Python-Scrapy框架(框架学习)
一、概述
Scrapy是一个用于爬取网站数据的Python框架,可以用来抓取web站点并从页面中提取结构化的数据。
基本组件:
-
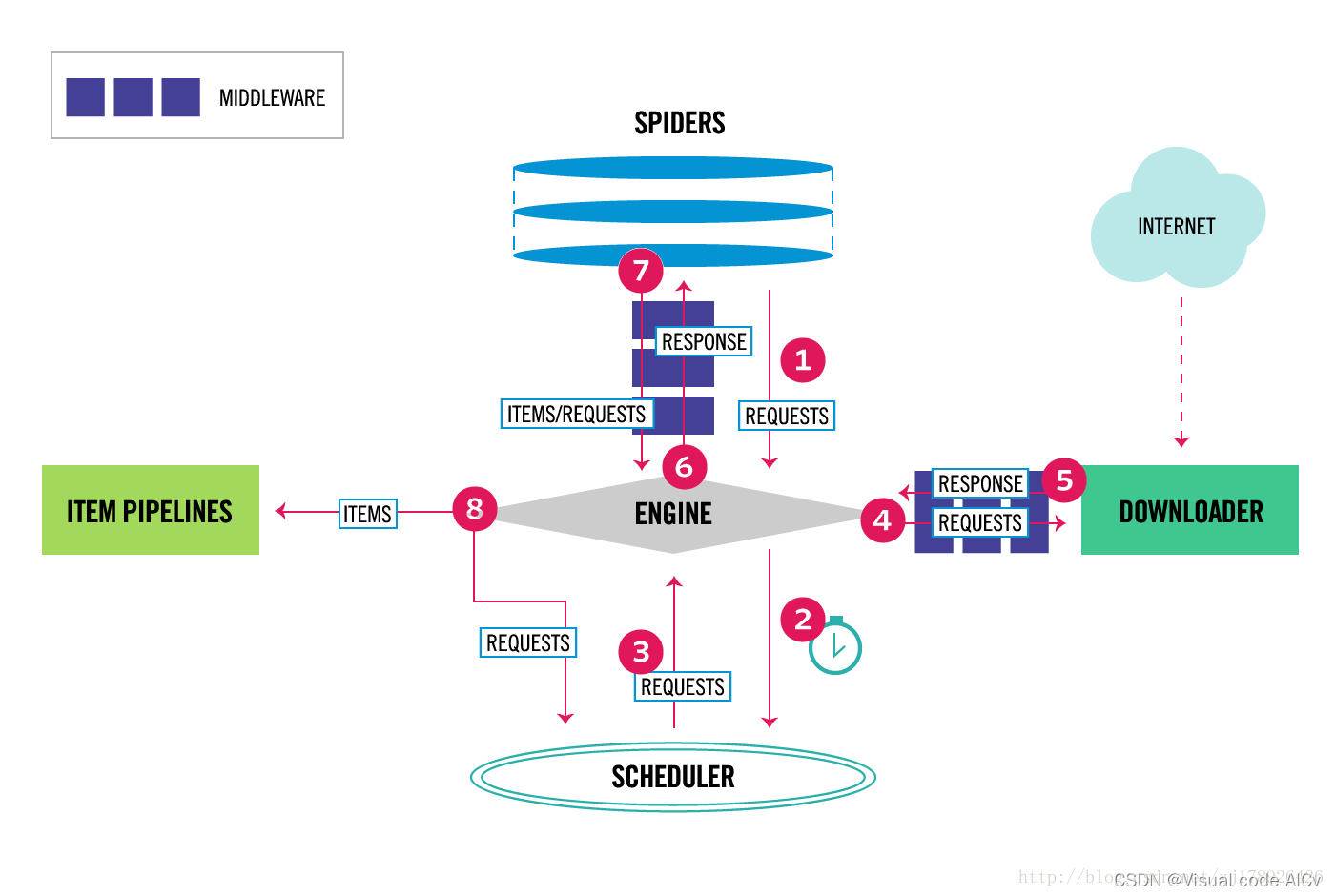
引擎(Engine):负责控制整个爬虫的流程,包括调度请求、处理请求和响应等。
-
调度器(Scheduler):负责接收引擎发送的请求,并将其按照一定的策略进行调度,生成待下载的请求。
-
下载器(Downloader):负责下载请求对应的网页,可以使用多种下载器,例如基于Twisted的异步下载器和基于requests的同步下载器。
-
中间件(Middleware):负责对请求和响应进行预处理和后处理,可以用于添加请求头、处理cookies等操作。
-
爬虫(Spider):负责定义如何解析网页和提取数据的规则,包括起始URL、请求构造、响应解析和数据提取等。
-
项目管道(Item Pipeline):负责处理爬虫从网页中提取的数据,并进行后续的处理,例如数据清洗、数据存储等。
数据处理流程:
-
引擎从爬虫中获取起始URL,并生成对应的请求。
-
引擎将请求发送到调度器,调度器将获取到的URL存储在队列中,按照一定的策略进行调度,并生成待下载的请求。
-
引擎从调度器中获取接下来需要爬取的页面。
-
引擎将待下载的请求通过下载中间件发送到下载器。
-
下载器下载网页,并将响应返回给引擎。
-
引擎将响应通过爬虫中间件发送给爬虫,爬虫根据定义的规则对响应进行解析,并提取出需要的数据。
-
爬虫将提取的数据发送给项目管道,项目管道对数据进行处理,并进行后续的存储或其他操作。
-
引擎根据配置的规则继续生成新的请求,并重复上述步骤,直到没有新的请求或达到指定的停止条件。
