Ultralytics(YoloV8)开发环境配置,训练,模型转换,部署全流程测试记录
关键词:windows docker tensorRT Ultralytics YoloV8
配置开发环境的方法:
1.Windows的虚拟机上配置:
Python3.10
使用Ultralytics 可以得到pt onnx,但无法转为engine,找不到GPU,手动转也不行,找不到GPU。这个应该是需要可以支持硬件虚拟化的GPU,才能在虚拟机中使用GPU。
2.Windows 上配置:
Python3.10
Cuda 12.1
Cudnn 8.9.4
TensorRT-8.6.1.6
使用Ultralytics 可以得到pt onnx,但无法转为engine,需要手动转换。这个实际上是跑通了的。
3.Docker中的配置(推荐)
Windows上的docker
使用的是Nvidia配置好环境的docker,包括tensorflow,nvcc,等。
启动镜像:
docker run --shm-size 8G --gpus all -it --rm tensorflow/tensorflow:latest-gpu在docker上安装libgl,Ultralytics等。
apt-get update && apt-get install libgl1
pip install ultralytics
pip install nvidia-tensorrt
然后进行提交,重新生成一个新的镜像文件:
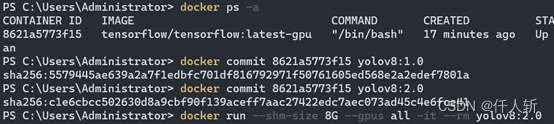
如果不进行提交,则刚才安装的所有软件包,在重启以后就会丢失,需要重新再装一遍。
在docker desktop中可以看到所有的镜像
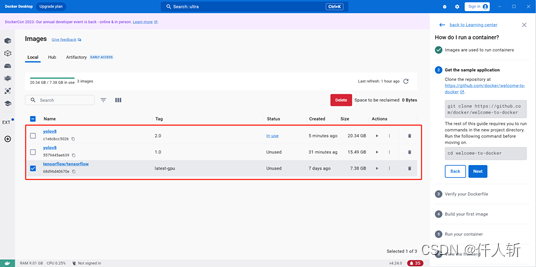
后续启动镜像可以使用
docker run --shm-size 8G --gpus all -it --rm yolov8:2.0
–shm-size 8G 一定要有,否则在dataloader阶段会报错,如下所示:

为了搜索引擎可以识别到这篇文章,将内容打出来:
RuntimeError: DataLoader worker (pid 181032) is killed by signal: Bus error. It is possible that dataloader’s workers are out of shared memory. Please try to raise your shared memory limit
更加详细的介绍,可以参考:https://blog.csdn.net/zywvvd/article/details/110647825
新生成的镜像,可以进行打包,在离线环境中使用。
docker save yolov8:2.0 |gzip > yolov8.tar.gz
将生成的镜像拷贝到离线环境,
docker load < yolov8.tar.gz
ultralytics 快速上手
参考:https://docs.ultralytics.com/modes/
官网的介绍很详细,按照指引,基本上可以配置成功。
模型训练:
def train():#model = YOLO("yolov8n.yaml") # build a new model from scratchmodel = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)model.train(data="coco128.yaml", epochs=3,batch=8) # train the modelmetrics = model.val() # evaluate model performance on the validation set#results = model("https://ultralytics.com/images/bus.jpg") # predict on an imagepath = model.export(format="onnx") # export the model to ONNX format模型转换:
def eval():model = YOLO("best.pt") # load a pretrained model (recommended for training)model.export(format="engine",device=0,simplify=True)model.export(format="onnx", simplify=True) # export the model to onnx format
此时在目录下的文件如下:
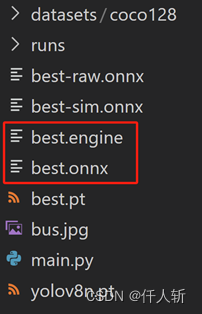
当使用Ultralytics无法导出engine格式的文件时,需要使用tensorRT提供的trtexec进行转换。
事实上,在笔者的测试过程中,即使Ultralytics可以导出engine格式的模型,c++API的tensorrt也无法加载使用。即使python中和c++中使用的tensorRT的版本一致。
在windows平台下,我们可以使用如下的方法进行转换,可以写一个.bat脚本
@echo off
trtexec.exe --onnx=best.onnx --saveEngine=best.engine --fp16 --workspace=2048
:end
PAUSE
对于可变尺寸,需要
@echo offtrtexec.exe --onnx=best.onnx --saveEngine=best.engine --minShapes=images:1x3x640x640 --optShapes=images:8x3x640x640 --maxShapes=images:8x3x640x640 --fp16 --workspace=2048
:end
PAUSE
使用tensorrt加载engine文件进行推理
方法1:python
Python,需要安装pycuda
直接使用
pip install pycuda
进行安装。
def engineeval():# 创建logger:日志记录器logger = trt.Logger(trt.Logger.WARNING)# 创建runtime并反序列化生成enginewith open("best.engine", "rb") as f, trt.Runtime(logger) as runtime:engine = runtime.deserialize_cuda_engine(f.read())# 创建cuda流stream = cuda.Stream()# 创建context并进行推理with engine.create_execution_context() as context:# 分配CPU锁页内存和GPU显存h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)d_input = cuda.mem_alloc(h_input.nbytes)d_output = cuda.mem_alloc(h_output.nbytes)# Transfer input data to the GPU.cuda.memcpy_htod_async(d_input, h_input, stream)# Run inference.context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)# Transfer predictions back from the GPU.cuda.memcpy_dtoh_async(h_output, d_output, stream)# Synchronize the streamstream.synchronize()# Return the host output. 该数据等同于原始模型的输出数据在调试界面,可以看到输入矩阵维度是1228800=13640*640
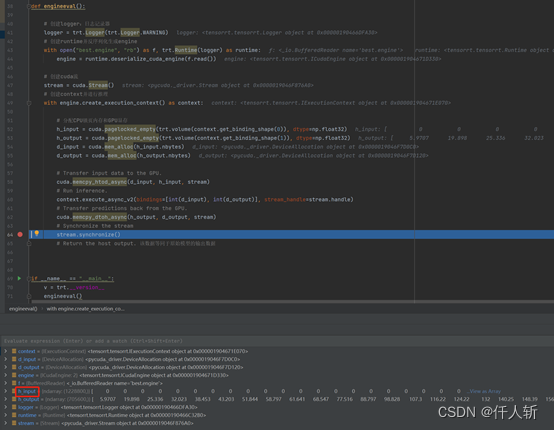
至于推理的精度,还需要传入实际的图像进行测试。这里就不在python环境下测试了。
方法2:c++
