知识增强语言模型提示 零样本知识图谱问答10.8
知识增强语言模型提示 零样本知识图谱问答
- 摘要
- 介绍
- 相关工作
- 方法
- 零样本QA的LM提示
- 知识增强的LM提示
- 与知识问题相关的知识检索

摘要
大型语言模型(LLM)能够执行 零样本closed-book问答任务 ,依靠其在预训练期间存储在参数中的内部知识。然而,这种内部化的知识可能是不足和错误的,这可能导致LLM生成错误的答案。此外,对LLM进行微调以更新其知识是昂贵的。为此,本文提议直接在LLM的输入中增加知识。具体而言,首先根据问题与相关事实之间的语义相似性从知识图谱中检索与输入问题相关的事实。然后,将检索到的事实以提示的形式前置到输入问题之前,然后将其转发给LLM生成答案。本文提出的框架,称为knowledge-Augmented language model PromptING(KAPING),无需模型训练,因此完全是零样本的。
还验证了KAPING框架在知识图谱问答任务上的性能,该任务旨在基于知识图谱上的事实回答用户的问题,在此任务上,本文的方法在多个不同规模的LLM上相对于相关的零样本基线平均提高了高达48%的性能。
Closed-book问答任务指在回答问题时,模型只能依靠其在预训练阶段学到的知识,而无法进行额外的外部搜索或引用。这意味着在回答问题时,模型不能直接访问互联网或其他外部资源。
Zero-shot closed-book问答任务是一种更具挑战性的闭书问答任务,其中模型在没有任何先前训练的情况下,无需额外的模型微调或更新,直接回答问题。
在传统的闭书问答任务中,模型需要在预训练后进行微调,以根据特定的问题集和答案集进行调整。而在zero-shot closed-book问答任务中,模型不需要进行任何额外的调整或微调,仍然可以回答新问题。
这种任务要求模型能够利用其预训练阶段学到的通用语言理解和推理能力,以及内部的知识表示来解决新问题。模型需要将问题与其内部知识进行联结,从而推断出答案,而无需对任务进行特定的针对性训练。
在zero-shot closed-book问答任务中,模型通常会使用问题的提示信息或关键词来引导答案的生成。模型会利用其预训练的语言表示能力和对内部知识的理解,以及与问题相关的提示信息,生成可能的答案。
介绍
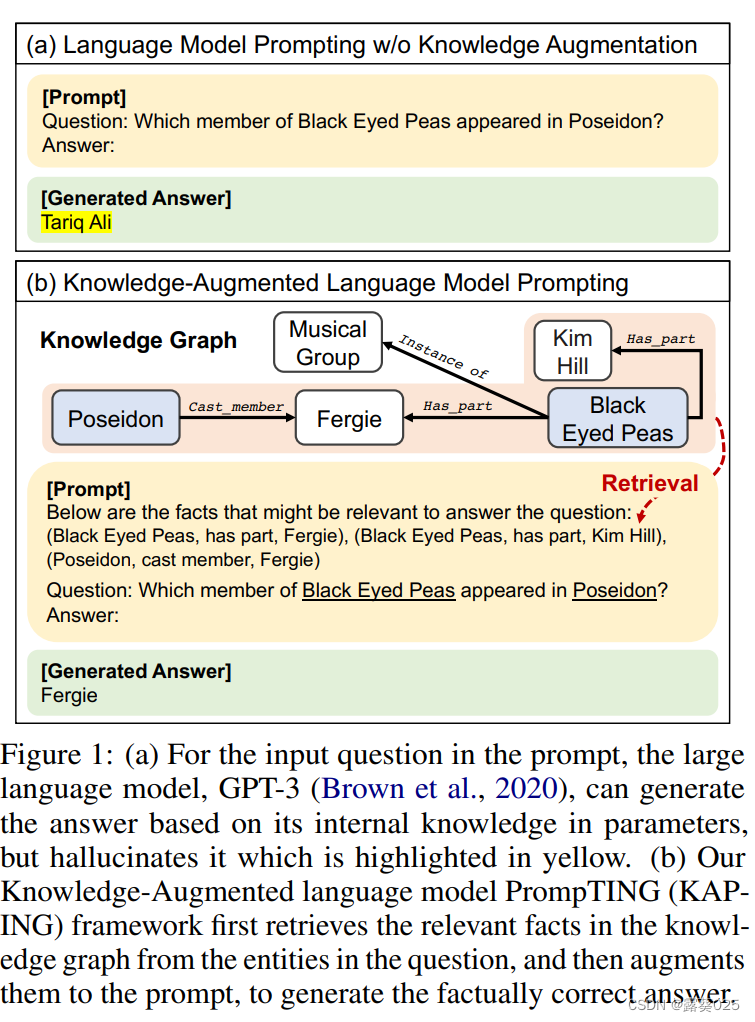
预训练语言模型通过自监督学习在大量文本语料上进行训练,可以执行闭书问答(closed-book Question Answering,QA)任务,即仅依靠其内部参数中的知识来回答用户的问题,而不使用任何外部知识。此外,当增加语言模型的规模时,大型语言模型可以在没有任何额外微调步骤的情况下为问题生成答案,这称为语言模型提示(LM prompting)。然而,由于LLMs中的知识可能是不完整、错误和过时的,它们经常会生成事实上错误的答案,即所谓的幻觉(hallucination)(见图1a)。此外,通过参数更新来完善LLMs中的知识是昂贵的,特别是当知识不断变化时(例如货币汇率)。最后,LLMs是否正在获取正确的知识来回答问题尚不清楚。
为了克服这些限制,本文提出直接检索和注入相关知识作为输入,称为提示(prompt),传递给LLMs(图1b)。使用知识图谱作为知识源,其中包含以三元组形式表示的符号知识(头实体、关系、尾实体)。因此,为了提取与输入问题相关的事实,首先将问题中的实体与知识图谱中的实体进行匹配。然后,与知识图谱中的实体相关联的三元组被转化为文本形式,并 前置到输入问题前面 ,然后传递给LLMs生成答案。
“前置到输入问题前”
指的是将相关知识直接插入到输入问题之前,作为输入序列的一部分。在传统的问答系统中,只有输入问题作为模型的输入,模型需要通过自身的预训练知识来回答问题。而在这种方法中,我们将从知识图谱中提取的相关知识以文本形式添加到输入问题之前,形成一个新的输入序列。
举个例子,假设有一个问题:
“谁是美国的第一位总统?”。
如果我们有一个知识图谱,并且知道其中包含了以下三元组:(美国,首都,华盛顿)和(华盛顿,位于,哥伦比亚特区)。那么,在前置知识的情况下,我们可以将这些知识转化为文本形式:
“美国的首都是华盛顿,华盛顿位于哥伦比亚特区。”
然后将这个文本知识添加到原始问题之前,形成新的输入序列:
“美国的首都是华盛顿,华盛顿位于哥伦比亚特区。谁是美国的第一位总统?”。
通过这种方式,语言模型在生成答案时可以同时考虑问题和前置的知识,从而能够更好地利用外部知识来提高答案的准确性和相关性。这种前置知识的方法可以帮助语言模型更好地理解问题的上下文和意图,避免产生基于不准确或过时知识的错误答案。
因此,基于事实知识的LLMs能够生成准确的答案,减轻了幻觉问题,同时保持LLMs的参数不变,无需进行知识更新的微调。整体框架称为Knowledge-Augmented language model PromptING(KAPING),它完全是零样本的,并且可以与任何现成的LLMs一起使用,无需额外的训练。
虽然上述方案看起来简单而有效,但还存在一些挑战。
首先,与问题实体相关的大多数检索到的三元组与回答给定问题无关。例如,在维基数据知识图谱中为问题实体(例如Poseidon)检索相关的三元组时,存在60个三元组,其中大多数(例如流派、出版日期等)与回答问题无关。因此,它们可能会误导模型生成错误的答案。
另一方面,问题实体的三元组数量有时很大(例如,WebQSP数据集中有27%的样本有超过1000个三元组),因此编码包括不必要的所有三元组会带来很高的计算成本,特别是对于大型语言模型来说。
为了克服这些挑战,受信息检索的启发,进一步提出了 基于语义相似性过滤不必要三元组 的方法。具体而言,首先将问题及其相关的语言化三元组表示为嵌入空间中的向量。然后,检索出一小部分三元组,其嵌入与输入问题的嵌入相比其他三元组更接近。这样,只将与给定问题更相关的三元组前置,可以有效防止大型语言模型生成与问题无关的答案,并且具有高的计算效率,不像增加所有三元组的方法那样。值得注意的是,这种过滤方法使用 现成的句子嵌入模型,因此在我们的流程的每个部分都不需要额外的训练。
基于语义相似性过滤不必要的三元组
是指通过比较问题和其关联的三元组之间的语义相似性来筛选出与问题相关性较高的三元组,从而减少不相关的三元组对于问题回答的干扰。
在知识图谱问答任务中,通常通过检索知识图谱中与问题实体相关的三元组来获取问题的背景知识。然而,检索到的三元组中可能包含大量与问题无关的信息,这些不必要的三元组可能会误导模型,导致生成错误的答案。
为了解决这个问题,可以使用语义相似性来衡量问题和三元组之间的相似程度。常见的方法是将问题和三元组表示为向量形式,然后计算它们之间的相似度。根据相似度的大小,可以选择保留与问题最相关的三元组,而过滤掉与问题关联性较低的三元组。
"现成的句子嵌入模型"指的是已经经过预训练并可供使用的句子级别的文本表示模型。这些模型通过将输入的句子转换为连续向量表示,捕捉句子的语义和语法信息,并将其映射到一个高维向量空间中。这些向量表示可以用于计算句子之间的相似性、分类、聚类等自然语言处理任务。常见的句子嵌入模型包括BRERT、GPT等。
然后,在知识图谱问答(KGQA)任务中验证了KAPING框架。结果表明,KAPING显著优于相关的零样本基线。此外,详细的分析支持知识检索和增强方案的重要性。
本文这项工作中的贡献有三个方面:
• 提出了一种新的知识增强的语言模型提示框架,利用知识图谱中的事实知识进行零样本问答。
• 提出了基于问题及其相关三元组之间的语义相似性来检索和增强知识图谱中相关事实的方法。
• 在知识图谱问答基准数据集上验证了我们的KAPING,在这些数据集上,本文的方法令人印象深刻地优于相关的零样本基线。
相关工作
语言模型提示
语言模型预训练是一种训练Transformer模型的方法,使用未标注的文本语料库进行自编码或自回归目标的训练。它已成为自然语言任务的一种重要方法。此外,大型语言模型能够进行零样本学习,例如基于预训练参数中存储的知识,根据输入的文本提示生成答案,而无需额外的参数更新或标记的数据集。为了进一步提高它们的性能,一些工作提出从训练数据集中检索与输入问题相关的样本,并将它们在少样本学习中添加到提示中。最近的一些工作进一步表明,当LLMs在从自然语言任务中提取的一系列指令上进行微调时,它们在未见过的零样本任务上具有强大的泛化性能。然而,LLMs内部的知识可能不足以处理事实性问题,这引发了知识增强的LLMs。
知识增强的语言模型
