ACGAN
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量;SGAN(Semi-Supervised GAN)通过使判别器/分类器重建标签信息来提高生成数据的质量。既然这两种思路都可以提高生成数据的质量,于是ACGAN综合了以上两种思路,既使用标签信息进行训练,同时也重建标签信息,结合CGAN和SGAN的优点,从而进一步提升生成样本的质量,并且还能根据指定的标签相应的样本。
1. ACGAN的网络结构为:
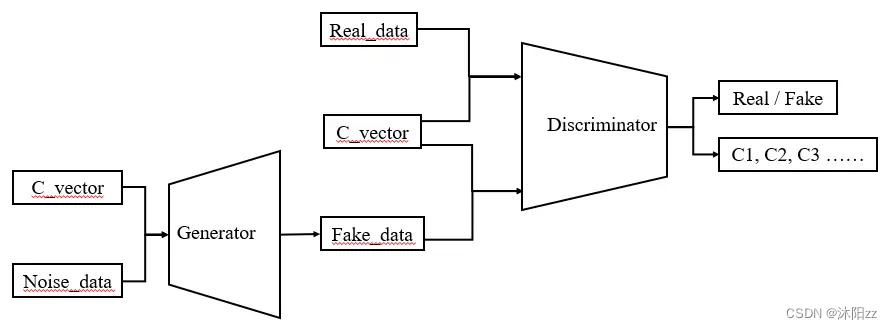
ACGAN的网络结构框图
生成器的输入包含C_vector和Noise_data两个部分,其中C_vector为训练数据标签信息的One-hot编码张量,其形状为:(batch_size, num_class) ;Noise_data的形状为:(batch_size, latent_dim)。然后将两者进行拼接,拼接完成后,得到的输入张量为:(batch_size, num_class + latent_dim)。生成器的的输出张量为:(batch_size, channel, Height, Width)。
判别器的输入为:(batch_size, channel, Height, Width); 判别的器的输出为两部分,一部分是源数据真假的判断,形状为:(batch_size, 1),一部分是输入数据的分类结果,形状为:(batch_size, class_num)。因此判别器的最后一层有两个并列的全连接层,分别得到这两部分的输出结果,即判别器的输出有两个张量(真假判断张量和分类结果张量)。
2. ACGAN的损失函数:
对于判别器而言,既希望分类正确,又希望能正确分辨数据的真假;对于生成器而言,也希望能够分类正确,当时希望判别器不能正确分辨假数据。
D_real, C_real = Discriminator( real_imgs) # real_img 为输入的真实训练图片
D_real_loss = torch.nn.BCELoss(D_real, Y_real) # Y_real为真实数据的标签,真数据都为-1,假数据都为+1
C_real_loss = torch.nn.CrossEntropyLoss(C_real, Y_vec) # Y_vec为训练数据One-hot编码的标签张量
gen_imgs = Generator(noise, Y_vec)
D_fake, C_fake = Discriminator(gen_imgs)
D_fake_loss = torch.nn.BCELoss(D_fake, Y_fake)
C_fake_loss = torch.nn.CrossEntropyLoss(C_fake, Y_vec)
D_loss = D_real_loss + C_real_loss + D_fake_loss + C_fake_loss
生成器的损失函数:
gen_imgs = Generator(noise, Y_vec)
D_fake, C_fake = Discriminator(gen_imgs)
D_fake_loss = torch.nn.BCELoss(D_fake, Y_real)
C_fake_loss = torch.nn.CrossEntropyLoss(C_fake, Y_vec)
G_loss = D_fake_loss + C_fake_loss
class Discriminator(nn.Module): # 定义判别器def __init__(self, img_size=(64, 64), num_classes=2): # 初始化方法super(Discriminator, self).__init__() # 继承初始化方法self.img_size = img_size # 图片尺寸,默认为(64.64)三通道图片self.num_classes = num_classes # 类别数self.conv1 = nn.Conv2d(3, 128, 4, 2, 1) # conv操作self.conv2 = nn.Conv2d(128, 256, 4, 2, 1) # conv操作self.bn2 = nn.BatchNorm2d(256) # bn操作self.conv3 = nn.Conv2d(256, 512, 4, 2, 1) # conv操作self.bn3 = nn.BatchNorm2d(512) # bn操作self.conv4 = nn.Conv2d(512, 1024, 4, 2, 1) # conv操作self.bn4 = nn.BatchNorm2d(1024) # bn操作self.leakyrelu = nn.LeakyReLU(0.2) # leakyrelu激活函数self.linear1 = nn.Linear(int(1024 * (self.img_size[0] / 2 ** 4) * (self.img_size[1] / 2 ** 4)), 1) # linear映射self.linear2 = nn.Linear(int(1024 * (self.img_size[0] / 2 ** 4) * (self.img_size[1] / 2 ** 4)),self.num_classes) # linear映射self.sigmoid = nn.Sigmoid() # sigmoid激活函数self.softmax = nn.Softmax(dim=1) # softmax激活函数self._init_weitghts() # 模型权重初始化def _init_weitghts(self): # 定义模型权重初始化方法for m in self.modules(): # 遍历模型结构if isinstance(m, nn.Conv2d): # 如果当前结构是convnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.BatchNorm2d): # 如果当前结构是bnnn.init.constant_(m.weight, 1) # w设为1nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.Linear): # 如果当前结构是linearnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0def forward(self, x): # 前传函数x = self.conv1(x) # conv,(n,3,64,64)-->(n,128,32,32)x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv2(x) # conv,(n,128,32,32)-->(n,256,16,16)x = self.bn2(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv3(x) # conv,(n,256,16,16)-->(n,512,8,8)x = self.bn3(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv4(x) # conv,(n,512,8,8)-->(n,1024,4,4)x = self.bn4(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = torch.flatten(x, 1) # 三维特征压缩至一位特征向量,(n,1024,4,4)-->(n,1024*4*4)# 根据特征向量x,计算图片真假的得分validity = self.linear1(x) # linear映射,(n,1024*4*4)-->(n,1)validity = self.sigmoid(validity) # sigmoid激活函数,将输出压缩至(0,1)# 根据特征向量x,计算图片分类的标签label = self.linear2(x) # linear映射,(n,1024*4*4)-->(n,2)label = self.softmax(label) # softmax激活函数,将输出压缩至(0,1)return (validity, label) # 返回(图像真假的得分,图片分类的标签)class Generator(nn.Module): # 定义生成器def __init__(self, img_size=(64, 64), num_classes=2, latent_dim=100): # 初始化方法super(Generator, self).__init__() # 继承初始化方法self.img_size = img_size # 图片尺寸,默认为(64.64)三通道图片self.num_classes = num_classes # 类别数self.latent_dim = latent_dim # 输入噪声长度,默认为100self.linear = nn.Linear(self.latent_dim, 4 * 4 * 1024) # linear映射self.bn0 = nn.BatchNorm2d(1024) # bn操作self.deconv1 = nn.ConvTranspose2d(1024, 512, 4, 2, 1) # transconv操作self.bn1 = nn.BatchNorm2d(512) # bn操作self.deconv2 = nn.ConvTranspose2d(512, 256, 4, 2, 1) # transconv操作self.bn2 = nn.BatchNorm2d(256) # bn操作self.deconv3 = nn.ConvTranspose2d(256, 128, 4, 2, 1) # transconv操作self.bn3 = nn.BatchNorm2d(128) # bn操作self.deconv4 = nn.ConvTranspose2d(128, 3, 4, 2, 1) # transconv操作self.relu = nn.ReLU(inplace=True) # relu激活函数self.tanh = nn.Tanh() # tanh激活函数self.embedding = nn.Embedding(self.num_classes, self.latent_dim) # embedding操作self._init_weitghts() # 模型权重初始化def _init_weitghts(self): # 定义模型权重初始化方法for m in self.modules(): # 遍历模型结构if isinstance(m, nn.ConvTranspose2d): # 如果当前结构是transconvnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.BatchNorm2d): # 如果当前结构是bnnn.init.constant_(m.weight, 1) # w设为1nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.Linear): # 如果当前结构是linearnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0def forward(self, input: tuple): # 前传函数noise, label = input # 从输入的元组中获取噪声向量和标签信息label = self.embedding(label) # 标签信息经过embedding操作,变成与噪声向量尺寸相同的稠密向量z = torch.multiply(noise, label) # 噪声向量与标签稠密向量相乘,得到带有标签信息的噪声向量z = self.linear(z) # linear映射,(n,100)-->(n,1024*4*4)z = z.view((-1, 1024, int(self.img_size[0] / 2 ** 4),int(self.img_size[1] / 2 ** 4))) # 一维特征向量扩展至三维特征,(n,1024*4*4)-->(n,1024,4,4)z = self.bn0(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv1(z) # trainsconv操作,(n,1024,4,4)-->(n,512,8,8)z = self.bn1(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv2(z) # trainsconv操作,(n,512,8,8)-->(n,256,16,16)z = self.bn2(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv3(z) # trainsconv操作,(n,256,16,16)-->(n,128,32,32)z = self.bn3(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv4(z) # trainsconv操作,(n,128,32,32)-->(n,3,64,64)z = self.tanh(z) # tanh激活函数,将输出压缩至(-1,1)return z # 返回生成图像
相关文章:
ACGAN
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量;SGAN(Semi-Supervised GAN)通过使判别器/分类器重建标签信息来提高生成数据的质量。既然这两种思路都可以提高生成数据的质…...

