NEON优化:性能优化经验总结
NEON优化:性能优化经验总结
- 1. 什么是 NEON
- Arm Adv SIMD 历史
- 2. 寄存器
- 3. NEON 命名方式
- 4. 优化技巧
- 5. 优化 NEON 代码(Armv7-A内容,但区别不大)
- 5.1 优化 NEON 汇编代码
- 5.1.1 Cortex-A 处理器之间的 NEON 管道差异
- 5.1.2 内存访问优化
Reference:
- NEON优化:性能优化经验总结
- NEON官方内联函数
- Arm NEON programming quick reference
- Learn the architecture - Neon programmers’ guide

1. 什么是 NEON
NEON 技术是用于 Arm Cortex-A 系列处理器的先进 SIMD(单指令多数据)架构。它可以加速多媒体和信号处理算法,如视频编码器/解码器、2D/3D图形、游戏、音频和语音处理、图像处理、电话和声音。
NEON 指令执行“打包 SIMD”处理:
- 寄存器被认为是相同数据类型元素的向量
- 数据类型支持:带符号/无符号 8 8 8 位, 16 16 16 位, 32 32 32 位, 64 64 64 位,ARM 32 32 32位平台上的单精度浮点数,ARM 64 64 64位平台上的单精度浮点数和双精度浮点数。
- 指令在所有通道中执行相同的操作
Arm Adv SIMD 历史
| Armv6 | Armv7-A | Armv8-A AArch64 |
|---|---|---|
| SIMD extension | NEON | NEON |
| 在32位通用ARM寄存器上操作 | 独立的寄存器库,32x64位NEON寄存器 | 独立的寄存器库,32x128位NEON寄存器 |
| 8位或16位整数 | 8/16/32/64位整数 | 8/16/32/64位整数 |
| 每条指令进行2x16位/4x8位操作 | 单精度浮点数 | 单精度浮点数、双精度浮点数 |
| – | 每条指令最多16x8位操作(16x4吧,待确认) | 每条指令最多16x8位操作 |
2. 寄存器
Armv7-A 和 AArch32 具有相同的通用 Arm 寄存器 - 16 16 16 x 32 32 32 位通用 Arm 寄存器(R0-R15)。
Armv7-A 和 AArch32 具有 32 x 64 位 NEON 寄存器(D0-D31)。这些寄存器也可以看作是 16 × 128 位寄存器(Quad-word, Q0-Q15)。每个 Q0-Q15 寄存器映射到一对D寄存器,如下图所示。
 相比之下,AArch64 具有 31 31 31 个 64 64 64 位通用 Arm 寄存器和 1 1 1 个具有不同名称的特殊寄存器,这取决于使用它的上下文。这些寄存器可以被看作是 31 31 31 个 64 64 64 位寄存器(X0-X30)或 31 31 31 个 32 32 32 位寄存器(W0-W30)。
相比之下,AArch64 具有 31 31 31 个 64 64 64 位通用 Arm 寄存器和 1 1 1 个具有不同名称的特殊寄存器,这取决于使用它的上下文。这些寄存器可以被看作是 31 31 31 个 64 64 64 位寄存器(X0-X30)或 31 31 31 个 32 32 32 位寄存器(W0-W30)。
AArch64 具有 32 32 32 x 128 128 128 位 NEON 寄存器(V0-V31,Vector Registers)。这些寄存器也可以看作是 32 32 32 位 Sn寄存器(Single-word Registers) 或 64 64 64 位 Dn寄存器(Double-word Registers)。
 (也就是说,V 寄存器有 128 位,D 寄存器 64 位,S寄存器 32 位,可以将 V 寄存器拆开使用)
(也就是说,V 寄存器有 128 位,D 寄存器 64 位,S寄存器 32 位,可以将 V 寄存器拆开使用)
3. NEON 命名方式
-
变量命名方式:
baseWxLxN_t- base:是基础数据类型
- W:是基础类型的宽度
- L:是向量的长度
- N:是向量数组的个数
- 如
uint8x16_t、uint8x16x3_t
-
函数命名方式:
ret v[p][q][r]name[u][n][q](args)- ret:返回值类型
- v:表示vector
- q:饱和运算,溢位后,为自动限制在数据类型的最大范围内
- r:圆整操作
- name:SIMD指令名称
- u:unsigned
- n:narrow
- q:做后缀表示128位满位宽寄存器运算 quarter*32
4. 优化技巧
-
