差…...

SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅
SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过,一张普通的图片如何能变成一个会思考、会对话、…...

Claude帮用户找回40万美元Bitcoin:AI在密码破解上真正擅长的是什么?
一名美国男子在2013年买了5个BTC,2015年在醉酒后修改钱包密码,忘记了新密码。 11年后,他用Claude找回了价值40万美元的资产。 网友:AI真的很神奇。 但很少有人问这个问题:Claude到底是怎么做到的,以及更重要…...

私域流量红利见顶?那是你没解锁企业微信 API 的隐藏玩法!
在公域流量成本居高不下的今天,“私域流量”成了每个品牌的标配。然而,许多企业在把客户拉进企业微信后,却发现运营陷入了瓶颈:每天机械地群发广告,客户互动率低,退群率却居高不下。很多人惊呼:…...

从U-net到U-net++:探索跳跃连接的演进与优化
1. U-net的跳跃连接:从基础原理到核心价值 我第一次接触U-net是在处理医学影像分割项目时。当时试遍了各种模型,直到发现这个结构简洁却效果惊人的网络,才真正体会到跳跃连接(Skip Connection)的魔力。简单来说&#x…...


移动魔百盒CM101s刷机后体验:告别卡顿,解锁安装自由,这存储空间真香!
移动魔百盒CM101s焕新体验:从卡顿到流畅的全方位升级 每次打开电视都要忍受漫长的加载等待,存储空间不足导致无法安装新应用,系统自带功能单一无法满足全家需求——这或许是许多移动魔百盒CM101s用户的共同困扰。经过一周的深度使用测试&…...

WarcraftHelper:魔兽争霸3终极兼容性增强插件完整指南
WarcraftHelper:魔兽争霸3终极兼容性增强插件完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为《魔兽争霸…...

基于加速度计的体感音乐控制器:用MakeCode与Circuit Playground Express实现交互式乐器
1. 项目概述:当硬件编程遇见音乐创作 如果你对嵌入式开发、物理计算或者音乐技术感兴趣,但又觉得从零开始门槛太高,那么这个项目可能就是为你量身定做的。今天我们来聊聊如何用一块巴掌大的开发板——Adafruit的Circuit Playground Express&a…...