机器学习——KNN算法流程详解(以iris为例)
、
目 录
前情说明
问题陈述
数据说明
KNN算法流程概述
代码实现
运行结果
基于可视化的改进
可视化代码
全部数据可视化总览
分类投票结果
改进后最终代码
前情说明
本书基于《特征工程入门与入门与实践》庄家盛 译版P53页K最近邻(KNN)算法进行讲解
问题陈述
Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
sepallength:萼片长度
sepalwidth:萼片宽度
petallength:花瓣长度
petalwidth:花瓣宽度
我们的任务就是:给定一组记录(包含sepallength,sepalwidth,petallength,petalwidth),使用KNN算法给出该组记录的分类 (使用0,1,2表示)
数据说明
本文使用数据源从机器学习库sklearn的datasets包中获取
# 导入iris数据
iris = datasets.load_iris()可支持的数据集如下:
"load_digits","load_files","load_iris","load_breast_cancer","load_linnerud","load_sample_image","load_sample_images","load_svmlight_file","load_svmlight_files","load_wine",
#不知道为什么我的机器学习库只有这些数据集参考链接: sklearn中的datasets数据集 - 知乎 (zhihu.com)
KNN算法流程概述
1.数据获取。要进行KNN,我们需要样本的部分属性完整数据以及在各种属性不同值的组合情况下的对应分类结果
2.数据清洗。获取数据后使用numpy整理缺失值,可视化查看是否有异常值(比如偏正态分布样本出现的极端值或者空值)
3.数据切分。将数据按照一定比例,从特定位置切分成训练集和测试集,必要情况还需要切割分一部分数据作为验证集
4.选取k个近邻点。使用某种数据结构或者库函数,获取逻辑距离最近的k个点位
5.获取结果。对k个点位进行统计,获取票数最多的结果进行分类。但是存在票数一致的情况,可以使用某种排序方式对数据进行排序,隐式的赋予某些特定的数据具有更高的优先级(即返回首位即可)
6.可视化(补充)。虽然使用KNN算法对结果进行展示了,但是整个过程的投票情况不够直观,于是我们接下来将对整体分类和循环内当前投票情况进行展示。
代码实现
from sklearn import datasets
from collections import Counter # 为了做投票计数
from sklearn.model_selection import train_test_split
import random
import numpy as np###############数据定义区
# 数据集划分随机数种子
randomNums=random.randint(1,9999)
print("随机数{}".format(randomNums))
# 最短投票对象数量
k=3
###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet,DataSet):# print("打印欧氏距离")# print(toBeMeasuredDataSet,'\n',DataSet)# **2的妙用result=np.sqrt(np.sum((toBeMeasuredDataSet - DataSet)**2 ))# print("打印欧氏距离",result)return result# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X,Y,k,testObject):# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集distanceList=[calcDistance(testObject,singleData) for singleData in X ]# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)theShortestIndex=np.argsort(distanceList)[:k]# 获取这k个结果resultList=Y[theShortestIndex]# 返回频率最高的结果 作为样本的类别return Counter(resultList).most_common(1)[0][0]def printTopLineA():print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")def printTopLineB():print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")# 导入鸾尾花数据集
irisDataSet=datasets.load_iris()#获取特征数据集
characteristicData=irisDataSet.data
# 获取分类数据集
categoricalData=irisDataSet.target
# 训练用特征数据集
# 测试用特征数据集
# 训练用分类数据集
# 测试用分类数据集
trainCharDataSet,testCharDataSet,trainCateDataSet,testCateDaSet\=train_test_split(characteristicData,categoricalData,random_state=randomNums)for index,i in enumerate(testCharDataSet):print("第{}个数据\n特征数据是:{}\n数据的类别是:{}".format(index+1,i,KNNSelect(trainCharDataSet,trainCateDataSet,k,i)))if (index&1):printTopLineA()else:printTopLineB()运行结果

