Hudi SQL DDL
本文介绍Hudi在 Spark 和 Flink 中使用SQL创建和更改表的支持。
1.Spark SQL 创建hudi表
1.1 创建非分区表
使用标准CREATE TABLE语法创建表,该语法支持分区和传递表属性。
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name, ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];创建一个非分区表就像创建一个常规表一样简单。
-- create a Hudi table
CREATE TABLE IF NOT EXISTS hudi_table (
id INT,
name STRING,
price DOUBLE
) USING hudi;SparkSQL和Hudi字段类型比较
| Spark | Hudi | Notes |
| boolean | boolean | |
| byte | int | |
| short | int | |
| integer | int | |
| long | long | |
| date | date | |
| timestamp | timestamp | |
| float | float | |
| double | double | |
| string | string | |
| decimal | decimal | |
| binary | bytes | |
| array | array | |
| map | map | |
| struct | struct | |
| char | not supported | |
| varchar | not supported | |
| numeric | not supported | |
| null | not supported | |
| object | not supported |
1.2 创建分区表
分区表可以通过添加partition by子句来创建。分区有助于根据分区列将数据组织到多个文件夹中。它还可以通过限制扫描的元数据、索引和数据的数量来帮助加快查询和索引查找。
CREATE TABLE IF NOT EXISTS hudi_table_partitioned (
id BIGINT,
name STRING,
dt STRING,
hh STRING
) USING hudi
TBLPROPERTIES (
type = 'cow'
)
PARTITIONED BY (dt);还可以通过提供逗号分隔的字段名来创建由多个字段分区的表。例如,“partitioned by dt,hh”
1.3 创建包含键和排序字段的表
表使用键跟踪表中的每个记录。Hudi 为每个新记录自动生成了一个高度压缩的键。如果要使用现有字段作为关键字,可以设置primaryKey选项。通常,这还要配置preCombineField选项,以处理传入写入中具有相同键的无序数据和潜在重复记录。
CREATE TABLE IF NOT EXISTS hudi_table_keyed (
id INT,
name STRING,
price DOUBLE,
ts BIGINT
) USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
);
1.4 外部表
通常,Hudi表是由流式写入器(如streamer tool,)创建的,后者可能需要一些SQL语句才能在其上运行。可以使用location 语句创建外部表。不需要指定schema和除分区列之外的任何properties,Hudi可以自动识别schemo和配置。
CREATE TABLE hudi_table_external
USING hudi
LOCATION 'file:///tmp/hudi_table/';
1.5 Create Table As Select (CTAS)
Hudi支持CTAS(create table as select)来支持Hudi表的创建和数据加载。为了确保高效地执行此操作,即使对于大负载,CTAS也使用bulk insert写入操作。
1.5.1 使用CATS创建分区表
# create managed parquet table
CREATE TABLE parquet_table
USING parquet
LOCATION 'file:///tmp/parquet_dataset/';# CTAS by loading data into Hudi table
CREATE TABLE hudi_table_ctas
USING hudi
TBLPROPERTIES (
type = 'cow',
preCombineField = 'ts'
)
PARTITIONED BY (dt)
AS SELECT * FROM parquet_table;
1.5.2 使用CATS创建非分区表
创建非分区表时也可以使用create table as select。
# create managed parquet table
CREATE TABLE parquet_table
USING parquet
LOCATION 'file:///tmp/parquet_dataset/';# CTAS by loading data into Hudi table
CREATE TABLE hudi_table_ctas
USING hudi
TBLPROPERTIES (
type = 'cow',
preCombineField = 'ts'
)
AS SELECT * FROM parquet_table;
1.5.3在使用CATS时设置主键
可以通过在表属性中设置primaryKey。
CREATE TABLE hudi_table_ctas
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'id'
)
PARTITIONED BY (dt)
AS
SELECT 1 AS id, 'a1' AS name, 10 AS price, 1000 AS dt;
1.5.4使用CATS复制数据
可以通过create table as select 复制外部表数据。
# create managed parquet table
CREATE TABLE parquet_table
USING parquet
LOCATION 'file:///tmp/parquet_dataset/*.parquet';# CTAS by loading data into hudi table
CREATE TABLE hudi_table_ctas
USING hudi
LOCATION 'file:///tmp/hudi/hudi_tbl/'
TBLPROPERTIES (
type = 'cow'
)
AS SELECT * FROM parquet_table;1.6 设置Hudi配置
可以通过不同的方法传递给定hudi表的配置。
使用set命令
可以使用set命令来设置Hudi的任何写入配置。这将适用于整个spark会话中的操作。
set hoodie.insert.shuffle.parallelism = 100;
set hoodie.upsert.shuffle.parallelism = 100;
set hoodie.delete.shuffle.parallelism = 100;使用表属性
还可以在创建表时配置表选项。这将仅适用于当前表,并覆盖任何SET命令值。
CREATE TABLE IF NOT EXISTS tableName (
colName1 colType1,
colName2 colType2,
...
) USING hudi
TBLPROPERTIES (
primaryKey = '${colName1}',
type = 'cow',
${hoodie.config.key1} = '${hoodie.config.value1}',
${hoodie.config.key2} = '${hoodie.config.value2}',
....
);e.g.
CREATE TABLE IF NOT EXISTS hudi_table (
id BIGINT,
name STRING,
price DOUBLE
) USING hudi
TBLPROPERTIES (
primaryKey = 'id',
type = 'cow',
hoodie.cleaner.fileversions.retained = '20',
hoodie.keep.max.commits = '20'
