【Python查找算法】二分查找、线性查找、哈希查找
目录
1 二分查找算法
2 线性查找算法
3 哈希查找算法
1 二分查找算法
二分查找(Binary Search)是一种用于在有序数据集合中查找特定元素的高效算法。它的工作原理基于将数据集合分成两半,然后逐步缩小搜索范围,直到找到目标元素或确定目标元素不存在。
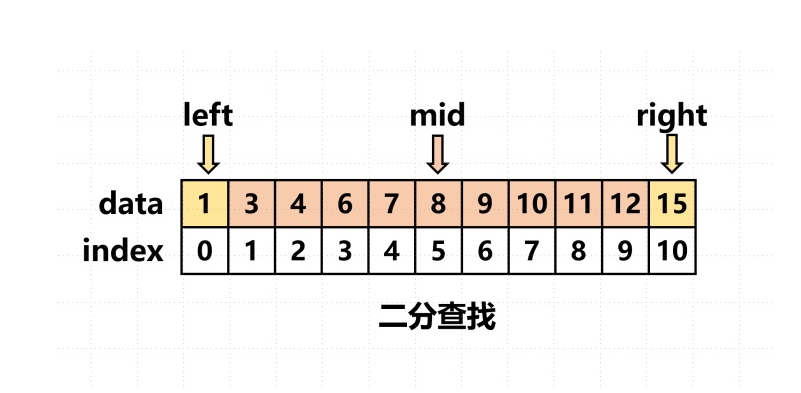
以下是二分查找的工作原理的详细说明:
有序数据集合:首先,数据集合必须是有序的,通常是按升序或降序排列的。这一点非常重要,因为二分查找的核心思想是根据中间元素与目标元素的大小关系来确定搜索范围。
初始化指针:初始化两个指针,一个指向数据集合的第一个元素(左指针),另一个指向最后一个元素(右指针)。
确定中间元素:计算左指针和右指针的中间位置,即
(left + right) // 2。这将确定搜索区域的中间元素。比较中间元素:将中间元素与目标元素进行比较:
- 如果中间元素等于目标元素,搜索成功,返回中间元素的索引。
- 如果中间元素大于目标元素,说明目标元素应该在左半部分,将右指针移到中间元素的左侧一位,即
right = mid - 1。- 如果中间元素小于目标元素,说明目标元素应该在右半部分,将左指针移到中间元素的右侧一位,即
left = mid + 1。重复步骤3和4:在每次比较后,缩小搜索范围,继续比较直到找到目标元素或搜索范围为空(即左指针大于右指针)。
返回结果:如果找到目标元素,返回它的索引;如果搜索范围为空仍未找到目标元素,返回一个指示未找到的值(通常是 -1)。
以下是一个简单的示例,演示如何使用二分查找在有序数组中查找目标元素:
def binary_search(arr, target):left, right = 0, len(arr) - 1 # 初始化左右指针,分别指向数组的起始和结束位置while left <= right: # 当左指针不大于右指针时,继续搜索mid = (left + right) // 2 # 计算中间位置if arr[mid] == target: # 如果中间元素等于目标元素,搜索成功return mid # 返回中间元素的索引elif arr[mid] < target: # 如果中间元素小于目标元素,说明目标在右半部分left = mid + 1 # 移动左指针到中间元素的右侧一位else: # 否则,目标在左半部分right = mid - 1 # 移动右指针到中间元素的左侧一位return -1 # 如果搜索范围为空仍未找到目标元素,返回 -1 表示未找到# 示例用法
sorted_list = [1, 2, 3, 4, 7, 9]
target_element = 7
result = binary_search(sorted_list, target_element)
if result != -1:print(f"元素 {target_element} 在索引 {result} 处找到。")
else:print("元素未找到。")
上述代码演示了如何使用二分查找在有序列表
sorted_list中查找目标元素7。根据工作原理,二分查找的时间复杂度为 O(log n),其中 n 是数据集合的大小,这使得它非常适合在大型有序数据集合中查找目标元素。
2 线性查找算法
线性查找(Linear Search)是一种简单的搜索算法,也称为顺序查找。它的工作原理是逐个遍历数据集合中的元素,直到找到匹配的元素或遍历整个集合。
原理:
从数据集合的第一个元素开始,逐个检查每个元素,直到找到匹配的元素或遍历整个集合。
如果找到与目标元素匹配的元素,返回该元素的索引(位置)。
如果遍历整个集合都没有找到匹配的元素,返回特定的“未找到”值(通常是 -1)。
以下是线性查找的原理示例:
数据集合: [2, 4, 7, 1, 9, 3]
要查找的元素: 7初始状态:↓
[2, 4, 7, 1, 9, 3]^第一次比较:元素 2 与目标 7 不匹配,继续下一个元素。↓
[2, 4, 7, 1, 9, 3]^第二次比较:元素 4 与目标 7 不匹配,继续下一个元素。↓
[2, 4, 7, 1, 9, 3]^第三次比较:元素 7 与目标 7 匹配,找到了目标元素。↓
[2, 4, 7, 1, 9, 3]^目标元素 7 找到在索引 2 处。
上述示意图演示了如何使用线性查找在给定的数据集合中查找目标元素 7。算法从数据集合的第一个元素开始逐个比较,直到找到匹配的元素或遍历整个集合。
这个示意图反映了线性查找的工作原理,即逐个遍历数据元素以寻找匹配项。如果目标元素存在于数据集合中,线性查找将找到该元素的索引。如果目标元素不存在,则遍历整个数据集合后返回特定的未找到值(通常是 -1)。
以下是一个Python线性查找示例代码:
def linear_search(arr, target):"""线性查找函数Parameters:- arr: 待查找的列表- target: 要查找的目标元素Returns:- 如果找到目标元素,返回其索引;否则返回 -1。"""for i in range(len(arr)): # 遍历列表中的每个元素if arr[i] == target: # 如果当前元素与目标元素匹配return i # 返回匹配元素的索引return -1 # 如果遍历完整个列表未找到匹配元素,返回 -1 表示未找到# 示例用法
my_list = [2, 4, 7, 1, 9, 3]
target_element = 7result = linear_search(my_list, target_element) # 调用线性查找函数if result != -1:print(f"元素 {target_element} 在索引 {result} 处找到。")
else:print("元素未找到。")
在上述代码中,
linear_search函数用于执行线性查找。它接受两个参数:要查找的列表arr和目标元素target。函数逐个遍历列表中的元素,如果找到匹配的元素,则返回匹配元素的索引;如果遍历完整个列表都没有找到匹配元素,则返回 -1 表示未找到。示例用法演示了如何调用
linear_search函数来查找目标元素7在列表my_list中的位置。如果找到目标元素,程序将打印出找到的索引,否则打印 "元素未找到。"。
3 哈希查找算法
哈希查找(Hash Search)是一种高效的搜索算法,它利用哈希函数将键映射到存储位置,并在该位置查找目标元素。哈希查找适用于快速查找和检索,特别适用于大型数据集合。以下是哈希查找的详细解释和示例:
工作原理:
哈希表:哈希查找的核心是哈希表,它是一个数据结构,由键-值对组成。哈希表内部使用哈希函数将键转换为存储位置(索引),然后将键和值存储在该位置。
哈希函数:哈希函数接受一个键作为输入,并生成一个索引(位置),通常是一个整数。好的哈希函数应该具有以下特性:
- 对于相同的输入键,始终生成相同的索引。
- 将不同的输入键均匀地映射到不同的索引,以减少冲突。
- 生成的索引应尽可能分散,以降低冲突的可能性。
查找过程:要查找目标元素,哈希函数首先计算目标元素的哈希值(索引),然后在哈希表的该位置查找对应的值。如果找到匹配的值,查找成功;否则,表示未找到目标元素。
示例代码:
以下是一个使用Python的哈希查找示例代码,我们将使用字典作为哈希表来演示:
# 创建一个哈希表(字典)
my_dict = {'apple': 3, 'banana': 2, 'cherry': 5, 'date': 1, 'grape': 4}# 要查找的目标键
target_key = 'banana'# 使用哈希查找
if target_key in my_dict:value = my_dict[target_key]print(f"The value of {target_key} is {value}")
else:print(f"{target_key} not found")
在上述示例中,我们首先创建了一个哈希表
my_dict,其中包含键-值对。然后,我们定义了要查找的目标键target_key为'banana'。通过使用哈希查找,我们可以直接访问哈希表中的值,而不需要逐个遍历整个集合。如果目标键存在于哈希表中,我们将获得与该键关联的值。请注意,哈希查找的效率非常高,因为它通常具有常量时间复杂度 O(1)。然而,哈希函数的设计和解决冲突的方法对算法的性能至关重要。合适的哈希函数和处理冲突的方法可以确保高效的哈希查找。
4 应用
-
线性查找(Linear Search):
- 工作原理:逐个遍历数据集合,查找目标元素。
- 应用:适用于小型无序数据集合,或当数据无序且不频繁查找时。常见于简单的列表或数组。
-
二分查找(Binary Search):
- 工作原理:适用于有序数据集合,将数据集合分成两半,逐步缩小搜索范围。
- 应用:适用于大型有序数据集合,如数组或有序列表。常见于数据库索引等高效查找场景。
-
哈希查找(Hash Search):
- 工作原理:通过哈希函数将键映射到存储位置,查找时直接访问该位置。
- 应用:适用于快速查找,如字典、散列表(哈希表)等数据结构。常用于处理大量数据的快速索引。
-
二叉搜索树查找(Binary Search Tree Search):
- 工作原理:通过二叉搜索树的有序性,在左子树或右子树中查找目标元素。
- 应用:适用于维护有序数据集合,如数据库索引、字典实现等
相关文章:
【Python查找算法】二分查找、线性查找、哈希查找
目录 1 二分查找算法 2 线性查找算法 3 哈希查找算法 1 二分查找算法 二分查找(Binary Search)是一种用于在有序数据集合中查找特定元素的高效算法。它的工作原理基于将数据集合分成两半,然后逐步缩小搜索范围,直到找到目标元素…...
【MySQL实战45讲-基础篇】
基础篇 基础架构 MySQL的基本架构示意图:MySQL可以分为Server层和存储引擎层两部分。 Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函…...