基于可视化的改进
我们还是从源数据入手,将源数据转换成key-value聚合的形式,
具体点就是将同一类数据打成列表,作为以列名为key的对应的value
运行网址:Replit: the collaborative browser based IDE - Replit
可视化代码
from collections import Counter # 为了做投票计数
from sklearn import datasets
from sklearn.model_selection import train_test_split
import random
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
###############说明
# 1.本地sns画图环境炸了,具体原因不详,运行平台为Replit,复制即可运行
# 2.参考了许多可视化案例,但大部分都没有理论支撑,就自己做了###############数据定义区
# 数据集划分随机数种子
randomNums=random.randint(1,9999)
print("随机数{}".format(randomNums))
# 最小投票对象数量
k=9
###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet,DataSet):# print("打印欧氏距离")# print(toBeMeasuredDataSet,'\n',DataSet)# **2的妙用result=np.sqrt(np.sum((toBeMeasuredDataSet - DataSet)**2 ))# print("打印欧氏距离",result)return result#这个方法会传来收集好的k个数据以及分类结果 然后返回成key-value的形式调用进行可视化
def showVisual(irisData,irisTarget):#数据处理irisDictData = {'sepalLength': [],'sepalWidth': [],'petalLength': [],'petalWidth': []}for index, i in enumerate(irisDictData):# print(index,i,irisDictData[i])#将每一列数据剥离出来irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]#将分类结果添加进来irisDictData['species']=irisTarget# 进行可视化visual(irisDictData)# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X,Y,k,testObject):# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集distanceList=[calcDistance(testObject,singleData) for singleData in X ]# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)theShortestIndex=np.argsort(distanceList)[:k]# 获取这k个源数据和结果dataList=X[theShortestIndex]resultList=Y[theShortestIndex]print("投票结果:{}".format(resultList))##########可视化出最近的k个点showVisual(dataList,resultList)# 返回频率最高的结果 作为样本的类别return Counter(resultList).most_common(1)[0][0]def showNcolsData():# 导入鸾尾花数据集irisDataSet = datasets.load_iris()# 分析花瓣与花萼的相关性# 宽度的相关性# 高度的相关性# data是采集数据 target是人工分好的类别数据irisData = irisDataSet["data"]# print(irisData[0][0])irisDictData = {'sepalLength': [],'sepalWidth': [],'petalLength': [],'petalWidth': []}for index, i in enumerate(irisDictData):# print(index,i,irisDictData[i])#将每一列数据剥离出来 注意这里用的下标是index 而不是indexs哈哈#感觉写的时候自己挺聪明,过两天就看不懂了qwq irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]# k2, p = stats.normaltest(irisDictData[i])# print(k2,p)# 添加预测结果数据irisDictData['species']=irisDataSet['target']return irisDictData# 装饰打印语句
def printTopLineA():print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")def printTopLineB():print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")#可视化函数
