一百八十二、大数据离线数仓完整流程——步骤一、用Kettle从Kafka、MySQL等数据源采集数据然后写入HDFS
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、项目背景
项目行业属于交通行业,因此数据具有很多交通行业的特征,比如转向比数据就是统计车辆左转、右转、直行、掉头的车流量等等。
三、业务需求
(一)预估数据规模
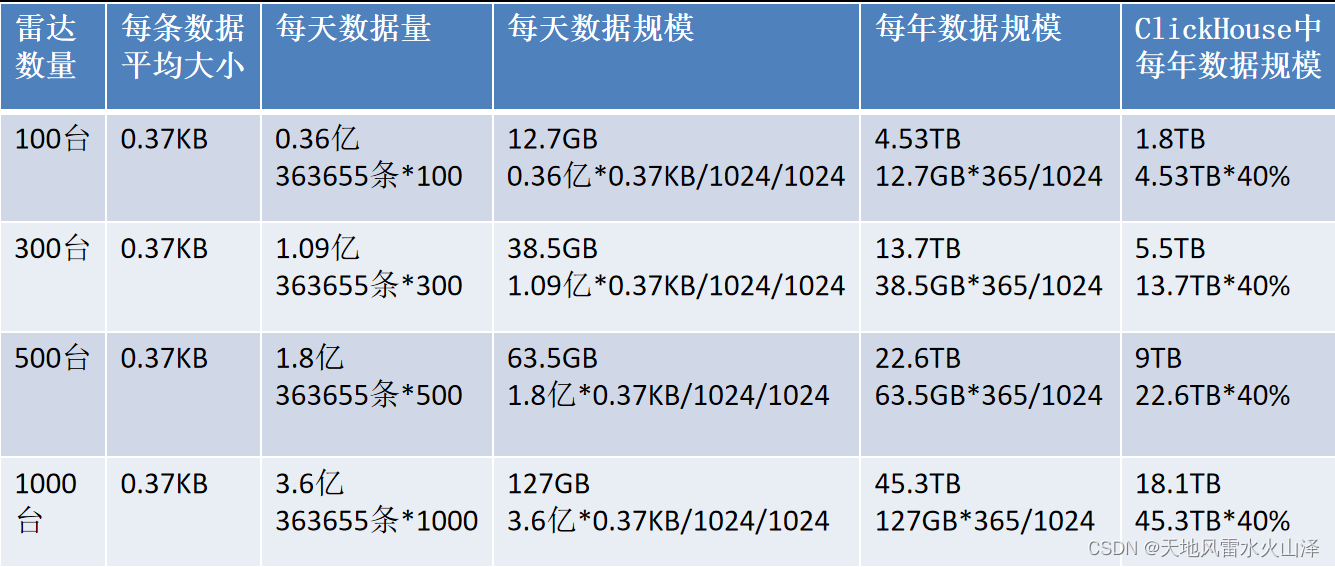
(二)指标查询频率
指标的实时查询由Flink实时数仓计算,离线数仓这边提供指标的T+1的历史数据查询
四、数仓技术架构
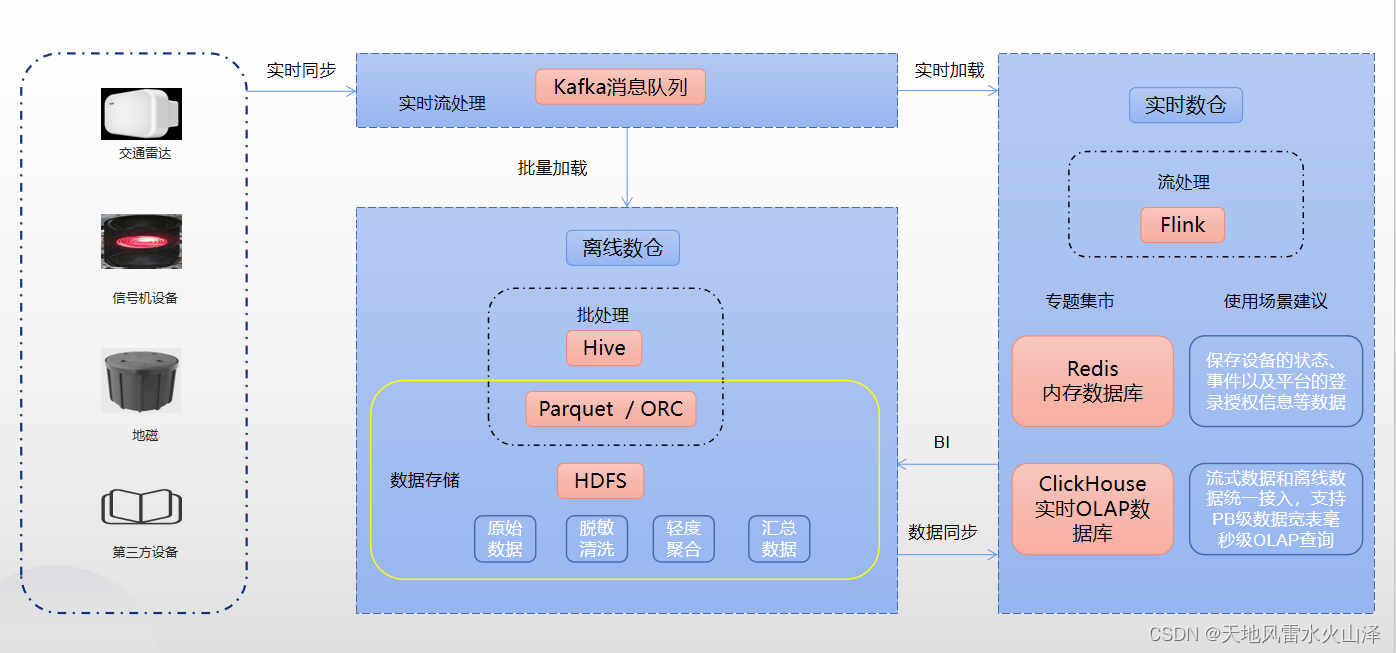
(一)简而言之,数仓模块的数据源是Kafka,终点是ClickHouse数据库
第一步,用kettle采集Kafka的数据写入到HDFS中;
第二步,在Hive中建数仓,ODS层、DWD层和DWS层
第三步,把Hive的DWS层处理好的结果数据用kettle同步到ClickHouse数据库中
(二)注意点
1、ETL工具统一使用kettle
