Hive SQL 执行计划
我们在写Hive SQL的时候,难免会在运行的时候有报错,所以知道Hive SQL的执行计划具体是什么,然后假如在之后的运行过程中有报错,可以根据执行计划定位问题,调试自己的SQL开发脚本。
一、含义
Hive SQL的执行计划描述SQL实际执行的整体轮廓,通过执行计划能了解SQL程序在转换成相应计算引擎的执行逻辑,掌握了执行逻辑也就能更好地把握程序出现的瓶颈点,从而能够实现更有针对性的优化。此外还能帮助开发者识别看似等价的SQL其实是不等价的,看似不等价的SQL其实是等价的SQL。可以说执行计划是打开SQL优化大门的一把钥匙。
二、关键字
explain
三、查看SQL的执行计划
Hive提供的执行计划目前可以查看的信息有以下几种:
explain:查看执行计划的基本信息;
explain dependency:dependency在explain语句中使用会产生有关计划中输入的额外信息。它显示了输入的各种属性;
explain authorization:查看SQL操作相关权限的信息;
explain vectorization:查看SQL的向量化描述信息,显示为什么未对Map和Reduce进行矢量化。从 Hive 2.3.0 开始支持;
explain analyze:用实际的行数注释计划。从 Hive 2.2.0 开始支持;
explain cbo:输出由Calcite优化器生成的计划。CBO 从 Hive 4.0.0 版本开始支持;
explain locks:这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 Hive 3.2.0 开始支持;
explain ast:输出查询的抽象语法树。AST 在 Hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复;
explain extended:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名,这些额外信息对我们用处不大;
四、explain的使用方法
1,语法格式:
explain query; //query为需要查看执行计划的查询语句
2,执行计划结果示例:
STAGE DEPENDENCIES: // 各个stage之间的依赖性Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS: // 各个stage的执行计划Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: test1Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: id (type: int)outputColumnNames: idStatistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: sum(id)mode: hashoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorsort order:Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col0 (type: bigint)Reduce Operator Tree:Group By Operatoraggregations: sum(VALUE._col0)mode: mergepartialoutputColumnNames: _col0Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
3,执行计划结果释义
第一部分 stage dependencies ,包含两个 stage,Stage-1 是根stage,说明这是开始的stage,Stage-0 依赖 Stage-1,Stage-1执行完成后执行Stage-0。第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
1.Map Operator Tree:MAP端的执行计划树
2.Reduce Operator Tree:Reduce端的执行计划树这两个执行计划树里面包含这条sql语句的 operator:
TableScan:表扫描操作,map端第一个操作肯定是加载表,所以就是表扫描操作,常见的属性:
alias:表名称
Statistics:表统计信息,包含表中数据条数,数据大小等
