Java --- MySQL8之索引优化与查询优化
目录
一、索引失效场景
1.1、全值匹配
1.2、最佳左前缀规则
1.3、主键插入顺序
1.4、计算、函数、类型转换(自动或手动)导致索引失效
1.5、类型转换导致索引失效
1.6、范围条件右边的列索引失效
1.7、不等于(!= 或者<>)索引失效
1.8、is null可以使用索引,is not null无法使用索引
1.9、like以通配符%开头索引失效
2.10、OR 前后存在非索引的列,索引失效
2.11、数据库和表的字符集统一使用utf8mb4
二、关联查询优化
2.1、左外连接
2.2、内连接
编辑2.3、join语句原理
2.3.1、驱动表与被驱动表
2.4、子查询优化
2.5、排序优化
2.6、filesort算法
2.6.1、双路排序(慢)
2.6.2、单路排序(快)
2.6.3、单路排序的优缺点
2.6.4、优化策略
2.7、GROUP BY优化
2.8、优化分页查询
三、覆盖索引
3.1、什么是覆盖索引
3.2、覆盖索引的优缺点
3.2.1、优点
3.2.2、缺点
四、索引下推
4.1、ICP的开启与关闭
4.2、ICP使用条件
五、其它查询优化策略
5.1、exists和in的区别
5.2、COUNT(*)与COUNT(具体字段)效率
5.3、select(*)的使用
5.4、limit 1的优化影响
5.5、多使用commit
六、数据库主键如何设计
6.1、自增ID的问题
6.2、主键设计
物理查询优化:通过索引和表连接方式等技术来进行优化。
逻辑查询优化:通过SQL等价变换提升查询效率。
数据准备:
创建表
CREATE TABLE `class`(
`id`INT(11)NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;#确保创建函数创建成功
SET GLOBAL log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。创建函数
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1));
RETURN i;
END //
DELIMITER创建存储过程
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu(START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;#设置手动提交事务
REPEAT#循环
SET i = i + 1;#赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT;#提交事务
END //
DELIMITER ;#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES (rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;删除某表上的索引
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND TABLE_NAME=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY';#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done=2;#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);一、索引失效场景
SQL语句是否使用索引、根数据库版本、数据量、数据选择度都有关系。
1.1、全值匹配
建立索引前:
SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND classId = 5 AND NAME = 'IFbpwl';#0.2s使用索引后查询时间:
CREATE INDEX idx_age ON student(age);#该索引使用查询后:0.03sCREATE INDEX idx_age_classid ON student(age,classId);#该索引使用查询后 0.005sCREATE INDEX idx_age_classid_name ON student(age,classId,NAME);#该索引使用查询后 0.002s1.2、最佳左前缀规则
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name = 'IFbpwl';总结:MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。如果查询条件中没有使用这些字段中第一个字段时,多列索引不会被使用。
1.3、主键插入顺序
实际开发中,主键值采用依次递增,这样可以减少性能损耗。
1.4、计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc'; 1.5、类型转换导致索引失效
#未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = 123;
#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = '123'; 1.6、范围条件右边的列索引失效
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId>20 AND student.name = 'abc'; 
name没有使用上索引,因为像< ,> betwwen,>=,<=等右边的列的字段都不能使用索引,在实际开发中,如范围查询的字段建立联合索引时应放在末尾。