下面是Scrapy框架的运行流程
二、基本使用方法
2.1 创建&管理Scrapy项目
2.1.1 Scrapy命令行
Scrapy自带一套命令行工具用于管理和运行Scrapy项目。
-
创建一个新的Scrapy项目:
scrapy startproject <project_name> -
在项目中创建一个新的Spider:
scrapy genspider <spider_name> <website_url> -
运行Spider并将结果保存为JSON或其他格式:
scrapy crawl <spider> -o <output_file>.json -
列出可用的Spider:
scrapy list -
检查Spider是否正确工作:
scrapy check <spider_name> -
运行Scrapy Shell来交互式地测试和调试Spider:
scrapy shell <website_url> -
查看Scrapy信息:
scrapy version
2.1.2 Pycharm
创建Scrapy项目:
1. 在Pycharm中创建一个“纯python”项目
注:demo1是项目名
2.在pycharm内使用命令行工具创建Scrapy项目
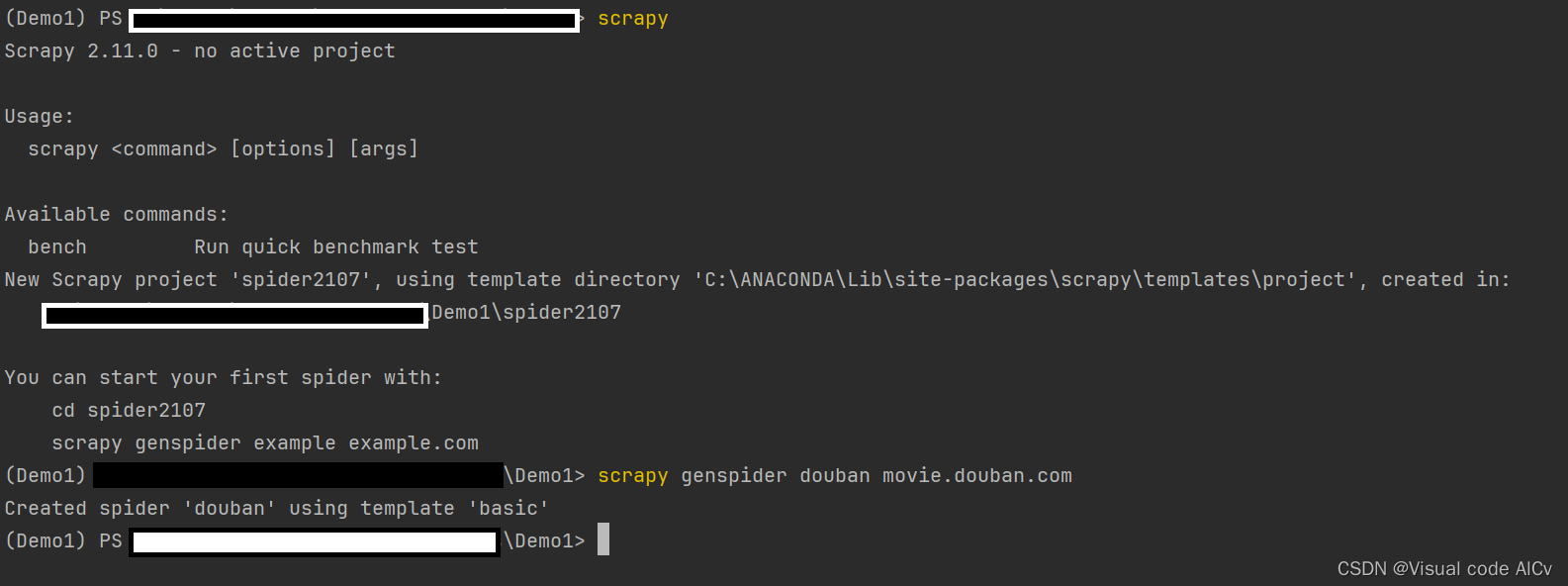
创建spider程序的命令行
scrapy genspider douban movie.douban.com
# douban为爬虫名称
# movie.douban.com为爬虫的作用域创建的目录
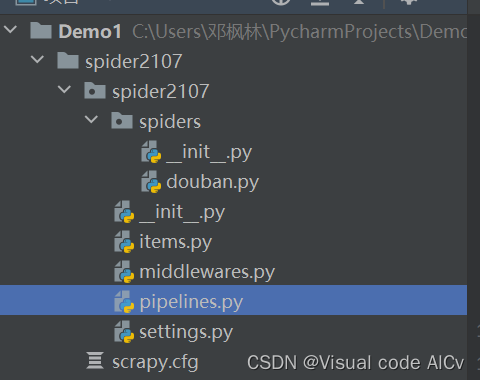
