强化学习------Sarsa算法
简介
SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法,通常应用于机器学习和强化学习学习领域中。它由Rummery 和 Niranjan在技术论文“Modified Connectionist Q-Learning(MCQL)” 中介绍了这个算法,并且由Rich Sutton在注脚处提到了SARSA这个别名。
State-Action-Reward-State-Action这个名称清楚地反应了其学习更新函数依赖的5个值,分别是当前状态S1,当前状态选中的动作A1,获得的奖励Reward,S1状态下执行A1后取得的状态S2及S2状态下将会执行的动作A2。我们取这5个值的首字母串起来可以得出一个词SARSA。
算法的核心思想可以简化为:
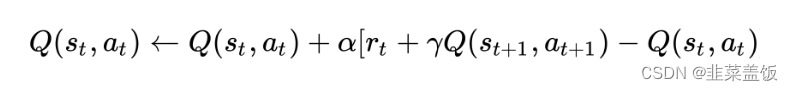
用伪代码可以表示为:

算法实战
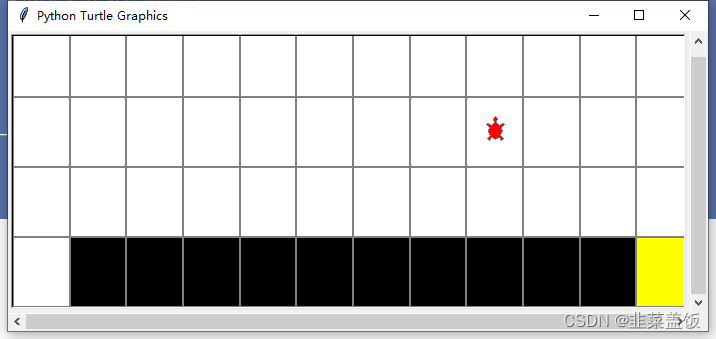
我们使用openAI的gym中的CliffWalking-v0作为环境
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import gym
import time
import gridworld#Sarsa算法
class Sarsa():def __init__(self,num_states,num_actions,e_greed=0.1,lr=0.9,gamma=0.8):#建立Q表格self.Q = np.zeros((num_states,num_actions))self.e_greed = e_greed #探索概率self.num_states = num_statesself.num_actions = num_actionsself.lr = lr #学习率self.gamma = gamma #折扣因子def predict(self,state):"""通过当前状态预测下一个动作:param state::return:"""#获取当前状态的所有动作的切片Q_list = self.Q[state,:]#随机选取其中最大值中的某一个(防止存在多个最大值时,总是选最前面的问题)action = np.random.choice(np.flatnonzero(Q_list == Q_list.max()))return actiondef action(self,state):"""选取动作:param state::return:"""#探索,随机选择一个动作if np.random.uniform(0,1) < self.e_greed:action = np.random.choice(self.num_actions)else: #直接选取最大Q值的动作action = self.predict(state)return actiondef learn(self,state,action,reward,next_state,next_action,done):cur_Q = self.Q[state,action]# 当游戏结束时,不存在next_action和next_stateif done:target_Q = rewardelse:target_Q = reward + self.gamma*self.Q[next_state,next_action]self.Q[state,action] += self.lr*(target_Q - cur_Q)#训练
def train_episode(env,agent,is_render):total_reward = 0#初始化环境state,_ = env.reset()action = agent.action(state)while True:#执行动作返回结果next_state,reward,done,_,_ = env.step(action)#根据状态获取动作next_action = agent.action(next_state)#更新参数agent.learn(state,action,reward,next_state,next_action,done)#循环执行action = next_actionstate = next_statetotal_reward += rewardif is_render:env.render()if done:breakreturn total_reward
#测试
def test_episode(env,agent,is_render=False):total_reward = 0# 初始化环境state,_ = env.reset()while True:action = agent.predict(state)next_state, reward, done, _,_ = env.step(action)state = next_statetotal_reward += rewardenv.render()time.sleep(0.5)if done:breakreturn total_reward
#训练
def train(env,episodes=500,lr=0.1,gamma=0.9,e_greed=0.1):agent = Sarsa(num_states = env.observation_space.n,num_actions = env.action_space.n,lr = lr,gamma = gamma,e_greed = e_greed)is_render = False#先训练episodes次for e in range(episodes):ep_reward = train_episode(env,agent,is_render)print('Episode %s : reward= %.1f'%(e,ep_reward))#每执行50轮就显示一次if e%50 == 0:is_render = Trueelse:is_render = False#训练结束后,我i们测试模型test_reward = test_episode(env,agent)print('test_reward= %.1f' % (test_reward))if __name__ == '__main__':env = gym.make("CliffWalking-v0")env = gridworld.CliffWalkingWapper(env)train(env)运行效果
另附工具类
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.# -*- coding: utf-8 -*-import gym
import turtle
import numpy as np# turtle tutorial : https://docs.python.org/3.3/library/turtle.htmldef GridWorld(gridmap=None, is_slippery=False):if gridmap is None:gridmap = ['SFFF', 'FHFH', 'FFFH', 'HFFG']env = gym.make("FrozenLake-v0", desc=gridmap, is_slippery=False)env = FrozenLakeWapper(env)return envclass FrozenLakeWapper(gym.Wrapper):def __init__(self, env):gym.Wrapper.