搭建全连接网络进行分类(糖尿病为例)
拿来练手,大神请绕道。
1.网上的代码大多都写在一个函数里,但是其实很多好论文都是把网络,数据训练等分开写的。
2.分开写就是有一个需要注意的事情,就是要import 要用到的文件中的模型或者变量等。
3.全连接的回归也写了,有空再上传吧。
4.一般都是先写data或者model
import torch
import torch.nn as nn
import torch.nn.functional as F
#nn.func这个里面很多功能其实nn里就有,可以不导入,而且后面新的版本的torch也取消了cc.functional里面的部分函数#定义网络,需要定义两部分,一部分就是初始化,另一部分就是数据流
class FCNet(nn.Module):def __init__(self):super(FCNet,self).__init__()self.fc1 = nn.Linear(8,16)#初始的这个8,要和你的数据的特征数一样才行,后面的数可以随意设置,但是不要太多,容易过拟合# self.fc2 = nn.Linear(50,20)self.fc3 = nn.Linear(16,2)#二分类,输出2,其实1也可以的#最后的就是分类数,因为用的sigmod和交叉熵损失,就不用额外加softmax了,多分类要用softmaxself.sig = nn.Sigmoid()# self.drop = nn.Dropout(0.3)#可以把用到的放在这里,也可以用nn.Sequential()放在一起,这样后面的话就可以直接用这个,不用写那么多了def forward(self,x):x = self.sig(self.fc1(x))# x = self.sig(self.fc2(x))x = self.sig(self.fc3(x))return x#就是x要怎么在网络中走,要写一遍#可以自己输出测试一下看看网络是不是自己想的那样,在真的调用的时候再屏蔽掉
# net= FCNet()
# print(net)首先看看数据是是啥样,outcome就是有没有糖尿病
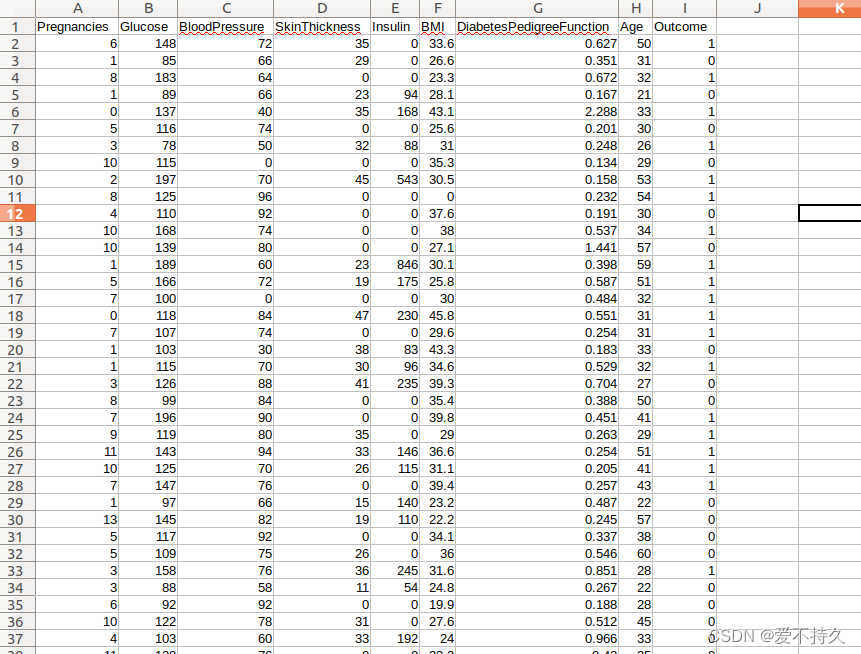
其实可以手动把csv分成train和test
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
#导入pands是为了读数据,当然使用numpy也可以读得,sklearn是为了把训练数据分为训练和验证集data = pd.read_csv('./train.csv')
#就是把对应的数据哪出来,x代表的是feature上的data,y代表的是label,因为pd可以读到最上面的标签,所以从第2行(i=1)开始读就行
x = data.iloc[1:,:-1]
y = data.iloc[1:,[-1]]
#可以输出看看数据对不对,x中不应该包含labels
# print(x)
# print(y)
#test_size就是划分的比例,后面的是种子,意思是每次运行这个函数时候,0.8就是那些,0.2也还是每次一样,如果想要不一样,只要每次运行这个函数时候换个值就行
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0)
#print(x_train,y_test)
# print(x_test,y_test)
#给数据进行归一化,可以用很多方法,我用最简单的归一到-1到1
x_train = x_train.apply(lambda x: (x - x.mean()) / (x.std()))
x_test = x_test.apply(lambda x: (x - x.mean()) / (x.std()))#写dataset可以用两种方法,第一种就是 每一个数据自己单独处理,第二个就是要自己重写dataset类
#1.
# 可以使用分别的处理,把数据(首先转换为tensor,或者把dataframe.valus拿出来才能转换为tensor)转换为tensor并且数据类型转换为float32,如果测试没有真值,需要单独转换
# x_train = torch.tensor(np.array(x_train),dtype=torch.float32)
# y_train = torch.tensor(np.array(y_train),dtype=torch.float32)
# x_test = torch.tensor(np.array(x_test),dtype=torch.float32)
# y_test = torch.tensor(np.array(x_test),dtype=torch.float32)
# train_dataset = torch.utils.data.TensorDataset(x_train,y_train)
# test_dataset = torch.utils.data.TensorDataset(x_test,y_test)#2.也可以直接重写datasetclass dataset(Dataset):def __init__(self, x, y):#把值拿出来或者变为np类型才能转换为tensor# self.data = torch.tensor(x.values,dtype=torch.float32)# self.labels = torch.tensor(y.values,dtype=torch.float32)self.data = torch.tensor(np.array(x),dtype=torch.float32)self.labels = torch.tensor(np.array(y),dtype=torch.float32)def __len__(self):return len(self.data)def __getitem__(self,idx):return self.data[idx],self.labels[idx]#应该返回的是list类型,不是字典也不是setBATCH_SIZE = 64#验证集一般不用shuffle
train_dataset = dataset(x_train,y_train)
test_dataset = dataset(x_test,y_test)