生产环境一般是c++,使用tensorrt c++ API进行engine文件的加载与推理,
参考:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#perform_inference_c
代码实现:
#include <iostream>
#include <fstream>#include "NvInfer.h"#include "cuda_runtime.h"using namespace nvinfer1;class Logger : public ILogger
{void log(Severity severity, const char* msg) noexcept override{// suppress info-level messagesif (severity <= Severity::kWARNING)std::cout << msg << std::endl;}
};int main()
{Logger gLogger;IRuntime* runtime = createInferRuntime(gLogger);std::ifstream model("best.engine", std::ios::binary);std::string modelString((std::istreambuf_iterator<char>(model)), std::istreambuf_iterator<char>());ICudaEngine* engine =runtime->deserializeCudaEngine(modelString.c_str(), modelString.length());int nNum = engine->getNbBindings(); //获取绑定的数量auto nDim0 = engine->getBindingDimensions(std::min(0, nNum - 1));auto nDim1 = engine->getBindingDimensions(std::min(1, nNum - 1));int nSize0 = nDim0.d[0] * nDim0.d[1] * nDim0.d[2] * nDim0.d[3];int nSize1 = nDim1.d[0] * nDim1.d[1] * nDim1.d[2];//都是浮点类型auto dt0 = engine->getBindingDataType(0);auto dt1 = engine->getBindingDataType(1);auto name = engine->getName();auto input = engine->getBindingName(0);auto output = engine->getBindingName(1);//准备输入输出空间auto inputBuffer = new float[nSize0];auto outputBuffer = new float[nSize1];memset(inputBuffer, 0, nSize0 * sizeof(float));memset(outputBuffer, 0, nSize1 * sizeof(float));bool ret = false;//创建执行上下文IExecutionContext* context = engine->createExecutionContext();//执行推理:拷贝到GPU->enqueueV3->拷贝回CPUif(1){void* buffers[2];//Allocate GPU memory for Input / Output datacudaMalloc(&buffers[0], nSize0 * sizeof(float));cudaMalloc(&buffers[1], nSize1 * sizeof(float));cudaStream_t stream;cudaStreamCreate(&stream);cudaMemcpyAsync(buffers[0], inputBuffer, nSize0 * sizeof(float), cudaMemcpyHostToDevice, stream);context->setTensorAddress(input, buffers[0]);context->setTensorAddress(output, buffers[1]);ret = context->enqueueV3(stream);if (!ret)std::cout << "error" << std::endl;cudaMemcpyAsync(outputBuffer, buffers[1], nSize1 * sizeof(float), cudaMemcpyDeviceToHost, stream);cudaStreamSynchronize(stream);cudaStreamDestroy(stream);cudaFree(buffers[0]);cudaFree(buffers[1]);}delete[]inputBuffer;delete[] outputBuffer;std::cout << "Done!" << std::endl;context->destroy();engine->destroy();runtime->destroy();return 0;
}执行结果:
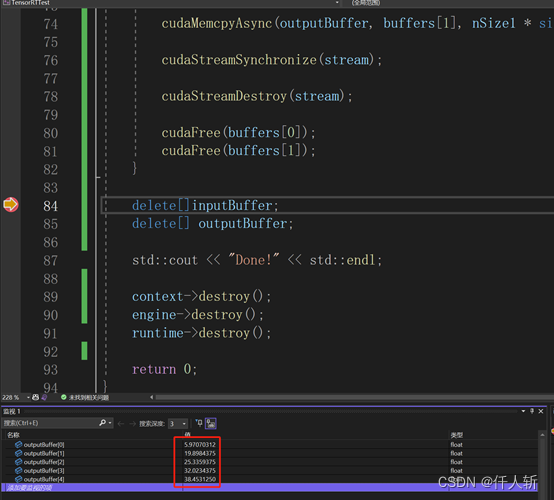
可以看到和python端是相同的。
然后可以做一些工程化的工作,比如对c++代码封装成为一个dll。后面还需要加一些前处理和后处理的步骤,将模型的结果进行解析。
相关文章:
Ultralytics(YoloV8)开发环境配置,训练,模型转换,部署全流程测试记录
关键词:windows docker tensorRT Ultralytics YoloV8 配置开发环境的方法: 1.Windows的虚拟机上配置: Python3.10 使用Ultralytics 可以得到pt onnx,但无法转为engine,找不到GPU,手动转也不行࿰…...