热点函数涉及到大量 IO 读写操作时,数据的内存地址尽量与 NEON 数组或系统位数对齐,如32位对齐,可降低访问开销;
-
重点优先搞 NEON 指令并行计算,能大幅降低开销;
-
大部分的 NEON 问题会出在存取、移动指令的滥用、混乱使用上(neon的寄存器和普通arm的寄存器是分开,也就是说arm的普通指令和neon指令之间不可以有过多的数据交换,但是sse没有这个限制?待验证);
-
for循环:- 如
for (b = 0; b < num; b++): - 可改成
for (b = 0; b < num - 3; b += 4); - 或者
for (b = num - 1; b >= 3; b -= 4); - 需注意结尾不能整除的几个还是用非SIMD方式计算:
- 原始:for (i = 0; i < size; i++);
- 并行:for (i = 0; i < size - 3; i += 4);
- 扫尾:for (; i < size; i ++)。
- 如
-
数组索引取值:
- 数组索引以及索引内部涉及运算的,尽量换成指针偏移加减来做;
- 避免大范围索引跳跃,减少 cache miss。
-
内存使用:
- 优先用局部变量,而非 malloc 堆内存,减少 cache miss;
- 针对具体变量类型,手动 for 循环并行拷贝值,可能比 memcpy() 函数更高效,因为 memcpy 内部还涉及大量判断,以保证平台兼容性;
- 用NEON指令时,4 路运算的数组(128位=16字节),内存地址最好要 16 字节对齐。
-
指令运算
- 矩阵乘场景,在不大幅增加寄存器变量的前提下,外部的A也最好并行多读几路数据进来,跟B的各列运算,减少B各列的读取次数;
- 乘加指令,add 和 mul 可以合并为 mla,一条指令完成乘加操作。
-
C 语言编码级考虑
- C 语言中一条事件的处理函数尽可能在一个源文件中(便于编译器自动向量化);
switch比if else快,而且代码整洁。
-
深入理解计算机系统
- 组织代码结构,善用 CPU 缓存,数据段/代码段连续可以提高 CPU 缓存命中率;
- 极简函数时,尽量 inline 展开,减少函数调用栈的开销;
- 消除不必要的存储器引用,如 for 循环中 *dest = *dest - nums[i],可用中间变量替换 *dest,for 循环后再赋值给 *dest,可减少 for 内的一次读写操作;
- 简单的循环展开,编译器可以自己完成,优化选项 O2 及以上,或者命令 -funroll-loops(O2 及以上自带),可调用 gcc 进行循环展开;
- 能用整型不用浮点,整数乘法/加法和浮点加法,只用一个周期,浮点乘法需要2个周期。
-
NEON 与 SSE 在寄存器处理数据时有一些区别。在 NEON 中,通常需要先将要处理的数据加载到 NEON 寄存器,然后执行 SIMD 操作。这与 SSE 有一些不同,因为 SSE 寄存器(XMM 寄存器)可以直接与内存交互(这一步可能格外耗时,需要特别注意)。在 NEON 中,加载数据到 NEON 寄存器通常包括以下步骤:
- 从内存加载数据到通用寄存器(通常是ARM通用寄存器)。
- 将数据从通用寄存器传送到 NEON 寄存器。
然后,您可以在 NEON 寄存器上执行 SIMD 操作,例如矢量加法、矢量乘法等。
这与 SSE 不同,因为 SSE 寄存器可以直接从内存加载数据,而不需要中间步骤。这可以在 SSE 指令中实现,而不需要将数据先加载到通用寄存器中。
总之,NEON 需要额外的步骤来加载数据到寄存器,然后才能进行 SIMD 操作,而 SSE 可以更直接地在寄存器中操作数据。这是因为不同架构和指令集设计的差异。
5. 优化 NEON 代码(Armv7-A内容,但区别不大)
5.1 优化 NEON 汇编代码
考虑处理器如何集成 NEON 技术的实现定义方面,因为针对特定处理器优化的指令序列可能在不同的处理器上具有不同的时序特征,即使 NEON 指令周期时序相同。
为了从手写的 NEON 代码中获得最佳性能,有必要了解一些底层硬件特性。特别是,程序员应该意识到流水线和调度问题、内存访问行为和调度危害。
5.1.1 Cortex-A 处理器之间的 NEON 管道差异
Cortex-A8 和 Cortex-A9 处理器共享相同的基本 NEON 管道,尽管在如何将其集成到处理器管道中存在一些差异。Cortex-A5 处理器包含一个完全兼容的简化 NEON 执行管道,但它是为尽可能最小和最低功耗的实现而设计的。
5.1.2 内存访问优化
TLB(Translation Lookaside Buffer) 是计算机系统中的一种硬件缓存,用于加速虚拟地址到物理地址的转换过程。TLB 的每个条目称为 TLB entry(TLB条目),它存储了一组虚拟地址和相应的物理地址之间的映射关系。TLB 通常位于 CPU 内部,用于提高内存访问的速度。
