Linux 5种网络模型
[参考]:《黑马程序员Redis》https://www.bilibili.com/video/BV1cr4y1671t/?p=166&share_source=copy_web&vd_source=9e65300ccca322aeb367bb1eb677b0fc
[参考]:《操作系统》
[参考]:《UNIX网络编程》
为了避免用户应用导致冲突甚至内核崩溃,用户应用与内核是分离的:
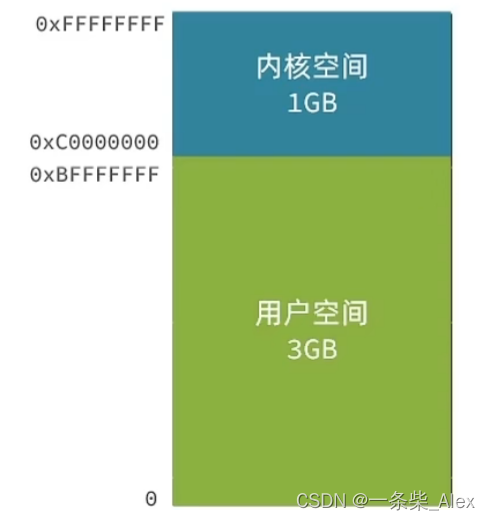
进程的寻址空间会划分为两部分:内核空间、用户空间
用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问内核空间可以执行特权命令 (Ringo),调用一切系统资源
必要的前置知识:
编译:由编译程序将用户源代码编译成若千个目标模块(编译就是把高级语言翻译为机器语言)
链接:由链接程序将编译后形成的一组目标模块,以及所需库函数链接在一起,形成一个完整的装入模块装入 (装载) : 由装入程序将装入模块装入内存运行
1、程序、内存、与寻址
程序代码通过(预处理、编译、汇编、链接)等步骤,形成可执行的机器指令后,这些指令会告诉CPU去内存的哪个地址读/写数据,然后与寄存器进行交互,进行一些计算操作,等等。
程序生成的指令中指明的地址,是逻辑地址(相对地址),而我们的数据真实所在的内存是物理地址。
在C语言中,可执行文件最终是以装入模块的形式,进入内存。
1.1 程序的装入
装入方式有三种:
1、绝对装入
只适用于单道程序环境,程序驻留在内存的实际位置是已知的,程序中的逻辑地址与内存的实际地址完全相同。由程序员直接赋予,或程序中采用符号地址,在编译或汇编时转换为绝对地址。
2、可重定位装入(静态重定位)
多道程序环境下,多个目标模块的起始地址都是0,程序中的其他地址都是相对于起始地址的。在装入时对目标程序的指令和数据地址进行修改的过程 称为重定位,因其地址变换通常是在进程装入时一次完成的,故称为【静态重定位】
3、动态运行时装入(动态重定位)
程序若在内存中会发生移动,则使用动态重定位,即重定位的过程并不是在装入时完成,而是推迟到了程序运行时进行,需要重定位寄存器支持。
1.2 逻辑地址与物理地址