springboot之@ImportResource:导入Spring配置文件~
ImportResource的作用是允许在Spring配置文件中导入其他的配置文件。通过使用ImportResource注解,可以将其他配置文件中定义的Bean定义导入到当前的配置文件中,从而实现配置文件的模块化和复用。这样可以方便地将不同的配置文件进行组合,提高…...
阿里云服务器免费申请入口_注册阿里云免费领4台服务器
注册阿里云账号,免费领云服务器,最高领取4台云服务器,每月750小时,3个月免费试用时长,可快速搭建网站/小程序,部署开发环境,开发多种企业应用。阿里云百科分享阿里云服务器免费领取入口、免费云…...

ES6中的async、await函数
async是为了解决异步操作,其实是一个语法糖,使代码书写更加简洁。 1. async介绍 async放在一个函数的前面,await则放在异步操作前面。async代表这个函数中有异步操作需要等待结果,在一个async函数中可以存在多个await࿰…...
代码随想录算法训练营第五十六天 | 动态规划 part 14 | 1143.最长公共子序列、1035.不相交的线、53. 最大子序和(dp)
目录 1143.最长公共子序列思路代码 1035.不相交的线思路代码 53. 最大子序和(dp)思路代码 1143.最长公共子序列 Leetcode 思路 本题和718. 最长重复子数组 区别在于这里不要求是连续的了,但要有相对顺序,即:“ace” …...

【数据挖掘】2021年 Quiz 1-3 整理 带答案
目录 Quiz 1Quiz 2Quiz 3Quiz 1 Problem 1 (30%). Consider the training data shown below. Here, A A A and B B B</...

【软件设计师-中级——刷题记录6(纯干货)】
目录 管道——过滤器软件体系结构风格优点:计算机英语重点词汇:单元测试主要检查模块的以下5个特征:数据库之并发控制中的事务:并发产生的问题解决方案:封锁协议原型化开发方法: 每日一言:持续更新中... 个…...

微信小程序点单左右联动的效果实现
微信小程序点单左右联动的效果实现 原理解析: 点击左边标签会跳到右边相应位置:点击改变rightCur值,转跳相应位置滑动右边,左边标签会跳到相应的位置:监听并且设置每个右边元素的top和bottom,再判断当…...
Socket通信
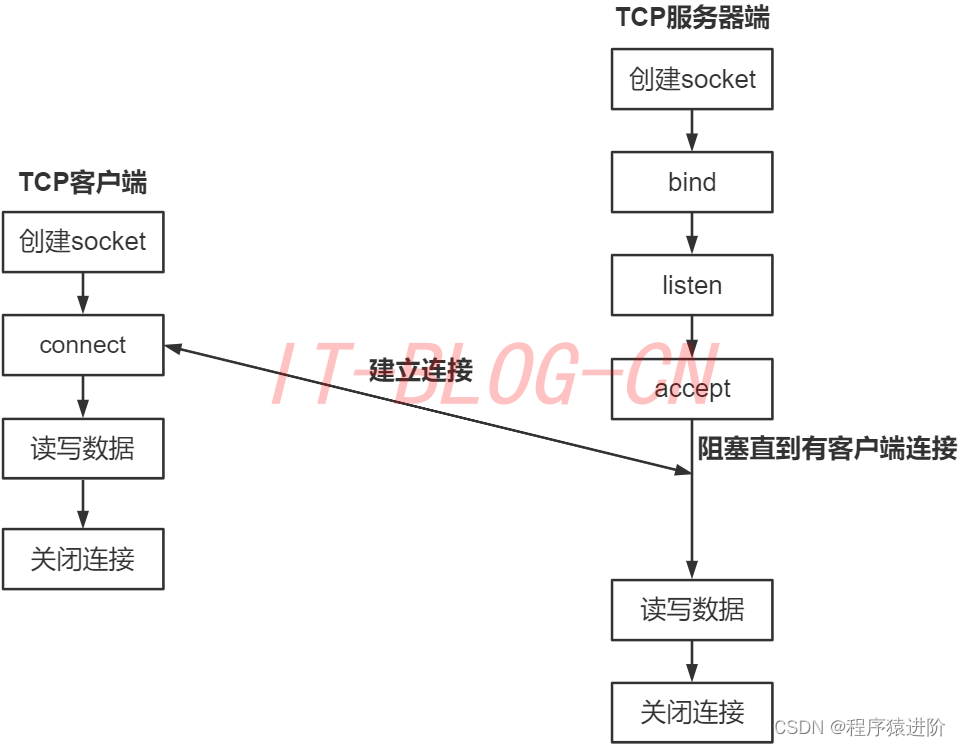
优质博文IT-BLOG-CN 一、简介 Socket套接字:描述了计算机的IP地址和端口,运行在计算机中的程序之间采用socket进行数据通信。通信的两端都有socket,它是一个通道,数据在两个socket之间进行传输。socket把复杂的TCP/IP协议族隐藏在…...