1.7、不等于(!= 或者<>)索引失效
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'adc';EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'adc';1.8、is null可以使用索引,is not null无法使用索引
#使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
#未使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;总结:设计数据表的时候就将字段设置为not null约束,同样not like也无法使用索引。
1.9、like以通配符%开头索引失效
#使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
#未使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE '%abc';2.10、OR 前后存在非索引的列,索引失效
CREATE INDEX idx_age ON student(age);
#因为classid字段没有索引会全表扫描,所有索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
#加上一个索引字段就可以解决
CREATE INDEX idx_cid ON student(classid);2.11、数据库和表的字符集统一使用utf8mb4
统一字符集可以避免由于字符集转换产生的乱码。不同的字符集进行比较前需要进行转换会造成索引失效
总结:
1、对于单列索引,尽量选择针对当前query过滤性更好的索引
2、在选择联合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
3、在选择联合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引。
4、在选择联合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
5、书写SQL语句,尽量避免造成索引失效的情况。
二、关联查询优化
CREATE TABLE IF NOT EXISTS `type`(
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,PRIMARY KEY (`id`)
);CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL
);INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `book`(card) VALUES(FLOOR(1 + (RAND() * 20)));2.1、左外连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
#添加索引
CREATE INDEX idx_bcard ON book(card);2.2、内连接
CREATE INDEX idx_bcard ON book(card);
CREATE INDEX idx_tcard ON TYPE(card);
DROP INDEX idx_bcard ON book;EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
查询优化器在内连接中可以选择那个作为驱动表与被驱动表
DROP INDEX idx_tcard ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card; 2.3、join语句原理
2.3、join语句原理
2.3.1、驱动表与被驱动表
内连接:
查询优化器会根据情况去调整驱动表与被驱动表
外连接:
在某些情况下查询优化器会优化为内连接来查询
总结:
1、整体效率比较:Index Nested-Loop Join > Block Nested-Loop Join > Simple Nested-Loop Join 。
2、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)(小的度量单位指的是表行数 * 每行大小)。
3、为被驱动表匹配的条件增加索引(减少内层表的循环匹配次数)。
4、增大join buffer size的大小(一次缓存的数据越多,那么内层包扫描次数就越少)。
5、减少驱动表不必要的字段查询(字段越少,join bufferr所缓存的数据就越多)。
2.4、子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结 果作为另一个SELECT语句的条件。 子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子 查询的执行效率不高。原因:
① 执行子查询时,MySQL需要为内层查询语句的查询结果 建立一个临时表 ,然后外层查询语句从临时表 中查询记录。查询完毕后,再 撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 不会存在索引 ,所以查询性能会 受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询 不需要建立临时表 ,其 速度比子查询 要快 ,如果查询中使用索引的话,性能就会更好。
2.5、排序优化
问题:
在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢?
回答:
在MySQL中,支持两种排序方式,分别为FileSort和index排序
①、index排序:索引可以保证数据的有序性,不需要再进行排序,效率更高。
②、FileSort排序一般在内存中进行排序,占用CPU较多,如待排序结果较大,会产生临时 文件I/O到磁盘进行排序的情况,效率较低。
优化:
1. SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中 避免全表扫 描 ,在 ORDER BY 子句 避免使用 FileSort 排序 。当然,某些情况下全表扫描,或者 FileSort 排 序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
2. 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列; 如果不同就使用联合索引。
3. 无法使用 Index 时,需要对 FileSort 方式进行调优。
#没有索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;
#创建索引
CREATE INDEX idx_age_classid_name ON student(age,classid,NAME);
#索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
#增加limit过滤条件,使用上索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10;结论:
1. 两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择
idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的 。
2. 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过 滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段 上。反之,亦然。
2.6、filesort算法
排序的字段如果不在索引列上,则filesort有两种算法:双路排序和单路排序。
2.6.1、双路排序(慢)
1、MySQL 4.1之前是使用双路排序 ,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和order by列 ,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取 对应的数据输出。
2、从磁盘取排序字段,在buffer进行排序,再从 磁盘取其他字段 。
2.6.2、单路排序(快)
从磁盘读取查询需要的 所有列 ,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输 出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空 间, 因为它把每一行都保存在内存中了。
2.6.3、单路排序的优缺点
1、由于单路是后出的,总体而言好过双路。
2、单路的问题:①、在sort_buffer中,单路比多路要多占用很多空间,因为单路是把所有字段都取出, 所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排……从而多次I/O。②、单路本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
2.6.4、优化策略
1、尝试提高 sort_buffer_size
2、尝试提高 max_length_for_sort_data
3、Order by 时select * 是一个大忌。最好只Query需要的字段。
2.7、GROUP BY优化
1、group by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接 使用索引。
2、group by 先排序再分组,遵照索引建的最佳左前缀法则。
3、当无法使用索引列,增大 max_length_for_sort_data 和 sort_buffer_size 参数的设置 。
4、where效率高于having,能写在where限定的条件就不要写在having中了。
5、减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
6、包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行 以内,否则SQL会很慢。
2.8、优化分页查询
优化方式1:在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
优化方式2:该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。
三、覆盖索引
3.1、什么是覆盖索引
理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它 不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数 据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列 (即建索引的字段正好是覆盖查询条件中所涉及的字段)。 简单说就是, 索引列+主键 包含 SELECT 到 FROM之间查询的列 。
示例1:
#创建索引
CREATE INDEX idx_age_name ON student(age,NAME);EXPLAIN SELECT * FROM student WHERE age != 20;