Select Operator:选取操作,常见的属性 :
expressions:需要的字段名称及字段类型
outputColumnNames:输出的列名称
Statistics:表统计信息,包含表中数据条数,数据大小等
Group By Operator:分组聚合操作,常见的属性:
aggregations:显示聚合函数信息
mode:聚合模式,值有 hash:随机聚合,就是hash partition;partial:局部聚合;final:最终聚合
keys:分组的字段,如果没有分组,则没有此字段
outputColumnNames:聚合之后输出列名
Statistics:表统计信息,包含分组聚合之后的数据条数,数据大小等
Reduce Output Operator:输出到reduce操作,常见属性:
sort order:值为空 不排序;值为 + 正序排序,值为 - 倒序排序;值为 +- 排序的列为两列,第一列为正序,第二列为倒序
Filter Operator:过滤操作,常见的属性:
predicate:过滤条件,如sql语句中的where id>=1,则此处显示(id >= 1)
Map Join Operator:join 操作,常见的属性:
condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join0 to 2
keys: join 的条件字段
outputColumnNames:join 完成之后输出的字段
Statistics:join 完成之后生成的数据条数,大小等
File Output Operator:文件输出操作,常见的属性
compressed:是否压缩
table:表的信息,包含输入输出文件格式化方式,序列化方式等
Fetch Operator 客户端获取数据操作,常见的属性:
limit,值为 -1 表示不限制条数,其他值为限制的条数
4、explain 的使用场景
(1)查询join 语句是否会过滤 null 的值
(2)查询group by 分组语句是否会进行排序
(3)哪条sql执行效率高
explain 还有很多其他的用途,如查看stage的依赖情况、排查数据倾斜、hive 调优等。
五、explain dependency的用法
1,语法
explain dependency query; // query为需要查看执行计划的SQL语句
2,含义
explain dependency用于描述一段SQL需要的数据来源,输出是一个json格式的数据,里面包含以下两个部分的内容:
input_partitions:描述一段SQL依赖的数据来源表分区,里面存储的是分区名的列表,如果整段SQL包含的所有表都是非分区表,则显示为空。
input_tables:描述一段SQL依赖的数据来源表,里面存储的是Hive表名的列表。
3,使用场景
explain dependency的使用场景有两个:
场景一:快速排除。快速排除因为读取不到相应分区的数据而导致任务数据输出异常。例如,在一个以天分区的任务中,上游任务因为生产过程不可控因素出现异常或者空跑,导致下游任务引发异常。通过这种方式,可以快速查看SQL读取的分区是否出现异常。
场景二:理清表的输入,帮助理解程序的运行,特别是有助于理解有多重子查询,多表连接的依赖输入。
六、explain authorization
1,语法
explain authorization query; // query为需要查看执行计划的SQL语句
2,含义
通过explain authorization可以知道当前SQL访问的数据来源(INPUTS)
和数据输出(OUTPUTS),以及当前Hive的访问用户 (CURRENT_USER)和操作(OPERATION)。
3,explain authorization查询示例
INPUTS: default@student_tb_orc
OUTPUTS: hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194- 90f1475a3ed5/-mr-10000
CURRENT_USER: hdfs
OPERATION: QUERY
AUTHORIZATION_FAILURES: No privilege 'Select' found for inputs { database:default, table:student_ tb_orc, columnName:s_score}
以上的内容来源网络,仅供学习交流,如有侵犯,联系删除哦!
相关文章:

Hive SQL 执行计划
我们在写Hive SQL的时候,难免会在运行的时候有报错,所以知道Hive SQL的执行计划具体是什么,然后假如在之后的运行过程中有报错,可以根据执行计划定位问题,调试自己的SQL开发脚本。 一、含义 Hive SQL的执行计划描述S…...

MySQL InnoDB引擎——三层B+树可以存储多少数据量
先说结论: 3层B树大概可以存: 主键为bigint:约2000w主键为int:约4000w*备注: 在《阿里开发手册》中建议,单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表,如果预计三年后…...

部署跨云容灾的五大难点
为什么企业需要跨云容灾? 据统计,全球已有70%的企业使用云计算服务。上云帮助企业更高效地管理数据资产,但它并非绝对安全。如停电、漏水等机房事故;地震、火灾等自然性灾害;亦或是人为失误,都有可能造成数…...

Docker Compose
为什么需要使用Docker ComposeDocker Compose 容器编排技术1、现在我们有一个springboot项目,需要依赖Redis、mysql、nginx。如果使用docker原生部署的话,则需要安装Redis、mysql、nginx容器,才可以启动我们springboot项目,这样的…...
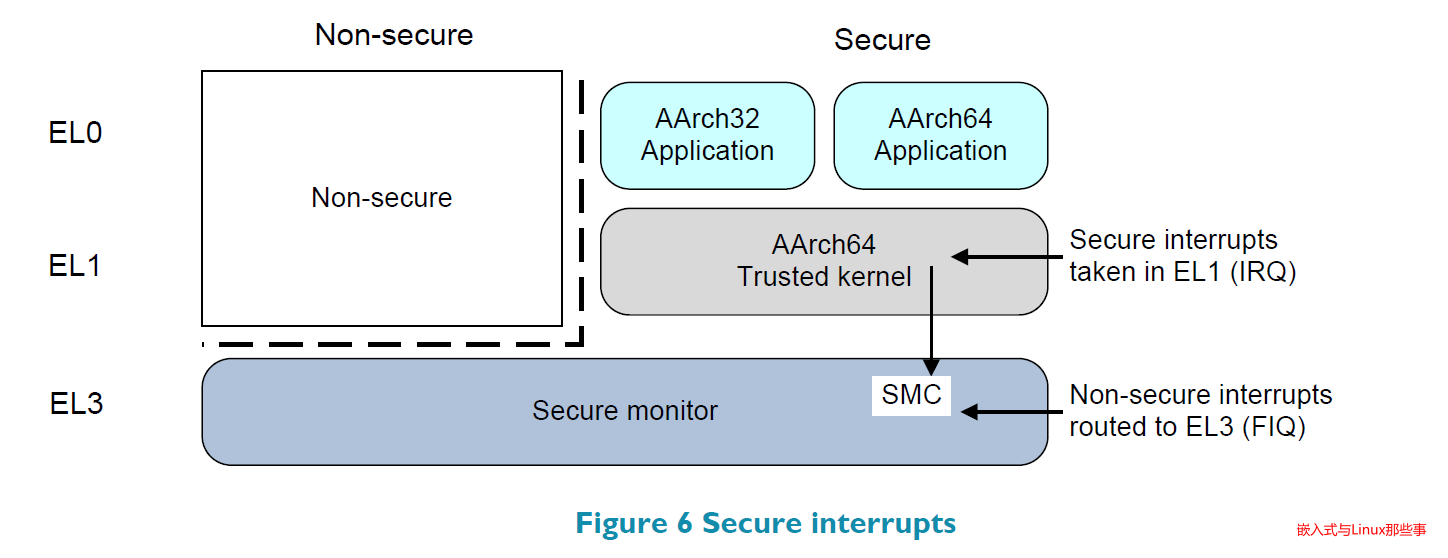
【ARM架构】armv8 系统安全概述
ARMv8-A 系统中的安全 一个安全或可信的操作系统保护着系统中敏感的信息,例如,可以保护用户存储的密码,信用卡等认证信息免受攻击。 安全由以下原则定义: 保密性:保护设备上的敏感信息,防止未经授权的访问…...

数学小课堂:数学边界
文章目录 引言I 费马大定理1.1毕达哥拉斯定理的推广1.2 一波三折的定理证明过程1.3 希尔伯特第十问题II 数学的边界2.1 认识论问题2.2 在边界内做事情2.3 总结引言 了解数学本身的局限性,才能更好地使用它的原理和思维方式。 数学的边界,这是一个硬的边界,大家不要试图逾越…...

检测中断到来时,让LED灯状态取反,并且在串口工具上打印一句话
任务:检测中断到来时,让LED灯状态取反,并且在串口工具上打印一句话例如:当按键1按下之后,让LED1状态取反,并打印“LED1 down”当按键2按下之后,让LED2状态取反,并打印“LED2 down”当…...
)
2023年CDGA考试-第7章-数据安全(含答案)
2023年CDGA考试-第7章-数据安全(含答案) 单选题 1.数据安全不仅涉及防止不当访问,也涉及对数据的适当访问,下列理解不正确的是 ( ) A.强密码有助于提高破解风险 B.安全专家建议 45-180天修改一次密码 C.用户要尽量使用多套密码和账户 D.具有高度敏感信息权限的用户都应使…...

