paddle2.3-基于联邦学习实现FedAVg算法
目录
1. 联邦学习介绍
2. 实验流程
3. 数据加载
4. 模型构建
5. 数据采样函数
6. 模型训练

1. 联邦学习介绍
联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备)。联邦学习的模式是在各分支节点分别利用本地数据训练模型,再将训练好的模型汇合到中心节点,获得一个更好的全局模型。
联邦学习的提出是为了充分利用用户的数据特征训练效果更佳的模型,同时,为了保证隐私,联邦学习在训练过程中,server和clients之间通信的是模型的参数(或梯度、参数更新量),本地的数据不会上传到服务器。
本项目主要是升级1.8版本的联邦学习fedavg算法至2.3版本,内容取材于基于PaddlePaddle实现联邦学习算法FedAvg - 飞桨AI Studio星河社区
2. 实验流程
联邦学习的基本流程是:
1. server初始化模型参数,所有的clients将这个初始模型下载到本地;
2. clients利用本地产生的数据进行SGD训练;
3. 选取K个clients将训练得到的模型参数上传到server;
4. server对得到的模型参数整合,所有的clients下载新的模型。
5. 重复执行2-5,直至收敛或达到预期要求
import os
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
import time
import paddle
import paddle.nn as nn
import numpy as np
from paddle.io import Dataset,DataLoader
import paddle.nn.functional as F
3. 数据加载
mnist_data_train=np.load('data/data2489/train_mnist.npy')
mnist_data_test=np.load('data/data2489/test_mnist.npy')
print('There are {} images for training'.format(len(mnist_data_train)))
print('There are {} images for testing'.format(len(mnist_data_test)))
# 数据和标签分离(便于后续处理)
Label=[int(i[0]) for i in mnist_data_train]
Data=[i[1:] for i in mnist_data_train]
There are 60000 images for training
There are 10000 images for testing
4. 模型构建
class CNN(nn.Layer):def __init__(self):super(CNN,self).__init__()self.conv1=nn.Conv2D(1,32,5)self.relu = nn.ReLU()self.pool1=nn.MaxPool2D(kernel_size=2,stride=2)self.conv2=nn.Conv2D(32,64,5)self.pool2=nn.MaxPool2D(kernel_size=2,stride=2)self.fc1=nn.Linear(1024,512)self.fc2=nn.Linear(512,10)# self.softmax = nn.Softmax()def forward(self,inputs):x = self.conv1(inputs)x = self.relu(x)x = self.pool1(x)x = self.conv2(x)x = self.relu(x)x = self.pool2(x)x=paddle.reshape(x,[-1,1024])x = self.relu(self.fc1(x))y = self.fc2(x)return y
5. 数据采样函数
# 均匀采样,分配到各个client的数据集都是IID且数量相等的
def IID(dataset, clients):num_items_per_client = int(len(dataset)/clients)client_dict = {}image_idxs = [i for i in range(len(dataset))]for i in range(clients):client_dict[i] = set(np.random.choice(image_idxs, num_items_per_client, replace=False)) # 为每个client随机选取数据image_idxs = list(set(image_idxs) - client_dict[i]) # 将已经选取过的数据去除client_dict[i] = list(client_dict[i])return client_dict
# 非均匀采样,同时各个client上的数据分布和数量都不同
def NonIID(dataset, clients, total_shards, shards_size, num_shards_per_client):shard_idxs = [i for i in range(total_shards)]client_dict = {i: np.array([], dtype='int64') for i in range(clients)}idxs = np.arange(len(dataset))data_labels = Labellabel_idxs = np.vstack((idxs, data_labels)) # 将标签和数据ID堆叠label_idxs = label_idxs[:, label_idxs[1,:].argsort()]idxs = label_idxs[0,:]for i in range(clients):rand_set = set(np.random.choice(shard_idxs, num_shards_per_client, replace=False)) shard_idxs = list(set(shard_idxs) - rand_set)for rand in rand_set:client_dict[i] = np.concatenate((client_dict[i], idxs[rand*shards_size:(rand+1)*shards_size]), axis=0) # 拼接return client_dict
class MNISTDataset(Dataset):def __init__(self, data,label):self.data = dataself.label = labeldef __getitem__(self, idx):image=np.array(self.data[idx]).astype('float32')image=np.reshape(image,[1,28,28])label=np.array(self.label[idx]).astype('int64')return image, labeldef __len__(self):return len(self.label)6. 模型训练