EXPLAIN SELECT age,NAME FROM student WHERE age != 20;
示例2:
EXPLAIN SELECT * FROM student WHERE NAME LIKE '%adc';
EXPLAIN SELECT age,NAME FROM student WHERE NAME LIKE '%adc';
3.2、覆盖索引的优缺点
3.2.1、优点
1、避免Innodb表进行索引的二次查询(回表)
Innodb以聚簇索引的顺序来存储,二级索引在叶子节点中保存行的主键信息,使用二级索引查询数据,找到对应主键,再通过主键查询获取到想要的信息。而覆盖索引,可以通过二级索引键值获取到想要的信息,避免了二次查询,减少io操作,提升查询效率。
2、可以把随机IO变成顺序IO加快查询效率
覆盖索引是按键值顺序存储的,对于IO密集型范围查找,可以利用覆盖索引在访问时将磁盘中的随机IO转变为索引查找的顺序IO。
覆盖索引可以减少树的搜索次数,提升查询性能,所以使用覆盖索引是性能优化常用手段。
3.2.2、缺点
索引字段的维护 总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。
四、索引下推
Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优 化方式。ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
4.1、ICP的开启与关闭
#关闭索引下推,默认开启状态
SET optimizer_switch = 'index_condition_pushdown=off';
#开启索引下推
SET optimizer_switch = 'index_condition_pushdown=on';4.2、ICP使用条件
① 只能用于二级索引(secondary index)
②explain显示的执行计划中type值(join 类型)为 range 、 ref 、 eq_ref 或者 ref_or_null 。
③ 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录 到server端做where过滤。
④ ICP可以用于MyISAM和InnnoDB存储引擎
⑤ MySQL 5.6版本的不支持分区表的ICP功能,5.7版本的开始支持。
⑥ 当SQL使用覆盖索引时,不支持ICP优化方法。
五、其它查询优化策略
5.1、exists和in的区别
那种情况下应该使用exists,那种情况下应该使用in,选择情况应该看使用表的索引吗?
索引是前提,选择是否要看表的大小,标准如小表驱动大表,这种效率最高。
5.2、COUNT(*)与COUNT(具体字段)效率
前提都是统计非空字段行数
环节1:COUNT(*)和COUNT(1)都是对所有结果进行count,两者本质上没有区别。如果有where子句,则对所有符合筛选条件的数据进行统计,如果没有where子句,则对数据行数进行统计。
环节2:如果是myisam存储引擎,统计数据表的行数只需要o(1)的复杂度,是因为每张myisam的数据表都有一个meta信息存储了row_count的值,而一致性则由表级锁来保证。
如果是innoDB存储引擎,支持事务,采用行级锁和MVCC机制,所以无法像myisam一样,维护一个row_count变量,因此需要采用扫描全表,是O(n)的复杂度,进行循环+计数的方式来完成统计。
环节3:在InnoDB引擎中,如果采用count(具体字段)来统计数据行数,要尽量采用二级索引。因为主键采用的索引是联合索引,联合索引包含的信息多,明显会大于二级索引。对于count(*)和count(1)不需要查找具体的行,只统计行数,系统会自动采用占用空间更小的二级索引来进行统计。
5.3、select(*)的使用
在查询语句中不要使用*作为查询的字段列表,原因:
①、MySQL在解析的过程中,会通过查询数据字典将*按序转换为所有列名,会大量消耗资源和时间。
②、无法使用覆盖索引。
5.4、limit 1的优化影响
针对的是扫描全表的SQL语句,当确定结果集只有一条的时候,加上limit 1找到一条结果的时候就不会继续扫描了,会加快查询速度。
当数据表建立了唯一索引,可以通过索引进行查询,不会全表扫描,加上limit 1意义不大。
5.5、多使用commit
尽可能在程序中多使用commit,程序性能得到提高,需求也会因为commit所释放的资源而减少。
commit所释放的资源:
①、回滚段上用于恢复的数据的信息。
②、被程序语句获得的锁。
③、redo/undo log buffer中的空间
六、数据库主键如何设计
6.1、自增ID的问题
1、可靠性不高
存在自增ID回溯的问题,到MySQL8.0后被修复
2、安全性不高
对外暴露的接口可以非常容易猜测对应的信息。
3、性能差
自增ID的性能较差,需要在数据库服务器断生成
4、交互多
业务还需要额外执行一次类似last_insert_id()的函数才能知道刚才插入的自增值,这需要多一次的网络交互。在海量并发的系统中,多1条上SQL,就多一次开销。
5、局部唯一性
自增id是局部唯一,只在当前数据库实现唯一,而不是全局唯一
6.2、主键设计
非核心业务:可以使用主键自增,如告警、日志、监控等信息
核心业务:主键设计至少应该是全局唯一性且是单调自增。
相关文章:
Java --- MySQL8之索引优化与查询优化
目录 一、索引失效场景 1.1、全值匹配 1.2、最佳左前缀规则 1.3、主键插入顺序 1.4、计算、函数、类型转换(自动或手动)导致索引失效 1.5、类型转换导致索引失效 1.6、范围条件右边的列索引失效 1.7、不等于(! 或者<>)索引失效 1.8、is null可以使用索引&…...