编译后,每个目标模块都是从0号单元开始编址,这称为该目标模块的相对地址(或逻辑地址),当链接程序将各个模块链接成一个完整的可执行的目标程序时,链接程序的顺序按照各个模块的相对地址构成统一的从0号地址单元开始编址的逻辑地址空间(或虚拟地址空间)。
对于32位系统,逻辑地址空间的范围是 0~2^32-1。进程在运行时,看到的和使用的都是逻辑地址。用户程序和程序员只需要知道逻辑地址,而内存管理的具体机制则是完全透明的(对用户不可视)。不同的进程可以有相同的逻辑,因为他们会被隐射到不同的主存位置。
寻址空间与计算机的位数有关系,因为每个地址单元的大小是1B,如果是32位系统,那么寻址空间大小是 2^32=4GB次方字节 。
2^10 =1024B =1K字节(1KByte), 2^20 =1MB,2^30 =1GB,
2^32 =(2^30)*(2^2) =4GB;
因此地址编号长度要能表示出4GB/1B =2^32个内存单元
32位2进制 可以转换成8位16进制表达
0地址
0x0000 0000
高地址
0xFFFF FFFF
涉及内存地址增长、存储的问题还有一个大小端的情况:
大端存储:地址低位存储数据高位,地址高位存储数据低位
小端存储:地址低位存储数据低位,地址高位存储数据高位
物理地址就是内存中物理单元的集合,是地址转换的最终地址。
逻辑地址通过页表映射到物理内存,页表由操作系统维护并被处理器引用。
1.3 进程的内存映像
当一个程序调入内存运行时,就构成了进程的内存映像。
- 代码段:即程序的二进制代码,代码段是只读的,可以被多个进程共享
- 数据段:即程序运行时加工处理的对象,包括全局变量和静态变量
- 进程控制块PCB:存放在系统区。操作系统通过PCB来控制和管理进程
- 堆:用来存放动态分配的变量,通过调用malloc函数动态的向高地址分配空间。
- 栈:用来实现函数调用,从用户控件的最大地址往低地址增长。
(补充一句:高级语言运行思路都是类似的,即使是Java这种运行逻辑依靠JVM的,其内部运行时数据区的设计思路都是源于操作系统管理的算法和逻辑)。
代码段和数据段在程序调入内存时就指定了大小。(其实我们在学C++时就说了这些东西其实是在编译期,运行之前就确定的,Java也有类似的方法区,其具体落地实现中,final 静态变量的值也是在编译期就已经确定值了)而堆和栈不同,当调用 malloc free 这样C标准库函数时,堆可以在运行时动态扩缩。用户栈也是随着程序中函数调用和返回,进行入栈弹栈操作。(java的堆和栈略有不同,可以参考我的JVM篇知识)。