输出月份英文名称--C语言实现
任务描述 本关需要你编写一个用指针数组处理的c程序,然后从键盘输入月份时输出对应的英文名。 相关知识 指针 指针是一个变量,其值为另一个变量的地址,即内存位置的直接地址。就像其他变量或常量一样,你必须在使用指针存储其他变量地址之前,对其进行声明。 指针变量声明…...
6年测试经验老鸟:做不好自动化测试,还谈什么高薪?
提起自动化测试,可谓仁者见人,智者见智,心中五味杂陈啊!你从任何一个招聘渠道来看最近两年对测试岗位的要求,几乎都要求会自动化测试。而不少人一直认为手工测试才是王道,工作中有的时候也用不到程序&#…...
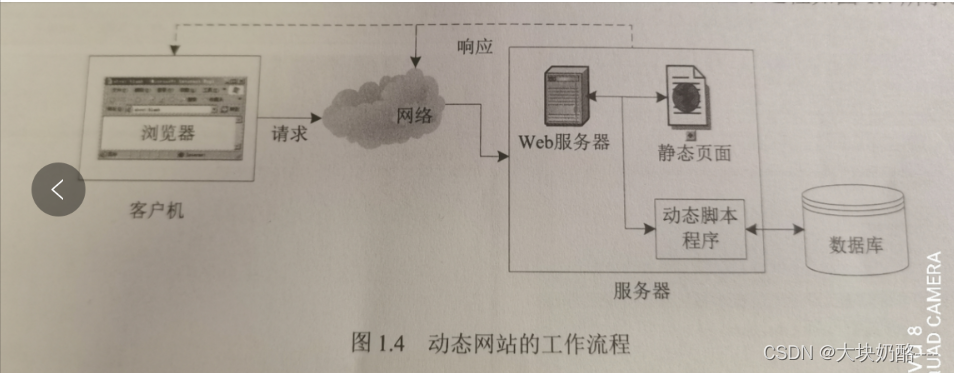
Java Web:开篇综述与第一章
前言 翻开这本书,又是一段新的学习路线,在学习的道路上是枯燥的,是乏味的,难免有放弃的想法。但回看曾经的学习笔记,自己也一步一步走过来了,即使会自我怀疑自我否定,但不坚持不努力是永远没有…...

ES6中对象的一些拓展
当对象键名与对应值名相等的时候,可以进行简写 const obj { name }允许字面量定义对象时,将表达式放在括号内 let lastWord last word;const a {first word: hello,[lastWord]: world };a[first word] // "hello" a[lastWord] // "wo…...

