【MySQL实战45讲-基础篇】
基础篇
基础架构
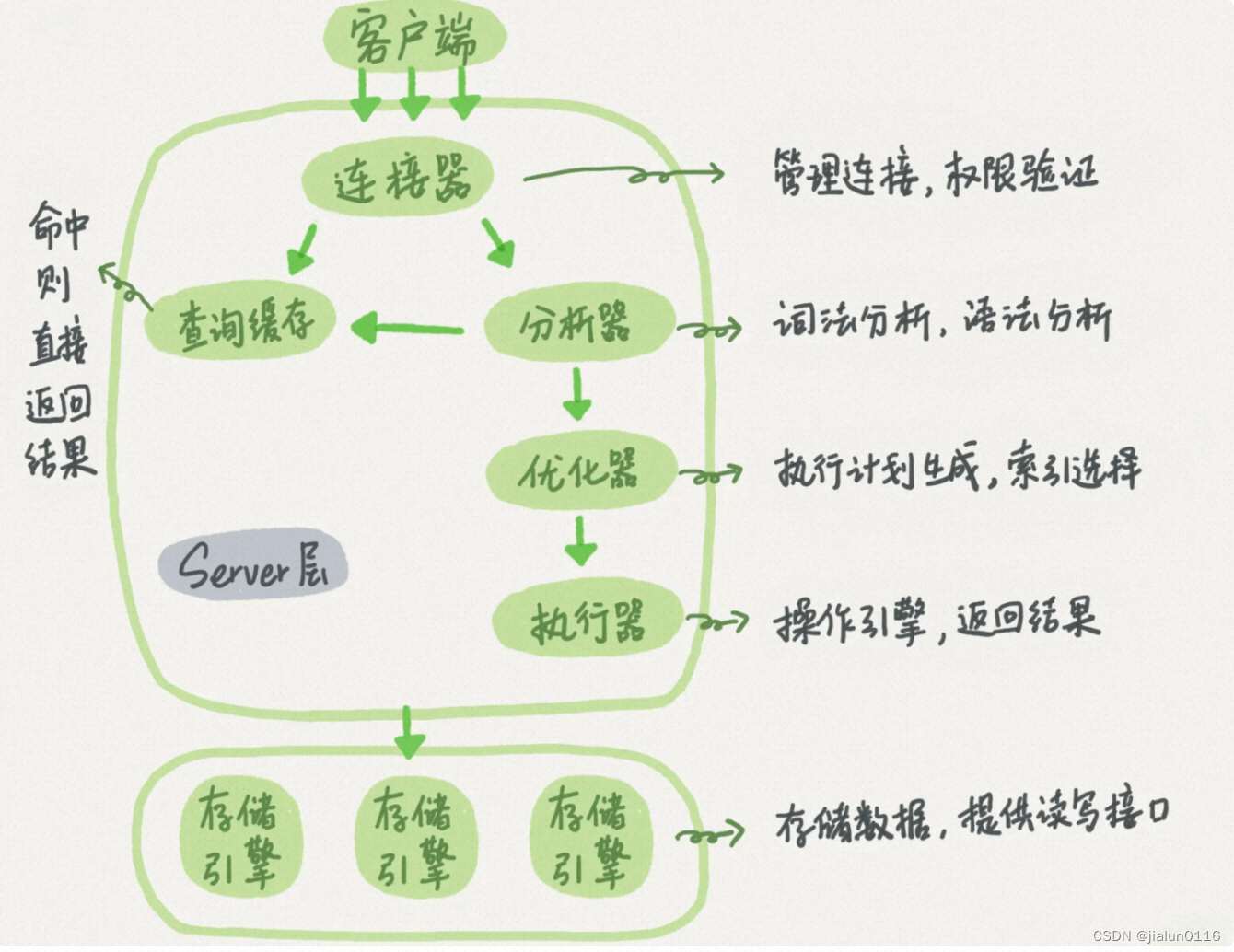
MySQL的基本架构示意图:MySQL可以分为Server层和存储引擎层两部分。
- Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎。
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
引擎扫描行数跟rows_examined并不是完全相同的
重要的日志模块:redo log
不知道你还记不记得《孔乙己》这篇文章,酒店掌柜有一个粉板,专门用来记录客人的赊账记录。如果赊账的人不多,那么他可以把顾客名和账目写在板上。但如果赊账的人多了,粉板总会有记不下的时候,这个时候掌柜一定还有一个专门记录赊账的账本。
如果有人要赊账或者还账的话,掌柜一般有两种做法:
- 一种做法是直接把账本翻出来,把这次赊的账加上去或者扣除掉;
- 另一种做法是先在粉板上记下这次的账,等打烊以后再把账本翻出来核算。
在生意红火柜台很忙时,掌柜一定会选择后者,因为前者操作实在是太麻烦了。首先,你得找到这个人的赊账总额那条记录。你想想,密密麻麻几十页,掌柜要找到那个名字,可能还得带上老花镜慢慢找,找到之后再拿出算盘计算,最后再将结果写回到账本上。
MySQL里经常说到的WAL技术,WAL的全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘,也就是先写粉板,等不忙的时候再写账本。具体来说,当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log(粉板)里面,并更新内存,这个时候更新就算完成了。同时,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么这块“粉板”总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写