最近的研究提出将知识,如来自无结构语料库(例如维基百科)的文档和来自知识图谱的事实,整合到语言模型中。其中,REALM和RAG学习检索文档并将其与语言模型结合。此外,知识图谱也可以是另一种知识源,其中知识以最紧凑的形式进行编码,一些方法将KG中的事实增强到语言模型中。然而,所有上述方法都需要大量的训练数据和模型更新用于下游任务。虽然最近的一些工作表明,通过检索增强的语言模型在少样本学习中具有很强的性能,但仍需要额外的训练步骤,这与完全零样本的LM提示不同。
最近,有几项研究在LM提示方案中增加了知识。首先,一些工作提出通过提示提取LLMs本身参数中的知识,然后使用提取的知识回答问题。然而,由于LLMs的参数可能不足以存储所有世界知识,提取的知识和生成的答案可能不准确。另一方面,最近,Lazaridou等人提出使用谷歌搜索在Web上检索文档,然后将检索到的文档与少样本演示一起添加到输入问题中,在少样本的LLM提示方案下回答问题。然而,关注与之前研究不同的零样本提示与KGs的结合,利用KGs可以带来额外的优势。具体而言,由于KGs可以以紧凑的三元组形式简洁地编码知识,在问答任务中,相比于文档情况,本文的方法使LLM提示更加高效(即减少输入序列长度),同时在零样本问答方案上更加有效:LLMs需要从提示中选择包含答案实体的一个三元组,而不是查找包含各种实体的冗长文档。
方法
接下来描述KAPING框架。
零样本QA的LM提示
首先从零样本问答开始,然后解释语言模型提示。
零样本问答
给定一个输入问题x,问答(QA)系统返回一个答案y,其中x和y都由一系列标记组成:x = [w1,w2,…,w|x|]。假设P是一个基于生成语言模型的QA模型,它生成给定问题x的答案y的条件概率如下:P(y|x)。与使用一组带标注的(x , y)样本来训练模型P的监督学习不同,零样本学习不使用任何带标签的样本和模型训练。值得注意的是,对这种零样本QA感兴趣是因为收集数据集并为每个新领域微调现有的LM被认为是昂贵且有时不可行的。
LM提示
LM通常通过基于先前标记预测下一个标记进行预训练,这被称为自回归语言建模。然后,由于这种预训练目标,LLM可以进行零样本指令学习。具体而言,当向LLM(即P)提供一个问题和一条指令(例如,“请回答以下问题:《Lady Susan》的作者是谁?”)时,LLM在输入文本的条件下可以顺序生成输出标记的概率,这可能是一个答案,比如“Jane Austen”。
为了更规范,对于每个输入问题x,首先使用特定的指令模板T将其修改为一个文本字符串x’,称为提示(prompt),如下所示:T:x → x’。例如,如果我们有先前的问题x = “Who is the author of Lady Susan?” 以及先前的指令模板"Please answer the question:",则生成的提示x’将为T(x) = “Please answer the question: Who is the author of Lady Susan?”。然后,将提示x’传递给LLM(即P),LLM通过P(y|x’)生成答案(即y)。注意,这种LM提示方案不需要对标记数据进行任何额外的模型参数更新(即微调),因此适用于目标零样本QA任务。
然而,在这种单纯的零样本提示QA中存在多个挑战。首先,LLM依赖参数中的知识,容易生成事实上不正确的答案,因为LLM中的知识可能是不准确和过时的:知识可能随时间的推移而出现和变化。此外,使用额外的参数更新来改进内部知识是昂贵的,而且有必要反映错误和不断增长的知识。最后,LLM在生成对问题提示的答案时记忆和利用哪些知识是不清楚的,这限制了它们在输出上的可解释性。
知识增强的LM提示
为了解决现有LM提示方案的前述限制,本文提出了一种将相关知识从知识图谱(KG)注入到输入问题中的方法,称为增强知识语言模型提示(Knowledge-Augmented language model PromptING,KAPING)。
在本小节中,首先定义了KAPING框架的主要目标,然后介绍了增强KG上的知识以及注入到LM提示中所需的要素。
使用知识图谱进行LM提示