def visual(rawData):# 传入一个没有被DataFrame的dfData=pd.DataFrame(rawData)# x X轴展示数据# y Y轴展示数据# data 数据源# hub 颜色分类依据列# 分类总览sns.relplot(x='sepalLength',y='sepalWidth',data=dfData,hue='species')plt.show()# 导入鸾尾花数据集
irisDataSet=datasets.load_iris()
#获取特征数据集
characteristicData=irisDataSet.data
# 获取分类数据集
categoricalData=irisDataSet.target
# print("打印分类结果",categoricalData)
# 训练用特征数据集,测试用特征数据集,训练用分类数据集,测试用分类数据集
trainCharDataSet,testCharDataSet,trainCateDataSet,testCateDaSet\=train_test_split(characteristicData,categoricalData,random_state=randomNums)
# 可视化需求分析
# 1.对训练集数据进行可视化
# 2.对每个测试对象展示一个独特的点
# 3.标出待测对象最近的k个点# 每一列key的字典 对应值是该列数据
irisDictData=showNcolsData()# sepalLength sepalWidth petalLength petalWidth
# print(dfData)
visual(irisDictData) #对整体进行可视化###使用循环处理待测数据 并给出结果
for index,i in enumerate(testCharDataSet):print("第{}个数据\n特征数据是:{}\n数据的类别是:{}"\.format(index+1,i,KNNSelect(trainCharDataSet,trainCateDataSet,k,i)))printTopLineA() if index&1 else printTopLineB()全部数据可视化总览
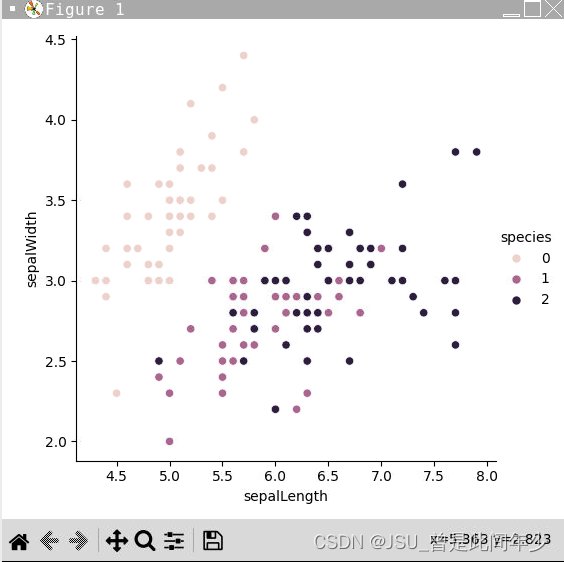
分类投票结果
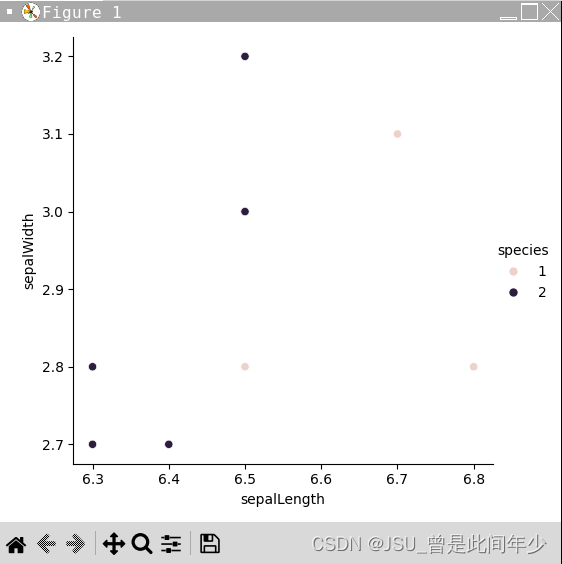
改进后最终代码
我们对代码进行优化,整理后最终代码如下,可在如上在线平台直接运行
from collections import Counter # 为了做投票计数
from sklearn import datasets
from sklearn.model_selection import train_test_split
import random
import numpy as np
import pandas as pd
import seaborn as sns #流行可视化工具
import matplotlib.pyplot as plt #sns的底层基于这个。。。需要用plt.show()###############说明
# 1.本地sns画图环境炸了,具体原因不详,运行平台为Replit,复制即可运行
# 2.参考了许多可视化案例,但大部分都没有理论支撑,就自己做了
###############数据定义区
# 数据集划分随机数种子
randomNums = random.randint(1, 9999)
print("随机数{}".format(randomNums))
# 最小投票对象数量
k = 9
# 定义空字典 增加复用率
irisDictEmptyData = {'sepalLength': [],'sepalWidth': [],'petalLength': [],'petalWidth': []
}###############数据定义区END
# 计算同类属性的欧氏距离 假设能这样计算欧式距离代表样本之间的差距
def calcDistance(toBeMeasuredDataSet, DataSet):# print("打印欧氏距离")# print(toBeMeasuredDataSet,'\n',DataSet)# **2的妙用result = np.sqrt(np.sum((toBeMeasuredDataSet - DataSet) ** 2))# print("打印欧氏距离",result)return resultdef dealRawDataToDict(irisDictData, irisData):for index, i in enumerate(irisDictData):# print(index,i,irisDictData[i])# 将每一列数据剥离出来 注意这里用的下标是index 而不是indexs哈哈# 感觉写的时候自己挺聪明,过两天就看不懂了qwq irisDictData[i] = [data[index] for indexs, data in enumerate(irisData)]return irisDictData# 这个方法会传来收集好的k个数据以及分类结果 然后返回成key-value的形式调用进行可视化
def showVisual(irisData, irisTarget):# 数据处理irisDictData = dealRawDataToDict(irisDictEmptyData, irisData)# 将分类结果添加进来irisDictData['species'] = irisTarget# 进行可视化visual(irisDictData)# 原始特征数据集 原始分类数据集 选取个数 待分类对象(一条记录)