2、调度工具是海豚调度器
五、数仓环境部署
(一)部署原则:易部署、易维护
(二)部署工具及其版本
1、jdk1.8.0
2、MySQL8.0.31
3、Kafka_2.13-3.0.0(Kafka自带ZooKeeper)
4、ClickHouse21.9.5.16
5、Hadoop3.1.3
6、Hive3.1.2(不要用Spark作为计算引擎,默认的mr即可)
7、DolphinScheduler2.0.5
8、Kettle9.2
(三)部署脚本以及部署文档
由于一开始的数据规模不大以及服务器资源有限问题,所以目前使用的单机版部署,没有部署集群
六、数仓实施步骤(搭建好数仓环境后)
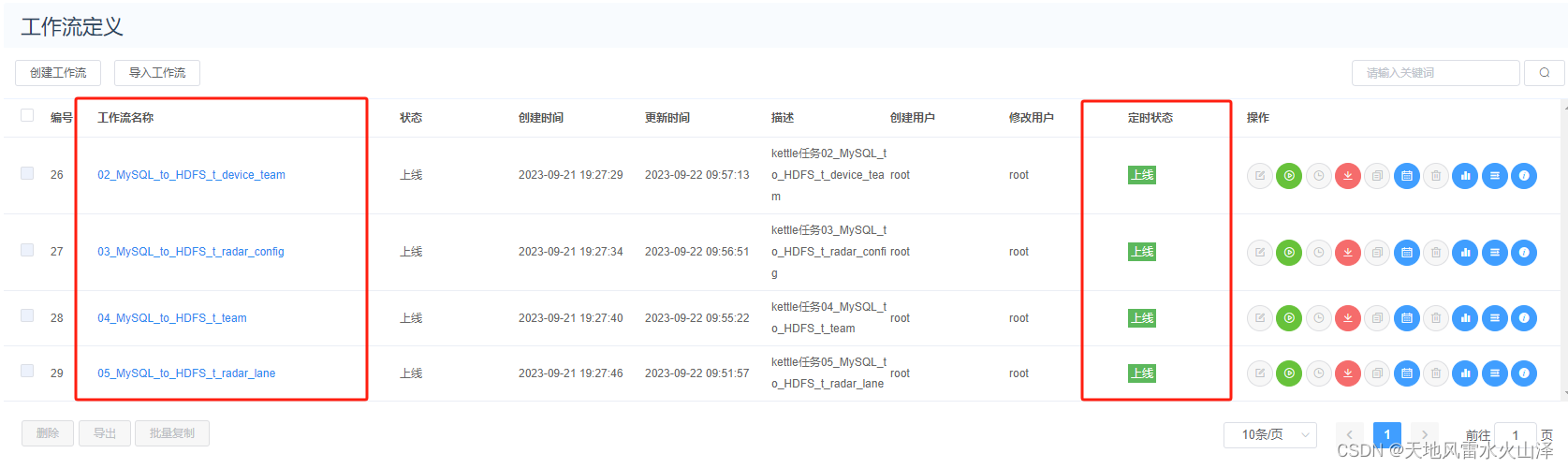
(一)步骤一、用Kettle从Kafka、MySQL等数据源采集数据然后写入HDFS
1、Kettle转换任务配置
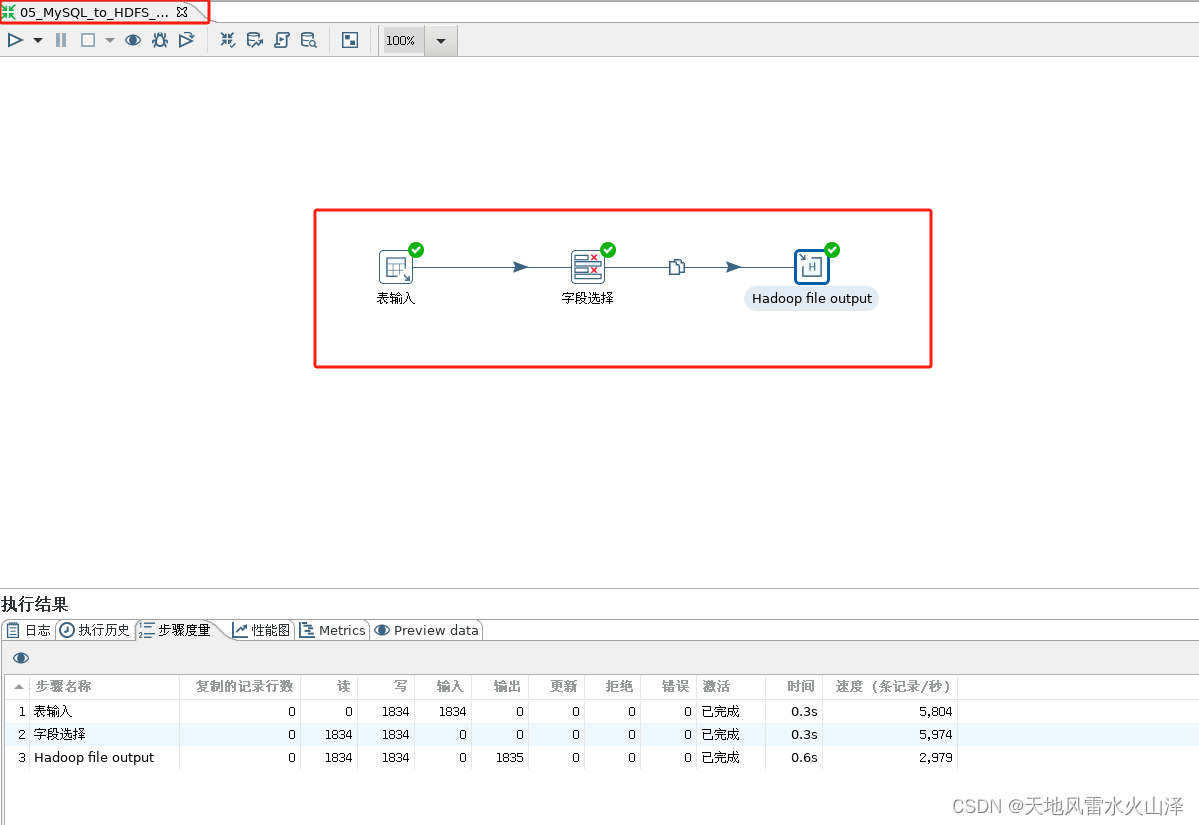
(1)样例一:维度表数据——从MySQL导入数据到HDFS
(2)样例二:事实表数据——从Kafka采集数据到HDFS