不再仅依赖于 参数内部化的知识 ,而是提出通过访问和注入来自外部KG的知识来回答问题,这些知识包含对回答问题有帮助的准确和最新的事实。形式上,知识图谱G由一组事实三元组{(s, r, o)}组成,其中s和o表示主体和客体实体,r是它们之间的特定关系类型。例如,一个关系型知识"《Lady Susan》是由Jane Austen编写的"可以表示为一个包含两个实体s = "Lady Susan"和o = "Jane Austen"以及关系r = "written by"的三元组。然后,对于通过模板T从示例问题x = "Who is the author of Lady Susan?"转换而成的问题提示x’,还将其相关三元组(Lady Susan, written by, Jane Austen)增加到LM提示方案中。通过这样做,LLM可以根据来自KG的增强知识生成正确的答案,形式化表示为P(y|x’, G)。需要注意的是,由于可以在KG中提供特定和有效的事实给LLM,该框架可以缓解LLM中不准确和过时知识导致的错误生成问题,而无需昂贵地更新模型参数。此外,还可以确认LLM是否基于增强事实生成答案,从而提高LM提示的可解释性。
剩下的问题是如何从输入问题中访问KG上的关系符号事实,将符号知识转化为文本字符串,并将转化后的知识注入到LM提示方案中。下面的段落中将逐一解释它们。
知识访问
为了利用与输入问题相关的事实,首先提取问题中的实体。例如,对于问题"谁是《Lady Susan》的作者?“,提取出实体"Lady Susan”。然后,基于提取的实体,在知识图谱中找到对应的实体,其关联的三元组成为与输入问题相关的事实。需要注意的是,实体匹配可以通过现有的实体链接技术来完成。
知识转化
LLMs处理的是文本输入,而事实三元组表示为符号图。因此,在将来自知识图谱的符号事实注入到LLMs之前,首先将包含(s, r, o)的三元组转化为文本字符串,称为转化。虽然存在最近的方法专门设计或学习图到文本的转换,但在本工作中,我们使用线性转化:将三元组中的主体、关系和客体文本连接起来,我们观察到这在LM提示中效果良好(参见附录B.5)。例如,一个三元组(Lady Susan, written by, Jane Austen)直接使用为"(Lady Susan, written by, Jane Austen)"作为LLM的输入。
知识注入
基于与输入问题相关的转化后的事实,剩下的步骤是实现知识注入机制,使LLMs能够基于外部知识生成答案。假设有一个与问题x相关的N个关联三元组k = {(sᵢ, rᵢ, oᵢ)}ᴺᵢ₌₁。类似于上述描述的指令模板T:x → x’,修改N个转化后的三元组k,并将知识注入指令添加到知识提示k’中,如下所示:T:k → k’。用于构建提示的一个特定模板,首先逐行列举N个转化后的三元组,然后在提示的顶部添加具体指令:“以下是以三元组形式表示的对回答问题有意义的事实。”。之后,将这样的知识提示字符串k’添加到问题提示x’之前,LLMs根据知识和问题提示生成答案标记,形式化表示为P(y|[k’, x’]),其中[·]表示连接。
与知识问题相关的知识检索
KAPING框架允许LLMs利用知识图谱中的知识进行零-shot问答。然而,存在一个关键挑战,即与问题相关的三元组数量往往太大,无法直接用于LLMs。而且,其中大部分与问题无关,会误导LLMs生成不相关的答案。
知识检索器
为了克服这些限制,进一步提出仅检索和增强与问题相关的三元组。需要注意的是,存在一种文档检索方案,其目标是根据嵌入相似性为给定查询检索相关文档,这激发了我们检索用户问题的三元组的想法。特别是,由于在上一节中定义的知识转化器,可以在文本空间中操作从符号知识图谱中获取的三元组。因此,对于转化后的三元组和问题,首先使用现成的句子嵌入模型对它们进行嵌入表示,然后计算它们之间的相似性。然后,仅使用与给定问题相关的前K个相似三元组,而不是使用所有与问题相关的N个三元组。需要注意的是,与最近的一些研究不同,这些研究旨在通过监督训练改进知识图谱检索器本身,专注于使用知识图谱进行零样本LM提示,因此将现成的检索器作为工具,用于过滤掉与问题无关的三元组。
相关文章:
知识增强语言模型提示 零样本知识图谱问答10.8
知识增强语言模型提示 零样本知识图谱问答 摘要介绍相关工作方法零样本QA的LM提示知识增强的LM提示与知识问题相关的知识检索 摘要 大型语言模型(LLM)能够执行 零样本closed-book问答任务 ,依靠其在预训练期间存储在参数中的内部知识。然而&…...

