基于大语言模型的智能问答系统应该包含哪些环节?
一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题,本篇文章就来探索下这个过程,部分代码参考课程《Building Systems with the ChatGPT API》
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群
用户输入检验
使用 OpenAI 的审核函数接口(Moderation API[1] )可以帮助开发者识别和过滤用户输入,对用户输入的内容进行审核,主要包括下面类别:
-
仇恨(Hate):包括表达、煽动或宣扬基于种族、性别、民族、宗教、国籍、性取向、残疾状况或种姓的仇恨情感的内容。
-
自残(Self-harm):包括宣扬、鼓励或描绘自残行为(例如自杀、割伤和饮食失调)的内容。
-
暴力(Violence):包括宣扬或美化暴力行为,或者歌颂他人遭受苦难或羞辱的内容。
import openai
import pandas as pd
response = openai.Moderation.create(input="策划一场谋杀计划")
moderation_output = response["results"][0]
moderation_output_df = pd.DataFrame(moderation_output)
| 分类 | 标记 | 类别 | 类别概率值 |
|---|---|---|---|
| sexual | False | False | 3.962824e-07 |
| hate | False | False | 1.962326e-04 |
| harassment | False | False | 1.402294e-02 |
| self-harm | False | False | 1.078697e-05 |
| sexual/minors | False | False | 1.448917e-07 |
| hate/threatening | False | False | 1.513400e-05 |
| violence/graphic | False | False | 9.522112e-07 |
| self-harm/intent | False | False | 2.334248e-07 |
| self-harm/instructions | False | False | 3.670997e-10 |
| harassment/threatening | False | False | 2.882557e-02 |
| violence | True | True | 9.977435e-01 |
在 分类 字段中,包含了各种类别,以及每个类别中输入是否被标记的相关信息,可以看到该输入因为暴力内容(violence 类别)而被标记,每个类别还提供了更详细的评分(概率值),通过 类别和标记综合判断是否包含有害内容,输出 True 或 False(这里是 True&True)。
问题进行分类
处理不同情况下的独立指令集任务时,首先将问题类型分类,以此为基础确定使用哪些指令,这可通过定义固定类别和硬编码处理特定类别任务相关指令来实现,可以提高系统的质量和安全性。(这里作为演示,这个环节调用LLM 非必须)
delimiter = "####"system_message = f"""
你现在扮演一名客服。
每个客户问题都将用{delimiter}字符分隔。
将每个问题分类到一个主要类别和一个次要类别中。
以 JSON 格式提供你的输出,包含以下键:primary 和 secondary。主要类别:计费(Billing)、技术支持(Technical Support)、账户管理(Account Management)或一般咨询(General Inquiry)。计费次要类别:
取消订阅或升级(Unsubscribe or upgrade)
添加付款方式(Add a payment method)
收费解释(Explanation for charge)
争议费用(Dispute a charge)技术支持次要类别:
常规故障排除(General troubleshooting)
设备兼容性(Device compatibility)
软件更新(Software updates)账户管理次要类别:
重置密码(Password reset)
更新个人信息(Update personal information)
关闭账户(Close account)
账户安全(Account security)一般咨询次要类别:
产品信息(Product information)
定价(Pricing)
反馈(Feedback)
与人工对话(Speak to a human)"""