# print(train_dataset)
train_loader = DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True)
test_lodaer = DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=False)
# print(train_loader)然后就可以写train或者test了,其实test和train一样
from Model import FCNet
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import data
#导入要调用的net和data,也可以from data import xxx 这样可以直接用xxx,现在的这个需要用data.xxx#看自己的设备,最好用gpu来跑
if (torch.cuda.is_available()):my_device = torch.device('cuda')
else:my_device = torch.device('cpu')print(my_device)
#实例化一个net,并且放到gpu上,需要放到gpu上的有inputs,labels,net,loss
net = FCNet().to(my_device)
# print(net)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
#一开始是不需要weight_decay(也就是l2正则化),可以等出现过拟合在用,也可以先用上
optimizer = optim.Adam(net.parameters(),lr=0.001,weight_decay=0.01)epochs = 600
#定义train,因为一边训练一边验证,所有就把两个loader都放进去了,不过写法很多,也可以不放dataloader,放epoches也可以
def train(dataloader,valloader):losses = []acces = []losses_val = []for epoch in range(epochs):loss_batch = 0for i,data in enumerate(dataloader):#需要注意的,这里的inputs和labels和之前定义的dataset相关,需要是list类型才可以inputs,labels = data#print(data)可以打印出来查看一下inputs,labels = inputs.to(my_device),labels.to(my_device)optimizer.zero_grad()#每次要梯度清零outputs = net(inputs)#print(outputs)#model的最后一层是sigmod#labels的格式需要注意,因为现在是[[1],[0],[1],[1]..]这样得格式,无法放到交叉熵了,需要时[0,1,1,1...]这样得格式才行loss = criterion(outputs,labels.squeeze(1).long()).to(my_device)#print(labels.squeeze(1).long())loss.backward()optimizer.step()loss_batch += loss.item()length = i#验证的时候不用反向传播和梯度下降这些net.eval()count = 0right = 0loss_batch_val =0with torch.no_grad():for j,data2 in enumerate(valloader):val_inputs,val_labels = data2val_inputs,val_labels = val_inputs.to(my_device),val_labels.squeeze(1).long().to(my_device)val_outputs = net(val_inputs)loss_val = criterion(val_outputs,val_labels)#因为net的最后一层是2,所以输出的是2维的【0.6,0.4】这种,但是这个可以直接放到交叉熵中#——中放的是概率,pred中放的是预测的类别,算损失还是要用outputs,但是算准确率就是用pred和真实labels相比了_,pred = torch.max(val_outputs,1)#print(pred)right = (pred == val_labels).sum().item()count = len(val_labels)acc = right/countloss_batch_val += loss_val.item()length2 = jif epoch % 10 == 9:print('train_epoch:',epoch+1,'train_loss:',loss_batch/length,'val_loss:',loss_batch_val/length2,'acc:',acc)losses.append(loss_batch/length)acces.append(acc)losses_val.append(loss_batch_val/length2)#可以画一些曲线,输出一些值plt.plot(range(60),losses,color ='blue',label ='train_loss')plt.plot(range(60),acces, color ='red',label ='val_acc')plt.plot(range(60),losses_val,color ='yellow',label ='val_loss')plt.legend()plt.show()torch.save(net.state_dict(),'./weights_epoch1000.pth')#保存参数train(data.train_loader,data.test_lodaer)最后看一下结果,最后的准确率在85%左右,还可以,毕竟数据不多,也是简单的全连接。
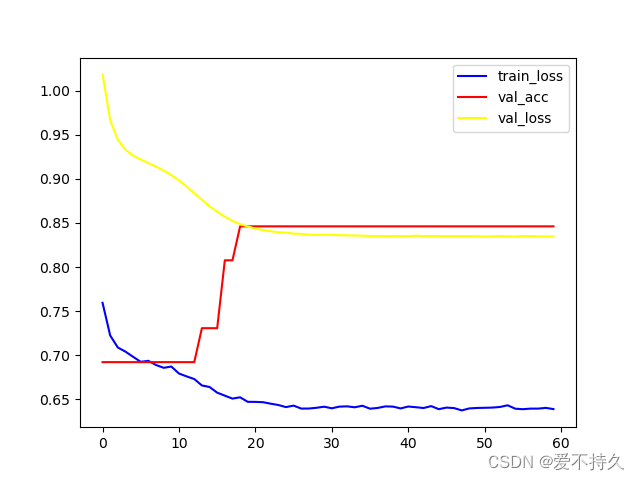
在这个结果之前出现了很多问题,比如波动很大,损失先降后升等问题,找个有问题的图