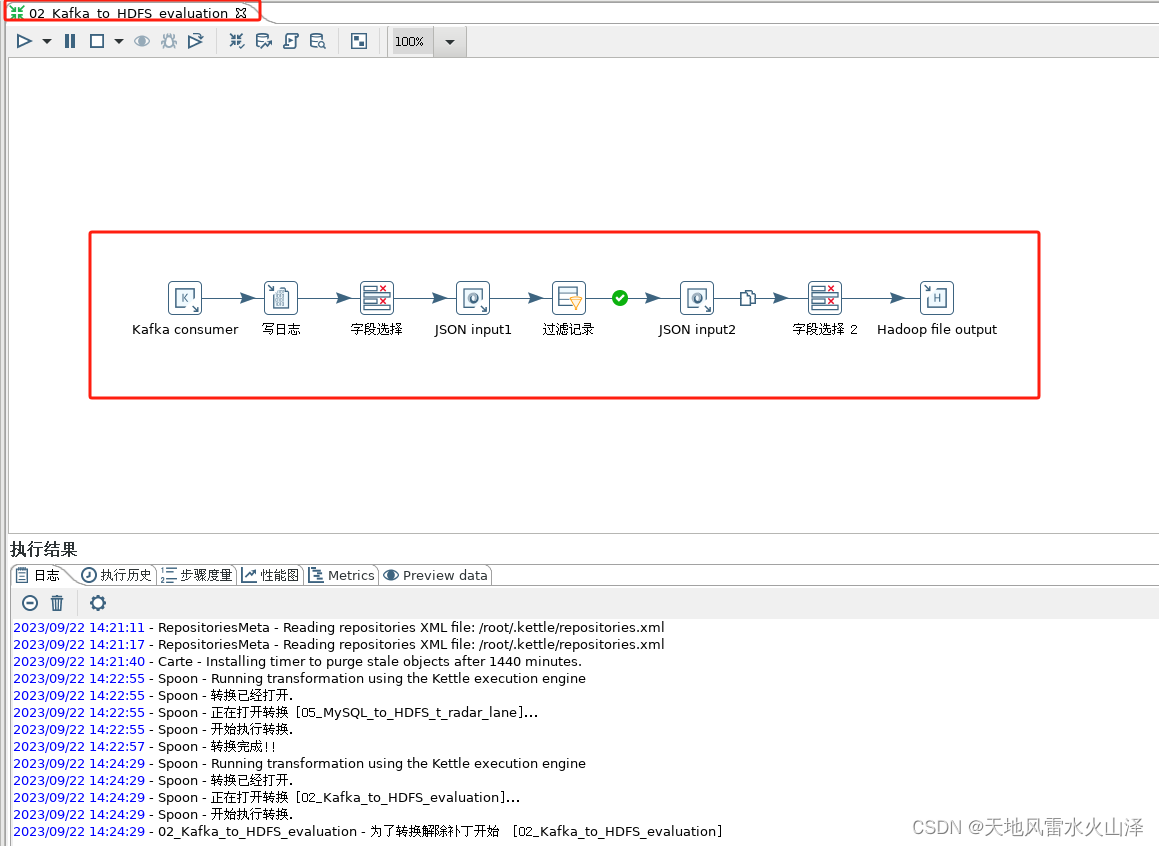
2、Kettle转换任务配置注意点
(1)维度表数据——从MySQL导入数据到HDFS
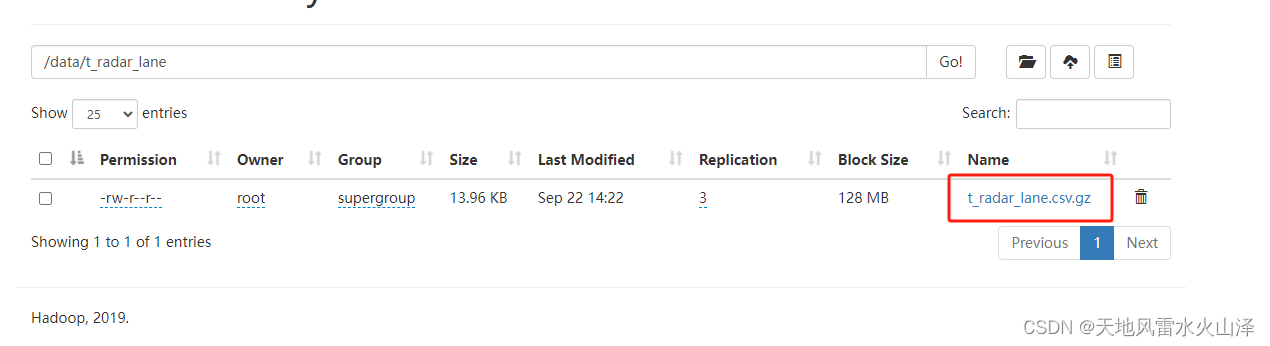
2.1.1、由于维度表数据量少,因此直接overwrite写入HDFS中,每次都是覆盖的全量导入
2.1.2、为了减少磁盘资源使用,在Hadoop file output控件中加了gzip压缩方式
(2)事实表数据——从Kafka采集数据到HDFS
2.2.1、由于Kafka的数据在不停发送,所以Kettle任务就需要一直运行。
2.2.2、由于HDFS的特性是以packet为单位写入,一个packet是64KB,所以不能根据日期每天自动生成一个HDFS文件,那样的话每天都会丢失一部分数据。
因为只要每天最后剩余的数据不满64KB,那这部分数据就不会写入。kettle任务直接生成第二天的数据文件、写入第二天的数据,即使这天的数据文件的状态还在写入。
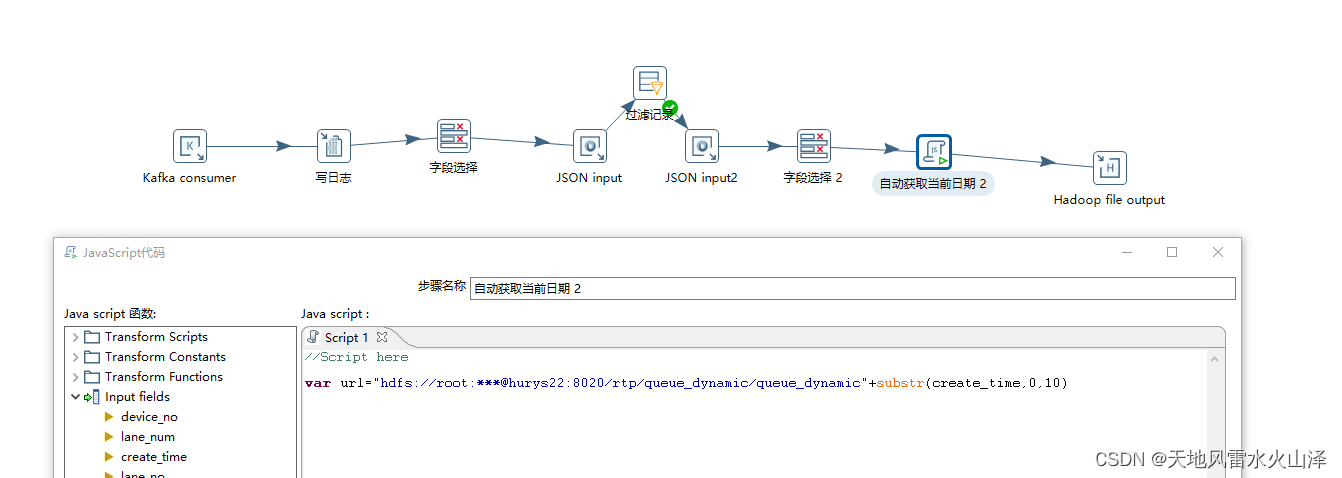