虚拟现实项目笔记:SDK、Assimp、DirectX Sample Browser、X86和X64
文章目录 SDK是什么Assimp是什么DirectX Sample Browser是什么X86和X64生成解决方案和重新生成解决方案 SDK是什么 SDK是Software Development Kit的英文缩写,意思是软件开发包。 软件开发包中往往包含有多种辅助进行软件开发的内容,包括一些软件开发工…...
openwrt rm500u ncm方式拨号步骤记录
1.进入设备页面 用户名:root 2.创建接口 3.配置接口 国内APN 信息 中国移动APN:CMNET 中国联通APN:3GNET 中国电信APN:CTNET 4.防火墙配置 5.点击Save&Apply 6.配置完成后重启设备。重新进入设备页面,可以看…...

使用js代码将一个值为“1=增量,2=全量“的字符串转化为一个数组,数据格式为[{value:““,label:“‘‘}]
const str "1增量,2全量"; const arr str.split(",").map(item > {const [value, label] item.split("");return { value, label}; });...

图片调色盘
图片预览 配置安装 Color-Thief 安装包使用文档 yarn add colorthief -S // npm install colorthief --save代码 <template><div class"img-thief"><div class"container"><div class"thief-item" v-for"(item, in…...
一文读懂Base64
这几天在和第三方交互的时候,对方返回的数据是base64格式的数据,所以这两天又彻底捋了下Base64的来龙去脉。之前看过一篇文章说的非常好(再找到给加上链接),我在这不详细说明了,只说转换过程。 还是使用中…...