这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- spider2107/: 项目的Python模块,将会从这里引用代码。
- spider2107/items.py: 项目的目标文件。
- spider2107/pipelines.py: 项目的管道文件。
- spider2107/settings.py: 项目的设置文件。
- spider2107/spiders: 存储爬虫代码目录。
新建虚拟环境:
文件 ——>设置项目设置 ——>新项目的设置
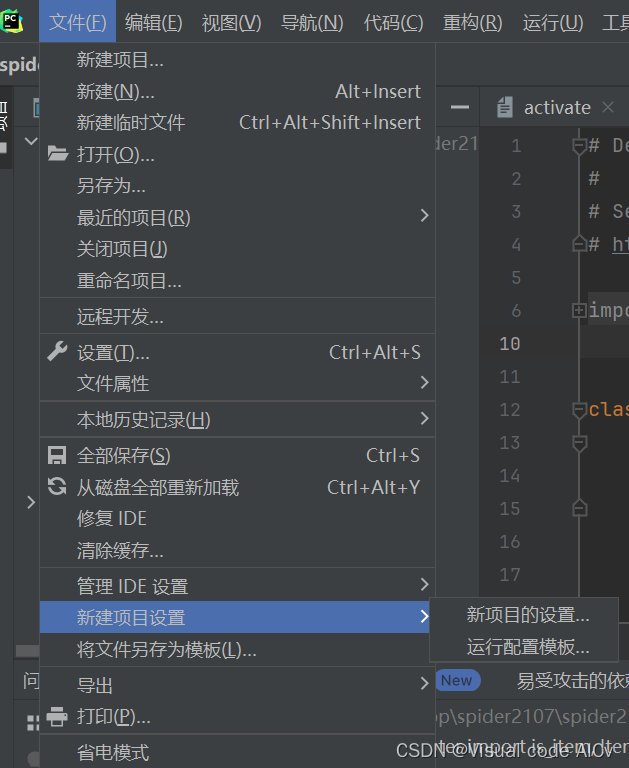
选择python解释器 ——>添加解释器 ——>Virtualenv环境 ——>在项目文件夹下添加envs (虚拟环境)——>确定
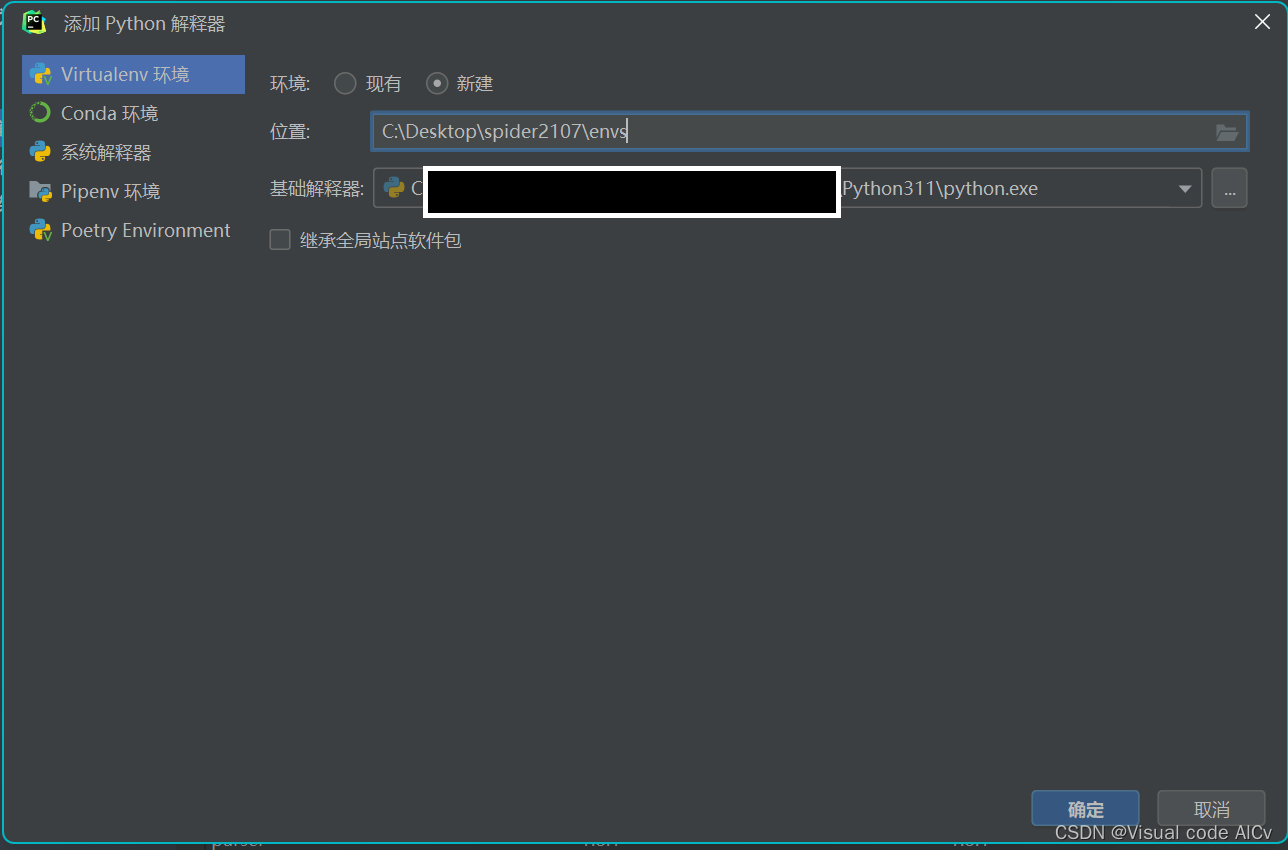
激活虚拟环境(Virtualenv环境)
env\Script\activate注:如果显示无法加载模块,可以先等一段时间,当pycharm新建索引到env文件夹时在运行这段命令
在pycharm中打开终端
使用pip下载scrapy
pip install scrapy创建spider程序
scrapy genspider <spidername><domain>写好程序后会scrapy会出现一个crawl的执行选项可用于执行spider
scrapy crawl <spidername>相关文章:
Python-Scrapy框架(框架学习)
一、概述 Scrapy是一个用于爬取网站数据的Python框架,可以用来抓取web站点并从页面中提取结构化的数据。 基本组件: 引擎(Engine):负责控制整个爬虫的流程,包括调度请求、处理请求和响应等。 调度器(Scheduler):负责…...