所以就直接生成一个HDFS文件,一直在这个文件里写入数据即可。后面先get到Linux本地,然后再overwrite写入HDFS的ODS层表中,这样不会每天丢数据。
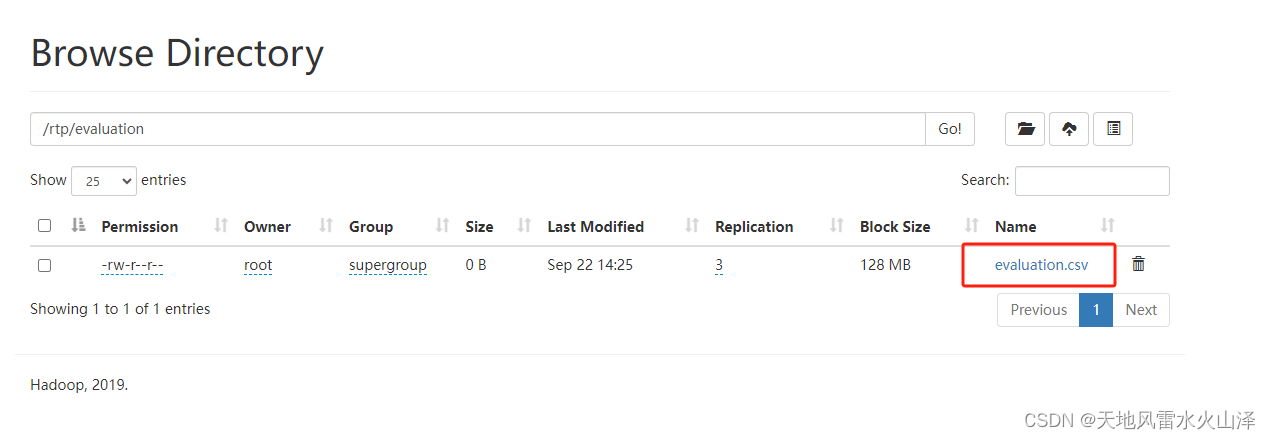
2.2.3、由于kettle任务需要一直运行,所以Hadoop file output控件不能添加数据压缩方式。
否则虽然显示HDFS文件有数据,但只要任务不停止文件就不会压缩,这样HDFS文件实际上没有数据,所以HDFS文输出控件不能添加压缩
3、海豚调度器调度kettle转换任务
(1)首先,为了便于团队开发,kettle需要配置共享资源库,把kettle任务统一放在资源库中运行。
用海豚调度kettle任务不需要开启carte服务,如果是用xxl-job调度,那可以开启carte服务
(2)对于事实表数据——从Kafka采集数据到HDFS
3.2.1、脚本不要加日志文件,因为数据量太大。
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/kettle/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/kafka_to_hdfs/ -trans=02_Kafka_to_HDFS_evaluation

