ChatGPT 在机器学习中的应用

一、介绍
大家都知道ChatGPT。它在解释机器学习和深度学习概念方面也非常高效,至少到 2021 年是这样。在这篇文章中,我想展示它的人工智能知识。我们来测试一下吧🔥
请记住,以下信息只是LLM生成的信息,可能完全不正确。
二、热门榜单
在本节中,我将测试各个领域中机器学习最常见、最有价值、最高效实体的 ChatGPT 知识。
2.1 前 5 名机器学习科学家

提供对人工智能发展影响最大的 5 位最有价值的机器学习科学家及其相关研究的列表。将信息格式化为表格 Markdown 格式,包含以下列:[“姓名”、“对 AI 的贡献”、“大学”、“AI 领域最有价值的出版物”]。
| 姓名 | 对人工智能的贡献 | 大学 | 人工智能领域最有价值的出版物 |
|---|---|---|---|
| 杰弗里·辛顿 | 深度学习先驱,创建反向传播算法 | 多伦多大学 | 《深度学习》教科书《使用深度卷积神经网络进行ImageNet分类》 |
| 严乐存 | 卷积神经网络的发明者 | 纽约大学 | “图像、语音和时间序列的卷积网络” |
| 约书亚·本吉奥 | 深度学习先驱,开发了早期神经语言模型 | 蒙特利尔大学 | 《深度学习》教材《神经概率语言模型》 |
| 吴恩达 | 谷歌大脑创始人,开发热门在线课程“机器学习” | 斯坦福大学 | 《深度学习》教科书《使用深度卷积神经网络进行ImageNet分类》 |
| 李飞飞 | 斯坦福人工智能实验室主任,开发ImageNet数据集 | 斯坦福大学 | “ImageNet:大规模分层图像数据库” |
2.2 计算机视觉损失函数的前 5 种

提供深度学习中计算机视觉中最常用的 5 个损失函数及其规范的列表。将表格中的信息格式化为Markdown格式,以下列:“Name”为损失函数的名称;“输入”带有值,即函数的输入及其解释;“输出”包含值(函数的输入)及其解释。使用 LaTeX 作为“输入”和“输出”列。
| Name | Input | Output |
|---|---|---|
| Mean Squared Error (MSE) |
方误差 | |
| Binary Cross-Entropy Loss |
给定真实标签的预测标签的负对数似然 | |
| Categorical Cross-Entropy Loss | ||
| Kullback-Leibler (KL) Divergence | p - 真实分布,q - 预测分布 | |
| Hinge Loss |
Top 5 Machine Learning Optimization Algorithms
2.3 前 5 名机器学习优化算法

提供训练数据科学模型的 8 种最有效技术的列表,例如梯度下降、进化算法等。此外,还提供其规范。将Markdown格式表中的信息格式化,以下列:“Name”为算法名称;“算法”用两句话描述算法,“优点”用算法的优点;算法的“缺点”。
| 姓名 | 算法 | 优点 | 缺点 |
|---|---|---|---|
| 梯度下降 | 沿损失函数负梯度方向更新模型参数的迭代优化算法 | 高效且应用广泛,可处理大型数据集 | 对学习率敏感,可能陷入局部最优 |
| 进化算法(EA) | 受自然选择启发的基于群体的优化算法,通常应用于离散参数空间 | 可以找到全局最优值,可以处理噪声和不可微函数,对于特征选择很有用 | 计算成本昂贵,需要大量人口规模和较长的训练时间,对超参数可能敏感 |
| 粒子群优化 (PSO) | 基于群体的优化算法,受到鸟群和鱼群集体行为的启发,通常应用于连续参数空间 | 可以找到全局最优值并处理不可微函数,计算效率高,可以处理约束和多目标优化 | 高维空间探索有限,可能陷入局部最优,对超参数敏感 |
| 贝叶斯优化 (BO) | 基于序列模型的优化算法,使用概率代理模型来选择下一个要评估的点 | 高效使用评估,可以处理噪声和不可微函数,可以处理约束和多目标优化 | 计算成本高,需要良好的代理模型,对超参数敏感 |
| 强化学习(RL) | 学习范例,其中代理与环境交互并学习采取最大化奖励信号的行动 | 可以学习复杂任务的最佳策略并处理部分可观察性和延迟奖励 | 样本可能效率低下并且需要大量训练集,可能会出现不稳定和不收敛的情况 |
2.4 深度学习最难的算法

深度学习最难的算法是什么?提供一个解释,它是如何工作的。提供技术细节。提供原始出版物的参考。
深度学习中最难的算法是神经图灵机(NTM),它将神经网络与可读写的存储库结合起来,使其能够学习算法并执行需要大量内存的任务。NTM 是由 Graves 等人提出的。在论文“神经图灵机”(2014)[1]中。NTM 的架构由一个控制器神经网络组成,该网络使用读写头与外部存储器矩阵进行交互。控制器网络将查询向量作为输入并生成读取和写入密钥,这些密钥用于对存储器矩阵进行寻址。然后,读取头和写入头根据键读取和写入内存矩阵,读取头输出读取向量,该读取向量与查询向量连接以产生最终输出。
NTM 使用随时间反向传播 (BPTT) 进行训练,可用于执行复制和排序序列等任务、学习执行二进制加法和乘法等算法,甚至玩简单的游戏。NTM 有潜力彻底改变人工智能领域,让机器能够学习算法并执行使用标准神经网络很难或不可能执行的任务。
[1] Graves, A.、Wayne, G. 和 Danihelka, I. (2014)。神经图灵机。arXiv 预印本 arXiv:1410.5401。
三、算法解释
让我们要求提供一些算法的解释。
3.1 亚当

解释 Adam 梯度下降优化算法的工作原理。使用乳胶。将解释分成 3 个句子。使用数学公式。
Adam 是一种自适应学习率优化算法,可计算不同参数的个体自适应学习率。它计算梯度的第二原始矩的运行估计,并使用估计的一阶矩和二阶矩的组合来更新参数。该算法结合了Adagrad和RMSprop的优点,可以用以下方程表示:
在这里和
是梯度的一阶矩和二阶矩,
和
是经过偏差校正的时刻估计,
是当前的参数集,
是时刻t的梯度 ,α 是学习率,β1 和β2 是第一和第二矩估计的指数衰减率,并且ε 是为了数值稳定性而添加到分母上的一个小值。
3.2 变压器

解释出版物“Attention Is All You Need”中的 Transformer 算法如何工作。使用乳胶。使用数学公式。绘制 ASCII 图解释注意矩阵的键、查询和管道中的值乘法。
Transformer 是一种基于注意力的神经网络架构,用于各种自然语言处理 (NLP) 任务。Vaswani 等人在论文《Attention Is All You Need》中介绍了这一点。(2017)。Transformer模型由编码器和解码器组成,两者均由自注意力层和前馈层组成。
自注意力用于通过对序列中所有标记的嵌入进行加权求和来计算输入序列中每个标记的输出,其中权重是通过根据序列中的所有标记的相关性来计算的到当前令牌。查询之间的注意力权重 和一把钥匙
使用其嵌入的点积计算,按嵌入维数的平方根缩放,然后通过 softmax 函数:
注意( Q ,K, V )分别是查询矩阵、键矩阵和值矩阵时;是keys的维度;然后将得到的注意力矩阵乘以值矩阵V以获得最终的输出。
在 Transformer 中,自注意力机制以多头方式使用,其中输入嵌入被投影到多个子空间,并且注意力在每个子空间中独立应用,从而使模型能够关注输入的不同方面。每个注意力头的输出被连接并投影回原始维度。
这是注意力机制的 ASCII 图:
<span style="color:#111111"><span style="background-color:#fdfdfd"><span style="background-color:#eeeeff"><span style="background-color:#eeeeff"><code> Q K V| | |v v v
+-----+-----+ +-----+-----+ +-----+-----+
| q1 | ... | | k1 | ... | | v1 | ... |
+-----+-----+ +-----+-----+ +-----+-----+| | |+-----------+-----------+|attention|v
+-------------------------------+
| output token |
+-------------------------------+`
</code></span></span></span></span>3.4 GPT-3