def KNNSelect(X, Y, k, testObject):# 获取欧氏距离列表 计算待测数据与特征数据集的欧数据集distanceList = [calcDistance(testObject, singleData) for singleData in X]# 排序后 切片获取逻辑距离最短的k个对记录的下标(维护前k个最值)theShortestIndex = np.argsort(distanceList)[:k]# 获取这k个源数据和结果dataList = X[theShortestIndex]resultList = Y[theShortestIndex]print("投票结果:{}".format(resultList))##########可视化出最近的k个点showVisual(dataList, resultList)# 返回频率最高的结果 作为样本的类别return Counter(resultList).most_common(1)[0][0]#拼装全部原始数据 然后送还字典
def showNcolsData():# 导入鸾尾花数据集irisDataSet = datasets.load_iris()# 分析花瓣与花萼的相关性# 宽度的相关性# 高度的相关性# data是采集数据 target是人工分好的类别数据irisData = irisDataSet["data"]# print(irisData[0][0])irisDictData = dealRawDataToDict(irisDictEmptyData, irisData)# 添加预测结果数据irisDictData['species'] = irisDataSet['target']return irisDictData# 装饰打印语句
def printTopLineA():print(r"/\/\/\/\/\/\/\/\/\/\/\/\/")def printTopLineB():print(r"\/\/\/\/\/\/\/\/\/\/\/\/\ ")# 可视化函数
def visual(rawData):# 传入一个没有被DataFrame的dfData = pd.DataFrame(rawData)# x X轴展示数据# y Y轴展示数据# data 数据源# hub 颜色分类依据列# 分类总览sns.relplot(x='sepalLength', y='sepalWidth', data=dfData, hue='species')plt.show()# 导入鸾尾花数据集
irisDataSet = datasets.load_iris()
# 获取特征数据集
characteristicData = irisDataSet.data
# 获取分类数据集
categoricalData = irisDataSet.target
# print("打印分类结果",categoricalData)
# 训练用特征数据集,测试用特征数据集,训练用分类数据集,测试用分类数据集
trainCharDataSet, testCharDataSet, trainCateDataSet, testCateDaSet \= train_test_split(characteristicData, categoricalData, random_state=randomNums)
# 可视化需求分析
# 1.对训练集数据进行可视化
# 2.对每个测试对象展示一个独特的点
# 3.标出待测对象最近的k个点# 每一列key的字典 对应值是该列数据
irisDictData = showNcolsData()# sepalLength sepalWidth petalLength petalWidth
# print(dfData)
visual(irisDictData) # 进行可视化###使用循环处理待测数据 并给出结果
for index, i in enumerate(testCharDataSet):print("第{}个数据\n特征数据是:{}\n数据的类别是:{}" \.format(index + 1, i, KNNSelect(trainCharDataSet, trainCateDataSet, k, i)))printTopLineA() if index & 1 else printTopLineB()部分参考链接:
1.sklearn数据集——iris鸢尾花数据集_iris 数据_lyb06的博客-CSDN博客
2.【机器学习实战】科学处理鸢尾花数据集_鸢尾花数据标准化处理-CSDN博客
3.数据分析——鸢尾花数据集-CSDN博客
4.Python collections模块之Counter()详解_python counter-CSDN博客
5.Python基本函数:np.argsort()-CSDN博客
6.Python中的Counter.most_common()方法-CSDN博客
7.史上最全面K近邻算法/KNN算法详解+python实现 - 知乎 (zhihu.com)
8.什么是KNN算法? - 知乎 (zhihu.com)
9.sklearn中的datasets数据集 - 知乎 (zhihu.com)
相关文章:
机器学习——KNN算法流程详解(以iris为例)
、 目 录 前情说明 问题陈述 数据说明 KNN算法流程概述 代码实现 运行结果 基于可视化的改进 可视化代码 全部数据可视化总览 分类投票结果 改进后最终代码 前情说明 本书基于《特征工程入门与入门与实践》庄家盛 译版P53页K最近邻(KNN)算…...
国庆假期day5
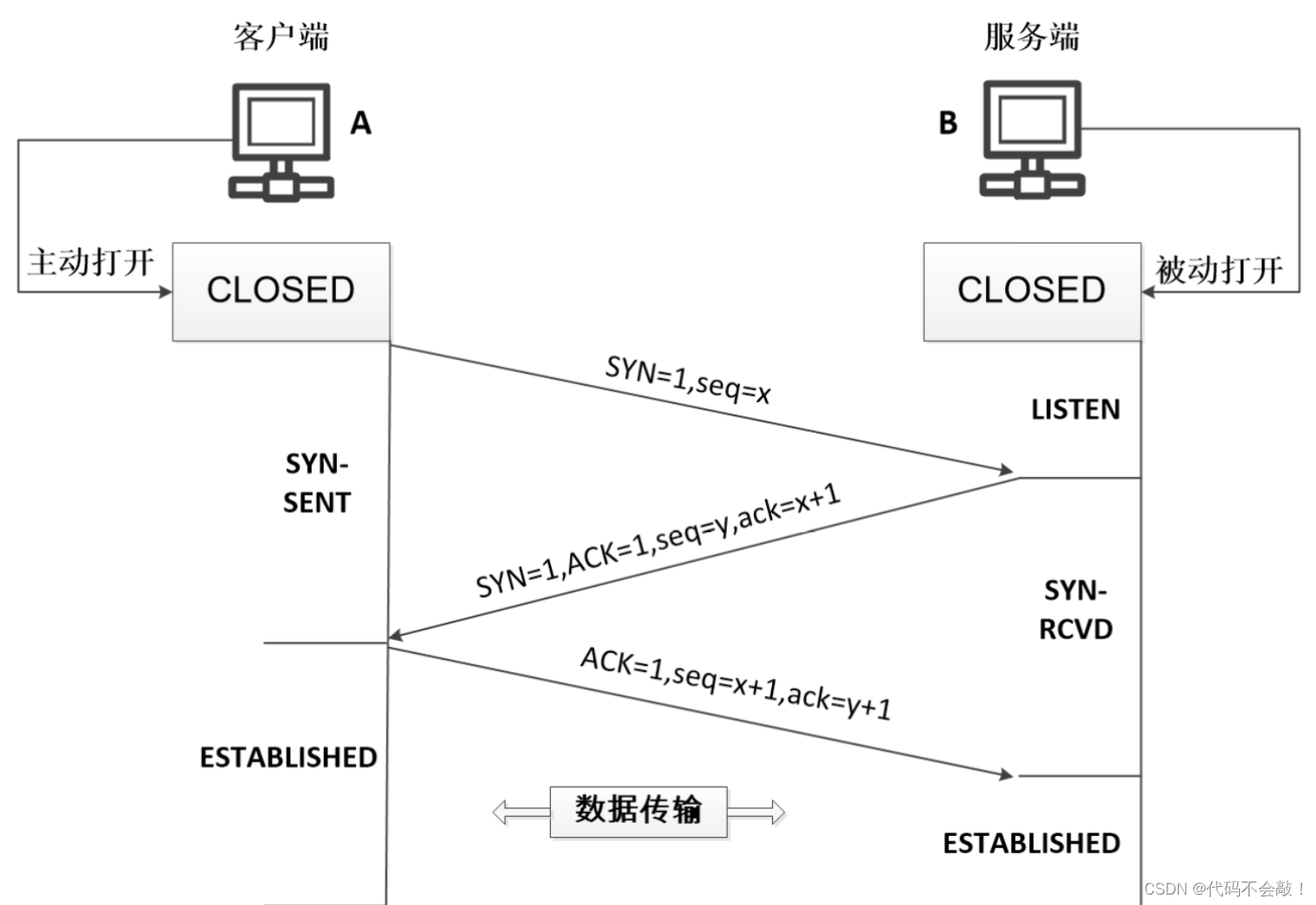
作业:请写出七层模型及每一层的功能,请绘制三次握手四次挥手的流程图 1.OSI七层模型: 应用层--------提供函 表示层--------表密缩 会话层--------会话 传输层--------进程的接收和发送 网络层--------寻主机 数据链路层----相邻节点的可靠传…...