__init__(self, env)self.max_y = env.desc.shape[0]self.max_x = env.desc.shape[1]self.t = Noneself.unit = 50def draw_box(self, x, y, fillcolor='', line_color='gray'):self.t.up()self.t.goto(x * self.unit, y * self.unit)self.t.color(line_color)self.t.fillcolor(fillcolor)self.t.setheading(90)self.t.down()self.t.begin_fill()for _ in range(4):self.t.forward(self.unit)self.t.right(90)self.t.end_fill()def move_player(self, x, y):self.t.up()self.t.setheading(90)self.t.fillcolor('red')self.t.goto((x + 0.5) * self.unit, (y + 0.5) * self.unit)def render(self):if self.t == None:self.t = turtle.Turtle()self.wn = turtle.Screen()self.wn.setup(self.unit * self.max_x + 100,self.unit * self.max_y + 100)self.wn.setworldcoordinates(0, 0, self.unit * self.max_x,self.unit * self.max_y)self.t.shape('circle')self.t.width(2)self.t.speed(0)self.t.color('gray')for i in range(self.desc.shape[0]):for j in range(self.desc.shape[1]):x = jy = self.max_y - 1 - iif self.desc[i][j] == b'S': # Startself.draw_box(x, y, 'white')elif self.desc[i][j] == b'F': # Frozen iceself.draw_box(x, y, 'white')elif self.desc[i][j] == b'G': # Goalself.draw_box(x, y, 'yellow')elif self.desc[i][j] == b'H': # Holeself.draw_box(x, y, 'black')else:self.draw_box(x, y, 'white')self.t.shape('turtle')x_pos = self.s % self.max_xy_pos = self.max_y - 1 - int(self.s / self.max_x)self.move_player(x_pos, y_pos)class CliffWalkingWapper(gym.Wrapper):def __init__(self, env):gym.Wrapper.__init__(self, env)self.t = Noneself.unit = 50self.max_x = 12self.max_y = 4def draw_x_line(self, y, x0, x1, color='gray'):assert x1 > x0self.t.color(color)self.t.setheading(0)self.t.up()self.t.goto(x0, y)self.t.down()self.t.forward(x1 - x0)def draw_y_line(self, x, y0, y1, color='gray'):assert y1 > y0self.t.color(color)self.t.setheading(90)self.t.up()self.t.goto(x, y0)self.t.down()self.t.forward(y1 - y0)def draw_box(self, x, y, fillcolor='', line_color='gray'):self.t.up()self.t.goto(x * self.unit, y * self.unit)self.t.color(line_color)self.t.fillcolor(fillcolor)self.t.setheading(90)self.t.down()self.t.begin_fill()for i in range(4):self.t.forward(self.unit)self.t.right(90)self.t.end_fill()def move_player(self, x, y):self.t.up()self.t.setheading(90)self.t.fillcolor('red')self.t.goto((x + 0.5) * self.unit, (y + 0.5) * self.unit)def render(self):if self.t == None:self.t = turtle.Turtle()self.wn = turtle.Screen()self.wn.setup(self.unit * self.max_x + 100,self.unit * self.max_y + 100)self.wn.setworldcoordinates(0, 0, self.unit * self.max_x,self.unit * self.max_y)self.t.shape('circle')self.t.width(2)self.t.speed(0)self.t.color('gray')for _ in range(2):self.t.forward(self.max_x * self.unit)self.t.left(90)self.t.forward(self.max_y * self.unit)self.t.left(90)for i in range(1, self.max_y):self.draw_x_line(y=i * self.unit, x0=0, x1=self.max_x * self.unit)for i in range(1, self.max_x):self.draw_y_line(x=i * self.unit, y0=0, y1=self.max_y * self.unit)for i in range(1, self.max_x - 1):self.draw_box(i, 0, 'black')self.draw_box(self.max_x - 1, 0, 'yellow')self.t.shape('turtle')x_pos = self.s % self.max_xy_pos = self.max_y - 1 - int(self.s / self.max_x)self.move_player(x_pos, y_pos)if __name__ == '__main__':# 环境1:FrozenLake, 可以配置冰面是否是滑的# 0 left, 1 down, 2 right, 3 upenv = gym.make("FrozenLake-v0", is_slippery=False)env = FrozenLakeWapper(env)# 环境2:CliffWalking, 悬崖环境# env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left# env = CliffWalkingWapper(env)# 环境3:自定义格子世界,可以配置地图, S为出发点Start, F为平地Floor, H为洞Hole, G为出口目标Goal# gridmap = [# 'SFFF',# 'FHFF',# 'FFFF',# 'HFGF' ]# env = GridWorld(gridmap)env.reset()for step in range(10):action = np.random.randint(0, 4)obs, reward, done, info = env.step(action)print('step {}: action {}, obs {}, reward {}, done {}, info {}'.format(\step, action, obs, reward, done, info))env.render() # 渲染一帧图像
相关文章:
强化学习------Sarsa算法
简介 SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法,通常应用于机器学习和强化学习学习领域中。它由Rummery 和 Niranjan在技术论文“Modified Connectionist Q-Learning(MCQL)” 中…...