CCF CSP认证 历年题目自练 Day20
题目一 试题编号: 201903-1 试题名称: 小中大 时间限制: 1.0s 内存限制: 512.0MB 问题描述: 题目分析(个人理解) 常规题目,先看输入,第一行输入n表示有多少数字&am…...

【Overload游戏引擎分析】从视图投影矩阵提取视锥体及overload对视锥体的封装
overoad代码中包含一段有意思的代码,可以从视图投影矩阵逆推出摄像机的视锥体,本文来分析一下原理 一、平面的方程 视锥体是用平面来表示的,所以先看看平面的数学表达。 平面方程可以由其法线N(A, B, C)和一个点Q(x0,…...

vue全局事件总线是什么?有什么用?解决了什么问题,与pinia有什么区别?
全局事件总线快速入门 概念基本概念(是什么?)核心概念 核心特性和优势(有什么用?)解决了什么问题?主要优势是什么? 案例演示?传递数据-案例演示传递事件-案例演示 与pinia有什么区别?…...
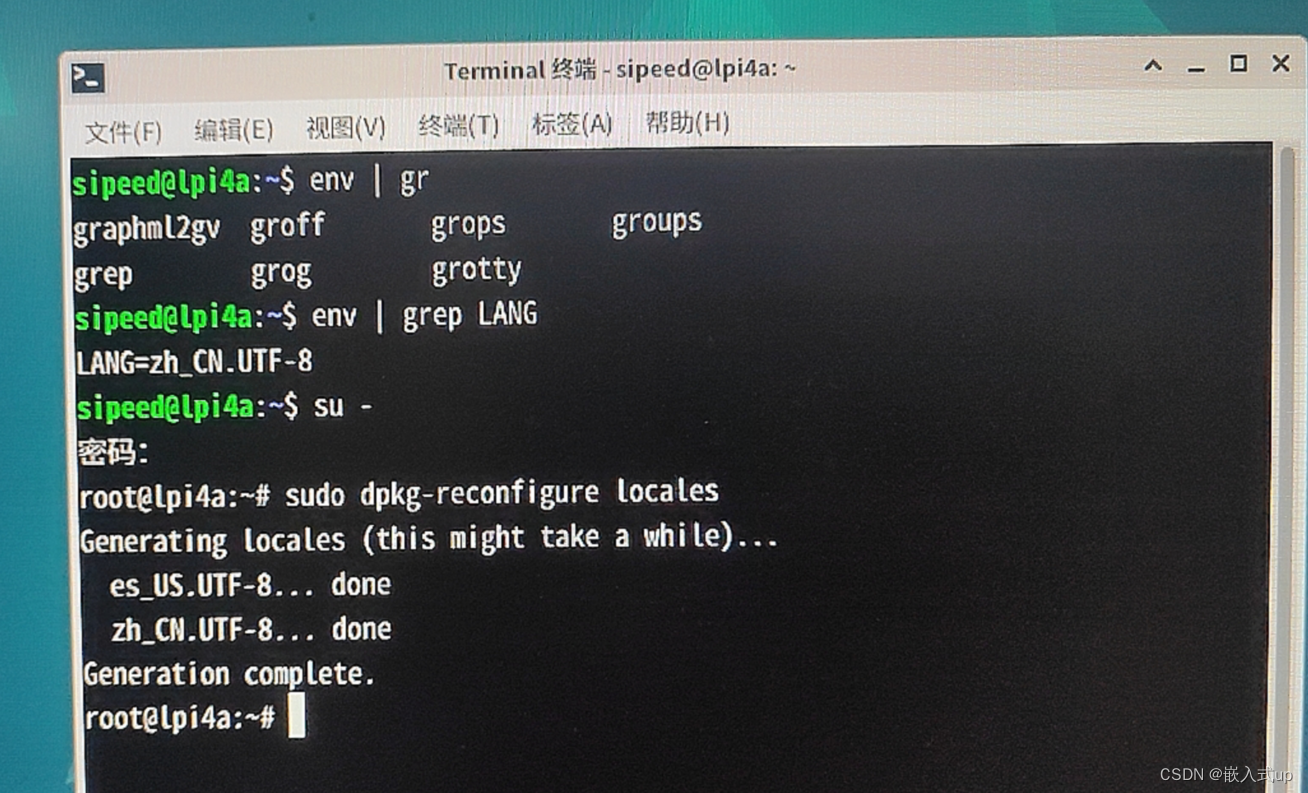
【debian 12】:debian系统切换中文界面
目录 目录 项目场景 基础参数 原因分析 解决方案 1.ctrlaltT 打开终端 2.查询当前语言环境(我的已经设置成了中文 zh_CN.UTF-8) 3.打开语言配置界面 4.最后一步:重启 不要放弃任何一个机会! 项目场景: 这两…...
)
es官方为我们提供的堆内存保护机制-熔断器( breaker )
总熔断器(相当于似乎总闸) 参数: indices.breaker.total.use_real_memory 默认值:true 在 elasticsearch.yml中配置。 参数: indices.breaker.total.limit 如果 indices.breaker.total.use_real_memory : true, in…...