TCP 如何保证有效传输及拥塞控制
TCP(传输控制协议)可以通过以下机制保证有效传输和拥塞控制: 确认机制:TCP使用确认机制来保证数据的有效传输。发送方在发送数据的同时还会发送一个确认请求,接收方收到数据后会回复确认响应。如果发送方没有收到确认响…...
PyQt5+Qt设计师初探
在上一篇文章中我们搭建好了PyQt5的开发环境,打铁到趁热我们基于搭建好的环境来简单实战一把 一:PyQt5包模块简介 PyQt5包括的主要模块如下。 QtCore模块——涵盖了包的核心的非GUI功能,此模块被用于处理程序中涉及的时间、文件、目录、数…...

rust cargo
一、cargo是什么 Cargo是Rust的构建工具和包管理器。 Cargo除了创建工程、构建工程、运行工程等功能,还具有下载依赖库、编译依赖等功能。 真正编写程序时,我们不直接用rustc,而是用cargo。 二、使用cargo (一)使用…...
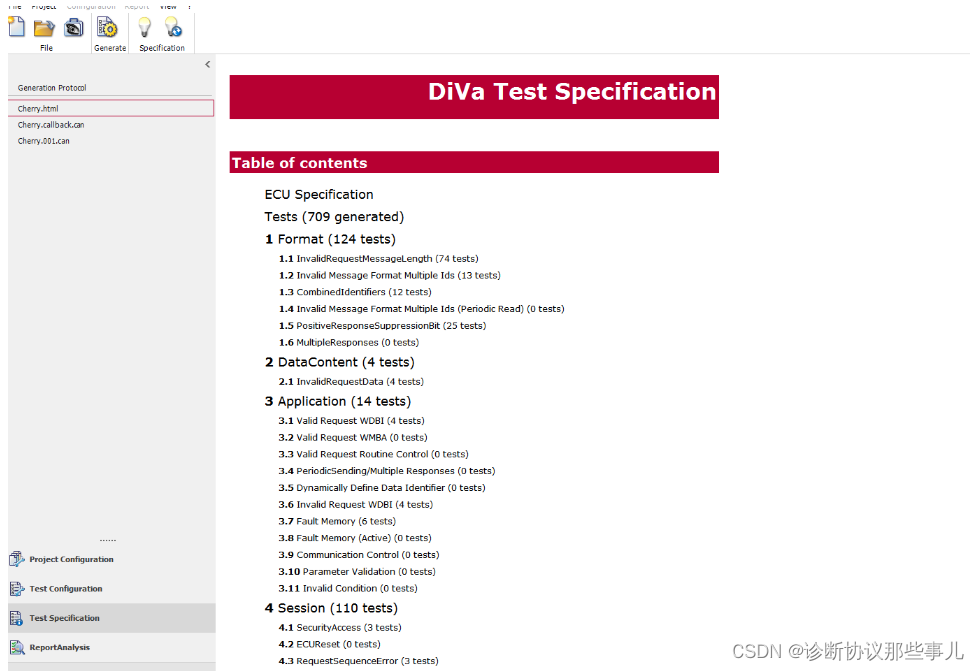
CANoe.Diva生成测试用例
Diva目录 一、CANoe.Diva打开CDD文件二、导入CDD文件三、ECU Information四、时间参数设置五、选择是否测试功能寻址六、勾选需要测试服务项七、生成测试用例 一、CANoe.Diva打开CDD文件 CANoe.Diva可以通过导入cdd或odx文件,自动生成全面的测试用例。再在CANoe中导…...

openGauss学习笔记-89 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用查询原生编译
文章目录 openGauss学习笔记-89 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用查询原生编译89.1 查询编译:PREPARE语句89.2 运行命令89.3 轻量执行支持的查询89.4 轻量执行不支持的查询89.5 JIT存储过程89.6 MOT JIT诊断89.6.1 mot_jit_detai…...
python获取时间戳
使用 datetime 库获取时间。 获取当前时间: import datetime print(datetime.datetime.now()) . 后面的是微秒,也是一个时间单位,1秒1000000微秒。 转为时间戳: import datetimedate datetime.datetime.now() timestamp date…...
2023年山东省安全员C证证考试题库及山东省安全员C证试题解析
题库来源:安全生产模拟考试一点通公众号小程序 2023年山东省安全员C证证考试题库及山东省安全员C证试题解析是安全生产模拟考试一点通结合(安监局)特种作业人员操作证考试大纲和(质检局)特种设备作业人员上岗证考试大…...