当程序执行时,CPU 需要将虚拟地址(由程序使用)转换为物理地址(在内存中实际存储数据的地址)。这个地址转换通常由操作系统的内存管理单元(MMU)来执行。MMU 将虚拟地址映射到物理地址,并在需要时将这些映射关系存储在 TLB 中,以便以后的访问可以更快地完成,而无需再次执行昂贵的地址转换操作。
TLB entry 通常包括以下信息:
- 虚拟地址(Virtual Address):程序使用的地址。
- 物理地址(Physical Address):在内存中实际存储数据的地址。
- 标志位(Flags):包括权限信息(例如,读、写、执行权限)和其他控制信息。
当 CPU 需要访问内存中的数据时,它首先查看 TLB 来查找虚拟地址和物理地址之间的映射关系。如果找到了匹配的 TLB entry,那么物理地址将用于访问内存,这将显著提高内存访问速度。如果没有找到匹配的 TLB entry,CPU 将向 MMU 请求执行地址转换,并将结果存储在 TLB 中以供将来使用。
总之,TLB entry 是 TLB 中存储的虚拟地址到物理地址映射的单元,用于加速计算机内存访问的过程。这有助于提高系统的性能和效率。
L1 和 L2 通常是指计算机的缓存层次结构中的两个不同级别的缓存:
L1 Cache(一级缓存):
L1 缓存是最接近 CPU 核心的缓存级别,通常位于 CPU 内部或非常靠近 CPU 核心。它是一个小而快速的缓存,用于存储最常用的数据和指令,以提高 CPU 的性能。
L1 缓存分为两个部分,分别是指令缓存(Instruction Cache)和数据缓存(Data Cache)。指令缓存存储 CPU 指令,而数据缓存存储处理数据。
由于其靠近 CPU 核心的位置,L1 缓存通常具有非常低的访问延迟。L2 Cache(二级缓存):
L2 缓存位于 L1 缓存之上,通常在 CPU 内部或者与 CPU 核心相对较近,但比 L1 缓存大。
它也用于存储数据和指令,但比 L1 缓存更大,能够容纳更多的数据。
L2 缓存的访问延迟通常比 L1 缓存稍高,但仍然比主内存的访问延迟要低。
有些计算机架构具有多个 L2 缓存层,通常是 L2 和 L3,L3 通常比 L2 更大,但访问延迟更高。
这两个缓存级别的存在是为了提高计算机的性能。L1 缓存专注于存储最常用的数据和指令,因此它们可以更快地被 CPU 核心访问。如果数据不在 L1 缓存中,CPU 将在 L2 缓存中查找,如果还不在,那么将从主内存中获取数据。通过在多个缓存层之间进行数据访问,计算机可以更有效地管理内存访问,从而提高整体性能。
NEON 单元很可能会处理大量数据,例如数字图像。一个重要的优化是确保算法以最适合缓存的方式访问数据。这样可以从 L1 和 L2 缓存中获得最大的命中率(hit rate)。考虑活动内存位置的数量也很重要。在 Linux 下,每个 4KB 的页面都需要一个单独的 TLB 条目。Cortex-A9 处理器有多个 32 32 32 个元素的 micro-TLB 和一个 128 128 128 个元素的主 TLB,之后它将开始使用 L1 缓存来加载页表条目(page table entry)。一种典型的优化是安排算法以适当的大小处理图像数据,以最大限度地提高缓存和 TLB 命中率。
支持 交错(interleaving) 和 反交错(de-interleaving) 的指令可以为性能改进提供很大的空间。VLD1 从内存加载寄存器,没有去交错。然而,其他 VLDn 操作使我们能够加载、存储和反交错包含两个、三个或四个相同大小的 8 8 8、 16 16 16 或 32 32 32 位元素的结构。VLD2 加载两个或四个寄存器,去交错的偶数和奇数元素。例如,这可以用于分割左通道和右通道立体声音频数据,如下图所示。类似地,VLD3 可用于将 RGB 像素分割为单独的通道,相应地,VLD4 可用于 ARGB 或 CMYK 图像。
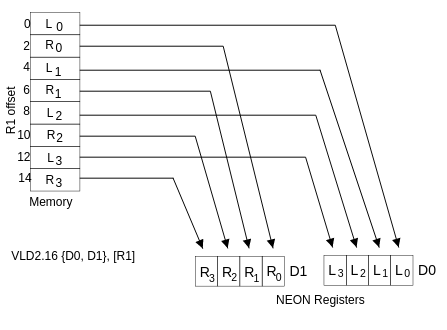
上图显示了用 VLD2.16( 16 16 16 字节) 从 R1 指向的内存中加载两个 NEON 寄存器。这在第一个寄存器中产生 4 4 4 个 16 16 16 位元素,在第二个寄存器中产生 4 4 4 个 16 16 16 位元素,相邻的成对左值和右值被分隔到每个寄存器中。
相关文章:
NEON优化:性能优化经验总结
NEON优化:性能优化经验总结 1. 什么是 NEONArm Adv SIMD 历史 2. 寄存器3. NEON 命名方式4. 优化技巧5. 优化 NEON 代码(Armv7-A内容,但区别不大)5.1 优化 NEON 汇编代码5.1.1 Cortex-A 处理器之间的 NEON 管道差异5.1.2 内存访问优化 Reference: NEON优…...