3.2.2、工作流不需要定时,直接启动,一直跑任务即可

(3)对于维度表数据——从MySQL导入数据到HDFS
3.3.1、脚本可以添加日志文件
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/kettle/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -trans=04_MySQL_to_HDFS_t_team level=Basic >>/home/log/kettle/04_MySQL_to_HDFS_t_team_`date +%Y%m%d`.log

3.3.2、工作流需要定时,不过需要注意不同工作流的定时时间,保留工作流之间充足的定时区间
剩余数仓部分,待续!
相关文章:
一百八十二、大数据离线数仓完整流程——步骤一、用Kettle从Kafka、MySQL等数据源采集数据然后写入HDFS
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、项目背景 项目行业属于交通行业,因此数据具有很…...
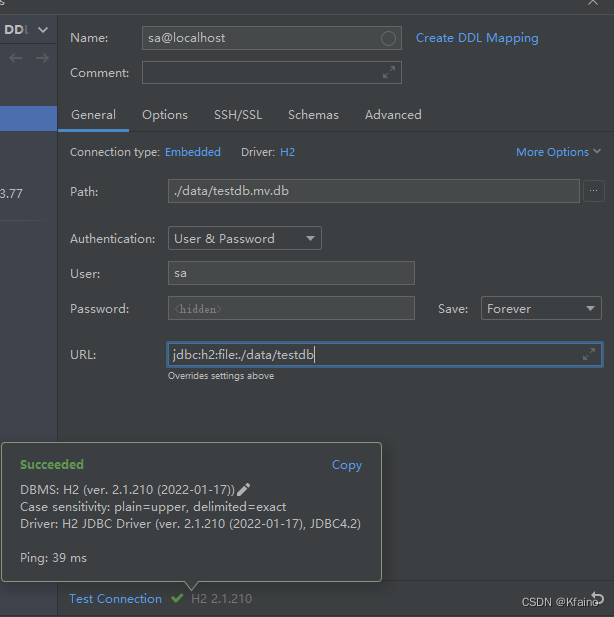
工具篇 | H2数据库的使用和入门
引言 1.1 H2数据库概述 1.1.1 定义和特点 H2数据库是一款以 Java编写的轻量级关系型数据库。由于其小巧、灵活并且易于集成,H2经常被用作开发和测试环境中的便利数据库解决方案。除此之外,H2也适合作为生产环境中的嵌入式数据库。它不仅支持标准的SQL…...
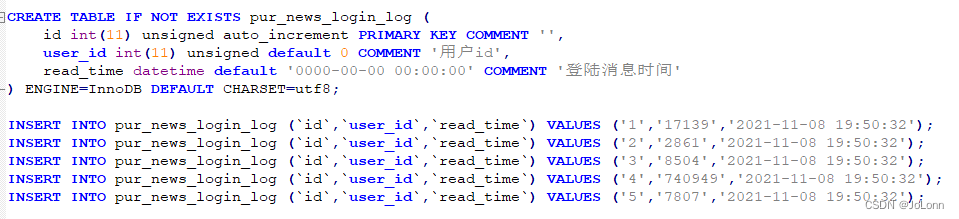
PHP脚本导出MySQL数据库
背景:有时候需要同步数据库的表结构和部分数据,同步全表数据非常大,也不适合。还有一个种办法是使用数据库的dump命令执行备份,无法进入服务器?没有权限怎么办? 这里只要能访问服务器中的 information_sch…...

生成随机单据号
背景:全局生成4位字符2222-9ZZ9 实现方式: 使用redis的原子自增 google的retry保证,生成4位数 1、pom <dependency><groupId>com.github.rholder</groupId><artifactId>guava-retrying</artifactId><v…...

【计算机网络笔记五】应用层(二)HTTP报文
HTTP 报文格式 HTTP 协议的请求报文和响应报文的结构基本相同,由四部分组成: ① 起始行(start line):描述请求或响应的基本信息;② 头部字段集合(header):使用 key-valu…...
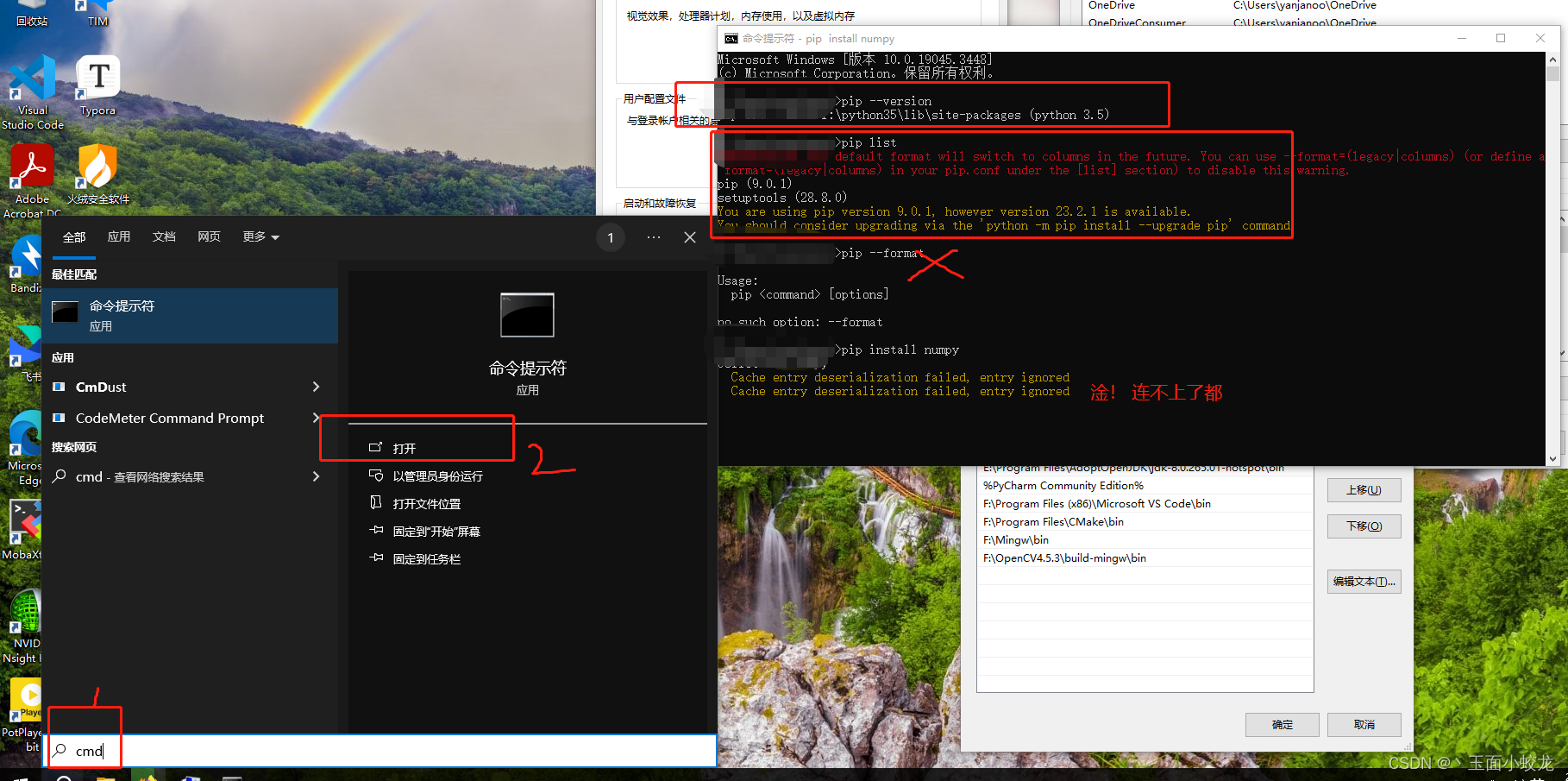
安装Python3.x--Windows
1 下载安装包 确定安装是干什么,要下哪个版本(如果是配置项目环境,最好按项目需求的版本来装) 1.1 官网链接 https://www.python.org 最新版本 指定版本 2 安装说明 点击下载exe,运行自定义安装路径,下…...

