<C++> 哈希表模拟实现STL_unordered_set/map
哈希表模板参数的控制
首先需要明确的是,unordered_set是K模型的容器,而unordered_map是KV模型的容器。
要想只用一份哈希表代码同时封装出K模型和KV模型的容器,我们必定要对哈希表的模板参数进行控制。
为了与原哈希表的模板参数进行区分,这里将哈希表的第二个模板参数的名字改为T。
template<class K, class T>
class HashTable
如果上层使用的是unordered_set容器,那么传入哈希表的模板参数就是key和key。
template<class K>
class unordered_set {
public://...
private:HashTable<K, K> _ht;//传入底层哈希表的是K和K
};
但如果上层使用的是unordered_map容器,那么传入哈希表的模板参数就是key以及key和value构成的键值对。
template<class K, class V>
class unordered_map {
public://...
private:HashTable<K, pair<K, V>> _ht;//传入底层哈希表的是K以及K和V构成的键值对
};
也就是说,哈希表中的模板参数T的类型到底是什么,完全却决于上层所使用容器的种类。

而哈希结点的模板参数也应该由原来的K、V变为T:
- 上层容器是unordered_set时,传入的T是键值,哈希结点中存储的就是键值。
- 上层容器是unordered_map时,传入的T是键值对,哈希结点中存储的就是键值对。
更改模板参数后,哈希结点的定义如下:
template<class T>
struct HashNode {HashNode<T> *_next;T _data;HashNode(const T &data): _data(data), _next(nullptr) {}
};
在哈希映射过程中,我们需要获得元素的键值,然后通过哈希函数计算出对应的哈希地址进行映射。
现在由于我们在哈希结点当中存储的数据类型是T,这个T可能就是一个键值,也可能是一个键值对,对于底层的哈希表来说,它并不知道哈希结点当中存储的数据究竟是什么类型,因此需要由上层容器提供一个仿函数,用于获取T类型数据当中的键值。
因此,unordered_map容器需要向底层哈希表提供一个仿函数,该仿函数返回键值对当中的键值。
template<class K, class V>
class unordered_map {
public:struct MapKeyOft {const K &operator()(const pair<K, V> &kv) {return kv.first;}};private:HashTable<K, pair<const K, V>, MapKeyOft> _ht;
};
而虽然unordered_set容器传入哈希表的T就是键值,但是底层哈希表并不知道上层容器的种类,底层哈希表在获取键值时会统一通过传入的仿函数进行获取,因此unordered_set容器也需要向底层哈希表提供一个仿函数。
template<class K>
class unordered_set {
public:struct SetKeyOfT {const K &operator()(const K &key) {return key;}};private:HashTable<K, K, SetKeyOfT> _ht;
};
因此,底层哈希表的模板参数现在需要增加一个,用于接收上层容器提供的仿函数。
template<class K, class T, class KeyOfT>
class HashTable
string类型无法取模问题
经过上面的分析后,我们让哈希表增加了一个模板参数,此时无论上层容器是unordered_set还是unordered_map,我们都能够通过上层容器提供的仿函数获取到元素的键值。
但是在我们日常编写的代码中,用字符串去做键值key是非常常见的事,比如我们用unordered_map容器统计水果出现的次数时,就需要用各个水果的名字作为键值。
而字符串并不是整型,也就意味着字符串不能直接用于计算哈希地址,我们需要通过某种方法将字符串转换成整型后,才能代入哈希函数计算哈希地址。
但遗憾的是,我们无法找到一种能实现字符串和整型之间一对一转换的方法,因为在计算机中,整型的大小是有限的,比如用无符号整型能存储的最大数字是4294967295,而众多字符能构成的字符串的种类却是无限的。
鉴于此,无论我们用什么方法将字符串转换成整型,都会存在哈希冲突,只是产生冲突的概率不同而已。
因此,现在我们需要在哈希表的模板参数中再增加一个仿函数,用于将键值key转换成对应的整型。
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
class HashTable
若是上层没有传入该仿函数,我们则使用默认的仿函数,该默认仿函数直接返回键值key即可,但是用字符串作为键值key是比较常见的,因此我们可以针对string类型写一个类模板的特化
template<class K>
struct HashFunc {size_t operator()(const K &key) {return key;}
};// 特化模板,传string的话,就走这个
template<>
struct HashFunc<string> {size_t operator()(const string &s) {size_t hash = 0;for (auto ch: s) {hash += ch;hash *= 31;}return hash;}
};
哈希表正向迭代器的实现
哈希表的正向迭代器实际上就是对哈希结点指针进行了封装,但是由于在实现++运算符重载时,可能需要在哈希表中去寻找下一个非空哈希桶,因此每一个正向迭代器中都应该存储哈希表的地址。
代码:
//前置声明
template<class K, class T, class KeyOft, class Hash = HashFunc<K>>
class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOft, class Hash>
struct HashIterator {typedef HashNode<T> Node;typedef HashTable<K, T, KeyOft, Hash> HT;//Ref和Ptr可能是T&和T*,也可能是const T&/const T*,需要创建一个支持普通转换为const的迭代器typedef HashIterator<K, T, Ref, Ptr, KeyOft, Hash> Self;typedef HashIterator<K, T, T &, T *, KeyOft, Hash> iterator;//正向迭代器HashIterator(Node *node, HT *ht): _node(node), _ht(ht) {}//正向迭代器实现反向迭代器,不能只靠self,如果self传的就是const迭代器,再加上const就有问题了HashIterator(const iterator &it): _node(it._node), _ht(it._ht) {}Ref operator*() {return _node->_data;}Ptr operator->() {return &_node->_data;}bool operator!=(const Self &s) {return _node != s._node;}bool operator==(const Self &s) {return _node == s._node;}Self &operator++() {if (_node->_next != nullptr) {_node = _node->_next;} else {//找下一个不为空的桶KeyOft kot;Hash hash;// 算出我当前的桶位置size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()) {if (_ht->_tables[hashi] != nullptr) {_node = _ht->_tables[hashi];break;} else {++hashi;}}//没有找到的话,返回_node为空if (hashi == _ht->_tables.size()) {_node = nullptr;}return *this;}return *this;}Node *_node;//迭代器指针HT *_ht; //哈希表,用于定位下一个桶
};
注意: 哈希表的迭代器类型是单向迭代器,没有反向迭代器,即没有实现–运算符的重载,若是想让哈希表支持双向遍历,可以考虑将哈希桶中存储的单链表结构换为双链表结构。
正向迭代器实现后,我们需要在哈希表的实现当中进行如下操作:
- 进行正向迭代器类型的typedef,需要注意的是,为了让外部能够使用typedef后的正向迭代器类型iterator,我们需要在public区域进行typedef。
- 由于正向迭代器中++运算符重载函数在寻找下一个结点时,会访问哈希表中的成员变量_table,而_table成员变量是哈希表的私有成员,因此我们需要将正向迭代器类声明为哈希表类的友元。
- 将哈希表中查找函数返回的结点指针,改为返回由结点指针和哈希表地址构成的正向迭代器。
- 将哈希表中插入函数的返回值类型,改为由正向迭代器类型和布尔类型所构成的键值对。
完整的HashTable
#pragma once
#include <cstdlib>
#include <ctime>
#include <iostream>
#include <utility>
#include <vector>
using namespace std;template<class K>
struct HashFunc {size_t operator()(const K &key) {return key;}
};// 特化模板,传string的话,就走这个
template<>