);
1.7 表属性
可以在创建表时设置表属性。
1.7.1 常用表属性
| 参数名 | 默认值 | 描述 |
| type | cow | 要创建的表类型。type='cow'创建COPY-ON-WRITE表,type='mor'创建MERGE-ON-READ表。与hoodie.datasource.write.table.type相同。 |
| primaryKey | uuid | 表的主键字段名,用逗号分隔。与hoodie.datasource.write.recordkey.field相同。如果忽略此配置,hudi将自动生成主键。如果明确设置,则主键生成将使用用户配置。 |
| preCombineField | 表的预合并字段。它用于在多个版本之间解析记录的最终版本。通常,事件时间或其他类似列将用于排序目的。Hudi将能够使用preCombine字段值处理无序数据。 |
primaryKey、preCombineField、type和其他属性区分大小写。
1.7.2并发写入器的Passing Lock Providers
Hudi需要一个锁提供程序来支持并发写入程序或异步表服务。用户也可以将这些表属性传递到TBLPROPERTIES中。下面是一个基于Zookeeper的配置示例。
-- Properties to use Lock configurations to support Multi Writers
TBLPROPERTIES(
hoodie.write.lock.zookeeper.url = "zookeeper",
hoodie.write.lock.zookeeper.port = "2181",
hoodie.write.lock.zookeeper.lock_key = "tableName",
hoodie.write.lock.provider = "org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider",
hoodie.write.concurrency.mode = "optimistic_concurrency_control",
hoodie.write.lock.zookeeper.base_path = "/tableName"
)
1.7.3为表启用列统计信息/记录级别索引
Hudi提供了利用有关表的丰富元数据和索引、加快DML和查询的能力。例如:可以启用列统计信息的收集来执行快速数据跳过,或者可以使用以下表属性使用记录级别索引来执行快速更新或点查找。
TBLPROPERTIES('hoodie.metadata.index.column.stats.enable' = 'true''hoodie.metadata.record.index.enable' = 'true'
)
1.8 Spark Alter Table
语法
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName;-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType [, colAndType]);样例
--rename to:
ALTER TABLE hudi_table RENAME TO hudi_table_renamed;--add column:
ALTER TABLE hudi_table ADD COLUMNS(remark STRING);1.9 修改表属性
语法
-- alter table ... set|unset
ALTER TABLE tableIdentifier SET|UNSET TBLPROPERTIES (table_property = 'property_value');样例
ALTER TABLE hudi_table SET TBLPROPERTIES (hoodie.keep.max.commits = '10');
ALTER TABLE hudi_table SET TBLPROPERTIES ("note" = "don't drop this table");ALTER TABLE hudi_table UNSET TBLPROPERTIES IF EXISTS (hoodie.keep.max.commits);
ALTER TABLE hudi_table UNSET TBLPROPERTIES IF EXISTS ('note');当前,尝试更改列类型可能会引发错误。不支持将列colName的oldColType更改为colName的newColType。由于一个开放的SPARK问题。
1.10 修改配置属性
还可以通过alter table SET SERDEPROPERTIES更改表的写入配置。
语法
-- alter table ... set|unset
ALTER TABLE tableName SET SERDEPROPERTIES ('property' = 'property_value');样例
ALTER TABLE hudi_table SET SERDEPROPERTIES ('key1' = 'value1');1.11 展示和删除分区
语法
-- Show partitions
SHOW PARTITIONS tableIdentifier;-- Drop partition
ALTER TABLE tableIdentifier DROP PARTITION ( partition_col_name = partition_col_val [ , ... ] );样例
--Show partition:
SHOW PARTITIONS hudi_table;--Drop partition:
ALTER TABLE hudi_table DROP PARTITION (dt='2021-12-09', hh='10');
1.12 使用限制
Hudi目前在使用Spark SQL创建/更改表时有以下限制。
1) ALTER TABLE ... RENAME TO ...使用AWS Glue Data Catalog作为配置单元元存储时不支持,因为Glue本身不支持表重命名。
2)Spark SQL创建的新Hudi表将默认设置hoodie.datasource.write.hive_style_partitioning=true,以便于使用。这可以使用表属性重写。
2.Flink SQL 创建Hudi表
2.1 创建catalog
catalog有助于管理SQL表,如果catalog保留表定义,则可以在会话之间共享表。对于hms模式,catalog还补充了配置单元同步选项。
样例
CREATE CATALOG hoodie_catalog
WITH ('type'='hudi','catalog.path' = '${catalog default root path}','hive.conf.dir' = '${directory where hive-site.xml is located}','mode'='hms' -- supports 'dfs' mode that uses the DFS backend for table DDLs persistence);选项
| 选项名 | 必填项 | 默认值 | 描述 |
| catalog.path | true | catalog表存储的默认路径,该路径用于自动推断表路径,默认表路径:${catalog.path}/${db_name}/${table_name} | |
| default-database | false | default | 默认数据库名称 |
| hive.conf.dir | false | hive-site.xml所在的目录,仅在hms模式下有效 | |
| mode | false | dfs | 支持使用hms持久化表选项的hms模式 |
| table.external | false | false | 是否创建外部表,仅在hms模式下有效 |
2.2 Create Table
CREATE TABLE hudi_table2(
id int,
name string,
price double
)
WITH (
'connector' = 'hudi',
'path' = 's3://bucket-name/hudi/',
'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, default is COPY_ON_WRITE
);
2.3 修改表
ALTER TABLE tableA RENAME TO tableB;
相关文章:

Hudi SQL DDL
本文介绍Hudi在 Spark 和 Flink 中使用SQL创建和更改表的支持。 1.Spark SQL 创建hudi表 1.1 创建非分区表 使用标准CREATE TABLE语法创建表,该语法支持分区和传递表属性。 CREATE TABLE [IF NOT EXISTS] [db_name.]table_name[(col_name data_type [COMMENT col_co…...
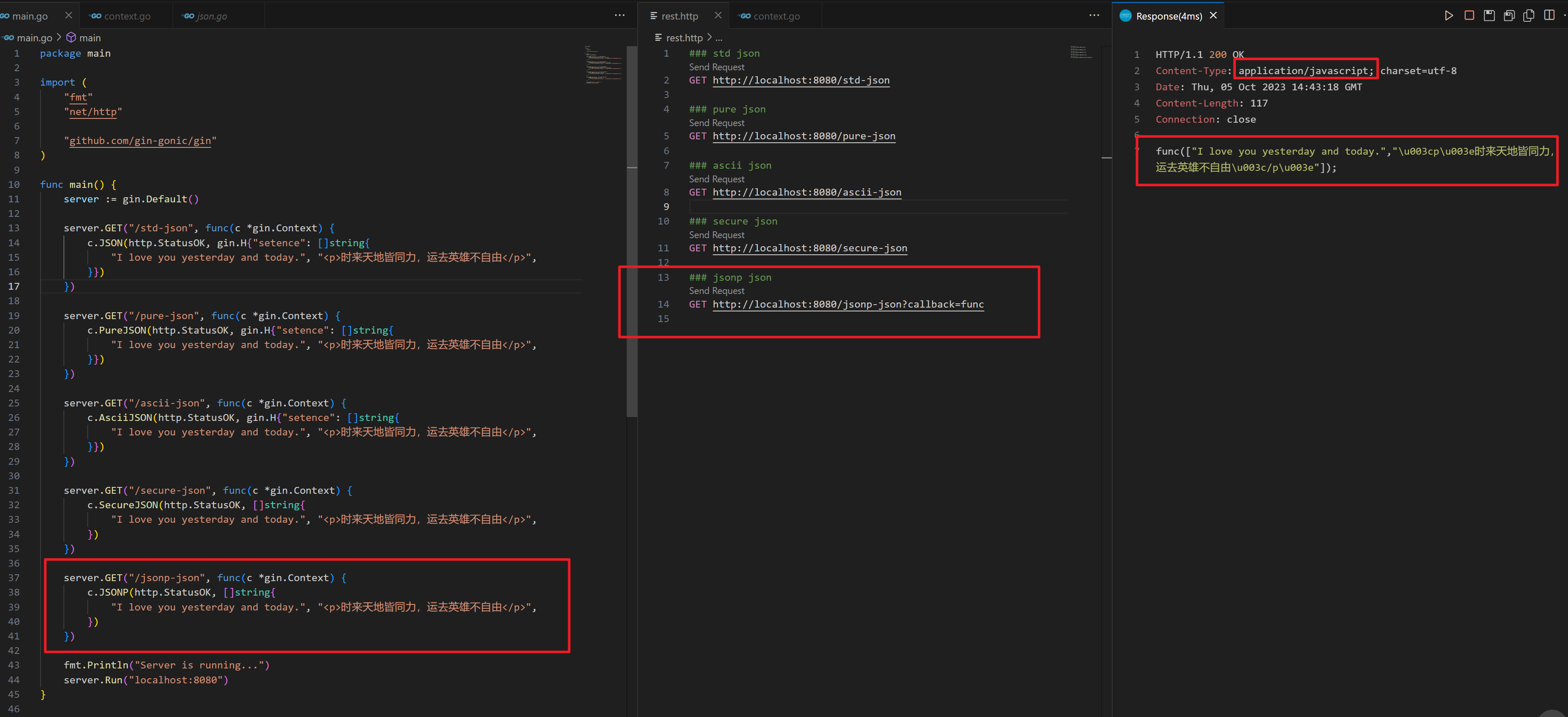
gin 框架的 JSON Render
gin 框架的 JSON Render gin 框架默认提供了很多的渲染器,开箱即用,非常方便,特别是开发 Restful 接口。不过它提供了好多种不同的 JSON Render,那么它们的区别是什么呢? // JSON contains the given interface obje…...
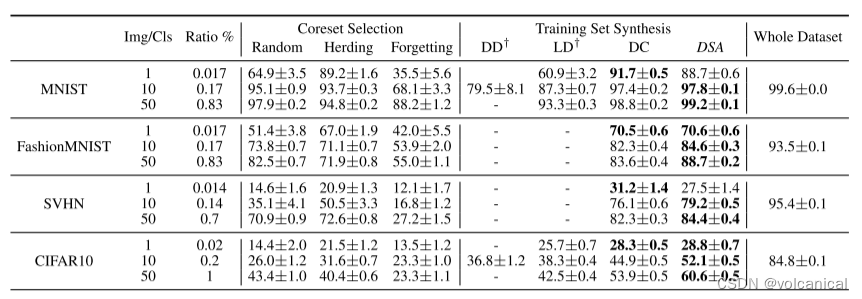
