传统机器学习聚类算法——总集篇
工作需要,涉及到一些聚类算法相关的知识。工作中需要综合考虑数据量、算法效果、性能之间的平衡,所以开启新的篇章——机器学习聚类算法篇。
传统机器学习中聚类算法主要分为以下几类:
1. 层次聚类算法
层次聚类算法是一种无监督学习算法,按照样本 or 簇之间的相似性对数据进行递归式划分,将数据样本从独立的点 逐步合并 成类簇,最终生成一颗树形结构。主要分为自上而下、自下而上 和以BIRCH算法为代表的分层、平衡迭代 三种方法。
1.1 凝聚层次聚类:自下而上 + 递归 的聚类方法
算法初始化将每个样本都作为单独的簇,然后将相邻的簇、自下而上逐渐合并成更大的簇,直到生成需要的簇数。
该类算法需要计算两个簇之间距离的度量,通常使用欧式距离,或者根据业务或数据类型自定义度量方法。
1.2 分裂层次聚类:自上而下 + 递归 的聚类方法
算法自上而下递归地对样本整体进行聚类,将所有样本归于一个簇,然后依次对簇进行分裂,直到每个簇只包含一个样本。
1.3 BIRCH算法
一种用于大规模数据聚类的层次聚类算法。该算法利用了B树结构来进行聚类,并使用了CF树(Clustering Feature Tree)来存储聚类中心信息。
补充:1.1和1.2两种算法都涉及簇之间的相似度 / 距离的计算or度量,这是层次聚类算法设计的核心。在计算簇之间的距离度量时,可以使用最短距离、最长距离、簇平均距离、重心距离、Ward's方差最小化等,每种距离度量方法都有其适用的数据类型和应用场景;更细致,可以根据业务和数据特征,定制相似度 / 距离的计算方式。
2. 划分聚类算法
划分聚类算法通过迭代聚类中心,达到(类内间距小、类间间距大)或者说 (簇内点足够近,簇间点足够远)的目标,最终算法将数据集划分为多个不相交的簇,每个数据点只属于一个簇。
常用的方法包括K-means、K-medoids、K-means++、二分K-means、C-means、
X-means、CLARANS和 CLARA等。
3. 密度聚类算法
基于密度的聚类算法,是从密度的角度考虑样本之间的关系。该类算法通过计算数据样本分布的疏密情况,从密度的角度考虑样本之间的关系,并利用样本的密度和密度可达性来判断是否属于某个簇,最终将高密度区域的点划分到同一个簇。这种方式可以处理具有复杂形状的簇和有噪声数据。
常用的算法包括DBSCAN(Density-Based Spatial Clustering of Applications with Noise)、OPTICS(Ordering Points To Identify the Clustering Structure)、DENCLUE(DENsity-based CLUstEring)等。
最近博主有复现 + 应用到实际业务中的密度聚类算法是密度峰值聚类DPC —— science《Clustering by fast search and find of density peaks》,效果还不错
4. 基于网格的聚类算法
基于网格的聚类算法,利用多分辨率的网络结构将数据空间划分为一个个的网格单元,并将数据点映射到相应的单元中来进行聚类和类簇的划分。
该类算法简单、高效、适用于高维数据和大规模数据集。但是,缺点是参数敏感、无法处理不规则分布的数据、处理精度也不高
代表算法有STING 算法、CLIQUE算法(结合网格和密度的聚类算法)、WAVE-CLUSTER 算法(引入了小波变换);不同的算法主要区别是采用了不同的网格划分方法,核心步骤如下:
a. 将数据空间划分为多个互不重叠的网格
b. 对每个网格内的数据进行统计,找到高密度网格单元;
c. 将相连的高密度网格单元进行合并,合并为一个簇
d. 将低密度网格单元划分给距离最近的高密度网格单元,并认定为一个粗
5. 模型聚类算法
该类算法主要包括基于概率的模型聚类和基于神经网络的模型聚类。这类算法利用统计模型来描述数据的分布,并根据模型判断数据点是否属于同一个簇(是否具有相同 / 相似的分布)。
5.1 基于模型的聚类算法
为每个未知的簇假设一个模型,然后寻找数据和模型的最佳拟合,最后根据模型判断出的不同簇的分布结果,进行聚类。例如:基于概率的模型聚类算法采用概率生成的方法,假定在同一个簇中的数据有相同的概率分布。最常用的是高斯混合模型(Gaussian Mixture Models, GMM)。
5.2 基于神经网络的聚类算法
主要利用神经网络的特点和能力进行数据聚类,通常将结果映射为数据所属类簇的概率问题。常见的模型有自组织映射(Self-Organizing Maps,SOM)、总体相似度神经网络(Growing Neural Gas,GNG)、流形学习聚类(Manifold Learning-based Clustering)、深度聚类(Deep Clustering)。
基于神经网络的聚类算法具有灵活性和强大的建模能力,能够捕捉数据的复杂结构和非线性关系。然而,它们通常需要更多的数据量、更多的计算资源和训练时间,并且对参数设置和网络结构的选择较为敏感。相对的,该类算法处理效率一般不高;特别是数据量很少时,聚类效果较差
相关文章:

传统机器学习聚类算法——总集篇
工作需要,涉及到一些聚类算法相关的知识。工作中需要综合考虑数据量、算法效果、性能之间的平衡,所以开启新的篇章——机器学习聚类算法篇。 传统机器学习中聚类算法主要分为以下几类: 1. 层次聚类算法 层次聚类算法是一种无监督学习算法&am…...

Ajax
一、什么是Ajax <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevice-wid…...

SQL_ERROR_INFO: “Duplicate entry ‘9003‘ for key ‘examination_info.exam_id‘“
今天刷题的时候,往数据库中插入一条语句,但是这个语句已经存在于数据库中了,所以不能用insert into 语句来插入,应该使用replace into 来插入。 REPLACE INTO examination_info(exam_id,tag,difficulty,duration,release_time) V…...
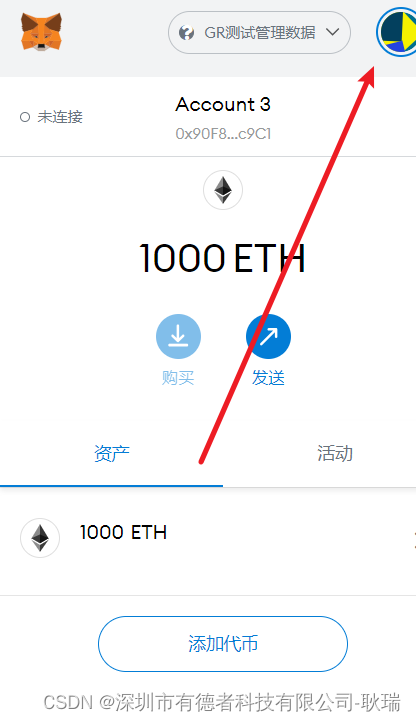
解决每次重启ganache虚拟环境,十个账号秘钥都会改变问题