flink生成水位线记录方式--基于特殊记录的水位线生成器
背景 在flink基于事件的时间处理中,水位线记录的生成是一个很重要的环节,本文就来记录下几种水位线记录的生成方式的其中一种:基于特殊记录的水位线生成器 基于特殊记录的水位线生成器 我们发送的事件中,如果带有某条特殊记录的…...

Arcgis日常天坑问题(1)——将Revit模型转为slpk数据卡住不前
这段时间碰到这么一个问题,revit模型在arcgis pro里导出slpk的时候,卡在98%一直不动,大约有两个小时。 首先想到的是revit模型过大,接近300M。然后各种减小模型测试,还是一样的问题,大概花了两天的时间&am…...
JavaWeb:上传文件
1.建普通maven项目,或者maven项目,这里以普通maven为例,区别的jar包的导入方式啦 到中央仓库下载哦 2.结构 3.写fileservlet public class FileServlet extends HttpServlet {Overrideprotected void doPost(HttpServletRequest req, HttpSe…...

STM32 大小端与字节对齐使用记录
大小端 串口数据包解析 MDK stm32 小段模式 接收到的数据包: DD 03 00 1B 11 59 00 00 00 00 17 70 00 00 2F 39 00 00 00 00 00 03 23 64 00 0E 02 0B 6E 0B 84 FC EA 77 其中数据内容为: DD 03 00 1B 11 59 //电压mV 00 00 00 00 17 70 …...