[HNCTF 2022 WEEK2]easy_unser - 反序列化+wakeup绕过+目录绕过
题目代码: <?php include f14g.php;error_reporting(0);highlight_file(__FILE__);class body{private $want,$todonothing "i cant get you want,But you can tell me before I wake up and change my mind";public function __construct($want){…...

FastThreadLocal 快在哪里 ?
FastThreadLocal 快在哪里 ? 引言FastThreadLocalset如何获取当前线程私有的InternalThreadLocalMap ?如何知道当前线程使用到了哪些FastThreadLocal实例 ? get垃圾回收 小结 引言 FastThreadLocal 是 Netty 中造的一个轮子,那么为什么放着…...

ggkegg | 用这个神包玩转kegg数据库吧!~(一)
1写在前面 好久没更了,实在是太忙了,值班真的是根本不不睡觉啊,一忙一整天,忙到怀疑人生。😭 最近看到比较🔥的就是ggkegg包,感觉使用起来还是有一定难度的。🫠 和大家分享一下使用教…...

【小黑送书—第三期】>>《深入浅出SSD》
近年来国家大力支持半导体行业,鼓励自主创新,中国SSD技术和产业良性发展,产业链在不断完善,与国际厂商的差距逐渐缩小。但从行业发展趋势来看,SSD相关技术仍有大幅进步的空间,SSD相关技术也确实在不断前进。…...

linux虚拟机查看防火墙状态
linux虚拟机查看防火墙状态 在Linux虚拟机中,你可以通过以下几种方法查看防火墙状态: 查看iptables防火墙状态 对于使用iptables防火墙的Linux系统,可以使用以下命令查看防火墙状态: sudo iptables -L -v -n查看firewalld防火墙…...

Docker 安装 MongoDB
一、什么是MongoDB MongoDB 是一个基于分布式文件存储的数据库。是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 二、MongoDB的安装 这里使用docker来安装MongoD 1.docker 拉取mysql镜像 docker pu…...
c++解压压缩包文件
功能实现需要依赖相关头文件和库文件,我这里的是64位的。需要的可以在这下载:https://download.csdn.net/download/bangtanhui/88403596 参考代码如下: #include <zip.h> #pragma comment(lib,"libzip.lib")//解压压缩包 /…...