模块化CSS
1、什么是模块化CSS 模块化CSS是一种将CSS样式表的规则和样式定义封装到模块或组件级别的方法,以便于更好地管理、维护和组织样式代码。这种方法通过将样式与特定的HTML元素或组件相关联,提供了一种更具可维护性、可复用性和隔离性的方式来处理样式。简单…...

意大利储能公司【Energy Dome】完成1500万欧元融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于意大利米兰的储能公司Energy Dome今日宣布已完成1500万欧元B轮融资。 本轮融资完成后,Energy Dome的融资总额已经达到了5500万欧元,本轮融资的参与者包括阿曼创新发…...

【Java 进阶篇】JDBC Connection详解:连接到数据库的关键
在Java中,要与数据库进行交互,需要使用Java数据库连接(JDBC)。JDBC允许您连接到不同类型的数据库,并执行SQL查询、插入、更新和删除操作。在JDBC中,连接数据库是一个重要的步骤,而Connection对象…...
vue-cli项目打包体积太大,服务器网速也拉胯(100kb/s),客户打开网站需要等十几秒!!! 尝试cdn优化方案
一、首先用插件webpack-bundle-analyzer查看自己各个包的体积 插件用法参考之前博客 vue-cli项目中,使用webpack-bundle-analyzer进行模块分析,查看各个模块的体积,方便后期代码优化 二、发现有几个插件体积较大,有改成CDN引用的…...

【优秀学员统计】python实现-附ChatGPT解析
1.题目 优秀学员统计 知识点排序统计编程基础 时间限制: 1s 空间限制: 256MB 限定语言:不限 题目描述: 公司某部门软件教导团正在组织新员工每日打卡学习活动,他们开展这项学习活动已经一个月了,所以想统计下这个月优秀的打卡员工。每个员工会对应一个id,每天的打卡记录记录…...
餐饮外卖配送小程序商城的作用是什么?
餐饮是支撑市场的主要行业之一,其市场规模很大,从业商家从大到小不计其数,对众商家来说,无论门店大小都希望不断生意增长,但在实际发展中却会面对不少痛点; 餐饮很适合线上经营,无论第三方外卖…...
【QT】使用toBase64方法将.txt文件的明文变为非明文(类似加密)
目录 0.环境 1.背景 2.详细代码 2.1 .h主要代码 2.2 .cpp主要代码,主要实现上述的四个方法 0.环境 windows 11 64位 Qt Creator 4.13.1 1.背景 项目需求:我们项目中有配置文件(类似.txt,但不是这个格式,本文以…...

《QDebug 2023年9月》
一、Qt Widgets 问题交流 1.Qt 程序在 Windows 上以管理员权限运行时无法响应拖放(Drop) 无论是 Widget 还是 QML 程序,以管理员权限运行时,都无法响应拖放操作。可以右键管理员权限打开 Qt Creator,然后丢个文本文件…...

C++使用高斯模糊处理图像
C使用高斯模糊处理图像 cv::GaussianBlur 是 OpenCV 中用于对图像进行高斯模糊处理的函数。高斯模糊是一种常用的图像滤波方法,它可以减少图像中的噪声,并平滑图像以降低细节级别。 void cv::GaussianBlur(const cv::Mat& src, cv::Mat& dst, …...

多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)
多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络) 目录 多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现PSO-BP粒子群优化BP神经网络多变量时间序列预测ÿ…...

LeetCode 283. 移动零
移动零 问题描述 LeetCode 283. 移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意,必须在不复制数组的情况下原地对数组进行操作。 解决思路 为了将所有 0 移动到数组的末尾&#…...

