如何在 Elasticsearch 中使用 Openai Embedding 进行语义搜索
随着强大的 GPT 模型的出现,文本的语义提取得到了改进。 在本文中,我们将使用嵌入向量在文档中进行搜索,而不是使用关键字进行老式搜索。
什么是嵌入 - embedding?
在深度学习术语中,嵌入是文本或图像等内容的数字表示。 由于每个深度学习模型的输入都应该是数字,因此要使用文本来训练模型,我们应该将其转换为一种数字格式。
有多种算法可以将文本转换为 n 维数字数组。 最简单的算法称为“Bag Of Word”,该算法中 n 是语料库中唯一单词的数量。 该算法只是简单地统计文本中出现的单词数量,并形成一个数组来表示它。
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> corpus = [
... 'This is the first document.',
... 'This document is the second document.',
... 'And this is the third one.',
... 'Is this the first document?',
... ]
>>> vectorizer = CountVectorizer()
>>> X = vectorizer.fit_transform(corpus)
>>> vectorizer.get_feature_names_out()
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third','this'], ...)
>>> print(X.toarray())
[[0 1 1 1 0 0 1 0 1][0 2 0 1 0 1 1 0 1][1 0 0 1 1 0 1 1 1][0 1 1 1 0 0 1 0 1]]这种表示形式不够丰富,无法从文本中提取语义和含义。 由于变换器的强大功能,模型可以学习嵌入。 Openai 提供了嵌入 API 来计算文本的嵌入数组。 该表示可以存储在矢量数据库中以供搜索。
Openai 嵌入 API
要使用 openai,我们需要在 openai 网站上生成一个 API 密钥。 为此,我们需要在 “View API Keys” 页面中注册并生成一个新密钥。
请记住:该密钥只会显示一次,因此请保存以供以后使用。
要检索文本嵌入,我们应该使用模型和文本调用 openai 嵌入 API。
{"input": "The food was delicious and the waiter...","model": "text-embedding-ada-002"
}输入是我们要计算嵌入数组的文本,模型是嵌入模型的名称。 Openai 对于此链接中提供的嵌入模型有多种选择。 在本文中,我们将使用默认的 “text-embedding-ada-002”。 为了调用 API,我们在 python 中使用以下脚本。
import os
import requestsheaders = {'Authorization': 'Bearer ' + os.getenv('OPENAI_API_KEY', ''),'Content-Type': 'application/json',
}json_data = {'input': 'This is the test text','model': 'text-embedding-ada-002',
}response = requests.post('https://api.openai.com/v1/embeddings',headers=headers,json=json_data)
result = response.json()嵌入的响应将类似于:
{"object": "list","data": [{"object": "embedding","embedding": [0.0023064255,-0.009327292,.... (1536 floats total for ada-002)-0.0028842222,],"index": 0}],"model": "text-embedding-ada-002","usage": {"prompt_tokens": 8,"total_tokens": 8}
}result['data']['embedding'] 是给定文本的嵌入向量。 ada-002 模型的向量大小为 1536 个浮点数,输入的最大标记为 8191 个标记。
存储和搜索
有多种数据库选择来存储嵌入向量。 在本文中,我们将探索 Elasticsearch 来存储和搜索向量。
Elasticsearch 有一个预定义的向量数据类型,称为 “密集向量”。 为了存储嵌入向量,我们需要创建一个索引,其中包括一个文本字段和一个嵌入向量字段。
PUT my_vector_index
{"mappings": {"properties": {"embedding": {"type": "dense_vector","dims": 1536},"text": {"type": "keyword"}}}
}对于 ada-002 模型,向量的维数应为 1536。 现在要查询该索引,我们需要熟悉不同类型的向量相似度得分。 余弦相似度是我们可以在 Elasticsearch 中使用的分数之一。 首先,我们需要计算搜索短语的嵌入向量,然后通过索引对其进行查询并获取 top-k 结果。
POST my_vector_index/_search
{"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "cosineSimilarity(params.query_vector, 'embedding') + 1.0","params": {"query_vector": [0.230, -0.120, 0.389, ...]}}}}
}当然,对于大规模部署,我们需要使用 aNN 搜索。请详细阅读 “Elasticsearch:在 Elastic Stack 8.0 中引入近似最近邻搜索”。
这将返回语义上与文本查询相似的文本。
结论
在本文中,我们探讨了新嵌入模型在文档中查找语义的强大功能。 你可以使用任何类型的文档,例如 PDF、图像、音频,并使用 Elasticsearch 作为语义相似性的搜索引擎。 该功能可用于语义搜索、推荐系统。
相关文章:
如何在 Elasticsearch 中使用 Openai Embedding 进行语义搜索
随着强大的 GPT 模型的出现,文本的语义提取得到了改进。 在本文中,我们将使用嵌入向量在文档中进行搜索,而不是使用关键字进行老式搜索。 什么是嵌入 - embedding? 在深度学习术语中,嵌入是文本或图像等内容的数字表示…...