澳大利亚新版《2023年消费品(36个月以下儿童玩具) 安全标准》发布 旨在降低危险小零件的伤害
2023年9月4日,澳大利亚政府发布了新的儿童玩具强制性安全标准《2023年消费品(36个月以下儿童玩具)安全标准》(Consumer Goods (Toys for Children up to and including 36 Months of Age) Safety Standard 2023)。该强制性标准旨在尽可能地降…...

表格内日期比较计算
需求:在表格中新增数据,计算开始日期中最早的和结束日期中最晚的,回显到下方。 <el-formref"formRef":model"ruleForm":rules"rules"style"margin-top: 20px;"label-position"top">…...

Linux内核启动流程-第二阶段start_kernel 函数
一. Linux内核启动 上一篇文章简单介绍了 Linux内核启动的第一阶段,即执行汇编流程。 本文简单了解一下,Linux内核启动的第二阶段:start_kernel函数,这是一个 C 函数。 本文续上一篇文章的学习,地址如下:…...

Disruptor:无锁队列设计的背后原理
简介 在高并发场景下,队列的速度和效率是关键。而Disruptor,一种高性能的并发队列,通过独特的设计,解决了传统队列在处理高并发时可能遇到的性能瓶颈。本文将深入分析Disruptor如何通过环形数组结构、元素位置定位以及无锁设计&a…...
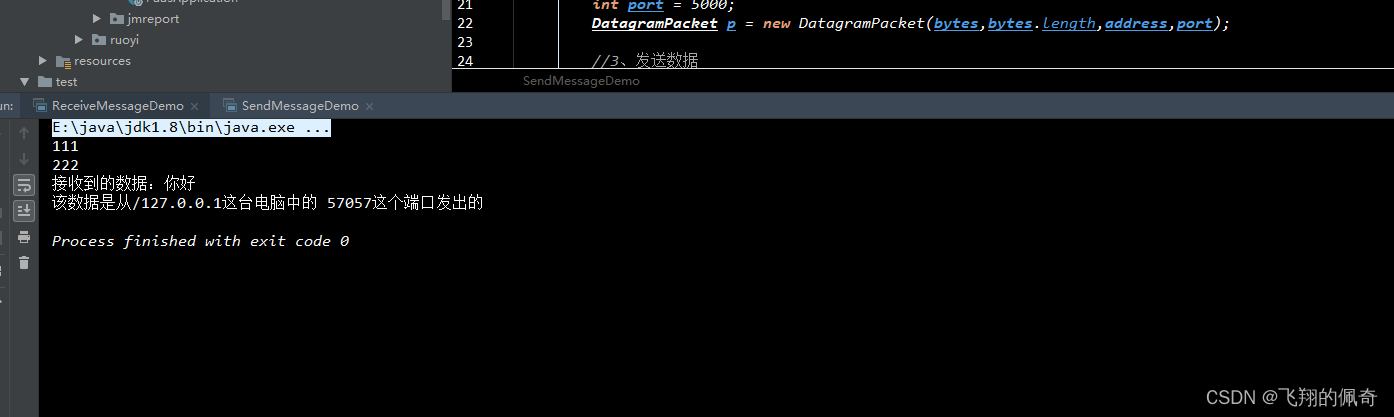
网络编程-UDP协议(发送数据和接收数据)
需要了解TCP协议的,可以看往期文章 https://blog.csdn.net/weixin_43860634/article/details/133274701 TCP/IP参考模型 通过此图,可以了解UDP所在哪一层级中 代码案例 发送数据 package com.hidata.devops.paas.udp;import java.io.IOException; …...

AI绘画普及课【一】绘画入门
文章目录 一、AI 绘画入门1、Stable Diffusion VS. MidJourney2、Stable Diffusion 介绍3、Stable Diffusion 环境搭建4、文生图与图生图 一、AI 绘画入门 1、Stable Diffusion VS. MidJourney Midjourney 优点: 操作简单、出图绚丽多彩 缺点: 订阅付费充钱 内容有限制&a…...