【数据结构】选择排序 堆排序(二)
目录 一,选择排序 1,基本思想 2, 基本思路 3,思路实现 二,堆排序 1,直接选择排序的特性总结: 2,思路实现 3,源代码 最后祝大家国庆快乐! 一…...

opencv实现目标跟踪及视频转存
创建跟踪器 def createTypeTracker(trackerType): 读取视频第一帧,选择跟踪的目标 读第一帧。 ok, frame video.read() 选择边界框 bbox cv2.selectROI(frame, False) 初始化跟踪器 tracker_type ‘MIL’ tracker createTypeTracker(tracker_type) 用第一…...
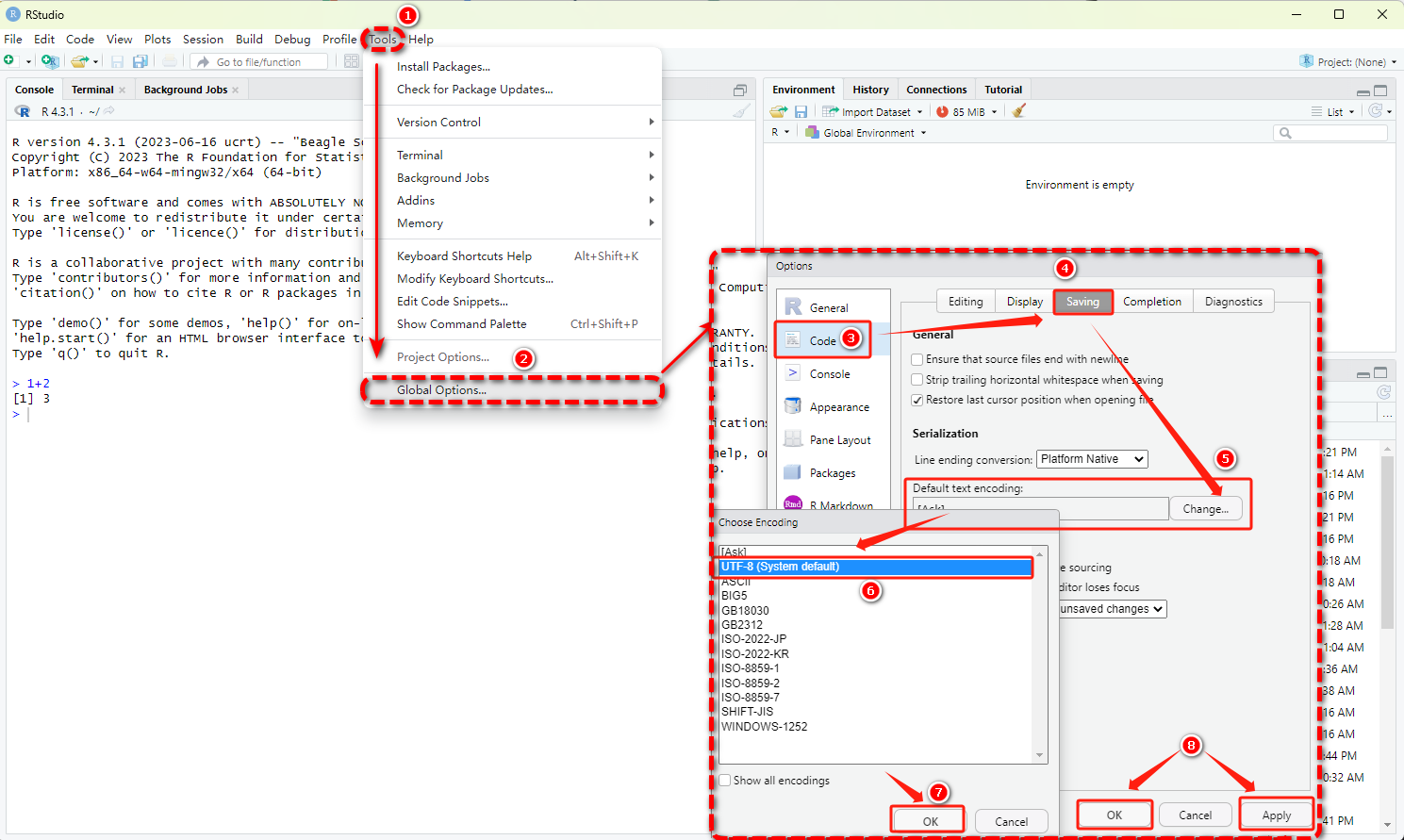
R | R及Rstudio安装、运行环境变量及RStudio配置
R | R及Rstudio安装、运行环境变量及RStudio配置 一、介绍1.1 R介绍1.2 RStudio介绍 二、R安装2.1 演示电脑系统2.2 R下载2.3 R安装2.4 R语言运行环境设置(环境变量)2.4.1 目的2.4.2 R-CMD测试2.4.3 设置环境变量 2.5 R安装测试 三、RStudio安装3.1 RStu…...
智能回答机器人的“智能”体现在哪里?
人工智能的广泛应用已经成为当今社会科技发展的趋势之一。通过人工智能技术,我们可以在不同领域中实现自动化、智能化和高效化,从而大大提升生产和生活效率。智能回答机器人的出现和使用便能很好的证明这一点。今天我们就来探讨一下智能会打机器人的“智…...
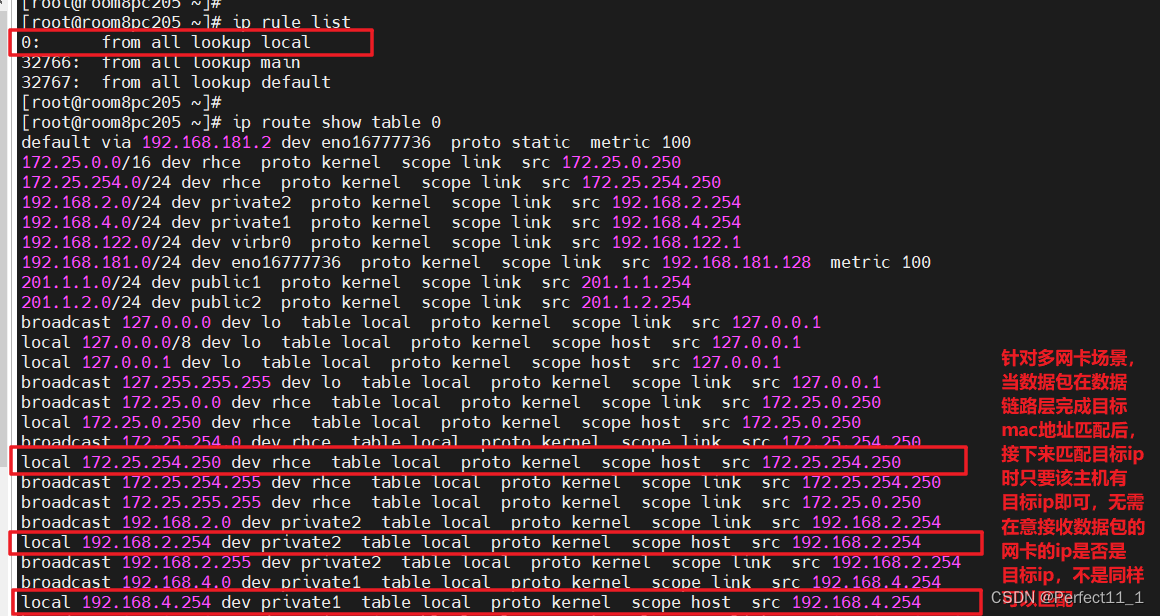
多网卡场景数据包接收时ip匹配规则
多网卡场景数据包接收时ip匹配规则 mac地址匹配规则 接收数据包时数据包中的目的mac地址匹配接收网卡的mac地址后,数据包才会继续被传递到网络层处理 ip地址匹配规则 图1: 参见:https://zhuanlan.zhihu.com/p/529160026?utm_id0 图2&am…...