《Dataset Condensation with Differentiable Siamese Augmentation》
《Dataset Condensation with Differentiable Siamese Augmentation》 在本文中,我们专注于将大型训练集压缩成显著较小的合成集,这些合成集可以用于从头开始训练深度神经网络,性能下降最小。受最近的训练集合成方法的启发,我们提…...
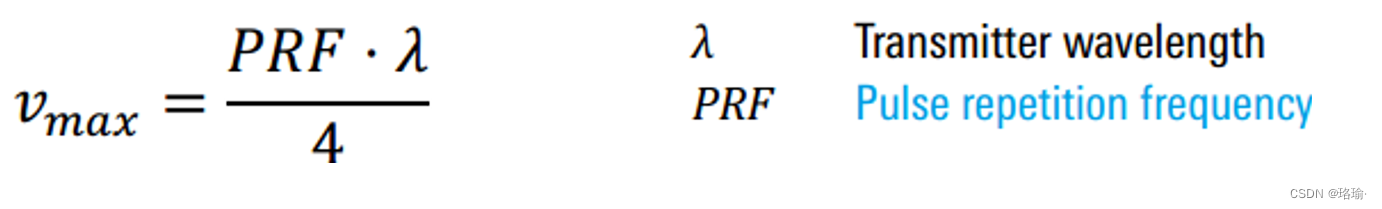
多普勒频率相关内容介绍
图1 多普勒效应 1、径向速度 径向速度是作用于雷达或远离雷达的速度的一部分。 图2 不同的速度 2、喷气发动机调制 JEM是涡轮机的压缩机叶片的旋转的多普勒频率。 3、多普勒困境 最大无模糊范围需要尽可能低的PRF; 最大无模糊速度需要尽可能高的PRF;…...
win10睡眠快捷方式
新建快捷方式 如下图 内容如下 rundll32.exe powrprof.dll,SetSuspendState 0,1,0 下一步 点击完成即可。 特此记录 anlog 2023年10月6日...