class ClientUpdate(object):def __init__(self, data, label, batch_size, learning_rate, epochs):dataset = MNISTDataset(data,label)self.train_loader = DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)self.learning_rate = learning_rateself.epochs = epochsdef train(self, model):optimizer=paddle.optimizer.SGD(learning_rate=self.learning_rate,parameters=model.parameters())criterion = nn.CrossEntropyLoss(reduction='mean')model.train()e_loss = []for epoch in range(1,self.epochs+1):train_loss = []for image,label in self.train_loader:# image=paddle.to_tensor(image)# label=paddle.to_tensor(label.reshape([label.shape[0],1]))output=model(image)loss= criterion(output,label)# print(loss)loss.backward()optimizer.step()optimizer.clear_grad()train_loss.append(loss.numpy()[0])t_loss=sum(train_loss)/len(train_loss)e_loss.append(t_loss)total_loss=sum(e_loss)/len(e_loss)return model.state_dict(), total_loss
train_x = np.array(Data)
train_y = np.array(Label)
BATCH_SIZE = 32
# 通信轮数
rounds = 100
# client比例
C = 0.1
# clients数量
K = 100
# 每次通信在本地训练的epoch
E = 5
# batch size
batch_size = 10
# 学习率
lr=0.001
# 数据切分
iid_dict = IID(mnist_data_train, 100)
def training(model, rounds, batch_size, lr, ds,L, data_dict, C, K, E, plt_title, plt_color):global_weights = model.state_dict()train_loss = []start = time.time()# clients与server之间通信for curr_round in range(1, rounds+1):w, local_loss = [], []m = max(int(C*K), 1) # 随机选取参与更新的clientsS_t = np.random.choice(range(K), m, replace=False)for k in S_t:# print(data_dict[k])sub_data = ds[data_dict[k]]sub_y = L[data_dict[k]]local_update = ClientUpdate(sub_data,sub_y, batch_size=batch_size, learning_rate=lr, epochs=E)weights, loss = local_update.train(model)w.append(weights)local_loss.append(loss)# 更新global weightsweights_avg = w[0]for k in weights_avg.keys():for i in range(1, len(w)):# weights_avg[k] += (num[i]/sum(num))*w[i][k]weights_avg[k]=weights_avg[k]+w[i][k] weights_avg[k]=weights_avg[k]/len(w)global_weights[k].set_value(weights_avg[k])# global_weights = weights_avg# print(global_weights)#模型加载最新的参数model.load_dict(global_weights)loss_avg = sum(local_loss) / len(local_loss)if curr_round % 10 == 0:print('Round: {}... \tAverage Loss: {}'.format(curr_round, np.round(loss_avg, 5)))train_loss.append(loss_avg)end = time.time()fig, ax = plt.subplots()x_axis = np.arange(1, rounds+1)y_axis = np.array(train_loss)ax.plot(x_axis, y_axis, 'tab:'+plt_color)ax.set(xlabel='Number of Rounds', ylabel='Train Loss',title=plt_title)ax.grid()fig.savefig(plt_title+'.jpg', format='jpg')print("Training Done!")print("Total time taken to Train: {}".format(end-start))return model.state_dict()#导入模型
mnist_cnn = CNN()
mnist_cnn_iid_trained = training(mnist_cnn, rounds, batch_size, lr, train_x,train_y, iid_dict, C, K, E, "MNIST CNN on IID Dataset", "orange")
W0605 23:22:00.961916 10307 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0605 23:22:00.966121 10307 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.Round: 10... Average Loss: 0.033
Round: 20... Average Loss: 0.011
Round: 30... Average Loss: 0.012
Round: 40... Average Loss: 0.008
Round: 50... Average Loss: 0.003
Round: 60... Average Loss: 0.002
Round: 70... Average Loss: 0.001
Round: 80... Average Loss: 0.001
Round: 90... Average Loss: 0.001
相关文章:
paddle2.3-基于联邦学习实现FedAVg算法
目录 1. 联邦学习介绍 2. 实验流程 3. 数据加载 4. 模型构建 5. 数据采样函数 6. 模型训练 1. 联邦学习介绍 联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备&#…...
伺服丝杠系统常用运算功能块
这篇博客主要介绍伺服、丝杠系统常用的运算功能块,其它相关运算可以查看下面文章链接: 信捷PLC脉冲频率、位移、转速相关计算(C语言编程应用)_RXXW_Dor的博客-CSDN博客里工业控制张力控制无处不在,也衍生出很多张力控制专用控制器,磁粉制动器等,本篇博客主要讨论PLC的张力…...
【Vue】模板语法,事件处理器及综合案例、自定义组件、组件通信
一、事件处理器 我们之前事件监听可以使用v-on 指令 1、事件修饰符 在Vue中我们通过由点(.)表示的指令后缀来调用修饰符,比如: .stop:阻止事件冒泡。当事件触发时,该修饰符将停止事件进一步冒泡到父元素。相当于调用了 event.stop…...
从0开始写中国象棋-创建棋盘与棋子
从控制台版本开始 考虑到象棋程序,其实就是数据结构与算法实现。 所以和界面相关的QT部分我们先放一放。 我们从控制台版本开始。这样大家更容易接受,也不影响开发。 后面我们会把控制台嫁接到QT上完成完整的游戏,那时候自然就水到渠成了…...

