24Hibench
1. Hibench
官网
HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCount, TeraSort, Repartition, Sleep, SQL, PageRank, Nutch indexing, Bayes, Kmeans, NWeight and enhanced DFSIO, etc. It also contains several streaming workloads for Spark Streaming, Flink, Storm and Gearpump.
1.1 workloads
There are totally 29 workloads in HiBench. The workloads are divided into 6 categories which are micro, ml(machine learning), sql, graph, websearch and streaming.
1.2 install maven
首先需要安装maven,并配好环境安装教程
mkdir repo
cd conf
vim settings.xml
修改仓库地址
<localRepository>/opt/module/maven/apache-maven-3.8.6/repo</localRepository>
阿里云镜像文件中已经有了,注释掉其他mirror
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>
1.3 bulid
下载zip文件,上传解压后的文件 不要使用7.11 会出现版本问题
参照文档中的,构建HiBench项目,我使用的是全部安装:
#ALL
mvn -Dspark=3.1 -Dscala=2.12 clean package
#SPARK
mvn -Psparkbench -Dspark=3.1 -Dscala=2.12 clean package
如果出现以下错误:
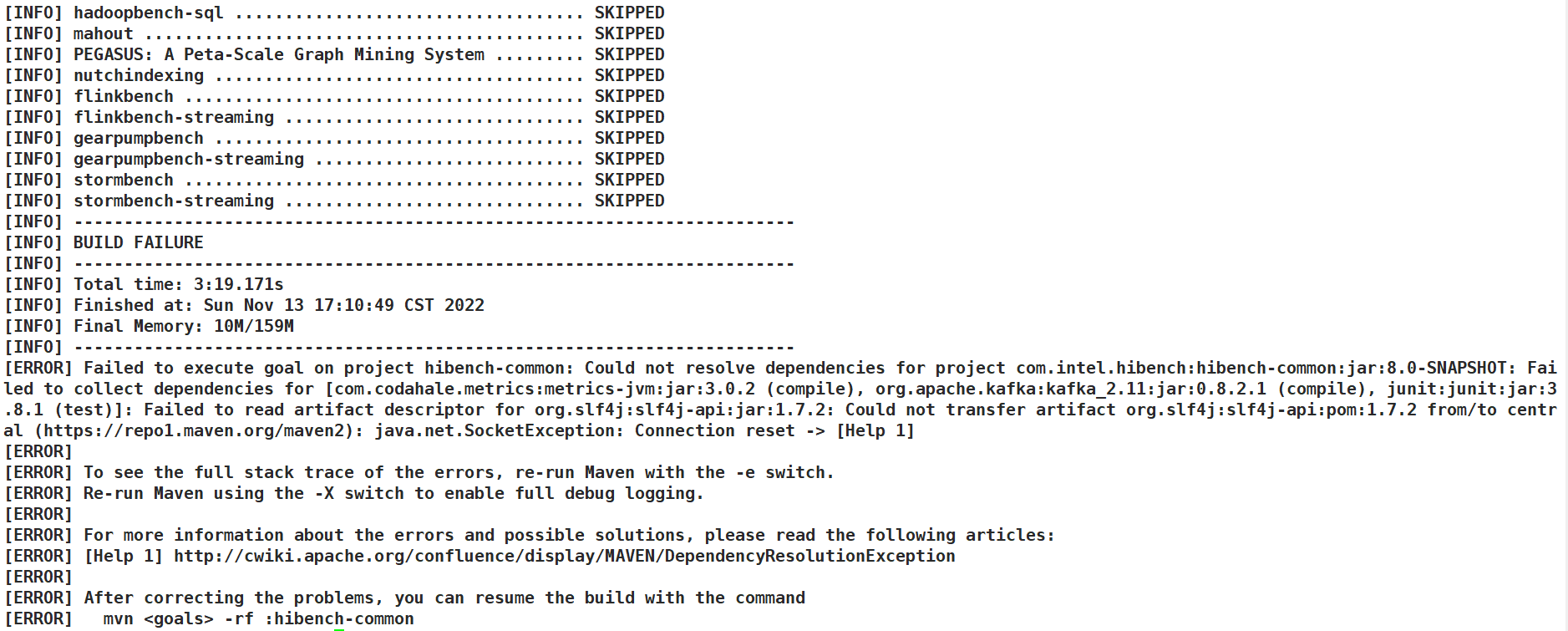
原因是maven没有安装好,没有设置好镜像以及安装仓库,详情见安装教程
build成功
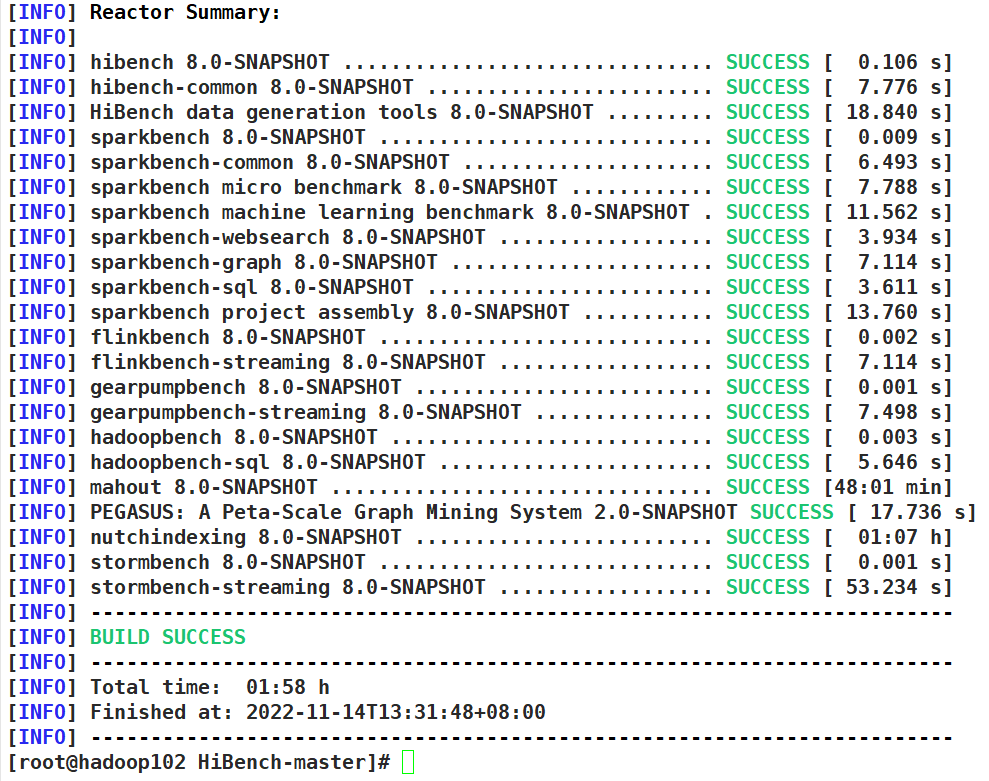
第二次
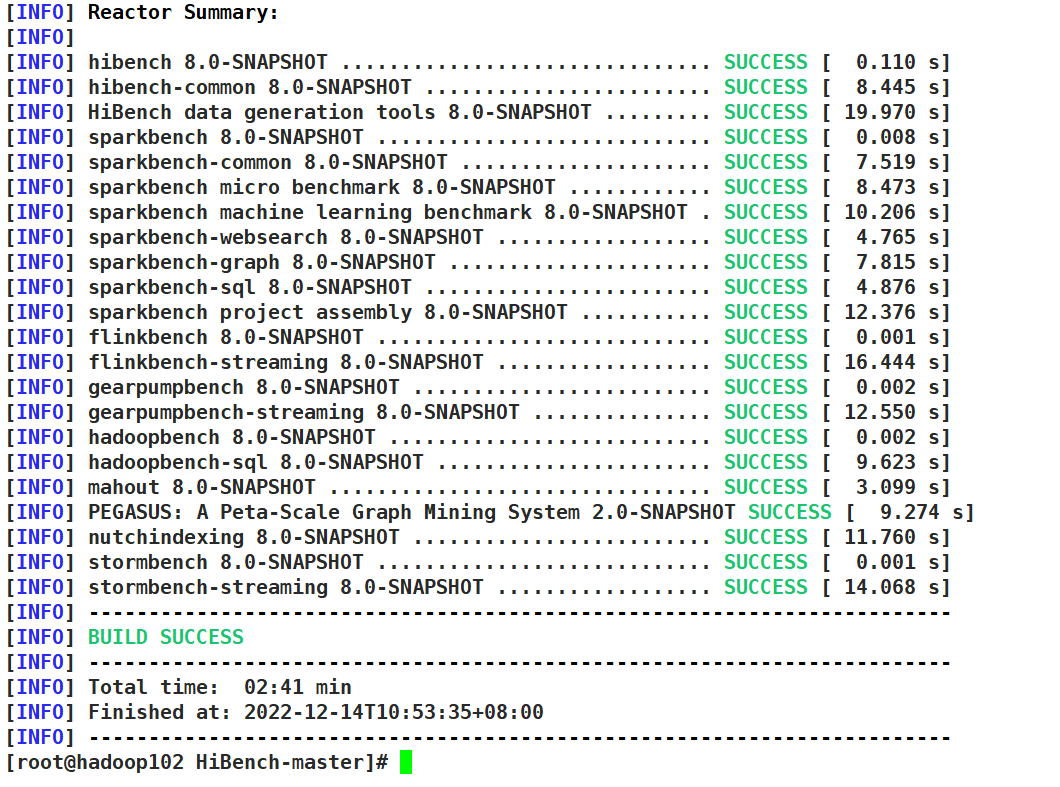
1.4 configure
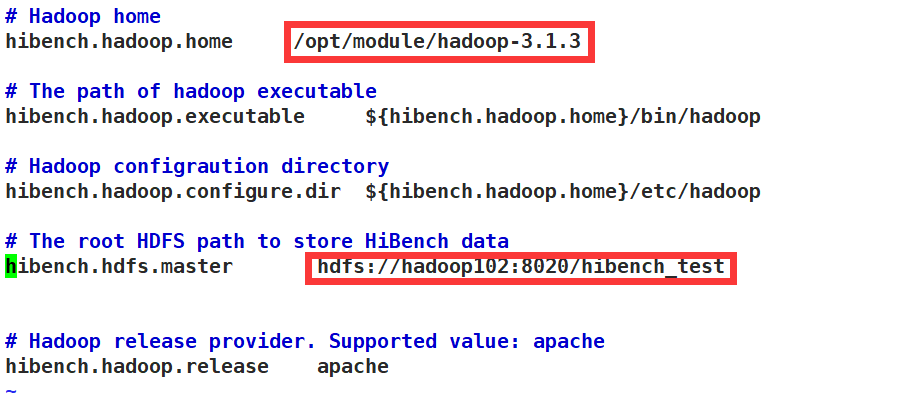
hadoop.conf
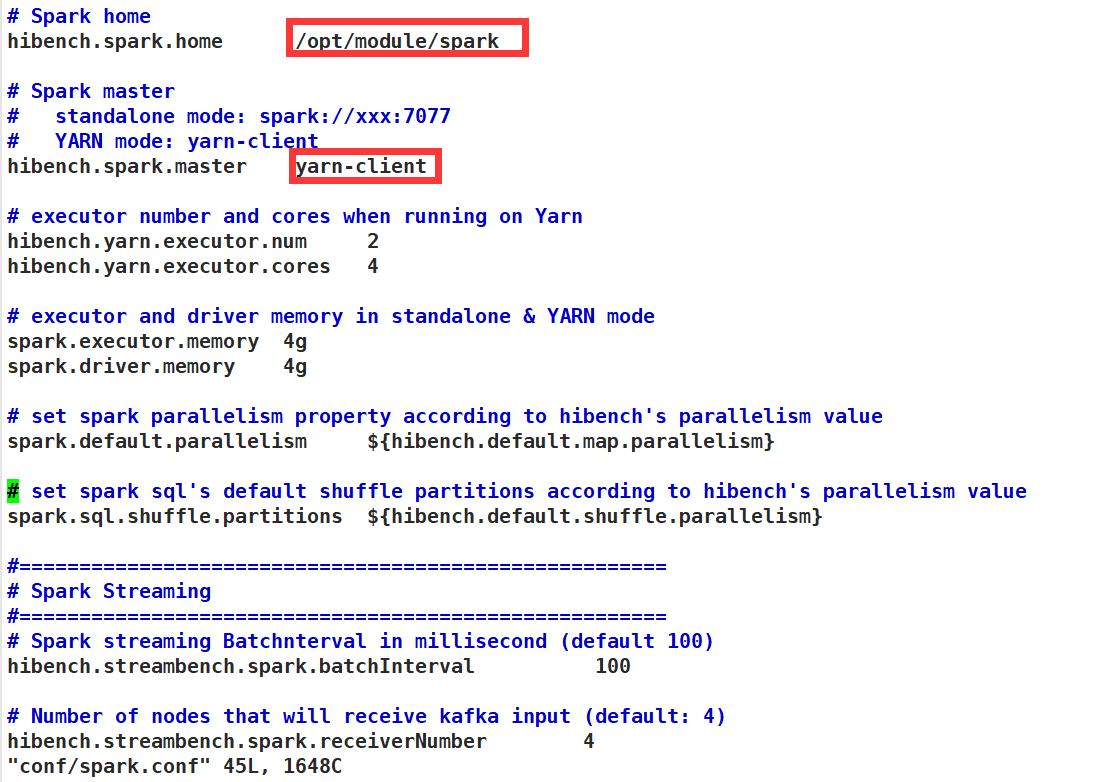
spark.conf
Input data size