下面是一些总结:
1.跳跃很大,波动:增大batch_size,减小lr。
2.降低过拟合:
a.降低模型的复杂程度,但是修改具体的神经元个数,因为这个网络本身就不大,所有没啥用,模型非常大没准会有用。
b.batchsize增大,lr减小是有效的。
c.输入数据进行归一化是有用的,归一化之后lr可以调大一点,收敛变快了。
d.L2正则化是有用的,很有用。dropout应该也有用,但是模型本来就很小,我试了试没啥差别。而且有正则化之后可以加速收敛,lr可以稍微调大一点,较少的epoches也可以收敛了,而已acc也会更高一点,稳定一点。
相关文章:
搭建全连接网络进行分类(糖尿病为例)
拿来练手,大神请绕道。 1.网上的代码大多都写在一个函数里,但是其实很多好论文都是把网络,数据训练等分开写的。 2.分开写就是有一个需要注意的事情,就是要import 要用到的文件中的模型或者变量等。 3.全连接的回归也写了&#…...
【小沐学前端】Node.js实现基于Protobuf协议的UDP通信(UDP/TCP)
文章目录 1、简介1.1 node1.2 Protobuf 2、下载和安装2.1 node2.2 Protobuf2.2.1 安装2.2.2 工具 3、node 代码示例3.1 HTTP3.2 UDP单播3.4 UDP广播 4、Protobuf 代码示例4.1 例子: awesome.proto4.1.1 加载.proto文件方式4.1.2 加载.json文件方式4.1.3 加载.js文件方式 4.2 例…...