- write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。checkpoint是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
- write pos和checkpoint之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果write pos追上checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把checkpoint推进一下。
- 有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
重要的日志模块:binlog
一块是Server层,它主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板redo log是InnoDB引擎特有的日志,而Server层也有自己的日志,称为binlog(归档日志)。
这两种日志有以下三点不同。
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
- redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
- redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
- binlog用于数据备份还原以及同步,redolog用于保证事务,从故障中恢复数据
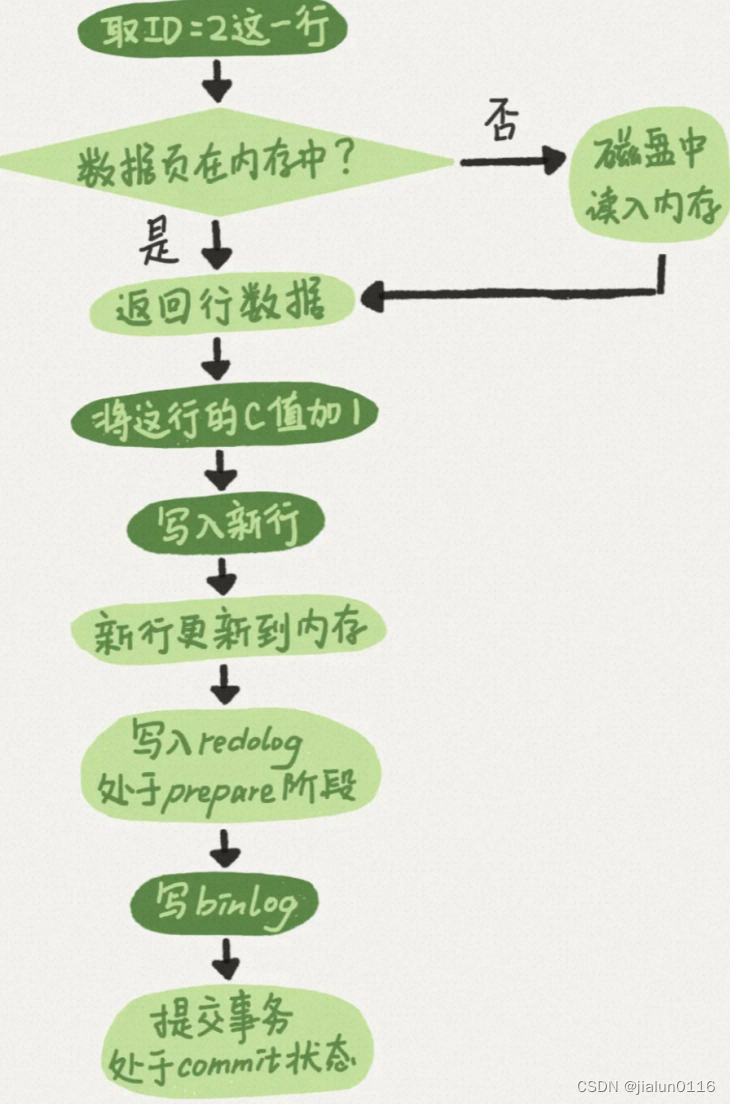
执行器和InnoDB引擎在执行这个简单的update语句时的内部流程。
- 执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的binlog,并把binlog写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
怎样让数据库恢复到半个月内任意一秒的状态?
binlog会记录所有的逻辑操作,并且是采用“追加写”的形式,同时系统会定期做整库备份。
假设当前ID=2的行,字段c的值是0,再假设执行update语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了crash,会出现什么情况呢?
先写redo log后写binlog。假设在redo log写完,binlog还没有写完的时候,MySQL进程异常重启。由于我们前面说过的,redo log写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行c的值是1。 但是由于binlog没写完就crash了,这时候binlog里面就没有记录这个语句。因此,之后备份日志的时候,存起来的binlog里面就没有这条语句。
先写binlog后写redo log。如果在binlog写完之后crash,由于redo log还没写,崩溃恢复以后这个事务无效,所以这一行c的值是0。但是binlog里面已经记录了“把c从0改成1”这个日志。所以,在之后用binlog来恢复的时候就多了一个事务出来,恢复出来的这一行c的值就是1,与原库的值不同。
redo log和binlog都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
binlog用于数据备份还原以及同步,redolog用于保证事务,从故障中恢复数据。RTO(恢复目标时间)
事务
提到事务,你肯定会想到ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),今天我们就来说说其中I,也就是“隔离性”。可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
你隔离得越严实,效率就会越低,SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )。
下面我逐一为你解释:
-
读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
-
读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
-
可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
-
串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
-
-
若隔离级别是“读未提交”, 则V1的值就是2。这时候事务B虽然还没有提交,但是结果已经被A看到了。因此,V2、V3也都是2。
-
若隔离级别是“读提交”,则V1是1,V2的值是2。事务B的更新在提交后才能被A看到。所以, V3的值也是2。
-
若隔离级别是“可重复读”,则V1、V2是1,V3是2。之所以V2还是1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
-
若隔离级别是“串行化”,则在事务B执行“将1改成2”的时候,会被锁住。直到事务A提交后,事务B才可以继续执行。所以从A的角度看, V1、V2值是1,V3的值是2。
你可能会问那什么时候需要“可重复读”的场景呢?我们来看一个数据校对逻辑的案例。
假设你在管理一个个人银行账户表。一个表存了账户余额,一个表存了账单明细。到了月底你要做数据校对,也就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一致。你一定希望在校对过程中,即使有用户发生了一笔新的交易,也不影响你的校对结果。这时候使用“可重复读”隔离级别就很方便。事务启动时的视图可以认为是静态的,不受其他事务更新的影响。
事务的实现
理解了事务的隔离级别,我们再来看看事务隔离具体是怎么实现的。这里我们展开说明“可重复读”。
在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。
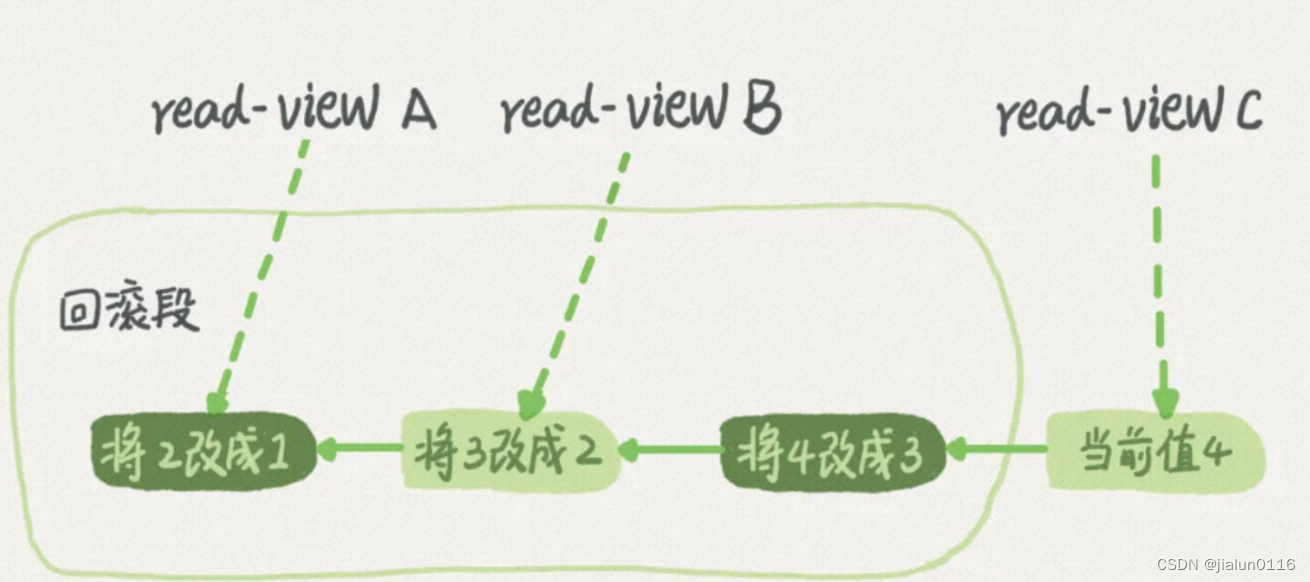
当前值是4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的read-view。如图中看到的,在视图A、B、C里面,这一个记录的值分别是1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于read-view A,要得到1,就必须将当前值依次执行图中所有的回滚操作得到。
事务的启动
- 显式启动事务语句, begin 或 start transaction。配套的提交语句是commit,回滚语句是rollback。
- set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个select语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行commit 或 rollback 语句,或者断开连接。