C++ 并发编程实战 第九章
目录 9.1 线程池 9.1.1 最简易可行的线程池 9.1.2 等待提交给线程池的任务完成运行 9.1.3等待其他任务完成的任务 9.1.4 避免任务队列上的争夺 9.1.5 任务窃取 9.2 中断线程 9.2.1 发起一个线程,以及把他中断 9.2.2 检测线程是否被中断 9.2.3 中断条件变…...
【Java】super 关键字用法
目录 this与super区别 1.访问成员变量-示例代码 继承中构造方法的访问特点 2.访问构造方法-示例代码: 继承中成员方法访问特点 3.访问成员方法-示例代码: super 关键字的用法和 this 关键字相似 this : 代表本类对象的引用super : 代表父类存储空间…...

前端笔试题总结,带答案和解析
1. 执行以下程序,输出结果为() var x 10; var y 20; var z x < y ? x:y; console.log(xx;yy;zz);A x11;y21;z11 B x11;y20;z10 C x11;y21;z10 D x11;y20;z11 初始化x的值为10,y的值为20,x < y返回结果为tru…...

Omniverse Machinima
Omniverse Machinima App | NVIDIA Omniverse Machinima 是 NVIDIA 推出的一款实时动画创作工具,可用于在虚拟世界中制作和操纵角色及其环境。该工具使用 Universal Scene Description (USD) 作为其通用场景描述格式,可与多种 3D 建模、动画和渲染应用程…...

【测试人生】游戏业务测试落地精准测试专项的一些思路
精准测试在互联网领域有广泛的应用。以变更为出发点,通过对变更内容进行分析,可以确定单次变更具体涉及到哪些模块和功能点,以及是否存在夹带风险,从而从QA的视角,可以知道哪些功能模块需要做测试,以及哪些…...

Redis 数据类型底层原理
String 内部编码有三种:int、embstr、raw int:如果一个字符串对象保存的是整数值,并且这个整数值可以用 long类型来表示(不超过 long 的表示范围,如果超过了 long 的表示范围,那么按照存储字符串的编码来存储…...
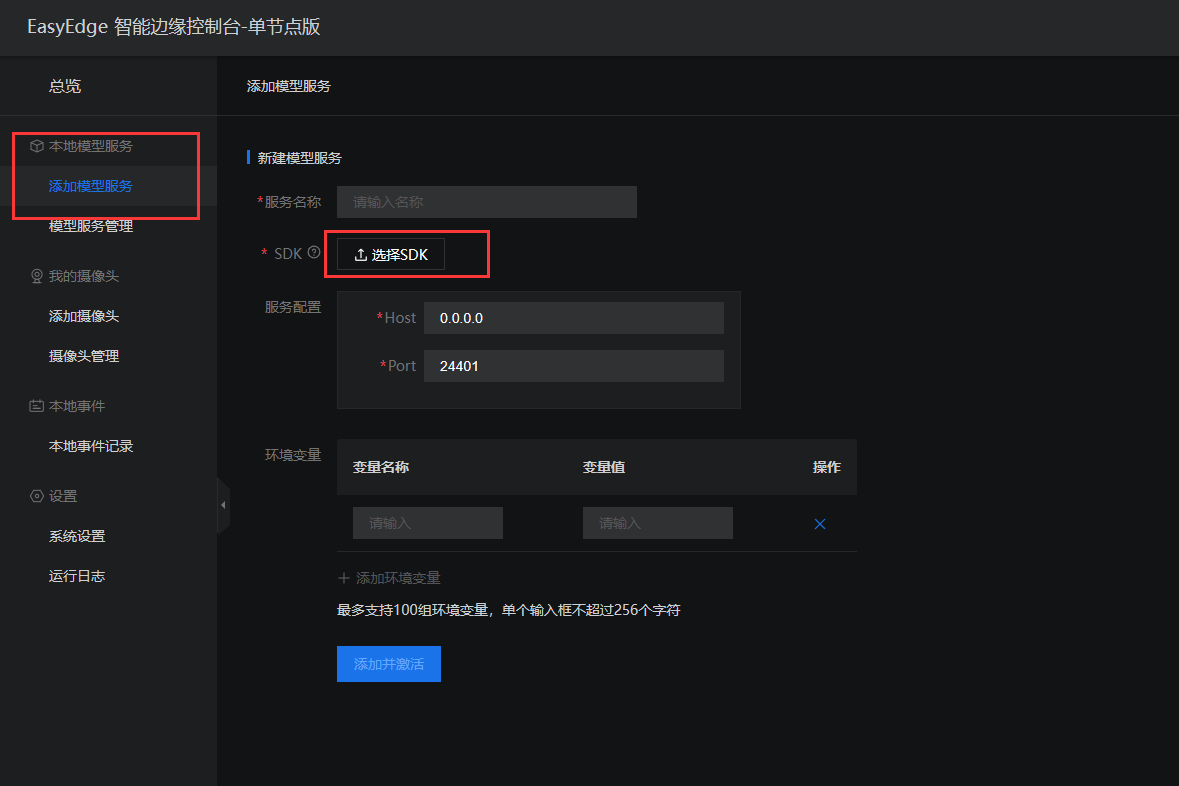
EasyEdge 智能边缘控制台通过sdk发布应用
离线部署SDK生成 模型部署完成后会出现下载SDK的按钮,点击按钮下载SDK并保存好SDK。 进入EasyDL官网的技术文档 安装智能边缘控制台 跟着教程,完成安装:点此链接 树莓派4b是Linux arm64的架构,点击对应的链接进行下载。 下载完成…...