MySql学习笔记:MySql性能优化
本文是自己的学习笔记,主要参考以下资料 - 大话设计模式,程杰著,清华大学出版社出版 - 马士兵教育 1、MySql调优金字塔2、MySql调优2.1、查询性能2.1.1、慢查询2.1.1.1、总结 1、MySql调优金字塔 Mysql 调优时设计三个层面,分别是…...
:粒子群优化(PSO)-提升机器学习模型准确率的秘密武器)
机器学习(四十八):粒子群优化(PSO)-提升机器学习模型准确率的秘密武器
文章目录 PSO算法简介为什么使用PSO优化机器学习参数?PSO与其他启发式算法的比较如何使用PSO优化机器学习模型?模块安装和测试例子PSO优化决策树总结PSO算法简介 粒子群优化算法(Particle Swarm Optimization,PSO)是一种模拟鸟群觅食行为的启发式算法。在PSO算法中,每个…...
MySQL - mysql服务基本操作以及基本SQL语句与函数
文章目录 操作mysql客户端与 mysql 服务之间的小九九了解 mysql 基本 SQL 语句语法书写规范SQL分类DDL库表查增 mysql数据类型数值类型字符类型日期类型 示例修改(表操作) DML添加数据删除数据修改数据 DQL查询多个字段条件查询聚合函数分组查询排序查询…...
[图论]哈尔滨工业大学(哈工大 HIT)学习笔记16-22
视频来源:2.7.1 补图_哔哩哔哩_bilibili 目录 1. 补图 1.1. 补图 2. 双图 2.1. 双图定理 3. 图兰定理/托兰定理 4. 极图理论 5. 欧拉图 5.1. 欧拉迹 5.2. 欧拉闭迹 5.3. 欧拉图 5.4. 欧拉定理 5.5. 伪图 1. 补图 1.1. 补图 (1)…...

使用关键字abstract 声明抽象类-PHP8知识详解
抽象类只能作为父类使用,因为抽象类不能被实例化。抽象类使用关键字abstract 声明,具体的使用语法格式如下: abstract class 抽象类名称{ //抽象类的成员变量列表 abstract function 成员方法1(参数); //抽象类的成员方法 abstract functi…...

Java中使用正则表达式
正则表达式 正则表达式(Regular Expression)是一种用于匹配、查找和替换文本的强大工具。它由一系列字符和特殊字符组成,可以用来描述字符串的模式。在编程和文本处理中,正则表达式常被用于验证输入、提取信息、搜索和替换文本等…...

