【MySQL】事务管理
目录
MySQL事务管理
事务的概念
事务的版本支持
事务的提交方式
事务的相关演示
事务的隔离级别
查看与设置隔离级别
读未提交(Read Uncommitted)
读提交(Read Committed)
可重复读(Repeatable Read)
串行化(Serializable)
隔离级别总结
关于一致性
多版本并发控制
记录中的3个隐藏字段
undo日志
快照的概念
Read View
RR与RC的本质区别
MySQL事务管理
事务的概念
事务的概念
- 事务由一条或多条SQL语句组成,这些语句在逻辑上存在相关性,共同完成一个任务,事务主要用于处理操作量大,复杂度高的数据。比如转账就涉及多条说SQL语句,包括查询余额(select)、在当前账户上减去指定金额(update)、在指定账户上加上对应金额(update)等,将这多条SQL语句打包便构成了一个事务。
- MySQL同一时刻可能存在大量事务,如果不对这些事务加以控制,在执行时就可能会出现问题。比如单个事务内部的某些SQL语句执行失败,或是多个事务同时访问同一份数据导致数据不一致的问题。
因此一个完整的事务并不是简单的SQL集合,事务还需要满足如下四个属性:
- 原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中如果发生错误,则会自动回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
- 隔离性:数据库允许多个事务同时访问同一份数据,隔离性可以保证多个事务在并发执行时,不会因为由于交叉执行而导致数据的不一致,
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏,这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联型以及后续数据可以自发性地完成预定的工作。
上面的四个属性简称ACID:
- 原子性(Atomicity,又称不可分割性)。
- 一致性(Consistency)。
- 隔离性(Isolation,又称独立性)。
- 持久性(Durability)。
为什么会出现事务?
- 事务被MySQL编写者设计出来,本质是为了当前应用程序访问数据库的时候,事务能够简化我们的编程模型,不需要用户自己去考虑各种各样潜在的错误和并发问题。
- 如果MySQL只是单纯的提供数据存储服务,那么用户在访问数据库时就需要自行考虑各种潜在问题,包括网络异常、服务器宕机等。因此事务本质是为了应用服务的,而不是伴随着数据库系统天生就有的。
事务的版本支持
事务的版本支持
通过show engines命令可以查看数据库引擎。如下

说明一下:
- Engine: 表示存储引擎的名称。
- Support: 表示服务器对存储引擎的支持级别,YES表示支持,NO表示不支持,DEFAULT表示数据库默认使用的存储引擎,DISABLED表示支持引擎但已将其禁用。
- Comment: 表示存储引擎的简要说明。
- Transactions: 表示存储引擎是否支持事务,可以看到InnoDB存储引擎支持事务,而MyISAM存储引擎不支持事务。
- XA: 表示存储引擎是否支持XA事务。
- Savepoints: 表示存储引擎是否支持保存点。
事务的提交方式
查看事务的提交方式
事务常见的提交方式有两种,分别是自动提交和手动提交。
通过show命令查看autocommit全局变量,可以查看事务的自动提交是否被打开。如下:
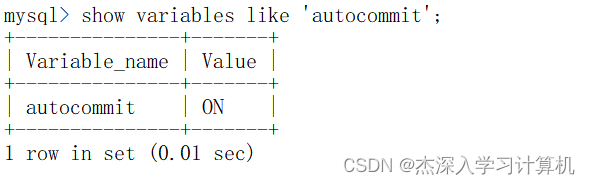
说明一下: autocommit的值为ON表示自动提交被打开,值为OFF表示自动提交被关闭,即事务的提交方式为手动提交。
设置事务的提交方式
通过set命令设置autocommit全局变量的值,可以打开或关闭事务的自动提交。如下:
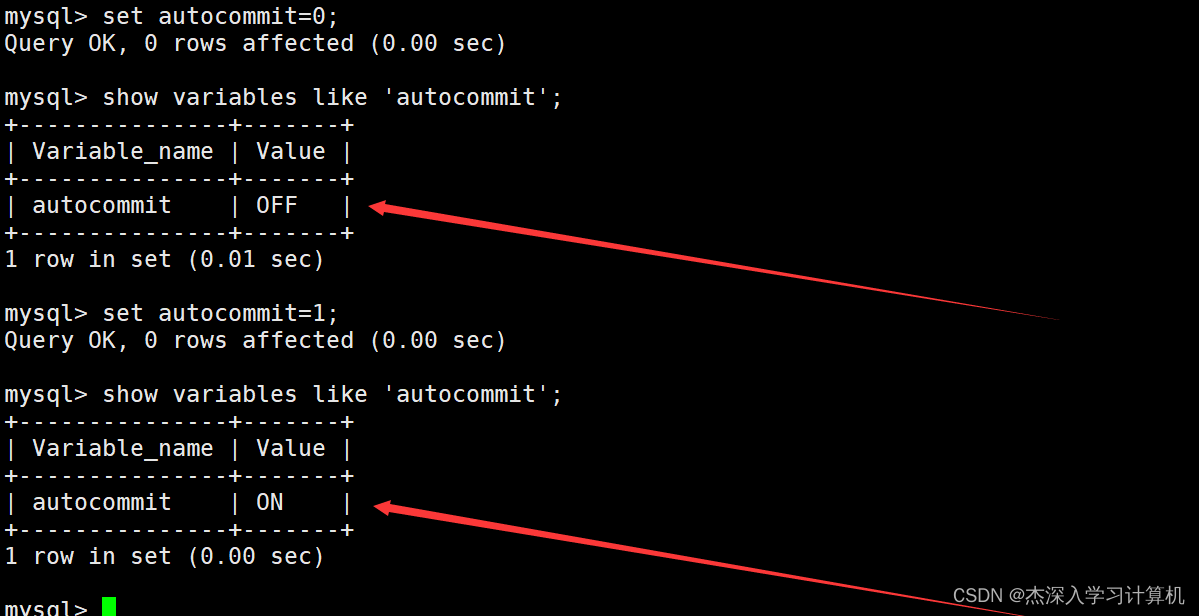
说明一下: 将autocommit的值设置为1表示打开自动提交,设置为0表示关闭自动提交,相当于将事务提交方式设置为手动提交。
事务的相关演示
准备测试表
为了便于演示,我们将MySQL的隔离级别设置成读未提交,也就是把隔离级别设置的比较低,方便看到实验现象。如下:

需要注意的是,设置全局隔离级别后当前会话的隔离级别不会改变,只会影响后续与MySQL新建立的连接,因此需要重启终端才能看到会话的隔离级别被成功设置。如下:
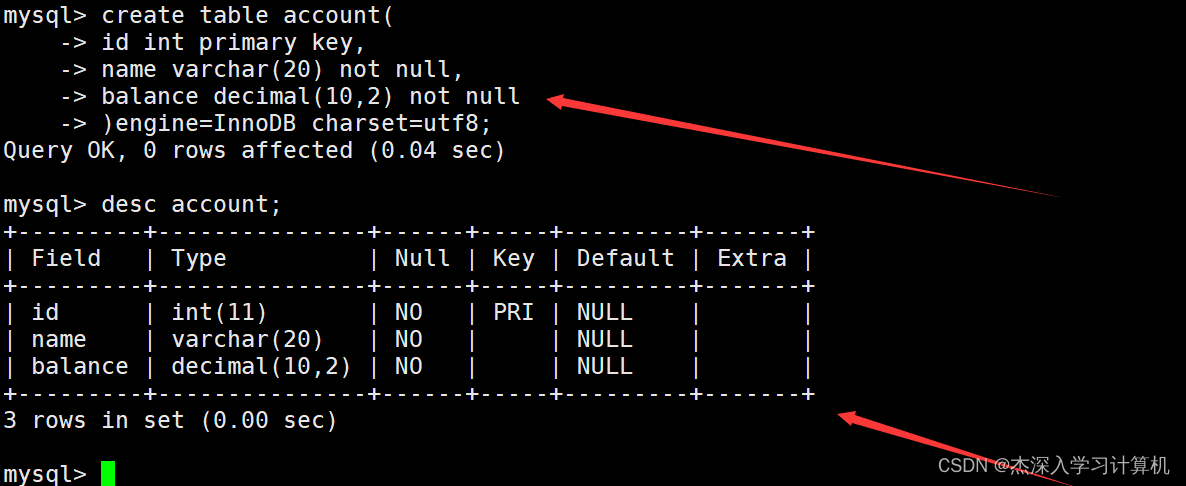
创建一个银行用户表,表中包含用户的id、姓名和账户余额。如下:
演示一:事务的常规操作
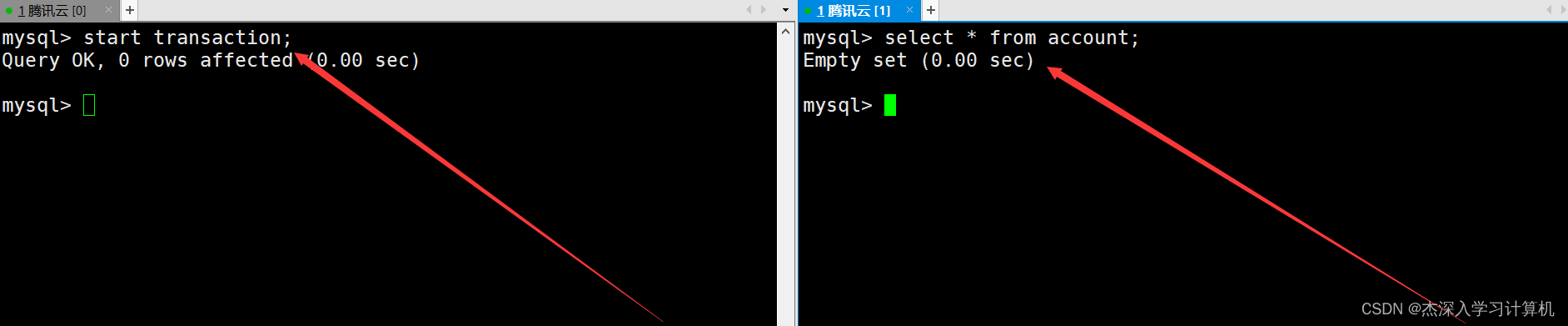
启动两个终端,左终端使用begin或start transaction命令启动一个事务,右终端查看银行用户表中的信息。如下:
左终端中的事务向表中插入一条记录,由于我们将隔离级别设置成了读未提交,因此在左终端中的事务使用commit提交之前,在右终端中就能查看到事务向表中插入的记录。如下:
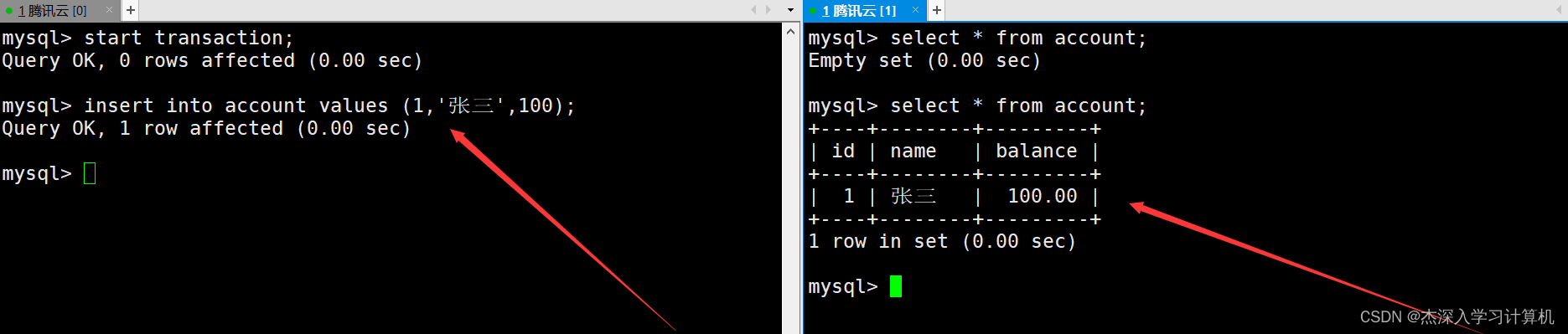
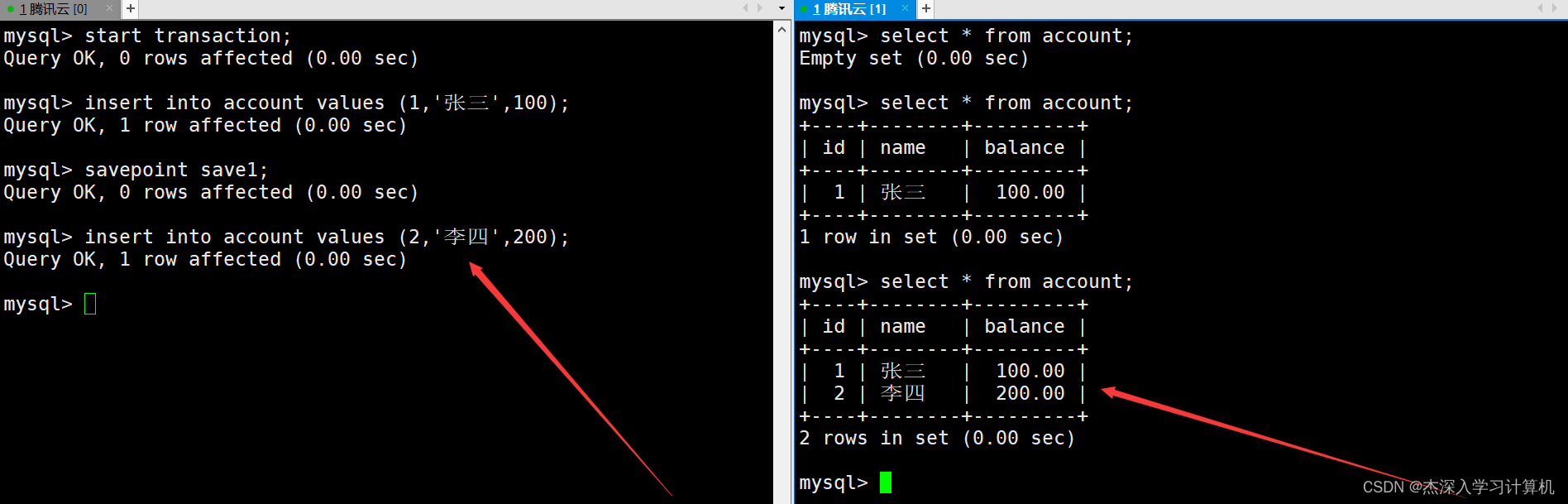
左终端中的事务使用savepoint命令创建一个保存点,然后继续向表中插入一条记录,这时在右终端中也能看到新插入的这条记录。如下:
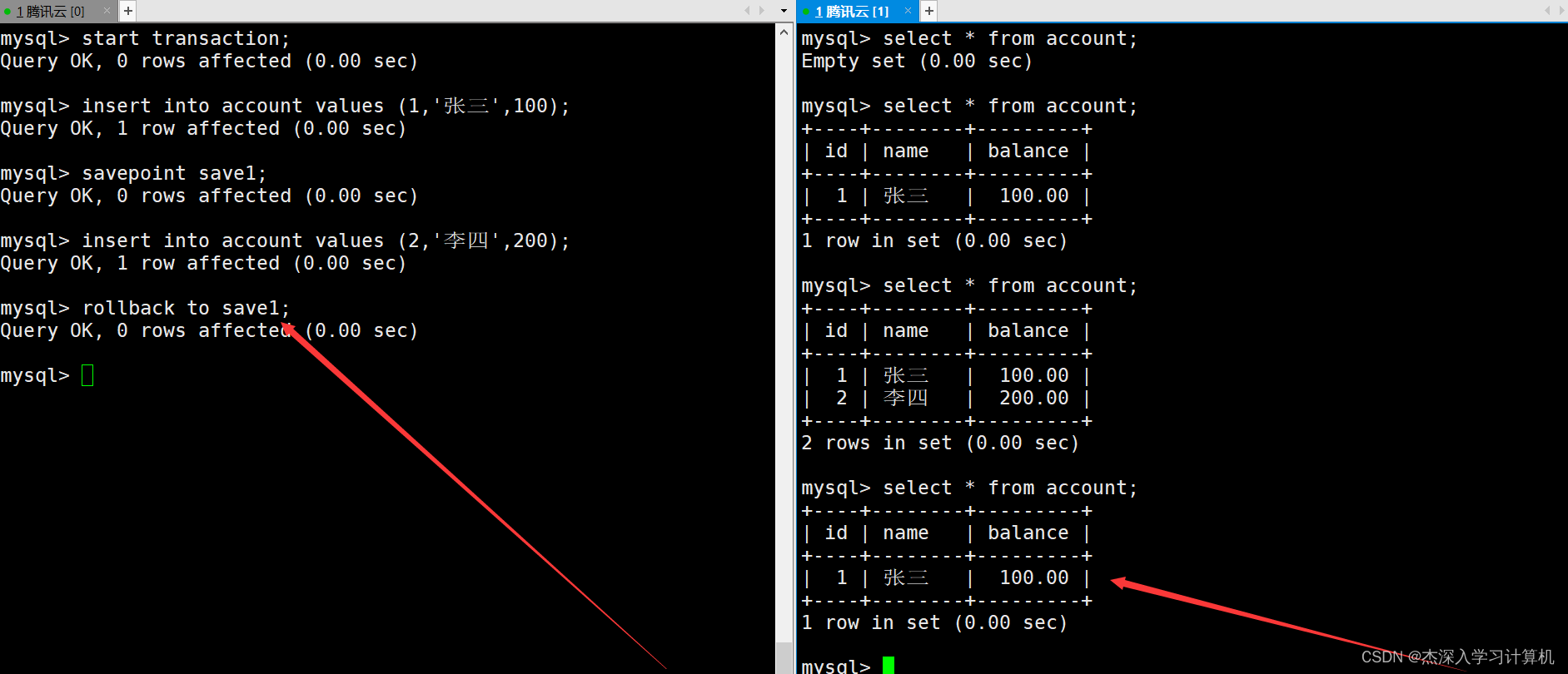
左终端中的事务使用rollback命令回滚到保存点,这时右终端在查看表中数据时就看不到刚才插入的第二条记录了。如下:
左终端中的事务使用rollback命令回滚到事务最开始,这时右终端在查看表中数据时就看不到任何记录了。如下: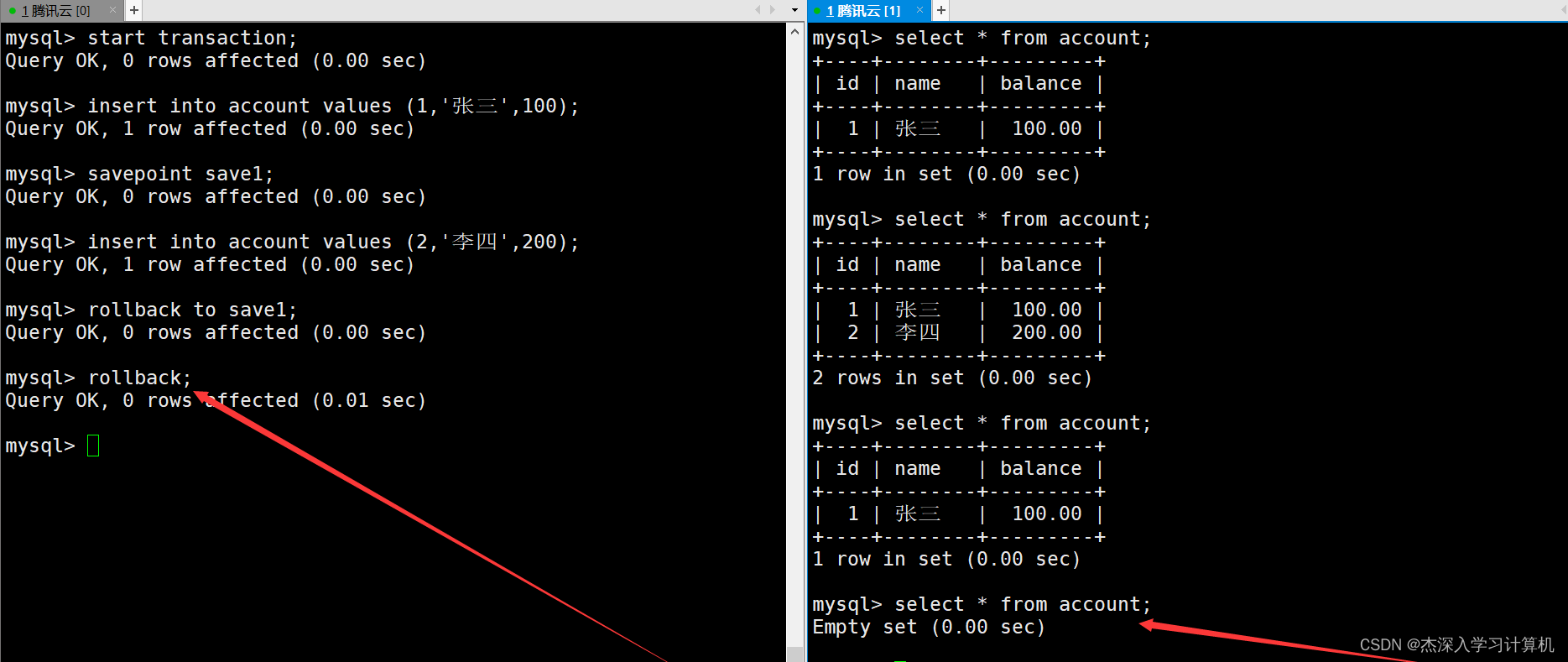
说明一下:
- 使用 begin 或 start transaction 命令,可以启动一个事务;
- 使用 savepoint 保存点 命令,可以在事务中创建指定名称的保存点;
- 使用 rollbacl to 保存点 命令,可以让事务回滚到指定保存点;
- 使用 rollback 命令,可以直接让事务回滚到最开始;
- 使用 commit 命令,可以提交事务,提交事务后就不能回滚了。
演示二:原子性
在左终端中启动一个事务,在右终端查看银行用户表中的信息。如下: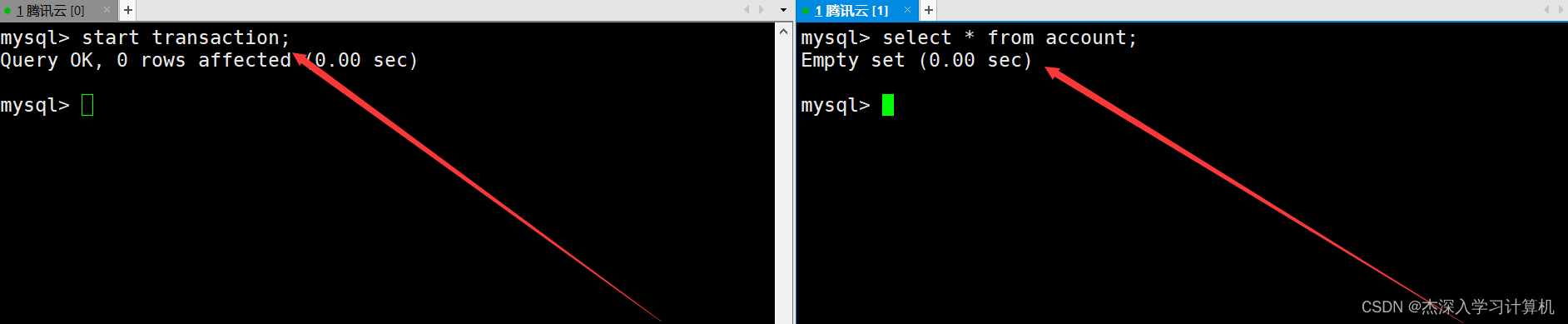
左终端中的事务向表中插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到插入的这条记录。如下: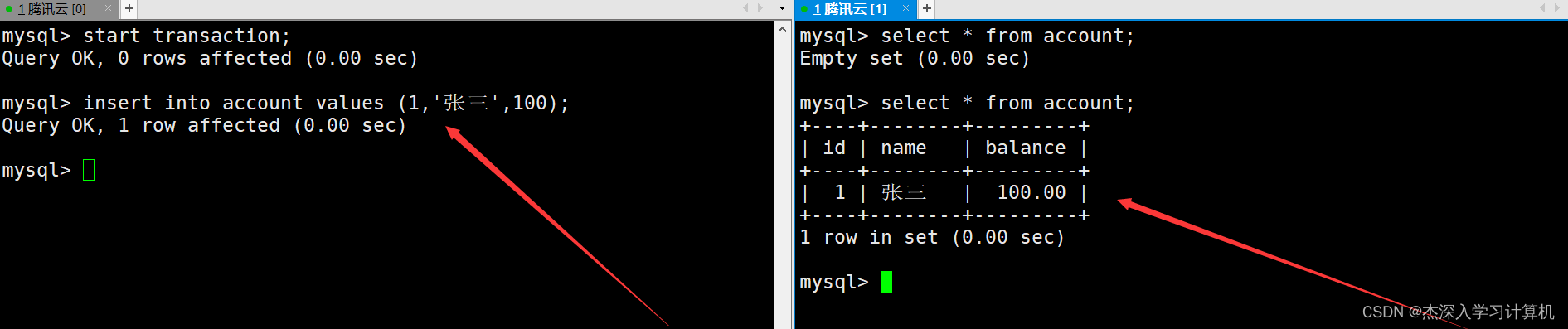
如果左终端中的事务在提交之前因为某些原因与MySQL断开连接,那么MySQL会自动让事务回滚到最开始,这时右终端中就看不到之前插入的记录了。如下: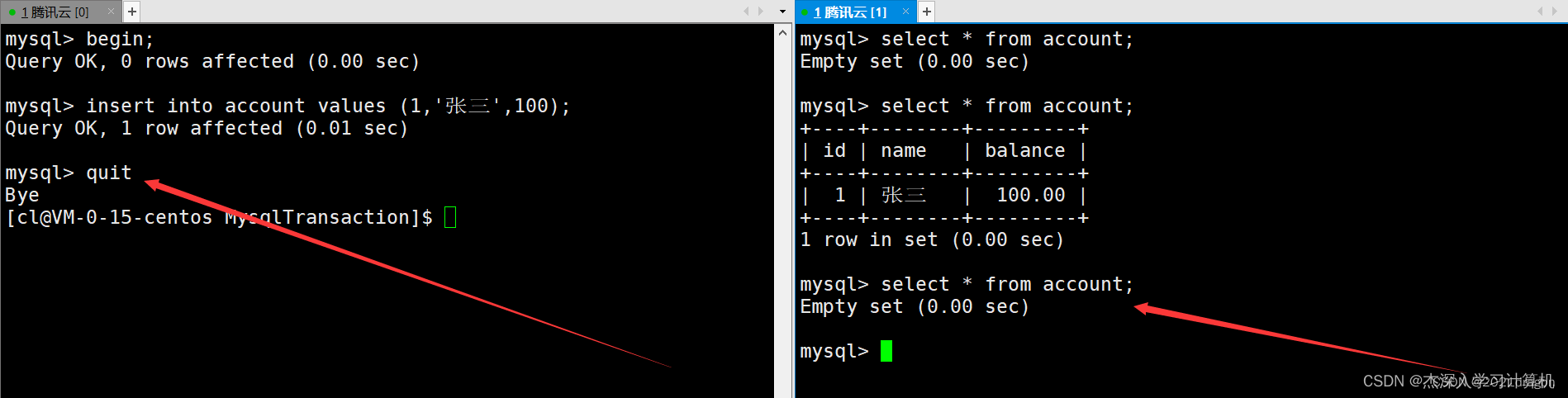
演示三:持久性
在左终端中启动一个事务,在右终端查看银行用户表中的信息。如下: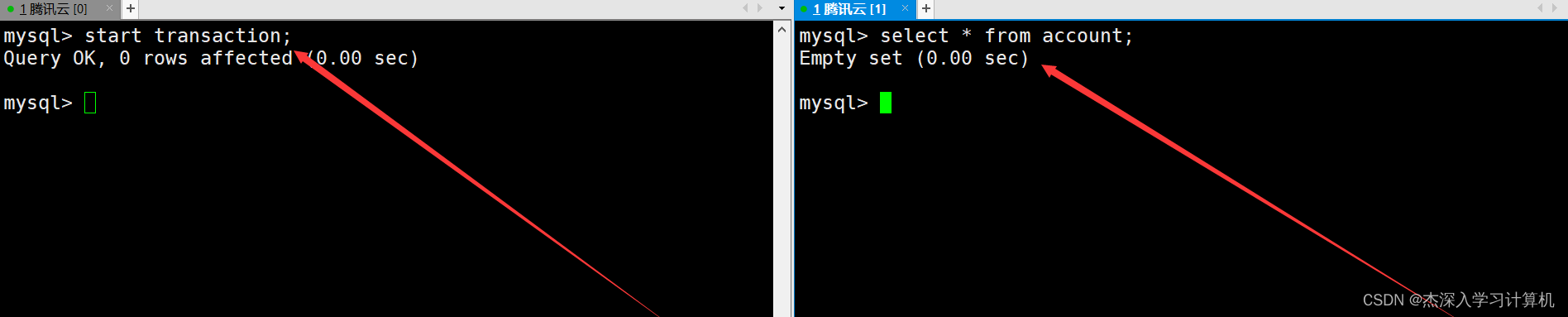
左终端中的事务向表中插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到插入的这条记录。如下: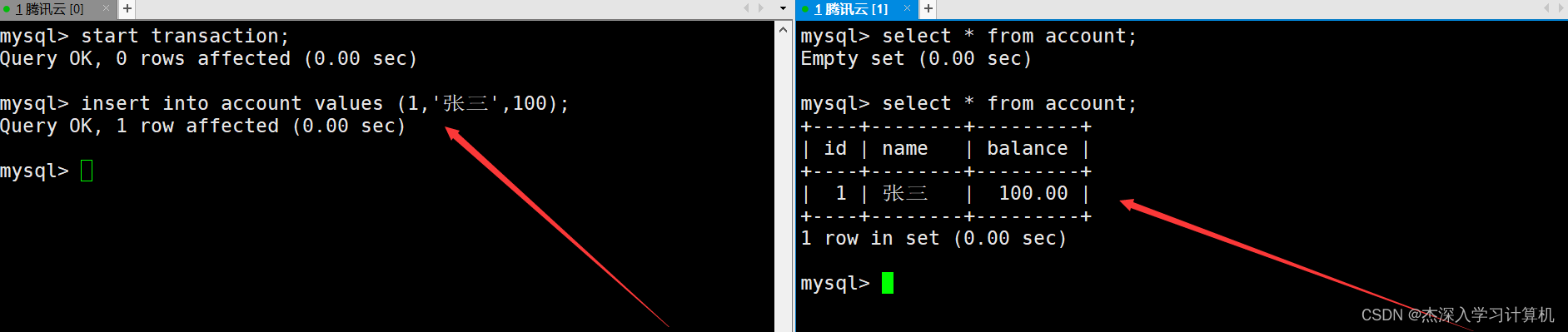
左终端中的事务在提交后与MySQL断开连接,这时右终端中仍然可以看到之前插入的记录,因为事务提交后数据就被持久化了。如下:
演示四:begin会自动更改提交方式
通过show命令查看autocommit的值为ON,表示事务的提交方式是自动提交,此时银行用户表中有一条记录。如下: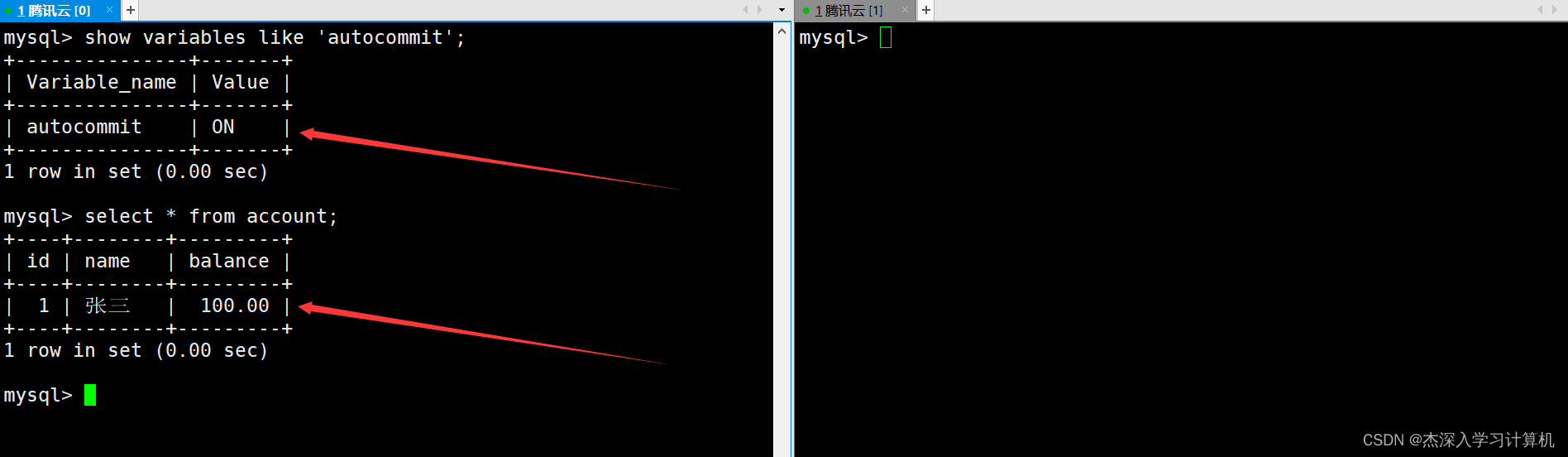
在左终端中启动一个事务并向表中新插入一条记录,由于隔离级别是读未提交,因此在右终端中能够查询到新插入的这条记录。如下:
如果左终端中的事务在提交之前与MySQL断开连接,那么MySQL依旧会自动让事务回滚到最开始,这时右终端中就看不到之前新插入的记录了。如下:
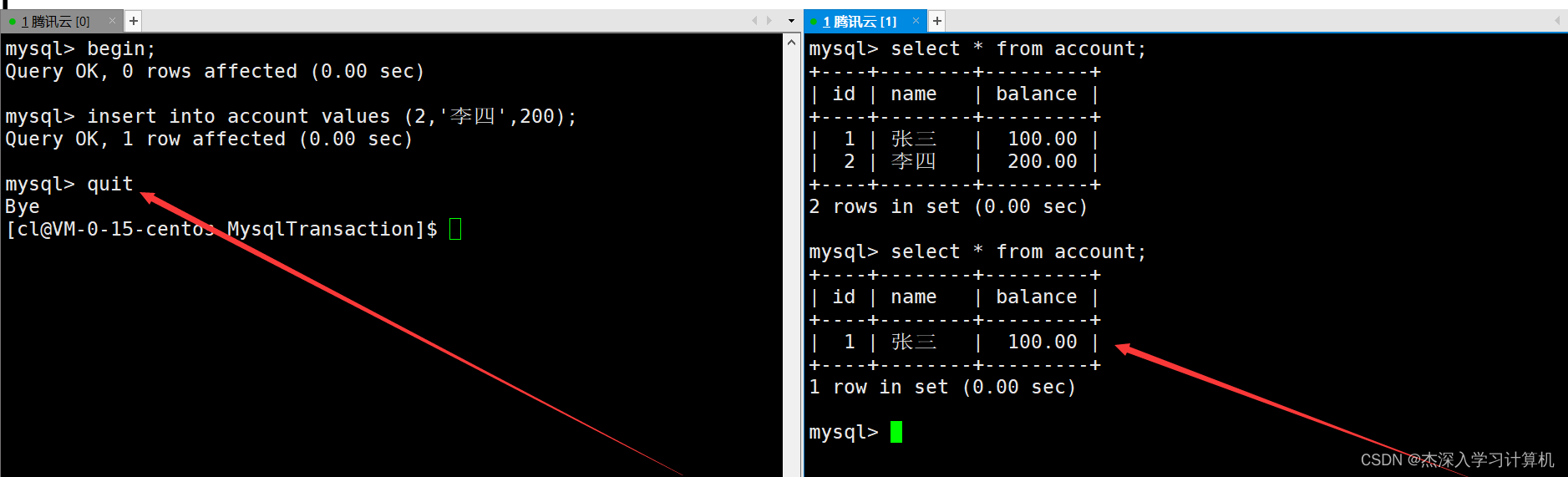
也就是说,使用begin或start transaction命令启动的事务,都必须要使用commit命令手动提交,数据才会被持久化,与是否设置autocommit无关。
演示五:单条SQL与事务的关系
- 实际全局变量autocommit是否被设置影响的是单条SQL语句,InnoDB中的每一条SQL都会默认被封装成事务。
- autocommit为ON,则单条SQL语句执行后会自动被提交,如果为OFF,则SQL语句执行后需要使用commit进行手动提交。
比如通过show命令查看autocommit的值为ON,表示事务的提交方式是自动提交,此时银行用户表中有一条记录。如下: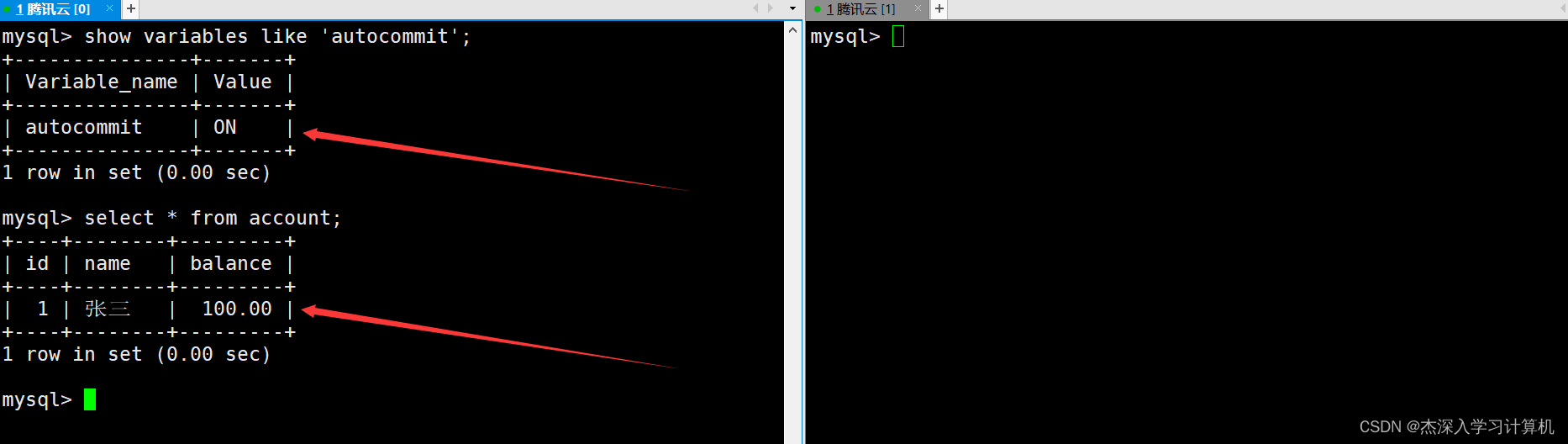
在左终端中直接向表中新插入一条记录,由于隔离级别是读未提交,因此在右终端中肯定能够查询到新插入的这条记录。如下: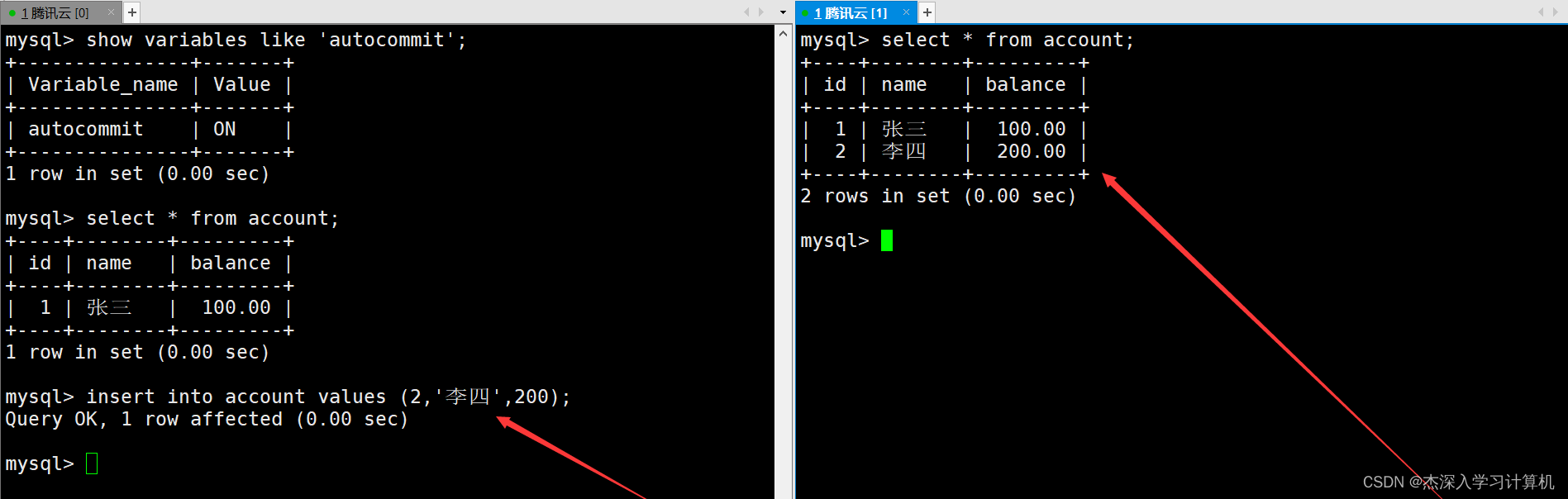
但就算左终端在执行单条SQL后不使用commit进行提交,而直接与MySQL断开连接,这时右终端仍然可以看到之前新插入的记录了,因为单条SQL在执行后被自动提交持久化了。如下: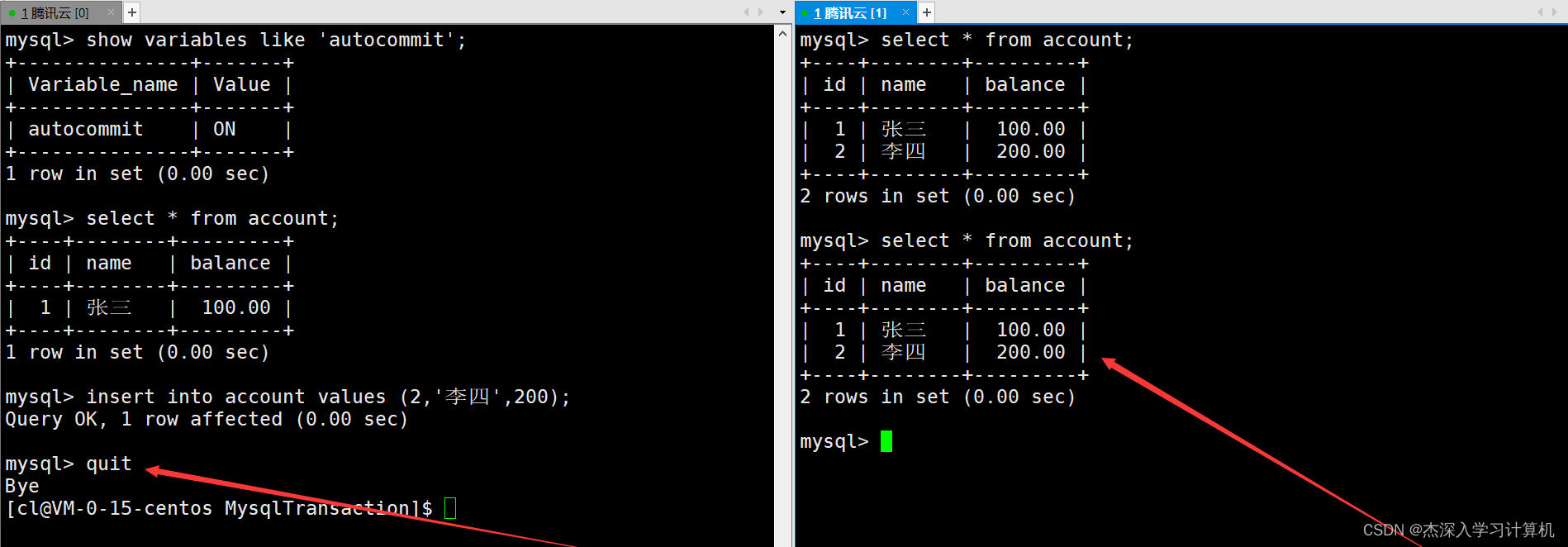
相反,如果将autocommit设置为OFF,表示事务执行后需要手动提交,此时银行用户表中有两条记录。如下: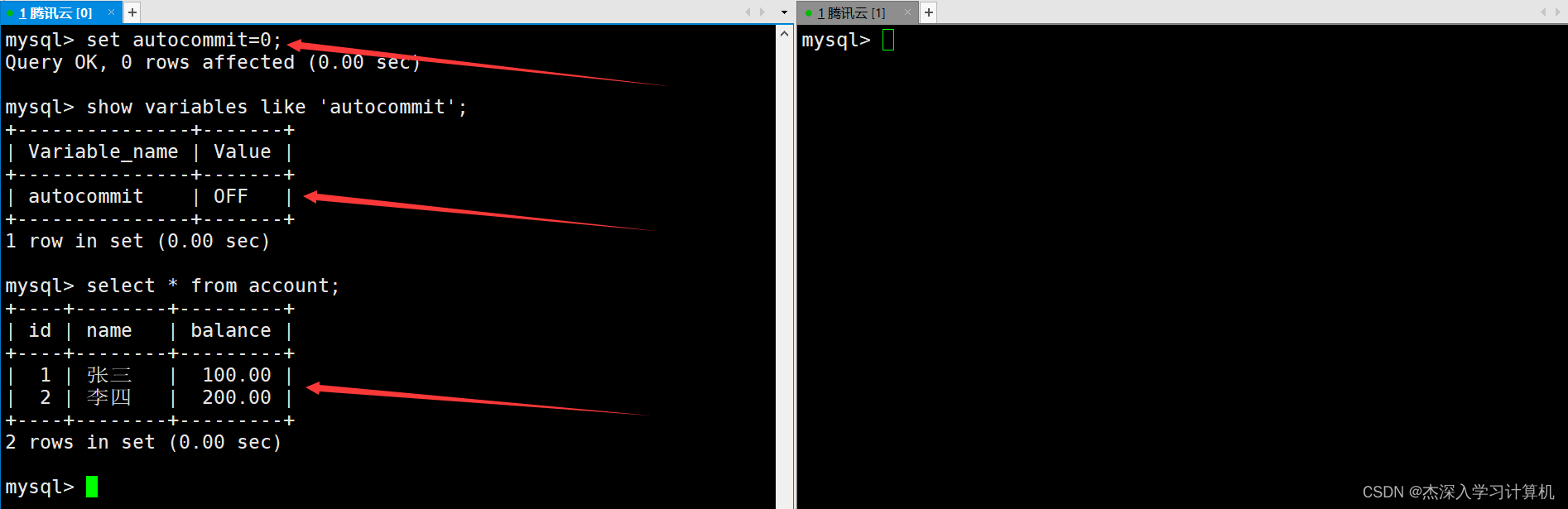
但如果此时左终端在执行单条SQL后不使用commit进行提交,而直接与MySQL断开连接,那么这时右终端中就看不到之前新插入的记录了,因为这时单条SQL执行后需要使用commit手动提交后才会持久化,在commit之前与MySQL断开连接则会自动进行回滚操作。如下: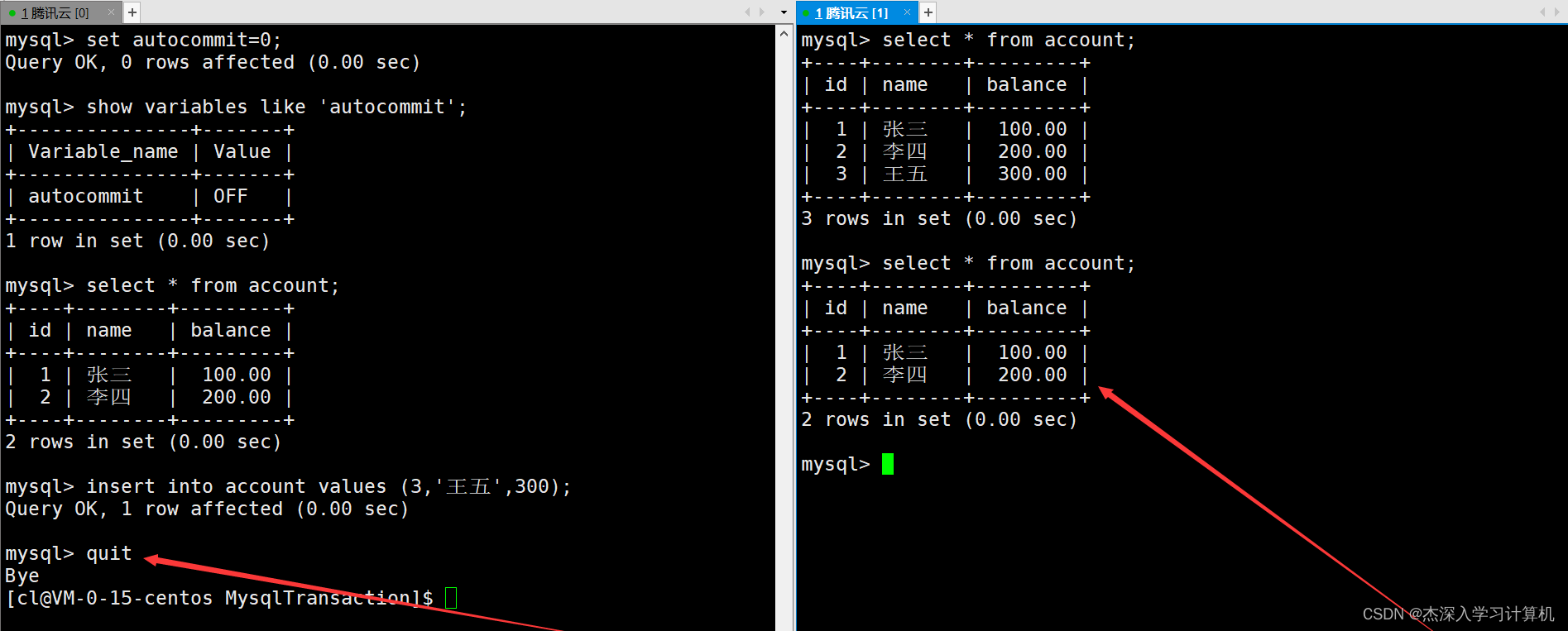
也就是说,实际我们之前一直都在使用单SQL事务,只不过autocommit默认是打开的,因此单SQL事务执行后自动就被提交了。
事务的隔离级别
- MySQL服务可能会同时被多个客户端进程(线程)访问,访问的方式以事务的方式进行。
- 一个事务可能由多条SQL语句构成,也就意味着任何一个事务,都有执行前、执行中和执行后三个阶段,而所谓的原子性就是让用户层要么看到执行前,要么看到执行后,执行中如果出现问题,可以随时进行回滚,所以单个事务对用户表现出来的特性就是原子性。
- 但毕竟每个事务都有一个执行的过程,在多个事务各自执行自己的多条SQL时,仍然可能会出现互相影响的情况,比如多个事务同时访问同一张表,甚至是表中的同一条记录。
- 数据库为了保证事务执行过程中尽量不受干扰,于是出现了隔离性的概念,而数据库为了允许事务在执行过程中受到不同程度的干扰,于是出现了隔离级别的概念。
数据库事务的隔离级别有以下四种:
- 读未提交(Read Uncommitted):在该隔离级别下,所有的事务都可以看到其他事务没有提交的执行结果,实际生产中不可能使用这种隔离级别,因为这种隔离级别相当于没有任何隔离性,会存在很多并发问题,如脏读。幻读、不可重复读等。
- 读提交(Read Committed): 该隔离级别是大多数数据库的默认隔离级别,但它不是MySQL默认的隔离级别,它满足了隔离的简单定义:一个事务只能看到其他已经提交的事务所做的改变,但这种隔离级别存在不可重复读和幻读的问题。
- 可重复读(Repeatable Read): 这是MySQL默认的隔离级别,该隔离级别确保同一个事务在执行过程中,多次读取操作数据时会看到同样的数据,即解决了不可重复读的问题,但这种隔离级别下仍然存在幻读的问题。
- 串行化(Serializable): 这是事务的最高隔离级别,该隔离级别通过强制事务排序,使之不可能相互冲突,从而解决了幻读问题。它在每个读的数据行上面加上共享锁,但是可能会导致超时和锁竞争问题,这种隔离级别太极端,实际生成中基本不使用。
说明一下:
- 虽然数据库事务的隔离级别有以上四种,但一个稳态的数据库只会选择这其中的一种,作为自己的默认隔离级别。但数据库默认的隔离级别有时可能并不满足上层的业务需求,因此数据库提供了这四种隔离级别,可以让我们自行设置。
- 隔离级别基本上都是通过加锁的方式实现的,不同的隔离级别对锁的使用是不同的,常见的有表锁、行锁、写锁、间隙锁(GAP)、Next-Key锁(GAP+行锁)等。
查看与设置隔离级别
查看全局隔离级别
通过select @@global.tx_isolation命令,可以查看全局隔离级别。如下:
查看会话隔离级别
通过select @@session.tx_isolation命令,可以查看当前会话的隔离级别。如下:

此外,通过select @@tx_isolation命令,也可以查看当前会话的隔离级别。如下:
设置会话隔离级别
通过set session transaction isolation level 隔离级别命令,可以设置当前会话的隔离级别。如下:
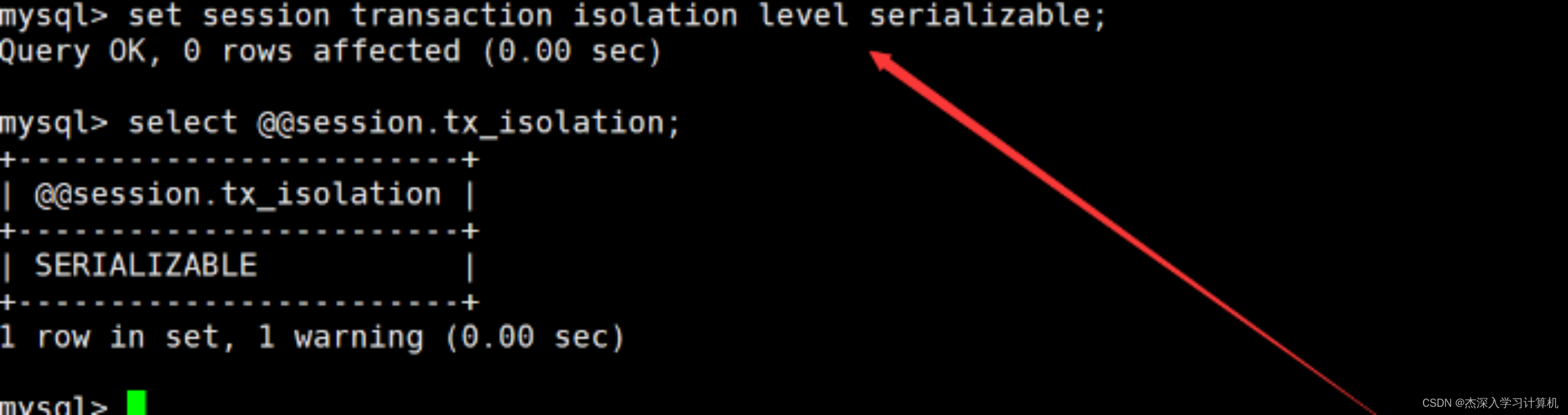
说明一下: 设置会话的隔离级别只会影响当前会话,新起的会话依旧采用全局隔离级。
设置全局隔离级别
通过set global transaction isolation level 隔离级别命令,可以设置全局隔离级别。如下:
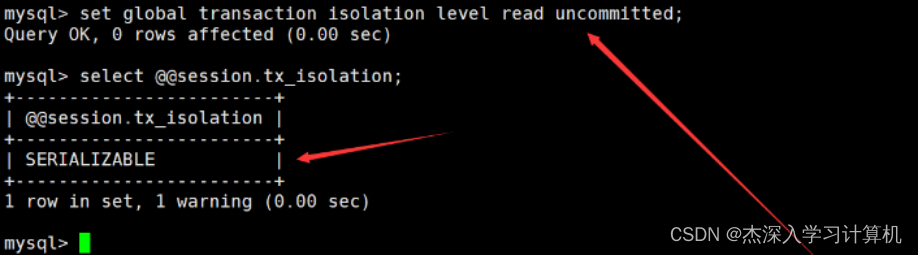
说明一下: 设置全局隔离级别会影响后续的新会话,但当前会话的隔离级别没有发生变化,如果要让当前会话的隔离级别也改变,则需要重启会话。
读未提交(Read Uncommitted)
读未提交(Read Uncommitted)
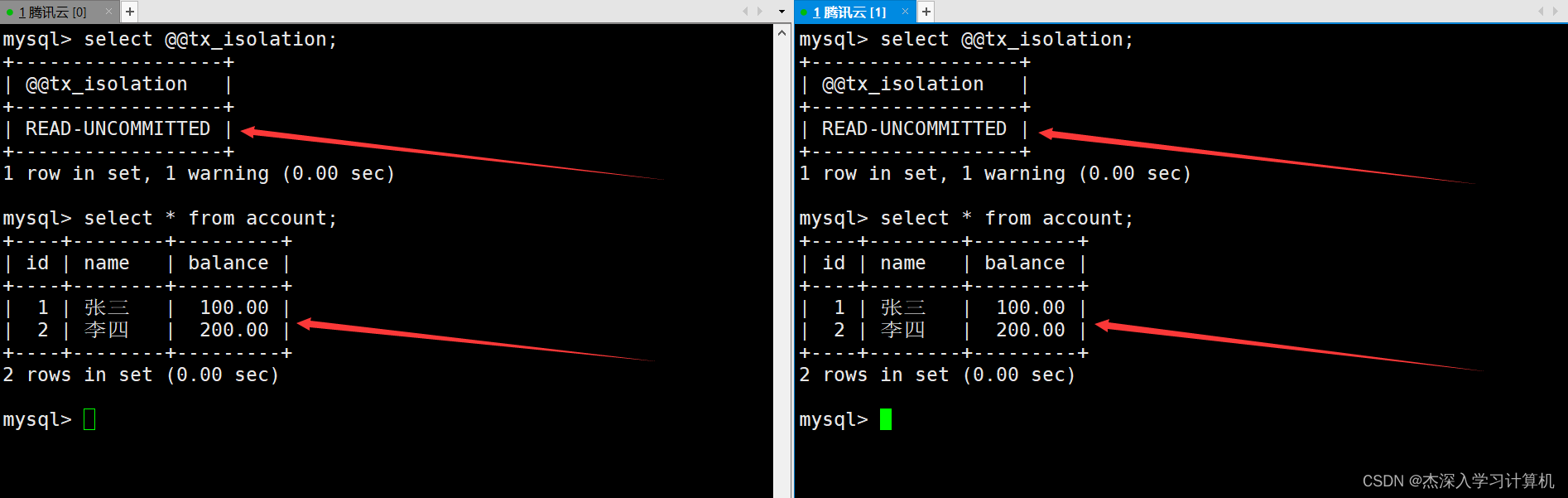
启动两个终端,将隔离级别都设置为读未提交,并查看此时银行用户表中的数据。如下:
在两个终端各自启动一个事务,左终端中的事务所作的修改在没有提交之前,右终端中的事务就已经能够看到了。如下:
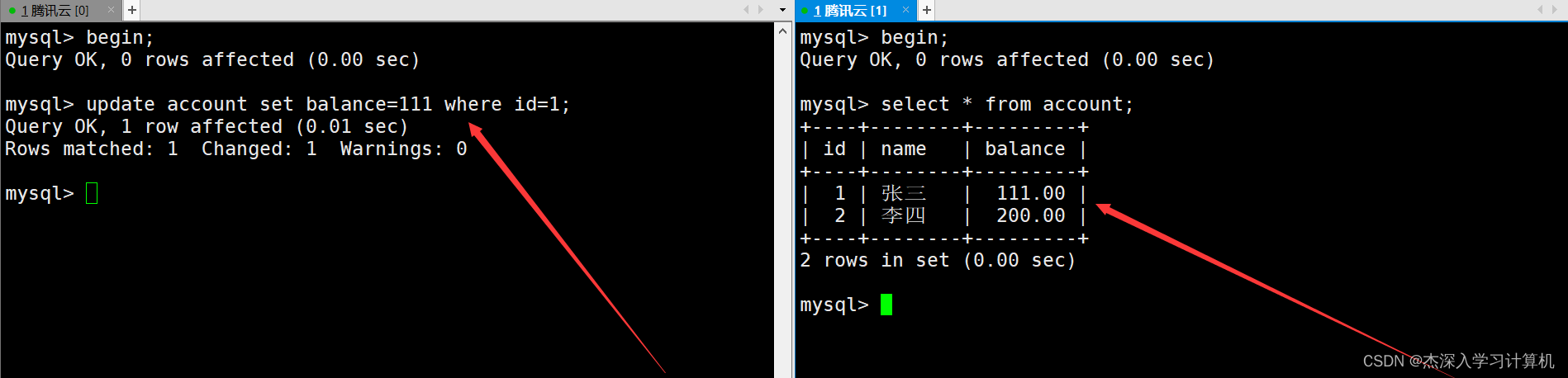
说明一下:
- 读未提交是事务的最低隔离级别,几乎没有加锁,虽然效率高,但是问题比较多,所以严重不建议使用。
- 一个事务在执行过程中,读取到另一个执行中的事务所做的修改,但是该事务还没有进行提交,这种现象叫做脏读。
读提交(Read Committed)
读提交(Read Committed)
启动两个终端,将隔离级别都设置为读提交,并查看此时银行用户表中的数据。如下: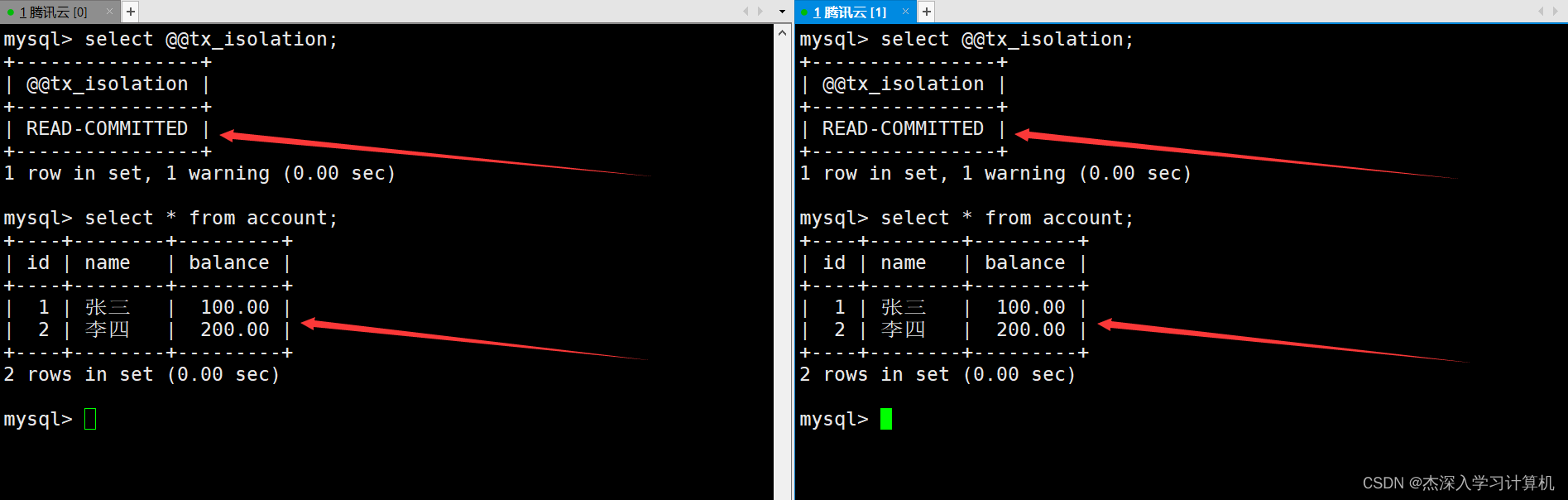
在两个终端各自启动一个事务,左终端中的事务所作的修改在没有提交之前,右终端中的事务无法看到。如下:

只有当左终端中的事务提交后,右终端中的事务才能看到修改后的数据。如下:

说明一下:
- 一个事务在执行过程中,两个相同的select查询得到了不同的数据,这种现象叫做不可重复读。
可重复读(Repeatable Read)
可重复读(Repeatable Read)
启动两个终端,将隔离级别都设置为可重复读,并查看此时银行用户表中的数据。如下:
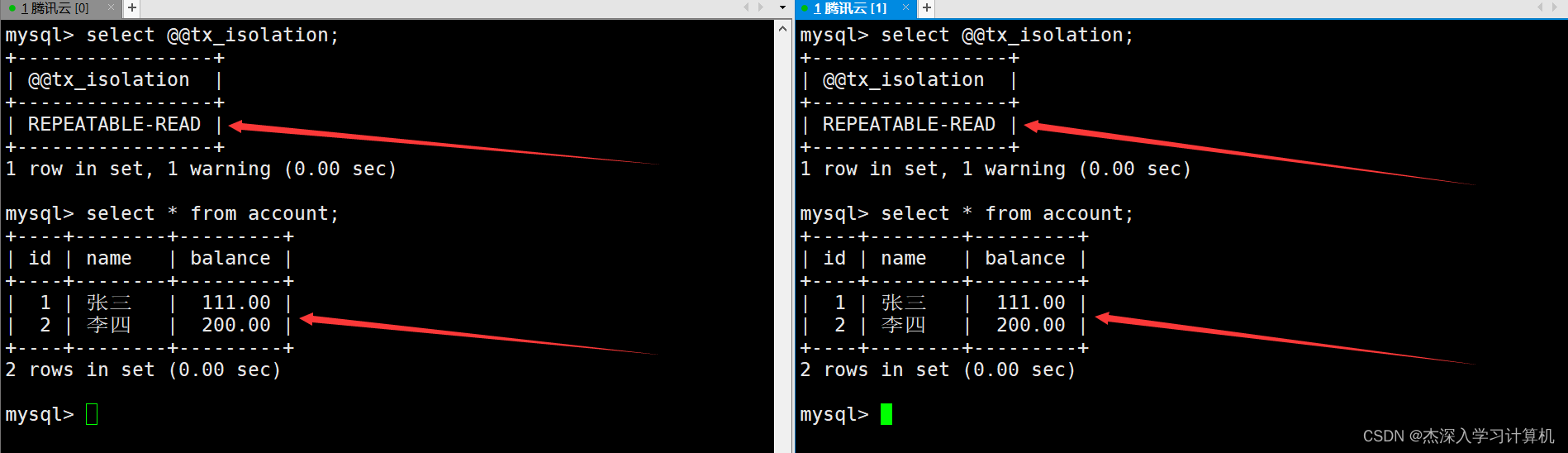
在两个终端各自启动一个事务,左终端中的事务所作的修改在没有提交之前,右终端中的事务无法看到。如下: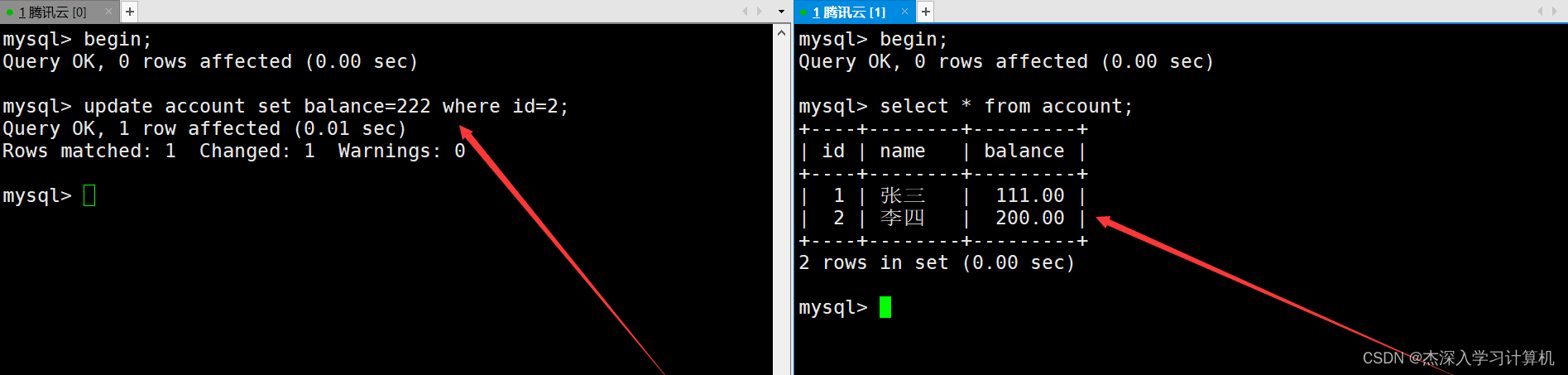
并且当左终端中的事务提交后,右终端中的事务仍然看不到修改后的数据。如下: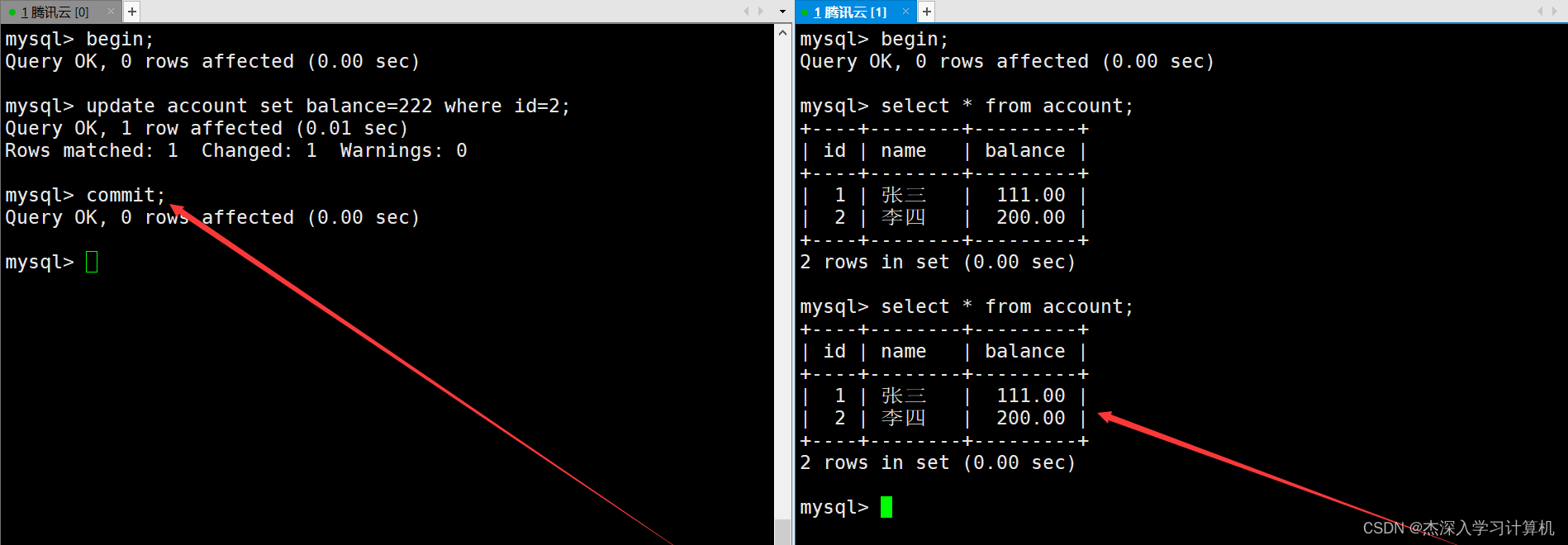
说明一下:
- 在可重复读隔离级别下,一个事务在执行过程中,相同的select查询得到的是相同的数据,这就是所谓的可重复读。
- 一般的数据库在可重复读隔离级别下,update数据是满足可重复读的,但insert数据会存在幻读问题,因为隔离性是通过对数据加锁完成的,而新插入的数据原本是不存在的,因此一般的加锁无法屏蔽这类问题。
- 一个事务在执行过程中,相同的select查询得到了新的数据,如同出现了幻觉,这种现象叫做幻读。
MySQL解决了可重复读隔离级别下的幻读问题,比如重新在这两个终端各自启动一个事务,左终端中的事务向表中插入数据的在没有提交之前,右终端中的事务无法看到。如下: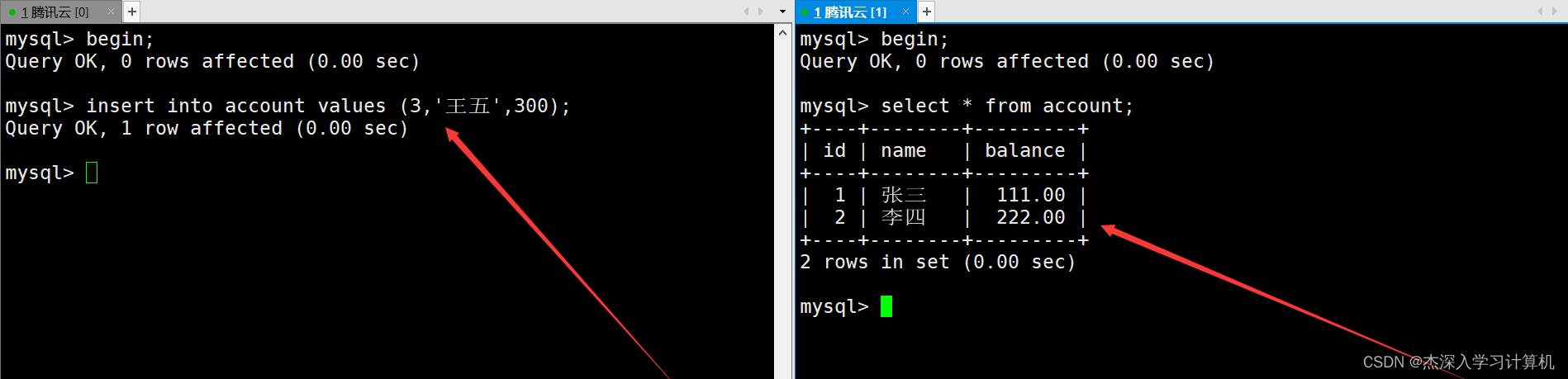
并且当左终端中的事务提交后,右终端中的事务仍然看不到新插入的数据。如下:
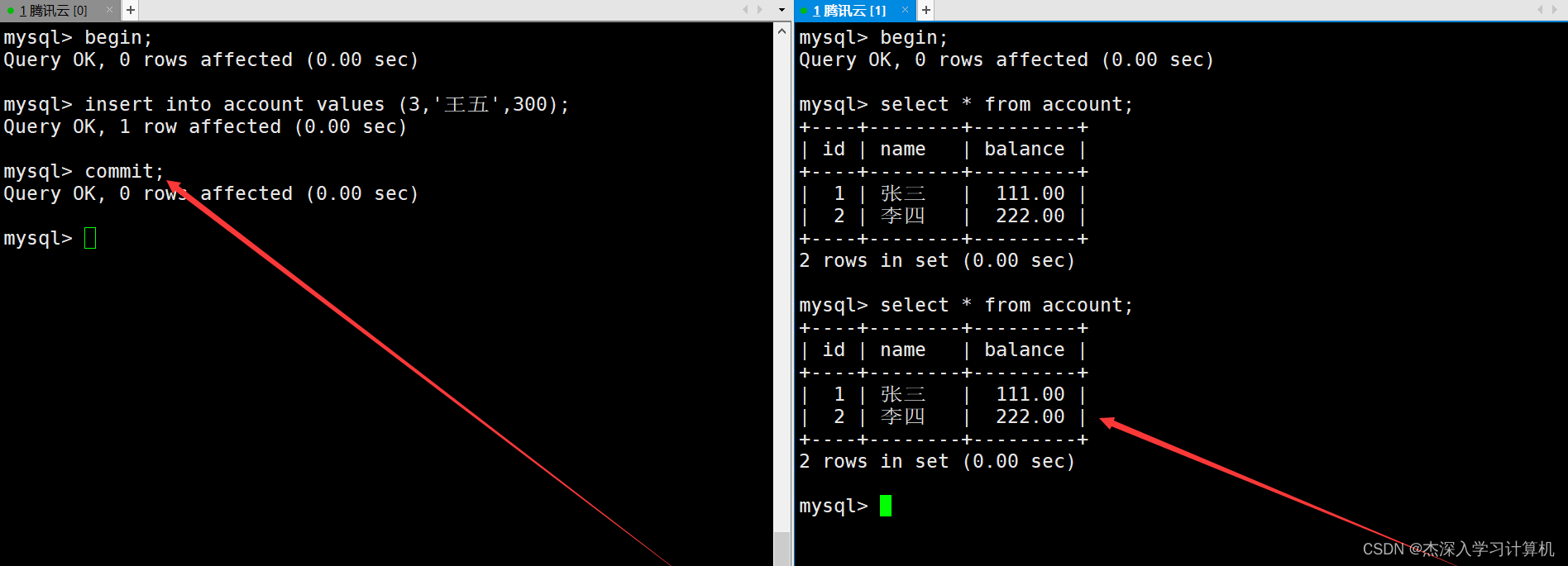
只有当右终端中的事务提交后再查看表中的数据,这时才能看到新插入的数据。如下:
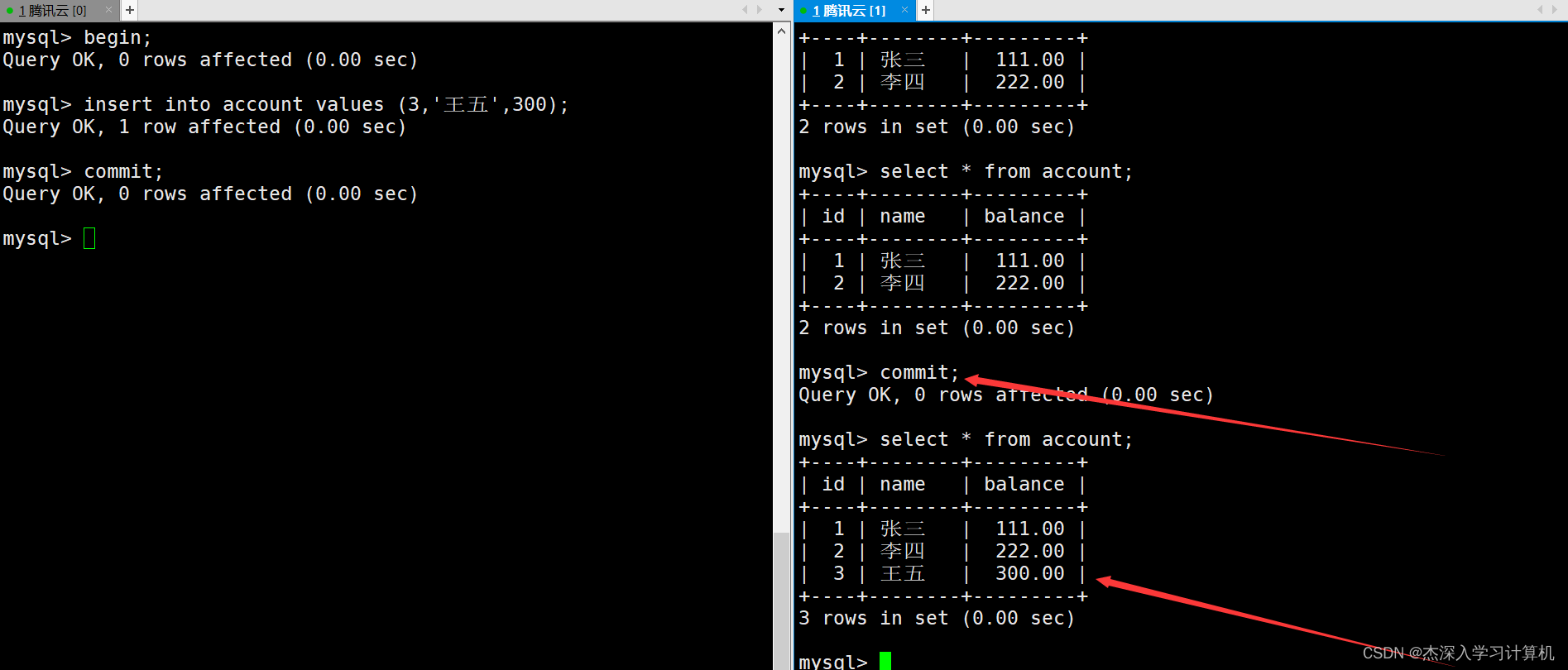
说明一下:
- MySQL是通过Next-Key锁(GAP+行锁)来解决幻读问题的。
串行化(Serializable)
串行化(Serializable)
启动两个终端,将隔离级别都设置为串行化,并查看此时银行用户表中的数据。如下: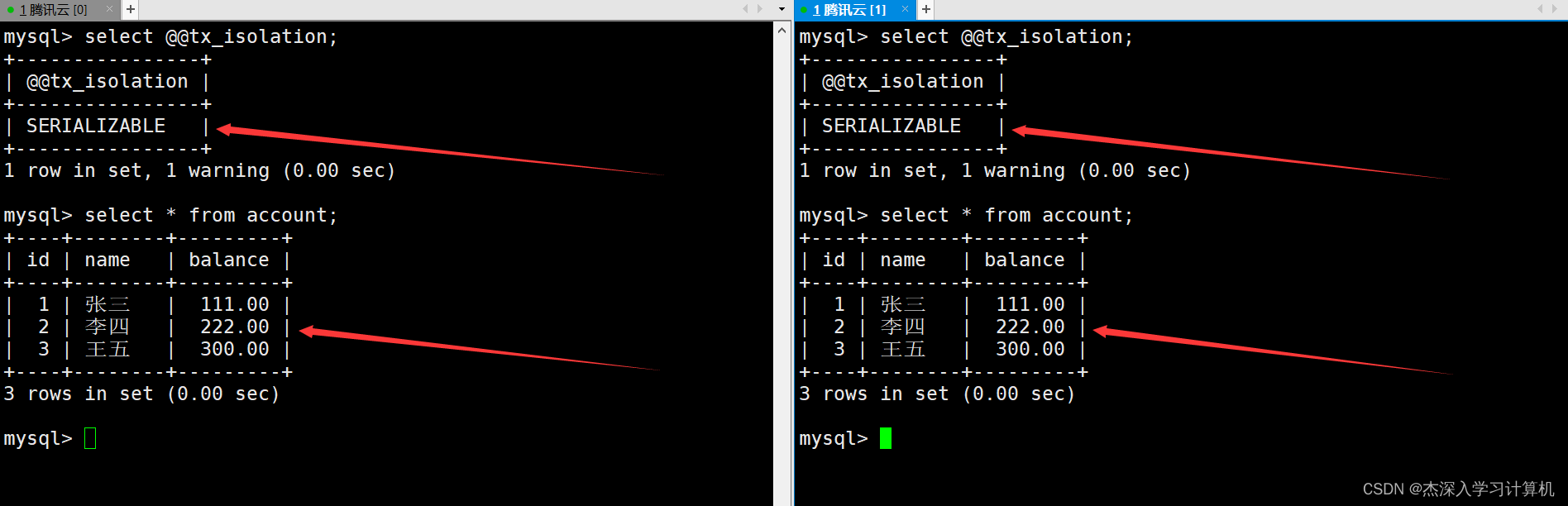
在两个终端各自启动一个事务,如果这两个事务都对表进行的是读操作,那么这两个事务可以并发执行,不会被阻塞。如下: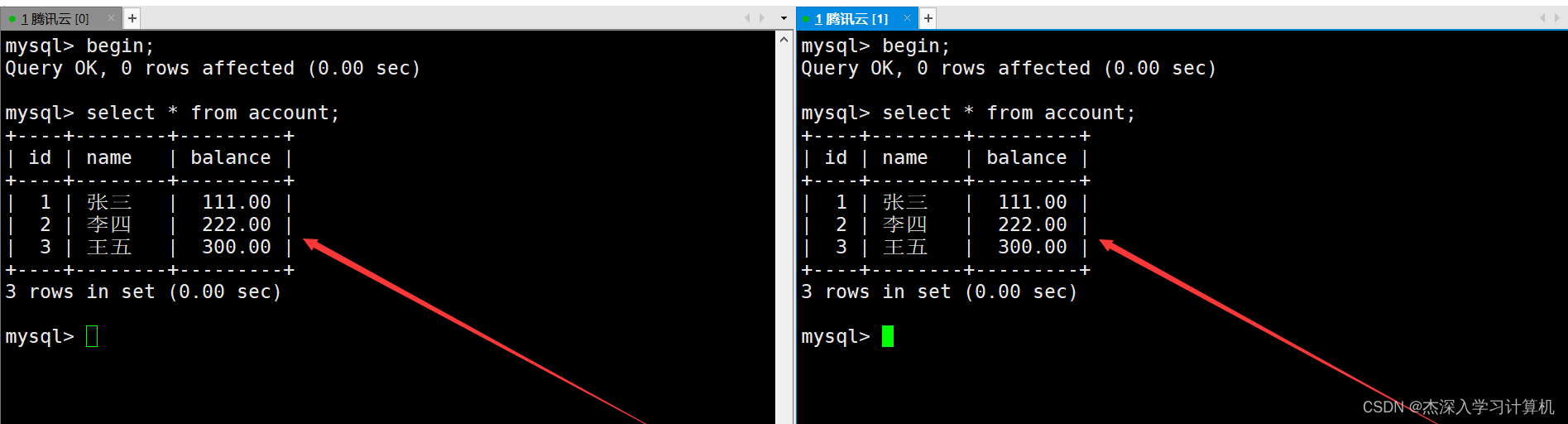
直到访问这张表的其他事务都提交后,这个被阻塞的事务才会被唤醒,然后才能对表进行修改操作。如下:
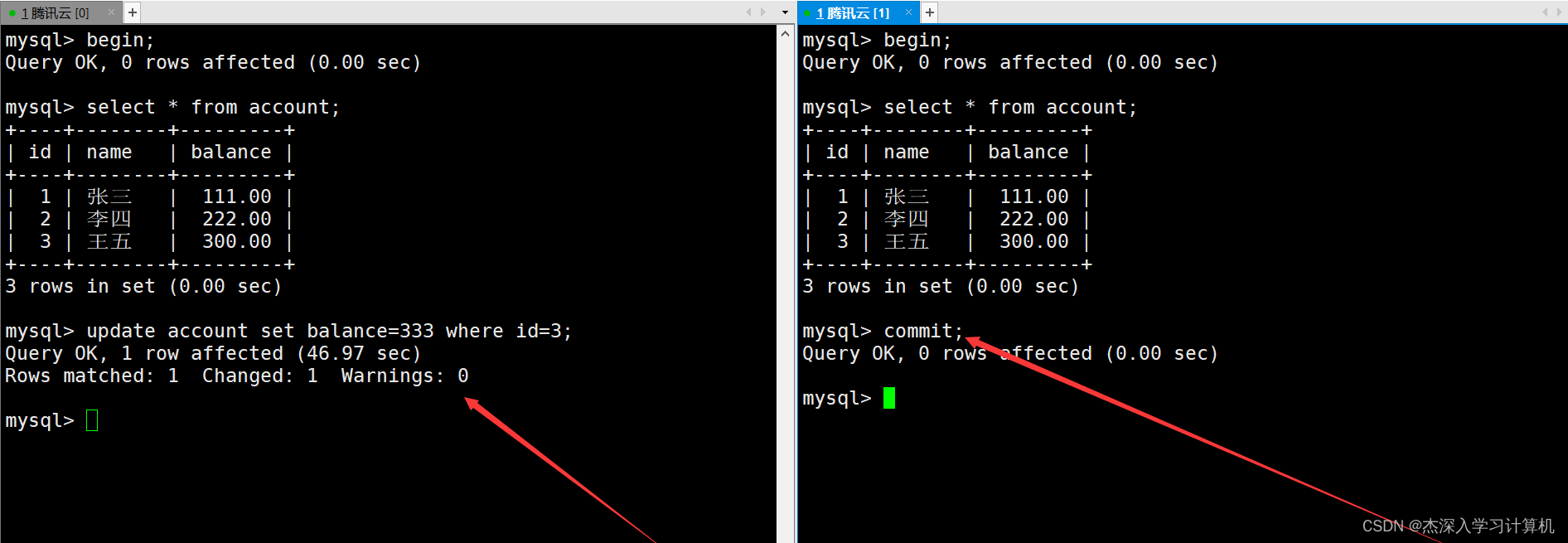
说明一下:
- 串行化是事务的最高隔离级别,多个事务同时进行读操作时加的是共享锁,因此可以并发执行读操作,但一旦需要进行写操作,就会进行串行化,效率很低,几乎不会使用。
隔离级别总结
隔离级别总结
对MySQL中的隔离级别总结如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交(read uncommitted) | √ | √ | √ | 不加锁 |
| 读已提交(read committed) | X | √ | √ | 不加锁 |
| 可重复读(repeatable read) | X | X | X | 不加锁 |
| 可串行化(serializable) | X | X | X | 加锁 |
√:会发生该问题
X:不会发生该问题
说明一下:
- 隔离级别越严格,安全性越高,但数据库的并发性能也就越低,在选择隔离级别时往往需要在两者之间找一个平衡点。
- 表中只写出了各种隔离级别下进行读操作时是否需要加锁,因为无论哪种隔离级别,只要需要进行写操作就一定需要加锁。
关于一致性
关于一致性
事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态,当数据库只包含事务成功提交的结果时,数据库就处于一致性状态。
- 事务在执行过程中如果发生错误,则需要自动回滚到事务最开始的状态,就像这个事务从来没有执行过一样,即一致性需要原子性来保证。
- 事务处理结束后,对数据的修改必须是永久的,即系统故障也不能丢失,即一致性需要持久性来保证。
- 多个事务同时访问一份数据时,必须保证这个多个事务在并发执行时,不能因为由于交叉执行而导致数据不一致,即一致性需要隔离性来保证。
- 此外,一致性与用户的业务逻辑强相关,如果用户本身的业务逻辑有问题,最终也会让数据库处于一种不一致的状态。
也就是说,一致性实际是数据库最终要达到的效果,一致性不仅需要原子性、持久性和隔离性来保证,还需要上层用户编写出正确的业务逻辑。
多版本并发控制
数据库的并发场景
数据库并发的场景无非如下三种:
- 读-读并发:不存在任何问题,也不需要并发控制。
- 读-写并发:有线程安全问题,可能会存在事务隔离性问题,可能遇到脏读、幻读、不可重复读。
- 写-写并发:有线程安全问题,可能会存在两类更新丢失问题。
说明一下:
- 写-写并发场景下的第一类更新丢失又叫做回滚丢失,即一个事务的回滚把另一个已经提交的事务更新的数据覆盖了,第二类更新丢失又叫做覆盖丢失,即一个事务的提交把另一个已经提交的事务更新的数据覆盖了。
- 读-读并发不需要进行并发控制,写-写并发实际也就是对数据进行加锁,这里最值得讨论的是读-写并发,读-写并发是数据库当中最高频的场景,在解决读-写并发时不仅需要考虑线程安全问题,还需要考虑并发的性能问题。
多版本并发控制
- 多版本并发控制(Multi-Version Concurrency Control,MVCC)是一种用来解决读写冲突的无锁并发控制,主要依赖记录中的3个隐藏字段、undo日志和Read View实现。
- 为事务分配单向增长的事务ID,为每个修改保存一个版本,将版本与事务ID相关联,读操作只读该事务开始前的数据库快照。
- MVCC保证读写并发时,读操作不会阻塞写操作,写操作也不会阻塞读操作,提高了数据库并发读写的性能,同时还可以解决脏读、幻读和不可重复读等事务隔离性问题。
记录中的3个隐藏字段
记录中的3个隐藏字段
数据库表中的每条记录都会有如下3个隐藏字段:
DB_TRX_ID:6字节,创建或最近一次修改该记录的事务ID。DB_ROW_ID:6字节,隐含的自增ID(隐藏主键)。DB_ROLL_PTR:7字节,回滚指针,指向这条记录的上一个版本。
说明一下:
- 采用InnoDB存储引擎建立的每张表都会有一个主键,如果用户没有设置,InnoDB就会自动以
DB_ROW_ID产生一个聚簇索引。 - 此外,数据库表中的每条记录还有一个删除flag隐藏字段,用于表示该条记录是否被删除,便于进行数据回滚。
示例
创建一个学生表,表中包含学生的姓名和年龄。如下:
当向表中插入一条记录后,该记录不仅包含name和age字段,还包含三个隐藏字段。如下:
说明一下:
- 假设插入该记录的事务的事务ID为9,那么该记录的
DB_TRX_ID字段填的就是9。 - 因为这是插入的第一条记录,所以隐式主键
DB_ROW_ID字段填的就是1。 - 由于这条记录是新插入的,没有历史版本,所以回滚指针
DB_ROLL_PTR的值设置为null。 - MVCC重点需要的就是这三个隐藏字段,实际还有其他隐藏字段,只不过没有画出。
undo日志
undo日志
- redo log:重做日志,用于MySQL崩溃后进行数据恢复,保证数据的持久性。
- bin log:逻辑日志,用于主从数据备份时进行数据同步,保证数据的一致性。
- undo log:回滚日志,用于对已经执行的操作进行回滚,保证事务的原子性。
MySQL会为上述三大日志开辟对应的缓冲区,用于存储日志相关的信息,必要时会将缓冲区中的数据刷新到磁盘。
说明一下:
- MVCC的实现主要依赖三大日志中的undo log,记录的历史版本就是存储在undo log对应的缓冲区中的。
快照的概念
快照的概念
现在有一个事务ID为10的事务,要将刚才插入学生表中的记录的学生姓名改为“李四”:
- 因为是要进行写操作,所以需要先给该记录加行锁。
- 修改前,先将该行记录拷贝到undo log中,此时undo log中就有了一行副本数据。
- 然后再将原始记录中的学生姓名改为“李四”,并将该记录的
DB_TRX_ID改为10,回滚指针DB_ROLL_PTR设置成undo log中副本数据的地址,从而指向该记录的上一个版本。 - 最后当事务10提交后释放锁,这时最新的记录就是学生姓名为“李四”的那条记录。
修改后的示意图如下:
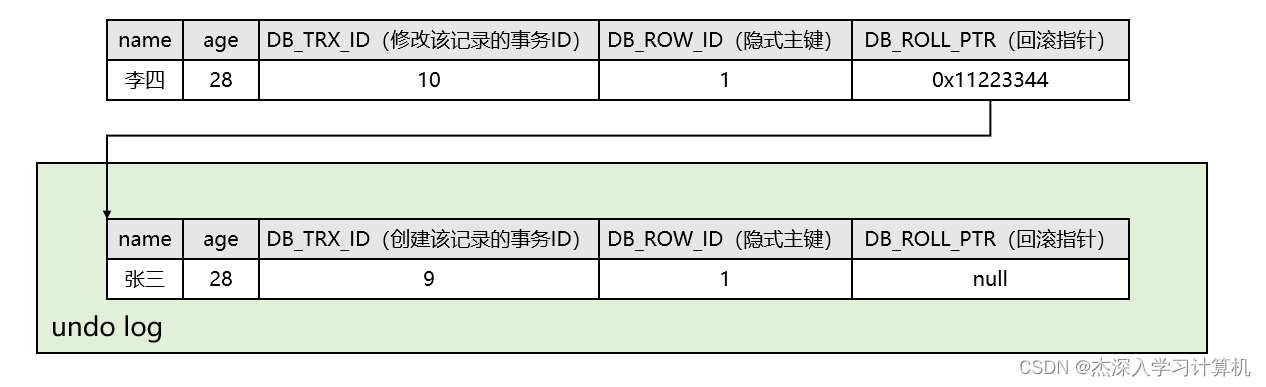
现在又有一个事务ID为11的事务,要将刚才学生表中的那条记录的学生年龄改为38:
- 因为是要进行写操作,所以需要先给该记录(最新的记录)加行锁。
- 修改前,先将该行记录拷贝到undo log中,此时undo log中就又有了一行副本数据。
- 然后再将原始记录中的学生年龄改为38,并将该记录的
DB_TRX_ID改为11,回滚指针DB_ROLL_PTR设置成刚才拷贝到undo log中的副本数据的地址,从而指向该记录的上一个版本。 - 最后当事务11提交后释放锁,这时最新的记录就是学生年龄为38的那条记录。
修改后的示意图如下:
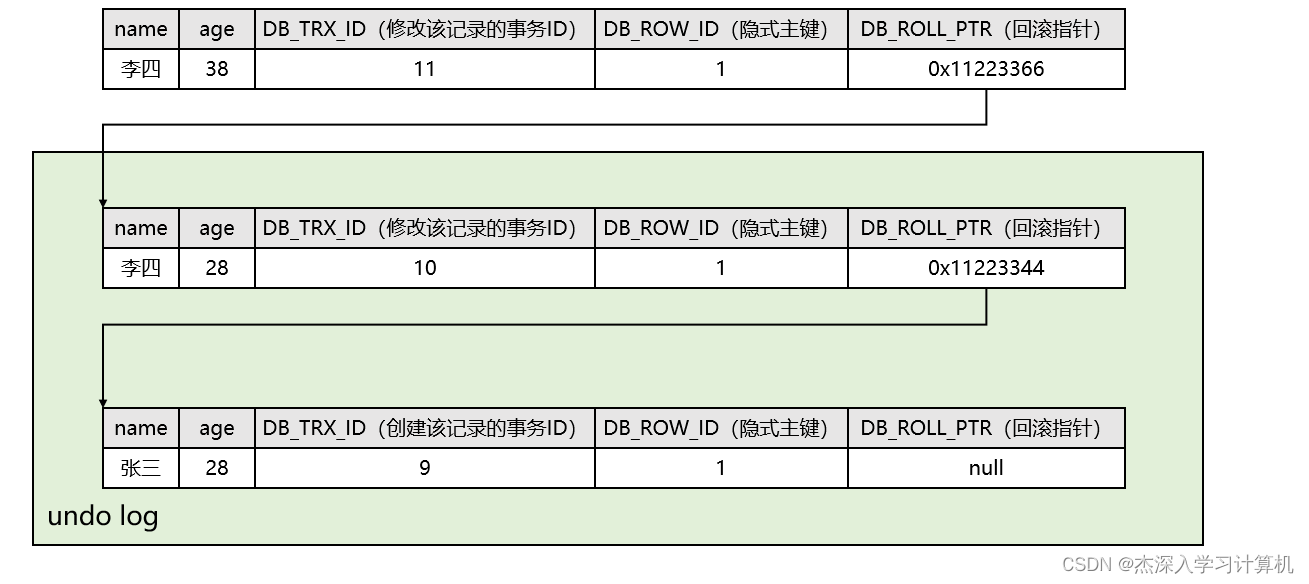
此时我们就有了一个基于链表记录的历史版本链,而undo log中的一个个的历史版本就称为一个个的快照。
说明一下:
- 所谓的回滚实际就是用undo log中的历史数据覆盖当前数据,而所谓的创建保存点就可以理解成是给某些版本做了标记,让我们可以直接用这些版本数据来覆盖当前数据。