struct HashFunc<string> {size_t operator()(const string &s) {size_t hash = 0;for (auto ch: s) {hash += ch;hash *= 31;}return hash;}
};template<class T>
struct HashNode {HashNode<T> *_next;T _data;HashNode(const T &data): _data(data), _next(nullptr) {}
};//前置声明
template<class K, class T, class KeyOft, class Hash = HashFunc<K>>
class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOft, class Hash>
struct HashIterator {typedef HashNode<T> Node;typedef HashTable<K, T, KeyOft, Hash> HT;//Ref和Ptr可能是T&和T*,也可能是const T&/const T*,需要创建一个支持普通转换为const的迭代器typedef HashIterator<K, T, Ref, Ptr, KeyOft, Hash> Self;typedef HashIterator<K, T, T &, T *, KeyOft, Hash> iterator;//正向迭代器HashIterator(Node *node, HT *ht): _node(node), _ht(ht) {}//正向迭代器实现反向迭代器,不能只靠self,如果self传的就是const迭代器,再加上const就有问题了HashIterator(const iterator &it): _node(it._node), _ht(it._ht) {}Ref operator*() {return _node->_data;}Ptr operator->() {return &_node->_data;}bool operator!=(const Self &s) {return _node != s._node;}bool operator==(const Self &s) {return _node == s._node;}Self &operator++() {if (_node->_next != nullptr) {_node = _node->_next;} else {//找下一个不为空的桶KeyOft kot;Hash hash;// 算出我当前的桶位置size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()) {if (_ht->_tables[hashi] != nullptr) {_node = _ht->_tables[hashi];break;} else {++hashi;}}//没有找到的话,返回_node为空if (hashi == _ht->_tables.size()) {_node = nullptr;}return *this;}return *this;}Node *_node;//迭代器指针HT *_ht; //哈希表,用于定位下一个桶
};template<class K, class T, class KeyOft, class Hash>// Hash用于将key转换成可以取模的类型
class HashTable {
public:typedef HashNode<T> Node;typedef HashIterator<K, T, T &, T *, KeyOft, Hash> iterator;typedef HashIterator<K, T, const T &, const T *, KeyOft, Hash> const_iterator;template<class K1, class T1, class Ref1, class Ptr1, class KeyOft1, class Hash1>friend struct HashIterator;//用于迭代器访问HashTable中的private成员变量,即_tables、public:~HashTable() {for (auto &cur: this->_tables) {while (cur) {Node *next = cur->_next;delete cur;cur = next;}cur = nullptr;}}iterator begin() {Node *cur = nullptr;for (size_t i = 0; i < _tables.size(); i++) {cur = _tables[i];if (cur != nullptr) {break;}}return iterator(cur, this);}iterator end() {return iterator(nullptr, this);}const_iterator begin() const {Node *cur = nullptr;for (size_t i = 0; i < _tables.size(); i++) {cur = _tables[i];if (cur != nullptr) {break;}}return const_iterator(cur, this);}const_iterator end() const {return const_iterator(nullptr, this);}//查找Key也是K类型iterator Find(const K &key) {if (this->_tables.size() == 0) {return iterator(nullptr, this);}KeyOft kot;//模板参数,用来区分是kv,还是v由上层map、set传模板参数过来(通过仿函数实现)Hash hash;size_t hashi = hash(key) % this->_tables.size();Node *cur = this->_tables[hashi];while (cur) {if (kot(cur->_data) == key) {return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}//删除的值key为K类型bool Erase(const K &key) {Hash hash;KeyOft kot;size_t hashi = hash(key) % this->_tables.size();Node *prev = nullptr;Node *cur = this->_tables[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {this->_tables[hashi] = cur->_next;} else {prev->_next = cur->_next;}delete cur;return true;} else {prev = cur;cur = cur->_next;}}return false;}// 扩容优化,使用素数扩容size_t GetNextPrime(size_t prime) {// SGIstatic const int _stl_num_primes = 28;static const uint64_t _stl_prime_list[_stl_num_primes] = {53, 97, 193, 389, 769, 1543,3079, 6151, 12289, 24593, 49157, 98317,196613, 393241, 786433, 1572869, 3145739, 6291469,12582917, 25165843, 50331653, 100663319, 201326611, 402653189,805306457, 1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < _stl_num_primes; ++i) {if (_stl_prime_list[i] > prime)return _stl_prime_list[i];}return _stl_prime_list[_stl_num_primes - 1];}//插入的类型是T类型,可能是K可能是pair<K,V> 通过模板参数传过来pair<iterator, bool> Insert(const T &data) {Hash hash;// 仿函数用于不能取模的值KeyOft kot;// 已经有这个数,就不用插入了iterator it = Find(kot(data));//如果it不是end(),说明找到了数,就不用插入,返回迭代器和falseif (it != end()) {return make_pair(it, false);}// 负载因子 == 1时扩容if (this->n == this->_tables.size()) {// size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newsize = this->GetNextPrime(_tables.size());vector<Node *> newtables(newsize, nullptr);for (auto &cur: this->_tables) {// cur是Node*while (cur) {// 保存下一个Node *next = cur->_next;// 头插到新表size_t hashi = hash(kot(cur->_data)) % newtables.size();cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}}_tables.swap(newtables);}size_t hashi = hash(kot(data)) % this->_tables.size();// 头插Node *newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;this->n++;//插入成功返回,通过newnode,和this构造迭代器,返回true。return make_pair(iterator(newnode, this), true);}// 获取哈希表索引最大长度(哈希桶长度)size_t MaxBucketSize() {size_t max = 0;for (int i = 0; i < _tables.size(); ++i) {auto cur = _tables[i];size_t size = 0;while (cur) {++size;cur = cur->_next;}printf("[%d]->%d\n", i, size);if (size > max) {max = size;}if (max == 5121) {printf("%d", i);break;}}return max;}private:vector<Node *> _tables;size_t n = 0;// 存储有效数据的个数