1.4 内存的分配管理
详细内容可以看我的【操作系统】专栏
1、连续分配管理
- 单一连续分配
- 固定分区分配
- 动态分区分配
2、离散分配管理
1、分页存储
2、分段存储
3、段页式存储
3、虚拟内存管理
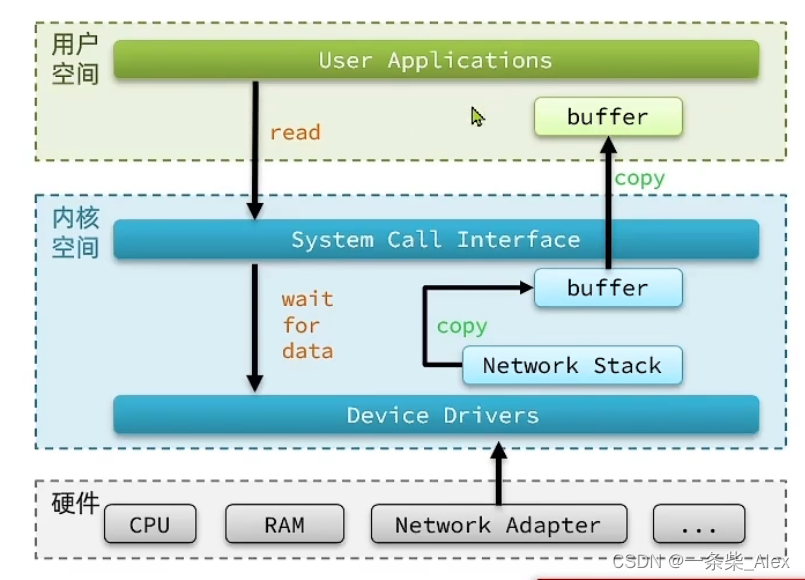
2、用户发起IO的基本流程
3、Linux五种IO模型
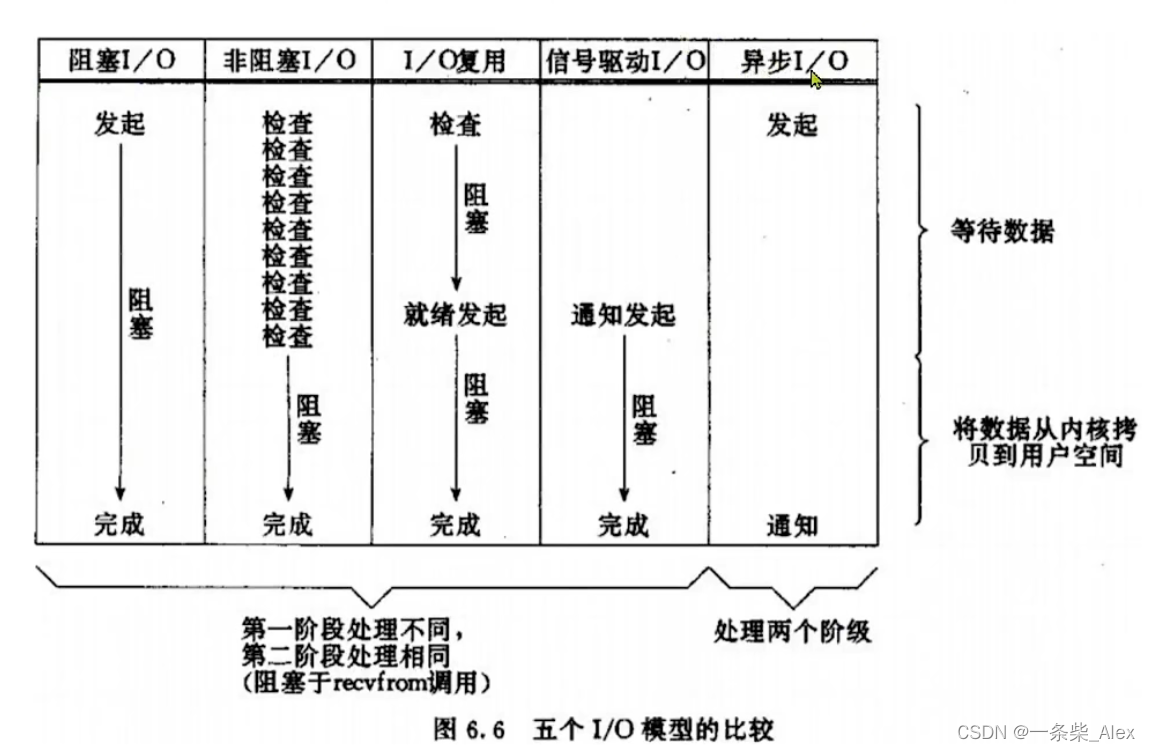
在《UNIX网络编程》一书中,总结归纳了5种IO模型:
- 阻塞I0 (Blocking IO)
- 非阻塞I0 (Nonblocking IO)
- IO多路复用 (IO Multiplexing)
- 信号驱动IO (SignalDriven IO)
- 异步IO(AsynchronousIO)
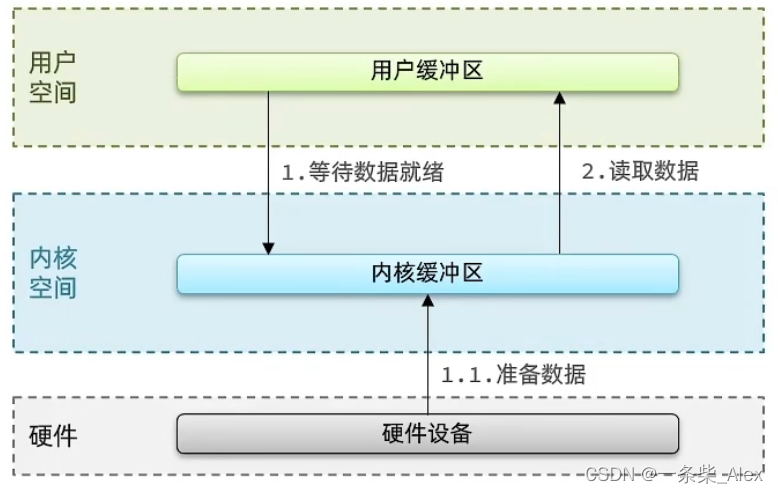
五种不同的IO模型其实关注点都是在这个区域
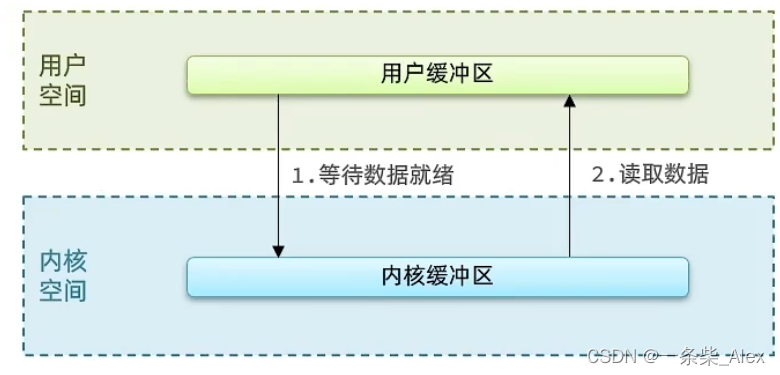
1、阻塞IO
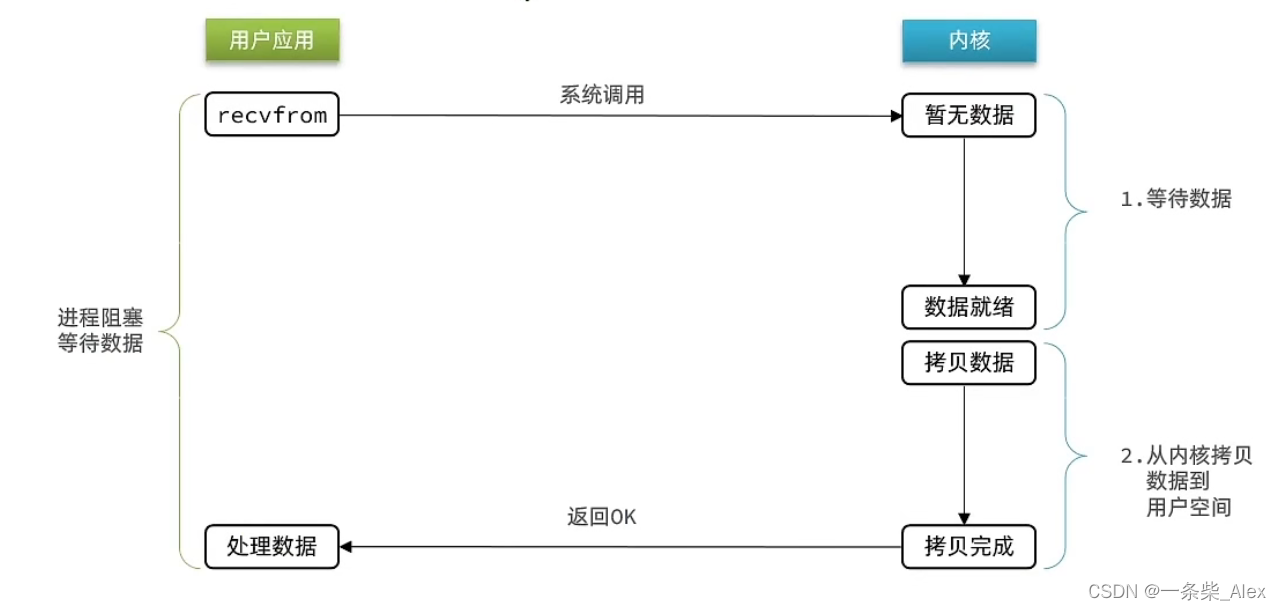
过程:用户发起recvfrom调用,若当前无法获得数据,用户会一直阻塞等待,直到内核完成数据获取、拷贝,并返回ok给用户,通知用户处理,用户进程才被唤醒。
阻塞IO,用户进程在用户在【内核尝试获取数据】,和【内核从内核缓存拷贝数据到用户缓存】,这两个阶段都是阻塞状态。
2、非阻塞IO
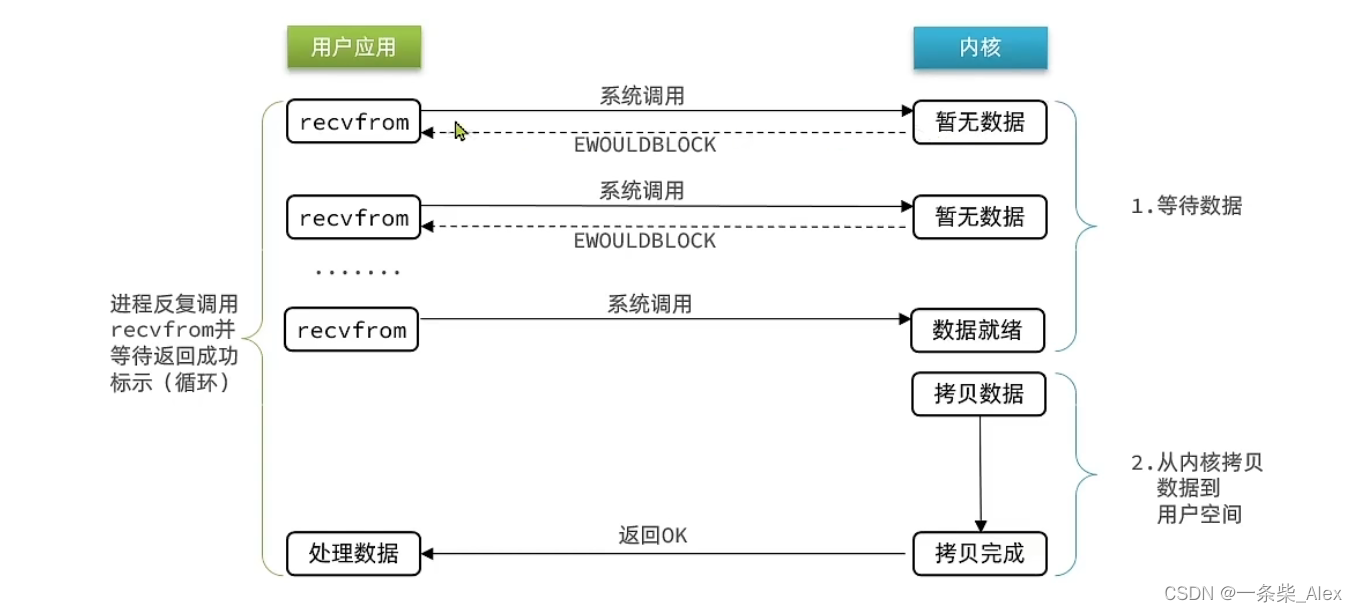
用户进程发起recvfrom调用之后会立即返回,而不是阻塞进程。数据拷贝阶段,用户进程仍然是阻塞的。
第一阶段一直轮询,用户进程并没有去做其他的事,并没有提高效率,忙等反而会导致CPU空转,整个系统效率反而不高。
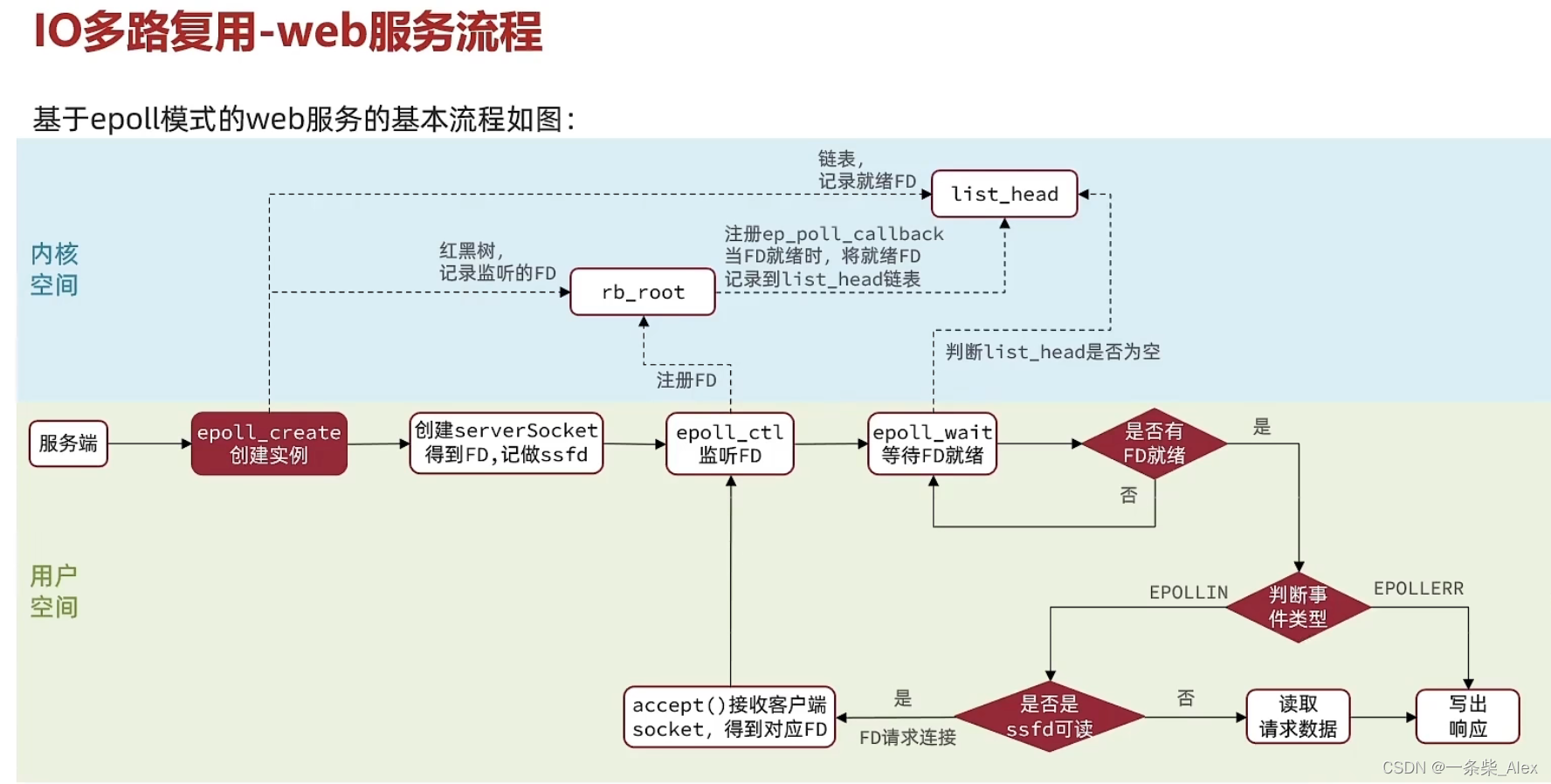
3、IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