世界第一ERP厂商SAP,推出类ChatGPT产品—Joule
9月27日,世界排名第一ERP厂商SAP在官网宣布,推出生成式AI助手Joule,并将其集成在采购、供应链、销售、人力资源、营销、数据分析等产品矩阵中,帮助客户实现降本增效。 据悉,Joule是一款功能类似ChatGPT的产品…...
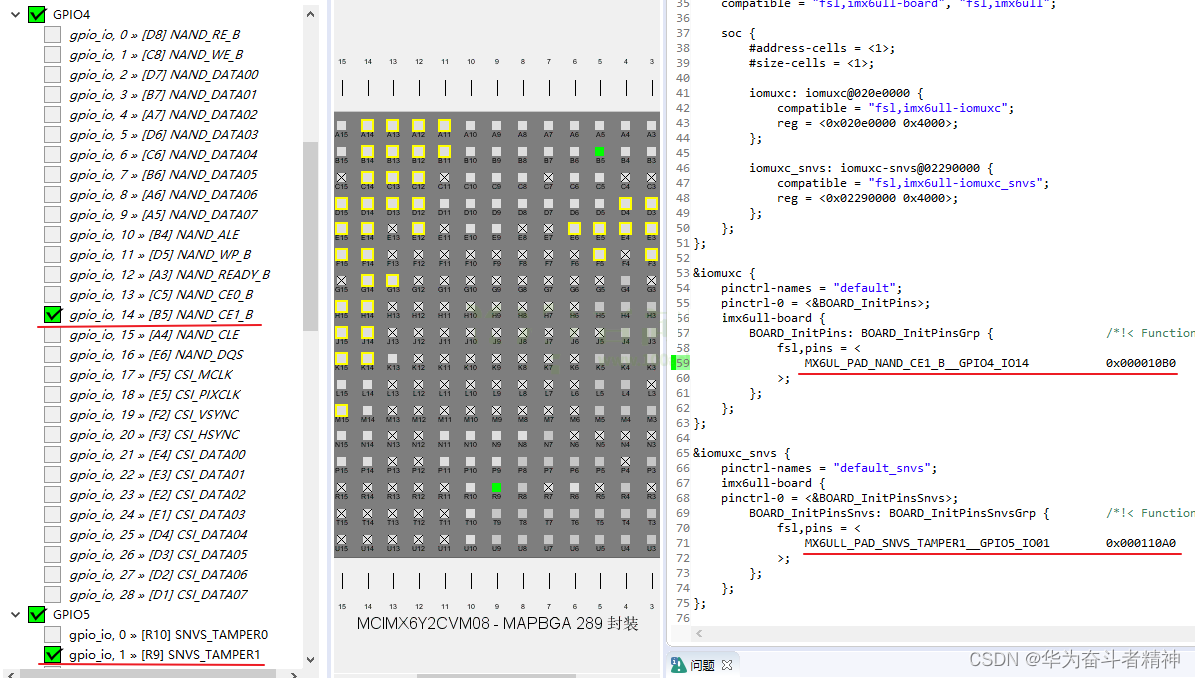
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③ 第十八章 Linux系统对中断的处理 ③18.5 编写使用中断的按键驱动程序 ③18.5.1 编程思路18.5.1.1 设备树相关18.5.1.2 驱动代码相关 18.5.2 先编写驱动程序18.5.2.1 从设备树获得 GPIO18.5.2.2 从 GPIO获得中断号18.5…...

