干旱预测方法总结及基于人工神经网络的干旱预测案例分析(MATLAB全代码)
本案例采用SPEI干旱指数,构建ANN和BP神经网络预测模型,并开展1~3个月预见期的干旱预测,对比分析干旱预测模型的适用性,为流域干旱预警和管理提供技术依据。
干旱预测
1 干旱预测方法
1.1 统计学干旱预测
根据历史降水或气温等时间序列建立预测对象与预测因子间统计关系的干旱预测,称之为统计学干旱预测。此类方法的本质是基于历史气象、水文资料的内在统计关系,建立预测对象与预测因子之间的函数关系以对未来干旱进行预测。
常用的统计学干旱预测方法有:
- 回归分析
- 时间序列分析
- 灰色系统
- 马尔科夫链
- 神经网络
- 支持向量机等
1.2 动力学干旱预测
第二类是基于全球或区域气候模式,经过偏差校正和降尺度处理后得到未来气候变化趋势,然后结合干旱指数对未来干旱状况进行预测。其中,在预测农业干旱和水文干旱时需要驱动水文模型,常用的模型有可变下渗容量模型(Variable Infiltration Capacity, VIC)、 SWAT(Soil and Water Assessment Tool)模型以及新安江模型等。这类干旱预测方法称之为动力学干旱预测。
2 案例
2.1 基于人工神经网络的干旱预测
采用SPEI干旱指数,构建ANN和BP神经网络预测模型,并开展1~3个月预见期的干旱预测,对比分析干旱预测模型的适用性,为流域干旱预警和管理提供技术依据。技术路线如图1所示。
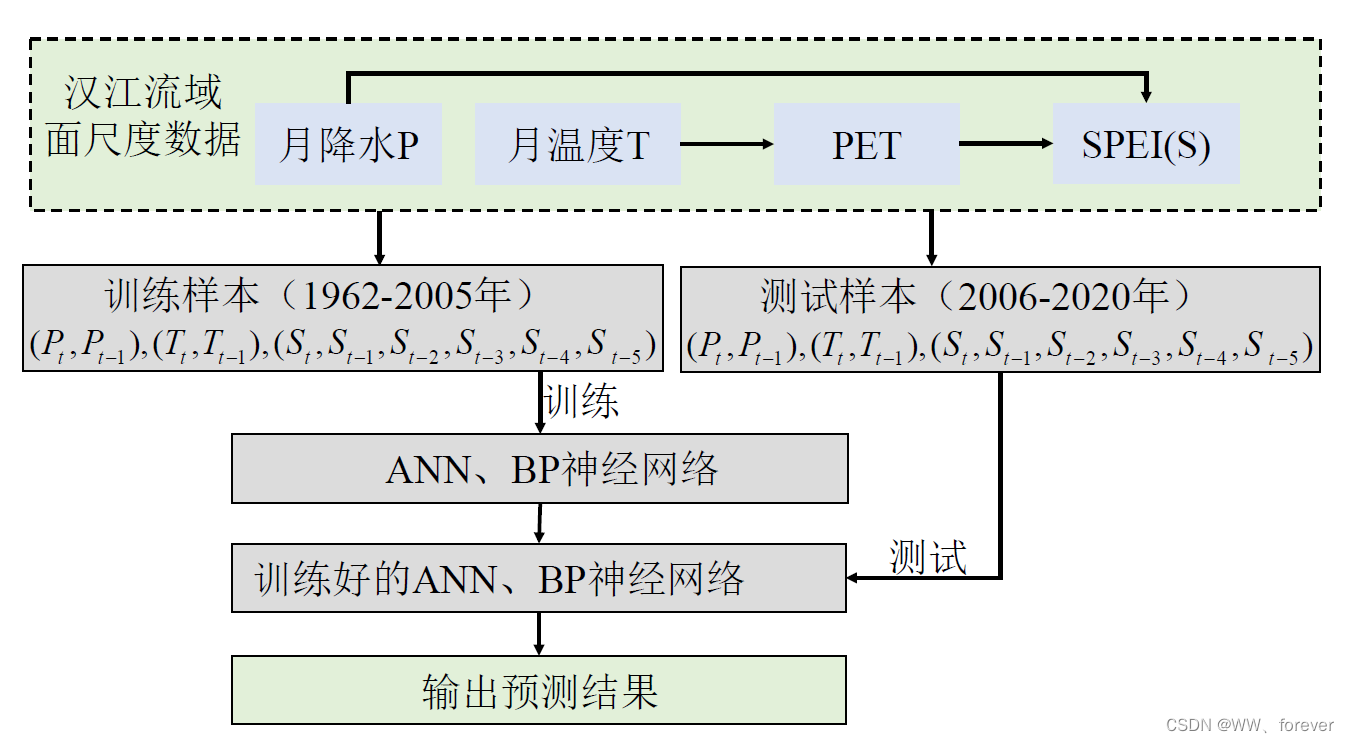
2.1.1 模型构建

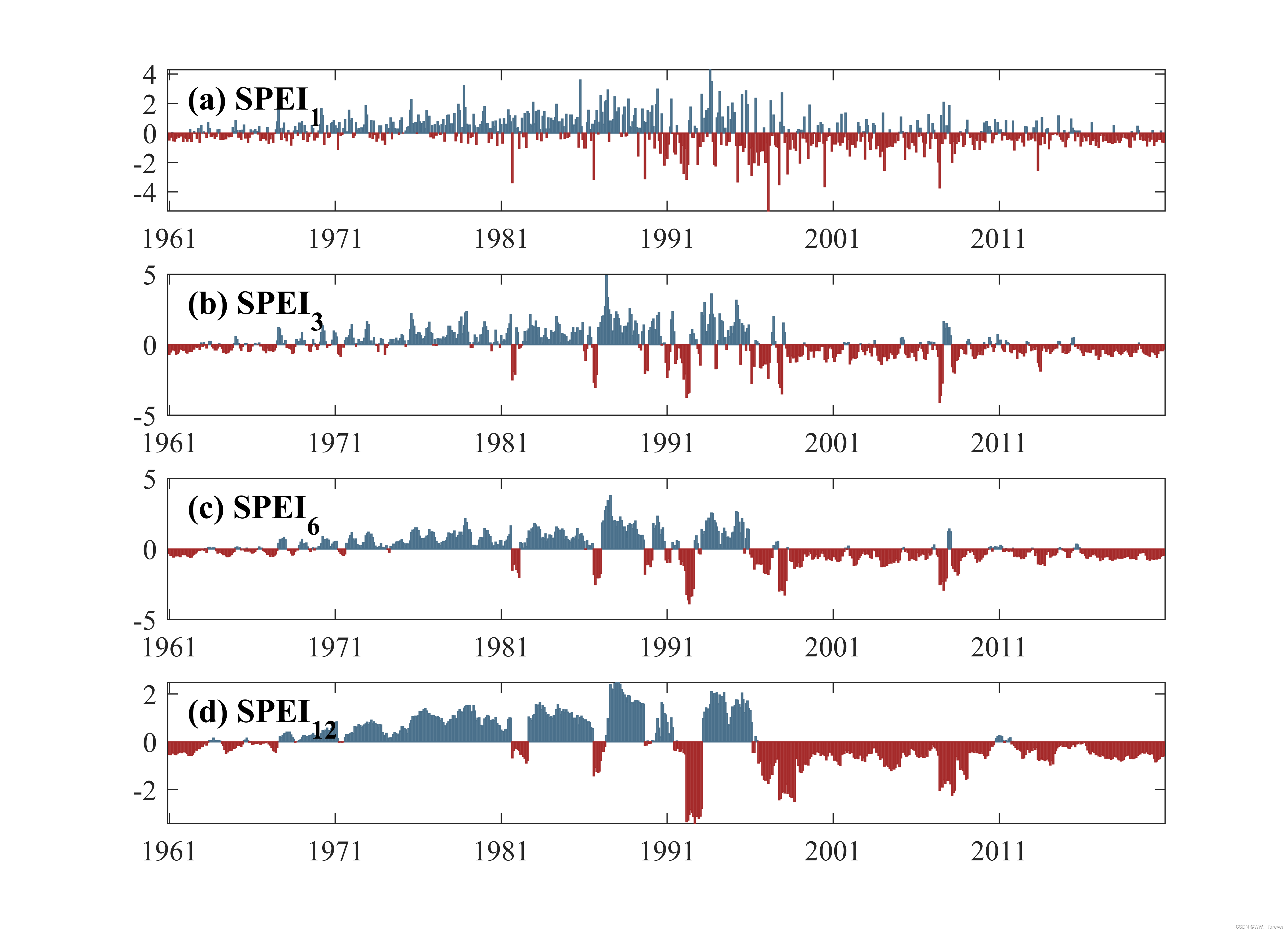
2.1.2 不同时间尺度的SPEI
2.1.3 模型预测结果
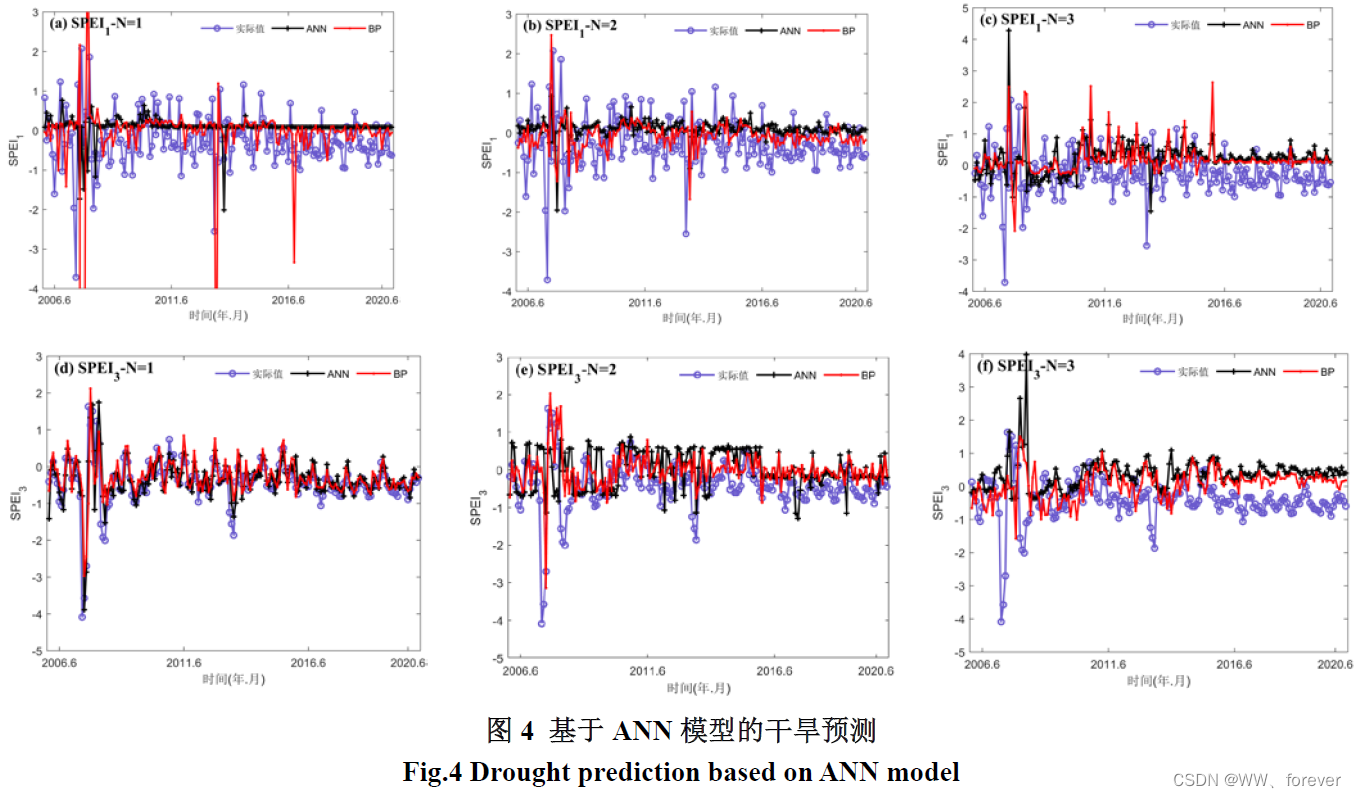
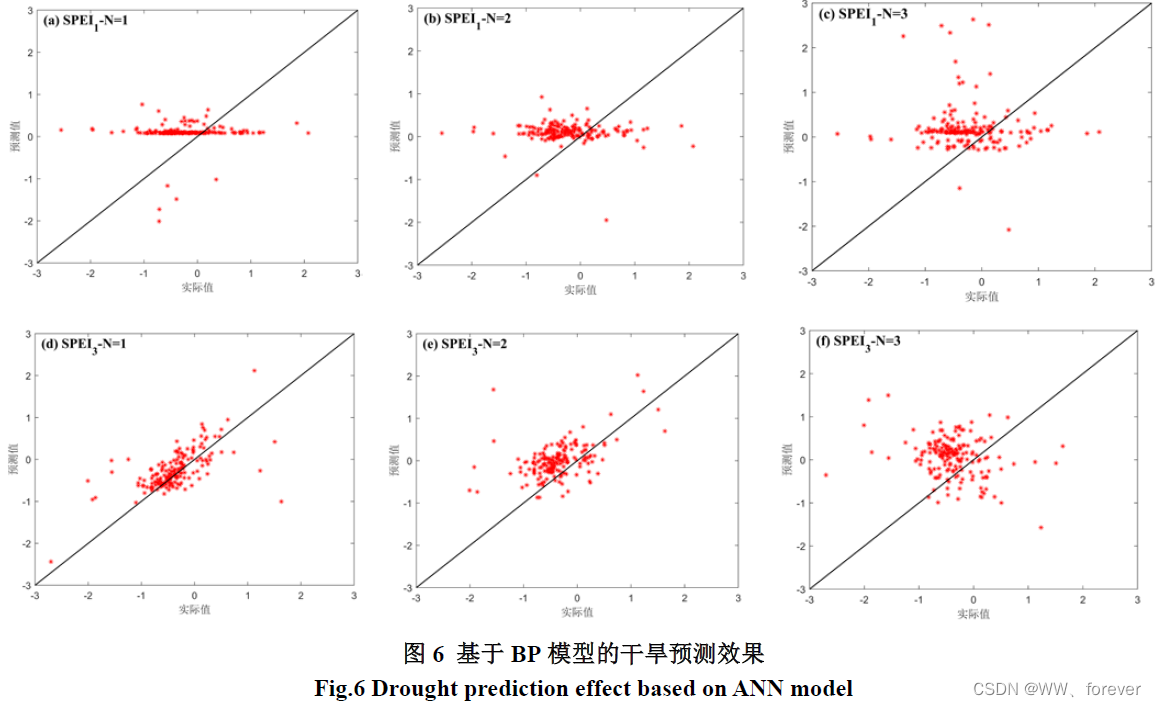
2.1.4 MATLAB相关代码
SPEI计算代码:
clc
close all
clear
%% 导入降水和气温数据
yearStart =1960;
yearEnd = 2020;
N_day = datenum(2020,12,31)-datenum(1960,1,1)+1;
ii = datenum('01-Jan-1960');
jj = datenum('31-Dec-2020');%% 计算潜在蒸散发PET
% 方法1:Thornthwaite法
PET = GetPE_Thornthwaite( DataMonthMean{3,1} , DataMonthMean{2,1});%% 计算1960-2020年各月SPEI指数
SPEI1= GetSPEI( P(:) , PET(:) , 1 );
SPEI3 = GetSPEI( P(:) , PET(:) , 3 );
SPEI6 = GetSPEI( P(:) , PET(:) , 6 );
SPEI12 = GetSPEI( P(:) , PET(:) , 12 );%% 绘制各尺度SPEI值
figure(2)
SPEI1Plot = SPEI1(end-720+1:end,1);
subplot(4,1,1)