有些客户端连接框架会默认连接成功后先执行一个set autocommit=0的命令。这就导致接下来的查询都在事务中,如果是长连接,就导致了意外的长事务。
但是有的开发同学会纠结“多一次交互”的问题。对于一个需要频繁使用事务的业务,第二种方式每个事务在开始时都不需要主动执行一次 “begin”,减少了语句的交互次数。如果你也有这个顾虑,我建议你使用commit work and chain语法。
在autocommit为1的情况下,用begin显式启动的事务,如果执行commit则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行begin语句的开销。同时带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。
你可以在information_schema库的innodb_trx这个表中查询长事务,比如下面这个语句,用于查找持续时间超过60s的事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
索引
三种常见、也比较简单的数据结构,它们分别是哈希表、有序数组和搜索树。
- 哈希索引做区间查询的速度是很慢的哈希表这种结构适用于只有等值查询的场景,比如Memcached及其他一些NoSQL引擎。
- 而有序数组在等值查询和范围查询场景中的性能就都非常优秀,有序数组索引只适用于静态存储引擎,插入删除修改等操作很费时间
- 二叉搜索树的特点是:父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。这样如果你要查ID_card_n2的话,按照图中的搜索顺序就是按照UserA -> UserC -> UserF -> User2这个路径得到。这个时间复杂度是O(log(N))。
 但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。这里,“N叉”树中的“N”取决于数据块的大小。你可以想象一下一棵100万节点的平衡二叉树,树高20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要20个10 ms的时间,这个查询可真够慢的。
但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。这里,“N叉”树中的“N”取决于数据块的大小。你可以想象一下一棵100万节点的平衡二叉树,树高20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要20个10 ms的时间,这个查询可真够慢的。
以InnoDB的一个整数字段索引为例,这个N差不多是1200。这棵树高是4的时候,就可以存1200的3次方个值,这已经17亿了。考虑到树根的数据块总是在内存中的,一个10亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为二级索引(secondary index)。
- 显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
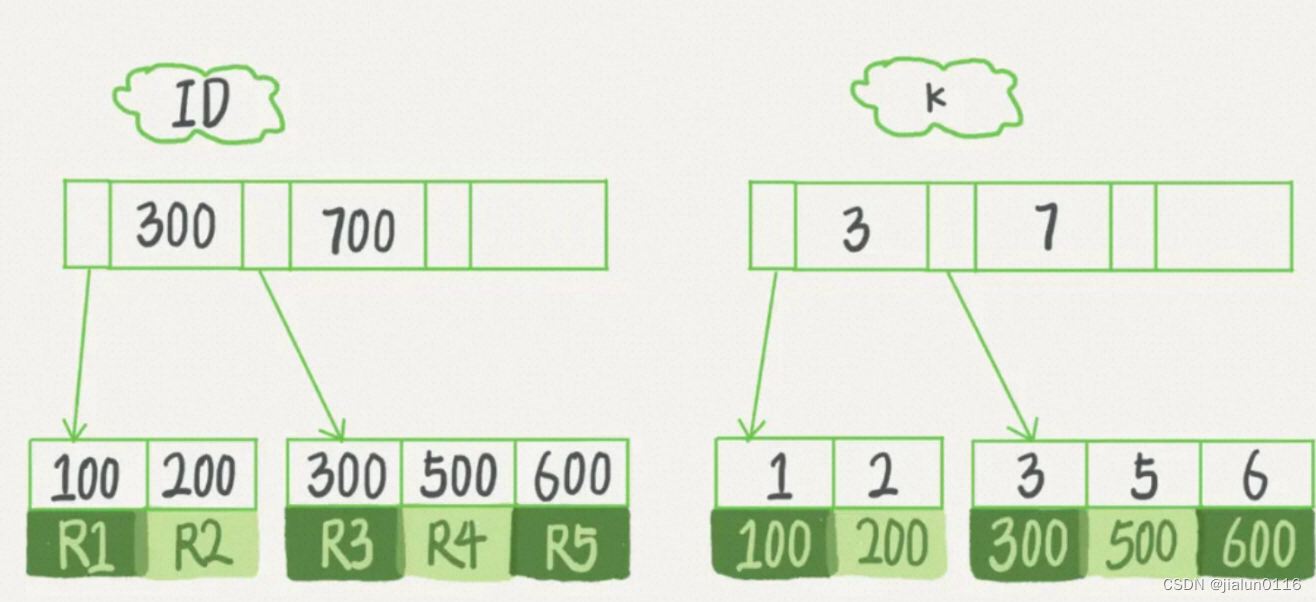
根据上面的索引结构说明,我们来讨论一个问题:基于主键索引和普通索引的查询有什么区别? - 如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
- 如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
- 自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
- 而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
B+树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
对于上面例子中的InnoDB表T,如果你要重建索引 k,你的两个SQL语句可以这么写:
altertable T drop index k;
altertable T add index(k);
如果你要重建主键索引,也可以这么写:
altertable T dropprimarykey;
altertable T addprimarykey(id);
我的问题是,对于上面这两个重建索引的作法,说出你的理解。如果有不合适的,为什么,更好的方法是什么? 重建索引k的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table T engine=InnoDB
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。在这个查询里面,索引k已经“覆盖了”我们的查询需求,我们称为覆盖索引。
B+树这种索引结构,可以利用索引的“最左前缀”,来定位记录。不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
在建立联合索引的时候,如何安排索引内的字段顺序。这里我们的评估标准是,索引的复用能力。因为可以支持最左前缀,所以当已经有了(a,b)这个联合索引后,一般就不需要单独在a上建立索引了。因此,第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
全局锁和表锁
根据加锁的范围,MySQL里面的锁大致可以分成全局锁、表级锁和行锁三类
1.全局锁
MySQL提供了一个加全局读锁的方法,命令是 Flush tables with read lock (FTWRL)。当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
让整库都只读,听上去就很危险:
● 如果你在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆;
● 如果你在从库上备份,那么备份期间从库不能执行主库同步过来的binlog,会导致主从延迟。
全局锁的典型使用场景是,做全库逻辑备份。也就是把整库每个表都select出来存成文本。
官方自带的逻辑备份工具是mysqldump。当mysqldump使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的。
你一定在疑惑,有了这个功能,为什么还需要FTWRL呢?一致性读是好,但前提是引擎要支持这个隔离级别。比如,对于MyISAM这种不支持事务的引擎,如果备份过程中有更新,总是只能取到最新的数据,那么就破坏了备份的一致性。这时,我们就需要使用FTWRL命令了。
所以,single-transaction方法只适用于所有的表使用事务引擎的库。如果有的表使用了不支持事务的引擎,那么备份就只能通过FTWRL方法。这往往是DBA要求业务开发人员使用InnoDB替代MyISAM的原因之一。