【Python】返回指定时间对应的时间戳
使用模块datetime,附赠一个没啥用的“时间推算”功能(获取n天后对应的时间 代码: import datetimedef GetTimestamp(year,month,day,hour,minute,second,*,relativeNone,timezoneNone):#返回指定时间戳。指定relative时进行时间推算"""根…...
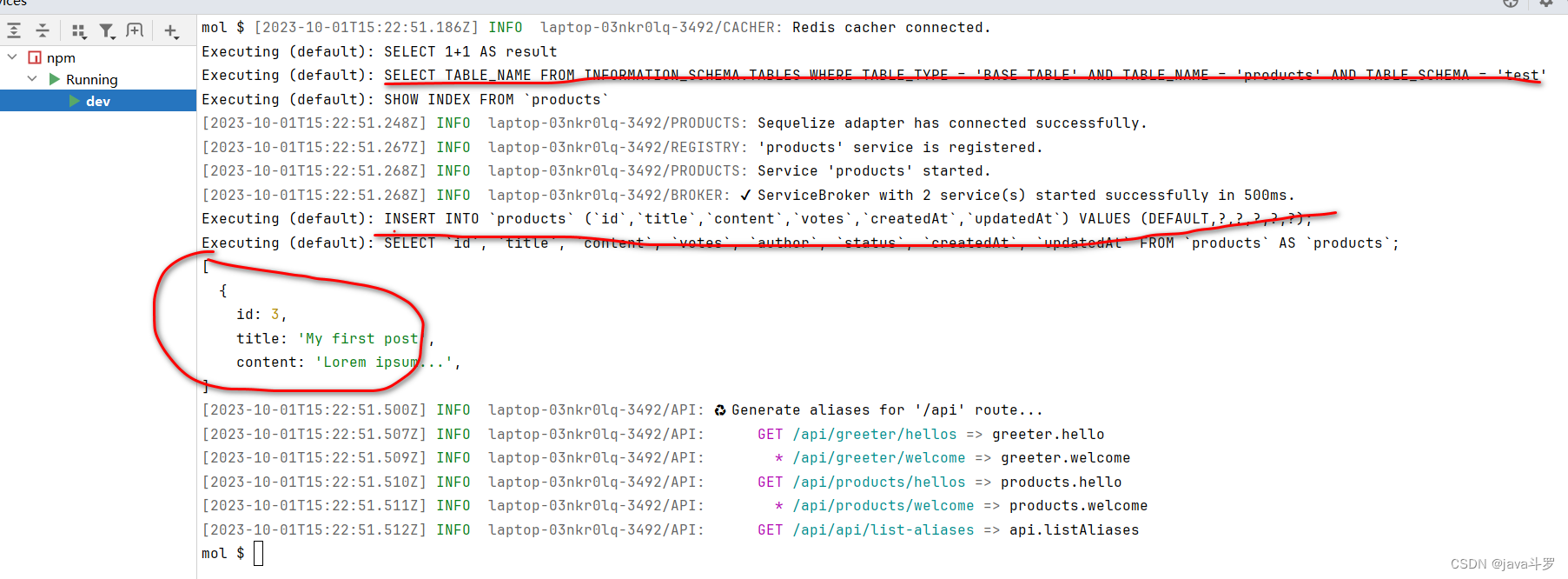
微服务moleculer03
1. Moleculer 目前支持SQLite,MySQL,MariaDB,PostgreSQL,MSSQL等数据库,这里以mysql为例 2. package.json 增加mysql依赖 "mysql2": "^2.3.3", "sequelize": "^6.21.3", &q…...