很多时候 我们启动一个 ganache 环境 然后 通过私钥 在 MetaMask 中 导入用户 但是 当我们因为 电脑要关机呀 或者 ETH 消耗没了呀 那我们就不得不重启一个ganache虚拟环境 然后 你在切一下网络 让它刷新一下 你就会发现 上一次导入的用户就没有了 这是因为 你每次 ganache…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第一周测验
课程2_第1周_测验题 目录:目录 第一题 1.如果你有10,000,000个例子,你会如何划分训练/验证/测试集? A. 【 】33%训练,33%验证,33%测试 B. 【 】60%训练,20%验证,20%测试 C. 【 】98…...
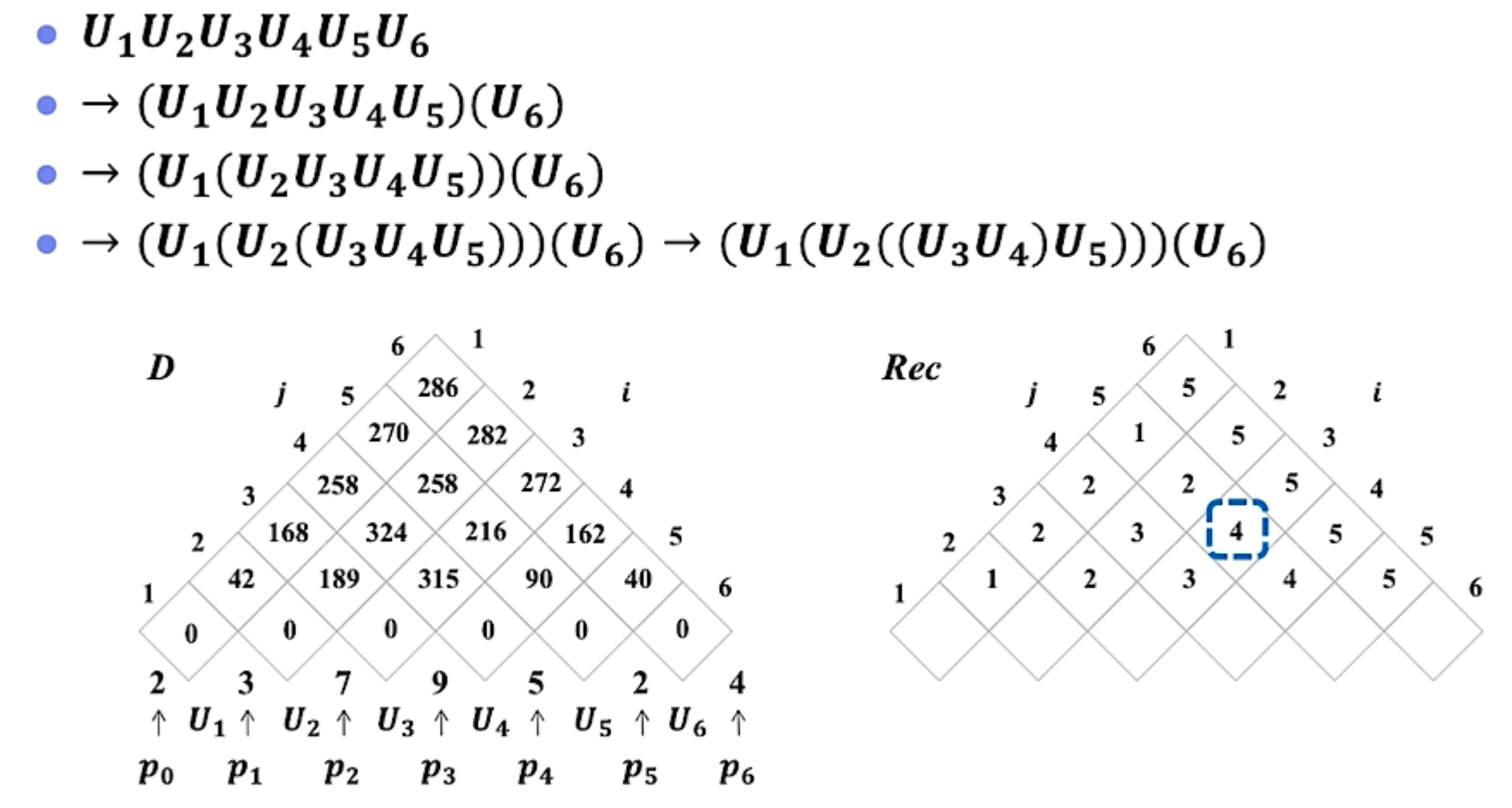
(粗糙的笔记)动态规划
动态规划算法框架: 问题结构分析递推关系建立自底向上计算最优方案追踪 背包问题 输入: n n n个商品组成的集合 O O O,每个商品有两个属性 v i v_i vi和 p i p_i pi,分别表示体积和价格背包容量 C C C 输出: …...
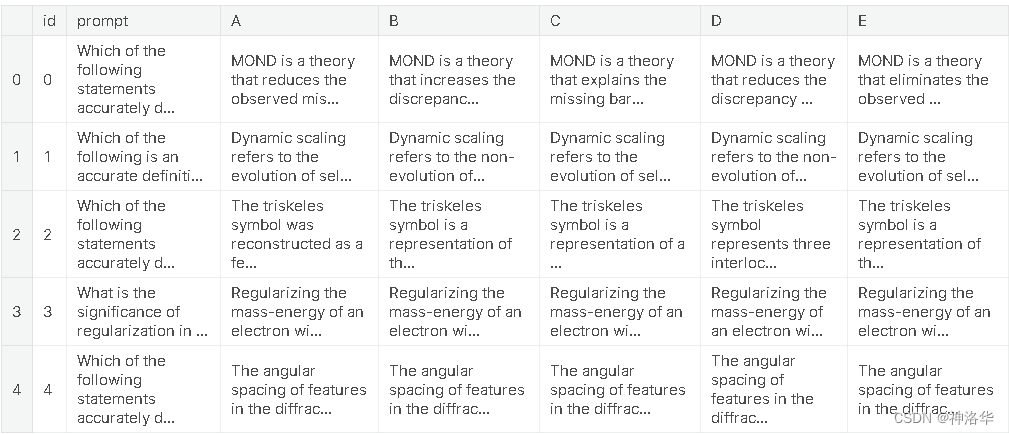
Kaggle - LLM Science Exam上:赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 相关优化 前言:国庆期间…...