Java中的Unicode字符编码与占用比特位解析
本文将详细介绍Java中Unicode字符编码与占用比特位的相关知识。我们将首先介绍Unicode字符集的基本概念,然后深入探讨Java中Unicode字符的编码方式以及占用比特位的特点。最后,我们将讨论一些特殊字符的编码情况,并给出一些在Java中处理Unico…...
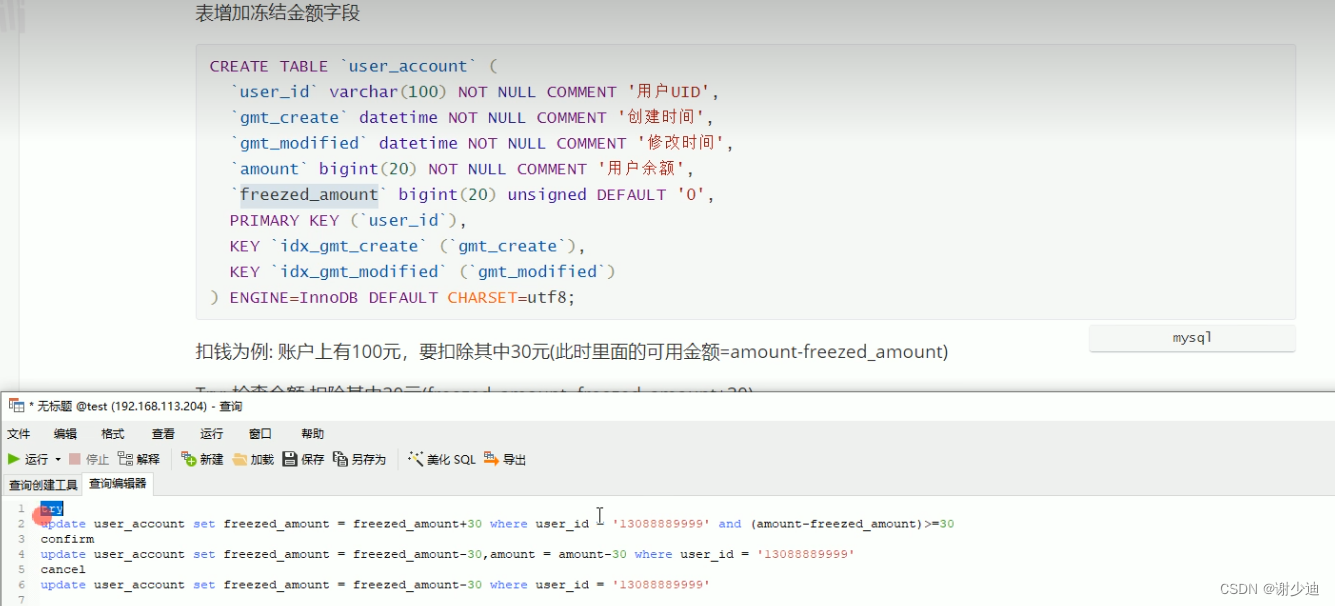
分布式事务-TCC案例分析流程图
防止cancel方法在最后执行出现问题,用户收到提示已经退款成功但是由于cancel过慢或者出现问题(虽然最后会重试成功但是用户体验很差),可以做以下的业务sql模型优化(增加一个冻结金额)。...

究竟是什么样的讲解数组算法的博客让我写了三小时???
版本说明 当前版本号[20231004]。 版本修改说明20231004初版 目录 文章目录 版本说明目录二. 基础数据结构2.1 数组1) 概述2) 动态数组1)插入addlast 方法测试: addlast 方法 add 方法测试:add方法 addlast 方法与 add 方法合并版get 方法测试&#x…...
Day-05 CentOS7.5 安装docker
参考 : Install Docker Engine on CentOS | Docker DocsLearn how to install Docker Engine on CentOS. These instructions cover the different installation methods, how to uninstall, and next steps.https://docs.docker.com/engine/install/centos/ Doc…...