解释 GPT-3 算法的工作原理。提供深度学习技术细节。使用乳胶。使用数学公式。将解释放入 5 个句子中。突出显示最重要的信息。提供 APA 风格的原始出版物。
GPT-3(Generative Pre-trained Transformer 3)是OpenAI开发的语言生成模型,利用深度学习技术生成类人自然语言。该模型在大量不同文本数据集上进行训练,以学习语言模式,并针对特定的自然语言处理任务进行微调。
GPT-3的架构基于具有1750亿个参数的Transformer模型,这使得它能够生成低错误率的高质量文本。该模型使用无监督学习来生成连贯且上下文相关的语言。
GPT-3 的独特功能之一是它能够执行广泛的自然语言处理任务,例如语言翻译、摘要和问答,而不需要特定于任务的训练数据。
该模型结合使用了注意力机制和概率语言模型,前者使其能够专注于输入文本的相关部分,后者根据学习到的语言模式分布生成输出文本。
根据布朗等人的说法。(2020) 中,GPT-3 在多个自然语言处理基准上的性能在许多情况下超过了最先进的水平,证明了其架构和训练方法的有效性。
参考:
Brown, TB、Mann, B.、Ryder, N.、Subbiah, M.、Kaplan, J.、Dhariwal, P....和 Amodei, D. (2020)。语言模型是小样本学习者。arXiv 预印本 arXiv:2005.14165。
四、比较架构
ChatGPT 应该比较不同的深度学习架构,并解释它们相对于模型的先前版本的差异或演变。
4.1 YOLO v1 到 v5 比较

创建 Markdown 表,其中包含“Architecture”、“Changes”列,其中将 YOLO v1、v2、v3、v4 和 v5 与之前的版本进行相应比较。
| 建筑学 | 变化 |
|---|---|
| YOLO v1 | - 采用单尺度检测方法的基本架构 - 基于 Darknet 的主干网 - 不使用锚框 - 仅限于检测 20 个类别 |
| YOLO v2 | - 引入锚框来处理多个尺度 - 添加批量归一化以提高收敛性 - 将卷积层替换为残差块 - 增加卷积层的数量 - 检测图现在在多个锚框之间共享 - 实现更高的精度,可以检测 80 个类别 |
| YOLO v3 | - 进一步增加了卷积层的数量并添加了跳跃连接 - 使用特征金字塔合并多个尺度 - 引入了三个检测头来捕获不同的尺度和纵横比 - 训练和网络正则化方面的改进 - 实现了最先进的对象精度检测任务 |
| YOLO v4 | - 利用 CSPDarknet53 和 SPP 块等多项高级功能 - 引入了 Mish 激活功能 - 使用空间注意力和上下文聚合模块 - 引入了跨阶段部分网络 (CSPNet) - 比 YOLOv3 更准确、更快 |
| YOLO v5 | - 引入了使用 FCOS 进行无锚物体检测 - 比以前的版本更小、更快 - 使用 BiFPN 融合多个尺度的特征 - 实施了新的损失函数和后处理方法 - 实现了与 YOLOv4 相当的精度,同时速度显着加快 |
4.2 梯度下降路线图

提供梯度下降优化算法的开发路线图,如SGD、Adam、AdamW等。制作一个Markdown表格,其中“Name”列为算法名称;随刊《Publication》,以APA风格呈现了该算法;以及该算法所做的改进的“贡献”。按发布时间升序对行进行排序。
| 姓名 | 出版物 | 贡献 |
|---|---|---|
| 梯度下降 | 阿拉巴马州柯西 (1847)。“同时求解系统的通用方法”。巴黎科学院会议 25:536–538。 | 经典优化算法,根据损失函数相对于参数的梯度来更新模型参数。 |
| 随机梯度下降 (SGD) | 罗宾斯,H.,&蒙罗,S.(1951)。“随机逼近法”。《数理统计年鉴》22 (3):400–407。 | 通过计算单个示例的梯度来优化模型,使其比标准梯度下降算法更快。 |
| 阿达格勒 | Duchi, J.、Hazan, E. 和 Singer, Y. (2011)。“在线学习和随机优化的自适应次梯度方法”。机器学习研究杂志,12:2121-2159。 | 使学习率适应参数,使频繁的参数获得较小的学习率,而不频繁的参数获得较高的学习率。 |
| 阿达德尔塔 | 蔡勒,医学博士(2012)。“ADADELTA:一种自适应学习率方法”。arXiv 预印本 arXiv:1212.5701。 | 计算自适应学习率,其中考虑了平方梯度的移动平均值。 |
| 均方根螺旋桨 | 蒂勒曼,T. 和辛顿,G. (2012)。“讲座 6.5-rmsprop:将梯度除以其最近幅度的运行平均值”。课程:机器学习神经网络 4:2-4。 | 根据梯度平方的移动平均值调整学习率,通过先前梯度的均方根对梯度进行归一化。 |
| 亚当 | Kingma, DP 和 Ba, J. (2015)。“Adam:一种随机优化方法”。arXiv 预印本 arXiv:1412.6980。 | 计算每个参数的自适应学习率,同时考虑梯度的一阶矩和二阶矩,从而实现更快的收敛和更好的泛化性能。 |
| 那达慕 | 多扎特,T.(2016)。“将涅斯特洛夫动力融入亚当”。ICLR 研讨会。 | 为 Adam 添加 Nesterov 动量,从而在鞍点的情况下实现更快的收敛。 |
| 亚当·W | Loshchilov, I. 和 Hutter, F. (2017)。“修复 Adam 中的权重衰减正则化”。arXiv 预印本 arXiv:1711.05101。 | 修复了 Adam 中的权重衰减问题,从而获得更好的泛化性能。 |
| 拉达姆 | 刘L.、江华、何鹏、陈文、刘X.、高J.、韩J. (2019)。“关于自适应学习率的方差及其他”。arXiv 预印本 arXiv:1908.03265。 | 纠正 Adam 中自适应学习率的方差,从而获得更好的泛化性能。 |
4.3 计算机视觉路线图