hold on;box on;
n1=find(SPEI1Plot>=0); %找出大于或等于0的元素的序号
n2=find(SPEI1Plot<0); %找出小于0的元素的序号
h(1) = bar(n1,SPEI1Plot(n1),1,'FaceColor',[0.2902 0.4392 0.5451],'EdgeColor',[0.2902 0.4392 0.5451],'FaceAlpha',0.8); % [0.2902 0.4392 0.5451] 'b'
h(2) = bar(n2,SPEI1Plot(n2),1,'FaceColor',[0.6471 0.1647 0.1647],'EdgeColor',[0.6471 0.1647 0.1647],'FaceAlpha',0.8); % [0.6471 0.1647 0.1647] 'r'
set(gca, 'XTick', [1:10*12:60*12],'XTickLabel',{'1961','1971','1981','1991','2001','2011'})
text( 'string',"(a) SPEI_1", 'Units','normalized','position',[0.02,0.75], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman');
set(gca,'FontSize',12,'Fontname', 'Times New Roman');SPEI3Plot = SPEI3(end-720+1:end,1);
subplot(4,1,2)
hold on;box on;
n3=find(SPEI3Plot>=0); %找出大于或等于0的元素的序号
n4=find(SPEI3Plot<0); %找出小于0的元素的序号
h(3) = bar(n3,SPEI3Plot(n3),1,'FaceColor',[0.2902 0.4392 0.5451],'EdgeColor',[0.2902 0.4392 0.5451],'FaceAlpha',0.8); % [0.2902 0.4392 0.5451] 'b'
h(4) = bar(n4,SPEI3Plot(n4),1,'FaceColor',[0.6471 0.1647 0.1647],'EdgeColor',[0.6471 0.1647 0.1647],'FaceAlpha',0.8); % [0.6471 0.1647 0.1647] 'r'
set(gca, 'XTick', [1:10*12:60*12],'XTickLabel',{'1961','1971','1981','1991','2001','2011'})
text( 'string',"(b) SPEI_3", 'Units','normalized','position',[0.02,0.75], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman');
set(gca,'FontSize',12,'Fontname', 'Times New Roman');SPEI6Plot = SPEI6(end-720+1:end,1);