坐标休斯顿,TDengine 受邀参与第九届石油天然气数字化大会
美国中部时间 9 月 14 日至 15 日,第九届石油天然气数字化大会在美国德克萨斯州-休斯顿-希尔顿美洲酒店举办。本次大会汇聚了数百名全球石油天然气技术高管及众多极具创新性的数据技术方案商,组织了上百场硬核演讲,技术专家与行业从业者共聚一…...
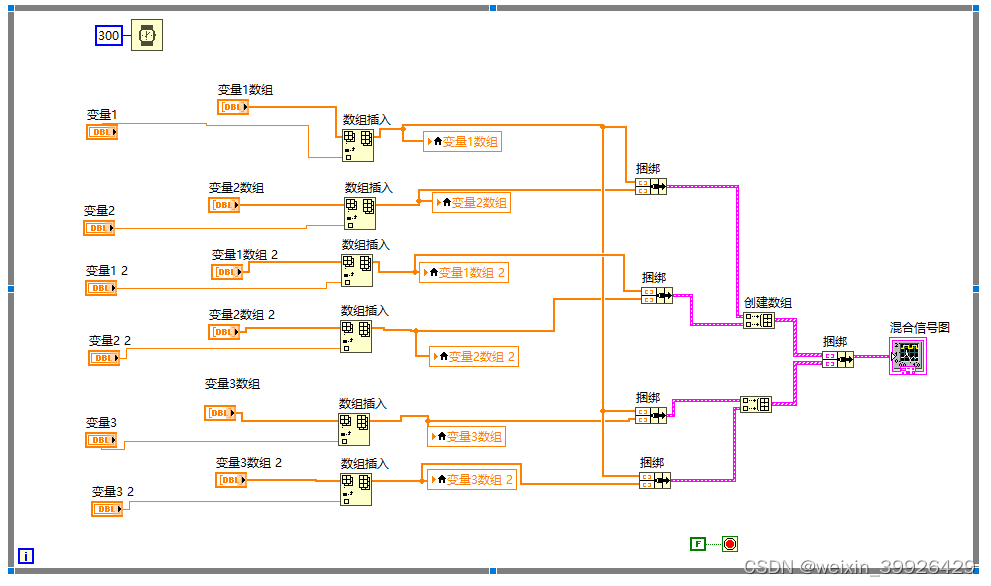
labview 混合信号图 多曲线分组
如果你遇到了混合信号图 多曲线分组显示的问题,本文能给你帮助。 在文章的最好,列出了参考程序下载链接。 一个混合信号图中可包含多个绘图区域。 但一个绘图区域仅能显示数字曲线或者模拟曲线之一,无法兼有二者。 以下显示的分两组&#…...
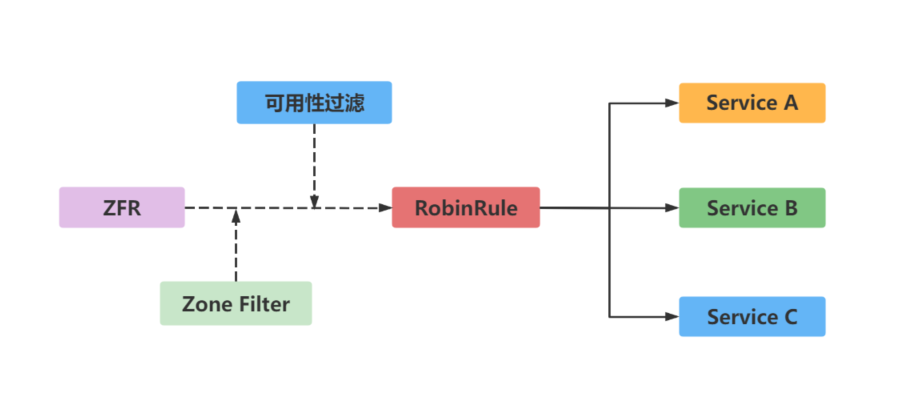
客户端负载均衡_负载均衡策略
以前的Ribbon有多种负载均衡策略 RandomRule - 随性而为 解释: 随机 RoundRobinRule - 按部就班 解释: 轮询 RetryRule - 卷土重来 解释: 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试。 Weigh…...
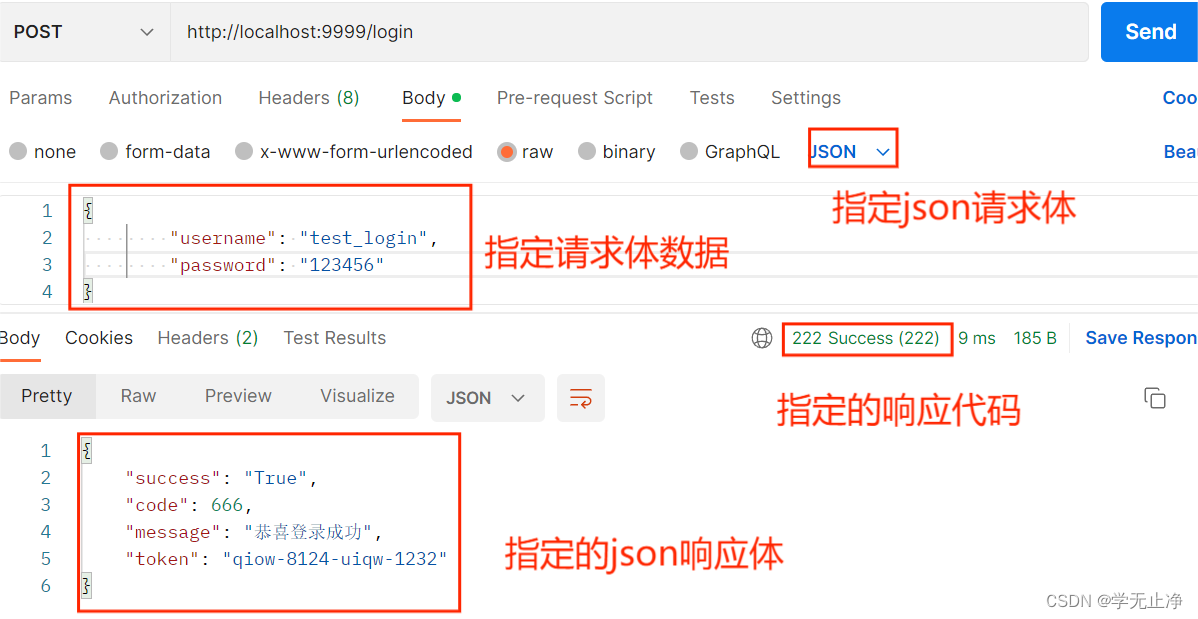
使用Python+Flask/Moco框架/Fiddler搭建简单的接口Mock服务
一、Mock测试 1、介绍 mock:就是对于一些难以构造的对象,使用虚拟的技术来实现测试的过程mock测试:在测试过程中,对于某些不容易构造或者不容易获取的对象,可以用一个虚拟的对象来代替的测试方法接口mock测试&#x…...