软件的开发步骤,需求分析,开发环境搭建,接口文档 ---苍穹外卖1
目录 项目总览 开发准备 开发步骤 角色分工 软件环境 项目介绍 产品原型 技术选型 开发环境搭建 前端:默认已有 后端 使用Git版本控制 数据库环境搭建 前后端联调 登录功能完善 导入接口文档 使用swagger 和yapi的区别 常用注解 项目总览 开发准备 开发步骤…...
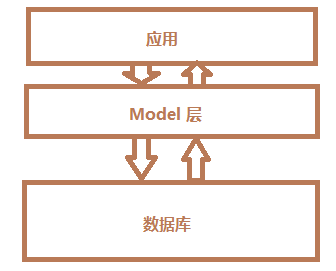
Qt扫盲-QSqlQueryModel理论总结
QSqlQueryModel理论总结 一、概述二、使用1. 与 view 视图 绑定2. 分离视图,只存数据 一、概述 QSqlQueryModel是用于执行SQL语句和遍历结果集的高级接口。它构建在较低级的 QSqlQuery之上,可用于向QTableView 等视图类提供数据,也是使用了Q…...

分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现WOA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MATLA…...

【单调栈】496. 下一个更大元素 I
496. 下一个更大元素 I 解题思路 首先计算nums2的每一个元素的下一个比他大的元素,使用单调栈将上面的结果和nums2中的每一个元素组成映射map针对每一个Nums1的元素 查询map 记录map 的value class Solution {public int[] nextGreaterElement(int[] nums1, int[…...
搭建Vue的开发环境,Edge浏览器安装VUE拓展工具
一、在下载vue.js文件 在vue官网中下载开发版本的vue.js文件--> 安装 — Vue.js (vuejs.org) 二、将vue.js导入到项目中 这时候我们运行项目控制台会抛出两个错误 三、安装拓展工具 这里以Edge浏览器为例,其他浏览器上可在拓展管理商店中下载 进入Edge的拓展…...