C++中的static和extern关键字
1 声明和定义 声明就是告诉编译器有这个东西的存在,而定义则是这个东西的实现。 对于变量来说,声明就是告诉编译器存在这个名称的变量,定义则是给这个变量分配内存并赋值: // 变量声明,声明时不能赋值,如…...

JAVA经典百题之找完数
题目:一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如61+2+3.编程找出1000以内的所有完数。 程序分析 首先,我们需要编写一个程序来找出1000以内的所有完数。"完数"是指一个数等于它的…...

CSS 滚动驱动动画 view-timeline-inset
view-timeline-inset 语法例子🌰 正 scroll-padding 为正正的 length正的 percentage 负 scroll-padding 为负负的 length负的 percentage 兼容性 view-timeline-inset 在使用 view() 时说过, 元素在滚动容器的可见性推动了 view progress timeline 的进展. 默认…...

ansible部署二进制k8s
简介 GitHub地址: https://github.com/chunxingque/ansible_install_k8s 本脚本通过ansible来快速安装和管理二进制k8s集群;支持高可用k8s集群和单机k8s集群地部署;支持不同版本k8s集群部署,一般小版本的部署脚本基本是通用的。 …...
Nginx限流熔断
一、Nginx限流熔断 Nginx 是一款流行的反向代理和负载均衡服务器,也可以用于实现服务熔断和限流。通过使用 Nginx 的限流和熔断模块,比如:ngx_http_limit_req_module 和 ngx_http_limit_conn_module,可以在代理层面对服务进行限流…...