RabbitMQ中basic**方法汇总与参数解释
当使用RabbitMQ进行消息传递时,Channel对象提供了一组称为"basic方法"的方法,用于执行最基本的消息传递操作。在本篇博客中,我们将详细介绍这些方法,包括示例和参数解释。 1. basicPublish 方法 basicPublish 方法用于…...

linux之/etc/default/useradd文件
/etc/default/useradd文件是在使用useradd添加用户时,一个需要调用的默认的配置文件之一,可以使用命令"useradd -D"进行修改。 useradd用法: [rootcentos79-3 mail]# useradd --help Usage: useradd [options] LOGINuseradd -Dus…...

3.primitive主数据类型和引用 认识变量
3.1 声明变量 Java注重类型。它不会让你做出把长颈鹿类型变量装进兔子类型变量中这种诡异又危险的举动——如果有人对长颈鹿调用“跳跃”这个方法会发生什么样的悲剧?并且它也不会让你将浮点数类型变量放进整数类型的变量中,除非你先跟编译器确认过数字…...

【群智能算法改进】一种改进的光学显微镜算法 IOMA算法[1]【Matlab代码#60】
文章目录 【获取资源请见文章第5节:资源获取】1. 光学显微镜算法(OMA)1.1 物镜放大倍数1.2 目镜放大倍数 2. 改进后的IOMA算法2.1 透镜成像折射方向学习 3. 部分代码展示4. 仿真结果展示5. 资源获取说明 【获取资源请见文章第5节:…...
第三课-软件升级-Stable Diffusion教程
前言: 虽然第二课已经安装好了 SD,但你可能在其它地方课程中,会发现很多人用的和你的界面差距很大。这篇文章会讲一些容易忽略或者常常需要做的操作,不一定要完全照做,以后再回过头看看也可以。 1.控制类型 问题:为什么别人有“控制类型”部分,而我没有?如下红色方框…...

【C++】设计模式之——建造者
建造者模式概念模拟实现建造者模式代码实现 建造者模式 首先先大体了解一下,建造者模式是什么意思,它是怎么实现的? 首先,建造者模式是一种创建型设计模式再一个它是使用多个简单的对象一步一步的搭建出一个复杂的对象它可以将一个…...
)
【C++】基础语句(学习笔记)
一、分支 1、三种基本结构 顺序结构分支结构循环结构 2、if与switch对比 1)使用场景 switch只支持常量值固定相等的分支判断if可以判断区间范围用switch能做的,用if都能做 2)性能比较 分支少时,差别不是很大。分支多时&…...