[React] react-router-dom的v5和v6
v5 版本既兼容了类组件(react v16.8前),又兼容了函数组件(react v16.8及以后,即hook)。v6 文档把路由组件默认接受的三个属性给移除了,若仍然使用 this.props.history.push(),此时pr…...
之mv)
Linux命令(91)之mv
linux命令之mv 1.mv介绍 linux命令mv是用来移动文件或目录,并且也可以用来更改文件或目录的名字 2.mv用法 mv [参数] src dest mv常用参数 参数说明-f强制移动,不提示 3.实例 3.1.重命名文件1.txt为ztj.txt 命令: mv 1.txt ztj.txt …...
C++ 强制类型转换(int double)、查看数据类型、自动决定类型、三元表达式、取反、
强制类型转换( int 与 double) #include <iostream> using namespace std;int main() {// 数据类型转换char c1;short s1;int n 1;long l 1;float f 1;double d 1;int p 0;int cc (int)c;// 注意:字符 转 整形时 是有问题的// “…...
Android自动化测试之MonkeyRunner--从环境构建、参数讲解、脚本制作到实战技巧
monkeyrunner 概述、环境搭建 monkeyrunner环境搭建 (1) JDK的安装不配置 http://www.oracle.com/technetwork/java/javase/downloads/index.html (2) 安装Python编译器 https://www.python.org/download/ (3) 设置环境变量(配置Monkeyrunner工具至path目彔下也可丌配置) (4) …...
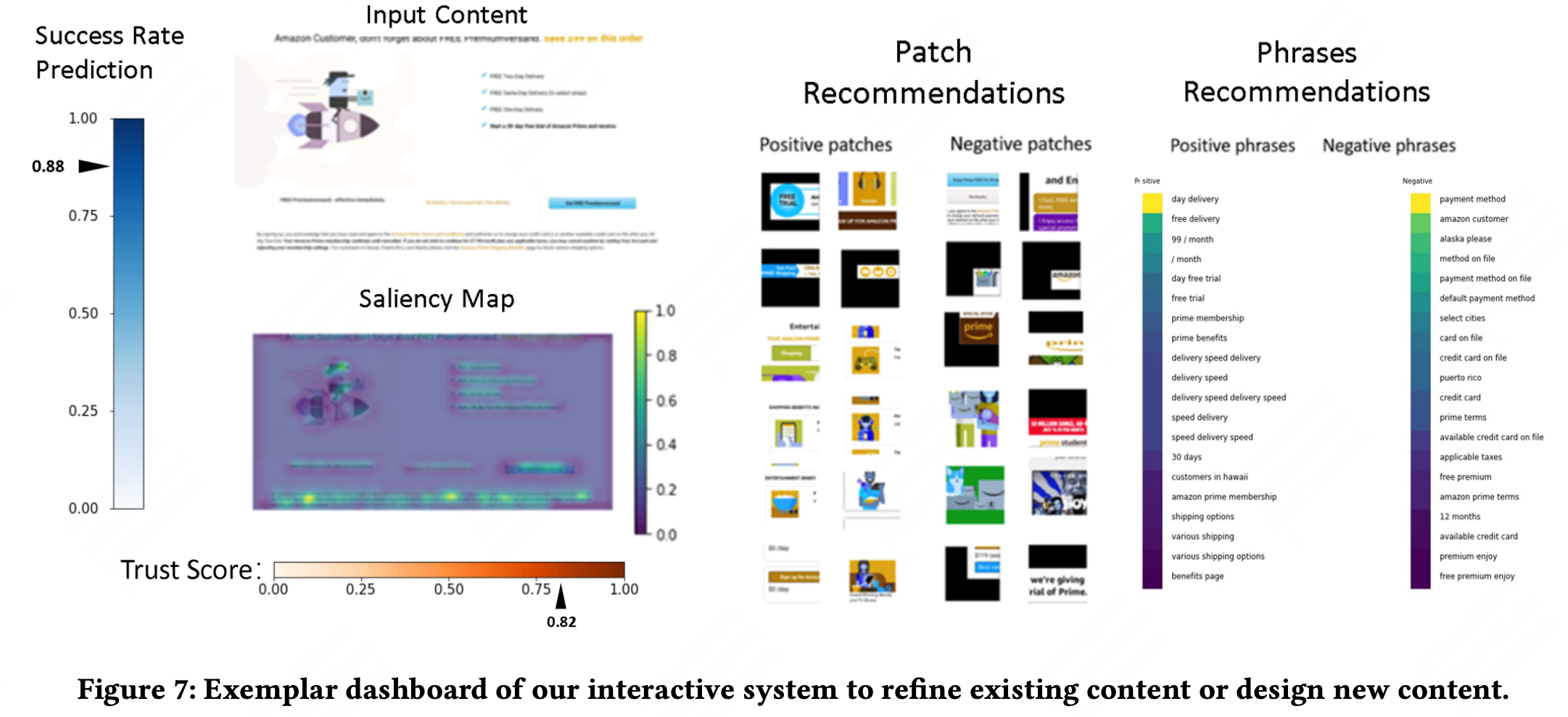
Neural Insights for Digital Marketing Content Design 阅读笔记
KDD-2023 很值得读的文章! 1 摘要 电商里,营销内容的实验,很重要。 然而,创作营销内容是一个手动和耗时的过程,缺乏明确的指导原则。 本文通过 基于历史数据的AI驱动的可行性洞察,来弥补 营销内容创作 和…...