既然要全库只读,为什么不使用set global readonly=true的方式呢?确实readonly方式也可以让全库进入只读状态,但我还是会建议你用FTWRL方式,主要有两个原因:
- 在有些系统中,readonly的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改global变量的方式影响面更大,我不建议你使用。
- 在异常处理机制上有差异。如果执行FTWRL命令之后由于客户端发生异常断开,那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为readonly之后,如果客户端发生异常,则数据库就会一直保持readonly状态,这样会导致整个库长时间处于不可写状态,风险较高。
业务的更新不只是增删改数据(DML),还有可能是加字段等修改表结构的操作(DDL)。不论是哪种方法,一个库被全局锁上以后,你要对里面任何一个表做加字段操作,都是会被锁住的。
2. 表锁
MySQL里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
表锁的语法是 lock tables … read/write。lock tables语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
举个例子, 如果在某个线程A中执行lock tables t1 read, t2 write; 这个语句,则其他线程写t1、读写t2的语句都会被阻塞。同时,线程A在执行unlock tables之前,也只能执行读t1、读写t2的操作。连写t1都不允许,自然也不能访问其他表。
另一类表级的锁是MDL(metadata lock)。MDL不需要显式使用,在访问一个表的时候会被自动加上。MDL的作用是,保证读写的正确性,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
● 读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
● 读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
事务中的MDL锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
基于上面的分析,我们来讨论一个问题,如何安全地给小表加字段?
首先我们要解决长事务,事务不提交,就会一直占着MDL锁。在MySQL的information_schema 库的 innodb_trx 表中,你可以查到当前执行中的事务。如果你要做DDL变更的表刚好有长事务在执行,要考虑先暂停DDL,或者kill掉这个长事务。
但考虑一下这个场景。如果你要变更的表是一个热点表,虽然数据量不大,但是上面的请求很频繁,而你不得不加个字段,你该怎么做呢?
这时候kill可能未必管用,因为新的请求马上就来了。比较理想的机制是,在alter table语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者DBA再通过重试命令重复这个过程。
ALTER TABLE tbl_name WAIT N add column …
MDL会直到事务提交才释放,在做表结构变更的时候,你一定要小心不要导致锁住线上查询和更新。
3. 行锁
并不是所有的引擎都支持行锁,比如MyISAM引擎就不支持行锁。不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有一个更新在执行,这就会影响到业务并发度
行锁就是针对数据表中行记录的锁。这很好理解,比如事务A更新了一行,而这时候事务B也要更新同一行,则必须等事务A的操作完成后才能进行更新。
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
死锁和死锁检测
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁。这里我用数据库中的行锁举个例子。
当出现死锁以后,有两种策略:
- 一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数innodb_lock_wait_timeout来设置。
- 另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数innodb_deadlock_detect设置为on,表示开启这个逻辑。
在InnoDB中,innodb_lock_wait_timeout的默认值是50s,意味着如果采用第一个策略,当出现死锁以后,第一个被锁住的线程要过50s才会超时退出,然后其他线程才有可能继续执行。对于在线服务来说,这个等待时间往往是无法接受的。
每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是O(n)的操作。假设有1000个并发线程要同时更新同一行,那么死锁检测操作就是100万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的CPU资源。因此,你就会看到CPU利用率很高,但是每秒却执行不了几个事务。
怎么解决由这种热点行更新导致的性能问题呢?问题的症结在于,死锁检测要耗费大量的CPU资源。
- 一种头痛医头的方法,就是如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。但是这种操作本身带有一定的风险,因为业务设计的时候一般不会把死锁当做一个严重错误,毕竟出现死锁了,就回滚,然后通过业务重试一般就没问题了,这是业务无损的。而关掉死锁检测意味着可能会出现大量的超时,这是业务有损的。
- 另一个思路是控制并发度。根据上面的分析,你会发现如果并发能够控制住,比如同一行同时最多只有10个线程在更新,那么死锁检测的成本很低,就不会出现这个问题。一个直接的想法就是,在客户端做并发控制。但是,你会很快发现这个方法不太可行,因为客户端很多。我见过一个应用,有600个客户端,这样即使每个客户端控制到只有5个并发线程,汇总到数据库服务端以后,峰值并发数也可能要达到3000。
- 考虑通过将一行改成逻辑上的多行来减少锁冲突。还是以影院账户为例,可以考虑放在多条记录上,比如10个记录,影院的账户总额等于这10个记录的值的总和。这样每次要给影院账户加金额的时候,随机选其中一条记录来加。这样每次冲突概率变成原来的1/10,可以减少锁等待个数,也就减少了死锁检测的CPU消耗。这个方案看上去是无损的,但其实这类方案需要根据业务逻辑做详细设计。如果账户余额可能会减少,比如退票逻辑,那么这时候就需要考虑当一部分行记录变成0的时候,代码要有特殊处理。
相关文章:
【MySQL实战45讲-基础篇】
基础篇 基础架构 MySQL的基本架构示意图:MySQL可以分为Server层和存储引擎层两部分。 Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函…...