Verasity Tokenomics — 社区讨论总结与下一步计划
Verasity 代币经济学的社区讨论已结束。 本次讨论从 8 月 4 日持续到 9 月 29 日,是区块链领域规模最大的讨论之一,超过 500,000 名 VRA 持有者和社区成员参与讨论,并收到了数千份回复。 首先,我们要感谢所有参与讨论并提出详细建…...

JUC第十三讲:JUC锁: ReentrantLock详解
JUC第十三讲:JUC锁: ReentrantLock详解 本文是JUC第十三讲,JUC锁:ReentrantLock详解。可重入锁 ReentrantLock 的底层是通过 AbstractQueuedSynchronizer 实现,所以先要学习上一章节 AbstractQueuedSynchronizer 详解。 文章目录 …...

WSL2安装历程
WLS2安装 1、系统检查 安装WSL2必须运行 Windows 10 版本 2004 及更高版本(内部版本 19041 及更高版本)或 Windows 11。 查看 Windows 版本及内部版本号,选择 Win R,然后键入winver。 2、家庭版升级企业版 下载HEU_KMS_Activ…...
Ubuntu20配置Mysql常用操作
文章目录 版权声明ubuntu更换软件源Ubuntu设置静态ipUbuntu防火墙ubuntu安装ssh服务Ubuntu安装vmtoolsUbuntu安装mysql5.7Ubuntu安装mysql8.0Ubuntu卸载mysql 版权声明 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程…...

【解决方案】‘create’ is not a member of ‘cv::aruco::DetectorParameters’
‘create’ is not a member of ‘cv::aruco::DetectorParameters’ 在构建AruCo标定板标定位姿代码的过程中,发现代码中认为create并不是aruco::DetectorParameters的成员函数,这是因为在4.7.0及以上的OpenCV版本中,对ArUco的代码做调整&…...
)
门牌制作(蓝桥杯)
门牌制作 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 小蓝要为一条街的住户制作门牌号。 这条街一共有 2020 位住户,门牌号从 1 到 2020 编号。 小蓝制作门牌的方法是先制作 0 到 9 这几个数字字…...
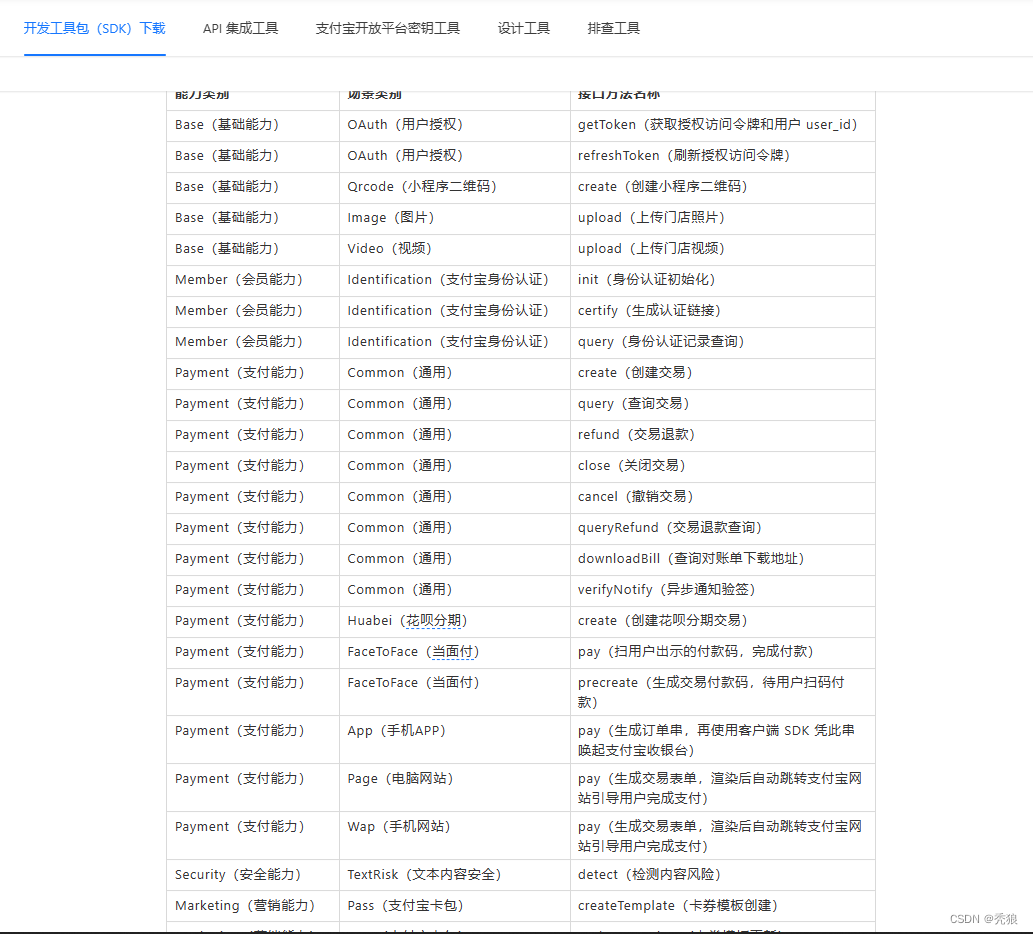
支付宝支付模块开发
生成二维码 使用Hutool工具类生成二维码 引入对应的依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.5</version> </dependency><dependency><groupId>com.go…...