if you chose a real large data size ,you may find the errors:
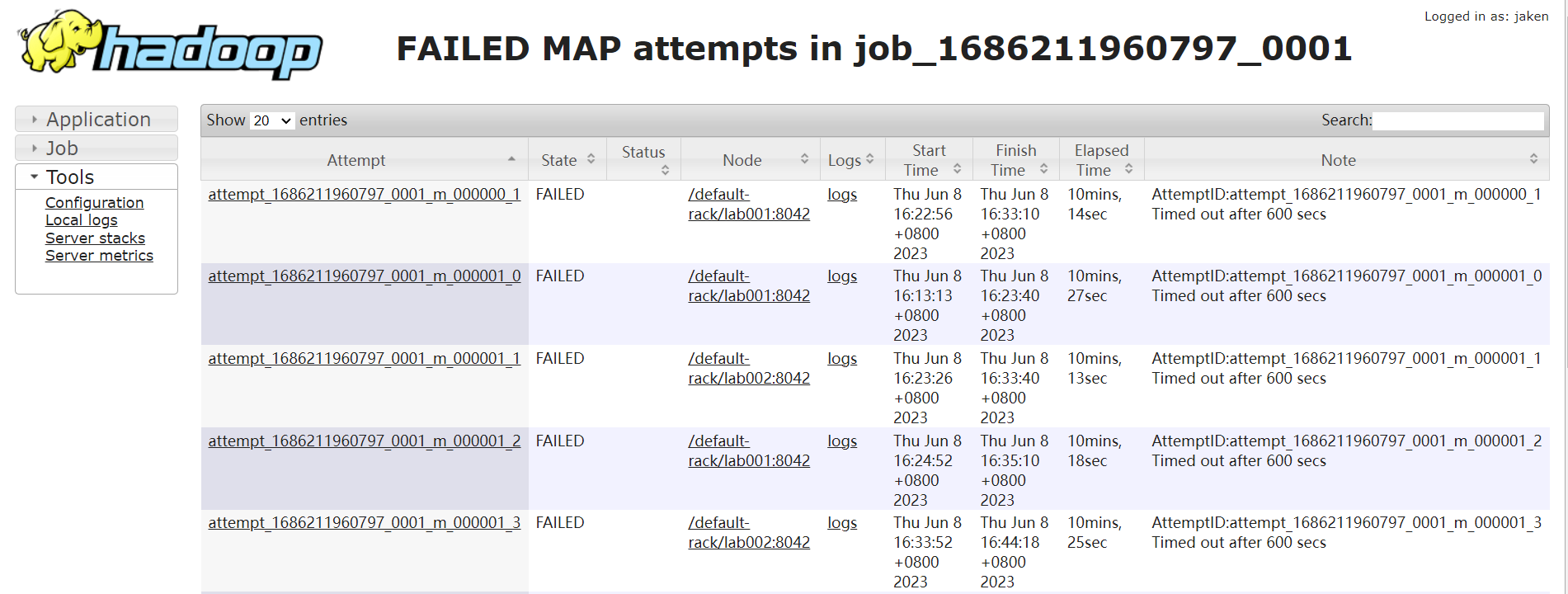

you need to modify the mapred-site.xml, and add the context:
<property><name>mapred.task.timeout</name><value>800000</value><final>true</final>
</property>
cluster mode
vim /opt/module/hibench/HiBench-master/HiBench-master/bin/functions/workload_functions.sh# 修改run_spark_job 方法

1.5 hadoop example
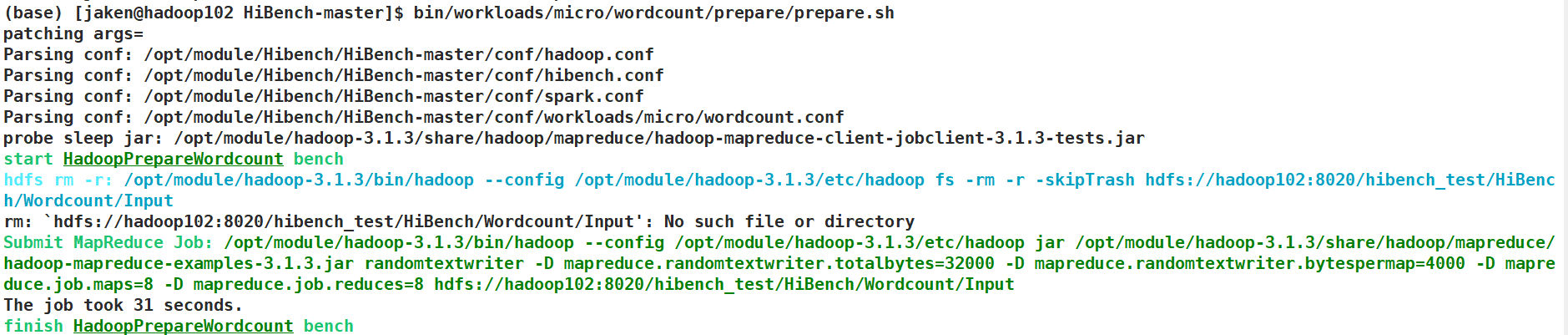
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/hadoop/run.sh
官网地址
运行成功
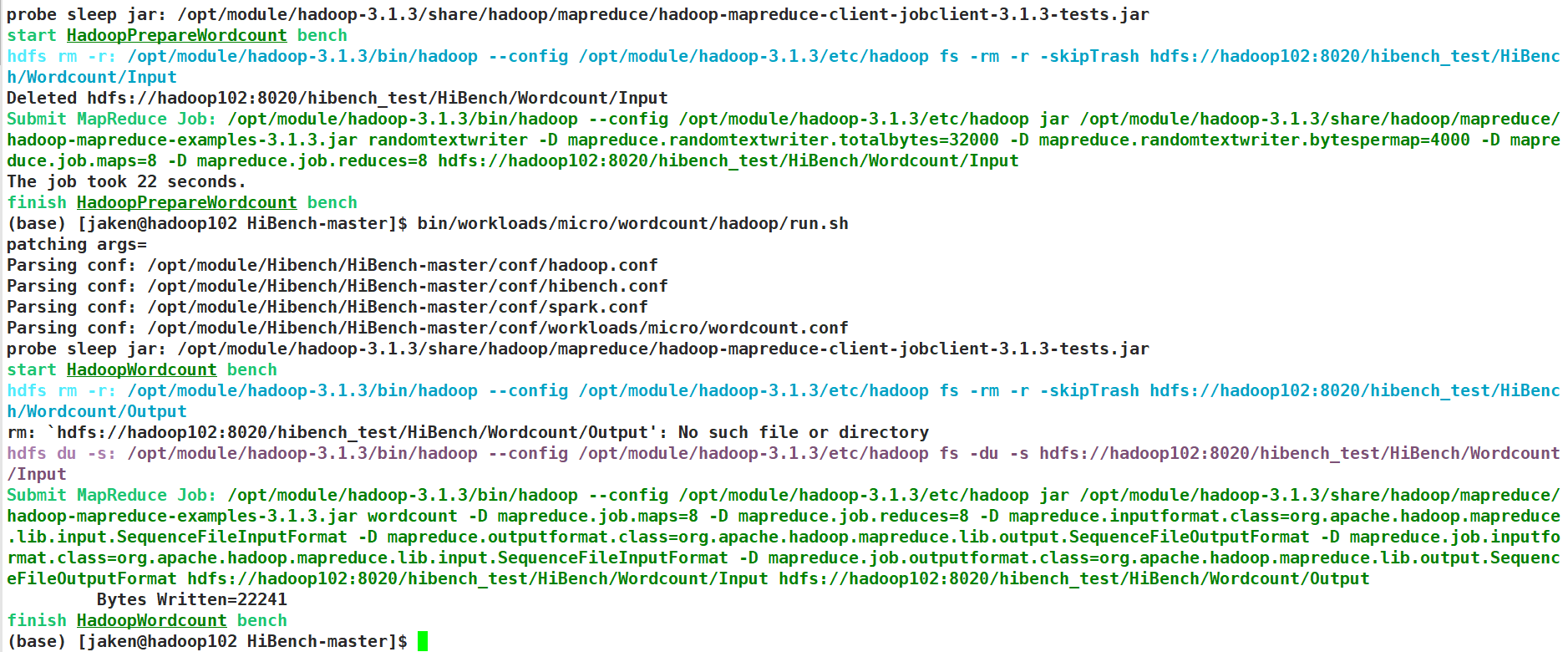

更详细的介绍
/opt/module/Hibench/HiBench-master/report/wordcount/hadoop
1.6 spark example
准备输入数据
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/prepare/prepare.sh
控制台输出
yarn
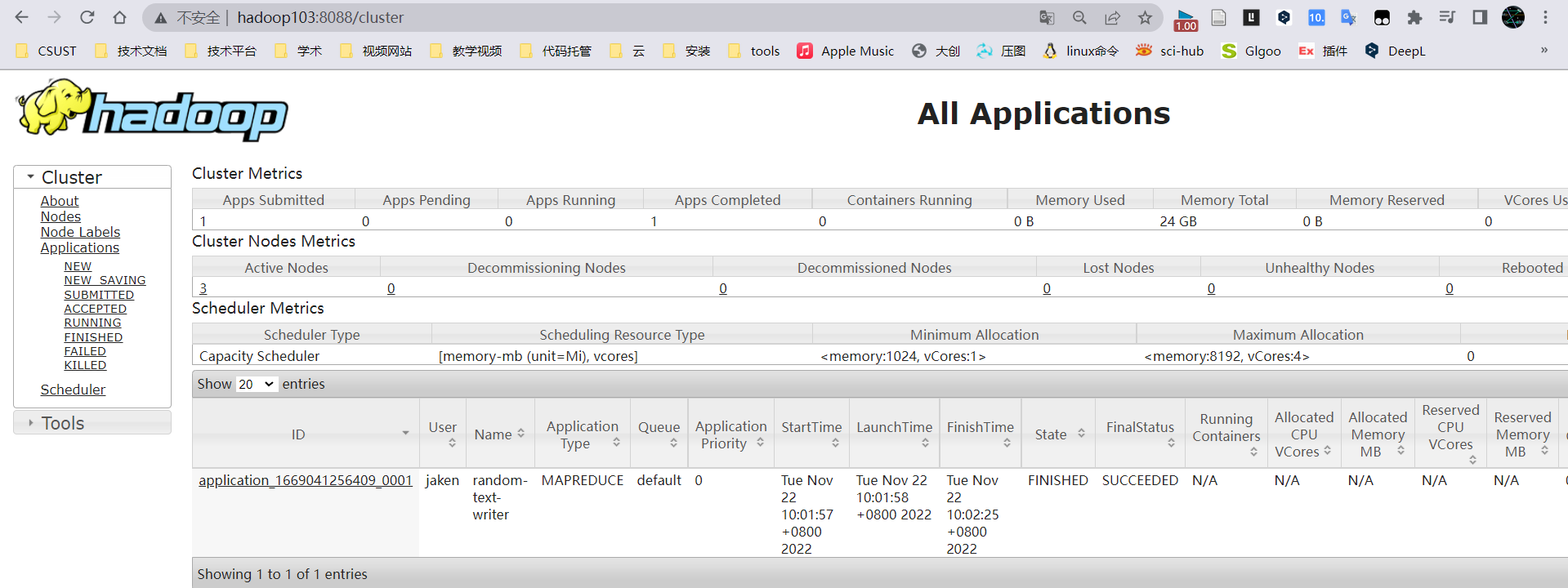
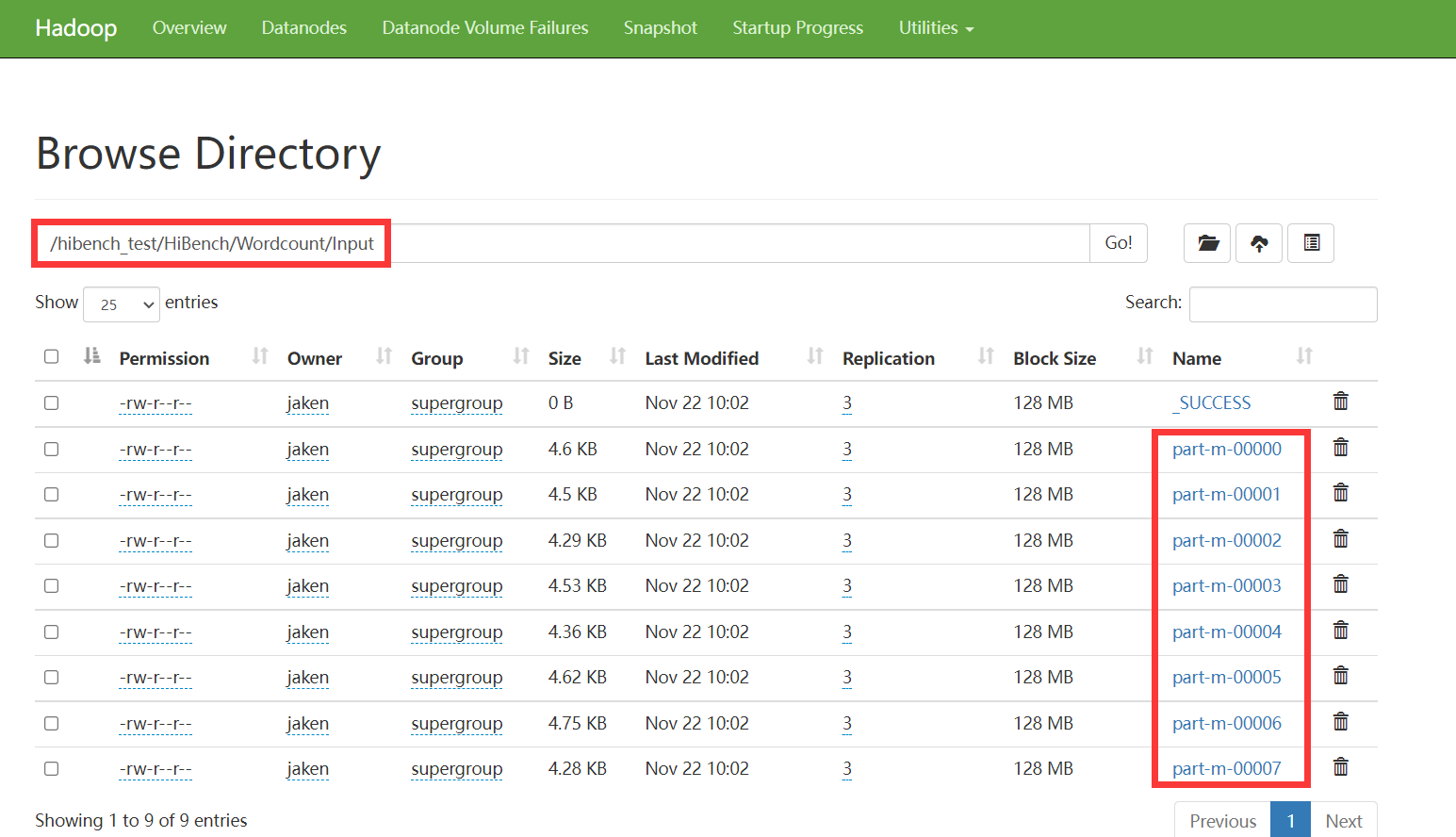
进入HDFS查看准备的输入数据
准备命令
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/prepare/prepare.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/prepare/prepare.sh
注意jar文件夹中不要包含其他备用的jar包
运行命令
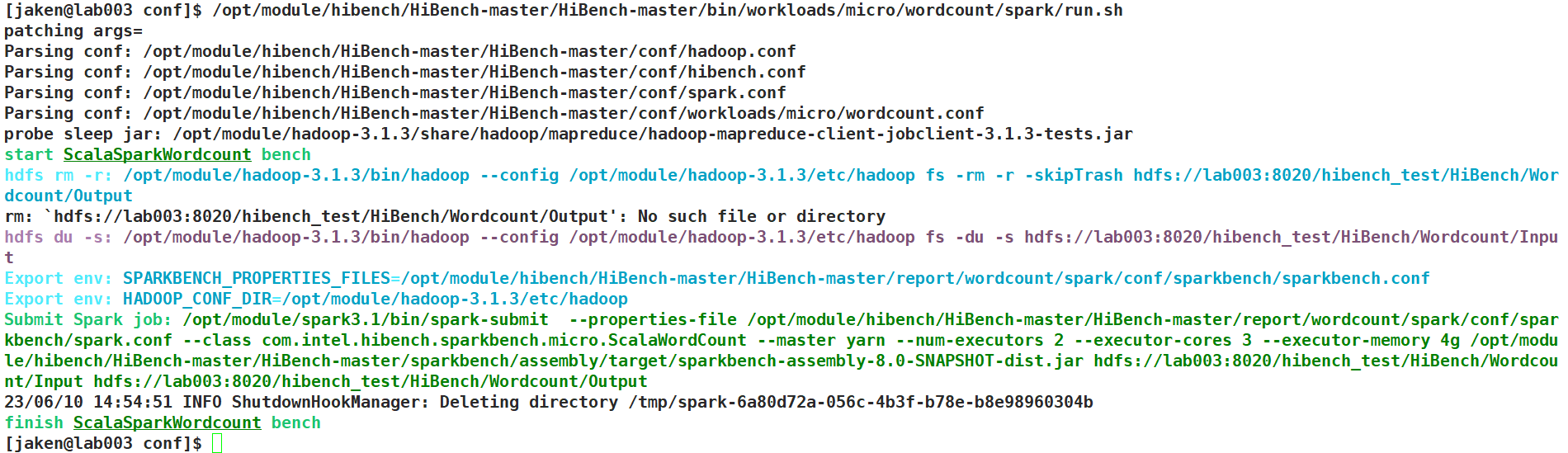
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/wordcount/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/terasort/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/micro/sort/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/kmeans/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/bayes/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/ml/lr/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/spark/run.sh/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/graph/nweight/spark/run.sh