如果调用recvfrom时,恰好没有数据,阻塞IO会使进程阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
比如服务端处理客户端Socket请求时,在单线程情况下,只能依次处理每一个socket,如果正在处理的sket恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有其它客户端socket都必须等待,性能自然会很差。
如果用户进程去监听多个Socket,只要某个套接字数据就绪了,可以开始真正的读写了,我们再去调用recvfrom呢
原本是一个服务员窗口,几十个顾客排队点餐。这种情况下,某一顾客一纠结吃啥,后面的人都只能等待。
现在是大家都坐在自己位置上,某个顾客想好了点什么,就叫服务员。
具体实现:
文件描述符(File Descriptor):简称FD,是一个从0 开始递增的无符号整数,用来关联Linux中的一个文件。
在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字 (Socket)
IO多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
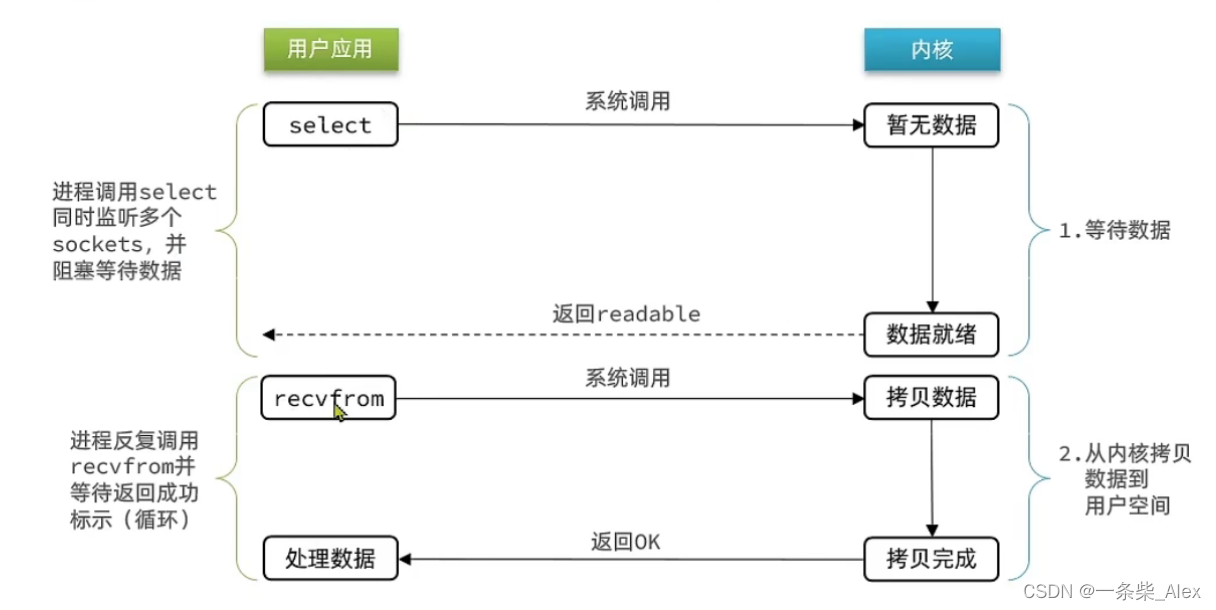
第二阶段调用recvfrom之所以要循环,是因为第一阶段可能有多个socketFD准备就绪,
在第二阶段里被循环依次被处理
select系统调用可以接收多个被监听的套接字FD
而recvfrom只能监听一个FD
** 所以前面阻塞IO 和非阻塞IO其实都是逮着一只羊薅(只服务一个FD),而IO多路复用虽然第一阶段也是阻塞的,但是select本质上是一种批处理的思想,同时监听多个FD,只要有一个FD就绪,就先处理它。
监听FD的方式、通知的方式有多种,常见的方式:
- select
- poll
- epoll
差异
- select和poll只会通知用户进程有FD就绪,但不确定具体是哪个FD,需要用户进程逐个遍历FD来确认
- epoll则会在通知用户进程FD就绪的同时,把已就绪的FD写入用户空间
1、Select模型
Select是Linux中最早的IO多路复用实现方案