QQ登录的具体流程
文章目录 网站授权QQ登录QQ登录的完整流程代码示例1. 添加依赖2. 配置文件3. 实现Service4. 创建Controller 网站授权QQ登录 首先需要去QQ互联申请应用填写网站的相关信息,以及回调地址,需要进行审核。申请流程暂时不说了,百度一下挺多申请失…...
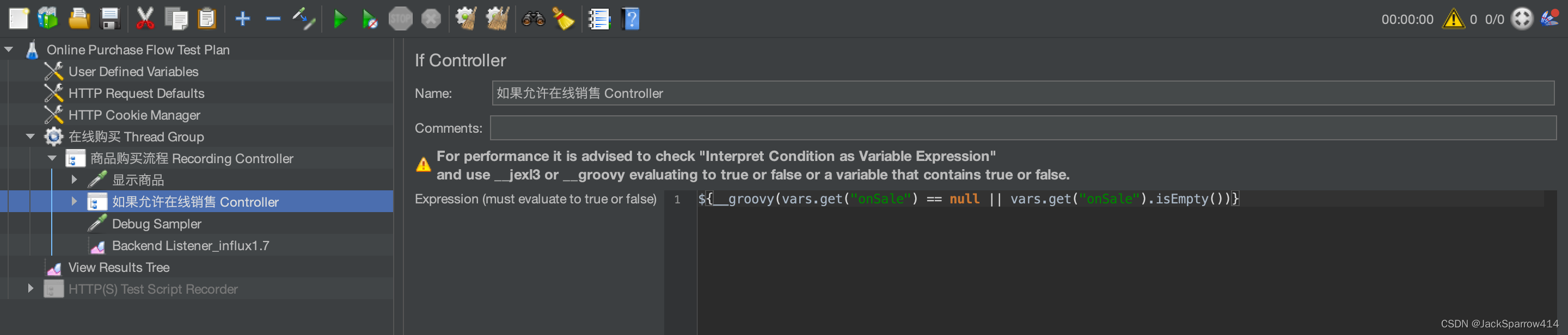
用JMeter对HTTP接口进行压测(一)压测脚本的书写、调试思路
文章目录 安装JMeter和Groovy为什么选择Groovy? 压测需求以及思路准备JMeter脚本以及脚本正确性验证使用Test Script Recorder来获取整条业务线上涉及的接口为什么使用Test Script Recorder? 配置Test Script Recorder对接口进行动态化处理处理全局变量以…...

接着聊聊如何从binlog文件恢复误delete的数据,模拟Oracle的闪回功能
看腻了文章就来听听视频演示吧:https://www.bilibili.com/video/BV1cV411A7iU/ delete忘加where条件(模拟Oracle闪回) 操作基本等同于上篇:再来谈谈如何从binlog文件恢复误update的数据,模拟Oracle的回滚功能 原理&a…...

计算机竞赛 深度学习机器视觉车道线识别与检测 -自动驾驶
文章目录 1 前言2 先上成果3 车道线4 问题抽象(建立模型)5 帧掩码(Frame Mask)6 车道检测的图像预处理7 图像阈值化8 霍夫线变换9 实现车道检测9.1 帧掩码创建9.2 图像预处理9.2.1 图像阈值化9.2.2 霍夫线变换 最后 1 前言 🔥 优质竞赛项目系列,今天要分…...

pyqt5使用经验总结
pyqt5环境配置注意: 安装pyqt5 pip install PyQt5 pyqt5-tools 环境变量-创建变量名: 健名:QT_QPA_PLATFORM_PLUGIN_PATH 值为:Lib\site-packages\PyQt5\Qt\plugins pyqt5经验2: 使用designer.exe进行设计࿱…...

【MQTT】mosquitto库中SSL/TLS相关API接口
文章目录 1.相关API1.1 mosquitto_tls_set1.2 mosquitto_tls_insecure_set1.3 mosquitto_tls_opts_set1.4 mosquitto_tls_insecure_set1.5 mosquitto_tls_set_context1.6 mosquitto_tls_psk_set 2.示例代码 Mosquitto 是一个流行的 MQTT 消息代理(broker)…...
假期题目整合
1. 下载解压题目查看即可 典型的猪圈密码只需要照着输入字符解开即可得到答案 2. 冷门类型的密码题型,需要特意去找相应的解题思路,直接百度搜索天干地支解密即可 3. 一眼能出思路他已经给了篱笆墙的提示提示你是栅栏密码对应解密即可 4. 最简单的社会主…...