成功!
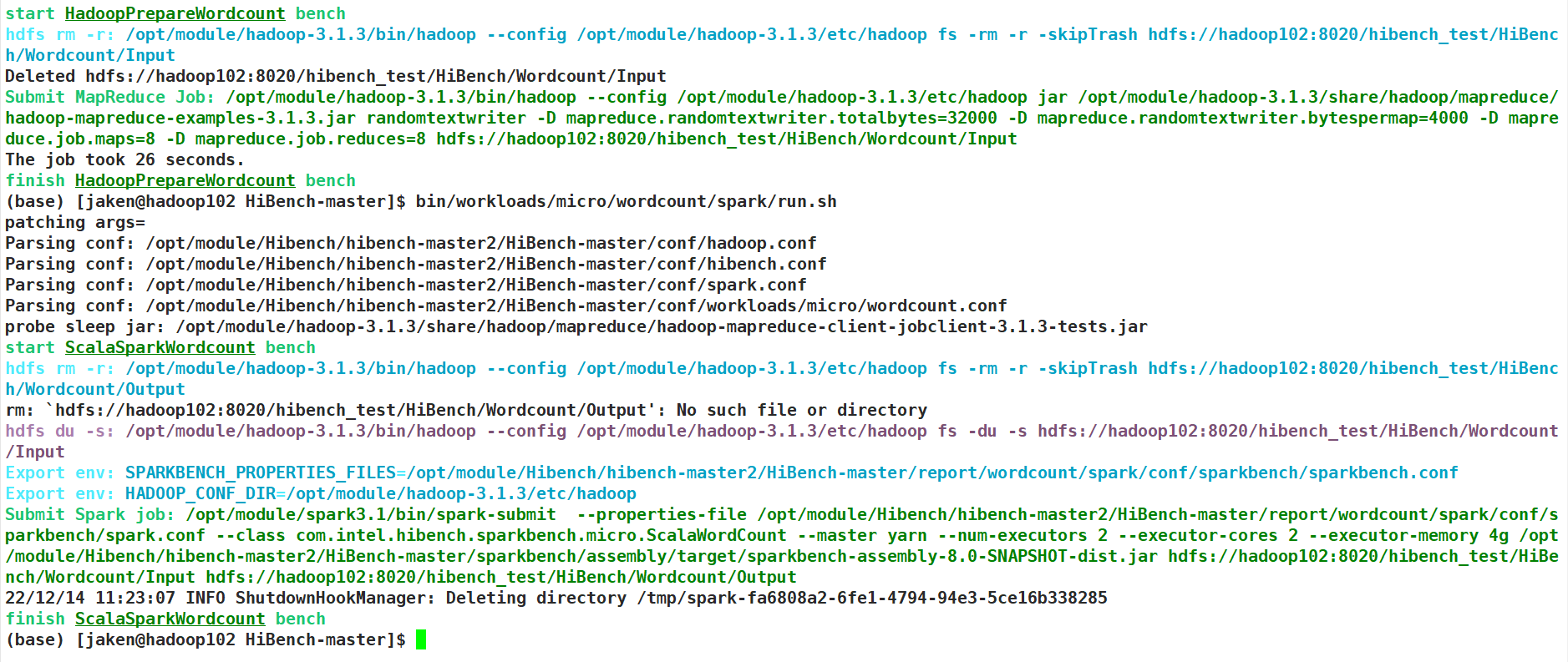
结果
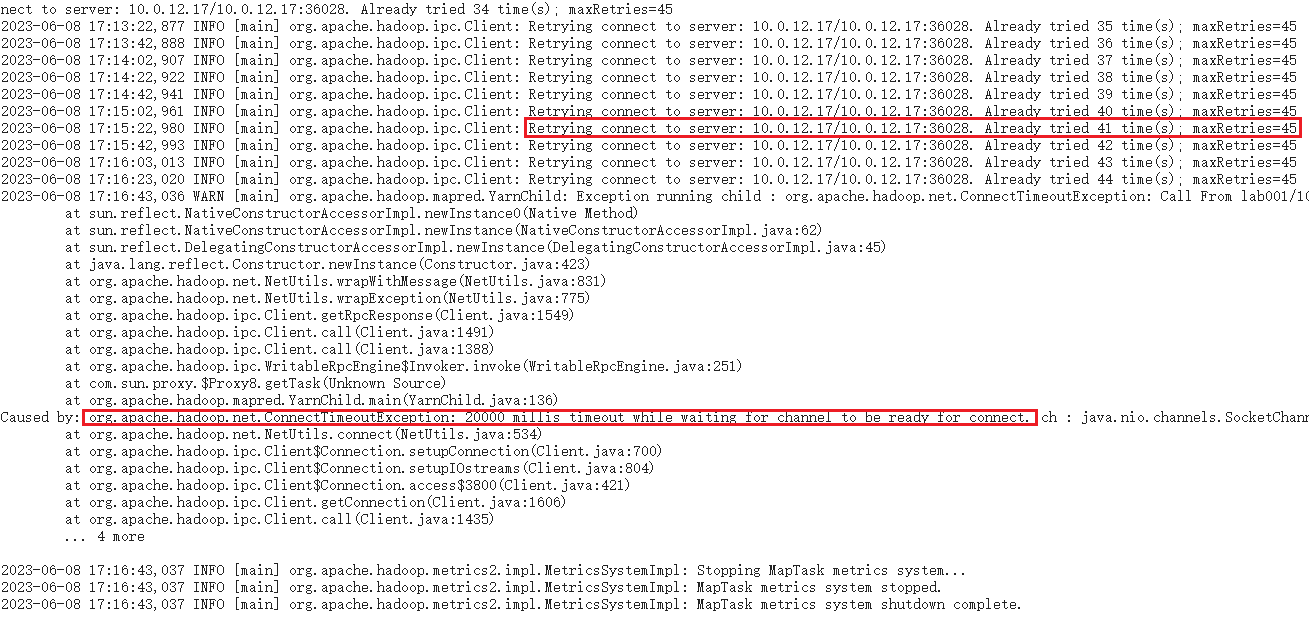
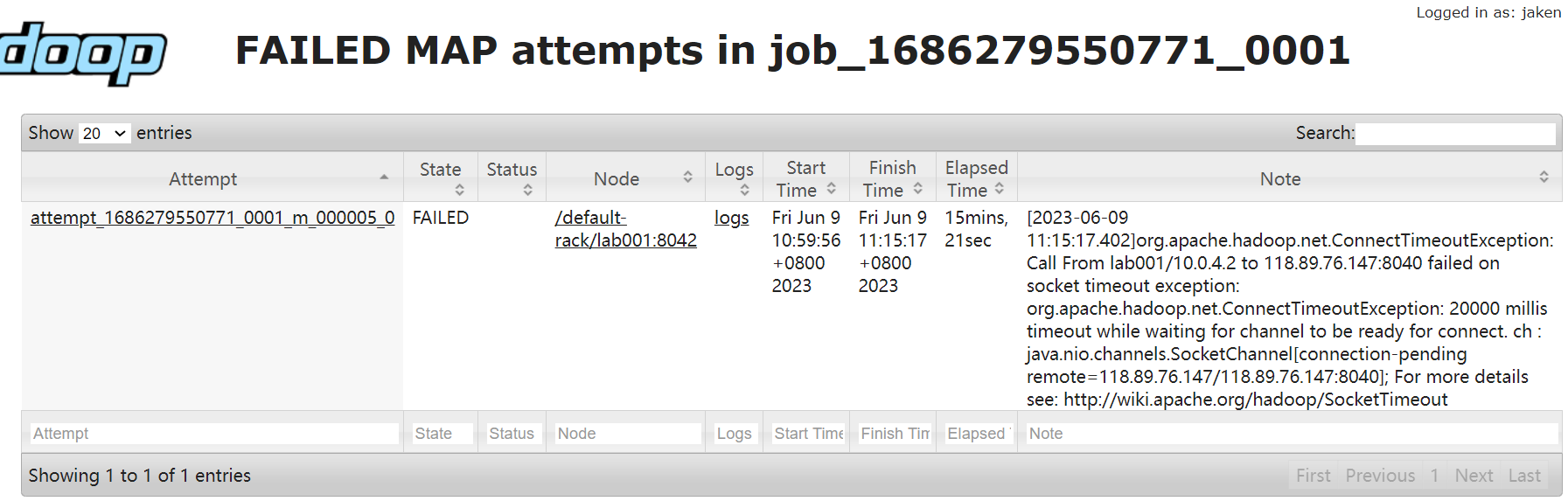
trouble
网络配置问题
所有任务在yarn上都用的是内网IP
Permission denied
# 进入bin目录
chmod -R +x ./bin/
multi-job

Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/hibench.conf
Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/spark.conf
Parsing conf: /opt/module/hibench/HiBench-master/HiBench-master/conf/workloads/websearch/pagerank.conf
probe sleep jar: /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar
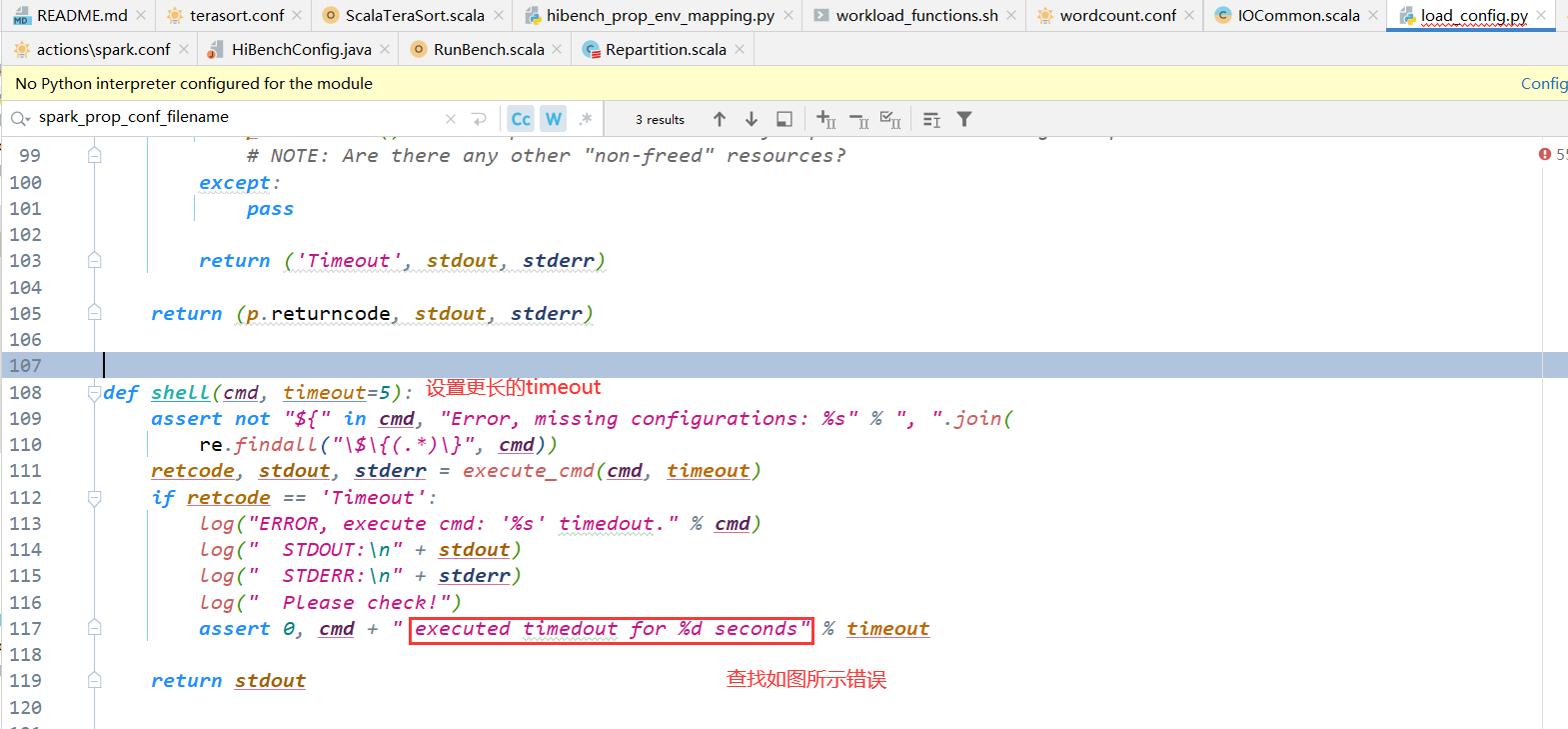
ERROR, execute cmd: '( /opt/module/hadoop-3.1.3/bin/yarn node -list 2> /dev/null | grep RUNNING )' timedout.STDOUT:STDERR:Please check!
Traceback (most recent call last):File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 685, in <module>load_config(conf_root, workload_configFile, workload_folder, patching_config)File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 217, in load_configgenerate_optional_value()File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 613, in generate_optional_valueprobe_masters_slaves_hostnames()File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 549, in probe_masters_slaves_hostnamesprobe_masters_slaves_by_Yarn()File "/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/load_config.py", line 500, in probe_masters_slaves_by_Yarnassert 0, "Get workers from yarn-site.xml page failed, reason:%s\nplease set `hibench.masters.hostnames` and `hibench.slaves.hostnames` manually" % e
AssertionError: Get workers from yarn-site.xml page failed, reason:( /opt/module/hadoop-3.1.3/bin/yarn node -list 2> /dev/null | grep RUNNING ) executed timedout for 5 seconds
please set `hibench.masters.hostnames` and `hibench.slaves.hostnames` manually
start ScalaSparkPagerank bench
/opt/module/hibench/HiBench-master/HiBench-master/bin/functions/workload_functions.sh: line 38: .: filename argument required
.: usage: . filename [arguments]
/opt/module/hibench/HiBench-master/HiBench-master/bin/workloads/websearch/pagerank/spark/run.sh: line 26: OUTPUT_HDFS: unbound variable
原因可能是系统负载过高导致的响应迟钝
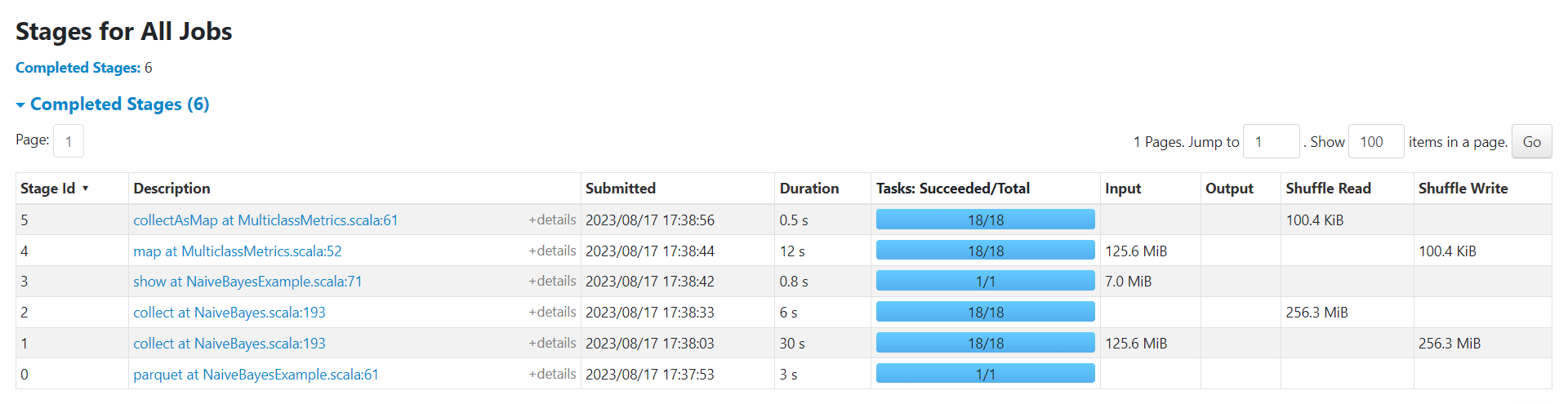
2.records
parallelism = 18
有input的stage的任务数是由数据数据的大小决定的,spark.default.parallelism决定的是shuffle后的stage的任务数
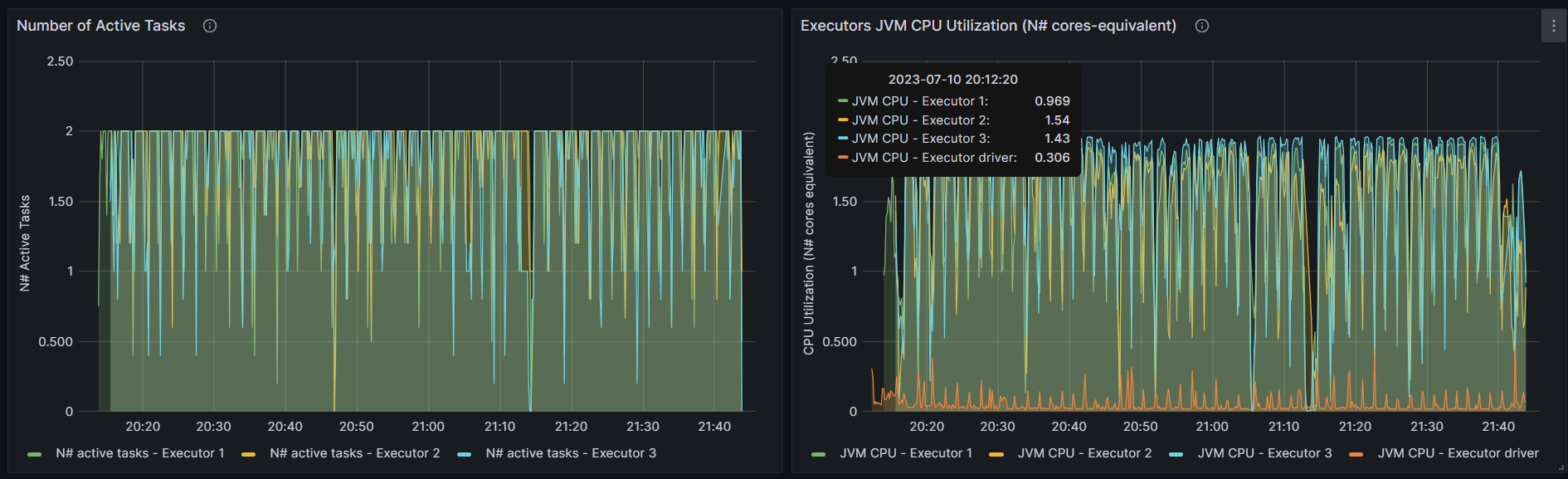
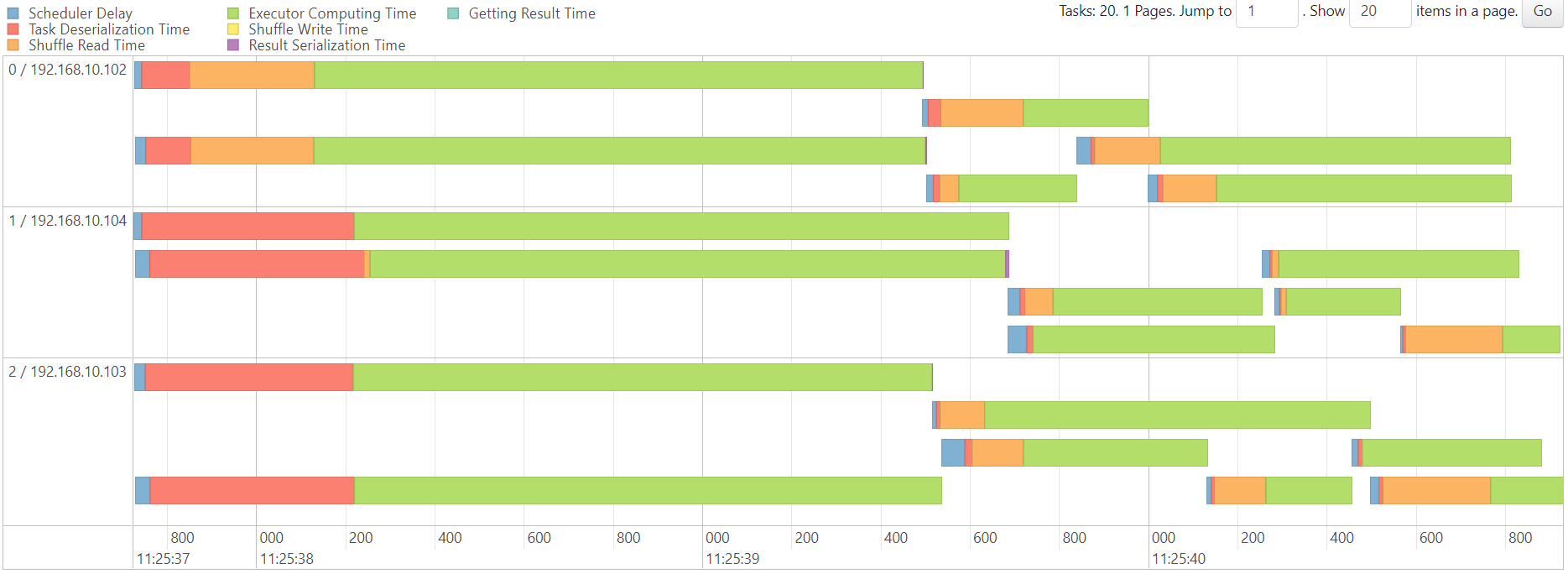
LR
内存不够
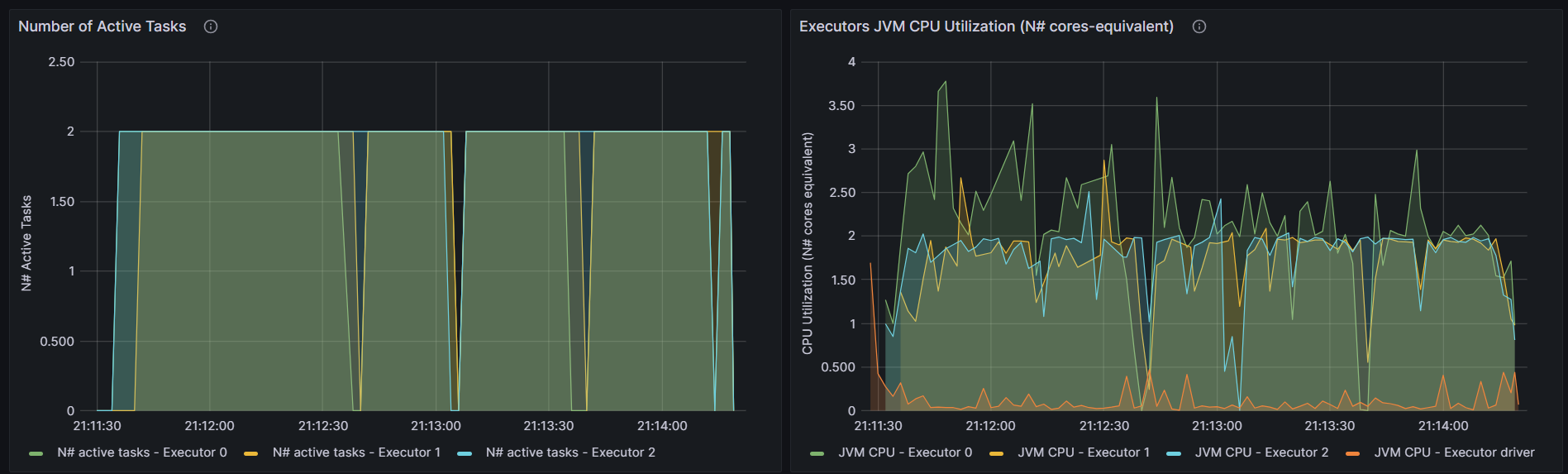
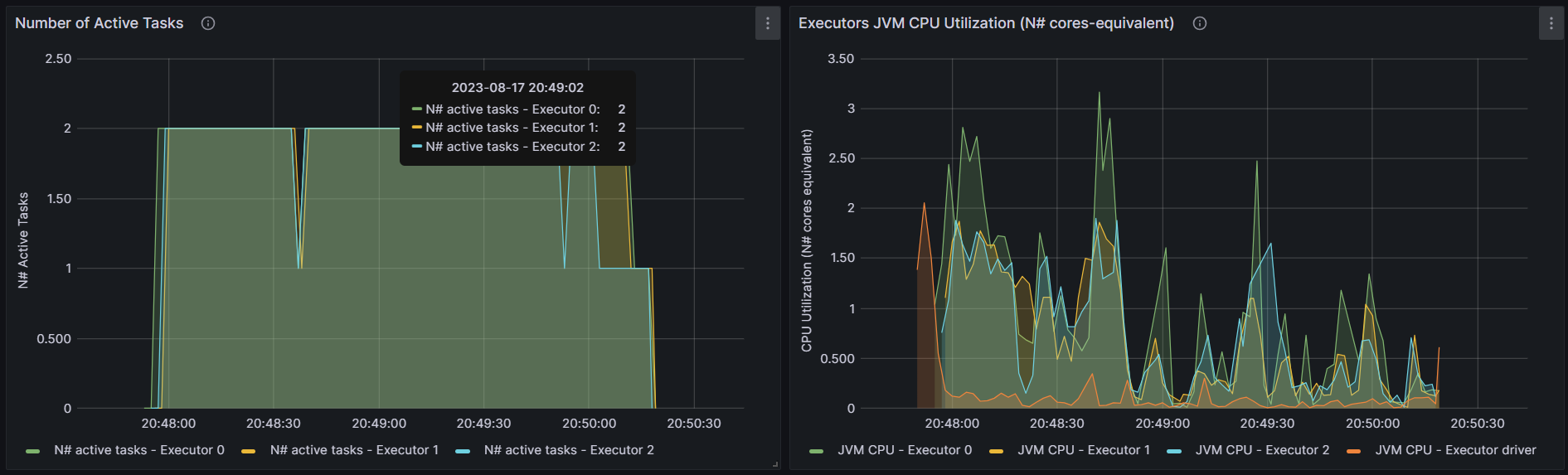
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692258304054&to=1692264023063&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817154625-0003&var-groupbyInterval=1s