fd_set 使用了位示图来表示fd状态。32个long型元素 即 32*32 =1024bit=1kB

select模式存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量不能超过1024
2、poll模式

fds 是一个结构体指针,同时它也是能构成一个自定义大小的结构体数组,fds+1即指向下一个数组元素。
该结构体内部由 fd,当前要监听的事件类型,和该事件真实发生的类型状态组成。
用户态调用poll函数,传入若干需要被监听fd结构体(每一个结构体实例就代表一个fd)构成结构体数组。
当系统进入内核态后,如果这些fd就绪,内核会修改这些fd对应的结构体实例的revent,最终把整个结构体数组返回给用户态。
IO流程
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- 内核遍历fd,判断是否就绪
- 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
- 用户进程判断n是否大于0
- 大于0则遍历pollfd数组,找到就绪的fd
poll和Select
1、poll没用监听fd数量限制,Select限制为1024,因为二者记录fd的数据结构不同。
2、Select和poll 都需要把 记录fd的数组 从用户态传入内核态。内核处理完后,同样从内核态拷贝回用户态
3、二者从内核态返回的fd数组,都没有直接指明具体是哪个fd就绪,需要用户逐一遍历,找到就绪fd
这就产生一个问题:数组容量变大了,但是任然需要遍历,样本空间变大的情况下,效率反而下降了。
3、epoll

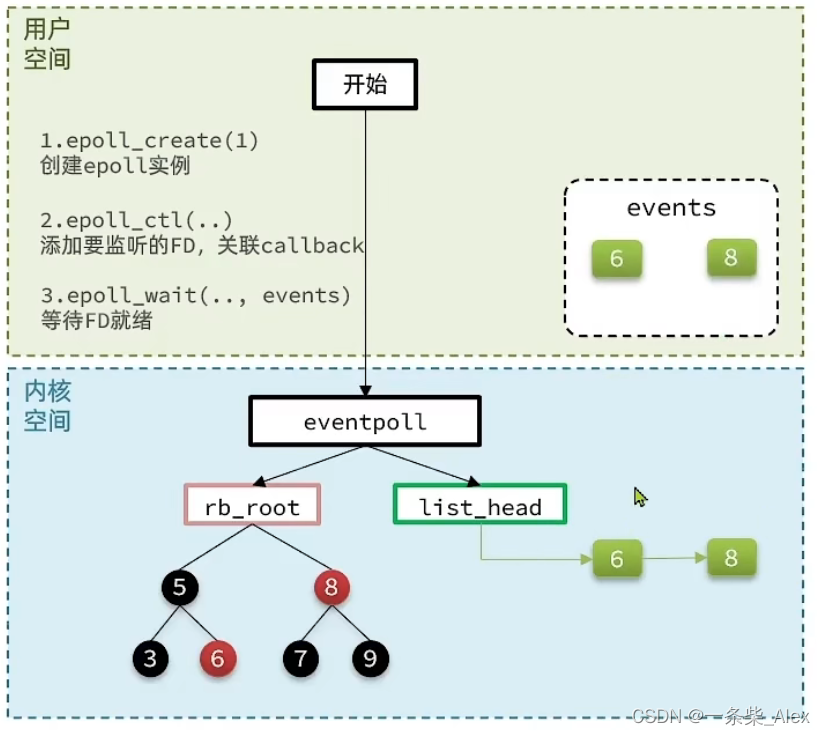
红黑树 的特点 :有序、按序插入删除时间复杂度相对链表要更低。(O(lg2N))

epfd是 eventpoll实例的唯一标识,用户端调用几次epoll_crate, 内核就会创建几个eventpoll,并返回对应的epfd 标识。
select模式存在的三个问题
- 能监听的FD最大不超过1024
- 每次select都需要把所有要监听的FD都拷贝到内核空间
- 每次都要遍历所有FD来判断就绪状态
poll模式的问题:
poll利用链表解决了select中监听FD上限的问题,但依然要遍历所有FD,如果监听较多,性能会下降
epoll模式中如何解决这些问题的?
- 基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高,性能不会随监听的FD数量增多而下降
- 每个FD只需要执行一次epoll ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
- 内核会将就绪的FD直接拷贝到用户空间的指定位置,用户进程无需遍历所有FD就能知道就绪的FD是谁
lO多路复用-事件通知机制
当FD有数据可读时,我们调用epoll_wait就可以得到通知。但是事件通知的模式有两种:
LevelTriggered:简称LT。当FD有数据可读时,会重复通知多次,直至数据处理完成。是Epoll的默认模式
EdgeTriggered:简称ET。当FD有数据可读时,只会被通知一次,不管数据是否处理完成
举例:
1、假设一个客户端socket对应的FD已经注册到了epoll实例中
2、客户端socket发送了2kb的数据
3、服务端调用epoll_wait,得到通知说FD就绪服务端从
4、FD读取了1kb数据
5、回到步骤3(再次调用epoll wait,形成循环)
结论:
ET模式避免了LT模式可能出现的惊群现象
ET模式最好结合非阻塞IO读取FD数据,相比LT会复杂一些
4、信号驱动IO
信号驱动10是与内核建立SIGI0的信号关联并设置回调,当内核有FD就绪时,会发出SIGI0信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。