BI神器Power Query(26)-- 使用PQ实现表格多列转换(2/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...

中间件中使用到的设计模式
本文记录阅读源码的过程中,了解/学习到中间件使用到的设计模式及具体运用的组件/功能点 1. 策略模式 1. Nacos2.x中grpc处理时通过请求type来进行具体Handler映射,找到对应处理器。 2. 模板模式 1. Nacos配置数据读取,内部数据源、外部数据…...

运用动态内存实现通讯录(增删查改+排序)
目录 前言: 实现通讯录: 1.创建和调用菜单: 2.创建联系人信息和通讯录: 3.初始化通讯录: 4.增加联系人: 5.显示联系人: 6.删除联系人: 编辑 7.查找联系人: …...
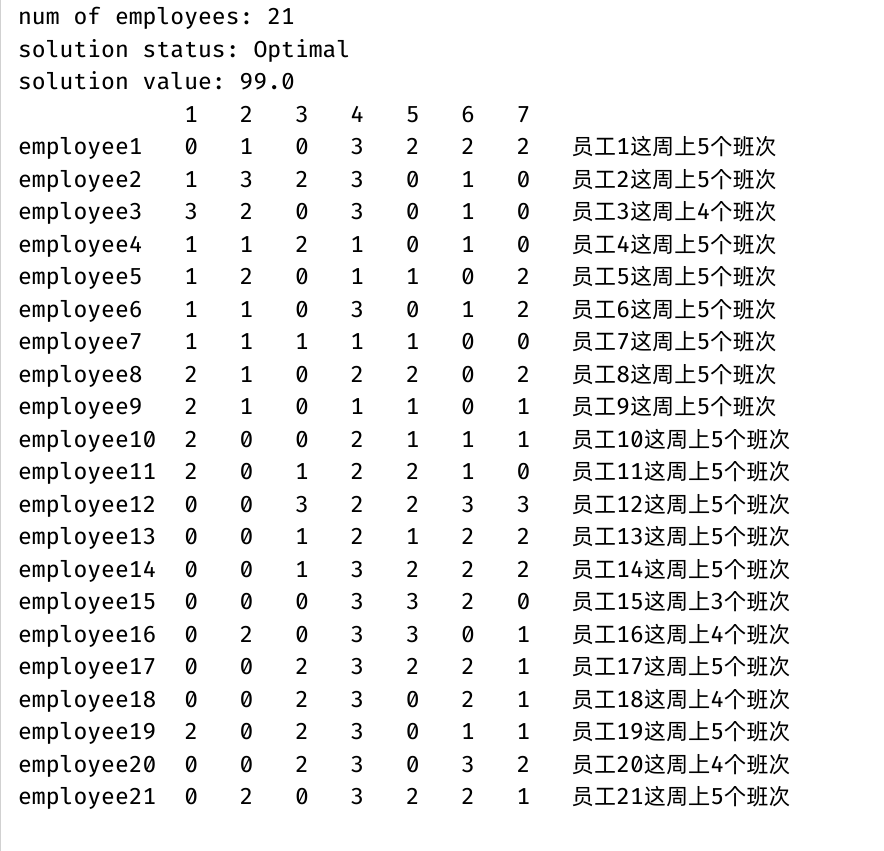
基于Cplex的人员排班问题建模求解(JavaAPI)
使用Java调用Cplex实现了阿里mindopt求解器的案例(https://opt.aliyun.com/platform/case)人员排班问题。 这里写目录标题 人员排班问题问题描述数学建模编程求解(CplexJavaAPI)求解结果 人员排班问题 随着现在产业的发展&#…...