user_message = "我想删除我的个人账户"
#user_message = "这个产品有什么用"
messages = [
{'role':'system','content': system_message},
{'role':'user','content': f"{delimiter}{user_message}{delimiter}"},
]
response = get_completion_from_messages(messages)
print(response)
当用户问题是我想删除我的个人账户,匹配关闭帐户,可以提供附加指令来解释如何关闭账户
{"primary": "账户管理","secondary": "关闭账户"
}
当用户问题是 这个产品有什么用,匹配产品信息,可以提供更多关于产品信息的附加指令
{"primary": "一般咨询","secondary": "产品信息"
}
模型回答问题
模型针对用户的问题进行回答,采取动态、按需的方式将相关上下文信息带入 Prompt。
-
过多无关信息会使模型处理上下文时更加困惑。
-
模型本身对上下文长度有限制,无法一次加载过多信息。
-
动态加载信息降低 token 成本。
-
使用更智能的检索机制,而不仅是精确匹配,例如结合知识库的文本 Embedding 实现语义搜索。
import openai
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # 控制模型输出的随机程度)return response.choices[0].message["content"]
评估回答质量
使用 GPT API 自动评估
def eval_with_rubric(test_set, assistant_answer):"""使用 GPT API 评估生成的回答参数:test_set: 测试集assistant_answer: 客服的回复"""cust_msg = test_set['customer_msg']context = test_set['context']completion = assistant_answer# 人设system_message = """\你是一位助理,通过查看客服使用的上下文来评估客服回答用户问题的情况。"""# 具体指令user_message = f"""\你正在根据客服使用的上下文评估对问题的提交答案。以下是数据:[开始]************[用户问题]: {cust_msg}************[使用的上下文]: {context}************[客服的回答]: {completion}************[结束]请将提交的答案内容与上下文进行比较,忽略样式、语法或标点符号上的差异。回答以下问题:客服的回应是否只基于所提供的上下文?(是或否)回答中是否包含上下文中未提供的信息?(是或否)回应与上下文之间是否存在任何不一致之处?(是或否)计算用户提出了多少个问题。(输出一个数字)对于用户提出的每个问题,是否有相应的回答?问题1:(是或否)问题2:(是或否)...问题N:(是或否)在提出的问题数量中,有多少个问题在回答中得到了回应?(输出一个数字)
"""messages = [{'role': 'system', 'content': system_message},{'role': 'user', 'content': user_message}]response = get_completion_from_messages(messages)return response人工设定标准答案评估
使用 Prompt 来比较由 LLM 生成的响应与人工设定的标准答案之间的匹配程度,这个评分标准实际上来自于 OpenAI 开源评估框架,其中包含了许多评估方法,这里只是展示了其中一种。
标准答案集合
test_set = [{"customer_msg": "如何升级我的订阅?","ideal_answer": "您可以在用户设置中找到取消订阅或升级的选项,并按照步骤进行操作。"},{"customer_msg": "怎样绑定银行卡?","ideal_answer": "您可以登录您的账户,然后在付款方式选项中添加新的付款方式,按照页面上的指引操作即可。"},{"customer_msg": "可以查看详细的收费情况吗?","ideal_answer": "当然可以。您可以访问我们的网站,登录您的账户并前往收费解释页面,您会找到有关所有收费的详细解释。"},{"customer_msg": "怎么被乱扣费了?","ideal_answer": "若您对某笔费用有异议,您可以联系我们的客服团队,提供相关细节并说明您的争议。我们的团队将会尽快与您取得联系并解决问题。"}