asp.net core中间件预防防止xss攻击
using System; using System.Text.Json; using System.Text.Json.Serialization;namespace CommonUtils {/// <summary>/// newtonsoft的转化器/// 防止xss攻击/// </summary>public class AntiXssNewtonsoftConverter : Newtonsoft.Json.JsonConverter<string&…...

jvm概述
1、JVM体系结构 2、JVM运行时数据区 3、JVM内存模型 JVM运行时内存 共享内存区 线程内存区 3.1、共享内存区 共享内存区 持久带(方法区 其他) 堆(Old Space Young Space(den S0 S1)) 持久代: JVM用持久带(Permanent Space)实现方法…...
C++简单上手helloworld 以及 vscode找不到文件的可能性原因
helloworld #include <iostream>int main() {std::cout << "hello world!" << std::endl;return 0; }输入输出小功能 #include <iostream> using namespace std; /* *主函数 *输出一条语句 */int main() {// 输出一条语句cout << &q…...

掌动智能:性能压力测试的重要性
采用性能压力测试可以帮助企业预估系统容量、提升用户体验以及降低风险和成本。在软件开发过程中,将性能压力测试纳入测试策略的重要一环,将为企业的成功和用户满意度打下坚实的基础。 性能压力测试的重要性: 一、发现性能瓶颈 性能压力测试能…...
kafka日志文件详解及生产常见问题总结
一、kafka的log日志梳理 日志文件是kafka根目录下的config/server.properties文件,配置log.dirs/usr/local/kafka/kafka-logs,kafka一部分数据包含当前Broker节点的消息数据(在Kafka中称为Log日志),称为无状态数据,另外一部分存在…...