从 LeNet 开始,制定计算机视觉架构的开发路线图。制作一个 Markdown 表,其中包含以下列:“名称”,以及架构的名称;随刊《Publication》,以APA风格呈现了该算法;以及该架构所做的改进的“贡献”。按发布时间升序对行进行排序。
| 姓名 | 出版物 | 贡献 |
|---|---|---|
| 乐网 | LeCun, Y.、Bottou, L.、Bengio, Y. 和 Haffner, P. (1998)。基于梯度的学习应用于文档识别。IEEE 会议录,86(11), 2278-2324。 | 第一个成功用于手写数字识别的卷积神经网络 (CNN) 之一。 |
| 亚历克斯网 | Krizhevsky, A.、Sutskever, I. 和 Hinton, GE (2012)。使用深度卷积神经网络进行 Imagenet 分类。神经信息处理系统的进展(第 1097-1105 页)。 | 第一个赢得 ImageNet 大规模视觉识别竞赛 (ILSVRC) 的 CNN。引入具有更深更广网络、ReLU 激活函数和 dropout 正则化的新架构。 |
| VGG网络 | 西蒙扬,K.,&齐瑟曼,A.(2014)。用于大规模图像识别的非常深的卷积网络。arXiv 预印本 arXiv:1409.1556。 | 更深层次的架构,最多 19 层,全部带有小型卷积滤波器。该架构为 ImageNet 树立了新的基准。 |
| 盗梦空间 v1 | Szegedy, C.、Liu, W.、Jia, Y.、Sermanet, P.、Reed, S.、Anguelov, D., … & Rabinovich, A. (2015)。更深入地了解卷积。IEEE 计算机视觉和模式识别会议论文集(第 1-9 页)。 | 引入 inception 模块,该模块由具有不同滤波器大小和池化操作的多个并行卷积层组成。该模块提高了准确性,同时保持了较低的参数数量。 |
| 残差网络 | 何凯、张旭、任胜、孙洁 (2016)。用于图像识别的深度残差学习。IEEE 计算机视觉和模式识别会议论文集(第 770-778 页)。 | 引入残差连接,通过解决梯度消失问题来允许更深的架构。该架构在 ImageNet 上树立了新的最先进水平。 |
| 盗梦空间 v3 | Szegedy, C.、Vanhoucke, V.、Ioffe, S.、Shlens, J. 和 Wojna, Z. (2016)。重新思考计算机视觉的初始架构。IEEE 计算机视觉和模式识别会议论文集(第 2818-2826 页)。 | 进一步开发 inception 模块,引入因式分解 7x7 卷积,并添加批量归一化。该架构在 ImageNet 上树立了新的最先进水平。 |
| Xception | 乔莱,F.(2017)。Xception:具有深度可分离卷积的深度学习。IEEE 计算机视觉和模式识别会议论文集(第 1251-1258 页)。 | 引入深度可分离卷积,将空间卷积和通道卷积分开,减少参数数量,同时提高准确性。该架构在 ImageNet 上树立了新的最先进水平。 |
| 高效网络 | Tan, M. 和 Le, QV (2019)。Efficientnet:重新思考卷积神经网络的模型扩展。国际机器学习会议(第 6105-6114 页)。 | 提出一种复合缩放方法,统一缩放网络的深度、宽度和分辨率。该架构在 ImageNet 上树立了新的最先进水平,同时比以前的架构具有更高的计算效率。 |
4.4 自然语言处理路线图

制定 NLP 架构的开发路线图。制作一个 Markdown 表,其中包含以下列:“名称”,以及架构的名称;随刊《Publication》,以APA风格呈现了该算法;以及该架构所做的改进的“贡献”。按发布时间升序对行进行排序。
| 姓名 | 出版物 | 贡献 |
|---|---|---|
| 隐马尔可夫模型 (HMM) | 拉宾纳,LR (1989) | 引入了用于预测未知变量序列的统计模型。 |
| 循环神经网络 (RNN) | 埃尔曼,JL (1990) | 引入了能够通过使用反馈连接处理顺序数据的神经网络架构。 |
| 长短期记忆 (LSTM) | Hochreiter, S. 和 Schmidhuber, J. (1997) | 通过引入记忆单元和门控机制改进了 RNN,从而可以更好地处理长期依赖性。 |
| 卷积神经网络 (CNN) | LeCun, Y.、Bottou, L.、Bengio, Y. 和 Haffner, P. (1998) | 引入了一种能够从输入数据的局部区域提取特征的架构,从而实现平移不变性。 |
| CBOW | Mikolov, T.、Chen, K.、Corrado, G. 和 Dean, J. (2013)。向量空间中单词表示的有效估计。 | 提出了一种简单的神经网络架构,用于计算单词的连续分布式表示,该架构计算效率高,适合大规模 NLP 任务。 |
| 跳语法 | Mikolov, T.、Chen, K.、Corrado, G. 和 Dean, J. (2013)。向量空间中单词表示的有效估计。 | 提出了一种简单的神经网络架构,用于计算单词的连续分布式表示,该架构计算效率高,适合大规模 NLP 任务。 |
| 格鲁乌 | Cho, K.、van Merrienboer, B.、Gulcehre, C.、Bahdanau, D.、Bougares, F.、Schwenk, H. 和 Bengio, Y. (2014)。使用 RNN 编码器-解码器学习短语表示以进行统计机器翻译。 | 提出了门控循环单元(GRU),它是 LSTM 架构的一种变体,参数更少,更容易训练,同时仍然能够对长期依赖关系进行建模。 |
| 变压器 | Vaswani, A.、Shazeer, N.、Parmar, N.、Uszkoreit, J.、Jones, L.、Gomez, AN, … & Polosukhin, I. (2017) | 引入了仅基于自注意力的模型,该模型在许多 NLP 任务中取得了 state-of-the-art 的结果。 |
| 伯特 | Devlin, J.、Chang, MW、Lee, K. 和 Toutanova, K. (2018) | 推出了基于 Transformer 架构的模型,该模型在大型语料库上进行预训练,然后对下游 NLP 任务进行微调,在其中许多任务中取得了最先进的结果。 |
| GPT-2 | Radford, A.、Wu, J.、Child, R.、Luan, D.、Amodei, D. 和 Sutskever, I. (2019) | 推出了基于 Transformer 的模型,该模型在海量语料库上进行了预训练,该模型在文本及其他方面展示了令人印象深刻的生成能力。 |
| T5 | Raffel, C.、Shazeer, N.、Roberts, A.、Lee, K.、Narang, S.、Matena, M.... & Liu, PJ (2019) | 推出了一种能够通过单一训练目标执行各种 NLP 任务的模型,并在多个基准测试中取得了最先进的结果。 |
| GPT-3 | Brown, TB、Mann, B.、Ryder, N.、Subbiah, M.、Kaplan, J.、Dhariwal, P....和 Amodei, D. (2020)。语言模型是小样本学习者。 | 提出了 GPT-3 模型,它是 GPT-2 的大规模版本,拥有 1750 亿个参数,并展示了令人印象深刻的少样本学习能力,这意味着它 |
4.5 时间序列路线图

