基于Dlib训练自已的人脸数据集提高人脸识别的准确率
前言
由于图像的质量、光线、角度等因素影响。这时如果使用官方提供的模型做人脸识别,就会导至识别率不是很理想。人脸识别的准确率与图像的清晰度和质量有关。如果图像模糊、光线不足或者有其他干扰因素,Dlib 可能无法正确地识别人脸。为了确保图像质量良好,可以使用更清晰的图像、改善光照条件或使用图像增强技术来提高图像质量。但这些并不是本篇章要讲述的内容。那么除去图像质量和光线不足等因素,如何解决准确率的问题呢?答案就是需要自已收集人脸并进行训练自已的识别模型。
模型训练
要使用Dlib训练自己的人脸数据集,可以按照以下步骤进行:
-
数据收集:收集一组包含人脸的图像,并对每个人脸进行标记。可以使用Dlib提供的标记工具来手动标记每个人脸的位置。
-
数据准备:将数据集划分为训练集和测试集。确保训练集和测试集中的图像具有不同的人脸,并且每个人脸都有相应的标记。
-
特征提取:使用Dlib提供的人脸特征提取器,如dlib.get_frontal_face_detector()和dlib.shape_predictor(),对每个图像进行人脸检测和关键点定位。可以使用这些关键点来提取人脸特征。
-
特征向量生成:对于每个人脸,使用关键点和人脸图像来生成一个唯一的特征向量。可以使用Dlib的face_recognition模块中的face_encodings()函数来生成特征向量。
-
训练分类器:使用生成的特征向量和相应的标签来训练分类器。可以使用Dlib的svm_c_trainer()或者其他分类器进行训练。确保使用训练集进行训练,并使用测试集进行验证。
-
评估准确率:使用测试集对训练好的分类器进行评估,计算准确率、召回率等指标来评估人脸识别的性能。
以下是一个简单的例子,展示了如何使用Dlib训练自己的人脸数据集:
导入必要的库
import dlib
import os
import numpy as np
from sklearn import svm
定义数据集路径和模型路径
dataset_path = "path_to_dataset"
model_path = "path_to_save_model"
加载人脸检测器和关键点定位器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
收集数据集中的图像和标签
images = []
labels = []# 遍历数据集目录
for person_name in os.listdir(dataset_path):person_path = os.path.join(dataset_path, person_name)if os.path.isdir(person_path):# 遍历每个人的图像for image_name in os.listdir(person_path):image_path = os.path.join(person_path, image_name)# 加载图像img = dlib.load_rgb_image(image_path)# 人脸检测和关键点定位dets = detector(img)for det in dets:shape = predictor(img, det)# 生成特征向量face_descriptor = np.array(face_recognition.face_encodings(img, [shape])[0])# 添加到训练集images.append(face_descriptor)labels.append(person_name)# 转换为numpy数组
images = np.array(images)
labels = np.array(labels)
设置训练分类器
# 训练分类器
classifier = svm.SVC(kernel='linear', probability=True)
classifier.fit(images, labels)
保存模型
dlib.save_linear_kernel(model_path, classifier)
完整代码
import dlib
import os
import numpy as np
from sklearn import svmdataset_path = "path_to_dataset"
model_path = "path_to_save_model"detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")images = []
labels = []# 遍历数据集目录
for person_name in os.listdir(dataset_path):person_path = os.path.join(dataset_path, person_name)if os.path.isdir(person_path):# 遍历每个人的图像for image_name in os.listdir(person_path):image_path = os.path.join(person_path, image_name)# 加载图像img = dlib.load_rgb_image(image_path)# 人脸检测和关键点定位dets = detector(img)for det in dets:shape = predictor(img, det)# 生成特征向量face_descriptor = np.array(face_recognition.face_encodings(img, [shape])[0])# 添加到训练集images.append(face_descriptor)labels.append(person_name)# 转换为numpy数组