};
封装unordered_set的代码
#pragma once
#include "HashTable.h"template<class K, class Hash = HashFunc<K>>
class unordered_set {
public:struct SetKeyOfT {const K &operator()(const K &key) {return key;}};public:typedef typename HashTable<K, K, SetKeyOfT, Hash>::const_iterator iterator;typedef typename HashTable<K, K, SetKeyOfT, Hash>::const_iterator const_iterator;iterator begin() {return _ht.begin();}iterator end() {return _ht.end();}const_iterator begin() const {return _ht.begin();}const_iterator end() const {return _ht.end();}//这里的pair<iterator,bool>中的iterator是const类型的,而Insert返回的是普通迭代器pair<iterator, bool> insert(const K &key) {return _ht.Insert(key);}iterator find(const K &key) {return _ht.Find(key);}bool erase(const K &key) {return _ht.Erase(key);}private:HashTable<K, K, SetKeyOfT, Hash> _ht;
};
封装unordered_map的代码
#pragma once#include "HashTable.h"
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map {
public:struct MapKeyOft {const K &operator()(const pair<K, V> &kv) {return kv.first;}};//typename 告诉编译器引入的是一个类型,而不是成员typedef typename HashTable<K, pair<const K, V>, MapKeyOft, Hash>::iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapKeyOft, Hash>::const_iterator const_iterator;iterator begin() {return _ht.begin();}iterator end() {return _ht.end();}const_iterator begin() const {return _ht.begin();}const_iterator end() const {return _ht.end();}pair<iterator, bool> insert(const pair<K, V> kv) {return _ht.Insert(kv);}V &operator[](const K &key) {pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.first->second;}iterator find(const K &key) {return _ht.Find(key);}bool erase(const K &key) {return _ht.Erase(key);}private:HashTable<K, pair<const K, V>, MapKeyOft, Hash> _ht;
};
测试
#include "unordered_map.h"
#include "unordered_set.h"
#include <iostream>
class Date {friend struct HashDate;public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day) {}bool operator<(const Date &d) const {return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date &d) const {return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}bool operator==(const Date &d) const {return _year == d._year && _month == d._month && _day == d._day;}friend ostream &operator<<(ostream &_cout, const Date &d);private:int _year;int _month;int _day;
};ostream &operator<<(ostream &_cout, const Date &d) {_cout << d._year << "-" << d._month << "-" << d._day;return _cout;
}//自定义Hash,模板最后一个参数,传自定义类型的话,需要自己写
struct HashDate {size_t operator()(const Date &d) {size_t hash = 0;hash += d._year;hash *= 31;hash += d._month;hash *= 31;hash += d._day;hash *= 31;return hash;}
};struct unordered_map_Test {static void unordered_map_Test1() {unordered_map<int, int> mp;mp.insert(make_pair(1, 1));mp.insert(make_pair(2, 2));mp.insert(make_pair(3, 3));unordered_map<int, int>::iterator it = mp.begin();while (it != mp.end()) {cout << it->first << " " << it->second << endl;++it;}cout << endl;}static void unordered_map_Test2() {string arr[] = {"西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉", "梨"};unordered_map<string, int> countMap;for (auto &e: arr) {countMap[e]++;}for (auto &kv: countMap) {cout << kv.first << "" << kv.second << endl;}}static void unordered_map_Test3() {Date d1(2023, 3, 13);Date d2(2023, 3, 13);Date d3(2023, 3, 12);Date d4(2023, 3, 11);Date d5(2023, 3, 12);Date d6(2023, 3, 13);Date a[] = {d1, d2, d3, d4, d5, d6};unordered_map<Date, int, HashDate> countMap;for (auto e: a) {countMap[e]++;}for (auto &kv: countMap) {cout << kv.first << ":" << kv.second << endl;}}
};struct unordered_set_Test {static void unordered_set_Test1() {unordered_set<int> s;s.insert(1);s.insert(3);s.insert(2);s.insert(7);s.insert(8);unordered_set<int>::iterator it = s.begin();while (it != s.end()) {cout << *it << " ";//(*it) = 1;++it;}cout << endl;}
};int main() {unordered_set_Test::unordered_set_Test1();unordered_map_Test::unordered_map_Test1();unordered_map_Test::unordered_map_Test2();unordered_map_Test::unordered_map_Test3();return 0;
}
相关文章:
<C++> 哈希表模拟实现STL_unordered_set/map
哈希表模板参数的控制 首先需要明确的是,unordered_set是K模型的容器,而unordered_map是KV模型的容器。 要想只用一份哈希表代码同时封装出K模型和KV模型的容器,我们必定要对哈希表的模板参数进行控制。 为了与原哈希表的模板参数进行区分…...