安防视频平台EasyCVR视频调阅全屏播放显示异常是什么原因?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
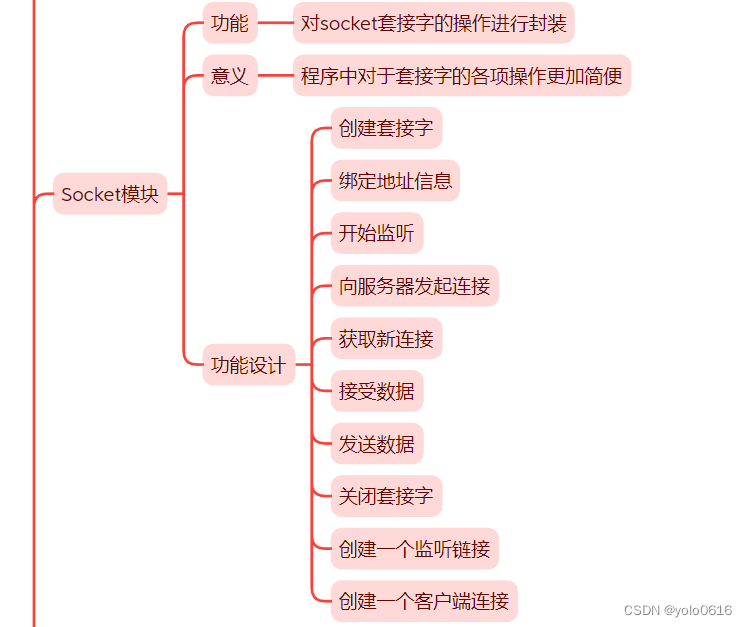
1.5.C++项目:仿muduo库实现并发服务器之socket模块的设计
项目完整版在: 一、socket模块:套接字模块 二、提供的功能 Socket模块是对套接字操作封装的一个模块,主要实现的socket的各项操作。 socket 模块:套接字的功能 创建套接字 绑定地址信息 开始监听 向服务器发起连接 获取新连接 …...