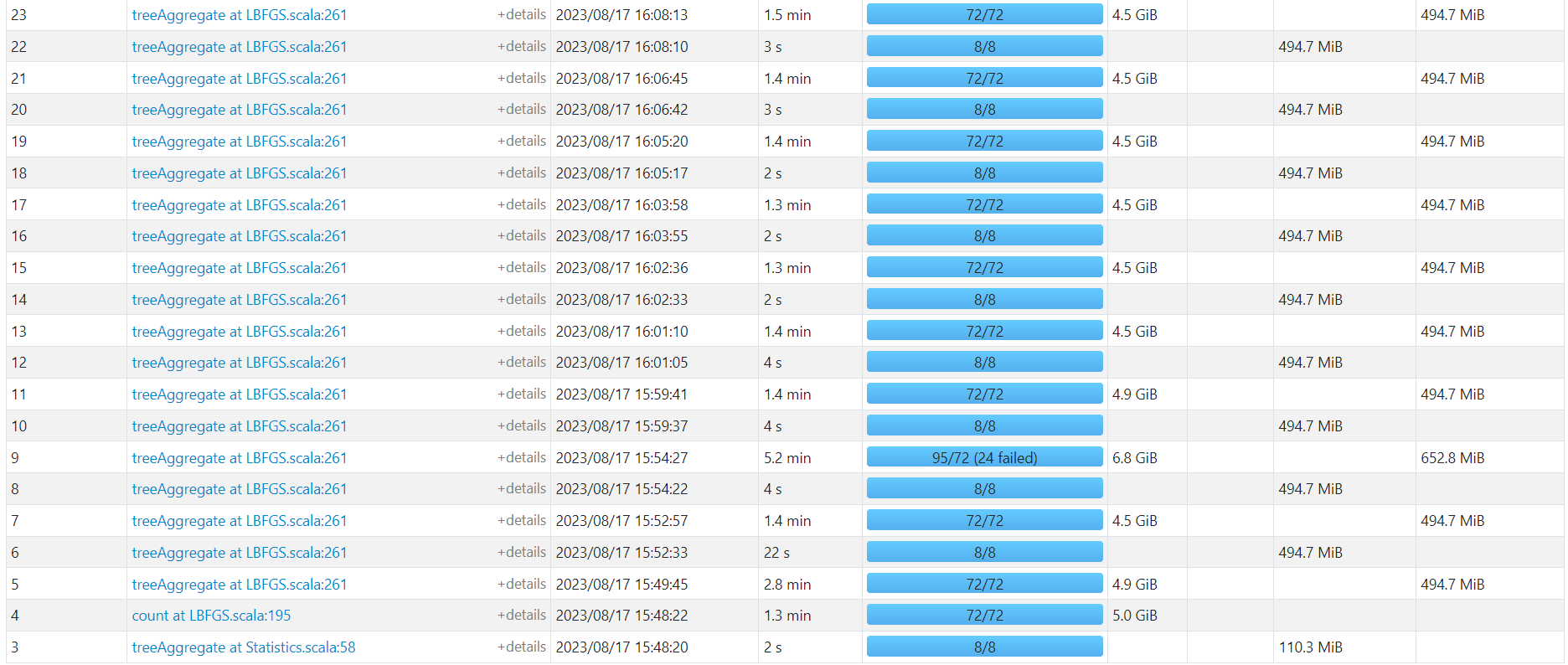
http://192.168.10.102:18080/history/app-20230817154625-0003/stages/

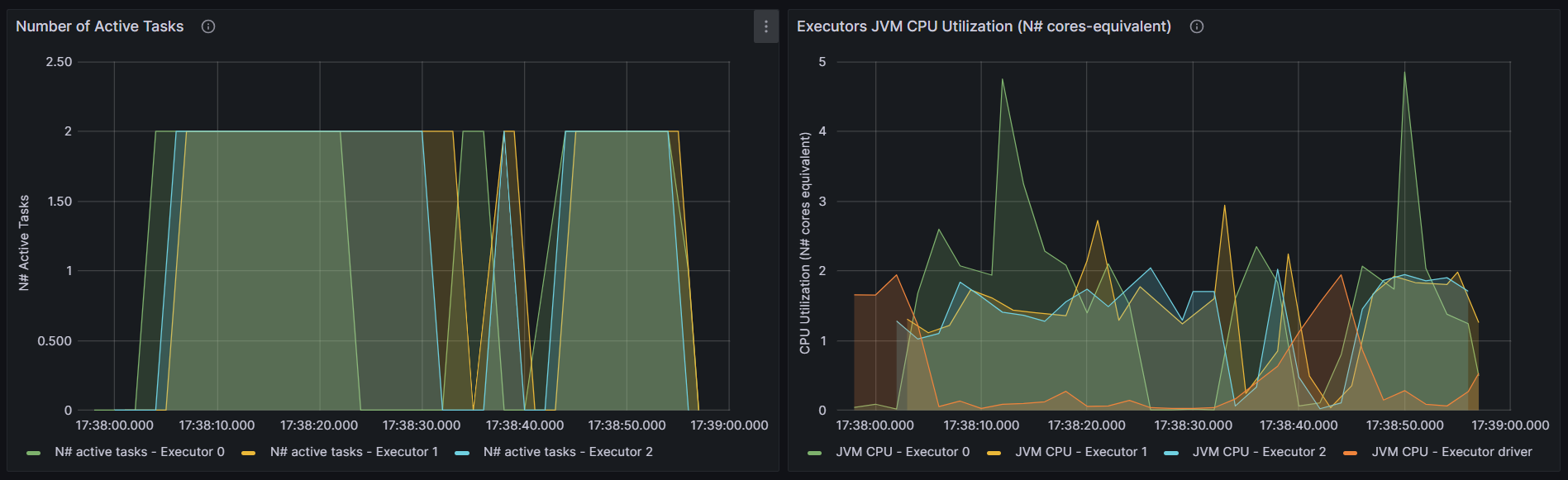
Bayes
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692265076383&to=1692265140060&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817173746-0004&var-groupbyInterval=1s
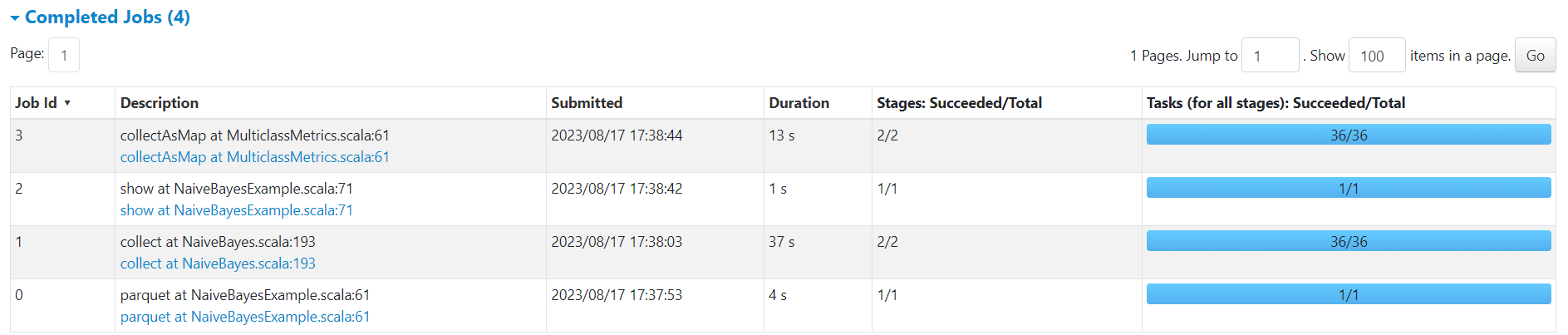
http://192.168.10.102:18080/history/app-20230817173746-0004/jobs/

NWeightGraphX


ScalaPageRank
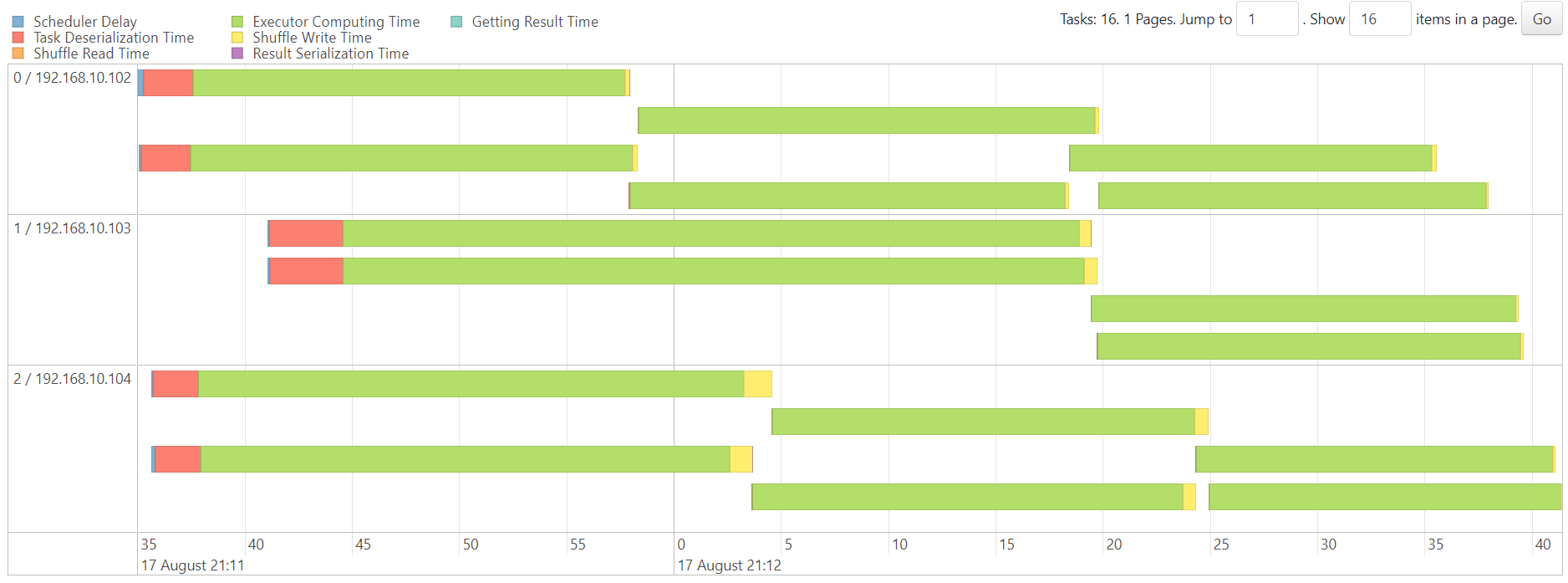
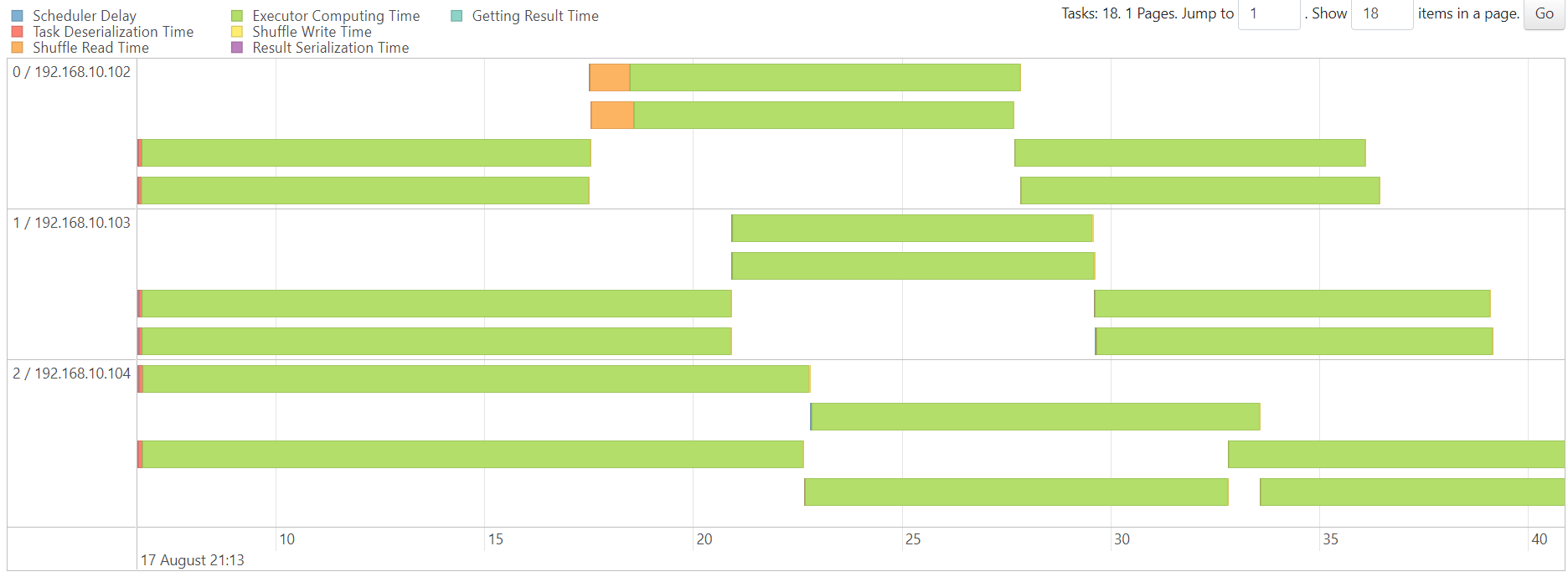
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692277885573&to=1692278062264&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817211121-0012&var-groupbyInterval=1s
http://192.168.10.102:18080/history/app-20230817211121-0012/stages/