大厂秋招真题【DP】米哈游20230924秋招T2-米小游与魔法少女-奇运
米哈游20230924秋招T2-米小游与魔法少女-奇运 题目描述与示例 题目描述 米小游都快保底了还没抽到希儿,好生气哦!只能打会活动再拿点水晶。 米小游和世界第一可爱的魔法少女 TeRiRi 正在打 BOSS,BOSS 的血量为h,当 BOSS 血量小…...
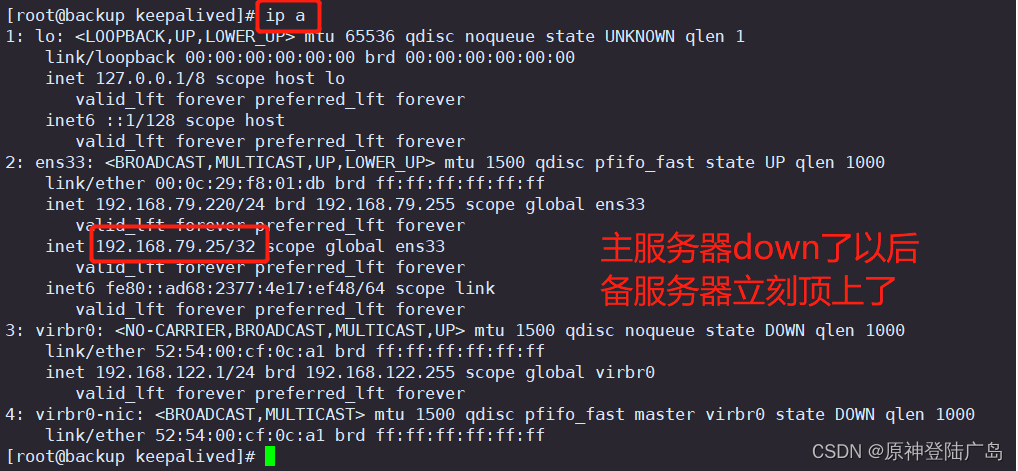
LVS+Keepalived 高可用集群负载均衡
一.keepalived介绍 1.1.Keepalived实现原理 由多台路由器组成一个热备组,通过共用的虚拟IP地址对外提供服务。 每个热备组内同时只有一台主路由器提供服务,其他路由器处于冗余状态。 若当前在线的路由器失效,则其他路由器会根据设置…...

Qt QList类和QLinkedList类 详解
一、QList 类 对于不同的数据类型,QList<T>采取不同的存储策略,存储策略如下: 如果T 是一个指针类型或指针大小的基本类型(该基本类型占有的字节数和指针类型占有的字节数相同),QList<T>将数值直接存储在它的数组当…...

Mac安装GYM遇到的一些坑
以下是遇到的一些问题 安装GitHub上说的直接 pip install gym成功了,但是运行实例报错没安装gym[classic_control],所以就全安装一下[all] 安装GitHub上说的直接 pip install gym成功了,但是运行实例报错没安装gym[classic_control]ÿ…...
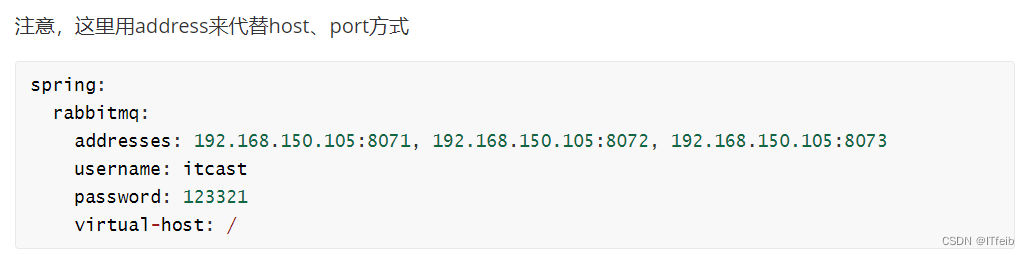
【高级rabbitmq】
文章目录 1. 消息丢失问题1.1 发送者消息丢失1.2 MQ消息丢失1.3 消费者消息丢失1.3.1 消费失败重试机制 总结 2. 死信交换机2.1 TTL 3. 惰性队列3.1 总结: 4. MQ集群 消息队列在使用过程中,面临着很多实际问题需要思考: 1. 消息丢失问题 1.1…...
数百个下载能够传播 Rootkit 的恶意 NPM 软件包
供应链安全公司 ReversingLabs 警告称,最近观察到的一次恶意活动依靠拼写错误来诱骗用户下载恶意 NPM 软件包,该软件包会通过 rootkit 感染他们的系统。 该恶意软件包名为“node-hide-console-windows”,旨在模仿 NPM 存储库上合法的“node-…...