Linux-Centos中配置docker
1.安装yum工具 yum install -y yum-utils 2.配置yam源头 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 3.安装docker yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin 4. 查看d…...
IDEA-2023-jdk8 HelloWorld的实现
目录 1 新建Project - Class 2 编写代码 3 运行 1 新建Project - Class 选择"New Project": 指名工程名、使用的JDK版本等信息。如下所示: 接着创建Java类: 2 编写代码 public class HelloWorld {public static void main(S…...
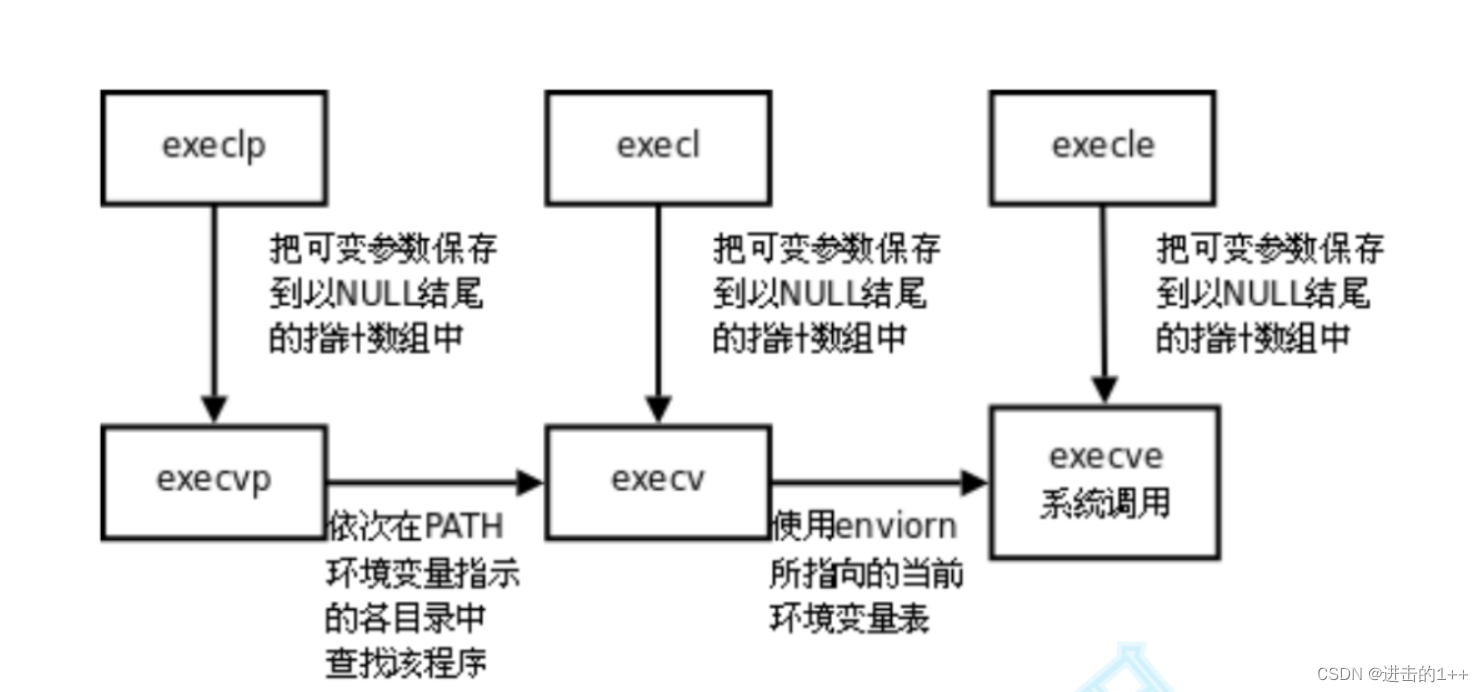
【1++的Linux】之进程(五)
👍作者主页:进击的1 🤩 专栏链接:【1的Linux】 文章目录 一,什么是进程替换二,替换函数三,实现我们自己的shell 一,什么是进程替换 我们创建出来进程是要其做事情的,它可…...