制定时间序列模型开发路线图。制作一个 Markdown 表,其中包含以下列:“名称”,以及模型的名称;《出版物》以出版物的形式,以APA的风格呈现了这个模型;和“贡献”以及该模型所做的改进。按发布时间升序对行进行排序。
| 姓名 | 出版物 | 贡献 |
|---|---|---|
| ARMA | Box,GEP,詹金斯,总经理(1970 年)。时间序列分析:预测和控制。旧金山:霍顿日。 | 引入了ARMA模型,该模型结合了AR(自回归)和MA(移动平均)模型,广泛用于预测平稳时间序列数据。 |
| 阿里玛 | Box,GEP,詹金斯,总经理 (1976)。时间序列分析:预测和控制。旧金山:霍顿日。 | 通过引入积分组件扩展了ARMA模型,使模型能够处理非平稳时间序列数据。 |
| 伽马奇 | 博勒斯列夫,T. (1986)。广义自回归条件异方差。计量经济学杂志,31, 307–327。 | 引入了 GARCH 模型,该模型可以通过将自回归和移动平均分量与时变方差相结合来对金融时间序列数据中常见的波动性聚类进行建模。 |
| 长短期记忆网络 | Hochreiter, S. 和 Schmidhuber, J. (1997)。长短期记忆。神经计算,9(8),1735–1780。 | 引入了 LSTM 架构,它是一种循环神经网络,可以通过合并可以随时间存储和检索信息的记忆单元来学习时间序列数据中的长期依赖性。 |
| 格鲁乌 | Cho, K.、Van Merrienboer, B.、Bahdanau, D. 和 Bengio, Y. (2014)。关于神经机器翻译的特性:编码器-解码器方法。arXiv 预印本 arXiv:1409.1259。 | 引入了 GRU 架构,这是另一种类型的循环神经网络,可以学习时间序列数据中的长期依赖性,但参数比 LSTM 少。 |
| 波网 | van den Oord, A.、Dieleman, S.、Zen, H.、Simonyan, K.、Vinyals, O.、Graves, A. 等人。(2016)。WaveNet:原始音频的生成模型。arXiv 预印本 arXiv:1609.03499。 | 引入了 WaveNet 架构,它是一种自回归模型,可以通过使用一堆扩张的因果卷积层预测波形中的下一个样本来生成高质量的音频。 |
| TCN | Bai, S.、Kolter, JZ 和 Koltun, V. (2018)。用于序列建模的通用卷积和循环网络的实证评估。arXiv 预印本 arXiv:1803.01271。 | 引入了 TCN 架构,它是一种卷积神经网络,可以通过扩张因果卷积学习时间序列数据中的长期依赖性,在多个序列建模任务中实现最先进的性能。 |
| 变压器 | Vaswani, A.、Shazeer, N.、Parmar, N.、Uszkoreit, J.、Jones, L.、Gomez, AN 等人。(2017)。您所需要的就是关注。arXiv 预印本 arXiv:1706.03762。 | 推出了 Transformer 架构,这是一种基于自注意力的模型,可以通过计算所有时间步之间的注意力权重来捕获时间序列数据中的全局依赖关系,在多个 NLP 任务和时间序列预测中实现最先进的性能。 |
五、个人发展
在本节中,我将向 ChatGPT 询问一些关于如何发展成为机器学习领域专家的建议。
5.1 如何成为人工智能专家

作为机器学习的初学者,为我制定一个路线图,说明如何将自己发展成为机器学习领域的专家。
- 学习数学基础知识,特别是微积分、线性代数和概率论。
- 熟悉 Python 和 R 等编程语言,因为它们广泛用于机器学习。
- 了解基本的机器学习概念,例如监督学习和无监督学习、过度拟合、欠拟合和偏差方差权衡。
- 通过获取数据预处理、特征工程和数据可视化方面的技能,学习如何处理数据。
- 掌握核心机器学习算法,例如线性回归、逻辑回归、决策树、随机森林和支持向量机 (SVM)。
- 获取深度学习和神经网络的知识,包括反向传播、卷积神经网络 (CNN)、循环神经网络 (RNN) 和长短期记忆 (LSTM) 网络等概念。
- 了解机器学习的高级技术,例如集成方法、聚类、强化学习和生成模型。
- 练习现实世界的项目和挑战,以获得实践经验并提高您的技能。
- 通过阅读研究论文、参加会议和关注该领域的专家,了解机器学习的最新研究和趋势。
- 考虑攻读机器学习学位或认证课程,例如数据科学硕士学位或机器学习工程师认证。
请记住,将自己培养成机器学习专家需要时间、努力和持续学习。坚持不懈地学习和实践以实现您的目标。
5.2 整理人工智能知识

如何有效记住无数不同的机器学习和深度学习算法?提供如何构建信息、哪些工具可以帮助组织知识以及如何快速查找信息。
为了有效地记住不同的机器学习和深度学习算法,采用结构化方法来组织信息非常重要。一种方法是创建一套全面的注释,其中包括:
- 算法简单描述
- 使用的数学公式和方程
- 算法的优缺点
- 使用该算法的真实世界示例
Evernote、OneNote 或 Google Keep 等工具可以帮助您整理笔记,并让您轻松快速地搜索特定算法。这些工具允许您为不同的主题创建不同的笔记本或部分,并轻松向笔记添加标签以帮助您以后找到它们。
记住算法的另一种有效方法是创建抽认卡。一侧写下算法名称,另一侧写下关键细节。使用这些抽认卡定期测验自己。
定期查看笔记并练习实施算法也很重要。参加在线课程或寻找编码挑战可以帮助您巩固对算法的理解并提高在现实场景中应用它们的能力。此外,加入在线社区或参加与机器学习相关的聚会可以让您有机会与也对该主题感兴趣的其他人进行讨论和学习。
5.3 如何通过初级机器学习工程师的面试

我怎样才能成功通过初级机器学习工程师职位的面试?
要成功通过初级机器学习工程师职位的面试,以下是一些提示:
-
温习基础知识:全面掌握数学、统计学和编程的基础知识,因为这些是机器学习的基石。
-
练习编码:用您最熟悉的语言练习编码练习、算法和数据结构。熟悉 TensorFlow、PyTorch 和 Scikit-Learn 等库和框架。
-
了解机器学习算法:熟悉不同的机器学习算法,例如线性回归、逻辑回归、决策树、随机森林、支持向量机和神经网络。
-
了解深度学习:熟悉卷积神经网络、循环神经网络、长短期记忆网络等深度学习技术。
-
了解数据准备:熟悉准备数据的技术,例如特征缩放、标准化和one-hot 编码。
-
了解评估指标:熟悉准确率、精确率、召回率、F1 分数、ROC 曲线等评估指标。
-
能够解释您的思维过程:在面试过程中,能够解释您的思维过程以及解决特定问题所采取的方法。
-
熟悉常见的机器学习挑战:熟悉常见的挑战,例如过度拟合、欠拟合、偏差-方差权衡和正则化。
-
练习沟通:练习沟通技巧,因为您需要向非技术利益相关者解释复杂的概念。
-
使用资源:使用在线课程、书籍和开源项目等资源来扩展您的知识。
通过遵循这些提示并定期练习,您可以增加成功通过初级机器学习工程师职位面试的机会。
六、结论

ChatGPT 可以记住广泛的机器学习、数据科学和深度学习方法。如果您需要快速回忆某些信息,它可能非常有用。
由于 ChatGPT 经常遗漏信息、不准确地输入日期和常量值以及其他错误,因此我不建议使用它来研究任何新主题。
ChatGPT 是一个很好的工具,可用于扩展您的信息、继续您的工作、检查具体细节或进行高级研究。它可以有效地比较几种著名的算法,创建路线图,并快速且可能正确地提出新的想法。
七、致谢
感谢 ChatGPT 团队创建了这个出色的工具并帮助其他人加速我们的研究和开发!
感谢您阅读机器学习 ChatGPT 上的这篇文章!我希望您发现这些信息内容丰富且有用。如果您有任何问题或反馈,请随时在下面发表评论或通过网站页脚中的任何沟通渠道直接与我联系。另外,请务必查看我的博客,了解有关机器学习和深度学习的更多精彩内容。
相关文章:
ChatGPT 在机器学习中的应用
办公室里一个机器人坐在人类旁边,Artstation 上的流行趋势,美丽的色彩,4k,充满活力,蓝色和黄色, DreamStudio出品 一、介绍 大家都知道ChatGPT。它在解释机器学习和深度学习概念方面也非常高效,…...