Selenium和Requests搭配使用
Selenium和Requests搭配使用 前要1. CDP2. 通过requests控制浏览器2. 1 代码一2. 2 代码2 3. 通过selenium获取cookie, requests携带cookie请求 前要 之前有提过, 用selenium控制本地浏览器, 提高拟人化,但是效率比较低,今天说一种selenium和requests搭配使用的方法 注意: 一定…...
【JDK 8-函数式编程】4.4 Supplier
一、Supplier 接口 二、实战 Stage 1: 创建 Student 类 Stage 2: 创建方法 Stage 3: 调用方法 Stage 4: 执行结果 一、Supplier 接口 供给型 接口: 无入参,有返回值(T : 出参类型) 调用方法: T get(); 用途: 如 无参的工厂方法&#x…...
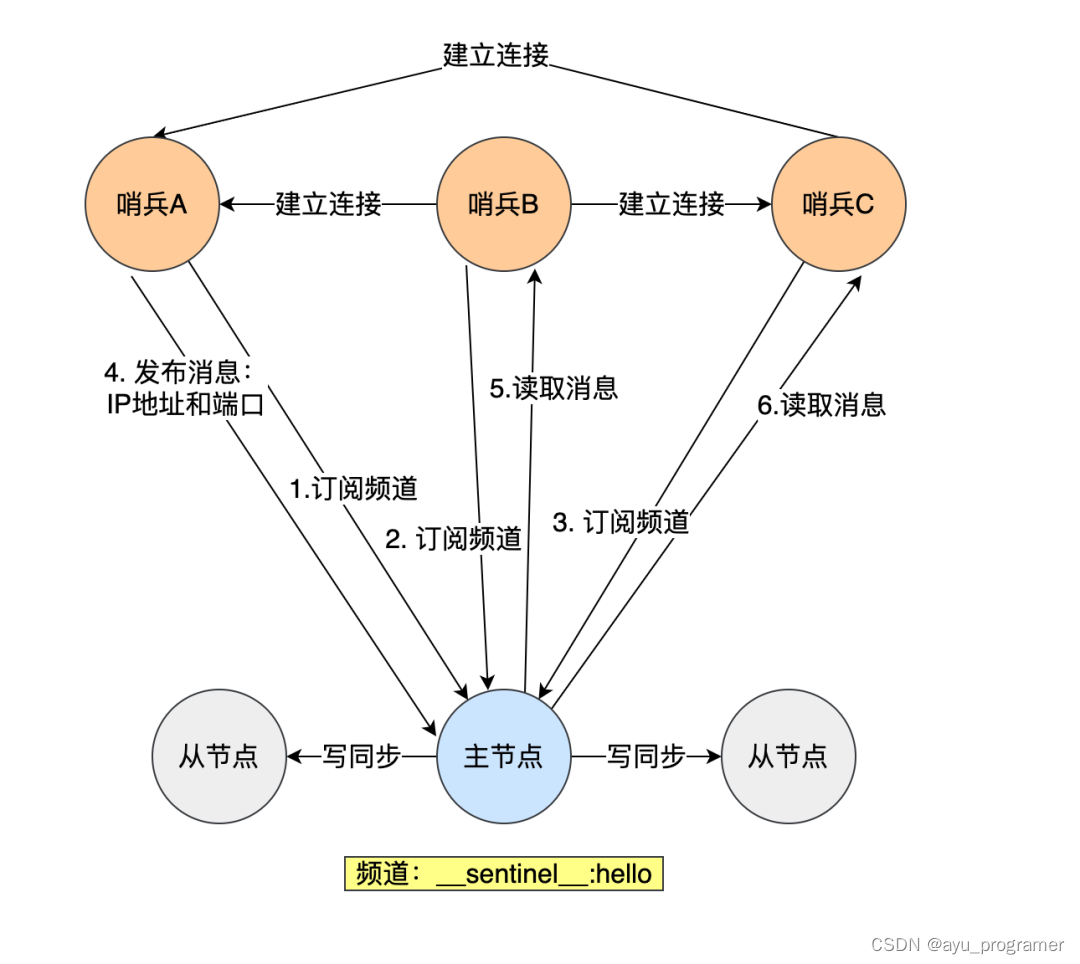
后端大厂面试-16道面试题
1 java集合类有哪些? List是有序的Collection,使用此接口能够精确的控制每个元素的插入位置,用户能根据索引访问List中元素。常用的实现List的类有LinkedList,ArrayList,Vector,Stack。 ArrayList是容量…...

产品经理认证(UCPM)备考心得
UCPM是联合国训练所CIFAL中心颁发的产品经理证书。如今,ESG是推动企业可持续发展的新潮流。UCPM作为一种可持续发展证书,为我们带来了一套先进科学、系统全面的产品管理模式,是产品管理领域公认的权威证书。那么,如何准备这张证书…...

E : A DS顺序表_删除有序表中的重复元素
Description 给定一个按升序排列的顺序表,请删除所有重复的元素,使得每个元素只出现一次,并输出处理后的顺序表。 Input 第一行输入t,表示有t个测试样例。 第二行起,每一行首先输入n,表示有n个元素&…...

前端教程-vite
官网 Vite中文网 视频教程 Vite世界指南(带你从0到1深入学习 vite)...
Java笔记三
包机制: 为了更好地组织类,Java提供了包机制,用于区别类名的命名空间。 包语句的语法格式为:pack pkg1[. pkg2[. pkg3...]]; 般利用公司域名倒置作为包名;如com.baidu.com,如图 导包: 为了能够…...