理解Go中的数据类型
引言 数据类型指定了编写程序时特定变量存储的值的类型。数据类型还决定了可以对数据执行哪些操作。 在本文中,我们将介绍Go的重要数据类型。这不是对数据类型的详尽研究,但将帮助您熟悉Go中可用的选项。理解一些基本的数据类型能让你写出更清晰、性能…...
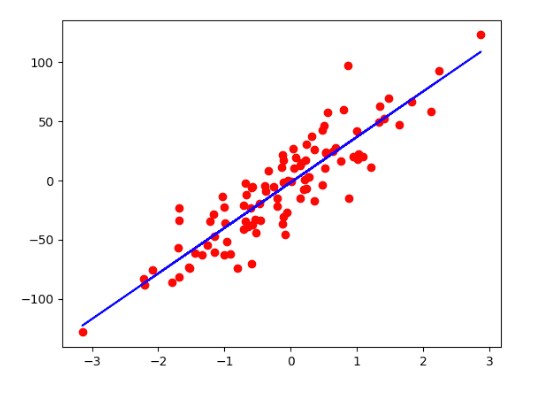
【人工智能导论】线性回归模型
一、线性回归模型概述 线性回归是利用函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。简单来说,就是试图找到自变量与因变量之间的关系。 二、线性回归案例:房价预测 1、案例分析 问题:现在要预测140平方的房屋的价格&…...
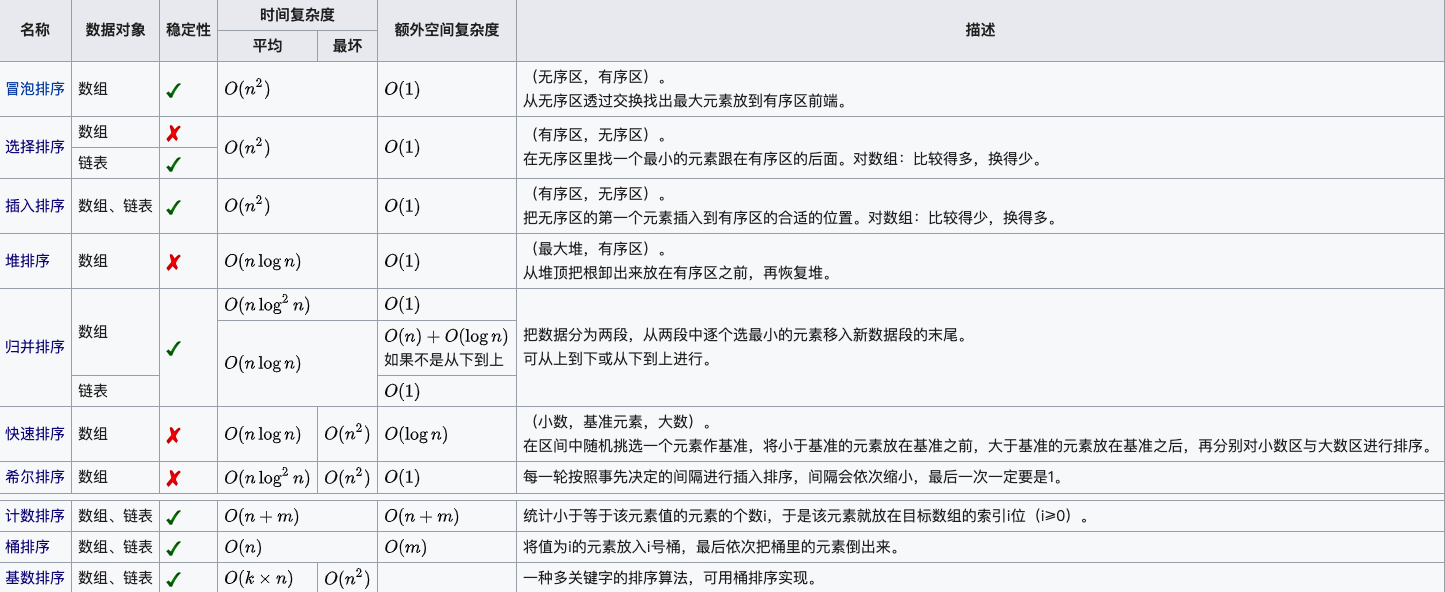
十大常见排序算法详解(附Java代码实现和代码解析)