distinct
flatMap
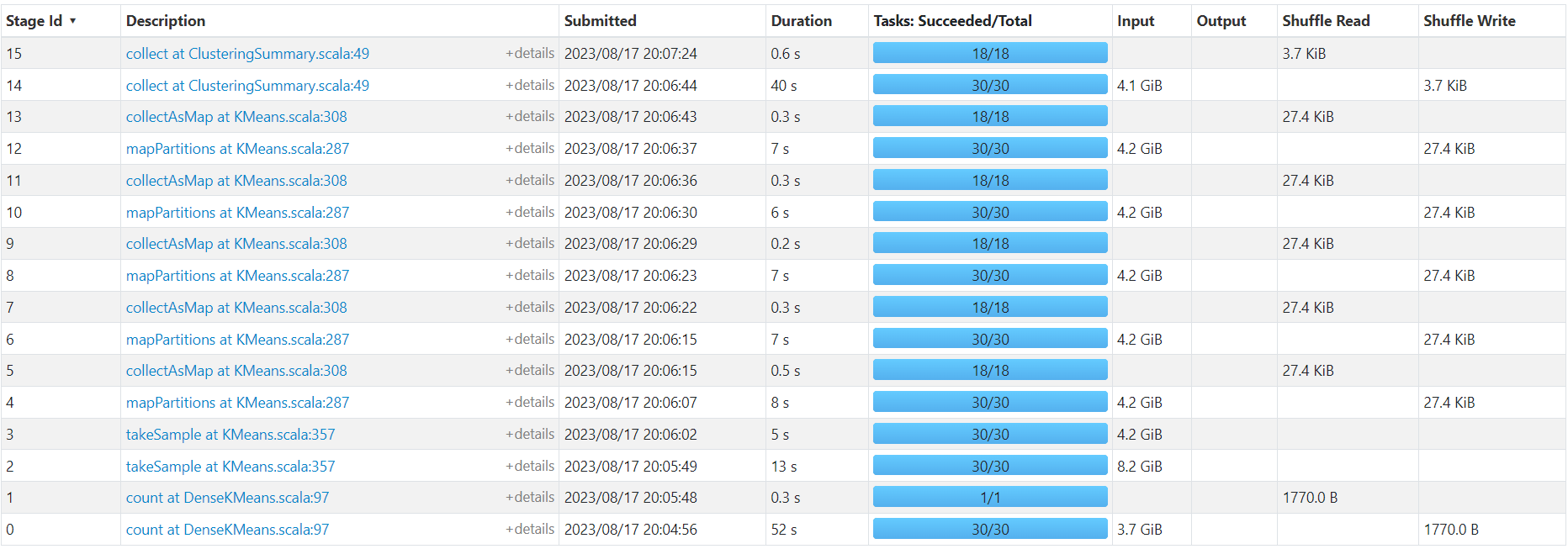
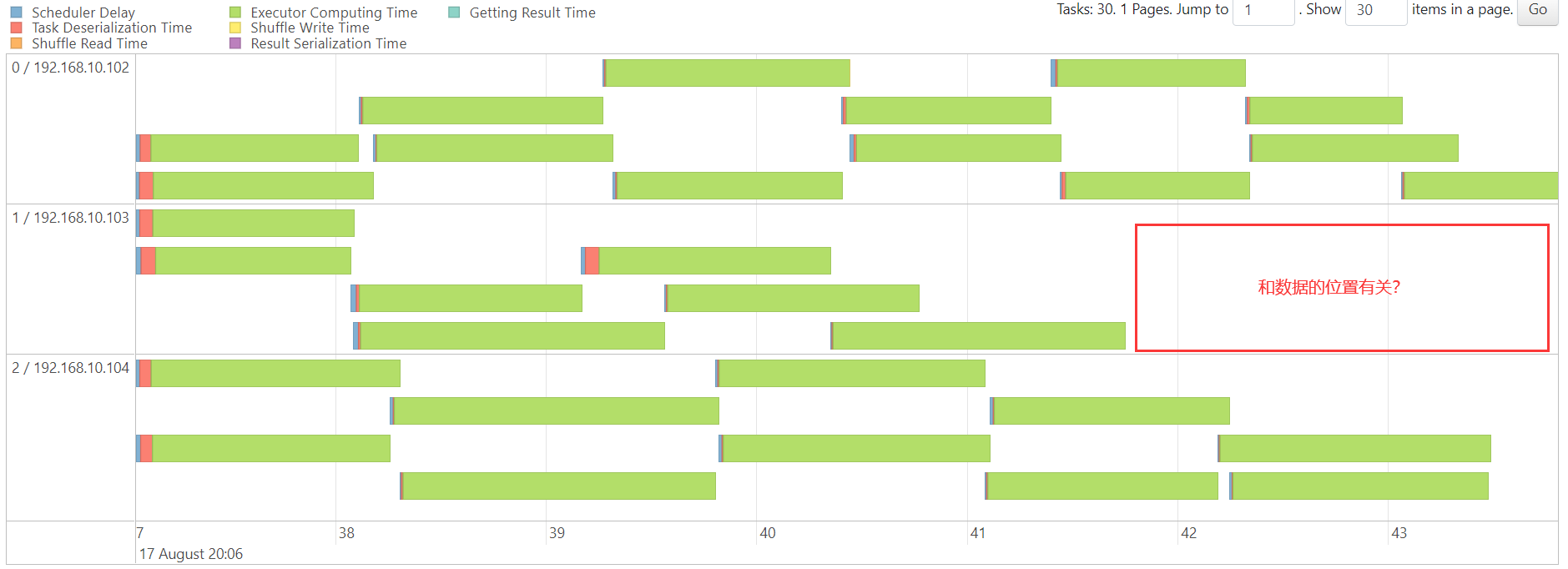
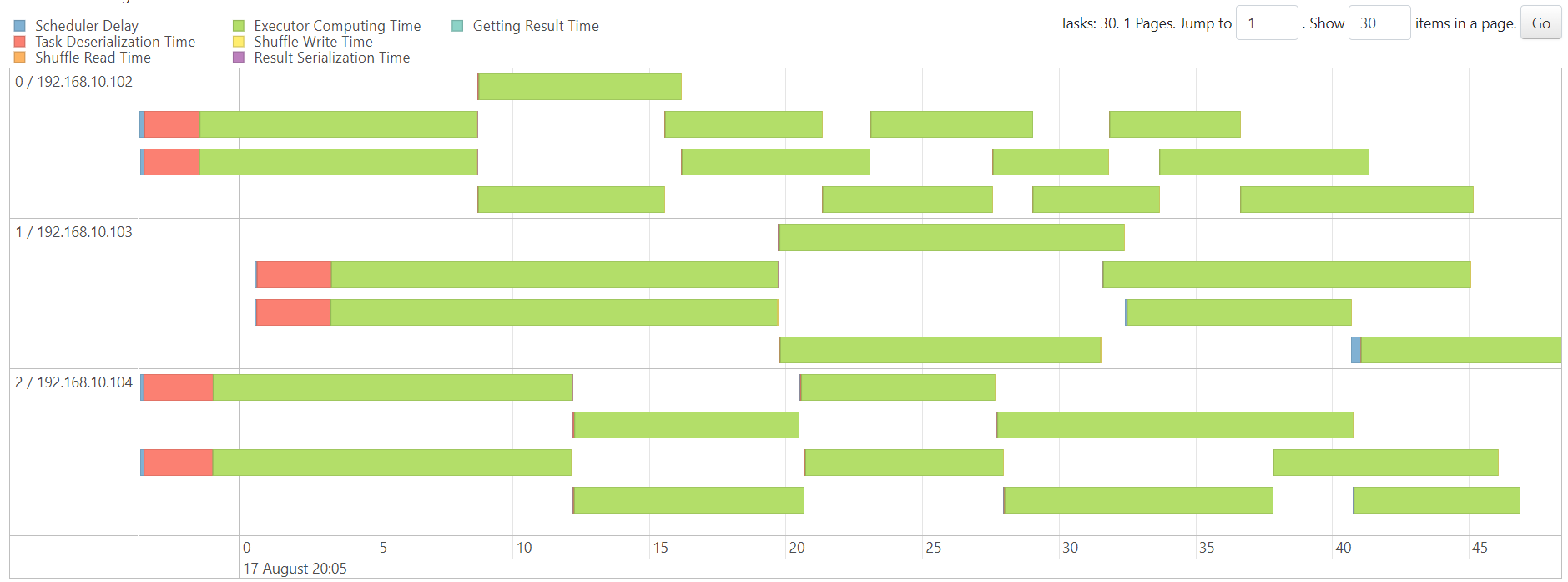
DenseKMeans
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692273890319&to=1692274051643&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817200442-0009&var-groupbyInterval=1s
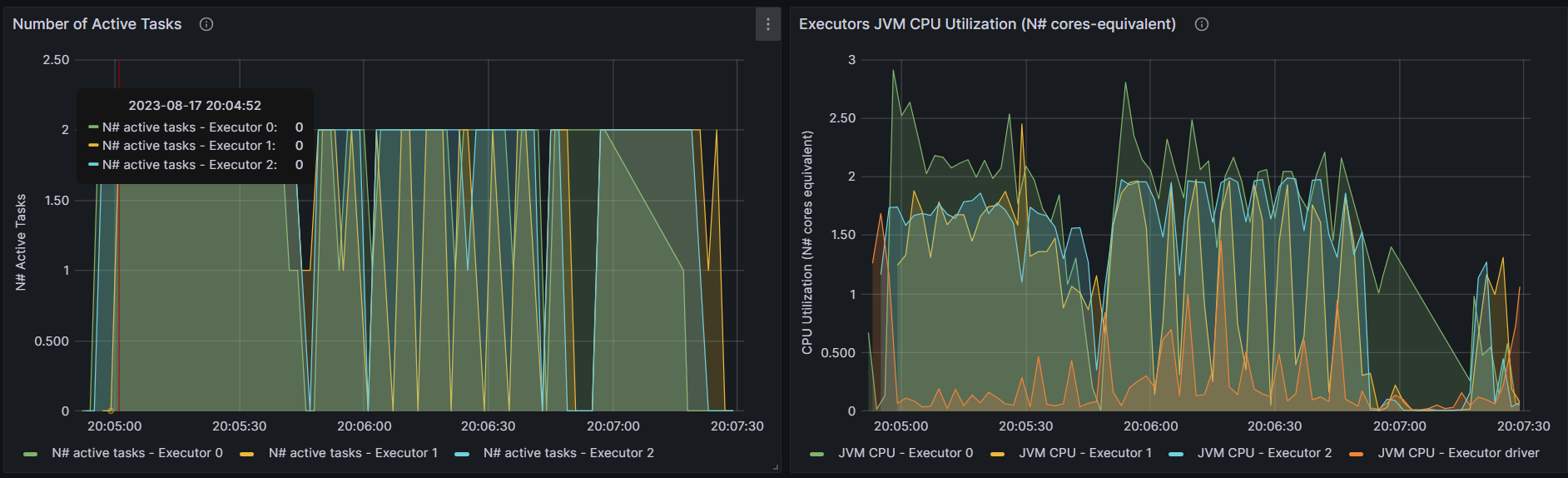
http://192.168.10.102:18080/history/app-20230817200442-0009/stages/

map
collect
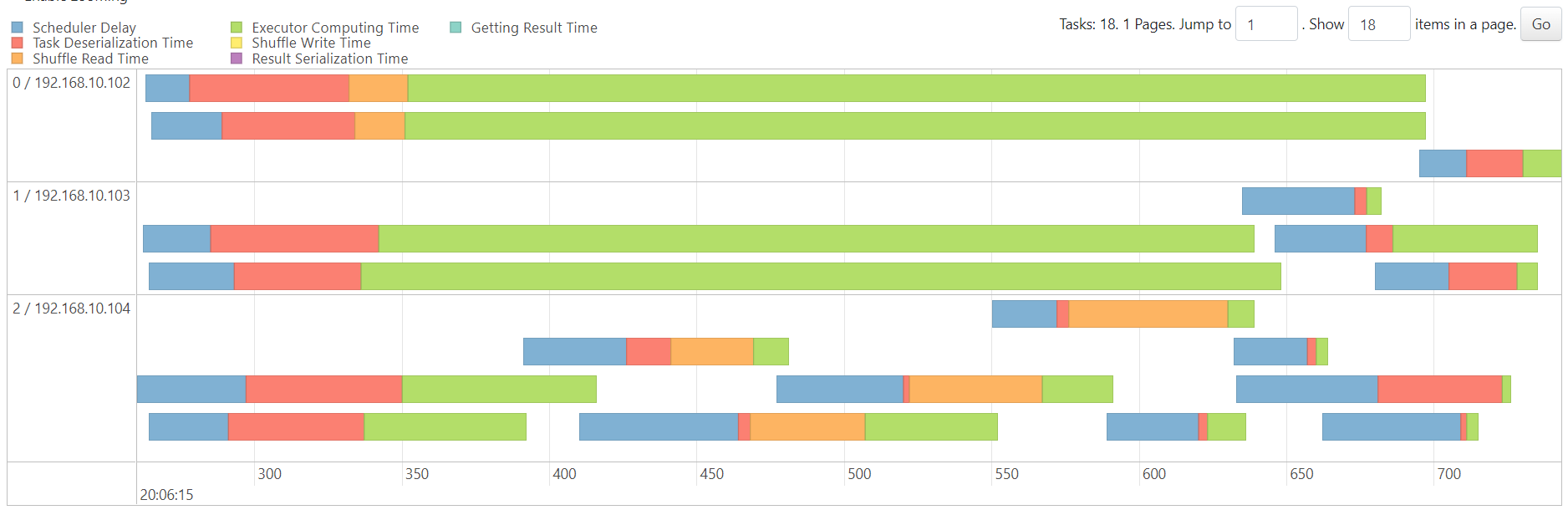
sort
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692276453862&to=1692276644236&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817204743-0011&var-groupbyInterval=1s
http://192.168.10.102:18080/history/app-20230817204743-0011/stages/