数据分析三剑客之一:Numpy详解及实战
1 NumPy介绍 NumPy 软件包是Python生态系统中数据分析、机器学习和科学计算的主力军。它极大地简化了向量和矩阵的操作处理。Python的一些主要软件包(如 scikit-learn、SciPy、pandas 和 tensorflow)都以 NumPy 作为其架构的基础部分。除了能对数值数据…...
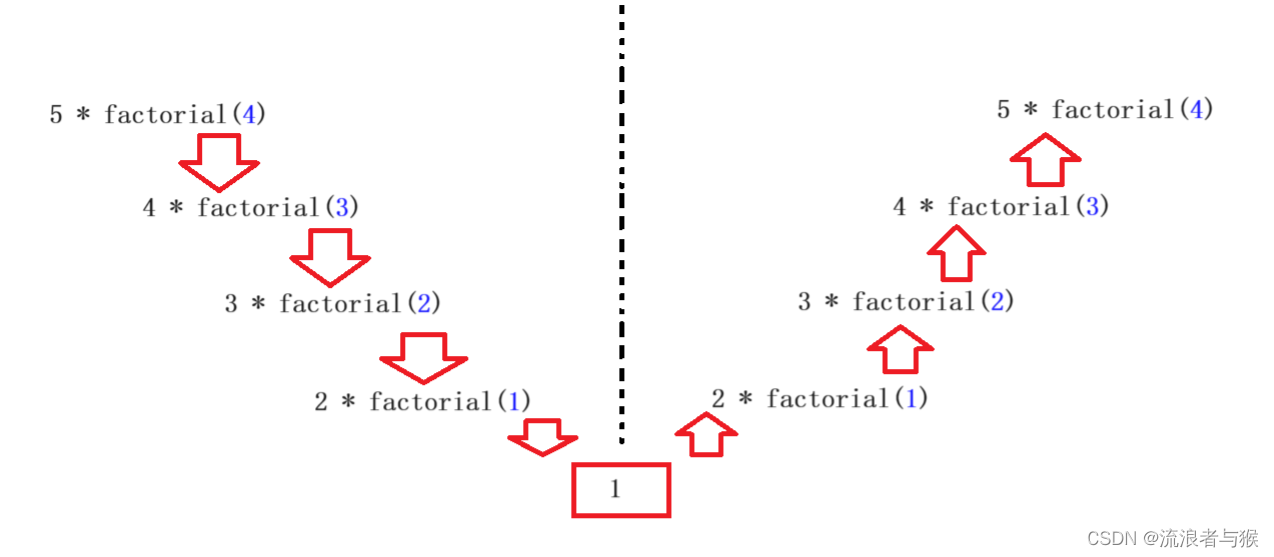
【C语言】函数的定义、传参与调用(二)
💗个人主页💗 ⭐个人专栏——C语言初步学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读: 1. 函数的嵌套调用 1.1 什么是嵌套调用 1.2 基础实现 1.3 调用流程解析 2. 函数的链式访问 2.1 …...
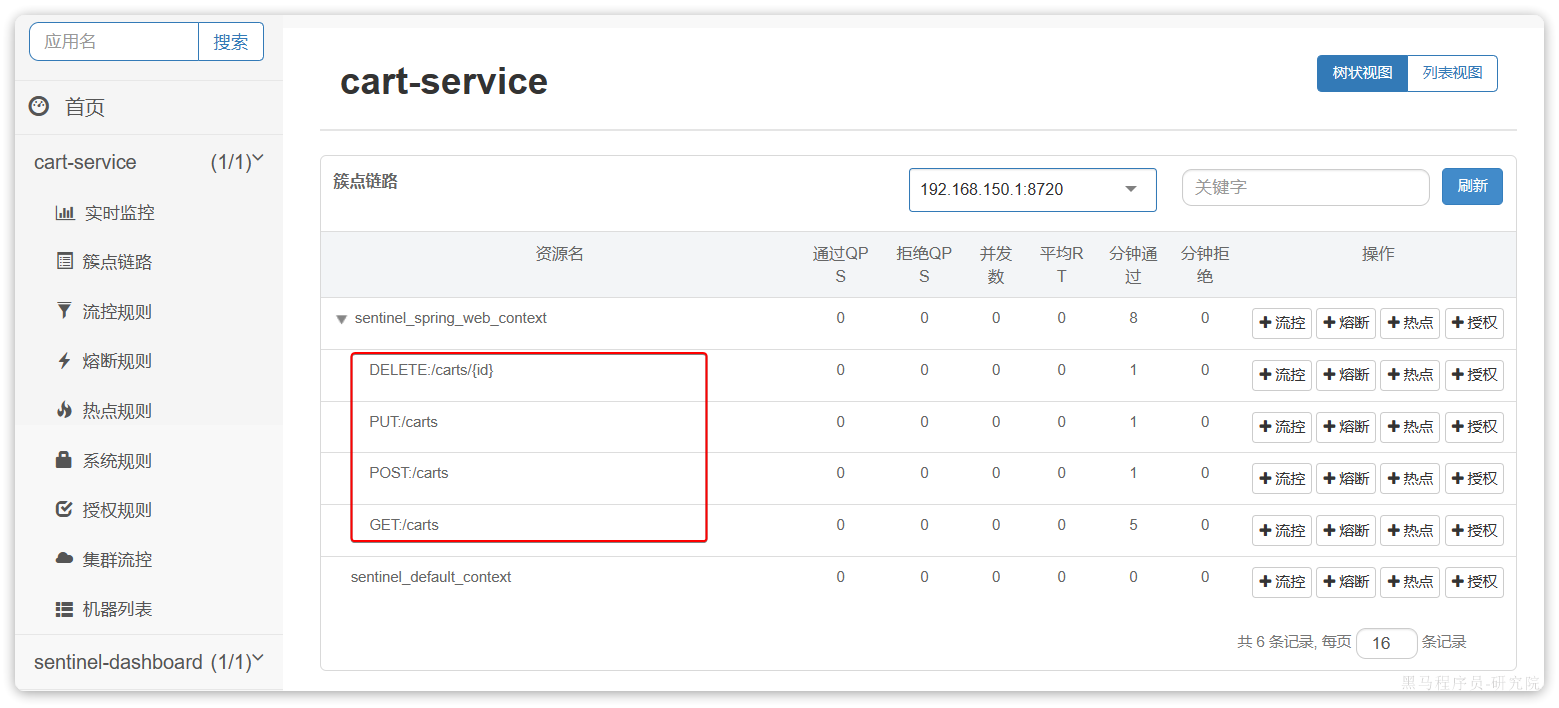
Sentinel安装