ES6中的let、const
let ES6中新增了let命令,用来声明变量,和var类似但是也有一定的区别 1. 块级作用域 只能在当前作用域内使用,各个作用域不能互相使用,否则会报错。 {let a 1;var b 1; } console.log(a); // 会报错 console.log(b); // 1为什…...

Python 列表操作指南3
示例,将新列表中的所有值设置为 ‘hello’: newlist [hello for x in fruits]表达式还可以包含条件,不像筛选器那样,而是作为操纵结果的一种方式: 示例,返回 “orange” 而不是 “banana”: …...
三个要点,掌握Spring Boot单元测试
单元测试是软件开发中不可或缺的重要环节,它用于验证软件中最小可测试单元的准确性。结合运用Spring Boot、JUnit、Mockito和分层架构,开发人员可以更便捷地编写可靠、可测试且高质量的单元测试代码,确保软件的正确性和质量。 一、介绍 本文…...
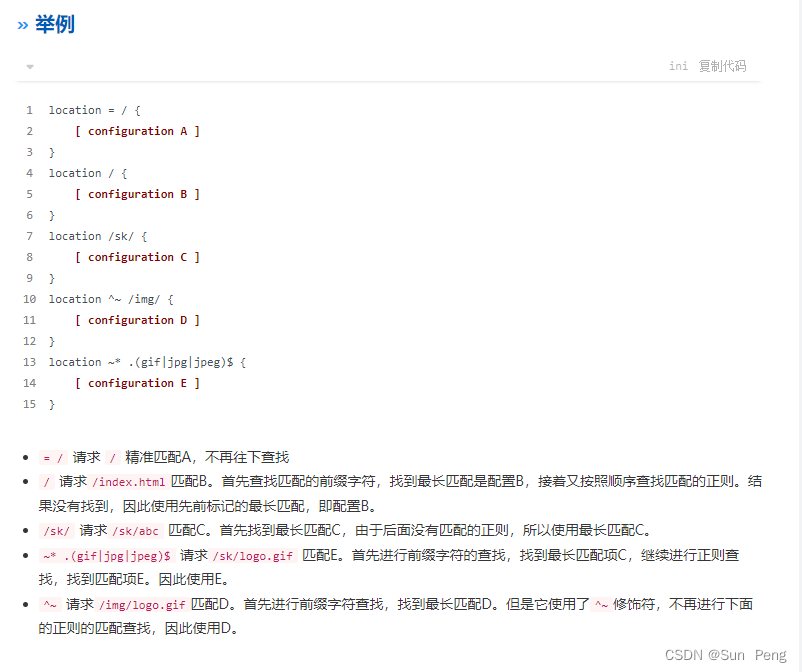
【nginx】Nginx配置:
文章目录 一、什么是Nginx:二、为什么使用Nginx:三、如何处理请求:四、什么是正向代理和反向代理:五、nginx 启动和关闭:六、目录结构:七、配置文件nginx.conf:八、location:九、单页…...