靶场通关记录
OSCP系列靶场-Esay-CyberSploit1 总结 getwebshell → 源码注释发现用户名 → robots.txt发现base64密码 → SSH登录 提 权 思 路 → 内网信息收集 → 发现发行版本有点老 → 内核overlayfs提权 准备工作 启动VPN 获取攻击机IP > 192.168.45.220 启动靶机 获取目标机器I…...
全网最新最全的软件测试面试题
一、前言 与开发工程师相比,软件测试工程师前期可能不会太深,但涉及面还是很广的。 在一年左右的实习生或岗位的早期面试中,主要是问一些基本的问题。 涉及到的知识主要包括MySQL数据库的使用、Linux操作系统的使用、软件测试框架问题、测试…...
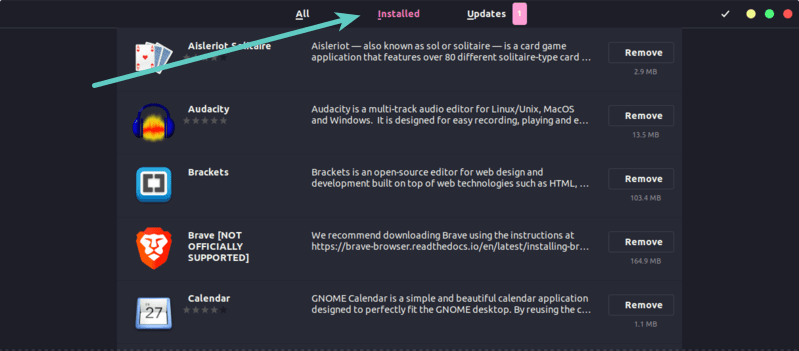
如何列出 Ubuntu 和 Debian 上已安装的软件包
当你安装了 Ubuntu 并想好好用一用。但在将来某个时候,你肯定会遇到忘记曾经安装了那些软件包。 这个是完全正常。没有人要求你把系统里所有已安装的软件包都记住。但是问题是,如何才能知道已经安装了哪些软件包?如何查看安装过的软件包呢&a…...