用url类来访问服务器上的文件
场景一: package com.guonian.miaosha;import java.io.BufferedReader; import java.io.File; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL;…...
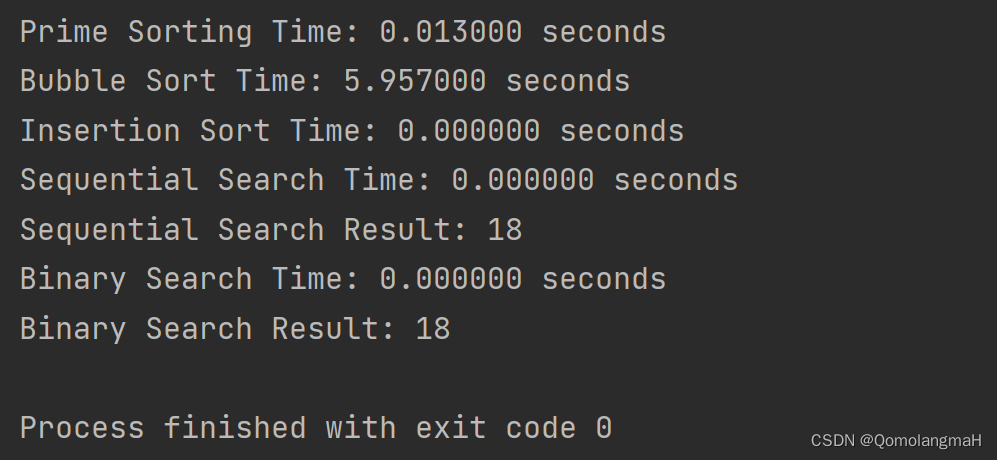
【重拾C语言】六、批量数据组织(二)线性表——分类与检索(主元排序、冒泡排序、插入排序、顺序检索、对半检索)
目录 前言 六、批量数据组织——数组 6.1~3 数组基础知识 6.4 线性表——分类与检索 6.4.1 主元排序 6.4.2 冒泡排序 6.4.3 插入排序 6.4.4 顺序检索(线性搜索) 6.4.5 对半检索(二分查找) 算法比较 前言 线性表是一种常…...

24 Python的sqlite3模块
概述 在上一节,我们介绍了Python的shutil模块,包括:shutil模块中一些常用的函数。在这一节,我们将介绍Python的sqlite3模块。sqlite3模块是Python中的内置模块,用于与SQLite数据库交互。SQLite是一个轻量级的磁盘数据库…...

ARM-流水灯
.text .global _start _start: 1、设置GPIOE寄存器的时钟使能 RCC_MP_AHB$ENSETR[4]->1 0x50000a28LDR R0,0X50000A28 LDR R1,[R0] 从R0起始地址的4字节数据取出放在R1 ORR R1,R1,#(0X3<<4) 第4位设置为1 STR R1,[R0] 写回2、设置PE10、PE8、PF10管脚为输出模式 …...

【虚拟机】NAT 模式下访问外网
目录 一、NAT 模式的作用原理 二、配置 NAT 模式实现外网访问 1、配置NAT模式的网段 2、虚拟机选择 VMnet8 网卡 3、IP地址设为自动分配 一、NAT 模式的作用原理 NAT模式下,虚拟机的系统会把宿主机当作一个大路由器,发送的网络请求和数据都是先发给…...
React 入门笔记
前言 国庆值班把假期拆了个稀碎, 正好不用去看人潮人海, 趁机会赶个晚集入门一下都火这么久的 React 前端技术. 话说其实 n 年前也了解过一丢丢来着, 当时看到一上来就用 JS 写 DOM 的套路直接就给吓退了, 扭头还去看 Vue 了🤣, 现在从市场份额 社区活度来看, 确实…...
Ubuntu MySQL
在安装前,首先看你之前是否安装过,如果安装过,但是没成功,就要先卸载。 一、卸载 1.查看安装 dpkg --list | grep mysql 有东西,就说明您之前安装过mysql。 2.卸载 先停掉server sudo systemctl stop mysql.servic…...

大数据软件系统开发框架
大数据处理框架是用于处理大规模数据集的软件工具和平台,它们可以帮助分析、存储和处理庞大的数据量。以下是一些常见的大数据处理框架,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.A…...

rust变量
一 、变量定义 (一)语法格式 使用let关键字定义变量 let varname: type value; 如,let a: i32 78;也可以不显式指定类型 let varname value; 如,let a 78;一些例子 1.布尔 let t true; let f: bool false;2.整数 let a …...