【数据结构与算法】通过双向链表和HashMap实现LRU缓存 详解
这个双向链表采用的是有伪头节点和伪尾节点的 与上一篇文章中单链表的实现不同,区别于在实例化这个链表时就初始化了的伪头节点和伪尾节点,并相互指向,在第一次添加节点时,不需要再考虑空指针指向问题了。 /*** 通过链表与HashMa…...
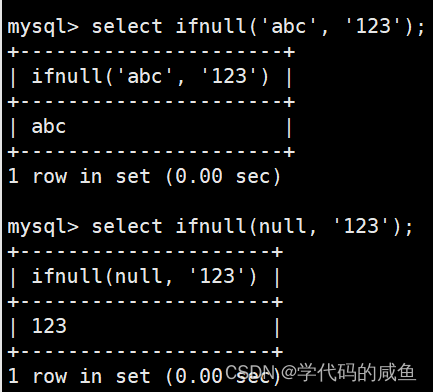
MySQL的内置函数
文章目录 1. 聚合函数2. group by子句的使用3. 日期函数4. 字符串函5. 数学函数6. 其它函数 1. 聚合函数 COUNT([DISTINCT] expr) 返回查询到的数据的数量 用SELECT COUNT(*) FROM students或者SELECT COUNT(1) FROM students也能查询总个数。 统计本次考试的数学成绩分数去…...