当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出
而且内核空间与用户空间的频繁信号交互性能也较低
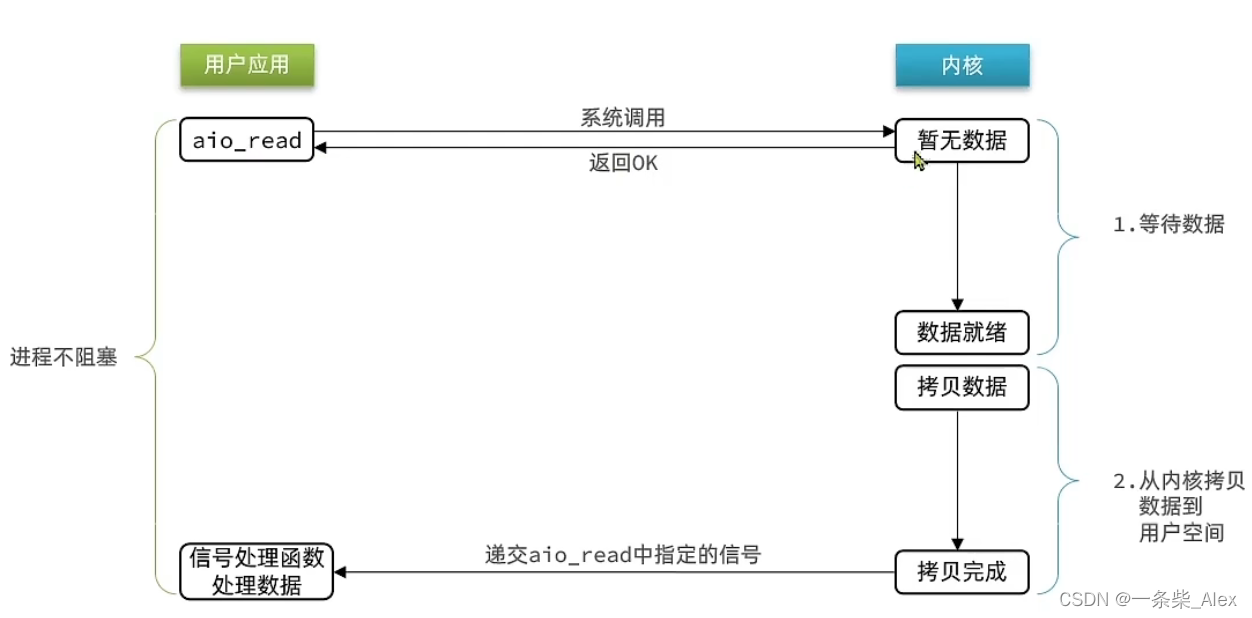
5、异步IO
异步IO的整个过程都是非阻塞的,用户进程调用完异步API后就可以去做其它事情,内核等待数据就绪并拷贝到用户空间后才会递交信号,通知用户进程。
异步IO要做好限流,防止异步IO请求请求过多,造成系统负荷过高。
IO操作是同步还是异步,关键看数据在内核空间与用户空间的拷贝过程(数据读写的10操作),也就是阶段是同步还是异步:
相关文章:
Linux 5种网络模型
[参考]:《黑马程序员Redis》https://www.bilibili.com/video/BV1cr4y1671t/?p166&share_sourcecopy_web&vd_source9e65300ccca322aeb367bb1eb677b0fc [参考]:《操作系统》 [参考]:《UNIX网络编程》 为了避免用户应用导致冲突甚至内…...
10.1 调试事件读取寄存器
当读者需要获取到特定进程内的寄存器信息时,则需要在上述代码中进行完善,首先需要编写CREATE_PROCESS_DEBUG_EVENT事件,程序被首次加载进入内存时会被触发此事件,在该事件内首先我们通过lpStartAddress属性获取到当前程序的入口地…...

Linux系统常用指令篇---(一)
Linux系统常用指令篇—(一) 1.cd指令 Linux系统中,磁盘上的文件和目录被组成一棵目录树,每个节点都是目录或文件。 语法:cd 目录名 功能:改变工作目录。将当前工作目录改变到指定的目录下。 (简单理解为进入指定目录下) 举例: cd .. : 返…...

【初识Linux】:常见指令(1)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux的基础知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精通 数…...
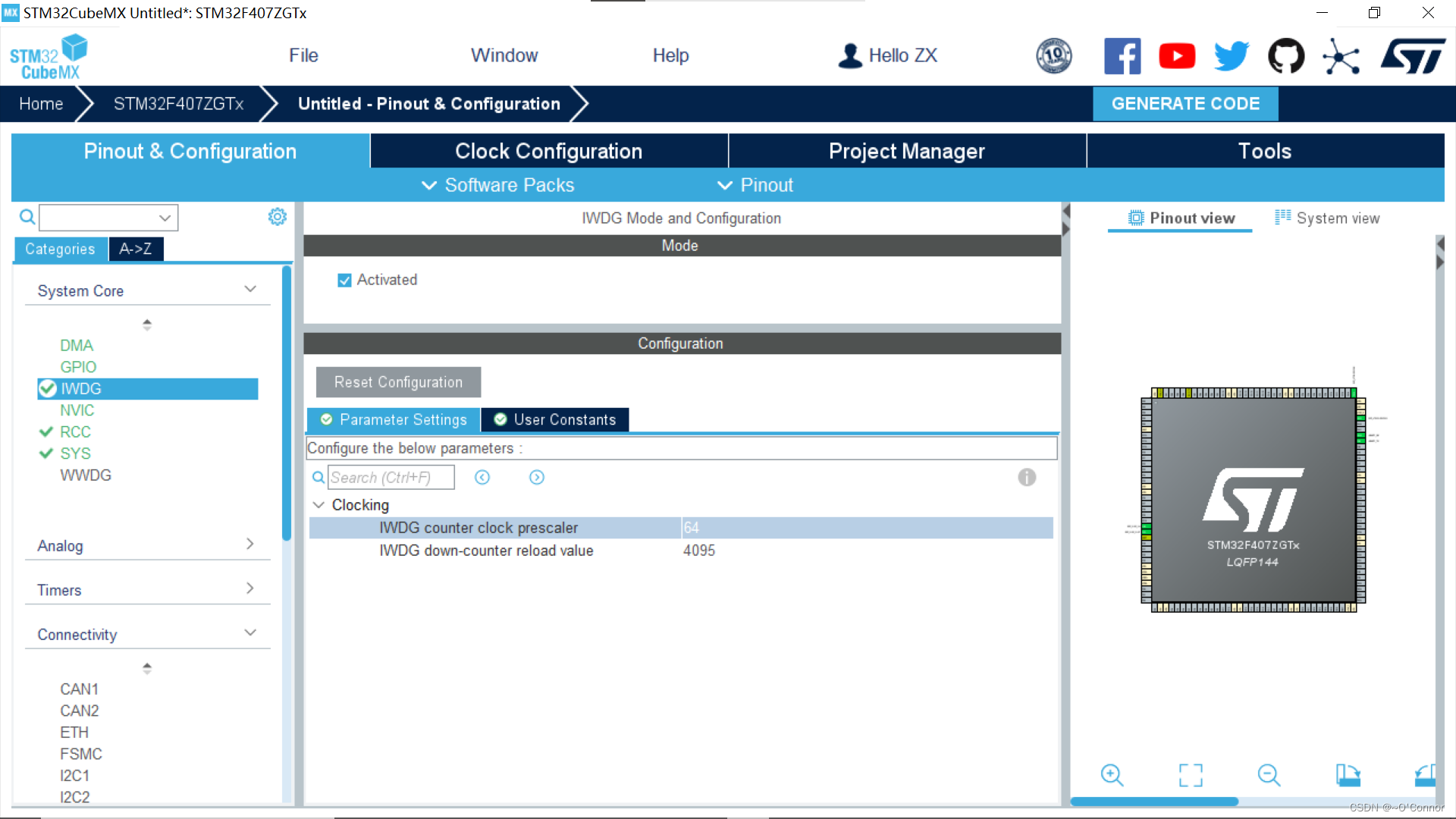
STM32复习笔记(四):看门狗
目录 (一)简介 (二)IWDG IWDG的CUBEMX工程配置 IWDG相关函数(非常少,所以直接贴上来): (三)WWDG (一)简介 看门狗分为独立看门…...