subplot(4,1,3)
hold on;box on;
n5=find(SPEI6Plot>=0); %找出大于或等于0的元素的序号
n6=find(SPEI6Plot<0); %找出小于0的元素的序号
h(5) = bar(n5,SPEI6Plot(n5),1,'FaceColor',[0.2902 0.4392 0.5451],'EdgeColor',[0.2902 0.4392 0.5451],'FaceAlpha',0.8); % [0.2902 0.4392 0.5451] 'b'
h(6) = bar(n6,SPEI6Plot(n6),1,'FaceColor',[0.6471 0.1647 0.1647],'EdgeColor',[0.6471 0.1647 0.1647],'FaceAlpha',0.8); % [0.6471 0.1647 0.1647] 'r'
set(gca, 'XTick', [1:10*12:60*12],'XTickLabel',{'1961','1971','1981','1991','2001','2011'})
text( 'string',"(c) SPEI_6", 'Units','normalized','position',[0.02,0.75], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman');
set(gca,'FontSize',12,'Fontname', 'Times New Roman');SPEI12Plot = SPEI12(end-720+1:end,1);
subplot(4,1,4)
hold on;box on;
n7=find(SPEI12Plot>=0); %找出大于或等于0的元素的序号
n8=find(SPEI12Plot<0); %找出小于0的元素的序号
h(7) = bar(n7,SPEI12Plot(n7),1,'FaceColor',[0.2902 0.4392 0.5451],'EdgeColor',[0.2902 0.4392 0.5451],'FaceAlpha',0.8); % [0.2902 0.4392 0.5451] 'b'
h(8) = bar(n8,SPEI12Plot(n8),1,'FaceColor',[0.6471 0.1647 0.1647],'EdgeColor',[0.6471 0.1647 0.1647],'FaceAlpha',0.8); % [0.6471 0.1647 0.1647] 'r'
set(gca, 'XTick', [1:10*12:60*12],'XTickLabel',{'1961','1971','1981','1991','2001','2011'})
text( 'string',"(d) SPEI_1_2", 'Units','normalized','position',[0.02,0.75], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman');
set(gca,'FontSize',12,'Fontname', 'Times New Roman');function ET = GetPE_Thornthwaite( T ,N)