SpringBoot的error用全局异常去处理
记录一下使用SpringBoot2.0.5的error用全局异常去处理 在使用springboot时,当访问的http地址或者说是请求地址输错后,会返回一个页面,如下: 这是因为请求的地址不存在,默认会显示error页面 但我们实际需要一个接口&a…...
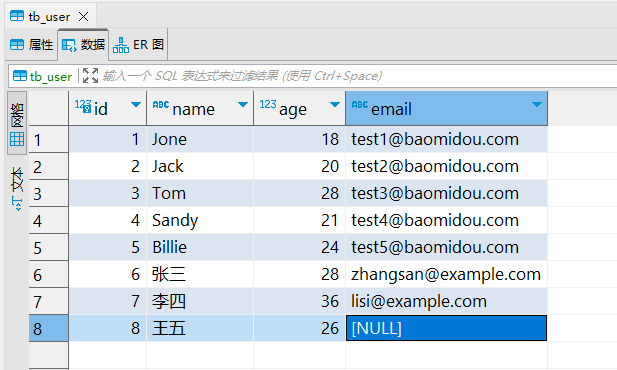
MyBatisPlus(十一)包含查询:in
说明 包含查询,对应SQL语句中的 in 语句,查询参数包含在入参列表之内的数据。 in Testvoid inNonEmptyList() {// 非空列表,作为参数List<Integer> ages Stream.of(18, 20, 22).collect(Collectors.toList());in(ages);}Testvoid in…...

运动分析革命:如何用Kinovea将视频变成精准的教练和研究员
运动分析革命:如何用Kinovea将视频变成精准的教练和研究员 【免费下载链接】Kinovea Video solution for sport analysis. Capture, inspect, compare, annotate and measure technical performances. 项目地址: https://gitcode.com/gh_mirrors/ki/Kinovea …...

半导体行业数据解析:销售额与资本支出双高增长背后的逻辑
1. 行业数据深度解析:半导体销售额与资本支出的双高增长最近和几个在晶圆厂和设计公司工作的朋友聊天,大家不约而同地提到了一个词:“忙疯了”。订单排到明年,产线24小时连轴转,连带着上游的设备商和材料供应商都跟着“…...

在Serv00共享主机上部署SOCKS5代理:原理、部署与优化指南
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的自托管服务时,遇到了一个经典难题:如何在资源受限的共享主机环境里,搭建一个轻量、稳定且可控的网络代理通道。这让我想起了之前在社区里看到的一个项目——cmliu/socks5-for-serv00。…...

3种方法快速激活Beyond Compare 5:完整密钥生成实战指南
3种方法快速激活Beyond Compare 5:完整密钥生成实战指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5是一款功能强大的专业文件对比工具,但30天评估期…...

DeepSeek总结的DwarfStar 4:专为 DeepSeek V4 Flash 设计的小型原生推理引擎
来源:https://github.com/antirez/ds4 DwarfStar 4 DwarfStar 4 是一个为 DeepSeek V4 Flash 设计的小型原生推理引擎。它是有意限定了范围的:不是通用的 GGUF 运行器,不是其他运行时的封装器,也不是一个框架。其主要路径是一个…...

Flow区块链开发:用AI规则库提升Cadence智能合约与FCL前端开发效率
1. 项目概述与核心价值 如果你正在Flow区块链上用Cadence语言开发智能合约,并且恰好也在用Cursor这样的AI辅助编程工具,那你可能和我一样,经历过一个有点“分裂”的阶段。一方面,Cadence作为一门资源导向型语言,其独特…...
多目标跟踪(Multi-Object Tracking, MOT)中的核心算法介绍:卡尔曼滤波算法和匈牙利算法
卡尔曼滤波算法和匈牙利算法两者都是多目标跟踪(Multi-Object Tracking, MOT)中的核心算法,但解决的是完全不同的问题。简单来说: 卡尔曼滤波:负责“预测未来”和“修正当前”。它帮你推测目标下一刻会出现在哪里。匈…...

【Perplexity引用格式设置终极指南】:20年科研老炮亲授5大避坑法则,90%用户都设错了!
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用格式设置的核心价值与认知重构 Perplexity 作为衡量语言模型预测能力的关键指标,其引用格式的规范性直接影响评估结果的可比性、复现性与学术严谨性。当研究者在论文、技术报…...
)
避开这3个坑,你的MAX30102心率数据才更准(Arduino实测经验分享)
避开这3个坑,你的MAX30102心率数据才更准(Arduino实测经验分享) 当你在健康监测或可穿戴设备项目中使用MAX30102传感器时,是否遇到过心率数据忽高忽低、稳定性差的问题?这很可能不是传感器本身的问题,而是你…...

通达信缠论插件:从复杂理论到直观可视化的技术革命
通达信缠论插件:从复杂理论到直观可视化的技术革命 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 你是否曾被缠论的复杂图表和抽象概念困扰?是否在手工画线分析中耗费大量时间却…...