文章目录 十大排序算法⛅前言🌱1、排序概述🌴2、排序的实现🌵2.1 插入排序🐳2.1.1 直接插入排序算法介绍算法实现 🐳2.1.2 希尔排序算法介绍算法实现 🌵2.2 选择排序🐳2.2.1 选择排序算法介绍算…...
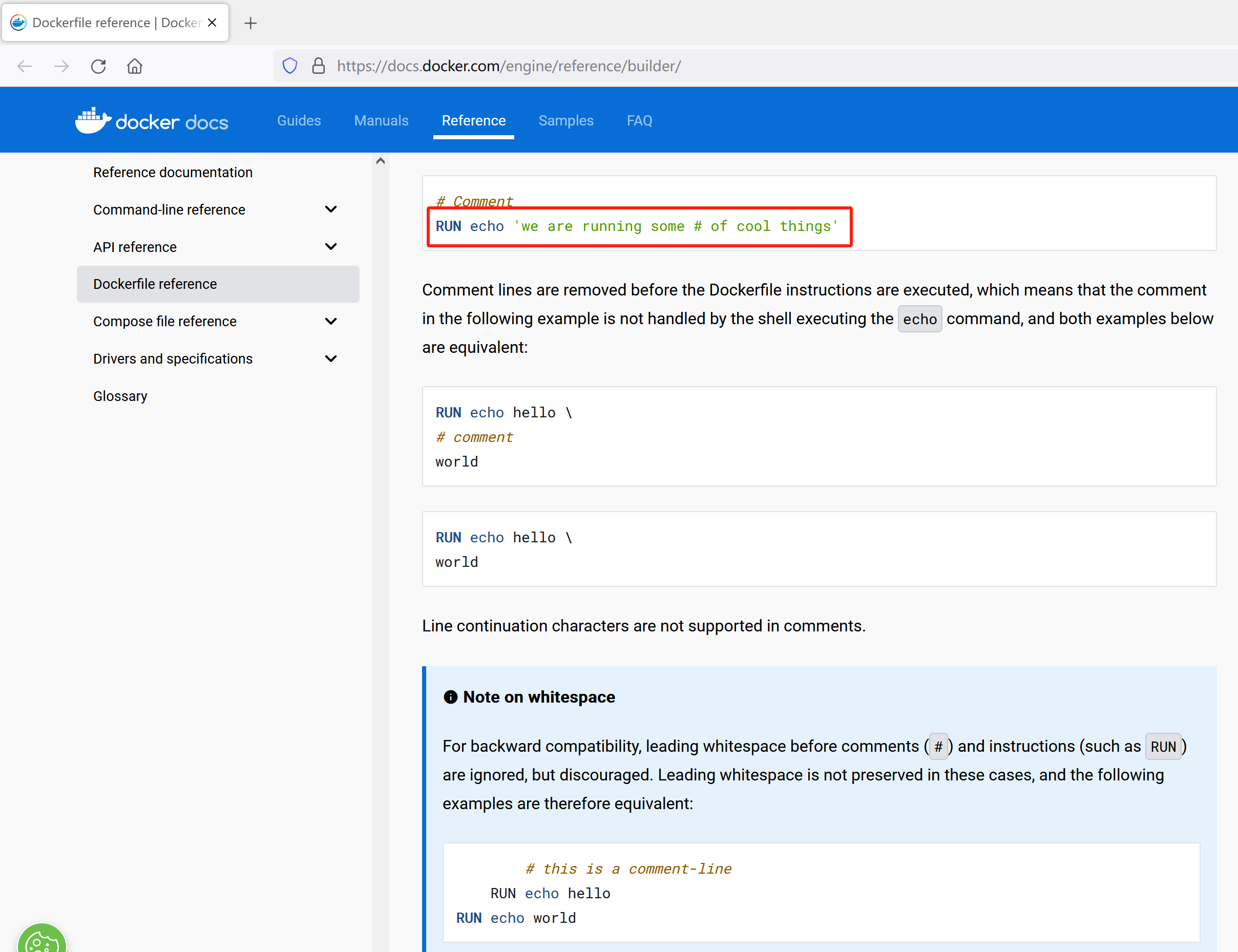
在Ubuntu上通过Portainer部署微服务项目
这篇文章主要记录自己在ubuntu上部署自己的微服务应用的过程,文章中使用了docker、docker-compose和portainer,在部署过程中遇到了不少问题,因为博主也是初学docker-compose,通过这次部署实战确实有所收获,在这篇文章一…...
软件测试基础学习
注意: 各位同学们,今年本人求职目前遇到的情况大体是这样了,开发太卷,学历高的话优势非常的大,公司会根据实际情况考虑是否值得培养(哪怕技术差一点);学历稍微低一些但是技术熟练的…...