【Vue】Mock.js介绍和使用与首页导航栏左侧菜单搭建
目录 一、Mock.js 1.1 mockjs介绍 1.2 mock.js安装与配置 1.2.1 安装mock.js 1.2.2 引入mock.js 1.3 mock.js的使用 1.3.1 准备模拟数据 1.3.2 定义拦截路由 1.3.3 测试 二、首页导航栏左侧菜单搭建 2.1 自定义界面组件 (完整代码) 2.2 配置路由 2.3 组件显示折叠和…...

离散小波变换(概念与应用)
目录 概念光伏功率预测中,如何用离散小波变换提取高频特征概念 为您简单地绘制一些示意图来描述离散小波变换的基本概念。但请注意,这只是一个简化的示意图,可能不能完全捕捉到所有的细节和特性。 首先,我将为您绘制一个简单的小波函数和尺度函数的图像。然后,我会提供一…...

代码随想录day49:动态规划part10
121.买卖股票的最佳时机 贪心: class Solution { public:int maxProfit(vector<int>& prices) {int low INT_MAX;int result 0;for (int i 0; i < prices.size(); i) {low min(low, prices[i]); // 取最左最小价格result max(result, prices[i…...

fofa搜索使用
fofa搜索使用 文章目录 fofa搜索使用网站fofa搜索语法多条件查询 网站fofa https://fofa.info/搜索语法 1.title”beijing”从标题中搜索“北京2.headerQ"thinkphp”从http响应头中搜索“thinkphp3.body”管理后台”从html正文中搜索“管理后台4.domain”163.com”从子域…...

husky+lint-staged+eslint+prettier+stylelint+commitlint
概念: husky,暴露出git的hook钩子,在这些钩子执行一些命令,lint-staged,只在git的暂存区有修改的文件进行lint操作,执行一些校验脚本eslint,prettier,styelint有npm包还有对应的scode插件,其中npm包是用于执行那些诸如入eslint --fix "src/**/*.{js,jsx,…}"的脚本命…...

图像处理与计算机视觉--第四章-图像滤波与增强-第一部分
目录 1.灰度图亮度调整 2.图像模板匹配 3.图像裁剪处理 4.图像旋转处理 5.图像邻域与数据块处理 学习计算机视觉方向的几条经验: 1.学习计算机视觉一定不能操之过急,不然往往事倍功半! 2.静下心来,理解每一个函数/算法的过程和精髓&…...