数据结构与算法-(7)---栈的应用-(3)表达式转换
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
)
Lilliefors正态性检验(一种非参数统计方法)
Lilliefors检验(也称为Kolmogorov-Smirnov-Lilliefors检验)是一种用于检验数据是否符合正态分布的统计检验方法,它是Kolmogorov-Smirnov检验的一种变体,专门用于小样本情况。与K-S检验不同,Lilliefors检验不需要假定数…...
)
【云原生】配置Kubernetes CronJob自动备份MySQL数据库(单机版)
文章目录 每天自动备份数据库MySQL【云原生】配置Kubernetes CronJob自动备份Clickhouse数据库 每天自动备份数据库 MySQL 引用镜像:databack/mysql-backup,使用文档:https://hub.docker.com/r/databack/mysql-backup 测试、开发环境:每天0点40分执行全库备份操作,备份文…...
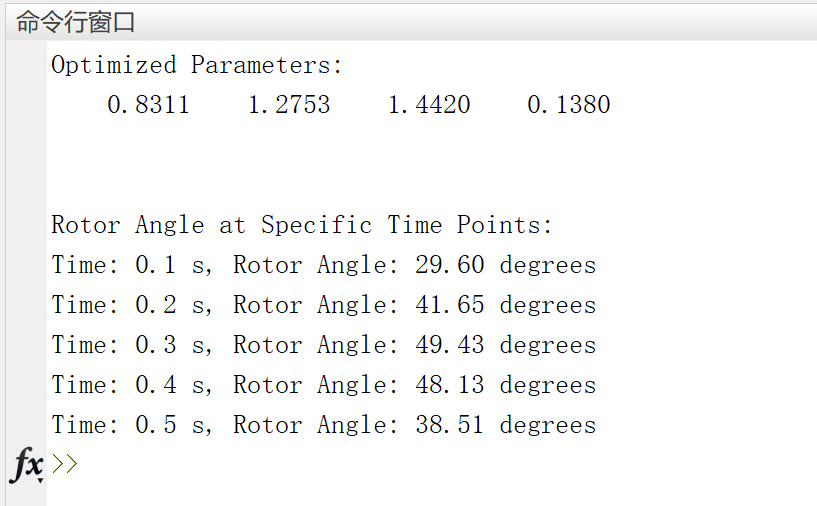
基于PSO算法的功率角摆动曲线优化研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
数论知识点总结(一)
文章目录 目录 文章目录 前言 一、数论有哪些 二、题法混讲 1.素数判断,质数,筛法 2.最大公约数和最小公倍数 3.快速幂 4.约数 前言 现在针对CSP-J/S组的第一题主要都是数论,换句话说,持数论之剑,可行天下矣! 一、数论有哪些 数论 原根,素数判断,质数,筛法最大公约数…...