ElementUI之首页导航与左侧菜单
目录 一、Mock 1.1 什么是Mock.js 1.2 安装与配置 1.2.1 安装mock.js 1.2.2 引入mock.js 1.3 mock.js使用 1.3.1 定义测试数据文件 1.3.2 mock拦截Ajax请求 1.3.3 界面代码优化 二、总线 2.1 定义 2.2 类型分类 2.3 前期准备 2.4 配置组件与路由关系 2.4.1 配置…...

java项目之在线教育资源管理系统(ssm源码+文档)
项目简介 在线教育资源管理系统实现了以下功能: 管理员:个人中心、学生管理、教师管理、公告信息管理、课程信息管理、试题管理、留言板管理、管理员管理、试卷管理、系统管理、考试管理。学生:个人中心、留言板管理、考试管理,…...

C/S架构学习之UDP服务器
UDP服务器的实现流程:一、创建用户数据报套接字(socket函数):通信域选择IPV4网络协议、套接字类型选择数据报式; int sockfd socket(AF_INET,SOCK_DGRAM,0); 二、填充服务器的网络信息结构体:1.定义网络信…...
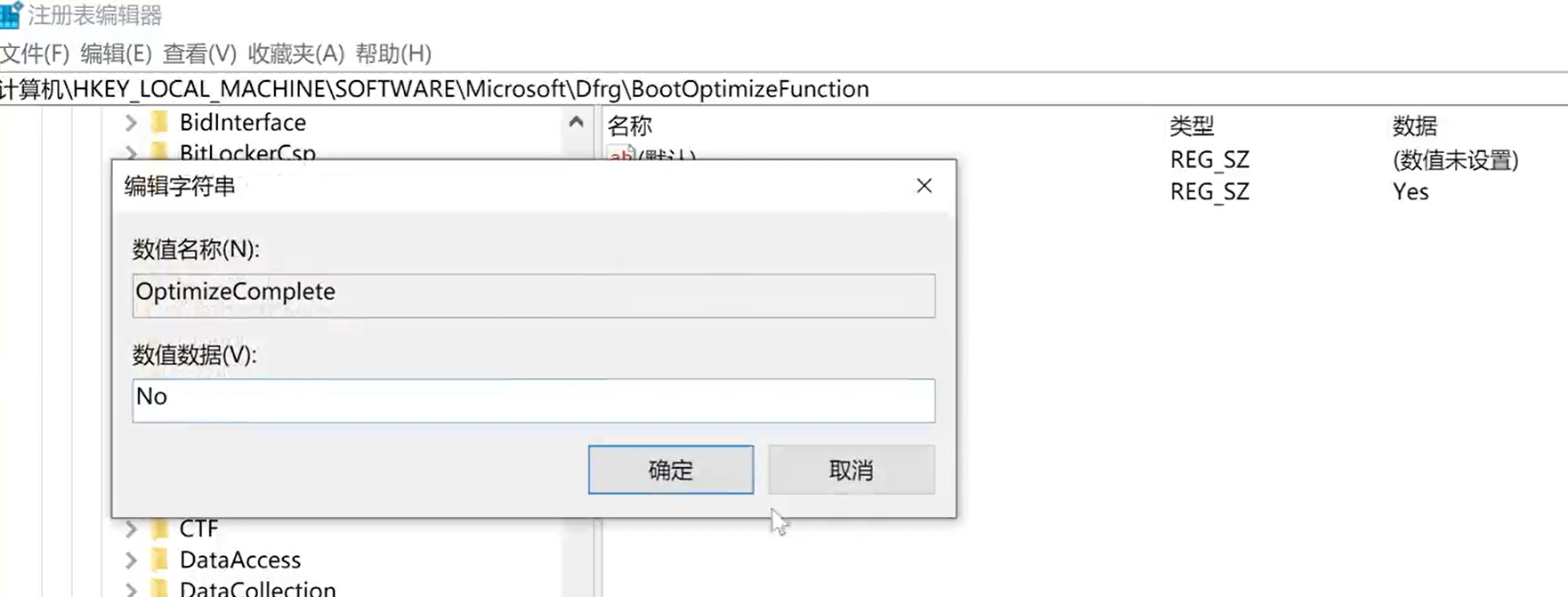
磁盘占用率100% 的优化方案
1.禁用不必要的系统服务 右键点击此电脑,打开管理 打开服务 寻找SysMain 右键属性 》 禁用 》 停止 》 应用 SysMain的作用:当开机后,windows会加载大量的应用程序预加载到内存中,会在后台预加载数据(如果是旧版本win…...