centos软件设置开机启动的方式
以下以redis作为案例: 开机启动方式一 [Unit] Descriptionredis-server Afternetwork.target [Service] Typeforking # 这里需要修改自己的配置文件 ExecStart/usr/local/bin/redis-server /etc/redis/redis.conf PrivateTmptrue [Install] WantedBymulti-user.tar…...
二叉树和堆
二叉树不存在度大于2的结点(每个根最多只有两个子结点)二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树 两个特殊的二叉树——(满二叉树,完全二叉树) 满二叉树——每个根结点都有左右…...
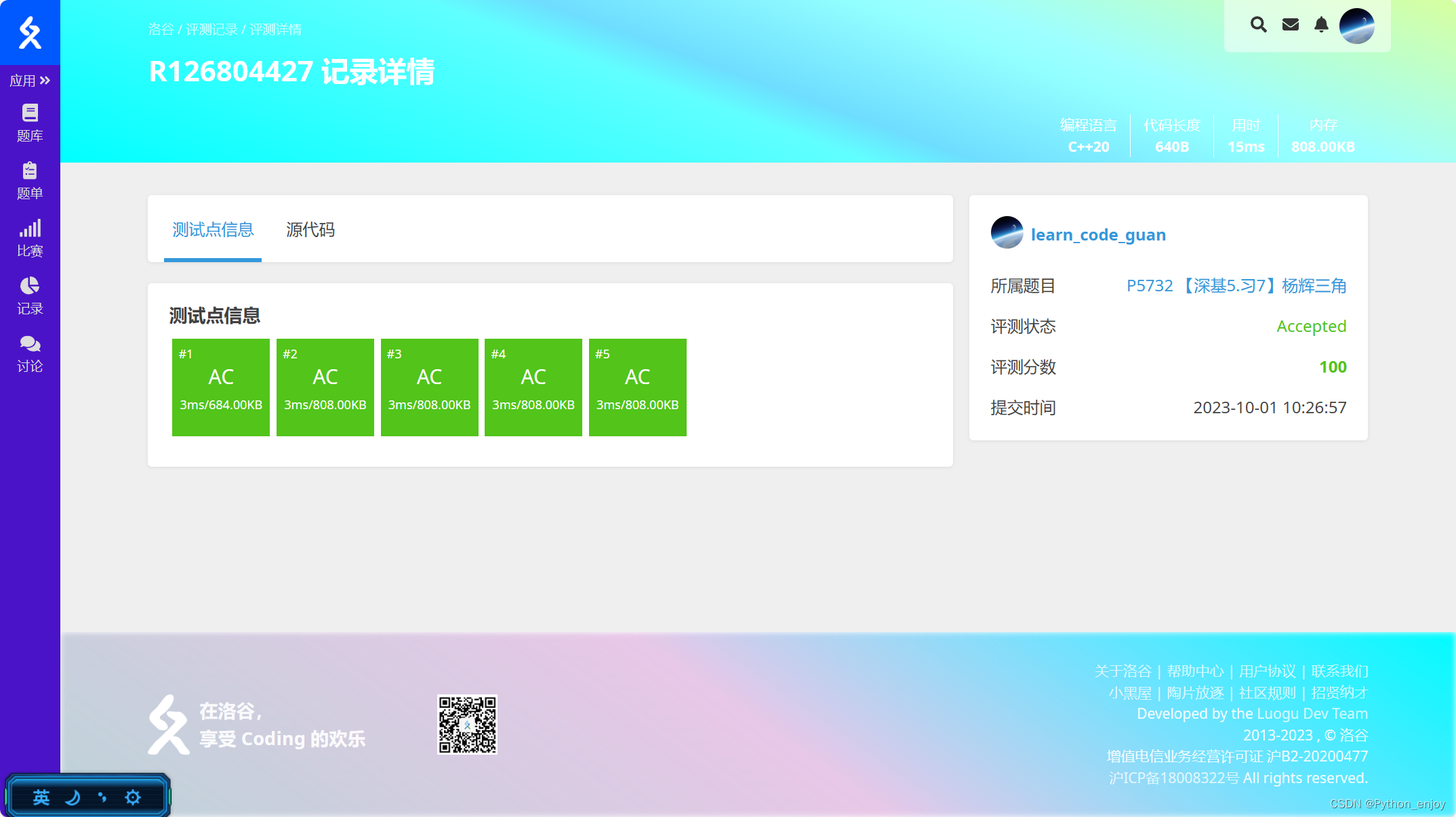
洛谷P5732 【深基5.习7】杨辉三角题解
目录 题目【深基5.习7】杨辉三角题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1传送门 代码解释亲测 题目 【深基5.习7】杨辉三角 题目描述 给出 n ( n ≤ 20 ) n(n\le20) n(n≤20),输出杨辉三角的前 n n n 行。 如果你不知道什么是杨辉三角…...