% 形式二:《五种潜在蒸散发公式在汉江流域的应用》
%------------------------------------------------------
% T为月均温度
% u为每月天数
% I为热量指数
% N为月均日照时间
% k为经验系数
k = 16;
monthAmount_Common = [31 28 31 30 31 30 31 31 30 31 30 31 ]; % 平年
monthofYear = length(monthAmount_Common);T = max(0,T);
% 输入序列为矩阵形式
if size(T)==size(N)Nmonth = size(T,1)*size(T,2);Nyear = size(T,1);
elseerror("月均温度序列长度同月均日照时间序列长度不相等!");
end% 计算各年份热量指数I
I = zeros(Nyear,1);
a = zeros(Nyear,1);
ET = zeros(Nyear,monthofYear);
for iyear=1:NyearI(iyear) = sum(0.09*T(iyear,:).^1.5) ;a(iyear) = 0.016*I(iyear) +0.5;for imonth=1:monthofYearET(iyear,imonth) = k*(10*T(iyear,imonth)/I(iyear))^a(iyear)*monthAmount_Common(imonth)*N(iyear,imonth)/360;end
end%{
% 输入序列为向量形式
if length(T)==length(N)if rem(T,12)==0Nmonth = length(T);Nyear = T/12;elseerror("温度序列T并未整年数据!");end
elseerror("月均温度序列长度同月均日照时间序列长度不相等!");
end
%}end% 函数2:GetSPEI用于计算各尺度SPEI值
%-----------------------------------------------------------------------------------
% (1) Computes accumulated precipitation-ET data for the specific time scale
% (2) Computes drought indicators (SPEI)
function SPEI = GetSPEI( P , PET , scale )
% SPEI(不考虑闰年)常采用Log-logistic概率分布函数拟合降水与蒸散的差值系列
% P 降水 precipitation
% PET 潜在蒸散发 potential evapotranspiration (mm/day)
% 注:降水和蒸散发均为日尺度数据
% scale (事件尺度): 1,3,6,12,48 月尺度monthOfYear = 12;
if length(P)==length(PET)
elseprintf("降水和潜在蒸散发的数据长度不等!")