- 这种技术实际就是基于版本的写时拷贝,当需要进行写操作时先将最新版本拷贝一份到undo log中,然后再进行写操作,和父子进程为了保证独立性而进行的写时拷贝是类似的。
insert和delete的记录如何维护版本链?
- 删除记录并不是真的把数据删除了,而是先将该记录拷贝一份放入undo log中,然后将该记录的删除flag隐藏字段设置为1,这样回滚后该记录的删除flag隐藏字段就又变回0了,相当于删除的数据又恢复了。
- 新插入的记录是没有历史版本的,但是一般为了回滚操作,新插入的记录也需要拷贝一份放入undo log中,只不过被拷贝到undo log中的记录的删除flag隐藏字段被设置为1,这样回滚后就相当于新插入的数据就被删除了。
也就是说,增加、删除和修改数据都是可以形成版本链的。
当前读 VS 快照读
- 当前读:读取最新的记录,就叫做当前读。
- 快照读:读取历史版本,就叫做快照读。
事务在进行增删查改的时候,并不是都需要进行加锁保护:
- 事务对数据进行增删改的时候,操作的都是最新记录,即当前读,需要进行加锁保护。
- 事务在进行select查询的时候,既可能是当前读也可能是快照读,如果是当前读,那也需要进行加锁保护,但如果是快照读,那就不需要加锁,因为历史版本不会被修改,也就是可以并发执行,提高了效率,这也就是MVCC的意义所在。
而select查询时应该进行当前读还是快照读,则是由隔离级别决定的,在读未提交和串行化隔离级别下,进行的都是当前读,而在读提交和可重复读隔离级别下,既可能进行当前读也可能进行快照读。
undo log中的版本链何时才会被清除?
- 在undo log中形成的版本链不仅仅是为了进行回滚操作,其他事务在执行过程中也可能读取版本链中的某个版本,也就是快照读。
- 因此,只有当某条记录的最新版本已经修改并提交,并且此时没有其他事务与该记录的历史版本有关了,这时该记录在undo log中的版本链才可以被清除。
说明一下:
- 对于新插入的记录来说,没有其他事务会访问它的历史版本,因此新插入的记录在提交后就可以将undo log中的版本链清除了。
- 因此版本链在undo log中可能会存在很长时间,尤其是有其他事务和这个版本链相关联的时候,但这也没有坏处,这说明它是一个热数据。
Read View
Read View
- 事务在进行快照读操作时会生成读视图Read View,在该事务执行快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃的事务ID。
- Read View在MySQL源码中就是一个类,本质是用来进行可见性判断的,当事务对某个记录执行快照读的时候,对该记录创建一个Read View,根据这个Read View来判断,当前事务能够看到该记录的哪个版本的数据。
ReadView类的源码如下:
class ReadView {// 省略...
private:/** 高水位:大于等于这个ID的事务均不可见*/trx_id_t m_low_limit_id;/** 低水位:小于这个ID的事务均可见 */trx_id_t m_up_limit_id;/** 创建该 Read View 的事务ID*/trx_id_t m_creator_trx_id;/** 创建视图时的活跃事务id列表*/ids_t m_ids;/** 配合purge,标识该视图不需要小于m_low_limit_no的UNDO LOG,* 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/trx_id_t m_low_limit_no;/** 标记视图是否被关闭*/bool m_closed;// 省略...
};
部分成员说明:
- m_ids: 一张列表,记录Read View生成时刻,系统中活跃的事务ID。
- m_up_limit_id: 记录m_ids列表中事务ID最小的ID。
- m_low_limit_id: 记录Read View生成时刻,系统尚未分配的下一个事务ID。
- m_creator_trx_id: 记录创建该Read View的事务的事务ID。
由于事务ID是单向增长的,因此根据Read View中的m_up_limit_id和m_low_limit_id,可以将事务ID分为三个部分:
- 事务ID小于 m_up_limit 的事务,一定是生成Read View时已经提交的事务,因为m_up_limit_id是生成Read View时刻系统中活跃事务ID中的最小ID,因此事务ID比它小的事务在生成Read View时一定已经提交了。
- 事务ID大于等于m_low_limit_id的事务,一定是生成Read View时还没有启动的事务,因为m_low_limit_id是生成Read View时刻,系统尚未分配的下一个事务ID。
- 事务ID位于m_up_limit_id和m_low_limit_id之间的事务,在生成Read View时可能正处于活跃状态,也可能已经提交了,这时需要通过判断事务ID是否存在于m_ids中来判断该事务是否已经提交。
示意图如下: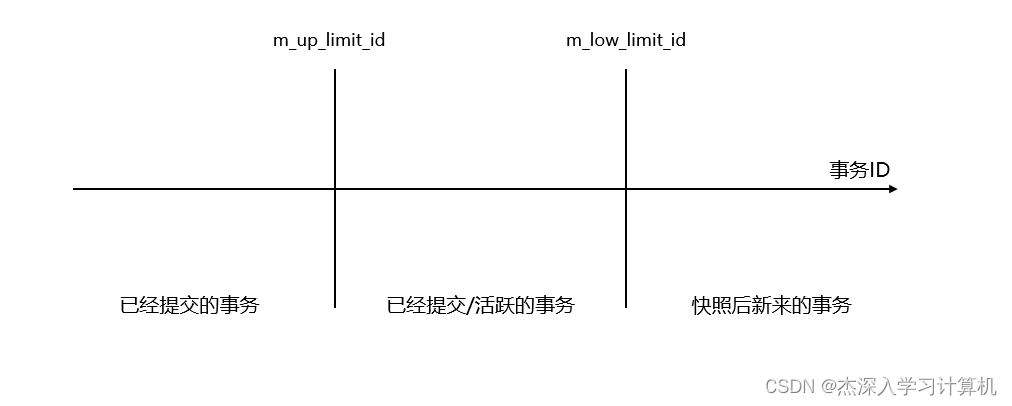
- 一个事务在进行读操作时,只应该看到自己或已经提交的事务所作的修改,因此我们可以根据Read View来判断当前事务能否看到另一个事务所作的修改。
- 版本链中的每个版本的记录都有自己的DB_TRX_ID,即创建或最近一次修改该记录的事务ID,因此可以依次遍历版本链中的各个版本,通过Read View来判断当前事务能否看到这个版本,如果不能则继续遍历下一个版本。
源码策略如下:
bool changes_visible(trx_id_t id, const table_name_t& name) const MY_ATTRIBUTE((warn_unused_result))
{ut_ad(id > 0);//1、事务id小于m_up_limit_id(已提交)或事务id为创建该Read View的事务的id,则可见if (id < m_up_limit_id || id == m_creator_trx_id) {return(true);}check_trx_id_sanity(id, name);//2、事务id大于等于m_low_limit_id(生成Read View时还没有启动的事务),则不可见if (id >= m_low_limit_id) {return(false);}//3、事务id位于m_up_limit_id和m_low_limit_id之间,并且活跃事务id列表为空(即不在活跃列表中),则可见else if (m_ids.empty()) {return(true);}const ids_t::value_type* p = m_ids.data();//4、事务id位于m_up_limit_id和m_low_limit_id之间,如果在活跃事务id列表中则不可见,如果不在则可见return (!std::binary_search(p, p + m_ids.size(), id));
}
说明一下: 使用该函数时将版本的DB_TRX_ID传给参数id,该函数的作用就是根据Read View,判断当前事务能否看到这个版本。
RR与RC的本质区别
现象演示
启动两个终端,将隔离级别都设置为可重复读,并查看此时银行用户表中的数据。如下:
在两个终端各自启动一个事务,在左终端中的事务操作之前,先让右终端中的事务查看一下表中的信息。如下:
左终端中的事务对表中的信息进行修改并提交,右终端中的事务看不到修改后的数据。如下: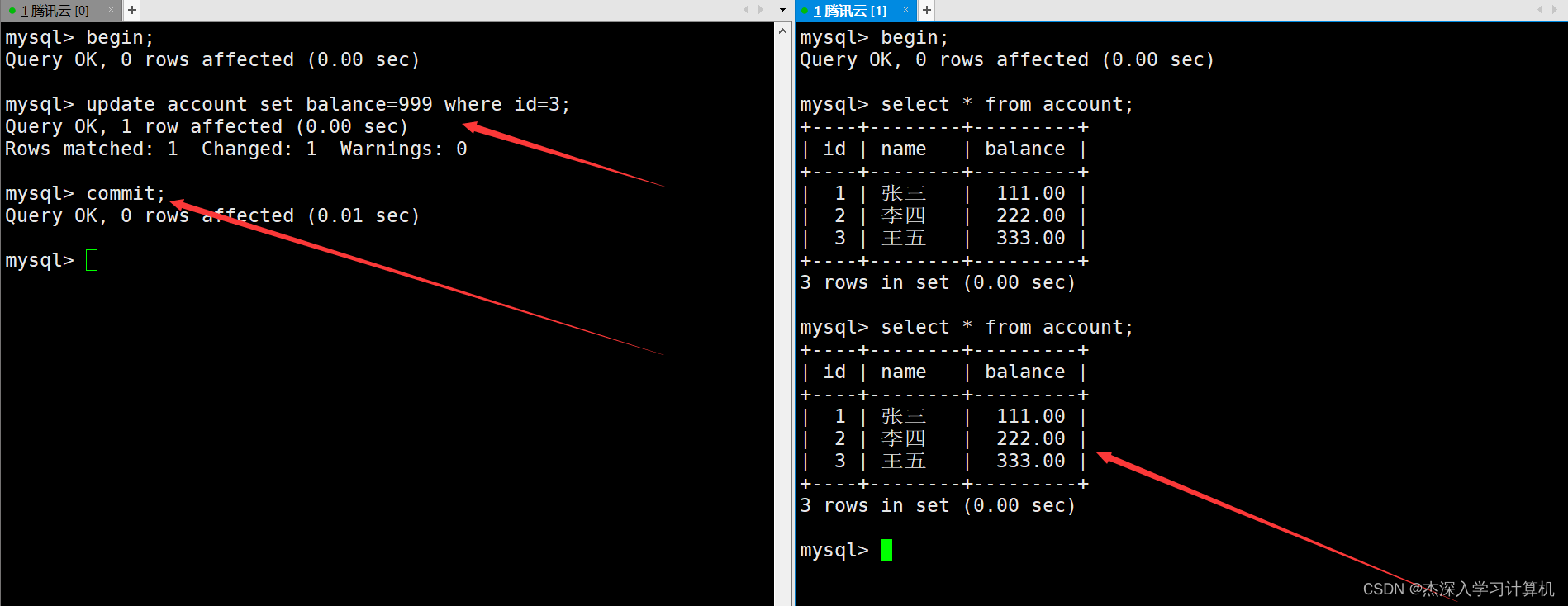
在右终端中使用select ... lock in share mode命令进行当前读,可以看到表中的数据确实是被修改了,只是右终端中的事务看不到而已。如下: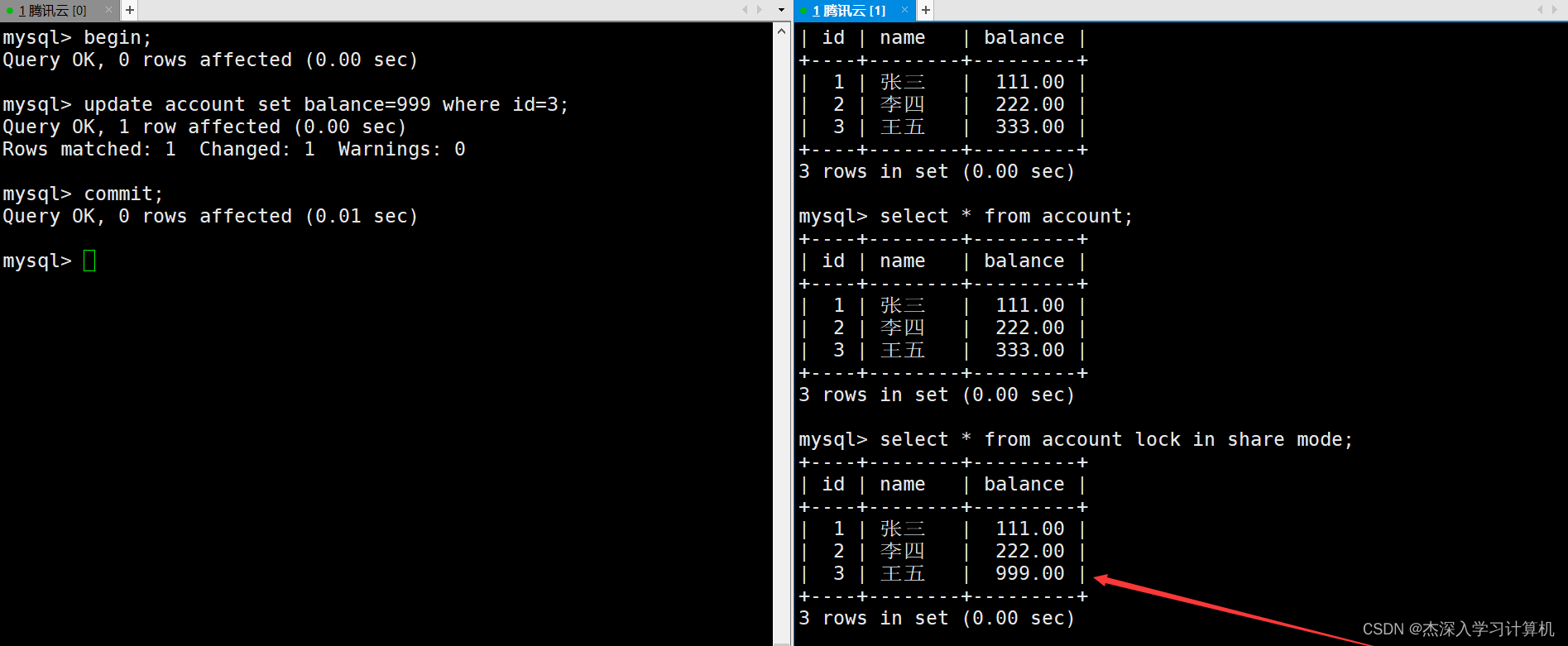
但如果修改一下SQL的执行顺序,在两个终端各自启动一个事务后,直接让左终端中的事务对表中的信息进行修改并提交,然后再让右终端中的事务进行查看,这时右终端中的事务就直接看到了修改后的数据。如下: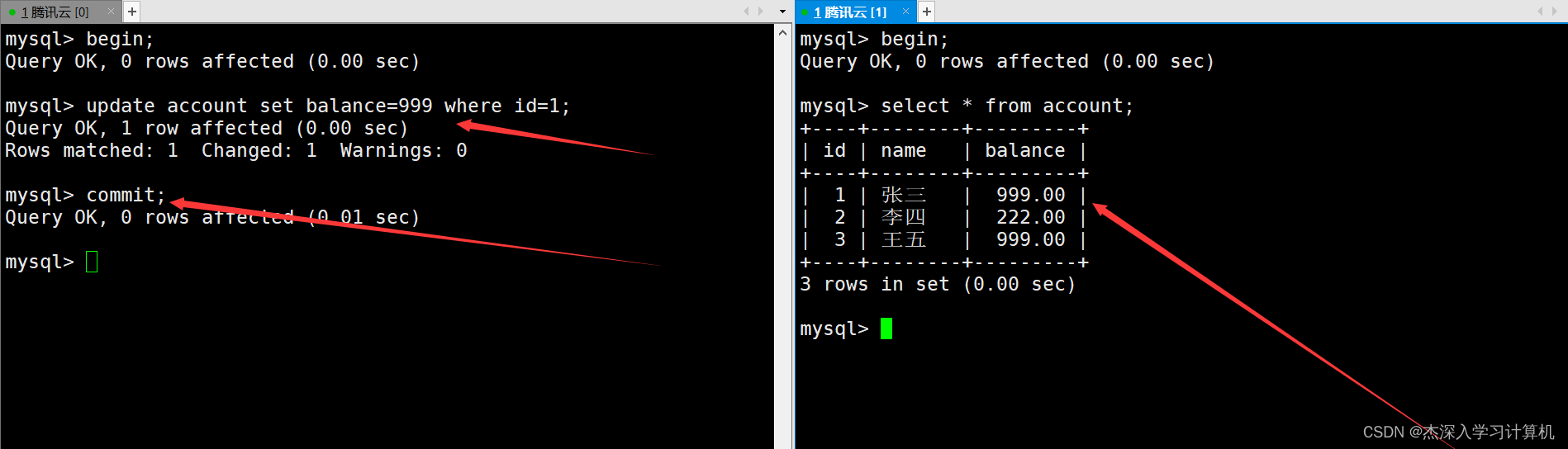
在右终端中使用select ... lock in share mode命令进行当前读,可以看到刚才读取到的确实是最新的数据。如下: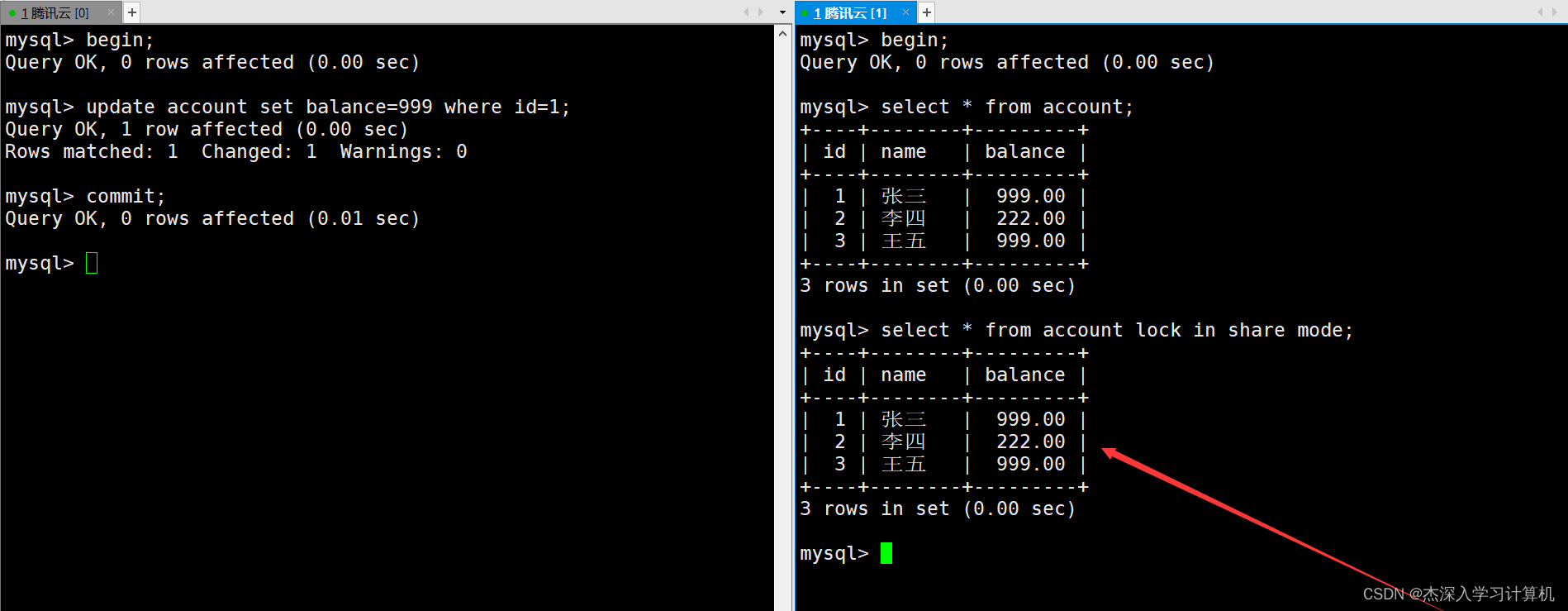
说明一下:
- 上面两次实验的唯一区别在于,右终端中的事务在左终端中的事务修改数据之前是否进行过快照读。
- 上面两次实验的唯一区别在于,右终端中的事务在左终端中的事务修改数据之前是否进行过快照读。
RR与RC的本质区别
- 正是因为Read View生成时机的不同,从而造成了RC和RR级别下快照读的结果的不同。
- 在RR级别下,事务第一次进行快照读时会创建一个Read View,将当前系统中活跃的事务记录下来,此后再进行快照读时就会直接使用这个Read View进行可见性判断,因此当前事务看不到第一次快照读之后其他事务所作的修改。
- 而在RC级别下,事务每次进行快照读时都会创建一个Read View,然后根据这个Read View进行可见性判断,因此每次快照读时都能读取到被提交了的最新的数据。
- RR级别下快照读只会创建一次Read View,所以RR级别是可重复读的,而RC级别下每次快照读都会创建新的Read View,所以RC级别是不可重复读的。
相关文章:
【MySQL】事务管理
目录 MySQL事务管理 事务的概念 事务的版本支持 事务的提交方式 事务的相关演示 事务的隔离级别 查看与设置隔离级别 读未提交(Read Uncommitted) 读提交(Read Committed) 可重复读(Repeatable Read…...