CSS3与HTML5
box-sizing content-box:默认,宽高包不含边框和内边距 border-box:也叫怪异盒子,宽高包含边框和内边距 动画:移动translate,旋转、transform等等 走马灯:利用动画实现animation:from…...
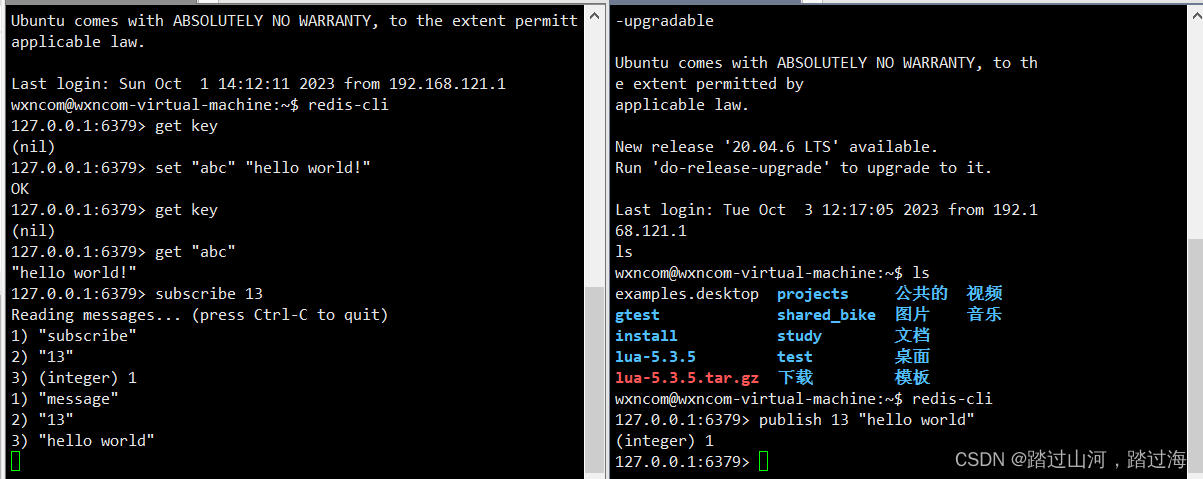
redis的简单使用
文章目录 环境安装与配置redis发布-订阅相关命令redis发布-订阅的客户端编程redis的订阅发布的例子 环境安装与配置 sudo apt-get install redis-server # ubuntu命令安装redis服务ubuntu通过上面命令安装完redis,会自动启动redis服务,通过ps命令确认&a…...
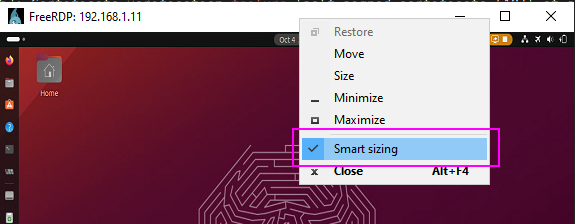
Windows下启动freeRDP并自适应远端桌面大小
几个二进制文件 xfreerdp # Linux下的,an X11 Remote Desktop Protocol (RDP) client which is part of the FreeRDP project wfreerdp.exe # Windows下的,freerdp2.0 主程序,freerdp3.0将废弃 sdl-freerdp.exe # Windows下的&…...