14:00面试,14:06就出来了,这问的谁顶得住啊
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到8月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%,…...
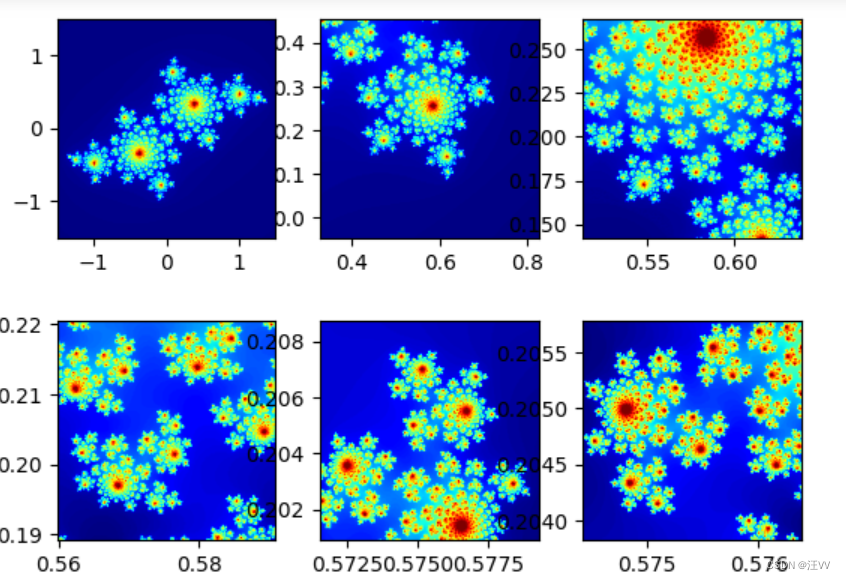
python 探索分形世界|曼德布洛特|np.frompyfunc()
文章目录 分形的重要特征曼德布洛特集合曼德布洛特集合有一个以证明的结论:图像展示np.ogrid[]np.frompyfunc()集合转图像 julia集合 无边的奇迹源自简单规则的无限重复 ---- 分形之父Benoit B.Mandelbrot 分形的重要特征 自相似性无标度性非线性 曼德布洛特集合…...

Android MVVM示例项目
项目地址 GitHub - yaolunwei/Androidbbc at androidx 项目简介 BBC(基础业务组件) 业务组件的基础,所有业务组件必须基于该组件进行开发,提供一站式开发 快速使用 gradle: implementation com.bigoat.android:bbc:0.0.1 约定成俗 以下继承关系…...
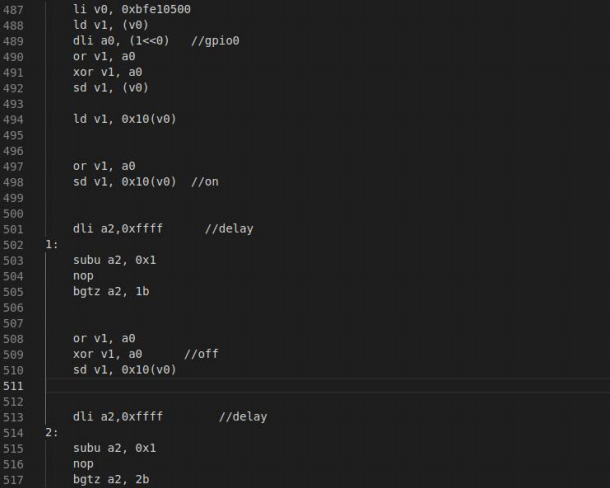
迅为龙芯2K1000开发板通过汇编控制GPIO
上一小节,我们使用了 C 语言控制了 gpio,这一小节我们来看一下如何使用汇编来控制 gpio 呢?有的 同学可能会有疑问了,既然我们可以使用 C 语言来控制 gpio,为什么我们还要使用更底层的汇编语言呢, 如果我…...