whisper+剪映+chatgpt实现实时语音对话功能
whisper将录音文件转成文字---chatgpt回答---剪映tts将文字转成语言。 GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision whisper剪映chatgpt实现实时语音对话功能_哔哩哔哩_bilibili...

Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化
Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化 【免费下载链接】bpmn-process-designer bpmn-js 工具库 项目地址: https://gitcode.com/gh_mirrors/bp/bpmn-process-designer Bpmn Process Designer是一款基于bpmn-js的强大流程设计器工具…...

通宵降AI率?10款降AI工具亲测:哪个神器一次过,哪个白花钱
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

Open MCT性能压测实战:JMeter定制化四阶测试方法论
1. 为什么Open MCT的性能不能只靠“感觉”来判断?Open MCT——NASA开源的航天器监控与控制平台,这几年在工业SCADA、能源调度、实验室数据可视化等场景里越来越常见。但凡用过它的团队,几乎都经历过这样一个阶段:开发阶段一切丝滑…...

【习题05】求n的阶乘
题目: 分别利用递归和非递归的方法求n的阶乘 1、题目分析 规定:0的阶乘为1。 非递归: 我们先列举几个求阶乘的案例,从中找寻规律。 0! 11! 12! 1 * 23! 1 * 2 * 3 从上述几个例子可…...
)
拒绝C盘爆红!自制 Windows 系统垃圾一键清理工具(精美UI设计)
你的 C盤 又红了吗?相信很多 Windows 用户都经历过被 **“C盘空间不足”** 支配的恐惧。随着日常办公、浏览网页、系统更新,各种临时文件和日志会悄悄吞噬掉我们珍贵的固态硬盘空间。市面上的清理软件鱼龙混杂,要么捆绑软件,要么后…...
超精密反射镜技术壁垒)
0602光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)超精密反射镜技术壁垒
第2小节:超精密反射镜技术壁垒(基底加工镀膜检测,全量化死磕)前置硬核声明EUV整机90%的成像误差、波像差、良率波动,最终全部归因于超精密反射镜的制造壁垒。EUV不是“普通光学抛光”,是原子级表面重构、皮…...

知识竞赛大屏计分方案:让比分一目了然
📺 知识竞赛大屏计分方案:让比分一目了然实时准确 视觉直观 操作简便 打造专业竞赛体验🎯 一、方案核心架构大屏计分方案通常由三部分组成:🖥️ 主控端:操作员电脑,运行计分软件📺…...

AI人工智能行业的现状:为什么说AI从业者的需求越来越大
一、AI产业爆发式增长:需求激增的时代底色2026年,人工智能产业已步入爆发式增长的黄金期,成为驱动全球经济复苏与产业变革的核心引擎。从全球市场来看,2025年AI市场规模达7575.8亿美元,同比增长18.7%,预计2…...

Chrome密码恢复终极指南:如何安全找回所有浏览器保存的密码
Chrome密码恢复终极指南:如何安全找回所有浏览器保存的密码 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经因为忘记某个重要网站的密码而焦虑࿱…...

独立开发者如何利用Taotoken的透明计费规避项目超支风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的透明计费规避项目超支风险 对于独立开发者而言,项目预算的控制是决定项目能否持续、健康…...