Docker 精简安装 Nacos 2.2.1 单机版本
准备工作: 1)已安装docker 2)数据库准备,演示使用MySql5.7版本 1、拉取 [rootTseng-HW ~]# docker pull nacos/nacos-server:v2.2.1 v2.2.1: Pulling from nacos/nacos-server 2d473b07cdd5: Already exists 77c5a601c050: Pul…...
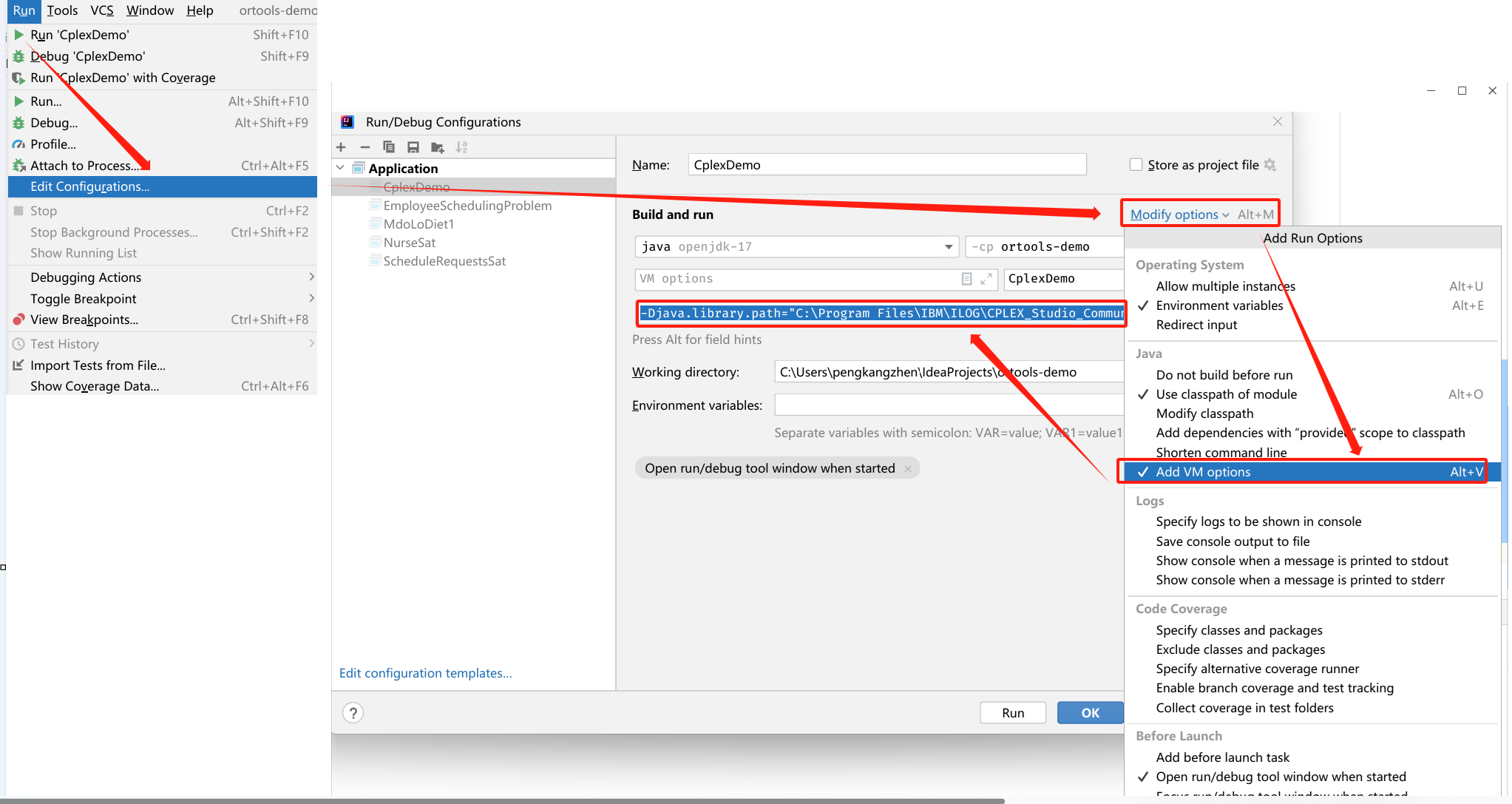
IntelliJ IDEA配置Cplex12.6.3详细步骤
Cplex12.6.3版IntelliJ IDEA配置详细步骤 一、Cplex12.6.3版下载地址二、Cplex安装步骤三、IDEA配置CPLEX3.1 添加CPLEX安装目录的cplex.jar包到项目文件中3.2 将CPLEX的x64_win64文件夹添加到IDEA的VM options中 四、检查IDEA中Cplex是否安装成功卸载Cplex 一、Cplex12.6.3版下…...