10分钟快速入门Pandas库
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的,这篇文章主要介绍了10分钟快速入门Pandas库,重点介绍pandas常见使用方法,结合实例代码介绍的非常详细,需要的朋友可以参考下目录Pandas的介绍pandas 是基于Num…...
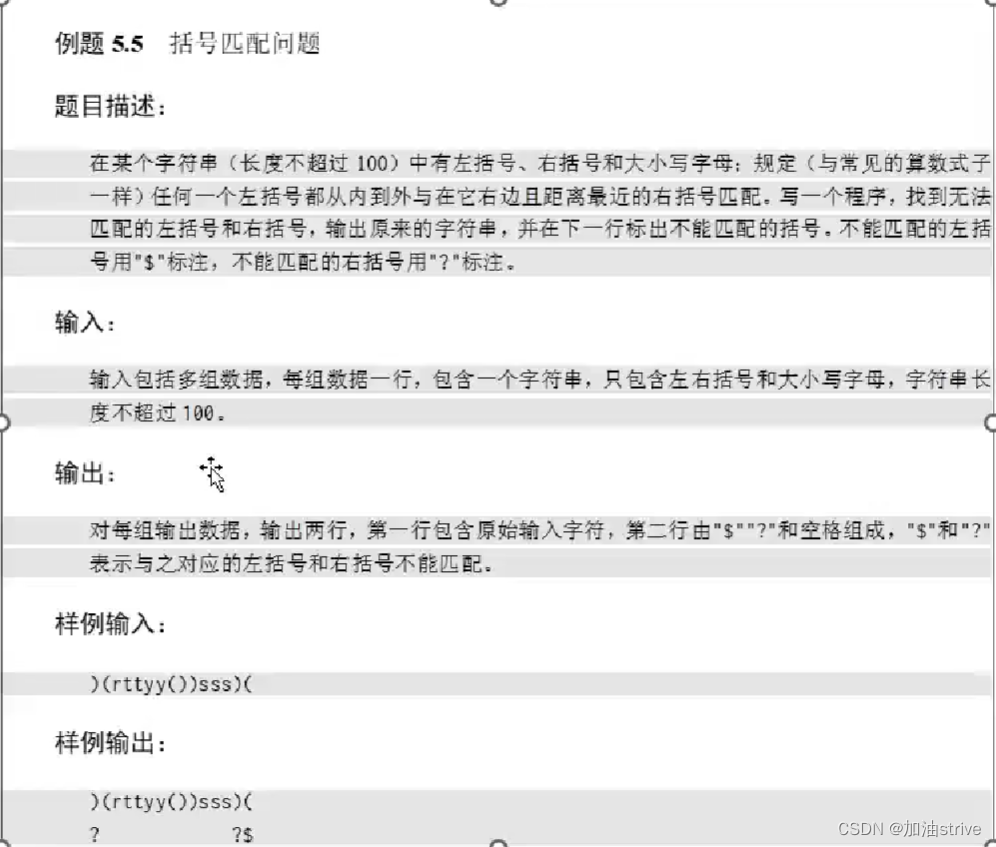
考研复试机试 | C++ | 王道机试课程笔记
目录Zero-complexity (上交复试题)题目:代码:括号匹配问题题目:代码:表达式解析问题 (浙大机试题)题目:代码:标准库里提供了栈 stack<typename> myStack .size() 栈的大小 .pu…...
【python科目一:生产线系统设计;激光刀切割材料】
工厂有若干条生产线,可以生产不同型号的产品,要求实现功能如下:1. ProductionLineMgmtSys 初始化生产线和产品的生产周期有num条生产线,编号从0开始periods[i]表示生产一个型号为i的产品所需的生产周期,单位为天2. Pro…...
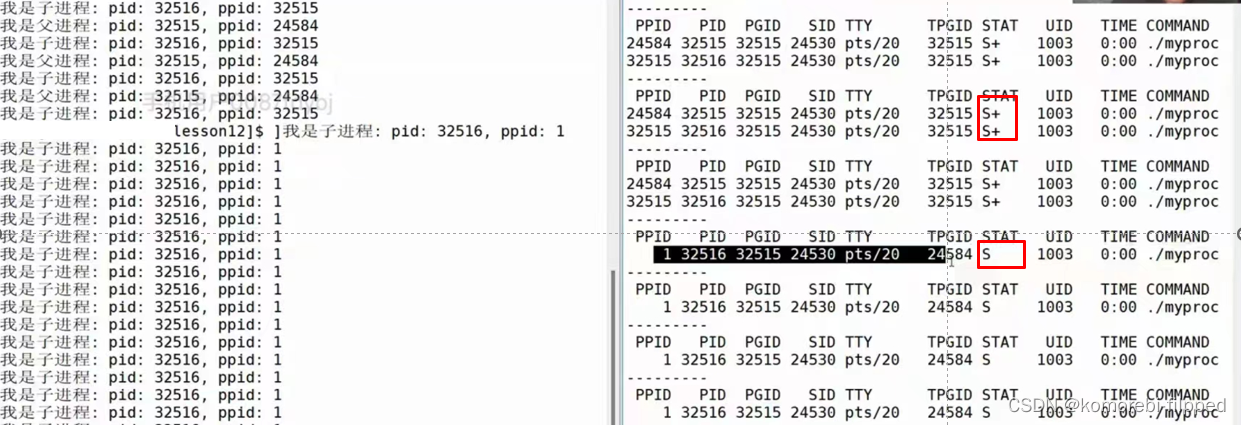
Linux——进程概念(进程状态)
目录 进程状态 三态模型 五态模型 七态模型 Example eg1:阻塞态:等待某种资源的过程 eg2:挂起态 Linux内核源代码 Linux进程状态查看 Linux运行状态 R运行状态(running): S睡眠状态(sleeping): D磁盘休眠状…...