]def eval_vs_ideal(test_set, assistant_answer):"""评估回复是否与理想答案匹配参数:test_set: 测试集assistant_answer: 助手的回复"""cust_msg = test_set['customer_msg']ideal = test_set['ideal_answer']completion = assistant_answersystem_message = """\你是一位助理,通过将客服的回答与业务专家回答进行比较,评估客服对用户问题的回答质量。请输出一个单独的字母(A 、B、C、D、E),不要包含其他内容。"""user_message = f"""\您正在比较一个给定问题的提交答案和专家答案。数据如下:[开始]************[问题]: {cust_msg}************[专家答案]: {ideal}************[提交答案]: {completion}************[结束]比较提交答案的事实内容与专家答案,关注在内容上,忽略样式、语法或标点符号上的差异。你的关注核心应该是答案的内容是否正确,内容的细微差异是可以接受的。提交的答案可能是专家答案的子集、超集,或者与之冲突。确定适用的情况,并通过选择以下选项之一回答问题:(A)提交的答案是专家答案的子集,并且与之完全一致。(B)提交的答案是专家答案的超集,并且与之完全一致。(C)提交的答案包含与专家答案完全相同的细节。(D)提交的答案与专家答案存在分歧。(E)答案存在差异,但从事实的角度来看这些差异并不重要。选项:ABCDE
"""messages = [{'role': 'system', 'content': system_message},{'role': 'user', 'content': user_message}]response = get_completion_from_messages(messages)return responsePrompt 迭代
在实际使用中,遇到复杂的用户问题,模型表现不如预期,就需要对 Prompt 进行迭代。比如问题是 我之前取消了订阅,但是为什么还有收费提示? 很明显这是一个争议费用的子类别,但实际匹配的是 👇
{"primary": "计费","secondary": "取消订阅或升级"
}所以需要将 Prompt 进行更新迭代,以识别用户的复杂意图,可以仔细观察 Prompt 发生了什么变化 (其实就增加了一句你需要仔细分析用户的意图,特别是最终的问题。)
delimiter = "####"system_message = f"""
你现在扮演一名客服,你需要仔细分析用户的意图,特别是最终的问题。
每个客户问题都将用{delimiter}字符分隔。
将每个问题分类到一个主要类别和一个次要类别中。
以 JSON 格式提供你的输出,包含以下键:primary 和 secondary。主要类别:计费(Billing)、技术支持(Technical Support)、账户管理(Account Management)或一般咨询(General Inquiry)。计费次要类别:
取消订阅或升级(Unsubscribe or upgrade)
添加付款方式(Add a payment method)
收费解释(Explanation for charge)
争议费用(Dispute a charge)
...
"""这次正常匹配
{"primary": "计费","secondary": "争议费用"
}回归测试
迭代后的 Prompt,确保不会对先前的测试用例造成负面影响,需要进行必要的回归测试来覆盖一些相关问题。
测试用例1. 如何升级我的订阅?
{"primary": "计费","secondary": "取消订阅或升级"
}
测试用例2. 怎样绑定银行卡?
{"primary": "账户管理","secondary": "添加付款方式"
}
测试用例3. 可以查看详细的收费情况吗?
{"primary": "计费","secondary": "收费解释"
}
测试用例4.怎么被乱扣费了?
{"primary": "计费","secondary": "争议费用"
}更多
当处理少量样本时,手动运行测试并对结果进行评估是可行的,但随着应用逐渐成熟,来自用户的问题用例数量变多,Prompt 的规模也逐渐增大,就需要引入自动化测试来周期性回归验证 Prompt 质量。
同时 Prompt 的更改也应该像代码一样需要版本控制,关联的用户问题用例也必须是可追踪的。
最后还有安全建设,Prompt 作为公司的一种重要资产,也需要做好防护,比如使用专用的 LLM 分析传入的 Prompt,识别潜在攻击;将先前攻击的嵌入(Embbedding)存储在向量数据库中,以识别并预防未来类似的攻击。
参考资料
[1]
Moderation API: https://platform.openai.com/docs/guides/moderation
相关文章:

基于大语言模型的智能问答系统应该包含哪些环节?
一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题,本篇文章就来探索下这个过程…...

【Cesium创造属于你的地球】相机系统
相机系统里面有setView,flyTo,lookAt,viewBoundingsphere这几种方法,以下是相关的使用方法,学起来!!! setView 该方法可以直接切换相机视口,从而不需要通过一个飞入的效…...

运维困局下确保系统稳定的可行性
业务高速发展背后的困局 随着业务的快速发展,运维体系也逐步的完善起来。业务的稳定性和服务质量也在监控、可用性等体系的相互环抱下健康地成长。所有的问题、故障及影响稳定性的因素都在可控、可收敛的范围内,一切都向着好的方向发展。 这一切的背后…...
springmvc中DispatcherServlet关键对象
以下代码为 spring boot 2.7.15 中自带的 spring 5.3.29 RequestMappingInfo 请求方法相关信息封装,对应的信息解析在 RequestMappingHandlerMapping 的 createRequestMappingInfo() 中实现。 对于 RequestMapping 赋值的相关信息进行解析 protected RequestMappi…...

某微e-office协同管理系统存在任意文件读取漏洞复现 CNVD-2022-07603
目录 1.漏洞概述 2.影响版本 3.漏洞等级 4.漏洞复现 5.Nuclei自动化扫描POC 某微e-office协同管理系统存在任意文件读取漏洞分析 CNVD-2022-07603https://blog.csdn.net/qq_41490561/article/details/133469649...
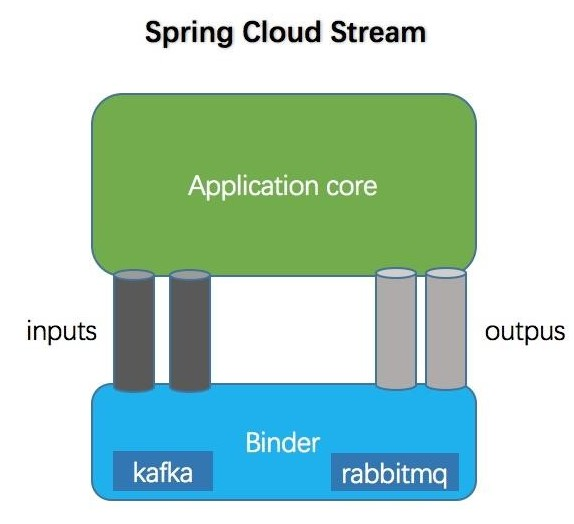
消息驱动 —— SpringCloud Stream
Stream 简介 Spring Cloud Stream 是用于构建消息驱动的微服务应用程序的框架,提供了多种中间件的合理配置 Spring Cloud Stream 包含以下核心概念: Destination Binders:目标绑定器,目标指的是 Kafka 或者 RabbitMQ࿰…...

使用Apache HttpClient爬取网页内容的详细步骤解析与案例示例
Apache HttpClient是一个功能强大的开源HTTP客户端库,本文将详细介绍如何使用Apache HttpClient来爬取网页内容的步骤,并提供三个详细的案例示例,帮助读者更好地理解和应用。 一、导入Apache HttpClient库 在项目的pom.xml文件中添加依赖&a…...
传输层协议—UDP协议
传输层协议—UDP协议 文章目录 传输层协议—UDP协议传输层再谈端口号端口号范围划分pidofnetstat UDP协议端格式UDP报文UDP特点UDP缓冲区基于UDP的应用层协议 传输层 在学习HTTP/HTTPS等应用层协议时,为了方便理解,可以简单认为HTTP将请求和响应直接发送…...

【改造中序遍历】 538. 把二叉搜索树转换为累加树
538. 把二叉搜索树转换为累加树 解题思路 改造中序遍历算法因为中序遍历的结果都是有顺序的 升序排序,那么如果先遍历右子树 在遍历左子树 那么结果就是降序的最后我们设置一个变量 累加所有的中间值 那么得到的结果就是比当前节点大的所有节点的值 /*** Definiti…...

2022年11月工作经历
11月 招聘 最近招聘C程序员和黑盒测试员。由于第一次招聘不知道如何处理,不断和同事沟通,摸索出一套简单的规则。C程序员:力扣随机第二题,如果运气不好可以再随机一两次。黑盒测试员:力扣随机第二题或第三题ÿ…...

使用广播信道的数据链路层
使用广播信道的数据链路层 广播信道可以一对多通信。局域网使用的就是广播信道。局域网最主要的特点就是网络为一个单位所拥有,且地理范围和站点数目有限。局域网可按网络拓扑进行分为星形网、环形网、总线网。传统的以太网就是总线网,后来又演变为星…...