知识分享 钡铼网关功能介绍:使用SSLTLS 加密,保证MQTT通信安全
背景 为了使不同的设备或系统能够相互通信,让旧有系统和新的系统可以集成,通信更加灵活和可靠。以及将数据从不同的来源收集并传输到不同的目的地,实现数据的集中管理和分发。 通信网关完美克服了这一难题,485或者网口的设备能通过…...

asp.net core mvc区域路由
ASP.NET Core 区域路由(Area Routing)是一种将应用程序中的路由划分为多个区域的方式,类似于 MVC 的控制器和视图的区域划分。区域路由可以帮助开发人员更好地组织应用程序的代码和路由,并使其更易于维护。 要使用区域路由&#…...
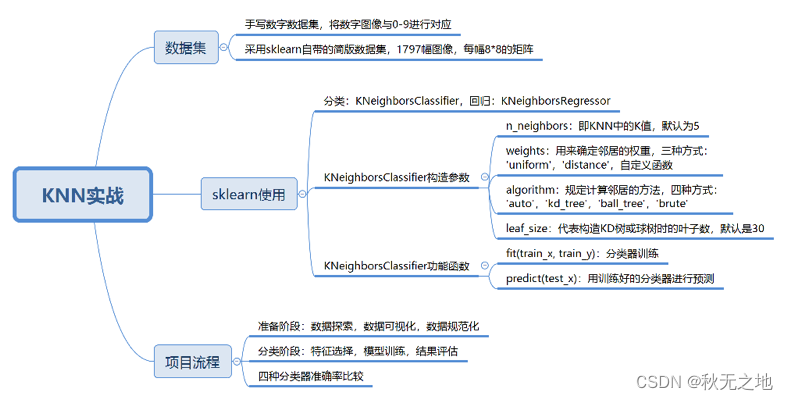
KNN(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