end% 1) Computes accumulated precipitation-ET data for the specific time scale 计算水分亏缺量D
Data = P -PET;A1=[]; % 初始化
for is=1:scaleA1=[A1,Data(is:length(Data)-scale+is)]; % 按时间尺度列出数据
end
XS=sum(A1,2); % 对A1的每行分别求和Nlength = length(XS);
SPEI = zeros(Nlength,2);for is=1:monthOfYeartind = is:monthOfYear:length(XS);Xn = XS(tind); % 对应序数Xnsort = sort(Xn);beta = GetBeta(Xnsort,length(Xnsort),0,0,0); par=logLogisticFit(beta);Gam_xs = logLogisticCDF(Xn,par);% 2) Computes drought indicators (SPEI) 计算SPEISPEI(tind,2) = norminv( real(Gam_xs) );% SPEI(tind,1) = real( norminv( real(Gam_xs)) );SPEI(tind,1) = real( Normalize( Gam_xs) );
endend
% ============================ SPEI 调用函数开始 ============================
% 函数1:利用矩法计算三参数Log-logistic的参数
% -------------------------------------------------------------------------------
function beta = GetBeta(series,n,A,B,isBeta)
acum=zeros(3,1);
if A==0&&B==0for i=1:nacum(1) = acum(1) + series(i);if isBeta==0 % compute alpha PWMsacum(2) = acum(2) + series(i) * (n-i) / (n-1);acum(3) = acum(3) + (series(i) * (n-i) * (n-i-1) / (n-1) / (n-2));elseif isBeta==1 % compute beta PWMsacum(2) = acum(2) + series(i) * (i-1) / (n-1);acum(3) = acum(3) + (series(i) * (i-1) * (i-2) / (n-1) / (n-2));endend
elseif A==-0.35&&B==0 %use plotting-position (biased) estimatorfor i=1:nF = (i+A) / (n+B);acum(1) = acum(1)+series(i);if isBeta==0 % compute alpha PWMsacum(2) = acum(2)+series(i)*(1-F);acum(3) = acum(3)+series(i)*(1-F)*(1-F);elseif isBeta==1 % compute beta PWMsacum(2) = acum(2)+series(i)*(F);acum(3) = acum(3)+series(i)*(F)*(F);endend
else for i=1:n%F = (i+A) / (n+B);acum(1) = acum(1)+series(i)*nchoosek(n-i,0)/nchoosek(n-1,0);acum(2) = acum(2)+series(i)*nchoosek(n-i,1)/nchoosek(n-1,1);acum(3) = acum(3)+series(i)*nchoosek(n-i,2)/nchoosek(n-1,2);end
end
beta(1) = acum(1) / n;
beta(2) = acum(2) / n;
beta(3) = acum(3) / n;
end% 函数2:利用矩法计算三参数Log-logistic的参数
% -------------------------------------------------------------------------------
function logLogisticParams=logLogisticFit(beta)% estimate gamma parameter 形状参数β
logLogisticParams(3) = (2*beta(2)-beta(1)) / (6*beta(2)-beta(1)-6*beta(3));g1 = exp(gammaLn(1+1/logLogisticParams(3)));
g2 = exp(gammaLn(1-1/logLogisticParams(3)));% estimate alpha parameter 尺度参数α
logLogisticParams(2) = (beta(1)-2*beta(2))*logLogisticParams(3) / (g1*g2);% estimate beta parameter 源参数γ
logLogisticParams(1) = beta(1) - logLogisticParams(2)*g1*g2;
end% 函数3:利用三参数Log-logistic的参数,计算累积概率分布CDF
% -------------------------------------------------------------------------------
function M=logLogisticCDF(value,params)
% logLogistic分布M=1./(1+(params(2)./(value-params(1))).^params(3));
end% 函数4:求gammaΓ分布
% -------------------------------------------------------------------------------
function z=gammaLn(xx)
cof=[76.18009172947146,-86.50532032941677,24.01409824083091,-1.231739572450155,0.1208650973866179e-2,-0.5395179384953e-5];
y = xx;
x = xx;
tmp = x + 5.5;
tmp = tmp-(x+0.5) * log(tmp);
ser = 1.000000000190015;
for j=1:6y=y+1;ser=ser+cof(j)/y;
end
z=-tmp+log(2.5066282746310005*ser/x);
end% 函数5:standardGaussianInvCDF通过变换,将累计概率密度CDF转化为标准正态分布
% -------------------------------------------------------------------------------
function resul = Normalize(prob)
% X 输入序列概率值
n = length(prob); % 序列长度% 常数
C= [2.515517,0.802853,0.010328];
d= [0,1.432788,0.189269,0.001308];resul =zeros(n,1);
for in=1:nif prob(in)<=0.5W = sqrt(-2*log(prob(in)));elseW =sqrt(-2*log(1-prob(in)));endWW = W*W;WWW = WW*W;resul(in) = W - (C(1) + C(2)*W + C(3)*WW) / (1 + d(2)*W + d(3)*WW + d(4)*WWW);if prob(in)<0.5resul(in) = -resul(in);end