vue组件的通信
文章目录 组件通信父传子父传子:通过prop来进行通信 子传父先在父组件用注册方法 , 在子组件触发使用 emit 函数 组件间通信-平行组件使用事件总线的方法,也就是把整个vue提出来,当为一个事件总线 其他组件通信父组件 provide来提供变量,然后再子组件中通过inject来注入变量 组…...
(搞定)排序数据结构(1)插入排序 选择排序+冒泡排序
目录 本章内容如下 一:插入排序 1.1插入排序 1.2希尔排序 二:选择排序 2.1选择排序 三:交换排序 3.1冒泡排序 一:插入排序 1.1直接插入排序 说到排序,其实在我们生活中非常常见&…...

多智能体协同控制未来的前景和方向如何?
在AI技术快速演进的今天,单一智能体已难以满足企业复杂业务场景的需求,多智能体协同正成为行业关注的焦点,它通过多个智能体分工协作、动态交互,形成更强大、更灵活的数字员工团队,有望重塑企业运营模式,推…...

AI 视频创作系统:新媒体高效增收工具,AI 自动成片,持续输出优质内容
一、新媒体行业增收难,传统创作模式遇瓶颈如今做新媒体账号想要稳定盈利,离不开高频优质内容输出。但多数从业者普遍面临诸多难题:人工写脚本耗时费力,实拍剪辑流程繁琐,长期聘请专职人员开支巨大;内容产出…...

企业级应用如何通过Taotoken实现API调用的审计与安全管控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken实现API调用的审计与安全管控 将大模型能力集成到企业内部系统,为业务流程带来智能化的同时…...

Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件
Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专门为Adobe Creative Clou…...

使用Taotoken后API调用延迟与稳定性体感观察报告
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后API调用延迟与稳定性体感观察报告 1. 引言:从直接对接模型到使用聚合平台 在开发基于大语言模型的应用…...

基于LLM的代码仓库智能分析:RepoMap-AI实现架构可视化与认知图谱
1. 项目概述:当AI成为你的代码库“活地图”最近在折腾一个老旧的Java项目,里面模块套模块,依赖关系复杂得像一团乱麻。想找个特定的工具类,得在十几个包里翻来覆去地搜;想理清某个核心服务的调用链路,光靠I…...

原创丨全球主流开源模型及其衍生生态解析
作者:李媛媛 本文约4800字,建议阅读15分钟本文介绍了全球主流开源基座模型及衍生模型的特点、应用与趋势。在人工智能技术产业化落地加速的当下,开源模型已成为推动行业创新的核心力量,其开放、可定制的特性打破了技术壁垒&#x…...

开源笔记Memos与AI助手Copaw集成:打造自动化知识管理工作流
1. 项目概述:当开源笔记遇上AI助手最近在折腾个人知识管理工具,发现一个挺有意思的组合:Hailpeng的copaw-memos-integration。简单来说,它把两个独立但都很棒的工具给“焊”在了一起。一边是Memos,一个极简、开源、自部…...

TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程
TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS设备设计的智能越…...

B站缓存视频转换全攻略:3分钟学会m4s转MP4无损转换
B站缓存视频转换全攻略:3分钟学会m4s转MP4无损转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到过这样的情况&#x…...