蓝桥杯---第一讲 递归与递推
文章目录 前言Ⅰ. 递归实现指数型枚举0x00 算法思路0x00 代码书写0x00 思考总结 Ⅱ. 递归实现排列型枚举0x00 算法思路0x01代码书写0x02 思考总结 Ⅲ. 简单斐波那契0x00 算法思路0x01 代码书写 Ⅳ. 费解的开关0x00 算法思路0x01 代码书写 Ⅴ. 递归实现组合型枚举0x00 算法思路0…...
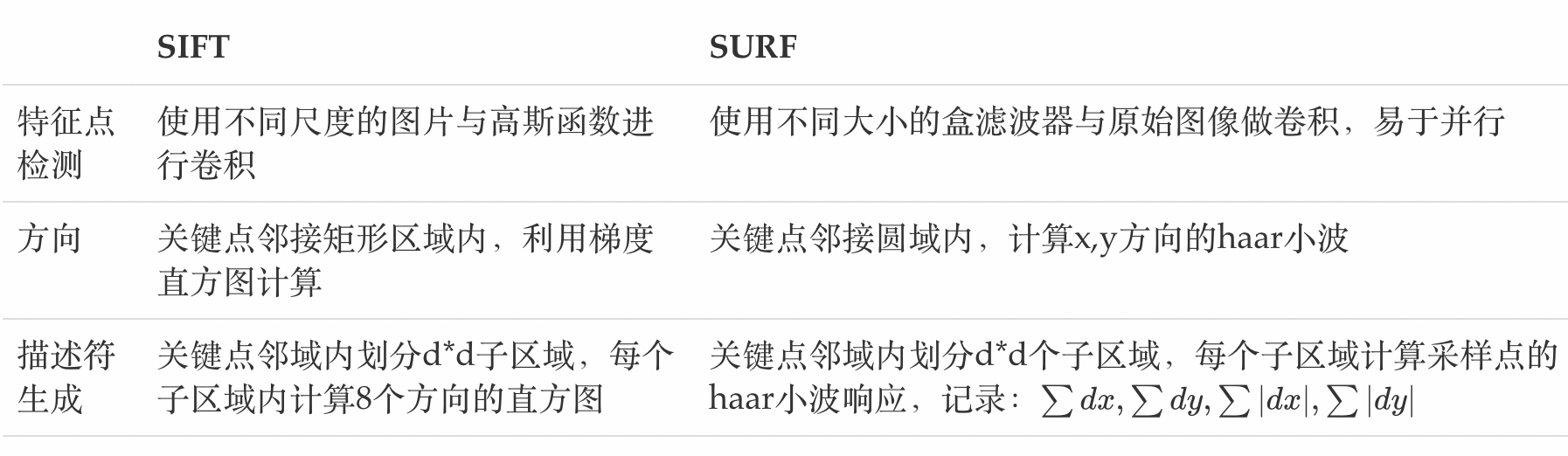
OpenCV 15(SIFT/SURF算法)
一、SIFT Harris和Shi-Tomasi角点检测算法,这两种算法具有旋转不变性,但不具有尺度不变性,以下图为例,在左侧小图中可以检测到角点,但是图像被放大后,在使用同样的窗口,就检测不到角点了。 尺度…...
)
SITS 2026图计算方案深度解析,独家披露金融风控与生物医药两大场景的GNN工程化适配矩阵(含12个可复用配置模板)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

南京彩钢瓦屋面防水供应商
在南京,彩钢瓦屋面广泛应用于各类建筑,然而其防水问题一直是困扰众多业主的难题。选择一家靠谱的彩钢瓦屋面防水供应商至关重要。今天就为大家详细介绍雨中行修缮工程有限公司,同时也对比其他一些大厂,看看雨中行修缮为何能在市场…...
)
DeepSeek模型服务Kubernetes化迁移 checklist(含CRD定义、ServiceMesh适配、TLS双向认证配置)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型服务Kubernetes化迁移全景概览 将DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)从单机或虚拟机部署迁移至Kubernetes集群,是支撑高并发推理、…...

Qdrant 如何配置 API Key 认证
Qdrant 如何配置 API Key 认证 Qdrant 是当下最流行的向量数据库之一,广泛应用于 RAG(检索增强生成)、相似度搜索、AI 应用等场景。生产环境中,API Key 认证是保障数据安全的基本手段。本文详细介绍 Qdrant 的 API Key 配置方法&a…...

终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置
终极指南:10分钟快速上手Ghidra逆向工程工具安装与配置 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 还在为复…...

告别龟速下载!实测对比Axel、Aria2、mwget三大神器,教你选对多线程工具
三大命令行下载神器深度横评:Axel、Aria2与mwget的性能对决 当你在终端里反复输入wget或curl命令,盯着缓慢增长的进度条时,是否想过还有更高效的解决方案?本文将带你深入探索Axel、Aria2和mwget这三款命令行下载加速工具ÿ…...

量子纠错AI预解码器:加速表面码实时处理
1. 量子纠错与实时解码的挑战量子计算的核心难题之一是量子比特的脆弱性。与环境相互作用导致的退相干效应,使得量子信息在极短时间内就会发生不可逆的丢失。表面码(Surface Code)作为最具实用前景的量子纠错方案,通过将逻辑量子比…...

云数据中心能效优化:集成资源管理与学习中心管理的实战指南
1. 项目概述:当云计算撞上“能耗墙”,我们如何破局?干了十几年IT,从自建机房到全面上云,我亲眼见证了云计算如何重塑整个行业。它确实像电力网络和公路一样,成了现代社会不可或缺的基础设施。但这些年&…...

云端AI模型基准测试:从参数迷信到效能优先的选型实战
1. 项目概述:一次颠覆认知的云端AI模型基准测试作为一名长期在本地部署AI智能体(我用的是OpenClaw)的实践者,模型选型一直是我工作流中的核心决策。过去几个月,我默认使用的都是阿里云出品的qwen3.5:397b-cloud。这个模…...

AI驱动SEO技术架构:从自动化脚本到模式识别的工程实践
1. 项目概述:从“垃圾场”到“架构师”的AI SEO转型如果你最近打开搜索引擎,发现前几页的结果里充斥着大量读起来味同嚼蜡、观点模糊、甚至自相矛盾的文章,那你大概率是撞上了“AI垃圾场”。没错,现在很多人的SEO策略简单得令人发…...