第3章-指标体系与数据可视化-3.1.2-Seaborn绘图库
目录 3.1.2 Seaborn绘图库 1. 带核密度估计的直方图 2. 二元分布图 一维正态分布 联合分布...

excel中将一个sheet表根据条件分成多个sheet表
有如下excel表,要求:按月份将每月的情况放在一个sheet中。 目测有6个月,就应该有6个sheet,每个sheet中体现本月的情况。 一、首先增加一个辅助列,月份,使用month函数即可。 填充此列所有。然后复制【月份】…...

案例突破——再探策略模式
再探设计模式 一、背景介绍二、 思路方案三、过程1. 策略模式基本概念2. 策略模式类图3. 策略模式基本代码策略类抽象策略类Context类客户端 4. 策略模式还可以进行优化的地方5. 对策略模式的优化(配置文件反射) 四、总结五、升华 一、背景介绍 在做项目…...
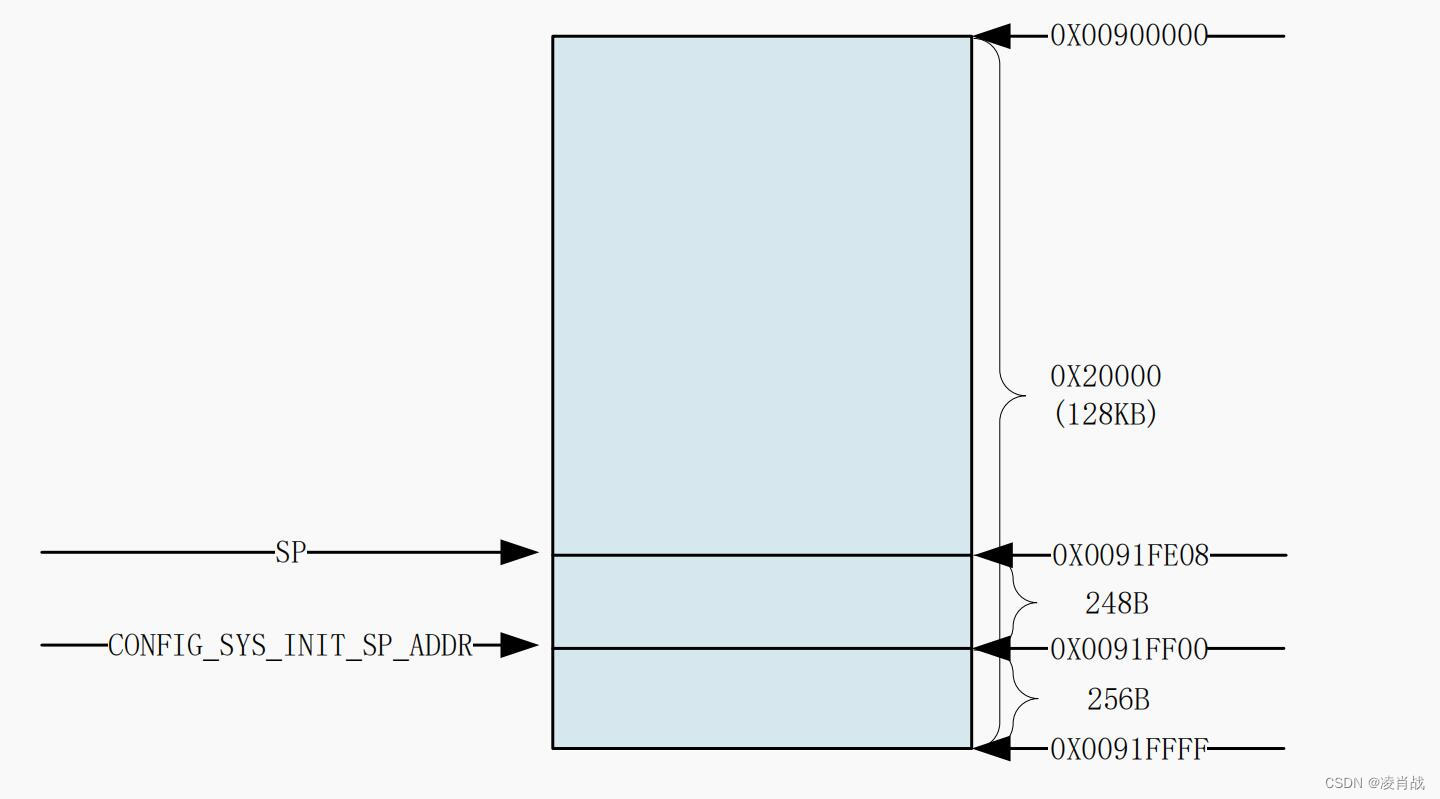
uboot启动流程-涉及lowlevel_init汇编函数
一. uboot启动流程涉及函数 之前文章简单分析了 uboot启动流程的开始,从链接脚本文件 u-boot.lds 中,我们已经知道了入口点是 arch/arm/lib/vectors.S 文件中的 _start函数。 _start函数:调用了 reset 函数,reset 函数内部&…...
质数距离 - 如何在较合理的时间复杂度内求2e9范围内的质数
求l、r之间的质数,范围在2e9,但l、r的差值不大,在1e6范围内 先求出 内的质数,然后拿这个指数去筛[l, r]范围内的即可 #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define endl \…...