Git 学习笔记 | Git 基本操作命令
Git 学习笔记 | Git 基本操作命令 Git 学习笔记 | Git 基本操作命令文件的四种状态查看文件状态忽略文件 Git 学习笔记 | Git 基本操作命令 文件的四种状态 版本控制就是对文件的版本控制,要对文件进行修改、提交等操作,首先要知道文件当前在什么状态&…...
)
第五章:最新版零基础学习 PYTHON 教程—Python 字符串操作指南(第七节 - Python 中的字符串模板类)
在字符串模块中,模板类允许我们为输出规范创建简化的语法。该格式使用由 $ 和有效 Python 标识符(字母数字字符和下划线)组成的占位符名称。用大括号将占位符括起来,使其后面可以跟更多的字母数字字母,且中间不留空格。写入 $$ 会创建一个转义的 $。 Python 字符串模板:…...
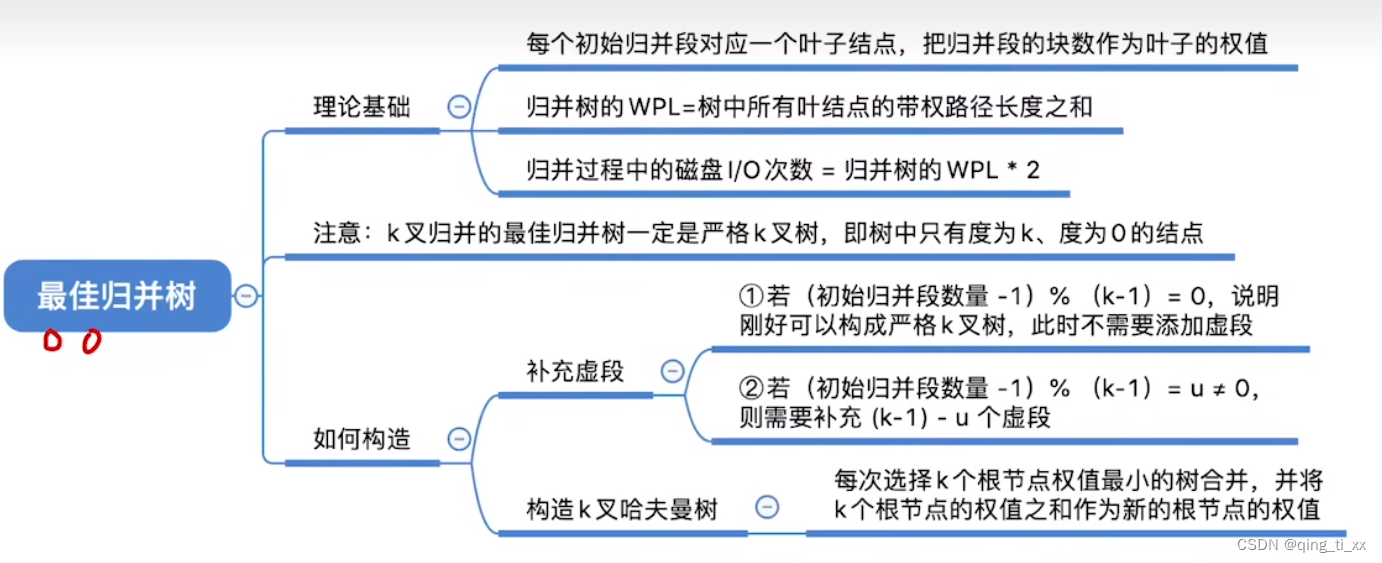
第八章 排序 十四、最佳归并树
目录 一、定义 二、多路最佳归并树 三、多路最佳归并树少了一个归并段 四、总结 一、定义 最佳归并树是指将若干个有序序列合并成一个有序序列的一种方式,使得所有合并操作的总代价最小的一棵二叉树。其中,代价通常指合并两个有序序列的操作次数或比…...