Servlet开发-session和cookie理解案例-登录页面
项目展示 进入登录页面,输入正确的用户名和密码以后会自动跳到主页 登录成功以后打印用户名以及上次登录的时间,如果浏览器和客户端都保存有上次登录的信息,则不需要登录就可以进入主页 编码思路 1.首先提供一个登录的前端页面&…...
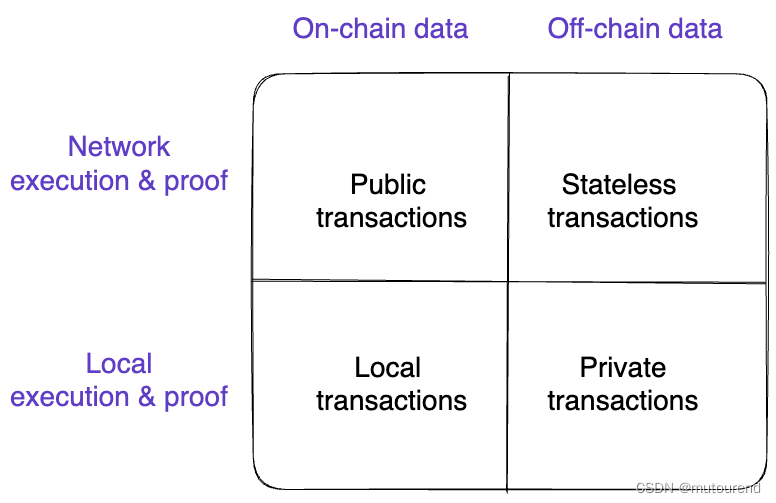
Polygon Miden:扩展以太坊功能集的ZK-optimized rollup
1. 引言 Polygon Miden定位为zkVM,定于2023年Q4上公开测试网。 zk、zkVM、zkEVM及其未来中指出,当前主要有3种类型的zkVM,括号内为其相应的指令集: mainstream(WASM, RISC-V)EVM(EVM bytecod…...

[题]宝物筛选 #单调队列优化
五、宝物筛选(洛谷P1776) 题目链接 好家伙,找到了一个之前学习多重背包优化时的错误…… 之前记的笔记还是很有用的…… #include<bits/stdc.h> using namespace std; const int N 1e5 10; int f[N]; int n, m; int v, w, s; int l…...

.NET的键盘Hook管理类,用于禁用键盘输入和切换
一、MyHook帮助类 此类需要编写指定屏蔽的按键,灵活性差。 using System; using System.Runtime.InteropServices; using System.Diagnostics; using System.Windows.Forms; using Microsoft.Win32;namespace MyHookClass {/// <summary>/// 类一/// </su…...

Anaconda Jupyter
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言An…...
Unity中Shader的前向渲染路径ForwardRenderingPath
文章目录 前言一、前向渲染路径的特点二、渲染方式1、逐像素(效果最好)2、逐顶点(效果次之)3、SH球谐(效果最差) 三、Unity中对灯光设置 后,自动选择对应的渲染方式1、ForwardBase仅用于一个逐像素的平行灯,以及所有的逐顶点与SH2、ForwardAdd用于其他所…...

简历项目优化关键方法论-START
START方法论是非常著名的面试法则,经常被面试官使用的工具 Situation:情况、事情、项目需求是在什么情况下发生Task:任务,你负责的做的是什么Action:动作,针对这样的情况分析,你采用了什么行动方式Result:结果,在这样…...
TensorFlow学习1:使用官方模型进行图片分类
前言 人工智能以后会越来越发达,趁着现在简单学习一下。机器学习框架有很多,这里觉得学习谷歌的 TensorFlow,谷歌的技术还是很有保证的,另外TensorFlow 的中文文档真的很友好。 文档: https://tensorflow.google.cn/…...
C++ 并发编程实战 第八章 设计并发代码 一
目录 8.1 在线程间切分任务 8.1.1 先在线程间切分数据,再开始处理 8.1.2 以递归方式划分数据 8.1.3 依据工作类别划分任务 借多线程分离关注点需防范两大风险 在线程间按流程划分任务 8.2 影响并发性能的因素 8.2.1 处理器的数量 8.2.2 数据竞争和缓存兵乓…...