Sentinel 微服务保护的技术有很多,但在目前国内使用较多的还是Sentinel,所以接下来我们学习Sentinel的使用。 1.介绍和安装 Sentinel是阿里巴巴开源的一款服务保护框架,目前已经加入SpringCloudAlibaba中。官方网站: 首页 | Se…...
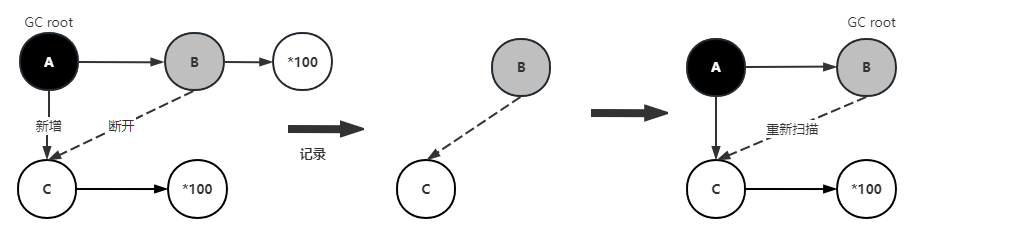
【JVM】并发可达性分析-三色标记算法
欢迎访问👋zjyun.cc 可达性分析 为了验证堆中的对象是否为可回收对象(Garbage)标记上的对象,即是存活的对象,不会被垃圾回收器回收,没有标记的对象会被垃圾回收器回收,在标记的过程中需要stop…...
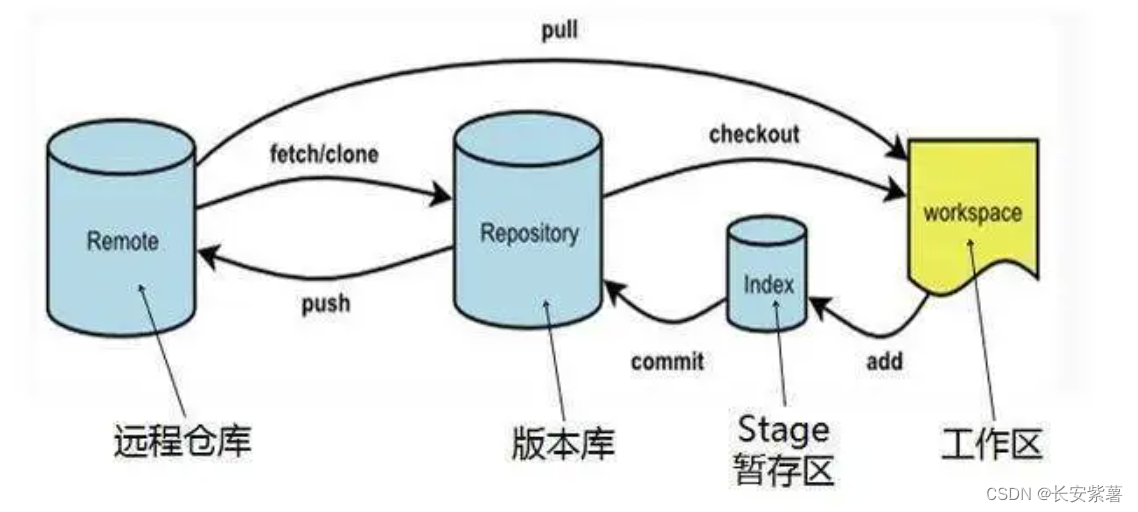
黑豹程序员-架构师学习路线图-百科:Git/Gitee(版本控制)
文章目录 1、什么是版本控制2、特点3、发展历史4、SVN和Git比较5、Git6、GitHub7、Gitee(国产)8、Git的基础命令 1、什么是版本控制 版本控制系统( Version Control )版本控制是一种管理和跟踪软件开发过程中的代码变化的系统。它…...