12、Kubernetes中KubeProxy实现之iptables和ipvs
目录 一、概述 二、iptables 代理模式 三、iptables案例分析 四、ipvs案例分析 一、概述 iptables和ipvs其实都是依赖的一个共同的Linux内核模块:Netfilter。Netfilter是Linux 2.4.x引入的一个子系统,它作为一个通用的、抽象的框架,提供…...

从0开始python学习-29.selenium 通过cookie信息进行登录
1. 手动输入cookie信息保持登录状态 url https://test.com/login driver.get(url) # 手动将cookie信息写入(有多个的情况需要分开写入)--弊端为需要每次都手动输入,很麻烦不适用 driver.add_cookie({"name": "SIAM_IMAGE_…...

CentOS安装OpenNebula(二)
被控端部署: 先要配置好yum源: [rootmaster yum.repos.d]# vim opennebula.repo[rootmaster yum.repos.d]# cat opennebula.repo [opennebula] nameopennebula baseurlhttps://downloads.opennebula.org/repo/5.6/CentOS/7/x86_64 enabled1 gpgkeyhttps…...

力扣第239题 c++滑动窗口经典题 单调队列
题目 239. 滑动窗口最大值 困难 提示 队列 数组 滑动窗口 单调队列 堆(优先队列) 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的…...

华为云云耀云服务器L实例评测|华为云云耀云服务器docker部署srs,可使用HLS协议
华为云云耀云服务器L实例评测|华为云云耀云服务器docker部署srs,可使用HLS协议 什么是华为云云耀云L实例 云耀云服务器L实例,面向初创企业和开发者打造的全新轻量应用云服务器。提供丰富严选的应用镜像,实现应用一键部署&#x…...
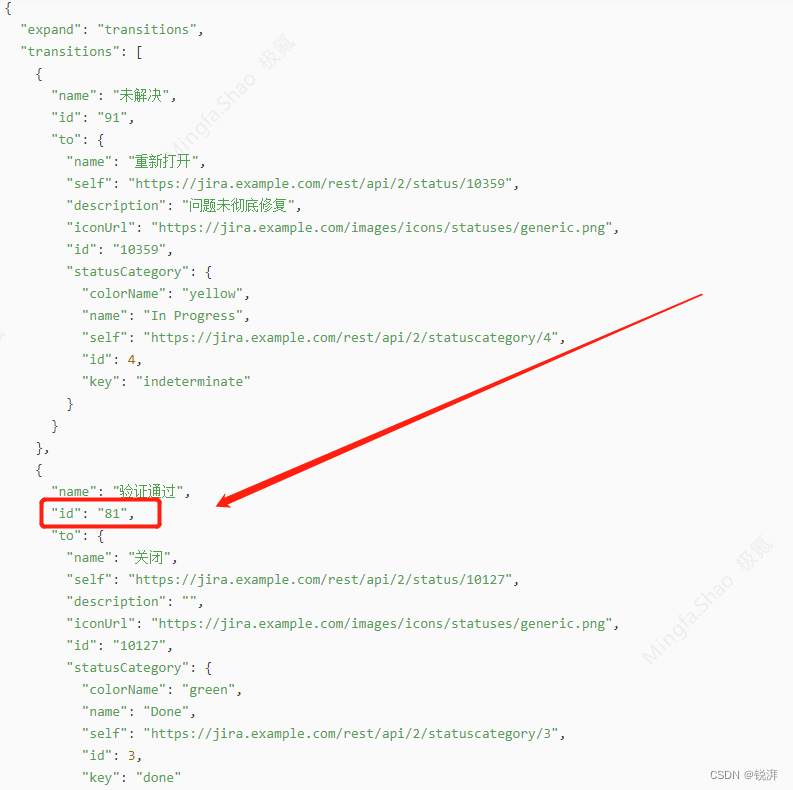
jira流转issue条目状态transitions的rest实用脚本,issue状态改变调整
官方文档链接地址: POST Transition issue Performs an issue transition and, if the transition has a screen, updates the fields from the transition screen. sortByCategory To update the fields on the transition screen, specify the fields in the fiel…...