AI应用安全新挑战:基于模糊测试的提示词注入漏洞自动化检测
1. 项目概述:当AI提示词成为攻击目标最近在跟几个做AI应用安全的朋友聊天,大家不约而同地提到了一个词:“提示词攻击”。听起来有点抽象,对吧?简单来说,就是有人不直接黑你的系统,而是通过精心构…...

开源项目发布自动化:GitHub与ClawHub技能包一键发布工具详解
1. 项目概述与核心价值如果你和我一样,经常需要将本地开发的项目,尤其是那些为ClawHub平台准备的技能包,发布到GitHub并同步推送到ClawHub技能市场,那你一定对下面这个场景不陌生:每次发布前,都要在脑子里重…...

量子计算模拟色团阵列振动电子动力学
1. 量子模拟色团阵列振动电子动力学的核心挑战在光合作用等生物过程中,色团阵列(chromophore arrays)的能量转移机制一直是科学家们关注的焦点。传统计算机在模拟这类量子多体系统时面临指数级增长的资源需求,而量子计算为解决这一…...

深耕高性价比多模型聚合平台赛道,这些企业值得重点关注
随着AI大模型的普及,单一模型的适配局限、高成本问题逐渐凸显,多模型聚合平台成为企业降本增效的核心选择。行业报告显示,近6个月国内多模型聚合平台的企业付费用户增速超40%,其中高性价比赛道更是成为竞争焦点。一、高性价比的核…...

AgentKernel:构建模块化智能体系统的核心引擎设计
1. 项目概述:从“AgentKernel”看智能体开发范式的演进最近在GitHub上看到一个名为“AgentKernel”的项目,作者是vijaygopalbalasa。这个标题本身就很有意思,它没有直接叫“AgentFramework”或者“AgentPlatform”,而是选择了“Ke…...

Meta与斯坦福:字节级AI实现逐字节生成瓶颈突破与速度提升能力
这项由Meta人工智能基础研究团队(FAIR at Meta)与斯坦福大学、华盛顿大学联合开展的研究,于2026年5月发表,论文预印本编号为arXiv:2605.08044v1。感兴趣的读者可以通过该编号在arXiv平台上查阅完整论文。现代语言模型的工作方式&a…...
1. 开源套刻精度核心原理)
0401开源光刻机整机控制与量检测系统(A级 中期集中攻坚)1. 开源套刻精度核心原理
开源光刻机整机控制与量检测系统(A级 中期集中攻坚) 1. 开源套刻精度核心原理(全参数开源硬核工程溯源喂饭级量化) 前置硬核声明 本文100%开源所有套刻精度核心参数、误差公式、耦合模型、制程阈值、国产实测短板数据,…...

计算机专业不想“敲代码”,都来冲这个行业
计算机专业不想“敲代码”,都来冲这个行业 在这个信息爆炸的时代,计算机专业作为热门选择之一,吸引了无数学子的目光。但与此同时,也有相当一部分同学心存疑虑:自己是计算机专业的,却对写代码提不起兴趣&a…...

交互式CLI工具开发指南:从原理到实战构建Node.js命令行应用
1. 项目概述:一个能“对话”的命令行工具如果你经常和命令行打交道,尤其是需要处理一些重复性、多步骤的配置或部署任务,你肯定有过这样的体验:打开一个脚本,面对一堆需要手动输入的参数,或者在不同的命令之…...

非洲车商采购中国二手车的完整流程:从找车到提车七步走
操作目标:帮助非洲车商、进口商、批发商及其采购代理,系统性地完成中国二手车采购。适用对象:想了解采购中国二手车完整流程的海外B端买家。采购流程SOP第一步:找车源渠道说明适用场景广州出口基地南沙、番禺、白云实地考察线上平…...