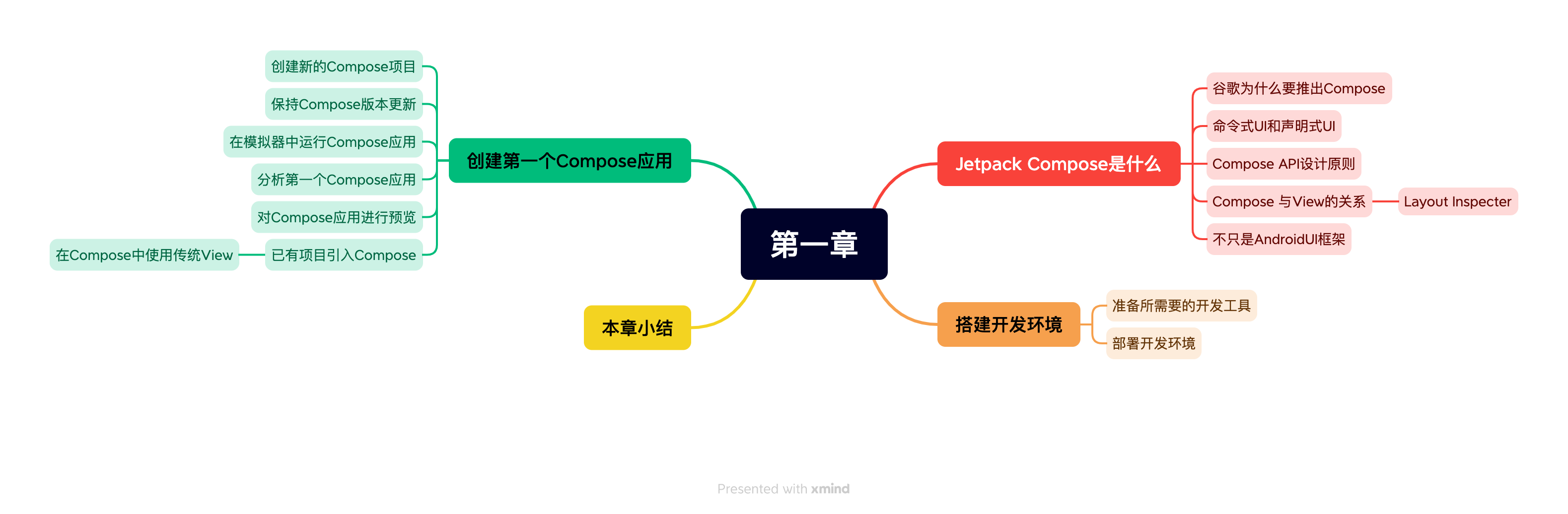
《Jetpack Compose从入门到实战》第一章 全新的 Android UI 框架
书籍源码 Compose官方文档 《Jetpack Compose从入门到实战》第一章 全新的 Android UI 框架 《Jetpack Compose从入门到实战》 第二章 了解常用UI组件 《Jetpack Compose从入门到实战》第三章 定制 UI 视图 《Jetpack Compose从入门到实战》第八章 Compose页面 导航 《Jet…...
基于Spring Boot的中小型医院网站的设计与实现
目录 前言 一、技术栈 二、系统功能介绍 前台首页界面 用户登录界面 用户注册界面 门诊信息详情界面 预约挂号界面 药品详情界面 体检报告界面 管理员登录界面 用户管理界面 医师管理界面 科室类型管理界面 门诊信息管理界面 药库信息管理界面 预约挂号管理界面…...