asp.net core中间件预防防止xss攻击
using System; using System.Text.Json; using System.Text.Json.Serialization;namespace CommonUtils {/// <summary>/// newtonsoft的转化器/// 防止xss攻击/// </summary>public class AntiXssNewtonsoftConverter : Newtonsoft.Json.JsonConverter<string&…...

jvm概述
1、JVM体系结构 2、JVM运行时数据区 3、JVM内存模型 JVM运行时内存 共享内存区 线程内存区 3.1、共享内存区 共享内存区 持久带(方法区 其他) 堆(Old Space Young Space(den S0 S1)) 持久代: JVM用持久带(Permanent Space)实现方法…...
C++简单上手helloworld 以及 vscode找不到文件的可能性原因
helloworld #include <iostream>int main() {std::cout << "hello world!" << std::endl;return 0; }输入输出小功能 #include <iostream> using namespace std; /* *主函数 *输出一条语句 */int main() {// 输出一条语句cout << &q…...

掌动智能:性能压力测试的重要性
采用性能压力测试可以帮助企业预估系统容量、提升用户体验以及降低风险和成本。在软件开发过程中,将性能压力测试纳入测试策略的重要一环,将为企业的成功和用户满意度打下坚实的基础。 性能压力测试的重要性: 一、发现性能瓶颈 性能压力测试能…...
kafka日志文件详解及生产常见问题总结
一、kafka的log日志梳理 日志文件是kafka根目录下的config/server.properties文件,配置log.dirs/usr/local/kafka/kafka-logs,kafka一部分数据包含当前Broker节点的消息数据(在Kafka中称为Log日志),称为无状态数据,另外一部分存在…...