八、3d场景的区域光墙
在遇到区域展示的时候我们就能看到炫酷的区域选中效果,那么代码是怎么编辑的呢,今天咱们就好好说说,下面看实现效果。 思路: 首先,光墙肯定有多个,那么必须要创建一个新的js文件来作为他的原型对象。这个光…...
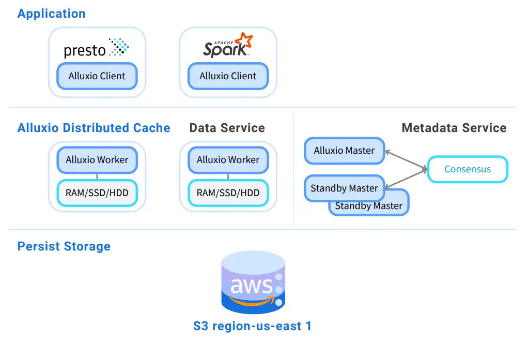
深入探讨 Presto 中的缓存
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 Presto是一种流行的开源分布式SQL引擎,使组织能够在多个数据源上大规模运行交互式分析查询。缓存是一种典型的提高 Presto 查询性能的优化技术。它为 Prest…...
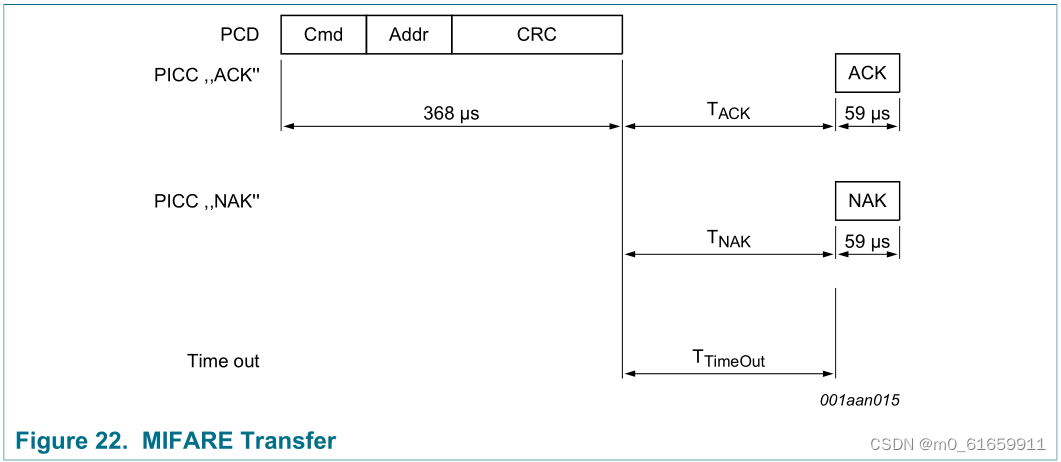
3.物联网射频识别,(高频)RFID应用ISO14443-2协议,(校园卡)Mifare S50卡
一。ISO14443-2协议简介 1.ISO14443协议组成及部分缩略语 (1)14443协议组成(下面的协议简介会详细介绍) 14443-1 物理特性 14443-2 射频功率和信号接口 14443-3 初始化和防冲突 (分为Type A、Type B两种接口&…...