images = np.array(images)
labels = np.array(labels)# 训练分类器
classifier = svm.SVC(kernel='linear', probability=True)
classifier.fit(images, labels)images = []
labels = []# 遍历数据集目录
for person_name in os.listdir(dataset_path):person_path = os.path.join(dataset_path, person_name)if os.path.isdir(person_path):# 遍历每个人的图像for image_name in os.listdir(person_path):image_path = os.path.join(person_path, image_name)# 加载图像img = dlib.load_rgb_image(image_path)# 人脸检测和关键点定位dets = detector(img)for det in dets:shape = predictor(img, det)# 生成特征向量face_descriptor = np.array(face_recognition.face_encodings(img, [shape])[0])# 添加到训练集images.append(face_descriptor)labels.append(person_name)# 转换为numpy数组
images = np.array(images)
labels = np.array(labels)# 训练分类器
classifier = svm.SVC(kernel='linear', probability=True)
classifier.fit(images, labels)images = []
labels = []# 遍历数据集目录
for person_name in os.listdir(dataset_path):person_path = os.path.join(dataset_path, person_name)if os.path.isdir(person_path):# 遍历每个人的图像for image_name in os.listdir(person_path):image_path = os.path.join(person_path, image_name)# 加载图像img = dlib.load_rgb_image(image_path)# 人脸检测和关键点定位dets = detector(img)for det in dets:shape = predictor(img, det)# 生成特征向量face_descriptor = np.array(face_recognition.face_encodings(img, [shape])[0])# 添加到训练集images.append(face_descriptor)labels.append(person_name)# 转换为numpy数组
images = np.array(images)
labels = np.array(labels)# 训练分类器
classifier = svm.SVC(kernel='linear', probability=True)
classifier.fit(images, labels)#保存模型
dlib.save_linear_kernel(model_path, classifier)
除了使用SVM分类器,你还可以使用其他分类器进行人脸识别模型的训练。以下是一些常见的分类器:
-
决策树分类器(Decision Tree Classifier):基于树结构的分类器,可以通过一系列的决策来对样本进行分类。
-
随机森林分类器(Random Forest Classifier):由多个决策树组成的集成学习模型,通过投票或平均预测结果来进行分类。
-
K最近邻分类器(K-Nearest Neighbors Classifier):根据样本之间的距离来进行分类,将未知样本分类为其最近的K个邻居中最常见的类别。
-
朴素贝叶斯分类器(Naive Bayes Classifier):基于贝叶斯定理的概率分类器,假设特征之间相互独立,通过计算后验概率进行分类。
-
神经网络分类器(Neural Network Classifier):由多层神经元组成的模型,通过反向传播算法进行训练,可以用于复杂的分类任务。
这些分类器都有各自的优缺点和适用场景,你可以根据你的数据集和需求选择合适的分类器进行训练。
相关文章:

基于Dlib训练自已的人脸数据集提高人脸识别的准确率
前言 由于图像的质量、光线、角度等因素影响。这时如果使用官方提供的模型做人脸识别,就会导至识别率不是很理想。人脸识别的准确率与图像的清晰度和质量有关。如果图像模糊、光线不足或者有其他干扰因素,Dlib 可能无法正确地识别人脸。为了确保图像质量…...

Git 详细安装教程(详解 Git 安装过程的每一个步骤
Git 详细安装教程(详解 Git 安装过程的每一个步骤) 该文章详细具体,值得收藏学习...

kafka伪集群部署,使用KRAFT模式
1:拉去管理kafka界面UI镜像 docker pull provectuslabs/kafka-ui2:拉去管理kafka镜像 docker pull bitnami/kafka3:docker-compose.yml version: 3.8 services:kafka-1:container_name: kafka1image: bitnami/kafka ports:- "19092:19092"- "19093:19093&quo…...

【双指针遍历】N数之和问题
文章目录 二数之和LC1三数之和LC15四数之和LC18最接近的三数之和LC16 二数之和LC1 题目链接 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对…...

Qt的QObject类
文章目录 QObject类如何在Qt中使用QObject的信号与槽机制?如何在Qt中使用QObject的属性系统?QObject的元对象系统如何实现对象的反射功能? QObject类 Qt的QObject类是Qt框架中的基类,它是所有Qt对象的父类。QObject提供了一些常用…...
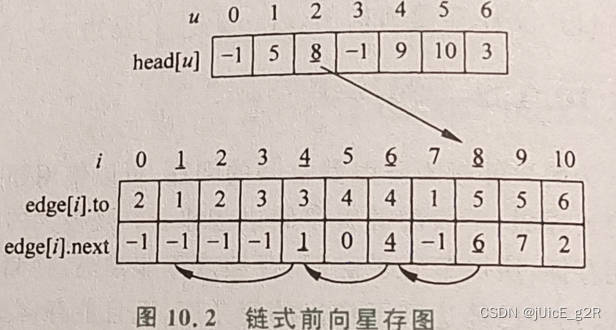
【图论C++】链式前向星(图(树)的存储)
/*** file * author jUicE_g2R(qq:3406291309)————彬(bin-必应)* 一个某双流一大学通信与信息专业大二在读 * * brief 一直在竞赛算法学习的路上* * copyright 2023.9* COPYRIGHT 原创技术笔记:转载需获得博主本人…...
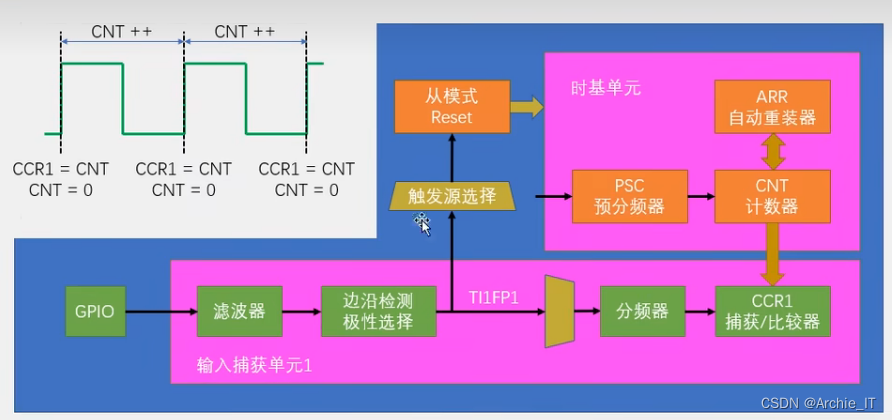
16.PWM输入捕获示例程序(输入捕获模式测频率PWMI模式测频率和占空比)
目录 输入捕获相关库函数 输入捕获模式测频率 PWMI模式测频率和占空比 两个代码的接线图都一样,如下 测量信号的输入引脚是PA6,信号从PA6进来,待测的PWM信号也是STM32自己生成的,输出引脚是PA0。 需要配置电路连接图示如下&…...

pip version 更新
最近报了一个错: 解决办法: 在cmd输入“conda install pip” conda install pip 完了之后再输入: python -m pip install --upgrade pip ok....

Oracle - 多区间按权重取值逻辑
啰嗦: 其实很早就遇到过类似问题,也设想过,不过一致没实际业务需求,也就耽搁了;最近有业务提到了,和同事讨论,各有想法,所以先把逻辑整理出来,希望有更好更优的解决方案;…...
)
本次CTF·泰山杯网络安全的基础知识部分(二)
简记23年九月参加的泰山杯网络安全的部分基础知识的题目,随时补充 15(多选)网络安全管理工作必须坚持“谁主管、谁负责,谁运营、谁负责,谁使用、谁负责”的原则,和“属地管理”的原则 谁主管、谁负责&…...