Linux-Centos中配置docker
1.安装yum工具 yum install -y yum-utils 2.配置yam源头 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 3.安装docker yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin 4. 查看d…...
IDEA-2023-jdk8 HelloWorld的实现
目录 1 新建Project - Class 2 编写代码 3 运行 1 新建Project - Class 选择"New Project": 指名工程名、使用的JDK版本等信息。如下所示: 接着创建Java类: 2 编写代码 public class HelloWorld {public static void main(S…...
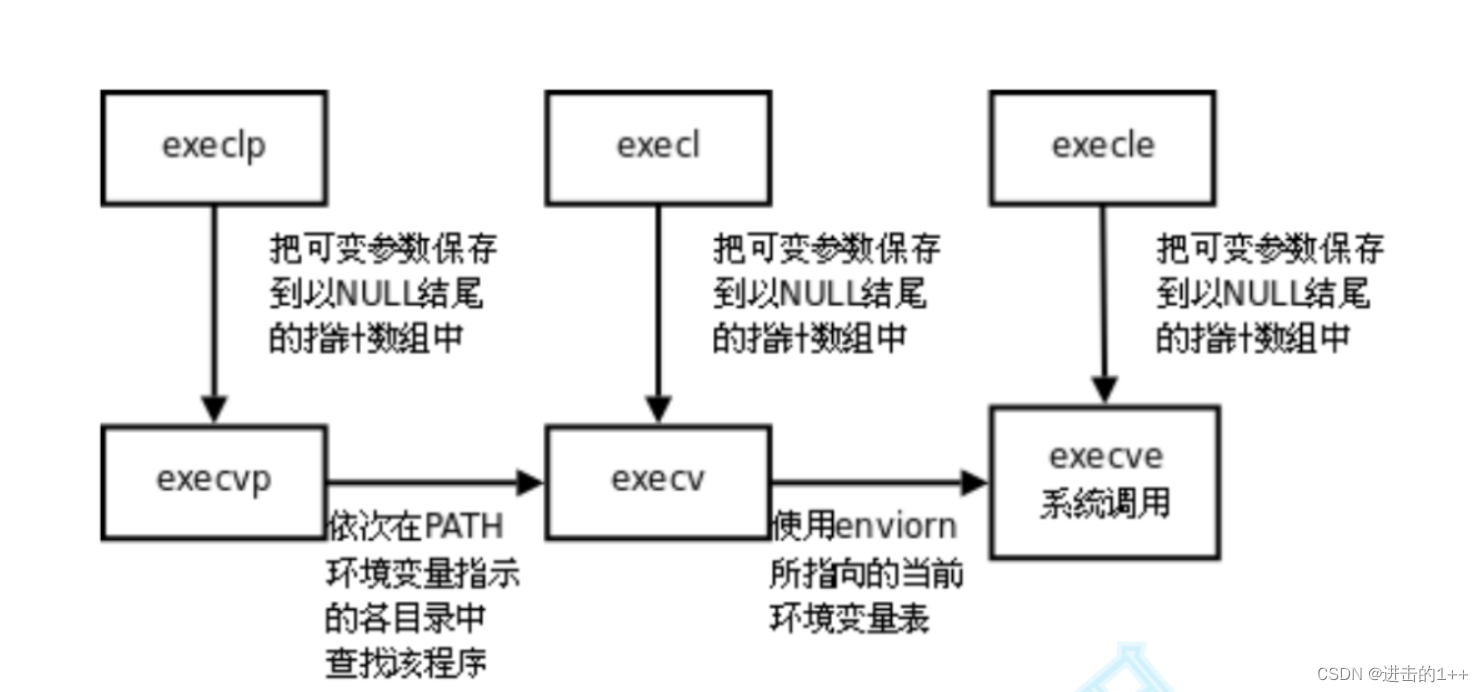
【1++的Linux】之进程(五)
👍作者主页:进击的1 🤩 专栏链接:【1的Linux】 文章目录 一,什么是进程替换二,替换函数三,实现我们自己的shell 一,什么是进程替换 我们创建出来进程是要其做事情的,它可…...

用url类来访问服务器上的文件
场景一: package com.guonian.miaosha;import java.io.BufferedReader; import java.io.File; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL;…...
【重拾C语言】六、批量数据组织(二)线性表——分类与检索(主元排序、冒泡排序、插入排序、顺序检索、对半检索)
目录 前言 六、批量数据组织——数组 6.1~3 数组基础知识 6.4 线性表——分类与检索 6.4.1 主元排序 6.4.2 冒泡排序 6.4.3 插入排序 6.4.4 顺序检索(线性搜索) 6.4.5 对半检索(二分查找) 算法比较 前言 线性表是一种常…...

24 Python的sqlite3模块
概述 在上一节,我们介绍了Python的shutil模块,包括:shutil模块中一些常用的函数。在这一节,我们将介绍Python的sqlite3模块。sqlite3模块是Python中的内置模块,用于与SQLite数据库交互。SQLite是一个轻量级的磁盘数据库…...

ARM-流水灯
.text .global _start _start: 1、设置GPIOE寄存器的时钟使能 RCC_MP_AHB$ENSETR[4]->1 0x50000a28LDR R0,0X50000A28 LDR R1,[R0] 从R0起始地址的4字节数据取出放在R1 ORR R1,R1,#(0X3<<4) 第4位设置为1 STR R1,[R0] 写回2、设置PE10、PE8、PF10管脚为输出模式 …...