超详细:正则表达式从入门到入门
文章目录匹配字符\d \D\s \S量词:匹配多个字符星号*加号问号?大括号{}集合字符[]明确字符范围字符补集字符常见字符集贪婪模式和非贪婪模式匹配开头和结尾贪婪模式和非贪婪模式常用函数re.findall()re.search()re.compile()re.split()re.sub()本文章首发…...

jupyter notebook小技巧
1、.ipynb 文件转word文档 将 jupyter notebook(.ipynb 文件)转换为 word 文件(.docx)的最简单方法是使用 pandoc。 首先安装pip install pandoc, 安装后,在将 Jupyter notebook文件目录cmd 然后输入打开…...
考研复试机试 | c++ | 王道复试班
目录n的阶乘 (清华上机)题目描述代码汉诺塔问题题目:代码:Fibonacci数列 (上交复试)题目代码:二叉树:题目:代码:n的阶乘 (清华上机) …...

js闭包简单理解
js里面的闭包是一个难点也是它的一个特色,是我们必须掌握的js高级特性,那么什么是闭包呢?它又有什么作用呢? 1,提到闭包我们这里先讲解一下js作用域的问题 js的作用域分两种,全局和局部,基于我…...

Atomic Layout测试策略:单元测试与集成测试最佳实践
Atomic Layout测试策略:单元测试与集成测试最佳实践 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout 在现代前端开发中,构建可靠的…...

机器学习算法选择的统计推断:从p值到保形预测的实战指南
1. 项目概述:当算法选择遇上统计推断在机器学习驱动的设计任务里,比如设计一个能高效结合特定蛋白质的RNA序列,或者优化一个酶分子,我们手头往往不只有一种设计算法。相反,我们有一个“菜单”,里面列着各种…...

UE5 Vulkan PC平台适配核心:DataDrivenPlatformInfo.ini详解
1. 这不是配置文件,是UE5 Vulkan平台适配的“宪法性文档”你打开UE5项目目录下的Engine/Config/Platform/路径,一眼扫过去,DataDrivenPlatformInfo.ini这个文件名平平无奇——它不像DefaultEngine.ini那样天天被修改,也不像BaseEn…...

CStealer工作原理揭秘:从Discord令牌到加密货币钱包的窃取技术
CStealer工作原理揭秘:从Discord令牌到加密货币钱包的窃取技术 【免费下载链接】cstealer [BIG UPDATE] A discord token grabber, crypto wallet stealer, cookie stealer, password stealer, file stealer etc. app written in Python. 项目地址: https://gitco…...

保姆级教程:用Python将EEG脑电信号转成图像,喂给VGG+LSTM做疲劳检测
从EEG信号到疲劳检测图像:Python实战全流程解析当脑电波遇见计算机视觉,会擦出怎样的火花?传统EEG分析往往局限于时频域特征提取,而本文将带你探索一种革命性的思路——将多通道脑电信号转化为彩色拓扑图像,让卷积神经…...

Redis 缓存实战案例与技术详解
Redis 缓存实战案例与技术详解 1. Redis 简介 Redis 是一种开源的内存数据存储,常用于缓存和消息队列。 2. 配置优化 使用 LRU 淘汰策略配置数据持久化功能 3. 实战案例 案例一:电商秒杀系统 架构:前端系统 Redis 持久化缓存特点:…...

Graph Fusion:一张 512 节点的图怎么压到 120 个以内
Operator Fusion 解决单点算子合并,Graph Fusion 在更大范围做整图级别的融合。GE 图引擎收到 ATC 编译好的图后,不是直接拿去执行——它先跑一遍图优化流水线,常量折叠、算子替换、模式匹配、Buffer 复用,把几百个节点的"散…...

别再为单细胞数据批次效应发愁了!手把手教你用Harmony算法搞定整合分析
单细胞数据整合实战:用Harmony消除批次效应的完整指南当你在不同时间、不同实验室或使用不同平台获得多个单细胞RNA测序数据集时,最令人头疼的问题莫过于批次效应——这种技术性差异会掩盖真实的生物学信号。想象一下,你精心设计的实验因为数…...

FPG平台:信息透明度建设的深度解析
FPG平台:信息透明度建设的深度解析金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG平台经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的…...

英语 听力 重读软件app
写一个可以读取一个pdf,或者doc 的apk。并语音播放出来。可以用语音指令或者某些在界面上的按键来控制,重复上一句,或者重复上一段,或者重复上5句,重复上10句,重复上3句。重复整个段落,重复整个章节。还有一…...