JAVA 注解
1 概念 Annotation(注解)是 Java 提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。Annatation(注解)是一个接口,程序可以通过反射来获取指定程序中元素的 Annotation 对象,然后通过该 An…...
C++面试题准备
文章目录 一、线程1.什么是进程,线程,彼此有什么区别?2.多进程、多线程的优缺点3.什么时候用进程,什么时候用线程4.多进程、多线程同步(通讯)的方法5.父进程、子进程的关系以及区别6.什么是进程上下文、中断上下文7.一…...

使用Java操作Redis
要在Java程序中操作Redis可以使用Jedis开源工具。 一、jedis的下载 如果使用Maven项目,可以把以下内容添加到pom中 <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId>…...
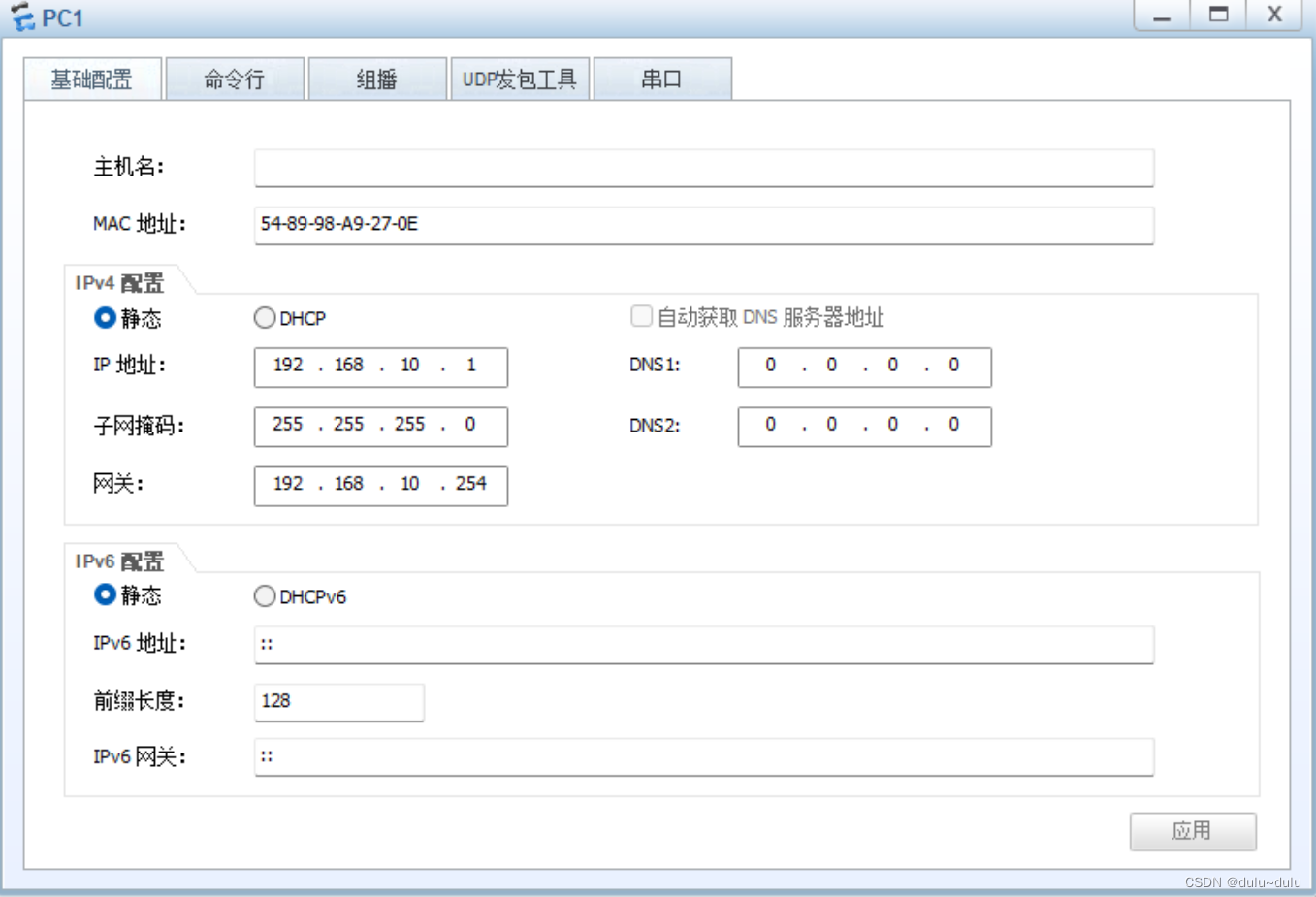
VRRP配置案例(路由走向分析,端口切换)
以下配置图为例 PC1的配置 acsw下行为access口,上行为trunk口, 将g0/0/3划分到vlan100中 <Huawei>sys Enter system view, return user view with CtrlZ. [Huawei]sysname acsw [acsw] Sep 11 2023 18:15:48-08:00 acsw DS/4/DATASYNC_CFGCHANGE:O…...
【图像处理】【应用程序设计】加载,编辑和保存图像数据、图像分割、色度键控研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