【虚拟机】NAT 模式下访问外网
目录 一、NAT 模式的作用原理 二、配置 NAT 模式实现外网访问 1、配置NAT模式的网段 2、虚拟机选择 VMnet8 网卡 3、IP地址设为自动分配 一、NAT 模式的作用原理 NAT模式下,虚拟机的系统会把宿主机当作一个大路由器,发送的网络请求和数据都是先发给…...
React 入门笔记
前言 国庆值班把假期拆了个稀碎, 正好不用去看人潮人海, 趁机会赶个晚集入门一下都火这么久的 React 前端技术. 话说其实 n 年前也了解过一丢丢来着, 当时看到一上来就用 JS 写 DOM 的套路直接就给吓退了, 扭头还去看 Vue 了🤣, 现在从市场份额 社区活度来看, 确实…...
Ubuntu MySQL
在安装前,首先看你之前是否安装过,如果安装过,但是没成功,就要先卸载。 一、卸载 1.查看安装 dpkg --list | grep mysql 有东西,就说明您之前安装过mysql。 2.卸载 先停掉server sudo systemctl stop mysql.servic…...

大数据软件系统开发框架
大数据处理框架是用于处理大规模数据集的软件工具和平台,它们可以帮助分析、存储和处理庞大的数据量。以下是一些常见的大数据处理框架,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.A…...

rust变量
一 、变量定义 (一)语法格式 使用let关键字定义变量 let varname: type value; 如,let a: i32 78;也可以不显式指定类型 let varname value; 如,let a 78;一些例子 1.布尔 let t true; let f: bool false;2.整数 let a …...

蓝桥杯---第一讲 递归与递推
文章目录 前言Ⅰ. 递归实现指数型枚举0x00 算法思路0x00 代码书写0x00 思考总结 Ⅱ. 递归实现排列型枚举0x00 算法思路0x01代码书写0x02 思考总结 Ⅲ. 简单斐波那契0x00 算法思路0x01 代码书写 Ⅳ. 费解的开关0x00 算法思路0x01 代码书写 Ⅴ. 递归实现组合型枚举0x00 算法思路0…...

【独家】Lindy内部SLO白皮书泄露:自主工作流SLA达标率低于99.95%的5个致命信号
更多请点击: https://intelliparadigm.com 第一章:Lindy AI Agent自主工作流的核心架构与SLO哲学 Lindy AI Agent 的核心架构基于“自治闭环”(Autonomous Closed Loop)范式,将任务规划、工具调用、状态反馈与自校准能…...

TinyRedis随笔
在TinyRedis的内存与AOF之间的关系中,AOF接入点在命令层中,因为只有在执行写命令,修改DB内存之后,再对AOF文件进行写入。但是这里也存在一个问题,如果对aof文件写入失败了呢,那就会造成内存与aof文件数据不…...

感统训练的真实效果能持续多久?会不会反弹?
直接给出结论:常见的感统训练维持周期短、反弹率高,多数孩子训练效果仅能保持3-6个月。一旦停止课程,大部分孩子会逐步退回原有状态。感统只能调整身体感官反应,无法从根源提升大脑自控力,治标不治本。感统训练适用人…...

AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则”
AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则” 在当今高性能计算和复杂SoC设计中,AXI协议已成为连接处理器、存储器和外设的黄金标准。但真正理解AXI的精髓,远不止于掌握基础操作——那些隐藏在规范字里…...

VLC源码深度定制:3大核心模块解析与编译实践
VLC源码深度定制:3大核心模块解析与编译实践 【免费下载链接】vlc VLC media player - All pull requests are ignored, please use MRs on https://code.videolan.org/videolan/vlc 项目地址: https://gitcode.com/gh_mirrors/vl/vlc 你是否曾想过ÿ…...

构建多模型对比评测工具时集成Taotoken的统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型对比评测工具时集成Taotoken的统一接口 在模型选型、效果验证或学术研究过程中,开发者或研究者常常需要并行…...

oh-my-prompt:模块化、高性能的终端提示符配置方案
1. 项目概述:一个为现代开发者量身打造的终端提示符如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么终端提示符(Prompt)就是你最亲密的“工作伙伴”。它不仅仅是那个闪…...

原神模型导入终极指南:GIMI深度定制框架完全解析
原神模型导入终极指南:GIMI深度定制框架完全解析 【免费下载链接】GI-Model-Importer Tools and instructions for importing custom models into a certain anime game 项目地址: https://gitcode.com/gh_mirrors/gi/GI-Model-Importer 原神模型导入&#x…...

3分钟搞定!Windows网络测速神器iperf3完整使用指南
3分钟搞定!Windows网络测速神器iperf3完整使用指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds 还在为网络速度不稳定而烦恼吗&#…...

解放双手:D3KeyHelper让暗黑3游戏操作变得前所未有的简单
解放双手:D3KeyHelper让暗黑3游戏操作变得前所未有的简单 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑3中繁琐的技能循环和…...