endend
% ============================ SPEI 调用参数结束 ============================
BP神经网络分析代码:
clc
close all
clear
%% 导入数据
% 原始数据
load('dataTrainOutput.mat')
load('dataTrainInput.mat')
load('dataTestOutput.mat')
load('dataTestInput.mat')% 预见期 N
N = [1 2 3];
trainLength = length(dataTrainOutput{1,1});
testLength = length(dataTestOutput{1,1});%% 利用BP神经网络进行预测
% 第一组 SPEI1 N=1
input_train = dataTrainInput{1,1}(:,1:10)';
output_train = dataTrainOutput{1,1}(:,1)';
input_test = dataTestInput{1,1}(:,1:10)';
output_test = dataTestOutput{1,1}(:,1)';
% 训练数据归一化
[inputn,inputps] = mapminmax(input_train);
[outputn,outputps] = mapminmax(output_train);
% 构建BP神经网络
net=newff(inputn,outputn,5);
% 网络参数配置
net.trainParam.epochs=1000;
net.trainParam.lr=0.05;
net.trainParam.goal=0.00004;
net.divideFcn = '';
% 训练
net=train(net,inputn,outputn);
% 预测数据归一化:各个维度的数据在-1到1之间,均值为0
inputn_test=mapminmax('apply',input_test,inputps);
% BP神经网络预测输出
an=sim(net,inputn_test);
% 输出结果反归一化
BPoutput1=mapminmax('reverse',an,outputps);% 构建BP神经网络
net=newff(inputn,outputn,4);
% 网络参数配置
net.trainParam.epochs=500;
net.trainParam.lr=0.05;
net.trainParam.goal=0.00004;
net.divideFcn = '';
% 训练
net=train(net,inputn,outputn);
% 预测数据归一化:各个维度的数据在-1到1之间,均值为0
inputn_test=mapminmax('apply',input_test,inputps);
% BP神经网络预测输出
an=sim(net,inputn_test);
% 输出结果反归一化
BPoutput11=mapminmax('reverse',an,outputps);% 结果整理
figure(1)
hold on;box on;
h(1) = plot(output_test,'-o','linewidth',1.5,'markersize',5,'color',[106 90 205]/255);
h(2) = plot(BPoutput11,'k-+','linewidth',1.5,'markersize',5);
h(3) = plot(BPoutput1,'r-*','linewidth',1.5,'markersize',2);
hl = legend(h([1 2 3]),"实际值","ANN","BP");
set(hl,'Box','off','Location','northeast','NumColumns',3);
xlabel("时间(年.月)")
ylabel("SPEI_1")
set(gca,'ylim',[-4 3 ]);
set(gca, 'XTick', [ 6, 66, 126, 174],'XTickLabel',{'2006.6','2011.6','2016.6','2020.6'})
text( 'string',"(a) SPEI_1-N=1", 'Units','normalized','position',[0.02,0.95], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman');
%set(gca,'FontSize',12,'Fontname', 'Times New Roman');% 计算相应指标
R2(1,1) = GetR2(output_test,BPoutput11);
R2(1,2) = GetR2(output_test,BPoutput1);
RMSE(1,1) =GetRMSE(output_test,BPoutput11);
RMSE(1,2) =GetRMSE(output_test,BPoutput1);figure(2)
hold on;box on;
plot(output_test,BPoutput11,'r*','markersize',5);
plot([-3 3],[-3 3],'k-','linewidth',1)
axis([-3 3 -3 3]);
xlabel("实际值")
ylabel("预测值")
text( 'string',"(a) SPEI_1-N=1", 'Units','normalized','position',[0.02,0.95], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman'); figure(3)
hold on;box on;
plot(output_test,BPoutput1,'k+','markersize',5);
plot([-3 3],[-3 3],'k-','linewidth',1)
axis([-3 3 -3 3]);
xlabel("实际值")
ylabel("预测值")
text( 'string',"(a) SPEI_1-N=1", 'Units','normalized','position',[0.02,0.95], 'FontSize',14,'FontWeight','Bold','FontName','Times New Roman'); %% 调用函数
% 计算决定系数R2
function Result = GetR2(X,Y)if length(X)==length(Y)n = length(X);
elseerror("输入X和Y序列不等!")
end
S1 = ( n*sum( X.*Y)-sum(X)*sum(Y))^2;
S2 = (n-1)*sum(X.^2);
S3 = (n-1)*sum(Y.^2);
Result = S1/S2/S3;end% 计算均方根误差RSME
function Result = GetRMSE(X,Y)if length(X)==length(Y)n = length(X);
elseerror("输入X和Y序列不等!")
end
Result = sqrt( sum( (X-Y).^2 )/n);end
参考
1.博士论文-D2022-气候变化下长江流域未来径流与旱涝变化特征研究-岳艳琳
相关文章:
干旱预测方法总结及基于人工神经网络的干旱预测案例分析(MATLAB全代码)
本案例采用SPEI干旱指数,构建ANN和BP神经网络预测模型,并开展1~3个月预见期的干旱预测,对比分析干旱预测模型的适用性,为流域干旱预警和管理提供技术依据。 干旱预测 1 干旱预测方法 1.1 统计学干旱预测 根据历史降水或气温等…...