【信息科学与工程学】【通信工程】第四十三篇 骨干网方案设计-02跨境网络
一、方案 1.1 整体方案设计概要 设计的云网融合方案,综合考虑其全球互联需求、安全合规性、性能优化及跨国运营挑战: 1.1.1、需求分析 网络互联需求: 国内互通: 安全、稳定、低延迟连接中国大陆(严格合规要求)。 国际互通: 高性能连接美国(东西海…...

告别60帧束缚:《原神》帧率解锁终极指南,轻松实现120帧流畅体验
告别60帧束缚:《原神》帧率解锁终极指南,轻松实现120帧流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为《原神》60帧的限制而烦恼吗?想…...

【AI原生多任务学习实战白皮书】:SITS 2026官方未公开的5大优化范式与3类典型失效场景复盘
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在 SITS 2026 挑战赛中,AI 原生多任务学习(MTL)不再仅依赖共享特征表示,而是通过任务感知梯…...

Legacy iOS Kit终极指南:一站式拯救老旧iPhone/iPad的免费工具
Legacy iOS Kit终极指南:一站式拯救老旧iPhone/iPad的免费工具 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-K…...

ABAP 7.40+新语法实战:从传统代码到现代编程范式的重构
1. ABAP 7.40新语法带来的编程革命 十年前我刚接触ABAP时,代码风格还停留在SAP R/3时代的传统写法。每次看到满屏的DATA声明、LOOP...ENDLOOP和APPEND语句,就像在看上世纪90年代的编程教科书。直到ABAP 7.40版本发布,这个被称为"ABAP语言…...

从一张‘正常’图片到服务器沦陷:文件包含漏洞如何让图片马‘活’过来?
从一张“正常”图片到服务器沦陷:揭秘文件包含漏洞的致命组合攻击 当你深夜检查服务器日志时,发现有人上传了一张普通的风景图。文件头校验通过,MIME类型正确,甚至预览也显示正常。但三天后,这张“图片”却成为攻击者控…...

避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节
避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节 在FPGA设计中,跨时钟域(CDC)数据传输一直是工程师们面临的棘手问题。Xilinx Vivado提供的FIFO IP核因其稳定性和易用性,成为处理CDC问题的首选方案。然而&a…...

别再为FDC2214数据抖动发愁了!一个接地气的屏蔽线替代方案与差分测量实战
FDC2214抗干扰实战:差分测量与数据稳定化技巧 在电容式传感项目中,FDC2214作为一款高分辨率多通道电容数字转换器,常被用于纸张计数、液位检测等场景。然而实际应用中,工程师们最头疼的莫过于数据抖动问题——导线轻微移动、环境…...
)
告别GSWP3:手把手教你为CESM2.1.3配置自定义气象强迫数据集(CLM1PT模式详解)
告别GSWP3:手把手教你为CESM2.1.3配置自定义气象强迫数据集(CLM1PT模式详解) 当研究团队需要将ERA5、CMIP6等新型再分析数据接入CESM模型时,往往会在数据接口环节遭遇"黑箱"操作困境。本文将以CLM1PT模式为切入点&#…...

BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案
BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX-Inst…...