合合信息、上海大学、华南理工大学发布业内首个古彝文编码“大字典” ,为古文字打造“身份证”
“乌蒙山连着山外山,月光洒向了响水滩。”近期在各大短视频平台爆火的《奢香夫人》你听过吗?奢香夫人是一位彝族“巾帼英雄”,这首同名歌曲早在2009年便已发布,如今突然“翻红”,不仅体现了大众对于少数民族文化高涨的…...

Django — 类视图和中间件
目录 一、类视图1、基于类的结构2、常见的类视图基类3、类视图的优点4、代码案例 二、中间件1、定义2、工作原理3、自带中间件4、中间件开发流程5、自定义中间件6、案例 一、类视图 类视图(Class-Based Views)是 Django 中用于处理 HTTP 请求和生成 HTT…...

VMware安装CentOS Stream 8以及JDK和Docker
一、下载镜像源 地址:https://developer.aliyun.com/mirror/?spma2c6h.25603864.0.0.285b32d48O2G8Y 二、安装配置 配置项 一共有以下这些,其中软件、软件选择 、安装目的地、网络主机名需要讲一下,其他都简单,自行设置即可。 …...
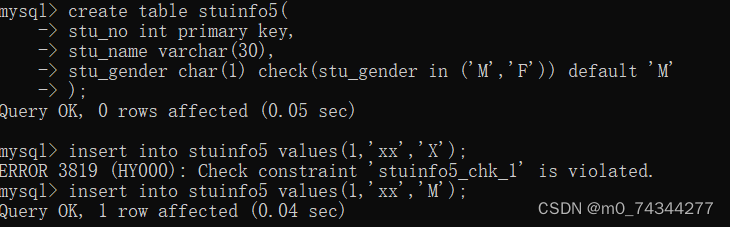
MySQL作业1
目录 一.创建一张表,包含以下所有数据类型 建表:编辑 二.使用以下六种约束 1.非空约束 2.唯一约束 3.主键约束 4.外键约束 5.检查约束 6.默认值约束 一.创建一张表,包含以下所有数据类型 Text 类型: Number 类型&#…...