Python 中,类的方法的标准注释模板
在 Python 中,类的标准注释通常遵循以下格式: class 类名:"""类的简要描述属性:- 属性1 (类型): 属性1的描述- 属性2 (类型): 属性2的描述方法:- 方法1(): 方法1的描述- 方法2(): 方法2的描述示例:>>> 对象 类名()>>>…...
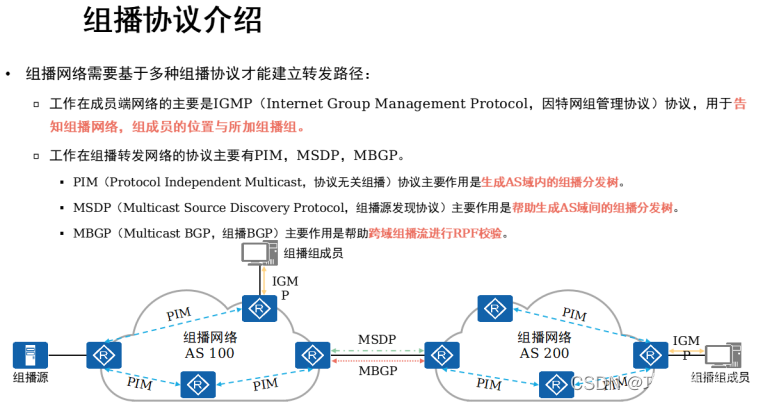
IPSG技术和IP组播
1,IPSG技术概述 实验: DHCP snooping IPSG 拓扑: 需求: 1,实现PC1 和PC2 动态获取IP地址 2, 在SW2 配置DHCP snooping 实现DHCP 服务器的安全 3, 在 连接PC 1 和 PC2 的 接口上 做IPSG ,防止终端…...