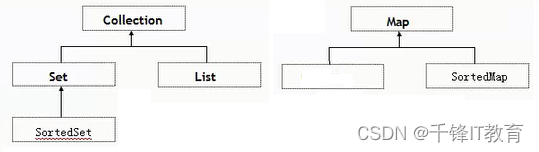
一篇文章弄清楚啥是数组和集合
数组和集合多语言都有,数组是集合的一种,是一种有序的集合,不面向对象,面向过程的也有。1.数组逻辑结构:线性的物理结构:顺序的存储结构申请内存:一次申请一大段连续的空间,一旦申请…...
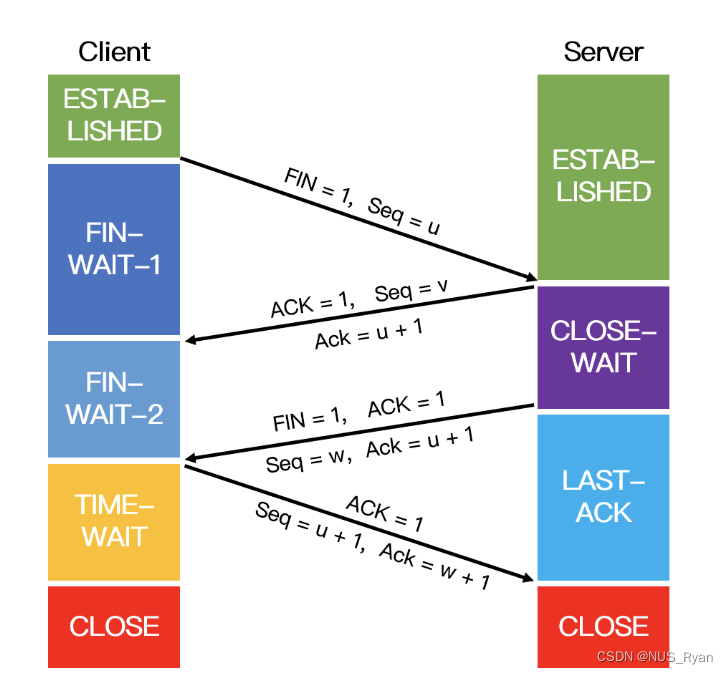
计算机网络(五):三次握手和四次挥手,TCP,UDP,TIME-WAIT,CLOSE-WAIT,拥塞避免,
文章目录零. TCP和UDP的区别以及TCP详解TCP是如何保证可靠性的TCP超时重传的原理TCP最大连接数限制TCP流量控制和拥塞控制流量控制拥塞控制TCP粘包问题一、三次握手和四次挥手二、为什么要进行三次握手?两次握手可以吗?三、为什么要进行四次挥手…...

【数据结构】二叉树(C语言实现)
文章目录一、树的概念及结构1.树的概念2.树的相关概念名词3.树的表示4.树在实际中的运用二、二叉树概念及结构1.二叉树的概念2.特殊的二叉树3.二叉树的性质4.二叉树的存储结构三、二叉树链式结构的实现1.结构的定义2.构建二叉树3.二叉树前序遍历4.二叉树中序遍历5.二叉树后序遍…...
高级信息系统项目管理(高项 软考)原创论文——成本管理(2)
1、如果您想了解如何高分通过高级信息系统项目管理师(高项)你可以点击链接: 高级信息系统项目管理师(高项)高分通过经验分享_高项经验 2、如果您想了解更多的高级信息系统项目管理(高项 软考)原创论文,您可以点击链接:...

代码签名即将迎来一波新关注
在数字化高度发展的当下,个人隐私及信息安全保护已经成了大家关注的重点,包括日常使用的电脑软件,手机APP等,由于包含了大量的用户信息,已经成了重点关注对象,任何一个疏忽就可能泄露大量用户信息。所以权威…...

黑盒渗透盲打lampiao
一、查找主机ip,通过Nmap扫描工具排查出我的靶机的IP 为.134 python tools.py ip -i 192.168.12.0 -h 254 -l 1 二、扫描其他端口。 1898 三、查看网站漏洞情况,典型的漏洞特征 Ac扫描漏洞情况,利用典型的漏洞。 四、开始getshell 1、启动M…...
)
笔记:VLAN及交换机处理详细教程(Tagged, UnTagged and Native VLANS Tutorial)
一、内容来源 本文是对下面这篇文章的总结,写的很全、很细致、干货满满,强力推荐: 《Tagged, UnTagged and Native VLANS Tutorial – A Quick Guide about What they Are?》 二、为什么引入VLAN? 早期设备间通过集线器&#x…...

在字节跳动,造赛博古籍
“你在字节跳动哪个业务?”“古籍数字化。把《论语》《左传》《道德经》这些古籍变成电子版,让大家都能免费看。”没错,除了你熟悉的那些 App,字节跳动还在做一些小众而特别的事情,古籍数字化就是其中之一。在字节跳动…...

Android 12.0设置默认Launcher安装一款Launcher默认Launcher无效的解决方案
1.概述 在12.0的系统rom定制化过程中,在系统中当有多个Launcher的时候,这时候会要求设置默认Launcher,但是在最近的产品开发过程中,发现在设置完默认Launcher以后,在安装个Launcher的时候,会让原来设置的默认Launcher变为空了,就是在系统Settings中的默认应用中,launche…...