2023 年最佳多 GPU 深度学习系统指南
动动发财的小手,点个赞吧! 本文[1]提供了有关如何构建用于深度学习的多 GPU 系统的指南,并希望为您节省一些研究时间和实验时间。 1. GPU 让我们从有趣(且昂贵)的部分开始! 购买 GPU 时的主要考虑因素是&am…...
Kotlin异常处理runCatching,getOrNull,onFailure,onSuccess(1)
Kotlin异常处理runCatching,getOrNull,onFailure,onSuccess(1) fun main(args: Array<String>) {var s1 runCatching {1 / 1}.getOrNull()println(s1) //s11,打印1println("-")var s2 ru…...

【深入探究人工智能】:历史、应用、技术与未来
深入探究人工智能 前言人工智能的历史人工智能的应用人工智能的技术人工智能的未来当代的人工智能产物结语🍀小结🍀 🎉博客主页:小智_x0___0x_ 🎉欢迎关注:👍点赞🙌收藏✍️留言 &am…...
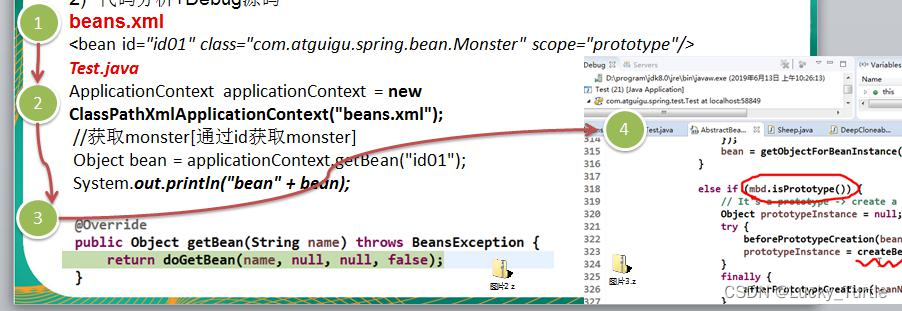
【设计模式】五、原型模式
文章目录 概述示例传统的方式的优缺点原型模式原理结构图-uml 类图 原型模式解决克隆羊问题的应用实例Sheep类实现clone()运行原型模式在 Spring 框架中源码分析 深入讨论-浅拷贝和深拷贝浅拷贝的介绍 小结 概述 示例 克隆羊问题 现在有一只羊 tom,姓名为: tom, 年…...