ES6中的数值扩展
1. 二进制和八进制的表示法 二进制和八进制的前缀分别为0b(或0B)和0o(或0O)表示 在ES5的严格模式下,八进制不再允许使用前缀0表示 如果要将0b和0x前缀的字符串数值转为十进制,要使用Number方法 Number(0b111); // 7 Number(0o10); // 82. Number.isF…...

自定义注解实现Redis分布式锁、手动控制事务和根据异常名字或内容限流的三合一的功能
自定义注解实现Redis分布式锁、手动控制事务和根据异常名字或内容限流的三合一的功能 文章目录 [toc] 1.依赖2.Redisson配置2.1单机模式配置2.2主从模式2.3集群模式2.4哨兵模式 3.实现3.1 RedisConfig3.2 自定义注解IdempotentManualCtrlTransLimiterAnno3.3自定义切面Idempote…...
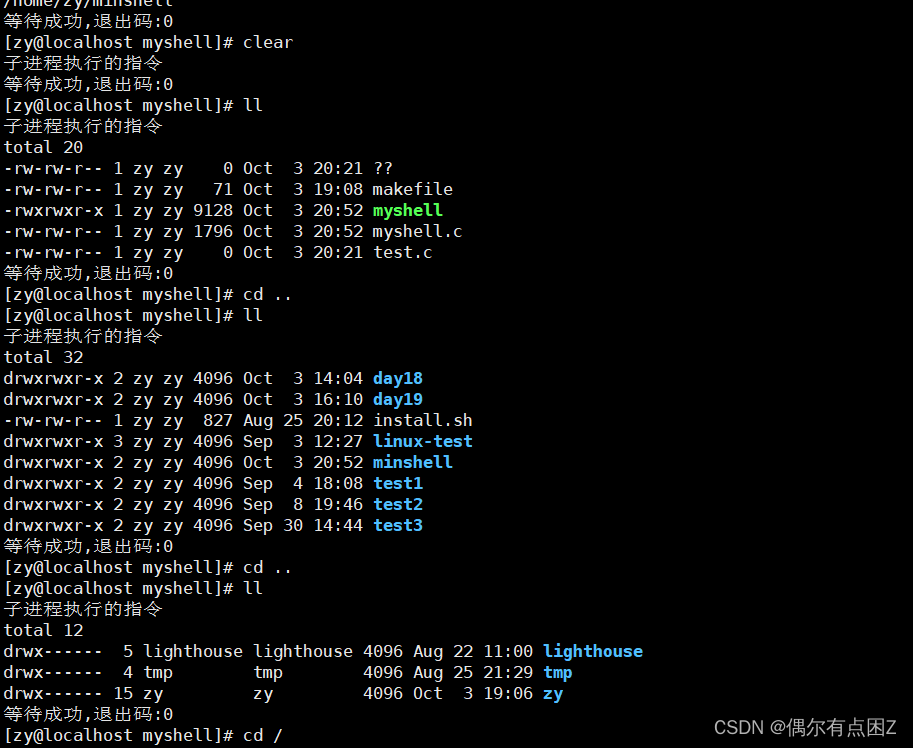
Linux:minishell
目录 1.实现逻辑 2.代码及效果展示 1.打印字符串提示用户输入指令 2.父进程拆解指令 3.子进程执行指令,父进程等待结果 4.效果 3.实现过程中遇到的问题 1.打印字符串的时候不显示 2.多换了一行 3.cd路径无效 4.优化 1.ll指令 2.给文件或目录加上颜色 代码链接 模…...

STM32驱动步进电机
前言 (1)本章介绍用stm32驱动42步进电机,将介绍需要准备的硬件器材、所需芯片资源以及怎么编程及源代码等等。 (2)实验效果:按下按键,步进电机顺时针或逆时针旋转90度。 (3ÿ…...

计算机视觉——飞桨深度学习实战-深度学习网络模型
深度学习网络模型的整体架构主要数据集、模型组网以及学习优化过程三部分,本章主要围绕着深度学习网络模型的算法架构、常见模型展开了详细介绍,从经典的深度学习网络模型以CNN、RNN为代表,到为了解决显存不足、实时性不够等问题的轻量化网络…...
实现手撸神经网咯230901)
用c动态数组(不用c++vector)实现手撸神经网咯230901
用c语言动态数组(不用c++的vector)实现:输入数据inputs = { {1, 1}, {0,0},{1, 0},{0,1} };目标数据targets={0,0,1,1}; 测试数据 inputs22 = { {1, 0}, {1,1},{0,1} }; 构建神经网络,例如:NeuralNetwork nn({ 2, 4,3,1 }); 则网络有四层、输入层2个nodes、输出层1个节点、第…...