MyBatis 映射文件(Mapper XML):配置与使用
MyBatis 映射文件(Mapper XML):配置与使用 MyBatis是一个强大的Java持久化框架,它允许您将SQL查询、插入、更新和删除等操作与Java方法进行映射。这种映射是通过MyBatis的映射文件,通常称为Mapper XML文件来实现的。本…...
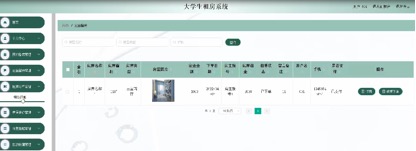
基于 SpringBoot 的大学生租房网站
文章目录 1 简介2 技术栈3 需求分析4 系统设计5 系统详细设计5.1系统功能模块5.2管理员模块5.3房主功能模块5.4用户功能模块 源码咨询 1 简介 本大学生租房系统使用简洁的框架结构,专门用于用户浏览首页,房屋信息,房屋评价,公告资…...
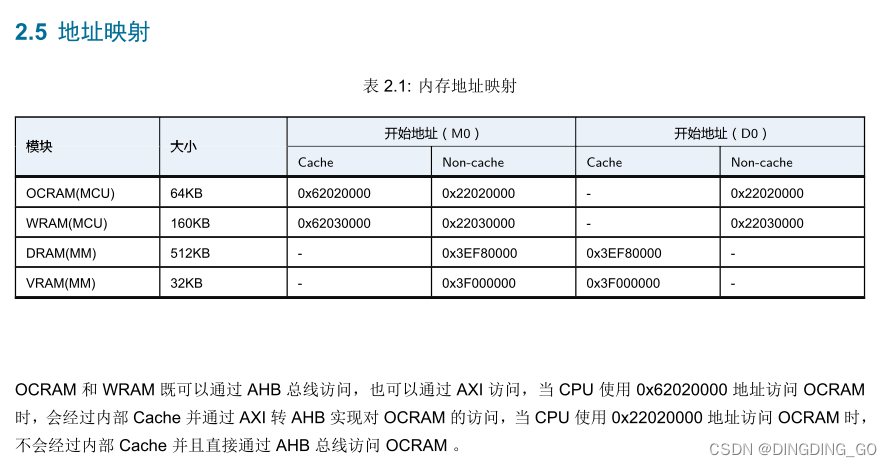
BL808学习日志-0-概念理解
一、主核心的介绍 1.三个核心在FREERTOS系统中相互独立,各负责各自的外设和程序;其中M0和LP核心在一个总线上,D0单独在一个总线上,两个总线使用AXI4.0(??)通讯? CPU0(M0)-E907架构,320MHz; CPU1(LP)-E9…...

CISSP学习笔记:业务连续性计划
第三章 业务连续性计划 3.1 业务连续性计划 业务连续性计划(BCP): 对组织各种过程的风险评估,发生风险的情况下为了使风险对组织的影响降至最小而定制的各种计划BCP和DRP首先考虑的人不受伤害,然后再解决IT恢复和还原问题BCP的主要步骤: 项…...

.NET Nuget包推荐安装
文章目录 前言通用WPFWebApiBlazor 前言 我这里的包主要是.NET Core的,.NET Framework可能不支持。 通用 Newtonsoft.Json:最常用的C#和Json对象互转的包。支持匿名对象,但是不支持Enum枚举类型,显示的是Enum的数值,…...
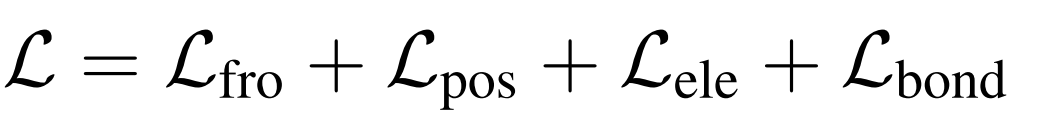
【文献阅读】Pocket2Mol : 基于3D蛋白质口袋的高效分子采样 + CrossDocked数据集说明
Pocket2Mol: Efficient Molecular Sampling Based on 3D Protein Pockets code: GitHub - pengxingang/Pocket2Mol: Pocket2Mol: Efficient Molecular Sampling Based on 3D Protein Pockets 所用数据集 与“A 3D Generative Model for Structure-Based Drug Desi…...