day36-注解
1. 注解 1.1 注释和注解的区别?(掌握) 共同点:都可以对程序进行解释说明。 不同点:注释,是给程序员看的。只在Java中有效。在class文件中不存在注释的。 当编译之后,会进行注释擦除。 …...
【C语言数据结构——————栈和队列4000字详解】
欢迎阅读新一期的c语言数据结构模块————栈和队列 ✒️个人主页:-_Joker_- 🏷️专栏:C语言 📜代码仓库:c_code 🌹🌹欢迎大佬们的阅读和三连关注,顺着评论回访🌹&#…...
电子地图 | VINS-FUSION | 小觅相机D系列
目录 一、相关介绍 二、VINS-FUSION环境安装及使用 (一)Ubuntu18.04安装配置 1、Ubuntu下载安装 2、设置虚拟内存(可选) (二)VINS-FUSION环境配置 1、ros安装 2、ceres-solver安装 3、vins-fusion…...

Verilog与SystemVerilog在Arm Cycle Model Compiler中的支持与优化
1. Verilog与SystemVerilog语言支持概述 作为数字电路设计的行业标准语言,Verilog和SystemVerilog在半导体领域占据着核心地位。Arm的Cycle Model Compiler 11.5版本对这两种语言提供了全面的支持,但在实际工程应用中,开发者需要特别注意不同…...

我让 AI 学会了“拆“App——Antigravity 逆向分析能力搭建手记
你能想象吗?对着 AI 说一句"帮我分析这个 APK",它就自己打开 IDA、拆解代码、Hook 运行时、提取密钥、还原源码……全程不用你碰一下鼠标。先说结论我给 AI 编程助手 Antigravity 装上了 4 把"瑞士军刀",让它从一个只会写…...

飞蜂窝技术:从概念到5G室内覆盖核心的实战演进
1. 从“未来可期”到“正在爆发”:飞蜂窝技术的十年之约在通信行业里待久了,你总会听到一些技术名词被反复提起,它们像流星一样划过天际,被分析师们预言将“改变一切”,然后……似乎又沉寂了下去。飞蜂窝(F…...

基于RAG与向量数据库的本地化个人知识库构建实践
1. 项目概述:一个为个人量身定制的知识库构建引擎 如果你和我一样,每天在浏览器、笔记软件、PDF文档和各种聊天记录之间疲于奔命,试图抓住那些一闪而过的灵感和零散的知识点,那么你肯定理解“知识碎片化”的痛苦。我们收藏了无数…...

重构计算机历史叙事:挖掘被遗忘的贡献者与构建包容性科技未来
1. 项目概述:为什么我们需要重写计算机历史如果你问一个对计算机历史稍有了解的人,让他列举几位先驱,大概率会听到冯诺依曼、艾伦图灵、比尔盖茨、史蒂夫乔布斯这些名字。这个名单很长,但有一个共同点:他们几乎都是白人…...

从苹果FBI解锁案看现代加密技术与工程师伦理抉择
1. 事件背景与核心争议点2016年初,美国联邦调查局(FBI)向苹果公司提出了一项史无前例的要求:协助解锁一部属于圣贝纳迪诺枪击案枪手的iPhone 5c。这部手机设置了密码保护,并启用了“数据自毁”功能,即在连续…...

RISC-V架构下轻量级LLM推理引擎的优化与部署实践
1. 项目概述:一个为RISC-V架构优化的轻量级LLM推理引擎最近在折腾边缘计算和嵌入式AI部署的朋友,可能都绕不开一个核心矛盾:大语言模型(LLM)能力虽强,但动辄数十亿甚至上百亿的参数规模,对计算资…...

自建团队协作平台TeamClaw:从架构设计到部署运维全指南
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫teamclaw,仓库地址是teamclawai/teamclaw。乍一看这个名字,可能有点摸不着头脑,但深入了解一下,你会发现它瞄准的是一个非常具体且高频的痛点:团…...

vibe-to-ui:让AI助手将你的“感觉”翻译成专业设计系统
1. 项目概述:当“感觉”成为设计语言如果你和我一样,是一个能写出复杂业务逻辑,但一碰到UI设计就头疼的开发者,那今天聊的这个工具,可能会彻底改变你的工作流。我们常常陷入一个困境:心里有一个模糊的“感觉…...

GPU云服务器选型指南:从核心参数到实际部署的深度解析
在当下人工智能跟高性能计算急剧速度发展状况里,GPU云服务器正沿着从专业领域迈向更为广泛应用场景的路径前行。对于构成企业的开发者、相关技术团队来讲,怎样精准无误理解这一技术方案所具备的本质,并且于实际选型期间做出合乎情理的判断&am…...