Python之字符串分割替换移除
Python之字符串分割替换移除 分割 split(sepNone, maxsplit-1) -> list of strings 从左至右sep 指定分割字符串,缺省的情况下空白字符串作为分隔符maxsplit 指定分割的次数,-1 表示遍历整个字符串立即返回列表 rsplit(sepNone, maxsplit-1) -> …...
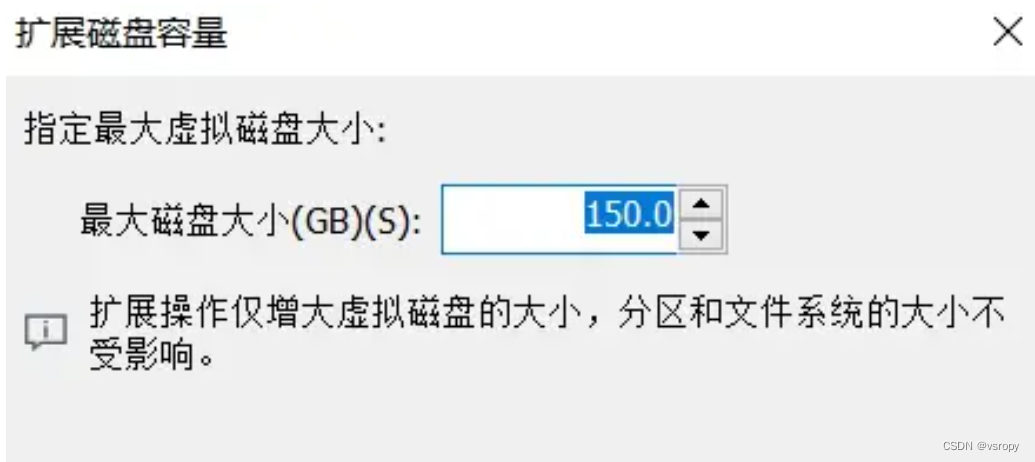
ubuntu增加内存
文章目录 1、硬盘操作步骤第二步:点击【扩展】(必须关闭ubuntu电源才能修改)第三步:修改【最大磁盘容量大小】1、硬盘操作步骤 最近发现Ubuntu空间不足,怎么去扩容呢? 第一步:点击【硬盘】 第二步:点击【扩展】(必须关闭ubuntu电源才能修改) 第三步:修改【最大磁…...
黑客都是土豪吗?真实情况是什么?
黑客的利益链条真的这么大这么好么,连最外围的都可以靠信息不对称赚普通人大学毕业上班族想都不敢想的金钱数目,黑客们是不是基本都是土豪 网络技术可以称为黑客程度的技术是不是真的很吃香?如果大部分大学生的智力资源都用在学习网络技术,会不会出现僧…...
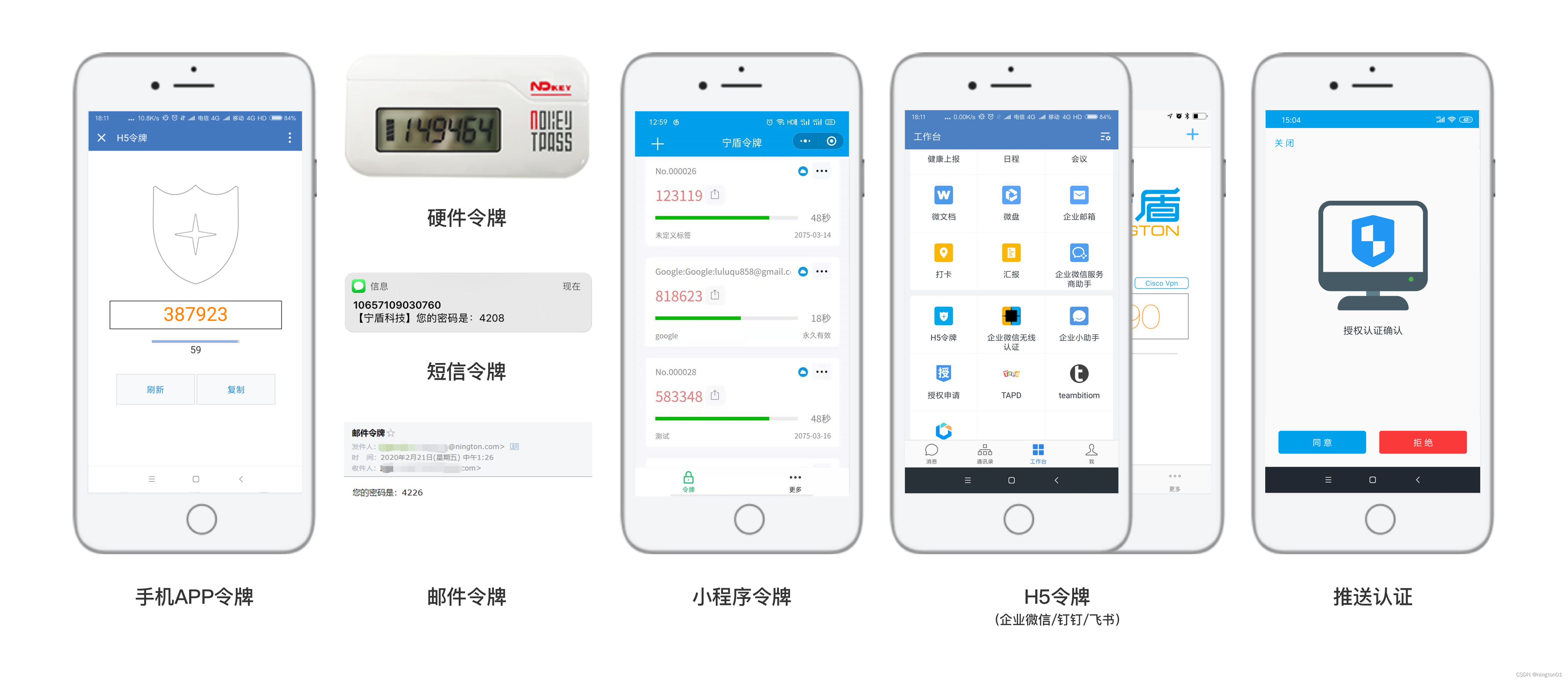
企业想过等保,其中2FA双因素认证手段必不可少
随着信息技术的飞速发展,网络安全问题日益凸显。等保2.0时代的到来,意味着企业和组织需要更加严格地保护自身的信息安全。而在这个过程中,双因素认证的重要性逐渐得到广泛认可。本文将探讨 2FA 双因素认证的重要性。 在了解 2FA 双因素认证的…...