Go语言屏幕自动化工具Rizzler:基于计算机视觉的RPA实践指南
1. 项目概述:一个能“读懂”你屏幕的智能助手最近在折腾一个挺有意思的开源项目,叫ghuntley/rizzler。乍一看这个名字,可能有点摸不着头脑,但如果你对自动化、RPA(机器人流程自动化)或者屏幕交互脚本感兴趣…...

Cursor SDD Starter:AI驱动开发工作流工程化实践指南
1. 项目概述:一个为工程团队设计的AI驱动开发工作流启动器 如果你和你的团队正在使用Cursor IDE,并且希望将AI辅助开发从一个偶尔使用的“代码补全工具”,升级为一套可预测、可复现、能真正融入团队协作流程的“工程化工作流”,那…...

从Excel到BI Launchpad:SAP BW/4HANA数据分析实战,手把手教你用BO做报表
从Excel到BI Launchpad:SAP BW/4HANA数据分析实战指南 1. 企业级数据分析的进化之路 在当今数据驱动的商业环境中,企业数据分析正经历着从静态报表到动态洞察的革命性转变。传统Excel虽然灵活易用,但在处理海量数据、实现实时协作和构建企业级…...

LynxPrompt Action:GitHub Actions 实现 AI 配置中心化与自动化管理
1. 项目概述:为什么我们需要一个AI配置的“中央仓库”? 如果你和我一样,日常开发中同时用着Cursor、Claude Code、GitHub Copilot,甚至还在尝试Windsurf和Aider,那你一定遇到过这个头疼的问题:每个工具的配…...

Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案 当Perplexity在Stack Overflow数据源上出现平均响应延迟 > 8s 的告警时&am…...

InjectFix实战解析:在Unity IL2CPP环境下实现C#热修复的权衡与策略
1. InjectFix在IL2CPP环境下的核心价值 当你的Unity手游在应用商店上线后突然出现致命Bug,传统解决方案往往需要重新打包、提交审核、等待上架,这个过程可能耗时数天。而InjectFix提供的C#热修复能力,可以在不更新客户端的情况下快速修复线上…...

数据库测试的盲区:用AI生成边界值,发现隐藏的数据异常
在软件测试领域,数据库层的质量保障常常陷入一种“平静的假象”——核心CRUD操作通过、索引命中率达标、慢查询被优化,一切看似井然有序。然而线上事故统计却揭示了一个残酷的事实:超过七成的数据库相关故障并非源于架构缺陷或性能瓶颈&#…...

别再到处找DEM了!手把手教你用ArcGIS Pro + Python脚本,从NASA官网免费下载并拼接出完整的中国90米高程数据
从NASA获取中国90米高程数据的自动化解决方案 在GIS和遥感研究领域,获取高质量的数字高程模型(DEM)数据是许多项目的基础工作。然而,对于中国区域的完整覆盖、高精度且免费可用的DEM数据,研究者们常常面临获取困难。本文将介绍如何利用ArcGI…...

基于MCP协议实现AI助手个性化:Terminal Buddies项目实战解析
1. 项目概述:当你的终端伙伴遇见AI助手 如果你和我一样,每天有大量时间泡在终端和代码编辑器里,那么一个能带来些许乐趣和陪伴感的“数字伙伴”或许能点亮枯燥的编码时光。Terminal Buddies 正是这样一个巧妙结合了复古 ASCII 艺术、轻量级游…...

2026届毕业生推荐的降重复率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下AIGC产业落地的进程里面,冗余算力的消耗,以及无效生成输出所导…...