【JavaEE】锁策略
文章目录 前言1. 乐观锁和悲观锁2. 重量级锁和轻量级锁3. 自旋锁和挂起等待锁4. 公平锁和非公平锁5. 可重入锁和非可重入锁6. 读写锁Java synchronized 分别对应哪些锁策略1. 乐观锁和悲观锁2. 重量级锁和轻量级锁3. 自旋锁和挂起等待锁4. 公平锁和非公平锁5. 可重入锁和非可重…...

在 SDXL 上用 T2I-Adapter 实现高效可控的文生图
T2I-Adapter 是一种高效的即插即用模型,其能对冻结的预训练大型文生图模型提供额外引导。T2I-Adapter 将 T2I 模型中的内部知识与外部控制信号结合起来。我们可以根据不同的情况训练各种适配器,实现丰富的控制和编辑效果。 同期的 ControlNet 也有类似的…...
Python分支结构和循环结构
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 一.分支结构 分支结构是根据判断条件结果而选择不同向前路径的运行方式,分支结构分为:单分支,二分支和多分支。 1࿰…...

Unity调用API函数对系统桌面和窗口截图
Unity3D调用WINAPI函数对系统窗口截图 引入WINAPI函数调用WINAPI函数进行截图使用例子 引入WINAPI函数 using System; using System.Collections; using System.Runtime.InteropServices; using System.Drawing;[DllImport("user32.dll")]private static extern Int…...

【问题思考总结】CPU怎么访问磁盘?CPU只有32位,最多只能访问4GB的空间吗?
问题 在学习操作系统的时候发现了这样一个问题,32位的CPU寻址空间只有4GB,难道只有4GB的空间可以使用吗?以此为始,我开始了一些思考。 思考 Q1:首先,我似乎混淆了一个概念,内存和外存&#x…...
-CAM-根据刀具对程序组进行重新分组)
UG NX二次开发(C++)-CAM-根据刀具对程序组进行重新分组
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1、前言2、在UG NX中创建一个三维模型3、在UG NX/CAM中创建多个加工程序4、采用UG NX二次开发(NXOpen)实现按照刀具分组程序组4.2 创建UI Styler4.1 实现逻辑4.2 生成的代码如下:4.3 测试效果4.…...

Unity如何实现TreeView
前言 最近有一个需求,需要实现一个TreeView的试图显示,开始我一直觉得这么通用的结构,肯定有现成的UI组件或者插件可以使用,结果,找了好久,都没有找到合适的插件,有两个效果差强人意。 最后在回家的路上突然灵光一闪,想到了一种简单的实现方式,什么插件都不用,仅使用…...

Android widget 小部件使用指南强化版
Android widget 小部件使用指南强化版 一、简单UI的小部件二、含集合的小部件三、可配置的小部件四、可控制的小部件五、Android 12 Widget 更新 小部件是主屏幕定制的一个重要方面。您可以将它们视为应用程序最重要的数据和功能的“概览”视图,这些数据和功能可以直…...
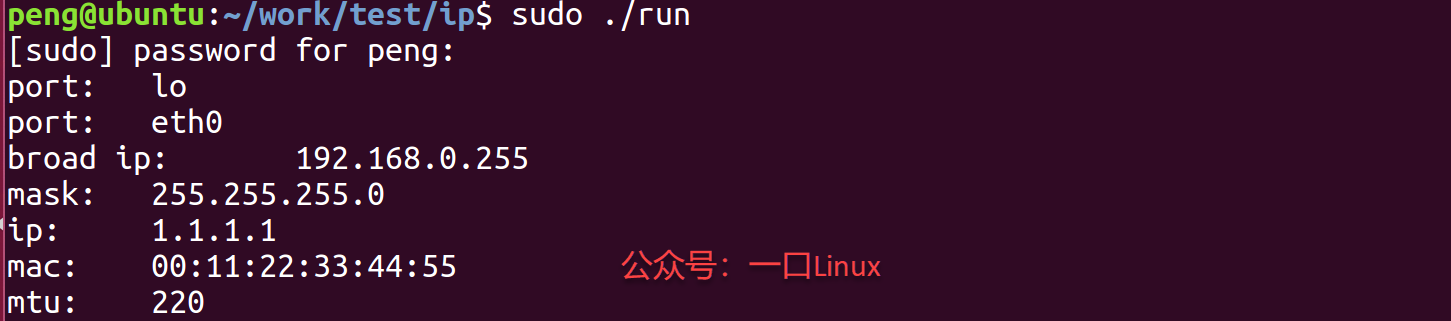
Linux下C语言操作网卡的几个代码实例?特别实用
前面写了一篇关于网络相关的文章:如何获取当前可用网口。 《简简单单教你如何用C语言列举当前所有网口!》 那么如何使用C语言直接操作网口? 比如读写IP地址、读写MAC地址等。 一、原理 主要通过系统用socket()、ioctl()、实现 int sock…...

noip2011选择旅馆
1.审题:第一个人与第二个人入住的旅馆要求是同色的; 两个人去消费的旅馆并没有要求与入住的旅馆是同色的(这点要小心) 2.要求记录以下数据: 1)a[color]表示当前同为颜色color的旅馆数 2)b[co…...
vue造轮子完整指南--npm组件包开发步骤
一、项目包文件的创建和初始化。 1. 新建项目包。 vue create <Project Name> //用于发布npm包的项目文件名 ps:一般选择自定义,然后不需要Vuex和Router,其他选项按自己实际情况选择安装即可。 2.修改原始src文件名、新增组件项目存放文件和修改…...
28 drf-Vue个人向总结-1
文章目录 前后端分离开发展示项目项补充知识开发问题浏览器解决跨域问题 drf 小tips设置资源root目录使用自定义的user表设置资源路径media数据库补充删除表中数据单页面与多页面模式过滤多层自关联后端提交的数据到底是什么jwt token登录设置普通的 token 原理使用流程解析 jw…...