uniapp iOS离线打包——如何创建App并提交版本审核?
uniapp 如何创建App,并提交版本审核? 文章目录 uniapp 如何创建App,并提交版本审核?登录 appstoreconnect创建AppiOS 预览和截屏应用功能描述技术支持App 审核信息 App 信息内容版权年龄分级 价格与销售范围App 隐私提交审核 登录…...
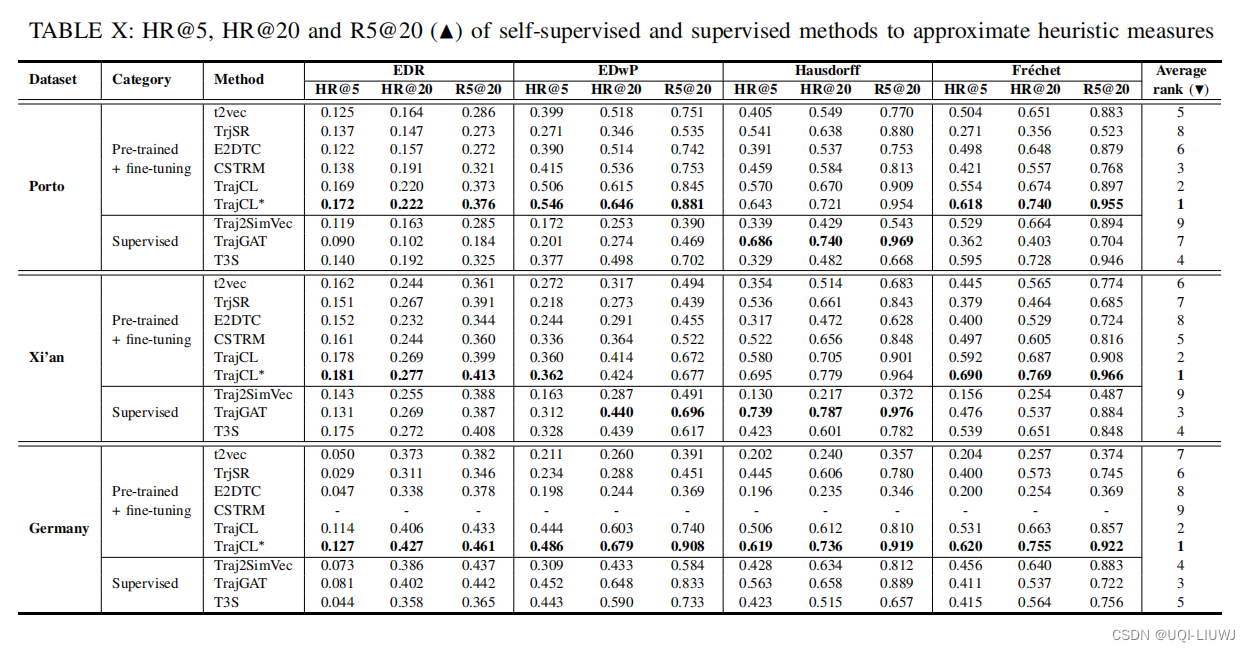
论文笔记:Contrastive Trajectory Similarity Learning withDual-Feature Attention
ICDE 2023 1 intro 1.1 背景 轨迹相似性,可以分为两类 启发式度量 根据手工制定的规则,找到两条轨迹之间基于点的匹配学习式度量 通过计算轨迹嵌入之间的距离来预测相似性值上述两种度量的挑战: 无效性: 具有不同采样率或含有噪…...