基于微信小程序的家校通系统设计与实现(亮点:选题新颖、上传作业、批改作业、成绩统计)
文章目录 前言运行环境说明家长微信小程序端的主要功能有:教师微信小程序端的主要功能有:管理员的主要功能有:具体实现截图详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考论文…...
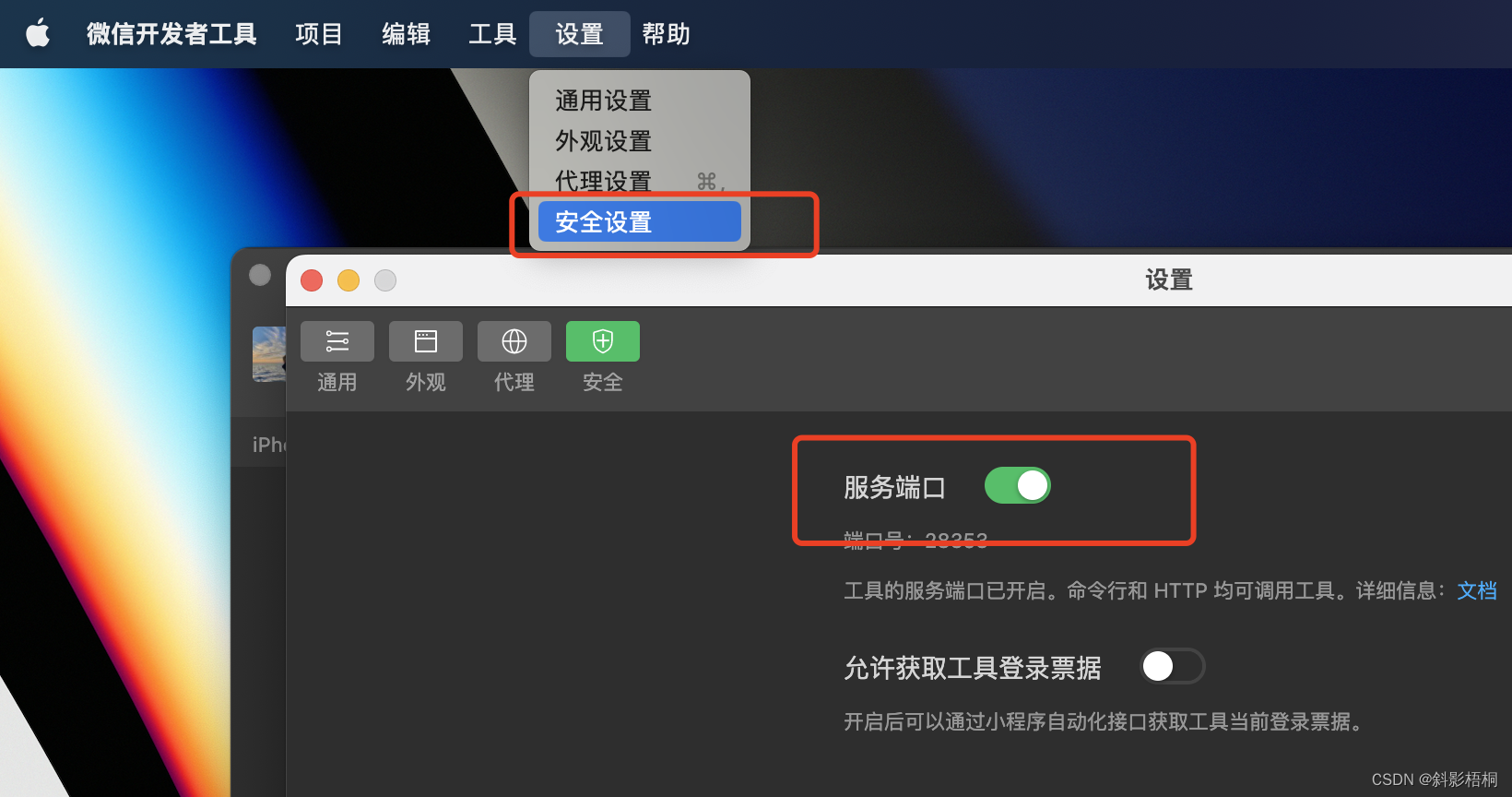
uni-app问题记录
一、启动问题记录 1. 报错1 解决办法: 开启微信开发者工具服务端口 2. 报错2:调用getLocation获取位置信息时报错以下内容 {errMsg: “getLocation:fail the api need to be declared in the requiredPrivateInfos field in app.json/ext.json”} 解决办法: manifest.json文…...

Leetcode---363周赛
题目列表 2859. 计算 K 置位下标对应元素的和 2860. 让所有学生保持开心的分组方法数 2861. 最大合金数 2862. 完全子集的最大元素和 一、计算k置为下标对应元素的和 简单题,直接暴力模拟,代码如下 class Solution { public:int sumIndicesWithKS…...

Python try...except ImportError 语句详解
在Python编程中,ImportError 是与模块导入相关的核心异常。优雅地处理它,是编写健壮、可维护和跨平台代码的关键。try...except ImportError 结构正是实现这一目标的标准工具。本文将为你抽丝剥茧,从基础概念到高级实践,全面解析这…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...

终极免费换肤方案:R3nzSkin国服版完整使用教程
终极免费换肤方案:R3nzSkin国服版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤&#x…...

Nextra:基于Next.js的现代化文档站构建利器
1. 项目概述:为什么Nextra能成为文档站构建的“瑞士军刀”?如果你最近在寻找一个构建技术文档、博客或个人知识库的工具,大概率会听到“Nextra”这个名字。它不是一个独立框架,而是一个基于Next.js的静态站点生成器,专…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...