线性代数(七) 矩阵分析
前言 从性线变换我们得出,矩阵和函数是密不可分的。如何用函数的思维来分析矩阵。 矩阵的序列 通过这个定义我们就定义了矩阵序列的收敛性。 研究矩阵序列收敛性的常用方法,是用《常见向量范数和矩阵范数》来研究矩阵序列的极限。 长度是范数的一个特…...
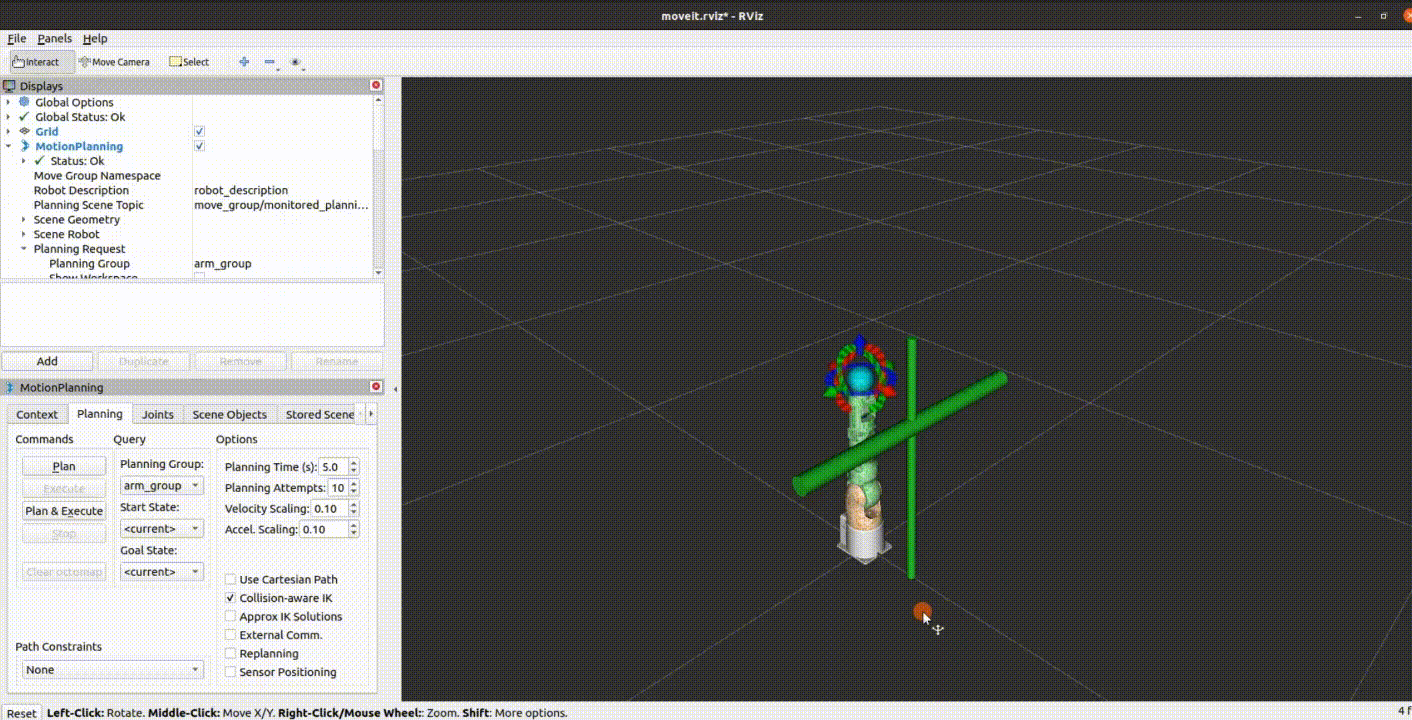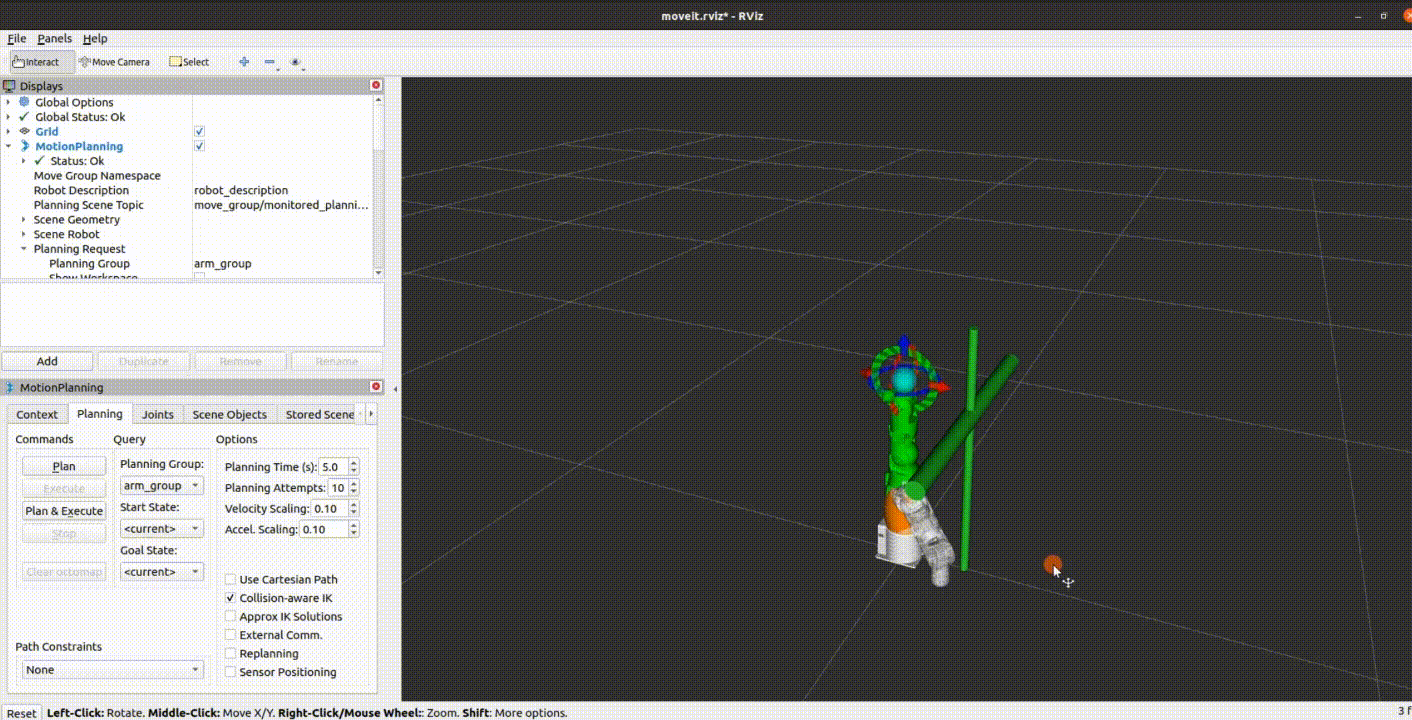