视频讲解|基于DistFlow潮流的配电网故障重构代码
目录 1 主要内容 2 视频链接 1 主要内容 该视频为基于DistFlow潮流的配电网故障重构代码讲解内容,对应的资源下载链接为基于DistFlow潮流的配电网故障重构(输入任意线路),对该程序进行了详尽的讲解,基本做到句句分析和讲解(讲解…...
Ultralytics(YoloV8)开发环境配置,训练,模型转换,部署全流程测试记录
关键词:windows docker tensorRT Ultralytics YoloV8 配置开发环境的方法: 1.Windows的虚拟机上配置: Python3.10 使用Ultralytics 可以得到pt onnx,但无法转为engine,找不到GPU,手动转也不行࿰…...

springboot之@ImportResource:导入Spring配置文件~
ImportResource的作用是允许在Spring配置文件中导入其他的配置文件。通过使用ImportResource注解,可以将其他配置文件中定义的Bean定义导入到当前的配置文件中,从而实现配置文件的模块化和复用。这样可以方便地将不同的配置文件进行组合,提高…...
阿里云服务器免费申请入口_注册阿里云免费领4台服务器
注册阿里云账号,免费领云服务器,最高领取4台云服务器,每月750小时,3个月免费试用时长,可快速搭建网站/小程序,部署开发环境,开发多种企业应用。阿里云百科分享阿里云服务器免费领取入口、免费云…...

ES6中的async、await函数
async是为了解决异步操作,其实是一个语法糖,使代码书写更加简洁。 1. async介绍 async放在一个函数的前面,await则放在异步操作前面。async代表这个函数中有异步操作需要等待结果,在一个async函数中可以存在多个await࿰…...
)
Claude技能构建指南|第五章 模式与故障排除(Patterns and Troubleshooting)
Claude技能构建指南|第五章 模式与故障排除(Patterns and Troubleshooting) 1. ① 本章核心主旨 本章提供5种高频复用的技能设计模式,并针对上传、触发、执行、MCP连接等常见问题给出标准化排查方案,学完可直接套用成熟…...

终极AMD锐龙处理器调试指南:深度掌握硬件性能调优的完整解决方案
终极AMD锐龙处理器调试指南:深度掌握硬件性能调优的完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...

H3C模拟器实战:基于时间与部门的精细化ACL策略部署
1. 企业网络访问控制的痛点与ACL解决方案 在企业网络管理中,最让人头疼的就是如何平衡安全性和便利性。我见过太多公司要么一刀切封锁所有端口导致业务受阻,要么放任自流引发数据泄露。就拿去年帮某中型企业排查的问题来说,他们的销售部员工在…...

ARM设备运行x86_64程序:Box64高效兼容方案深度解析
ARM设备运行x86_64程序:Box64高效兼容方案深度解析 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在AR…...

PasteMD:一键解决AI内容到Office文档的格式转换难题
1. 项目概述与痛点解析如果你经常需要写论文、做报告,或者整理从各种AI助手(比如ChatGPT、DeepSeek、Kimi)那里得到的答案,那你一定遇到过这个让人头疼的问题:辛辛苦苦从网页上复制下来的内容,一粘贴到Word…...

AI代码智能体突破电话验证瓶颈:从环境模拟到混合架构的实战方案
1. 项目概述:当代码智能体遇上“电话验证墙”最近在折腾Claude这类AI代码助手做自动化任务时,我发现一个挺有意思的瓶颈:它们经常在需要电话验证(Phone Verification)的环节上“卡壳”。这可不是个小问题,想…...
)
ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT提示词在Discord中失效率高达68%?基于172个真实会话日志的Prompt工程优化矩阵(含Discord专属角色设定模板) Discord 的异步消息流、上下文截断机制与用户高频…...

CS Demo Manager:免费开源CS比赛录像分析工具终极指南
CS Demo Manager:免费开源CS比赛录像分析工具终极指南 【免费下载链接】cs-demo-manager Companion application for your Counter-Strike demos. 项目地址: https://gitcode.com/gh_mirrors/cs/cs-demo-manager 你是否曾想过,为什么职业选手总能…...

别再死记硬背公式了!用“预测-更新”的贝叶斯视角,5分钟看懂卡尔曼滤波核心
卡尔曼滤波:用贝叶斯思维解决自动驾驶中的不确定性追踪问题 想象一下你正驾驶一辆特斯拉行驶在高速公路上,车载雷达显示前方100米处有一辆卡车。但下一秒雷达数据突然跳变到105米,而摄像头却显示距离是98米。作为人类司机,你会本能…...
)
AI大模型赋能数据治理:小白也能掌握的5个高频场景与避坑指南(收藏备用)
数据治理是企业数字化转型难题,AI大模型带来破局点。本文阐述大模型如何解决效率低、门槛高、适配弱等痛点,提供3个高价值落地场景(非结构化数据治理、数据质量治理、数据资产化治理)及5个高频踩坑陷阱,并给出最佳实践…...