【go】字符串切片与字符串出入数据库转化
文章目录 需求代码入库出库 需求 将请求数据存入数据库与从数据库读取数据返回在出库不使用反序列化情况下 请求结构体 type NoticegroupsCreateReq struct {Name string json:"name" binding:"required"UserIds []string json:"user_ids…...
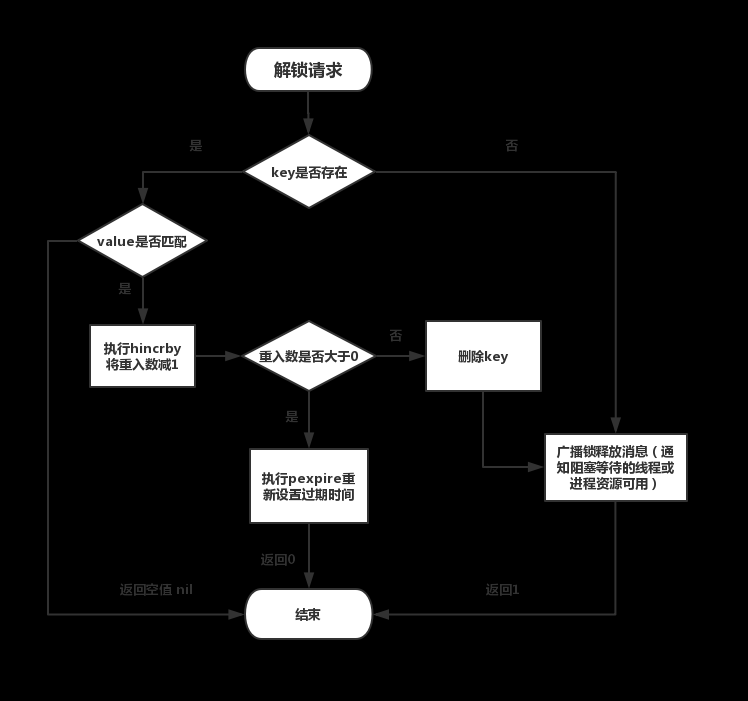
Redis中是如何实现分布式锁的?
分布式锁常见的三种实现方式: 数据库乐观锁; 基于Redis的分布式锁; 基于ZooKeeper的分布式锁。 本次面试考点是,你对Redis使用熟悉吗?Redis中是如何实现分布式锁的。 要点 Redis要实现分布式锁,以下条件应…...

似然和概率
前言 高斯在处理正态分布的首次提出似然,后来英国物理学家,费歇尔 概率是抛硬币之前,根据环境推断概率 似然则相反,根据结果推论环境 P是关于x的函数,比如x为正面朝上的结果,或者反面朝上的结果…...

php代码审计篇熊海cms代码审计
文章目录 自动审计逐个分析首页index.php文件包含漏洞后台逻辑漏洞cookie绕过登录后台sql报错注入存储型XSS 结束吧 自动审计 看到有很多 逐个分析 首页index.php文件包含漏洞 读一下代码,可以看到很明显的一个文件包含 <?php //单一入口模式 error_repor…...

红队实战靶场搭建与ATTCK攻击链复现
1. 红队靶场环境搭建全流程 搭建红队实战靶场是安全研究的必修课,但很多新手常被复杂的网络配置劝退。我去年给某金融企业做内网渗透培训时,就遇到过学员集体卡在靶机互连阶段的尴尬场面。下面分享一套经过20企业实战验证的搭建方法。 首先需要准备三台虚…...

MLX90614红外测温传感器:从原理到Arduino实战应用指南
1. 项目概述:从接触式到非接触式的测温革新在嵌入式开发和物联网项目中,温度测量是一个永恒的主题。从传统的热敏电阻、DS18B20,到热电偶,我们习惯了将探头紧贴甚至刺入被测物体来获取读数。但你是否遇到过这样的困境:…...

【亲测免费】 探索卷积神经网络之美:一键绘制专业结构图的利器
探索卷积神经网络之美:一键绘制专业结构图的利器 【下载地址】卷积神经网络结构绘制工具 本资源适用于需要展示卷积神经网络具体结构的研究人员。用户下载本项目后,按照README官方教程中的“Getting Started”部分进行操作,简单学习语法后即可…...
)
TVA智能体范式的工业视觉革命(4)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Token工厂:无锡部署昇腾384超节点算力集群,制造Token
AI智能体正在成为人工智能发展新范式,Token调用量暴增,拉动算力产业链资本开支迅猛加速。据央视新闻,今年3月,我国日均Token调用量超140万亿,相比2024年初增长1000多倍。AI模型使用成本水涨船高,不少从业者…...

数据冗余与规范化的本质[数据库原理]
我们把它想象成整理一个乱七八糟的杂物间的过程。我们的目标是把所有东西分门别类放好,让找东西、放东西、更新东西都变得轻松,并且避免重复占用空间。 第一部分:为什么要“规范化”?—— 解决“大杂烩”表的三大痛点 假设我们管…...

魔兽争霸III终极优化指南:7个实用方案让经典游戏完美适配现代硬件
魔兽争霸III终极优化指南:7个实用方案让经典游戏完美适配现代硬件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为一款经典…...

随机化、盲法、匹配:让你的研究更接近“可信因果”——控制额外变量的策略与实验内部效度提升
在科研写作和研究设计中,很多人把注意力放在“用了什么统计方法”上,却忽视了一个更根本的问题:你的研究结果,真的是干预或自变量造成的吗?如果不是,那么即使你的 p 值很小、回归系数显著、模型拟合很好&am…...

设计师核心能力框架:从思维策略到工程落地的系统化成长路径
1. 项目概述:一个设计师的“内功”修炼场如果你是一名设计师,或者对设计工作感兴趣,那么你一定有过这样的时刻:面对一个设计任务,脑子里有无数想法,但打开软件却不知从何下手;或者看到别人的优秀…...

基于RAG的代码库智能助手:从原理到本地化部署实战
1. 项目概述:一个为开发者打造的“智能副驾”最近在GitHub上看到一个挺有意思的项目,叫maziminds/manage-buddy。光看名字,你可能会觉得它是个任务管理工具,或者是个团队协作软件。但当你真正点进去,仔细研究它的READM…...