移动手机截图,读取图片尺寸
这个代码的设计初衷是为了解决图片处理过程中的一些痛点。想象一下,我们都曾遇到过这样的情况:相机拍摄出来的照片、网络下载的图片,尺寸五花八门,大小不一。而我们又渴望将它们整理成一套拥有统一尺寸的图片,让它们更…...

QQ音乐加密文件解密终极指南:qmcdump实战深度解析
QQ音乐加密文件解密终极指南:qmcdump实战深度解析 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否遇到…...

为什么92%的DeepSeek私有化部署在K8s上遭遇OOMKilled?——GPU内存隔离、vLLM适配与cgroups v2调优三重解法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek私有化部署的Kubernetes现状与OOMKilled困局 当前,DeepSeek系列大模型在企业私有化场景中广泛采用Kubernetes进行容器化编排部署。然而,实际落地过程中,内存…...

这家头部智能家居品牌是如何让全渠道电商闭环运营落地?
在电商渠道愈发多元的当下,让很多企业陷入 “数据多却用不好” 的困境。这不是个别现象,而是绝大多数全渠道电商企业正在经历的“成长烦恼”。今天,我们用一个真实案例,带您看看如何用一套系统,彻底告别这些噩梦。这家…...

工程师幽默竞赛:从技术梗到团队文化的创意表达
1. 项目概述:一场工程师的幽默竞赛如果你在电子工程行业待过一段时间,大概率在《EE Times》这样的行业媒体上,见过那种线条简洁、寓意深刻的单格漫画。漫画本身往往描绘一个充满电子元件、示波器或一脸困惑的工程师的实验室场景,但…...

Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册
Windows平台即时通讯消息保留技术深度解析:RevokeMsgPatcher企业级解决方案完全手册 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) …...

构建个人技能库:从代码片段到可复用技能单元的设计与实践
1. 项目概述:当代码遇上魔法,技能库的构建哲学在软件开发的日常里,我们常常会羡慕那些“魔法师”般的同事:他们似乎总能信手拈来一段代码,优雅地解决一个棘手问题;或者拥有一个私人的“百宝箱”,…...

基于Python与aiogram构建多模型AI助手:集成GPT-4、Claude与Gemini的Telegram机器人开发实践
1. 项目概述:一个多模型AI助手的自研之路 最近在折腾一个挺有意思的玩意儿,我把它叫做“AIAssistantBot”。简单来说,这是一个跑在Telegram上的机器人,但它不是那种只会回复固定指令的“傻”机器人。它的核心是整合了市面上几家主…...

构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增
构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增 【免费下载链接】obsidian-template Starter templates for Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-template 在信息过载的时代,知识工作者面临的核心挑战…...

实战复盘:我是如何用Elastic Security+Zeek构建一个小型企业安全监控平台的
实战复盘:Elastic SecurityZeek构建小型企业安全监控平台 当企业规模扩张到50人以上时,网络资产和终端设备数量会呈现指数级增长。去年为某电商团队部署安全系统时,他们的CTO向我展示了一份令人不安的数据:平均每天遭遇23次暴力破…...

PCIe均衡参数测量实战:从8GT/s到32GT/s,示波器上的电压怎么量?
PCIe均衡参数测量实战:从8GT/s到32GT/s的示波器操作指南 在高速串行通信领域,PCIe接口的均衡参数测量是确保信号完整性的关键环节。随着数据传输速率从8GT/s跃升至32GT/s,工程师面临的测量挑战也呈指数级增长。本文将深入探讨如何利用示波器准…...