【大数据】Apache NiFi 助力数据处理及分发
Apache NiFi 助力数据处理及分发 1.什么是 NiFi ?2.NiFi 的核心概念3.NiFi 的架构4.NiFi 的性能预期和特点5.NiFi 关键特性的高级概览 1.什么是 NiFi ? 简单的说,NiFi 就是为了解决不同系统间数据自动流通问题而建立的。虽然 dataflow 这个术…...

什么是 SRE?一文详解 SRE 运维体系
目录 可观测性系统 故障响应 故障复盘 测试与发布 容量规划 自动化工具开发 用户体验 可观测性系统 在任何有一定规模的企业内部,一旦推行起来整个SRE的运维模式,那么对于可观测性系统的建设将变得尤为重要,而在整个可观测性系统中&a…...
【Docker】初识 Docker,Docker 基本命令的使用,Dockerfile 自定义镜像的创建
文章目录 前言:项目部署的挑战一、初识 Docker1.1 什么是 Docker1.2 Docker 与 虚拟机的区别1.3 镜像和容器以及镜像托管平台1.4 Docker的架构解析1.5 Docker 在 CentOS 中的安装 二、Docker 的基本操作2.1 操作 Docker 镜像命令2.1.1 镜像操作相关命令2.1.2 示例一…...

【Docker】简易版harbor部署
文章目录 依赖于docker-compose下载添加执行权限测试 安装harbor下载解压修改配置文件部署配置开机自启动登录验证 使用harbor登录打标签上传下载 常见问题 依赖于docker-compose 下载 curl -L “https://github.com/docker/compose/releases/download/2.22.0/docker-compose-…...
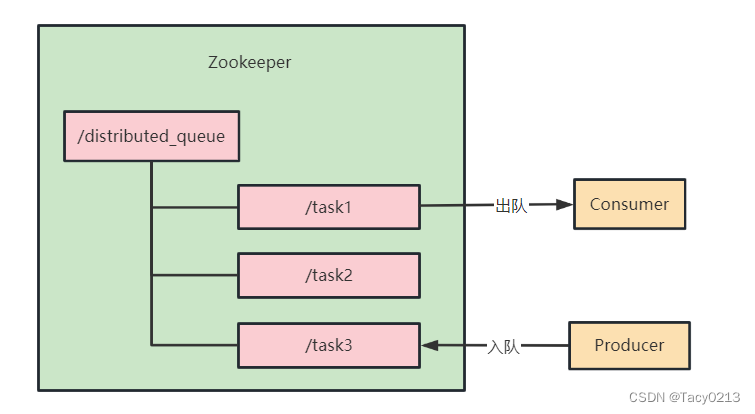
Zookeeper经典应用场景实战(一)
文章目录 1、Zookeeper Java客户端实战1.1、 Zookeeper 原生Java客户端使用1.2、 Curator开源客户端使用 2、 Zookeeper在分布式命名服务中的实战2.1、 分布式API目录2.2、 分布式节点的命名2.3、 分布式的ID生成器 3、Zookeeper实现分布式队列3.1、 设计思路3.2、 使用Apache …...
Chrome报错:Unchecked runtime.lastError
项目背景、安装了 Express 框架,目的是为了快速创建一个web服务器。创建成功后,控制台出现了报错,而在这之前没有出现过这个错误,所以一直在纠结是不是框架本身的问题。 错误原因:这个错误一般是浏览器与扩展或者插件…...
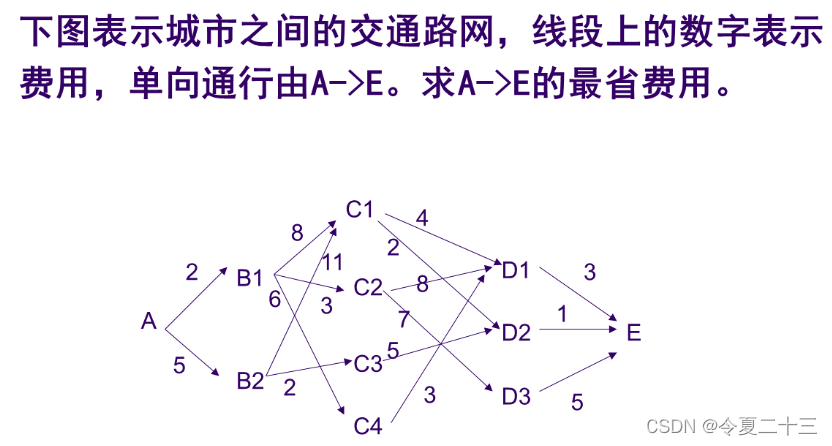
【算法】算法设计与分析 课程笔记 第三章 动态规划
1.1 动态规划简介 1.1.1 引例 动态规划算法和分治法类似,基本思想也是将待求解问题分解成若干个子问题,子问题可以以继续拆分,直到问题规模达到临界条件即可。多说无益,举个例子来解释一下: 这其实是一个多阶段图求最…...

贪心找性质+dp表示+矩阵表示+线段树维护:CF573D
比较套路的题目 首先肯定贪心一波,两个都排序后尽量相连。我一开始猜最多跨1,但其实最多跨2,考虑3个人的情况: 我们发现第3个人没了,所以可以出现跨2的情况 然后直接上dp,由 i − 1 , i − 2 , i − 3 i…...
小谈设计模式(17)—状态模式
小谈设计模式(17)—状态模式 专栏介绍专栏地址专栏介绍 状态模式关键角色上下文(Context)抽象状态(State)具体状态(Concrete State) 核心思想Java程序实现首先,我们定义一个抽象状态类 State,其中包含一个处理请求的方法 handleRe…...

Arm64体系架构-MPIDR_EL1寄存器
背景 在Arm64多核处理器中, 各核间的关系可能不同. 比如1个16 core的cpu, 每4个core划分为1个cluster,共享L2 cache. 当我们需要从core 0将任务调度出来时,如果优先选择core 1~3, 那么性能明显时优于其他core的. 那么操作系统怎么知道core之间这样的拓扑信息呢? Arm提供了MPID…...

MySQL支持哪些存储引擎
mysql支持九大存储引擎: 1)MYISAM存储引擎(优点:可被转换为压缩、只读表来节省空间。) 它管理的表具有以下特征: 使用三个文件表示每个表 格式文件-存储表结构的定义(mytable.frm) 数据文件-存…...

ElementUI结合Vue完成主页的CUD(增删改)表单验证
目录 一、CUD ( 1 ) CU讲述 ( 2 ) 编写 1. CU 2. 删除 二、验证 前端整合代码 : 一、CUD 以下的代码基于我博客中的代码进行续写 : 使用ElementUI结合Vue导航菜单和后台数据分页查询 ( 1 ) CU讲述 在CRUD操作中,CU代表创建(Create)…...
Flutter开发笔记 —— 语音消息功能实现
前言 最近在开发一款即时通讯(IM)的聊天App,在实现语音消息功能模块后,写下该文章以做记录。 注:本文不提供相关图片资源以及IM聊天中具体实现代码,单论语音功能实现思路 需求分析 比起上来直接贴代码,我们先来逐步…...
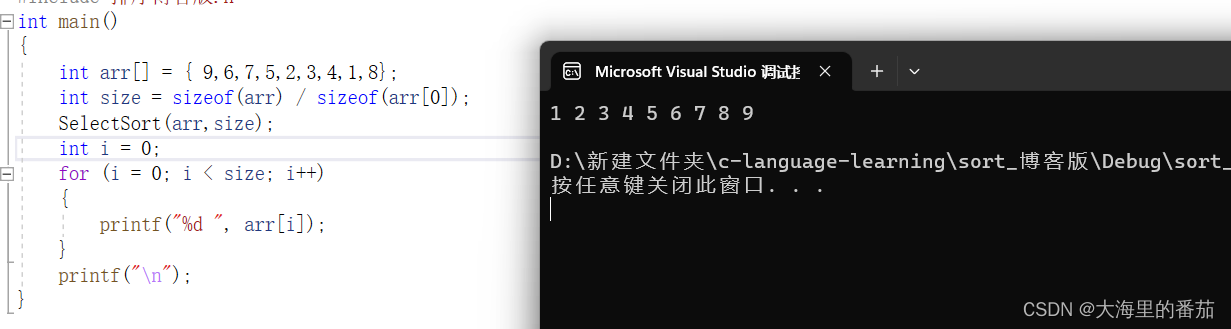
冒泡排序和选择排序
目录 一、冒泡排序 1.冒泡排序的原理 2.实现冒泡排序 1.交换函数 2.单躺排序 3.冒泡排序实现 4.测试 5.升级冒泡排序 6.升级版代码 7.升级版测试 二、选择排序 1.选择排序的原理 2.实现选择排序 1.单躺排序 2.选择排序实现 3.测试 4.修改 5.测试 一、冒泡排序…...

医疗AI数据偏见:从耳镜图像分类看模型泛化陷阱与实战避坑指南
1. 项目概述与核心挑战作为一名在医疗AI领域摸爬滚打了十多年的从业者,我见过太多“实验室里天花乱坠,临床上寸步难行”的模型。最近,我和团队深入剖析了一项关于利用人工智能(AI)进行中耳炎耳镜图像分类的研究&#x…...

DeepSeek代码能力实测:3大编程范式通过率对比,92.7%准确率背后的5个隐藏陷阱
更多请点击: https://intelliparadigm.com 第一章:DeepSeek HumanEval测试全景概览 HumanEval 是由 OpenAI 提出的函数级代码生成基准测试集,包含 164 道 Python 编程题,每道题提供函数签名、文档字符串(docstring&am…...

Python内置模块:io、file、json、csv
一、io StringIO - 文本字符串的缓冲区 from io import StringIO# 创建StringIO对象 sio StringIO() # 空缓冲区 sio StringIO("initial text") # 带初始数据# 常用方法 sio.write("Hello ") # 写入字符串&…...

Hermes Agent:引爆企业AI革命!自进化智能体协作实战与落地指南
Hermes Agent 是一款自进化AI代理系统,具备完整学习循环、跨会话记忆、用户建模等核心特性。本文深入解析其架构、多智能体协作机制及自进化能力,并通过智能客服、DevOps自动化、数据分析等企业级案例,展示如何构建高效AI代理系统。同时提供性…...

魔兽争霸3优化指南:5个常见问题与WarcraftHelper解决方案
魔兽争霸3优化指南:5个常见问题与WarcraftHelper解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否在玩《魔兽争霸3》时遇到过…...
)
树莓派玩转MIPI:手把手教你连接CSI摄像头与DSI显示屏(保姆级图文教程)
树莓派玩转MIPI:手把手教你连接CSI摄像头与DSI显示屏(保姆级图文教程) 树莓派作为一款广受欢迎的微型计算机,其强大的扩展能力一直是开发者们津津乐道的话题。特别是它内置的MIPI接口,为连接高性能摄像头和显示屏提供了…...

动感软膜天花技术白皮书:从异形设计到商业照明的实战解析
动感软膜天花技术白皮书:从异形设计到商业照明的实战解析动感软膜天花的科技内核与市场演进当人们走进现代商业空间,头顶那片既能模拟蓝天白云软膜天花效果,又能实现动态光影变幻的顶面系统,正是动感软膜天花技术的具象化呈现。这…...

GPU加速网络爬虫:OpenCL异构计算在数据采集中的实践
1. 项目概述:一个面向硬件加速的开源抓取工具包最近在折腾一些数据采集和自动化任务时,我常常遇到一个瓶颈:当需要处理海量网页、进行高频次请求或者解析复杂的动态内容时,传统的基于CPU的抓取框架(比如Scrapy、Reques…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

XUnity自动翻译器:打破语言壁垒的终极Unity游戏汉化解决方案
XUnity自动翻译器:打破语言壁垒的终极Unity游戏汉化解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过精彩的游戏剧情?是否在面对日文RPG或英文…...