【C++进阶(七)】仿函数深度剖析模板进阶讲解
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 模板进阶 1. 前言2. 仿函数的概念3. 仿函数的实…...
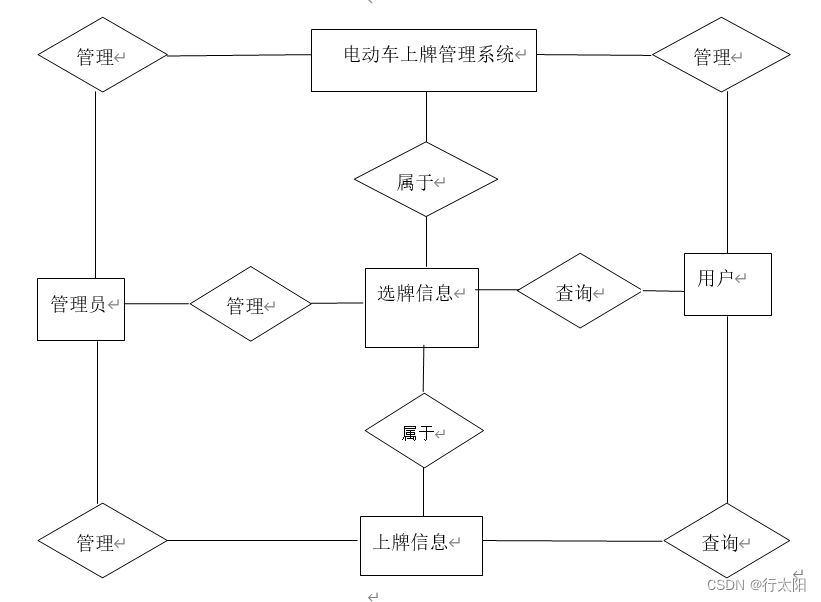
基于SSM的电动车上牌管理系统(有报告)。Javaee项目。
演示视频: 基于SSM的电动车上牌管理系统(有报告)。Javaee项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring SpringM…...
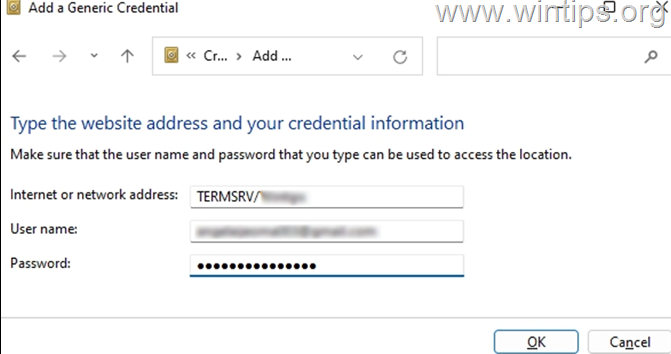
mstsc无法保存RDP凭据, 100%生效
问题 即使如下两项都打勾,其还是无法保存凭据,特别是连接Ubuntu (freerdp server): 解决方法 网上多种复杂方法,不生效,其思路是修改后台配置,以使mstsc跟平常一样自动记住凭据。最后,如下的…...

OpenGLES:绘制一个混色旋转的3D球体
效果展示 本篇博文会实现一个混色旋转的3D球体 一.球体解析 前面几篇博文讲解了如何使用OpenGLES实现不同的3D图形 本篇博文讲解怎样实现3D世界的代表图形:一个混色旋转的3D球体 1.1 极限正多面体 如果有学习过我前几篇3D图形绘制的博文,就知道要想…...

Spring AOP 基于注解源码整理
导入配置类 EnableAspectJAutoProxy 注解导入 AspectJAutoProxyRegistrarImportBeanDefinitionRegistrar#registerBeanDefinitions向容器中加入AnnotationAwareAspectJAutoProxyCreatorAnnotationAwareAspectJAutoProxyCreator#initBeanFactory初始化ReflectiveAspectJAdvisor…...
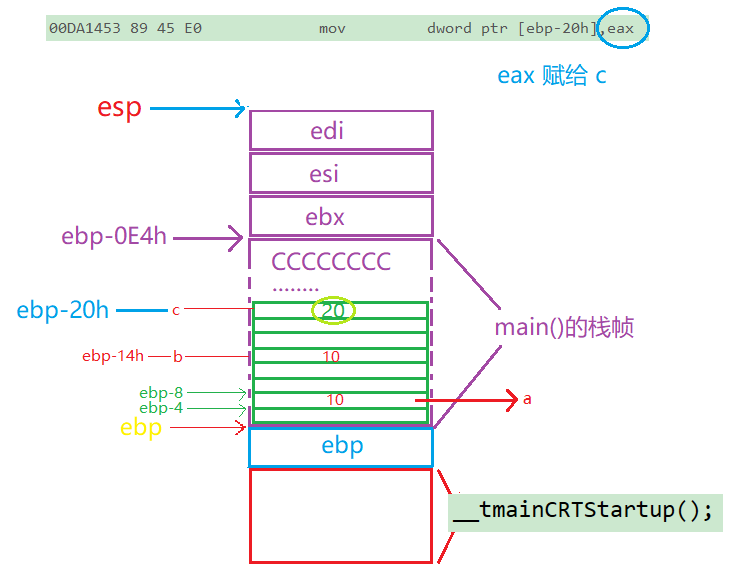
C语言 —— 函数栈帧的创建和销毁
在我们之前学习函数的时候,我们可能有很多困惑? 比如: 局部变量是怎么创建的?为什么局部变量的值是随机值?函数是怎么传参的?传参的顺序是怎样的?形参和实参是什么关系?函数调用是怎么做的?函数调用是结束后怎么返回的? 那么要解决这些问题, 我们就需要知道…...

Appleid苹果账号自动解锁改密(自动解锁二验改密码)
目前该项目能实现以下功能: 多用户使用,权限控制多账号管理账号分享页,支持设置密码、有效期、自定义HTML内容自动解锁与关闭二步验证自动/定时修改密码自动删除Apple ID中的设备代理池与Selenium集群,提高解锁成功率允许手动触发…...

Conflicting peer dependency: eslint@8.50.0
npm install 输出 npm ERR! code ERESOLVE npm ERR! ERESOLVE could not resolve npm ERR! npm ERR! While resolving: vue/eslint-config-standard6.1.0 npm ERR! Found: eslint-plugin-vue8.7.1 npm ERR! node_modules/eslint-plugin-vue npm ERR! dev eslint-plugin-vue…...