map
reduce
TeraSort
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1692275803257&to=1692276079162&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230817203719-0010&var-groupbyInterval=1s

http://192.168.10.102:18080/history/app-20230817203719-0010/stages/

map

reduce
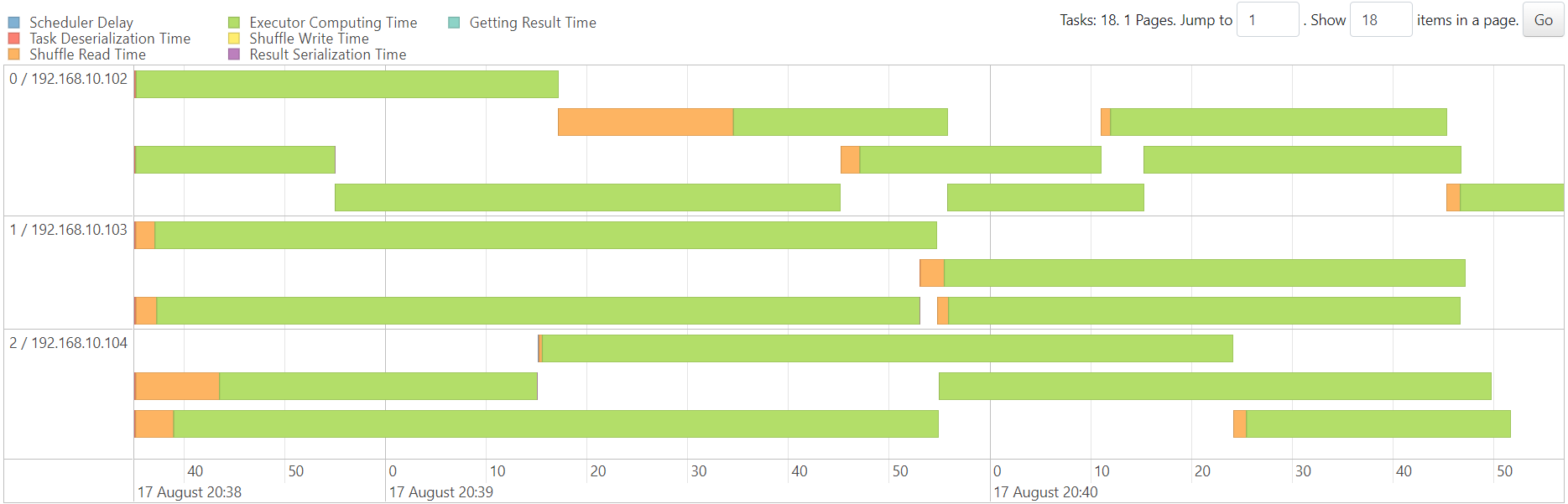
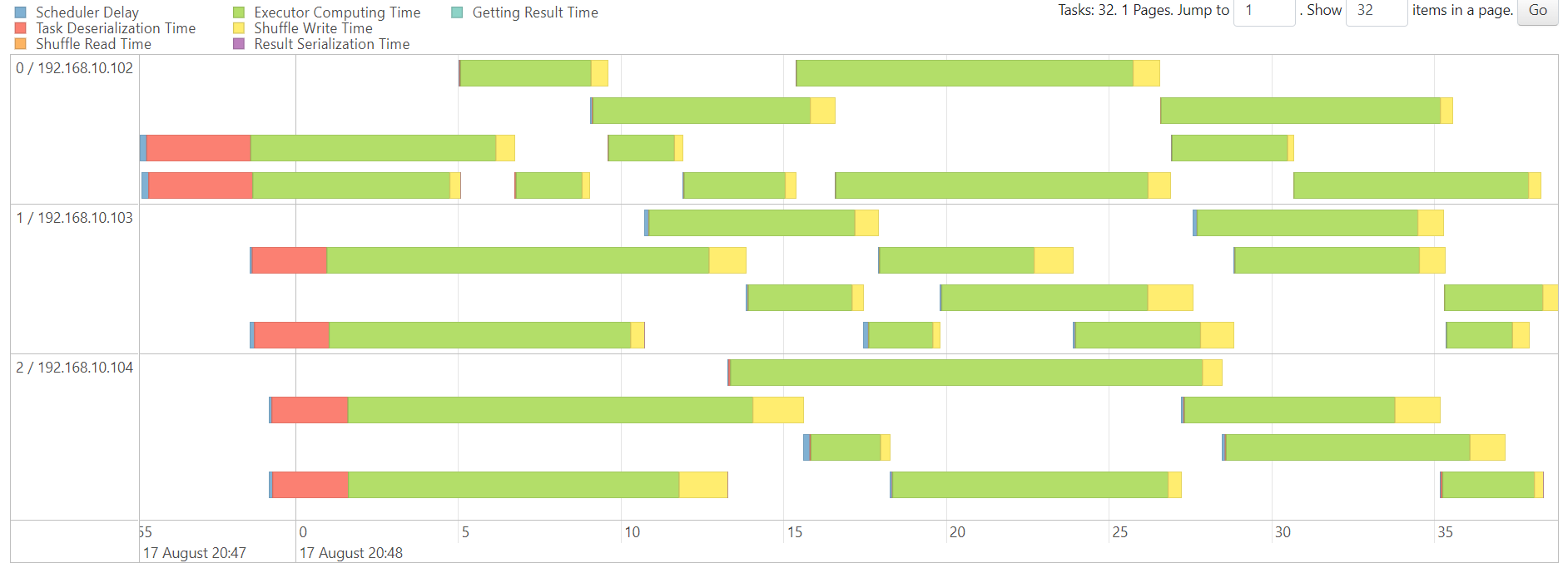
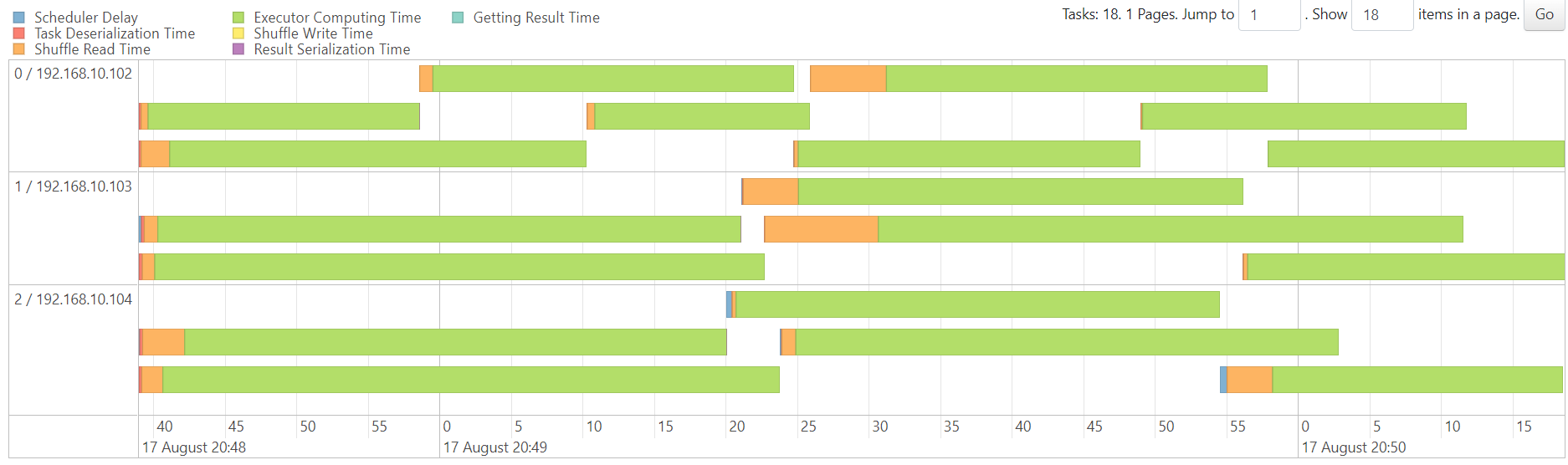
WordCount
http://192.168.10.102:3000/d/e9e40733-bb3a-42c8-8704-38ec27cbee3f/spark-perf-dashboard-v04-custom?from=1691983226006&to=1691983545077&orgId=1&var-UserName=jaken&var-ApplicationId=app-20230814112024-0002&var-groupbyInterval=1s
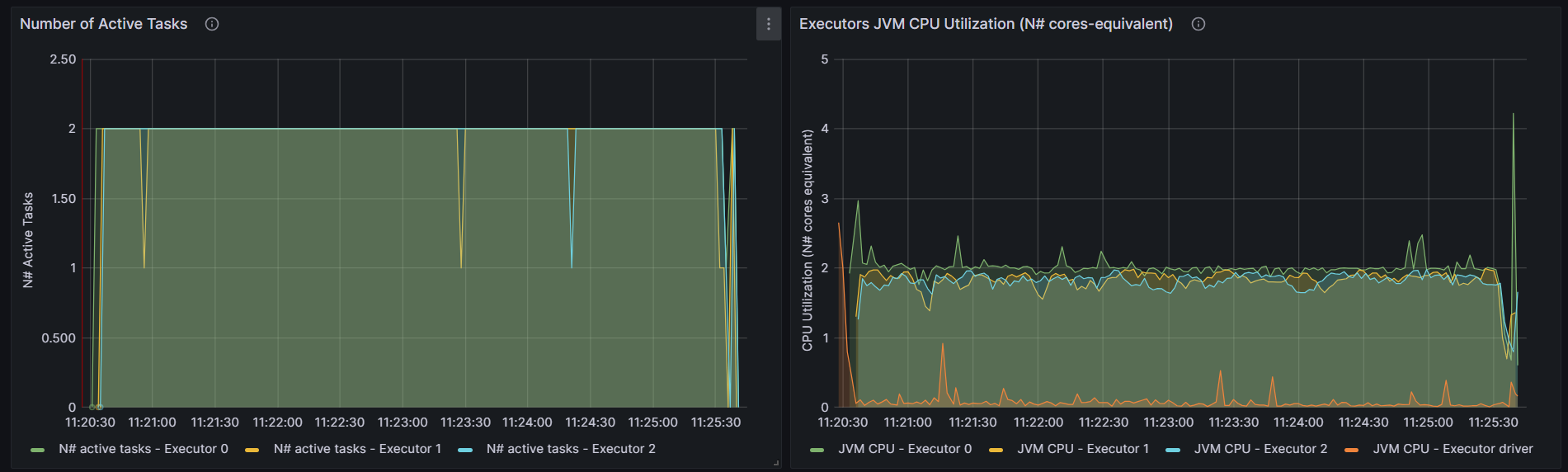
parallelism=20

http://192.168.10.102:18080/history/app-20230814112024-0002/jobs/
map
reduce
hdfs维护
hadoop fs -rm -r -skipTrash /hibench_test/HiBench/
hadoop dfsadmin -safemode leave
var-ApplicationId=app-20230814112024-0002&var-groupbyInterval=1s
[外链图片转存中…(img-eGnFeoml-1696143711685)]
parallelism=20
[外链图片转存中…(img-tqMq87MT-1696143711685)]
http://192.168.10.102:18080/history/app-20230814112024-0002/jobs/
map
[外链图片转存中…(img-ckoZlP4I-1696143711686)]
reduce
[外链图片转存中…(img-yA8CbUjp-1696143711686)]
hdfs维护
hadoop fs -rm -r -skipTrash /hibench_test/HiBench/
hadoop dfsadmin -safemode leave
相关文章:
24Hibench
1. Hibench 官网 HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCou…...