整数和字符串比较的坑
结果竟然是相同,惊呆了吧? $num1 2023快放假了; $num2 2023;if ($num1 $num2) {echo 相同; } else {echo 不相同; }num2改成字符串类型,结果:不相同,又不懵了吧? $num1 2023快放假了; $num2 2023;if…...

LeetCode 面试题 08.04. 幂集
文章目录 一、题目二、C# 题解 一、题目 幂集。编写一种方法,返回某集合的所有子集。集合中不包含重复的元素。 说明: 解集不能包含重复的子集。 示例: 输入: nums [1,2,3] 输出: [ [3], [1], [2], [1,2,3], [1,3], [2,3], [1…...

【m_listCtrl !=NULL有多个运算符与操作数匹配】2023/9/21 上午11:03:44
2023/9/21 上午11:03:44 m_listCtrl !=NULL有多个运算符与操作数匹配 2023/9/21 上午11:04:00 如果您在编译或运行代码时遇到"M_listCtrl != NULL有多个运算符与操作数匹配"的错误提示,这通常是由于以下几个原因之一: 错误使用运算符:在条件判断语句中,应该使…...

Logrus 集成 color 库实现自定义日志颜色输出字符原理
问题背景 下列代码实现了使用 Logurs 日志框架输出日志时根据级别不同,使用对应的自定义颜色进行输出。那么思考下代码的逻辑是怎么实现的呢? 效果如下: 代码如下: import ("fmt""github.com/sirupsen/logrus&q…...

生物认证锁:用虹膜加密核心模块——软件测试从业者的专业指南
在数字化转型浪潮中,生物认证技术正重塑安全防护体系,其中虹膜识别凭借其超高精度和防伪特性,成为加密核心模块(如支付系统、数据库访问控制或敏感API)的首选方案。作为软件测试从业者,您肩负着验证系统鲁棒…...

虚拟光驱软件Daemon Tools Lite
链接:https://pan.quark.cn/s/ebc5b998a07bDaemon Tools Lite 是一款免费、稳定、方便、优秀的虚拟光驱软件。安装后会自动在资源管理器生成一个和真实光驱一样的盘符,让您像访问真正光驱一样来访问虚拟光驱。Daemon Tools Lite 还可以模拟备份并且合并保…...

打破学术写作边界:NativeOverleaf离线工作流全解析
打破学术写作边界:NativeOverleaf离线工作流全解析 【免费下载链接】NativeOverleaf Next-level academia! Repository for the Native Overleaf project, attempting to integrate Overleaf with native OS features for macOS, Linux and Windows. 项目地址: ht…...

从“连连看”到DFA最小化:一个游戏化思路帮你彻底理解状态等价
从“连连看”到DFA最小化:用游戏化思维破解编译原理难题 编译原理作为计算机科学的核心课程之一,常常让初学者望而生畏。特别是当教材开始讨论"确定性有限自动机(DFA)最小化"这类概念时,那些抽象的状态转换图…...

Vial-QMK键盘固件从入门到精通:打造专属机械键盘体验
Vial-QMK键盘固件从入门到精通:打造专属机械键盘体验 【免费下载链接】vial-qmk QMK fork with Vial-specific features. 项目地址: https://gitcode.com/gh_mirrors/vi/vial-qmk Vial-QMK是一款功能强大的开源键盘固件,为机械键盘爱好者提供了全…...

如何用WechatFerry构建企业级微信自动化解决方案
如何用WechatFerry构建企业级微信自动化解决方案 【免费下载链接】wechatferry 基于 WechatFerry 的微信机器人底层框架 项目地址: https://gitcode.com/gh_mirrors/wec/wechatferry 一、场景化价值:从业务痛点到自动化突破 在数字化转型加速的今天…...
)
终极指南:如何使用Rainmeter构建内存使用趋势预测模型(ARIMA/SVM应用)
终极指南:如何使用Rainmeter构建内存使用趋势预测模型(ARIMA/SVM应用) 【免费下载链接】rainmeter Desktop customization tool for Windows 项目地址: https://gitcode.com/gh_mirrors/ra/rainmeter Rainmeter作为一款强大的Windows桌…...
)
Node RED实战:5分钟搞定MQTT消息发布与订阅(附EMQX配置)
Node RED与MQTT实战:从零构建物联网消息系统 1. 为什么选择Node RED与MQTT组合? 物联网开发领域一直存在一个核心挑战:如何快速搭建可靠的消息通信系统而不陷入底层协议实现的泥潭。这正是Node RED与MQTT这对黄金组合的价值所在——它们让开发…...

Qwen3.5-4B-Claude-Opus惊艳效果:编译原理词法分析器状态转换图生成
Qwen3.5-4B-Claude-Opus惊艳效果:编译原理词法分析器状态转换图生成 1. 模型能力展示:从代码到状态转换图 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF模型在编译原理领域展现了令人惊艳的代码理解与可视化能力。当输入词法分析器代码时&…...

压力型旋流喷嘴内喉部一点横向流体运动
(一)单图逐段解读图 1:0~0.0045s 全时段曲线(含完整瞬态 准稳态)分段特征与机理瞬态冲击段(0~0.0002s)曲线特征:极端剧烈的高频正负震荡,峰值接近 2m/s,是全…...