Redisson—分布式服务
一、 分布式远程服务(Remote Service) 基于Redis的Java分布式远程服务,可以用来通过共享接口执行存在于另一个Redisson实例里的对象方法。换句话说就是通过Redis实现了Java的远程过程调用(RPC)。分布式远程服务基于可…...
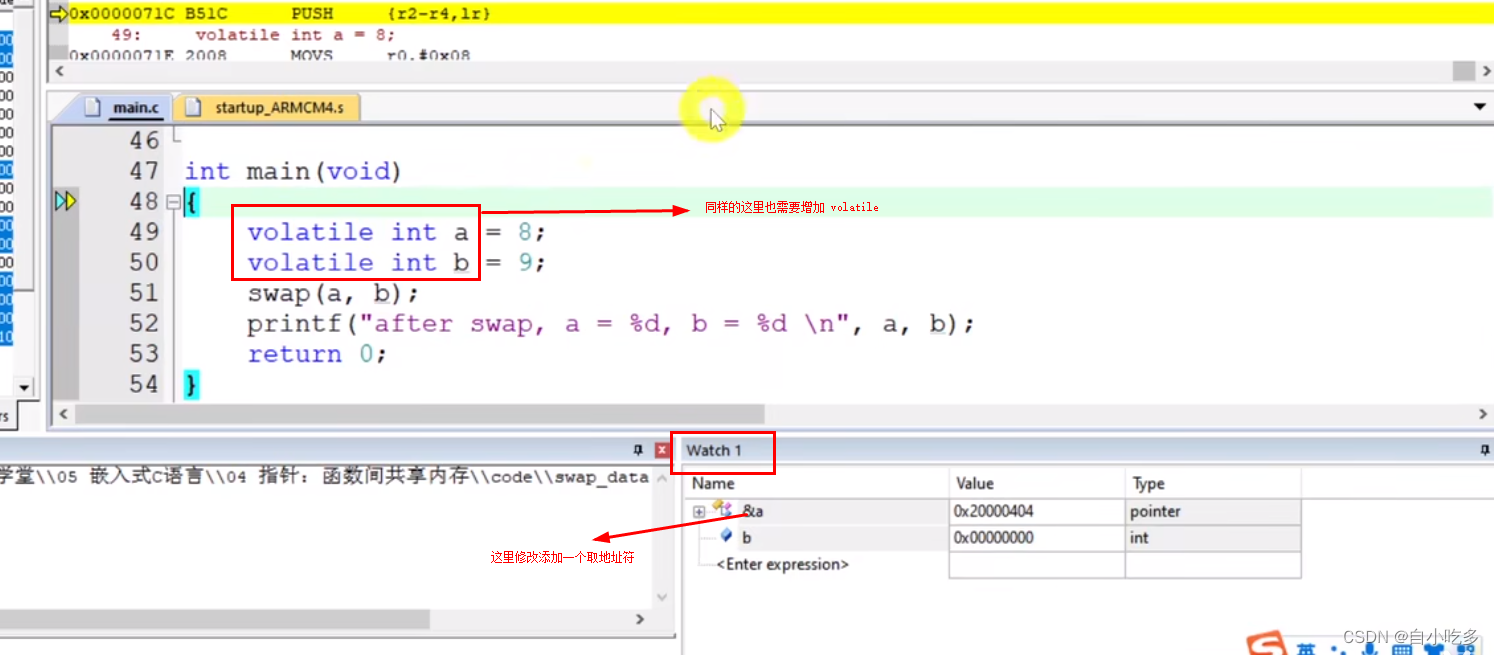
volatile使用方法
volatile使用方法 编译优化。使用等级3的话,可能将优化了一些变量。 这为什么会开启等第三呢?这是关于单片机的内存容量比较小,所以开启优化的话,可以可以省一些空间,但是如果。会出现些变量的问题,需要通过…...

提升您的 Go 应用性能的 6 种方法
优化您的 Go 应用程序 1. 如果您的应用程序在 Kubernetes 中运行,请自动设置 GOMAXPROCS 以匹配 Linux 容器的 CPU 配额 Go 调度器 可以具有与运行设备的核心数量一样多的线程。由于我们的应用程序在 Kubernetes 环境中的节点上运行,当我们的 Go 应用程…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...

全方位梳理 OpenClaw 部署与使用干货
OpenClaw 一键安装包|可视化部署,简化环境配置流程 ✨适配系统:Windows10/11 64 位 当前版本:v2.7.5(虾壳云版) ✨核心优势:全程可视化操作,不用命令行、不用手动配置 Python/Node…...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...

第十五章:Agent产品的监控与可观测性:如何构建“看得见、管得住“的AI系统
导读 想象一下:你上线了一个客服Agent,第一个月运行平稳。第二个月开始,你陆续收到用户投诉说"答案不对"。但你的监控系统显示:请求量正常、延迟正常、错误率正常。你打开日志,发现Agent确实"成功"处理了每个请求——只是它给错了答案。 这不是监控…...