TrustRadius 评论:为什么 Splashtop 优于 LogMeIn
在当今日益数字化的格局中,远程访问和远程支持工具不仅方便而且至关重要。无论对于居家办公人员,还是对于提供远程支持的 IT 专家,能够安全高效地访问远程系统已成为以技术为导向的日常生活的主要内容。 Splashtop 和 LogMeIn 是远程领域的两…...
【动态规划】动态规划经典例题 力扣牛客
文章目录 跳台阶 BM63 简单跳台阶扩展 JZ71 简单打家结舍 LC198 中等打家劫舍2 LC213中等最长连续递增序列 LC674 简单乘积最大子数组LC152 中等最长递增子序列LC300 中等最长重复子数组LC718最长公共子串NC BM66最长公共子序列LC1143 中等完全平方数LC279零钱兑换 LC322 中等单…...
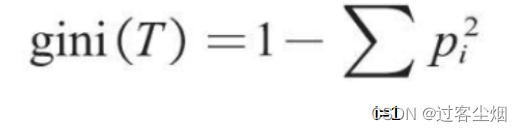
统计模型----决策树
决策树 (1)决策树是一种基本分类与回归方法。它的关键在于如何构建这样一棵树。决策树的建立过程中,使用基尼系数来评估节点的纯度和划分的效果。基尼系数是用来度量一个数据集的不确定性的指标,其数值越小表示数据集的纯度越高。…...

C# List 复制之深浅拷贝
C# List 复制 之深浅拷贝 声明类 public class TestStu{public int Number{get;set; }public string Name{get;set; }}public static async Task<int> Main(string[] args){var stu1 new TestStu(){Number 1,Name "1"};var stu2 new TestStu(){Numbe…...

DocX入门指南:如何在不安装Word的情况下快速创建第一个Word文档
DocX入门指南:如何在不安装Word的情况下快速创建第一个Word文档 【免费下载链接】DocX Fast and easy to use .NET library that creates or modifies Microsoft Word files without installing Word. 项目地址: https://gitcode.com/gh_mirrors/doc/DocX Do…...
)
千问 LeetCode 2281.巫师的总力量和 public int totalStrength(int[] strength)
LeetCode 2281. 巫师的总力量和 是一道经典的 贡献法 + 单调栈 + 前缀和的前缀和 题目。题目要求对数组的所有非空连续子数组,计算: min(subarray) * sum(subarray) 的总和,并对 10^9 + 7 取模。 ✅ 解题思路(核心思想) 我们 不枚举所有子数组(那样是 O(n)),而是 枚…...

权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区
更多请点击: https://intelliparadigm.com 第一章:权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区 在企业级部署 Gemini Workspace 时,大量团队遭遇“功能可登录但协作不可用”的隐性故障。根本原因并非 …...

OpenClaw狂欢暗藏安全隐患,深圳机密计算科技端云一体方案筑牢AI Agent安全基座
AI Agent时代,安全信任的崩塌2026年初,OpenClaw横空出世,仅用60天打破React保持十年的GitHub Star纪录,成为当年热度最高的现象级开源项目。2026年3月,在英伟达GTC全球开发者大会上,黄仁勋直言称“OpenClaw…...
换个角度思考【牛客tracker 每日一题】
换个角度思考 时间限制:1秒 空间限制:256M 知识点:线段树 网页链接 牛客tracker 牛客tracker & 每日一题,完成每日打卡,即可获得牛币。获得相应数量的牛币,能在【牛币兑换中心】,换取相…...

别再死磕外链了:用Python+搜索API实现Google SEO自动化内容生产
做Google SEO的人都有一个共同感受:越来越难了。 以前发发外链、堆堆锚文本就能上去,现在不行了。Google的算法从"匹配关键词"进化到了"匹配搜索意图"。外链权重从60%降到30%,内容质量成了核心排名因素。 但问题是&#…...

Sunshine游戏串流服务器:打造你的个人云端游戏平台
Sunshine游戏串流服务器:打造你的个人云端游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏?Sunshine游戏串流服务器是你…...
Translumo:Windows游戏实时翻译的终极免费解决方案:如何轻松翻译游戏字幕和视频文本
Translumo:Windows游戏实时翻译的终极免费解决方案:如何轻松翻译游戏字幕和视频文本 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.c…...

淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟
淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojin…...
自动做化学实验的机器)
图解人工智能(12)自动做化学实验的机器
近年来,人工智能和传统科学的结合备受瞩目。2019年,英国利物浦大学在《自然》杂志发表论文,介绍了一种可以自动做化学实验的机器人。查找相关资料,并讨论一下类似的工作能给人类社会带来怎样的变革。首先,实验人员的培…...