)
数据结构第16周 :( 希尔排序+ 堆排序 + 快速排序 )
目录希尔排序堆排序快速排序希尔排序 【问题描述】给出一组数据,请用希尔排序将其按照从小到大的顺序排列好。 【输入形式】原始数据,以0作为输入的结束;第二行是增量的值,都只有3个。 【输出形式】每一趟增量排序后的结果 【…...

【C++】类和对象
1.面向过程和面向对象初步认识 我们知道,C语言是面向过程的,关注的就是问题解决的过程; C是面向过程和面向对象混编,因为C兼容了C语言,而面向对象关注的不再是问题解决的过程; 而是一件事情所关联的不同…...
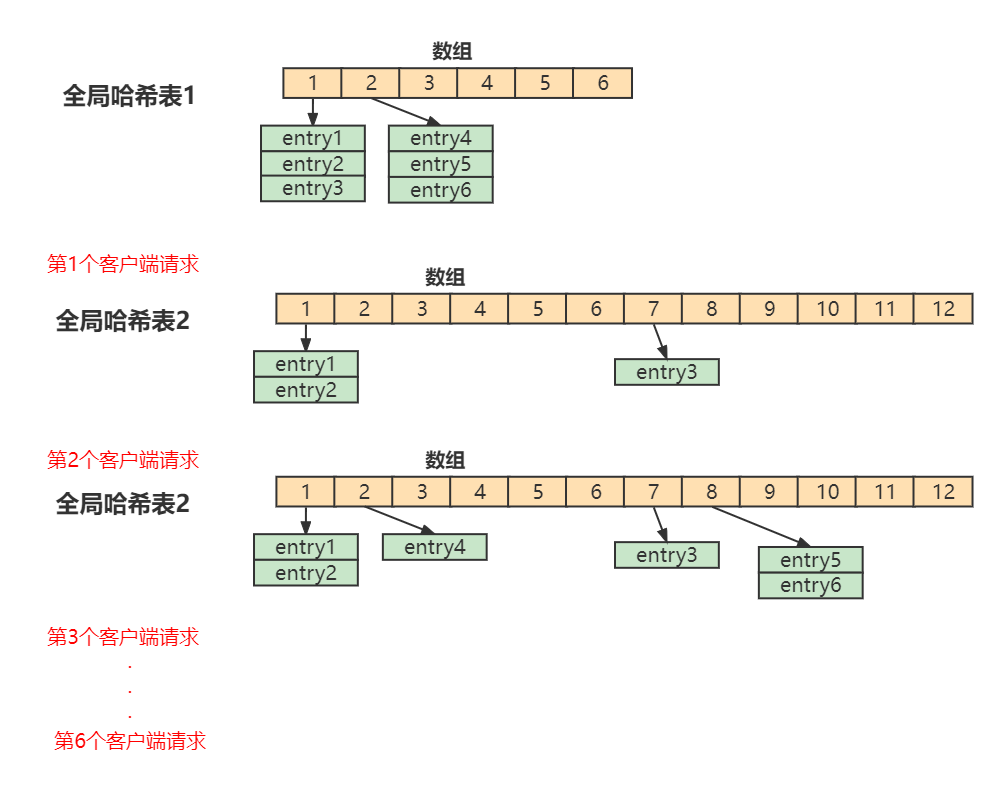
Java缓存面试题——Redis应用
文章目录1、为什么要使用Redis做缓存?2、为什么Redis单线程模型效率也能那么高?3、Redis6.0为什么要引入多线程呢?4、Redis常见数据结构以及使用场景字符串(String)哈希(Hash)列表(list)集合&am…...

KMP算法详细理解
一、目的1.KMP应用场景:可以解决字符串匹配问题; 在一个串中查找是否出现过另一个串。2.KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。3.KMP算法关键在于&…...

RabbitMQ单节点安装
在学习RabbitMQ之前,必须要把RabbitMQ的环境搭建起来,刚开始学习时,搭建单节点是入门RabbitMQ最方便、最快捷的方式,这篇文章就是介绍如何使用RabbitMQ压缩包的方式搭建一个单节点的RabbitMQ。 在实际项目中,服务器都…...

tomcat 服务的目录结构和tomcat的运行模式
目录 一、tomcat 服务的目录结构解析: 1、tomcat目录结构: bin目录: conf目录: lib目录: logs目录: temp目录: webapps目录: wokr目录: 二、tomcat服务的运行模…...
vector迭代器失效问题
一、迭代器: 迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所…...

2023年排名前茅的十大饭店装修设计!
相信大家都是知道的,饭店装修设计其实是一门很深的学问,只有掌握这门学问才能够打造出来精美的空间,因此饭店装修必须要有专业餐饮设计公司的设计师进行设计。但是在国内饭店装修设计公司那么多,饭店老板要如何选择呢?…...
MFCCA多通道多说话人语音识别模型上线魔搭(ModelScope)
实验室研发的基于多帧跨通道注意力机制(MFCCA)的多说话人语音识别模型近日上线魔搭(ModelScope)社区,该模型在AliMeeting会议数据集上获得当前最优性能。欢迎大家下载。开发者可以基于此模型进一步利用ModelScope的微调…...

刷题记录:牛客NC25078[USACO 2007 Ope S]City Horizon
传送门:牛客 题目描述: Farmer John has taken his cows on a trip to the city! As the sun sets, the cows gaze at the city horizon and observe the beautiful silhouettes formed by the rectangular buildings. The entire horizon is represented by a number line …...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...