VC++父进程交互式操作子进程标准输入输出
父进程接管子进程的标准输入输出和错误,实现对子进程的交互操作。比如子进程是一个类似mysql这种可以交互的命令,执行操作后输出结果,父进程根据结果分析决定执行下一步的命令,从而替代人工的输入。 通过父进程创建子进程,使用管道重定向子进程的输入输出错误可以实现 在 …...
一步一招,教你如何制作出成功的优惠促销微传单
在当今的数字化时代,几乎所有的事情都可以在互联网上完成,包括制作宣传单。有很多在线工具可以帮助我们轻松制作出精美的商场促销宣传单。下面就以乔拓云为例,详细介绍如何简单几步制作出让人眼前一亮的商场促销宣传单。 1. 注册并登录乔拓云…...
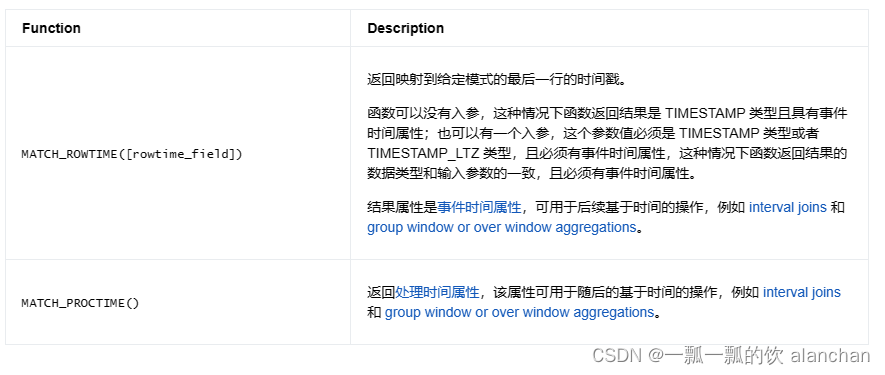
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
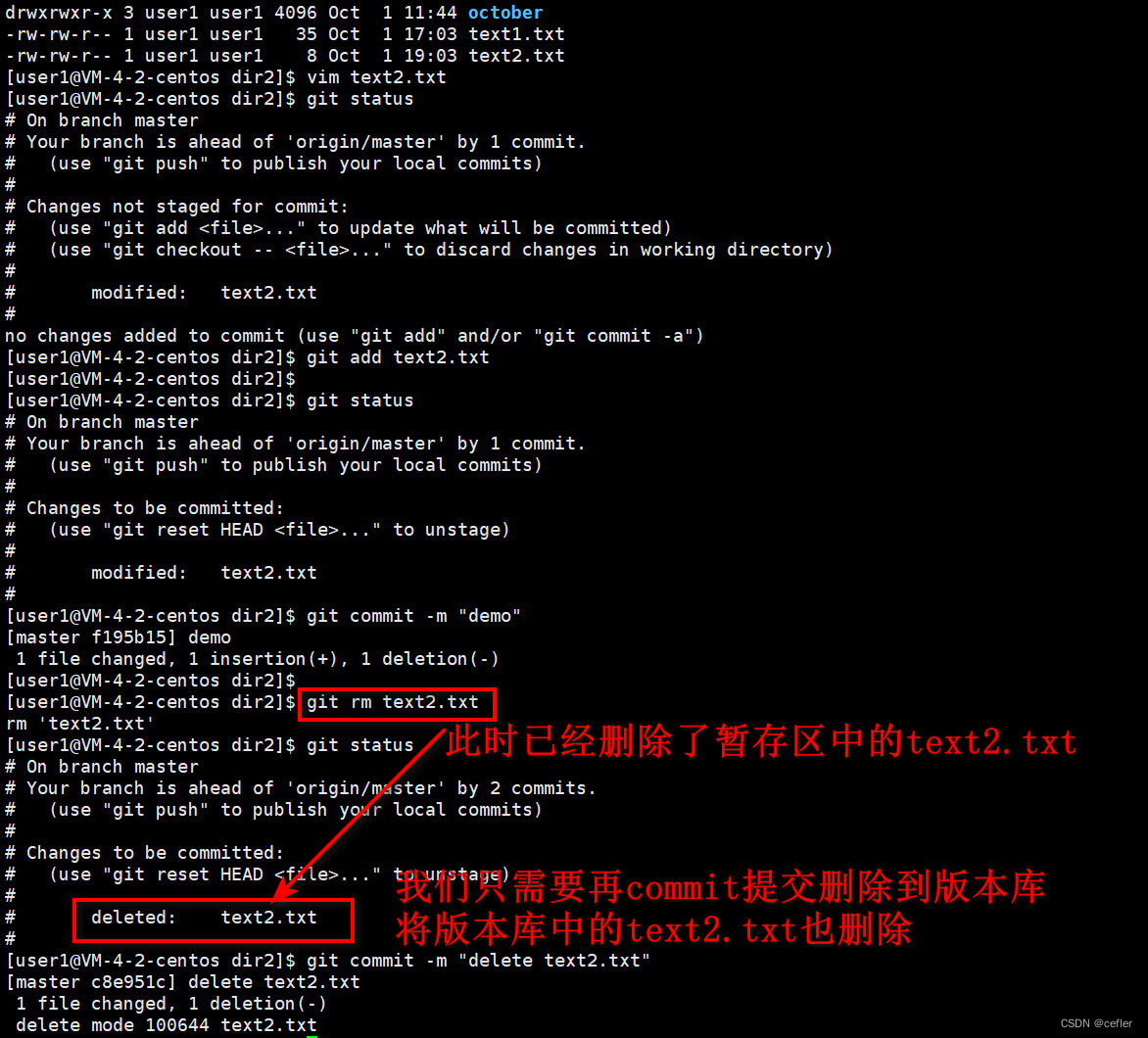
Git使用【上】
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析3 前言 先前有些git命令我在我的其它文章里面已经写过,若要查看可参考【Linu…...
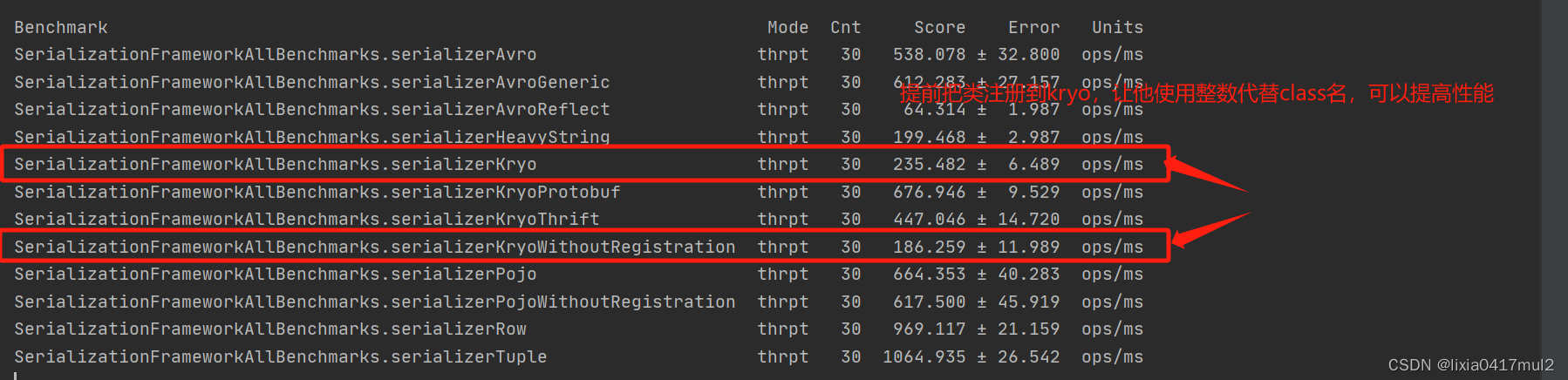
flink的序列化基准测试
背景: flink提供了在本地环境使用jmh测试不同序列化方法的性能差异,本文就是基于这个https://github.com/apache/flink-benchmarks这个性能测试,总结几个结论,以便后面使用时避免掉坑 基准测试 我们本次运行的是SerializationF…...

Error: node: unknown or unsupported macOS version: :dunno 错误解决
一、原因 今天安装 brew install node报错了,错误信息如下: 二、解决方案 1)查找homebrew-cask安装位置 echo $(brew --repo homebrew/homebrew-cask) // 输出 /opt/homebrew/Library/Taps/homebrew/homebrew-cask2)使用 gi…...

嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理②
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理② 第十八章 Linux系统对中断的处理 ②18.3 Linux中断系统中的重要数据结构18.3.1 irq_desc数组18.3.2 irqaction结构体18.3.3 irq_data结构体18.3.4 irq_domain结构体18.3.5 irq_chip结构体 18.4 在设备树中指定中断_在…...

Kolmogorov-Smirnov正态性检验
Kolmogorov-Smirnov正态性检验是一种统计方法,用于检验数据集是否服从正态分布。其基本原理和用途如下: 基本原理: 假设检验:Kolmogorov-Smirnov检验基于一个假设,即待检验的数据集服从特定的理论正态分布。计算累积…...

BI神器Power Query(25)-- 使用PQ实现表格多列转换(1/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...
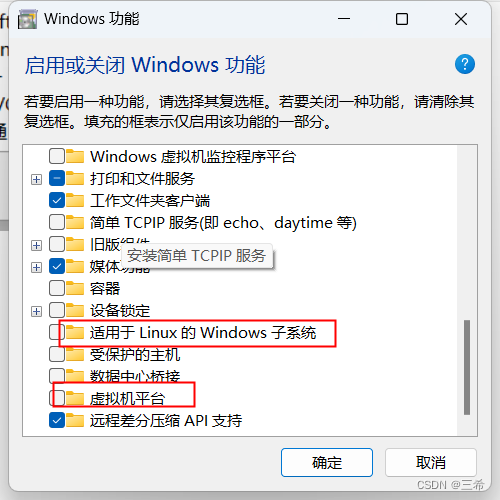
windows系统一键开启和关闭虚拟化
说明 跟虚拟化相关的三个程序 一键开启脚本 REM 开启 Hyper-V 服务 pushd "%~dp0"dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txtfor /f %%i in (findstr /i . hyper-v.txt 2^>nul) do dism /online /norestart /add-package:"%Sy…...

NSSCTF做题(5)
[NSSCTF 2022 Spring Recruit]babyphp 代码审计 if(isset($_POST[a])&&!preg_match(/[0-9]/,$_POST[a])&&intval($_POST[a])){ if(isset($_POST[b1])&&$_POST[b2]){ if($_POST[b1]!$_POST[b2]&&md5($_POST[b1])md5($_POST[b2])){…...

java基础题——二维数组的基本应用
1.设计程序按照各个学生的 Java 成绩进行排序 ( 降序 ) 2.设计程序,根据学生总成绩进行排序(降序排列),并输出学生姓名、每门课程的名称和该学生的成绩、该学生的总成绩 public static void main(String[] args) {String[] names {"安琪拉",…...

Leetcode 2119.反转两次的数字
反转 一个整数意味着倒置它的所有位。 例如,反转 2021 得到 1202 。反转 12300 得到 321 ,不保留前导零 。 给你一个整数 num ,反转 num 得到 reversed1 ,接着反转 reversed1 得到 reversed2 。如果 reversed2 等于 num &#x…...
BI神器Power Query(27)-- 使用PQ实现表格多列转换(3/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...
VUE3照本宣科——认识VUE3
VUE3照本宣科——认识VUE3 前言一、命令创建项目1.中文官网2.菜鸟教程 二、VUE3项目目录结构1.public2.src(1)assets(2)components 3. .eslintrc.cjs4. .gitignore5. .prettierrc.json6.index.html7.package.json8.README.md9.vit…...

《计算机视觉中的多视图几何》笔记(12)
12 Structure Computation 本章讲述如何在已知基本矩阵 F F F和两幅图像中若干对对应点 x ↔ x ′ x \leftrightarrow x x↔x′的情况下计算三维空间点 X X X的位置。 文章目录 12 Structure Computation12.1 Problem statement12.2 Linear triangulation methods12.3 Geomet…...

TFT LCD刷新原理及LCD时序参数总结(LCD时序,写的挺好)
cd工作原理目前不了解,日后会在博客中添加这一部分的内容。 1.LCD工作原理[1] 我对LCD的工作原理也仅仅处在了解的地步,下面基于NXP公司对LCD工作原理介绍的ppt来学习一下。 LCD(liquid crystal display,液晶显示屏) 是由液晶段阵列组成,当…...

基于Java的电影院购票系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

Linux基础指令(六)
目录 前言1. man 指令2. date 指令3. cal 指令4. bc 指令5. uname 指令结语: 前言 欢迎各位伙伴来到学习 Linux 指令的 第六天!!! 在上一篇文章 Linux基本指令(五) 中,我们通过一段故事线,带大家感性的了…...

绝地求生罗技鼠标宏实战指南:5步实现高效压枪技巧
绝地求生罗技鼠标宏实战指南:5步实现高效压枪技巧 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 对于《绝地求生》玩家来说…...

3分钟快速解锁网易云音乐NCM格式:ncmdump音频解密工具完全指南
3分钟快速解锁网易云音乐NCM格式:ncmdump音频解密工具完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放,无法在其他设…...

009、NPU、TPU与硬件加速器在TinyML中的作用
009、NPU、TPU与硬件加速器在TinyML中的作用 去年冬天调试一个智能门锁的唤醒词模型,模型在PC上跑得飞起,量化后只有48KB,自信满满地烧进STM32F4。结果呢?唤醒延迟从预期的200ms直接飙到1.2秒,电池续航从三个月缩水到两周。拆开示波器一看,CPU在跑模型的时候几乎被占满,…...

用TensorFlow 2.2复现Deep Biaffine Attention:一个在Colab上跑通的依存解析实战教程
用TensorFlow 2.2复现Deep Biaffine Attention:一个在Colab上跑通的依存解析实战教程 依存句法解析是自然语言处理中的核心任务之一,它通过分析句子中词语之间的修饰关系,构建句子的语法结构树。近年来,基于神经网络的依存解析方法…...

新加坡高校 Canvas 攻击事件影响评估与安全治理研究
摘要 2026 年 5 月发生的 Canvas 学习平台全球供应链攻击事件,对新加坡国立大学、新加坡社科大学、新加坡管理学院等高校造成服务中断与数据泄露风险,成为教育数字化场景下第三方平台安全风险的典型案例。本次攻击由 Shiny Hunters 组织实施,…...

从图文对到通用视觉:CLIP如何用对比学习重塑多模态预训练范式
1. 从图文匹配到通用视觉:CLIP的颠覆性思路 第一次看到CLIP模型时,我正为一个老问题头疼:训练好的图像分类器遇到新类别就直接"罢工"。比如用猫狗数据集训练的模型,突然给它看一只考拉,结果只会输出"猫…...

【NotebookLM音频黑科技深度解析】:20年AI产品经理亲测的5大颠覆性功能与3个未公开技巧
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Audio Overview NotebookLM Audio 是 Google 推出的实验性语音增强功能,深度集成于 NotebookLM 平台,旨在将用户上传的 PDF、网页文本等资料转化为可交互的语音知识体…...

CTFd平台集成MCP协议:AI助手赋能CTF赛事智能运维实践
1. 项目概述:CTFd与MCP的融合实践最近在安全圈和CTF(Capture The Flag,夺旗赛)赛事运维圈子里,一个名为AaryaBhusal/ctfd-mcp的项目引起了我的注意。乍一看,这像是一个针对CTFd平台的插件或扩展,…...

基于Spring Boot的金融级钱包与支付系统设计与实现
1. 项目概述与核心价值 最近在折腾一个需要集成支付功能的项目,后台管理、用户体系都搭好了,就差一个稳定、灵活且能快速上线的钱包与支付模块。找了一圈开源方案,要么太重,耦合了太多业务逻辑;要么太轻,连…...

LinkedOM与JSDOM性能对比:10倍速度提升的秘诀
LinkedOM与JSDOM性能对比:10倍速度提升的秘诀 【免费下载链接】linkedom A triple-linked lists based DOM implementation. 项目地址: https://gitcode.com/gh_mirrors/li/linkedom 在现代Web开发中,DOM解析和操作性能直接影响应用响应速度。Lin…...