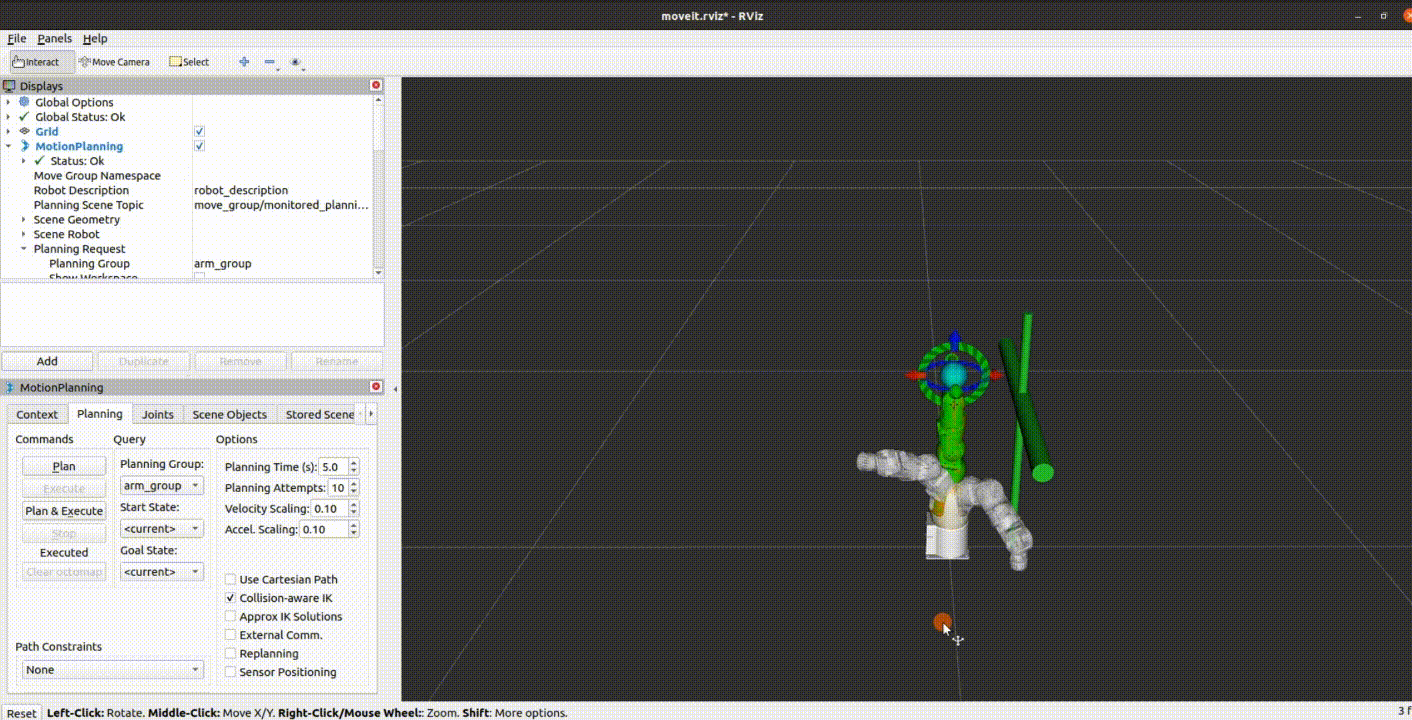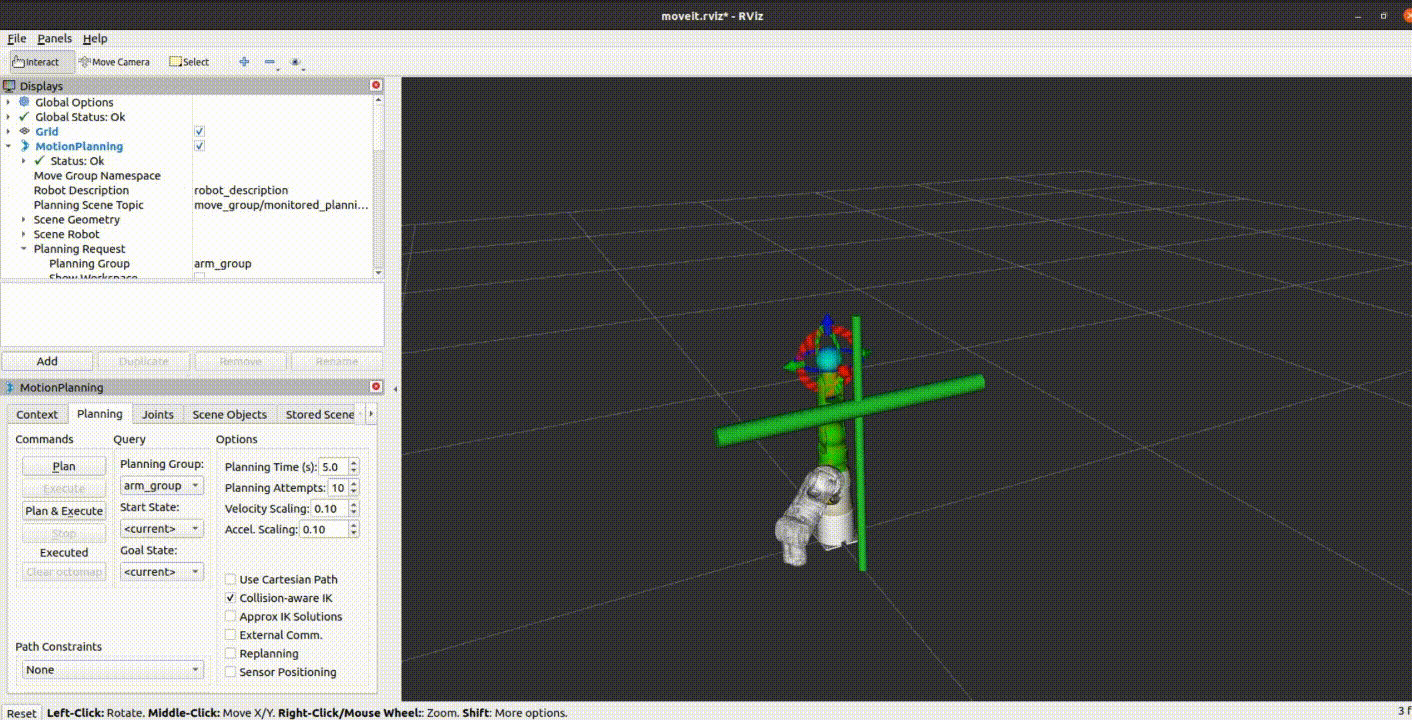
myArm 全新七轴桌面型机械臂
引言 在不断演进的科技世界中,我们始终追求创新和卓越,以满足客户的需求并超越他们的期望。今天,我们很高兴地宣布我们的最新产品——myArm 300 Pi,一款七轴的桌面型机械臂。这款产品的独特之处在于其灵活性和可编程性,…...