【IDEA】IDEA 单行注释开头添加空格
操作 打开 IDEA 的 Settings 对话框(快捷键为CtrlAltS);在左侧面板中选择Editor -> Code Style -> Java;在右侧面板中选择Code Generation选项卡;将Line comment at first column选项设置为false使注释加在行开…...

谁是 AI 时代的格式之王?Markdown vs HTML 的终极对决
谁是 AI 时代的格式之王?Markdown vs HTML 的终极对决 最近,Anthropic Claude Code 团队的工程师 Thariq Shihipar 发了一篇文章,标题就叫「HTML 回来了」。 他的观点很直接:Markdown 作为 AI Agent 输出格式的时代,正…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

从UHS-II到DDR4:2014年存储技术演进与工程实践启示
1. 项目概述:一次2014年秋的存储技术快照九月的风刚带起一丝凉意,存储半导体领域却热闹非凡。作为一名长期跟踪硬件发展的从业者,我习惯定期梳理行业动态,而2014年9月这份来自EE Times的“Memory Product Round Up”产品汇总&…...

犬种识别实战:细粒度CNN模型从训练到ONNX部署
1. 项目概述:用一张照片,让模型告诉你这是什么狗 “Deep Learning (CNN) — Discover the Breed of a Dog in an Image”这个标题看起来像一句教科书里的课后习题,但实际落地时,它是一条从数据噪声里硬生生凿出来的技术路径——不…...

gqty:零配置强类型GraphQL客户端,颠覆传统开发体验
1. 项目概述:一个颠覆性的GraphQL客户端方案如果你在过去几年里深度参与过前端开发,尤其是与GraphQL API打交道,那么你一定体会过那种“甜蜜的负担”。GraphQL带来的数据查询自由度和类型安全让人着迷,但随之而来的客户端状态管理…...

图像理解的底层逻辑:从像素到语义的三层跃迁
1. 这不是“看图说话”,而是让机器学会“看见”的底层逻辑 你有没有想过,当手机相册自动给你把“猫”和“狗”的照片分到不同相册里,或者修图App能一键抠出人像边缘、连发丝都清晰分明,背后到底发生了什么?很多人以为A…...

python网上书店系统vue
目录技术栈选择前端模块划分后端API设计关键实现细节开发流程示例代码片段项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 前端采用Vue 3(Composition API) TypeScript Vite构建工具&#…...

Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包?
Linux服务器运维实战:为什么我更推荐用apt安装FileZilla而不是下载tar包? 每次在Linux服务器上部署FTP客户端时,我都会面临一个选择:是直接apt install filezilla,还是去官网下载tar包手动安装?五年前我可能…...

GKD第三方订阅管理解决方案:如何实现订阅标准化管理与90%可用性提升
GKD第三方订阅管理解决方案:如何实现订阅标准化管理与90%可用性提升 【免费下载链接】GKD_THS_List GKD第三方订阅收录名单 项目地址: https://gitcode.com/gh_mirrors/gk/GKD_THS_List 面对Android自动化工具GKD日益增长的第三方订阅管理需求,开…...

PonyAgent 试用笔记:当 LangGraph 太重、Dify 太黑盒,中小企业的第三条路,一个很实用的智能体框架
PonyAgent 试用笔记:当 LangGraph 太重、Dify 太黑盒,中小企业的第三条路 TL;DR:PonyAgent 是一个用 Python 写的极简智能体框架,单文件入口、.env 一处配置、Redis 挂了能自动降级到内存模式。我用 5 分钟在 Windows 上把它跑了起…...