Vue3 defineProps使用
MyTag.vue <script setup> import { ref, nextTick, defineProps, defineEmits } from "vue"; const props defineProps({flag: Boolean,title: String, }); // 写成这样也可以 // const props defineProps(["flag", "title"]);const e…...
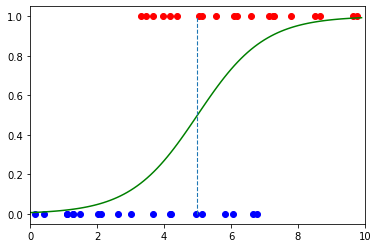
机器学习7:逻辑回归
一、说明 逻辑回归模型是处理分类问题的最常见机器学习模型之一。二项式逻辑回归只是逻辑回归模型的一种类型。它指的是两个变量的分类,其中概率用于确定二元结果,因此“二项式”中的“bi”。结果为真或假 — 0 或 1。 二项式逻辑回归的一个例子是预测人…...

生活小记-纸张尺寸
A系列纸张: A0:841 x 1189 毫米A1:594 x 841 毫米A2:420 x 594 毫米A3:297 x 420 毫米A4:210 x 297 毫米A5:148 x 210 毫米A6:105 x 148 毫米A7:74 x 105 毫米A8…...
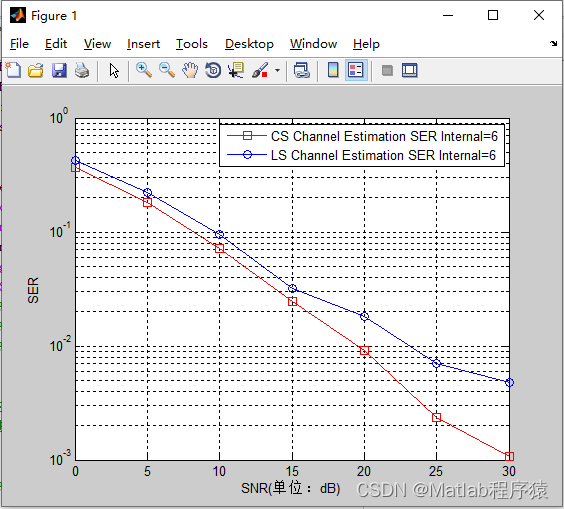
【MATLAB源码-第41期】基于压缩感知算法的OFDM系统信道估计和LS算法对比仿真。
操作环境: MATLAB 2013b 1、算法描述 压缩感知(Compressed Sensing, CS)是一种从稀疏或可压缩信号中重构完整信号的数学理论和技术。下面详细介绍压缩感知和它在OFDM信道估计中的应用。 1. 压缩感知基本概念 在传统采样理论中࿰…...

优思学院|六西格玛将烹饪和美味提升至极致
最近,我们曾提到一个美国男子如何利用六西格玛来控制糖尿病。这表明六西格玛逐渐被认为是一个不仅可以在工作场所之外使用,尤其不仅限于制造业的系统。 六西格玛的核心理念是改进过程的质量,从而改善最终结果。如果你做了晚餐或尝试了一道新…...

git stash
git stash 是 Git 中一个非常有用的命令,用于临时保存当前工作目录中的修改,以便你可以切换到其他分支或处理其他任务而不丢失你的修改。它的主要用途是: 保存未提交的修改:你可以使用 git stash 命令将未提交的修改(包…...

Flink Data Source
Flink Data Source 一、内置 Data Source Flink Data Source 用于定义 Flink 程序的数据来源,Flink 官方提供了多种数据获取方法,用于帮助开发者简单快速地构建输入流,具体如下: 1.1 基于文件构建 1. readTextFile(path):按照 TextInputFormat 格式读取文本文件,并将…...

TinyTroupe:轻量级智能体协作范式与确定性AI工程实践
1. 项目概述:这不是另一个“小模型”,而是一套轻量级智能体协作范式你可能已经看过不少标题带“Tiny”“Mini”“Lite”的AI项目,它们大多是在说“把大模型压缩一下,跑在手机上”。但 Microsoft 的TinyTroupe完全不是这个路数——…...

别再只用轮盘赌了!遗传算法选择算子实战对比:Python代码实现与性能调优心得
遗传算法选择算子深度实战:从轮盘赌到锦标赛的Python优化指南 在解决复杂优化问题时,遗传算法展现出了惊人的适应能力。但许多开发者止步于基础的轮盘赌选择(Roulette Wheel Selection),却不知不同选择策略对算法性能的…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...
)
保姆级教程:手把手教你用Keil 5为APM32F030C6搭建第一个工程(附固件库下载与常见编译错误解决)
从零到一:APM32F030C6在Keil 5上的工程搭建实战指南 第一次接触极海APM32系列芯片的开发者,往往会被陌生的开发环境和复杂的固件库结构弄得手足无措。不同于常见的STM32生态,APM32虽然硬件兼容但软件配置上存在不少差异点。本文将带你用Keil …...

终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案
终极指南:EdgeDB内置迁移系统实现零停机数据库演进的完整方案 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirrors/ed/edgedb …...

基于MCP协议构建Jira Tempo工时管理AI助手:从原理到实践
1. 项目概述:一个专为Jira Tempo设计的MCP服务器 如果你和我一样,每天都要在Jira里手动填写Tempo工时,然后对着那些重复的、琐碎的操作感到厌倦,那么这个项目可能就是你的“救星”。 ivelin-web/tempo-mcp-server 是一个基于Mo…...

终极指南:MobileAgent如何用AI智能体彻底改变跨平台自动化体验
终极指南:MobileAgent如何用AI智能体彻底改变跨平台自动化体验 【免费下载链接】MobileAgent Mobile-Agent: The Powerful GUI Agent Family 项目地址: https://gitcode.com/GitHub_Trending/mo/mobileagent 你是否曾经想过,如果有一个AI助手能够…...

BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼![特殊字符]
BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼!🚀 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModMa…...

华为2288H V5服务器折腾记:LSI SAS3008阵列卡的IT与IR模式到底该怎么选?
华为2288H V5服务器实战:LSI SAS3008阵列卡IT与IR模式深度解析 当你第一次接触华为2288H V5服务器时,那块小小的LSI SAS3008阵列卡可能会让你陷入选择困难——到底该用IT模式还是IR模式?这个问题看似简单,却直接影响着服务器的存储…...

【独家首发】DeepSeek-VL与R1在HumanEval上的性能断层:87.3 vs 62.1分,这15.2分差距究竟卡在哪一行代码?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-VL与R1在HumanEval上的性能断层现象 HumanEval 是评估代码生成模型逻辑正确性的黄金基准,其测试集由 164 道手写 Python 编程题构成,每题包含函数签名、文档字符串和若…...