tomcat乱码解决
解决乱码 1、修改bin\catalina.bat配置文件 修改tomcat的配置文件,找到tomcat路径下的\bin目录下的catalina.bat文件,修改 set “JAVA_OPTS%JAVA_OPTS% %JSSE_OPTS% -Dfile.encodingUTF-8 -Dsun.jnu.encodingUTF-8 ” 2、修改conf\logging.properties配置…...

【Linux】详解线程第三篇——线程同步和生产消费者模型
线程同步和生消模型 前言正式开始再次用黄牛抢票来讲解线程同步的思想通过条件变量来实现线程同步条件变量接口介绍初始化和销毁pthread_cond_waitsignal和broadcast 生产消费者模型三种关系用基本工程师思维再次理解基于生产消费者模型的阻塞队列版本一版本二多生多消 利用RAI…...

k8s 安装
文章目录 k8s 客户端安装k8s集群minikubekindkubeadm 验证 k8s 客户端 用于连接k8s集群,建议下载1.23.x的版本,其他的版本本地运行可能会有莫名其妙的报错 https://dl.k8s.io/release/v1.23.16/bin/linux/amd64/kubectl 安装k8s集群 minikube Minik…...

红队打靶:THE PLANETS: MERCURY打靶思路详解(vulnhub)
目录 写在开头 第一步:主机发现和端口扫描 第二步:Web渗透 第三步:获取初步立足点并搜集信息 第四步:软连接劫持sudo提权 总结与思考 写在开头 本篇博客在自己的理解之上根据大佬红队笔记的视频进行打靶,详述了…...
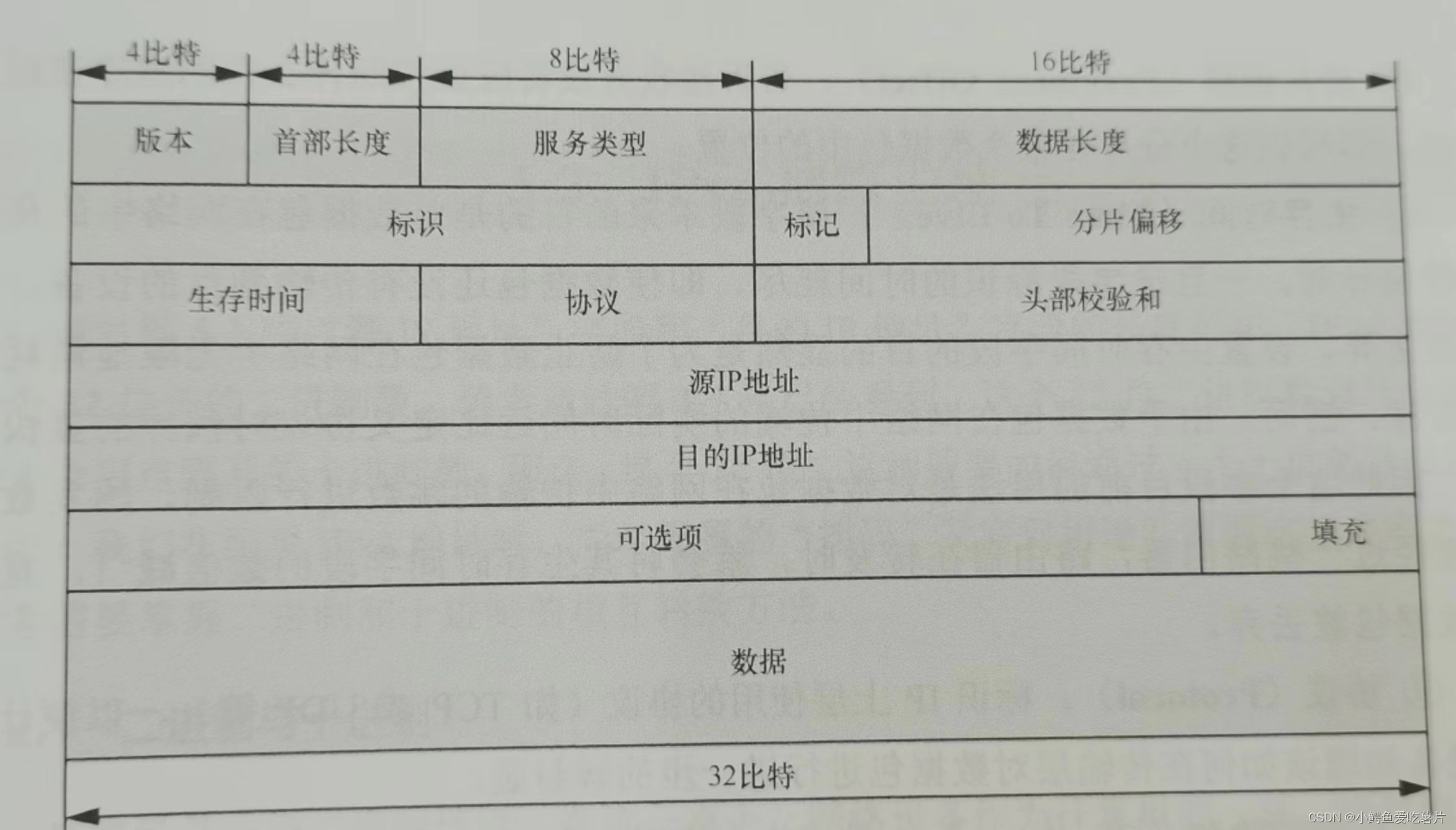
【网络协议】IP
当连接多个异构的局域网形成强烈需求时,用户不满足于仅在一个局域网内进行通信,他们希望通过更高一层协议最终实现异构网络之间的连接。既然需要通过更高一层的协议将多个局域网进行互联,那么这个协议就必须为不同的局域网环境定义统一的寻址…...

CVPR2025新星DehazeXL:开源8K去雾数据集与可解释归因图,高分辨率图像处理新范式
1. 高分辨率图像去雾的痛点与DehazeXL的突破 第一次处理8K航拍图像时,我盯着显存不足的报错信息愣了半天——当时用的某知名去雾模型,光是加载81928192的图片就吃掉了48GB显存。这其实是高分辨率图像处理领域的普遍困境:传统方法要么被迫降采…...

别再折腾无障碍服务了!用Android蓝牙HID实现投屏反控的保姆级避坑指南
蓝牙HID协议在Android投屏反控中的深度实践 如果你正在开发一款类似Scrcpy的Android投屏工具,肯定遇到过这样的困境:无障碍服务(AccessibilityService)的授权流程繁琐且容易被厂商拦截,反射调用InputManagerService又需要系统级权限。这时候&…...

别再为H5读Excel发愁了!UniApp里用FileReader+XLSX库的保姆级避坑指南
UniApp H5开发实战:Excel文件解析的深度解决方案 当你在UniApp中开发H5应用时,处理本地Excel文件可能会遇到一些独特的挑战。与标准Web环境不同,UniApp的混合架构对文件操作有着特殊限制和要求。本文将带你深入理解这些差异,并提供…...

图像传感器噪声全解析:从原理到降噪实战
1. 图像传感器噪声的底层逻辑 每次按下手机快门时,你可能不知道图像传感器正在经历一场电子风暴。就像老式收音机的沙沙声,图像传感器也会产生各种"电子噪音"。这些噪声直接影响照片质量,尤其在弱光环境下更为明显。 我拆解过上百款…...
)
毫米波雷达信号处理入门:用MATLAB解析DCA1000采集的IWR6843原始数据(附代码)
毫米波雷达信号处理实战:从原始数据到距离谱的MATLAB实现 在自动驾驶和智能感知领域,毫米波雷达因其全天候工作能力和精确的距离测量特性,成为不可或缺的传感器。当开发者完成硬件配置和数据采集后,面对adc_data.bin这样的原始数据…...

SKILL语言在数字IC设计中的高级应用:如何优化你的工作流程
SKILL语言在数字IC设计中的高级应用:如何优化你的工作流程 在数字IC设计的复杂世界里,效率就是竞争力。当大多数工程师还在手动点击EDA工具菜单时,掌握SKILL语言的高手已经用几行代码完成了批量操作。这不是魔法,而是SKILL语言赋…...

突破式3步实现:用MOOTDX构建零成本金融数据获取引擎
突破式3步实现:用MOOTDX构建零成本金融数据获取引擎 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析领域,数据获取一直是从业者面临的核心挑战。无论是量化交…...
:从原理到代码,新手全疑问一次性解决)
零基础吃透静态链表(数组模拟链表):从原理到代码,新手全疑问一次性解决
本文面向刚入门数据结构、已掌握动态链表但看不懂静态链表的新手,全程从已知到未知,循序渐进拆解所有核心知识点、代码逻辑和新手高频误区,看完就能彻底吃透静态链表。目录什么是静态链表?和动态链表的核心区别静态链表的核心规则…...

华三M-LAG实战:从零构建高可用数据中心网络
1. 为什么数据中心需要M-LAG技术? 刚接手数据中心网络建设项目时,我最头疼的就是如何实现高可用性。传统方案要么成本太高,要么切换速度达不到要求。直到接触华三的M-LAG技术,才发现原来跨设备链路聚合可以这么玩。 M-LAG全称Mult…...

OpenClaw定时任务实践:Qwen3.5-4B-Claude实现凌晨数据备份自动化
OpenClaw定时任务实践:Qwen3.5-4B-Claude实现凌晨数据备份自动化 1. 为什么需要夜间自动化备份 作为一个独立开发者,我经常遇到这样的困境:白天在多个项目间切换开发,晚上关机前才想起忘记备份关键数据。手动执行备份不仅占用休…...