Combination Lock
题目描述 新学期开学,您又回到了学校。您需要记住如何操作储物柜上的组合锁。一个组合锁的常见设计如图 1 所示。组合锁有一个圆形刻度表盘,在表盘上,有 40 个编号为从 0 至 39 的刻度,正上方有一个刻度指针。一个组合由这些数字…...
SpringBoot解决LocalDateTime返回数据为数组问题
现象: 在SpringBoot项目中,接口返回的数据出现LocalDateTime对象被转换成了数组 原因分析: 默认序列化情况下会使用SerializationFeature.WRITE_DATES_AS_TIMESTAMPS。使用这个解析时就会打印出数组。 解决方法: 在配置类中…...

从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱
从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱 当你在COCO数据集上训练的Mask R-CNN模型取得了0.85的mAP,满怀信心地将其部署到自动驾驶项目的Cityscapes数据集上时,却发现mIOU从预期的0.75骤降到0.52——这种&qu…...

小程序制作平台哪个好,新手好用开发工具推荐
小程序制作平台终极对决:码云数智、有赞、微盟,谁才是你的命定之选?2026年的小程序赛道,早已不是"一招鲜吃遍天"的时代。当数字化转型成为每一个商家的必答题,选平台就不再是选一个工具,而是选一…...

PX4开环控制避坑指南:为什么你的仿真无人机转圈总失败?从`setpoint_raw`话题到模式切换的深度解析
PX4开环控制避坑指南:为什么你的仿真无人机转圈总失败?从setpoint_raw话题到模式切换的深度解析 当你在Gazebo中启动PX4仿真环境,满怀期待地运行自己编写的开环控制代码,却发现无人机要么拒绝转圈,要么突然坠毁&#…...

causal-learn实战指南:从算法选择到因果图解读
1. 为什么你需要causal-learn? 第一次接触因果发现这个概念时,我正被一个电商用户行为分析项目搞得焦头烂额。传统机器学习模型能准确预测用户是否会购买商品,但产品经理总追着我问:"到底哪些因素真正导致了购买行为…...

Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤 在 Node.js 服务端应用中集成大模型能力,通常需要处理密…...

NewJob智能识别插件:求职时间管理的终极解决方案
NewJob智能识别插件:求职时间管理的终极解决方案 【免费下载链接】NewJob 一眼看出该职位最后修改时间,绿色为2周之内,暗橙色为1.5个月之内,红色为1.5个月以上 项目地址: https://gitcode.com/GitHub_Trending/ne/NewJob 在…...

Inkscape实战:用蒙版给你的Logo或文字快速添加酷炫的渐变效果
Inkscape蒙版进阶:打造专业级渐变Logo的5种创意技法 在矢量设计领域,一个普通的Logo与令人眼前一亮的作品之间,往往只差一层巧妙的渐变蒙版。作为开源矢量图形编辑器的标杆,Inkscape的蒙版功能远不止于基础遮罩——当它与渐变工具…...

为什么选择nxdumptool:Switch游戏备份的完全指南
为什么选择nxdumptool:Switch游戏备份的完全指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxdum…...

1951-2025年中国1km月平均气温逐年年内季节波动幅度数据集
中国1000米分辨率月平均气温数据集(1951-2025)提供了长时间序列、规则网格的气象背景信息,为开展气候变化分析和区域比较研究提供了基础数据支撑。针对原始月尺度序列直接使用不够便捷的问题,需要进一步形成具有明确主题和统一格式…...

taotoken api密钥管理与审计日志保障ubuntu服务器访问安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API密钥管理与审计日志保障Ubuntu服务器访问安全 1. 场景概述 在基于Ubuntu的服务器环境中集成大模型服务,安…...