图论---最小生成树问题
在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。解决最小生成树问题一般有两种算法:Kruskal算法和Prim算法。 Kruskal算法 原理:基本思想是从小到大加入边,是个贪心算法。我们将图中的每个边按…...

elementplus 时间范围选择器限制选择时间范围
<el-date-pickerv-model"form.time" type"daterange"range-separator"-"start-placeholder"开始时间"end-placeholder"结束":disabled-date"disabledDate"calendar-Change"calendarChange" />co…...
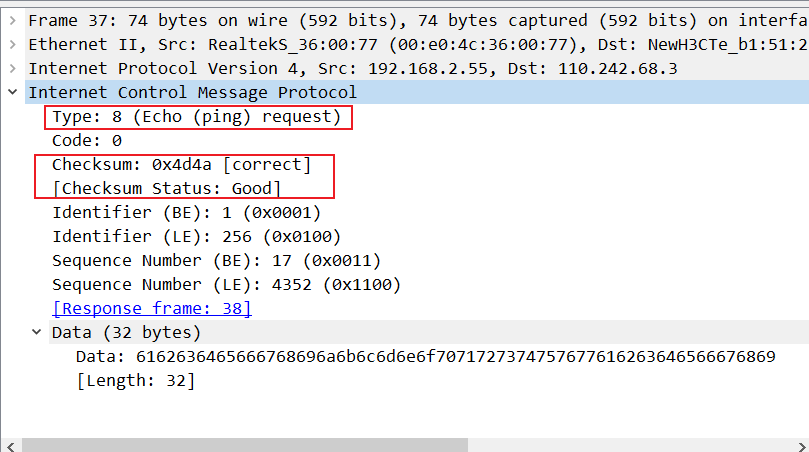
【网络】抓包工具Wireshark下载安装和基本使用教程
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助…...

Metasequoia 4 水杉3D建模工具 附序列号
Metasequoia 4是一款非常强大的3D水杉建模工具,它基于多边形建模技术,可以用于创建各种对象并支持多种第三方3DCG软件的文件格式,是一款非常适合从爱好到业务,支持3D电脑绘图,3D印刷,游戏开发等的3D建模软件…...

股票杠杆交易平台排名:淘配网推荐的十大平台
在投资世界中,股票杠杆交易一直以其提供更高回报机会的吸引力而备受欢迎。随着市场的不断发展,出现了越来越多的股票杠杆交易平台。本文将为您介绍淘配网推荐的十大股票杠杆交易平台,并分析它们的特点。 富灯网 - 富灯网以其全面的杠杆产品和…...

CoreData + CloudKit 在初始化 Schema 时报错 A Core Data error occurred 的解决
问题现象 如果希望为 CoreData 支持的 App 增加云数据备份和同步功能,那么 CloudKit 是绝佳的选择。CloudKit 会帮我们默默处理好一切,我们基本不用为升级而操心。 不过,有时在用本地 CoreData NSManagedObjectModel 初始化 iCloud 中的 Schema 时会发生如下错误: Error …...

sndcpy:Android设备音频转发终极指南
sndcpy:Android设备音频转发终极指南 【免费下载链接】sndcpy Android audio forwarding PoC (scrcpy, but for audio) 项目地址: https://gitcode.com/gh_mirrors/sn/sndcpy 想要在电脑上享受Android设备的音频体验吗?sndcpy音频转发工具正是您需…...

ABAP 7.40+新语法实战:从传统代码到现代编程范式的重构
1. ABAP 7.40新语法带来的编程革命 十年前我刚接触ABAP时,代码风格还停留在SAP R/3时代的传统写法。每次看到满屏的DATA声明、LOOP...ENDLOOP和APPEND语句,就像在看上世纪90年代的编程教科书。直到ABAP 7.40版本发布,这个被称为"ABAP语言…...

反向传播不神秘:手把手调试一个计算图,看梯度是怎么‘流’回来的
反向传播不神秘:手把手调试一个计算图,看梯度是怎么"流"回来的 在深度学习的实践中,我们常常会调用loss.backward()这样的魔法函数,然后梯度就自动计算好了。但这个过程究竟发生了什么?为什么调整参数时梯度…...

ARM AMBA总线演进史:从AHB到AXI,再到CHI和ACE,我们经历了什么?
ARM AMBA总线演进史:从AHB到AXI,再到CHI和ACE的技术脉络解析 二十年前,当ARM首次提出AMBA总线架构时,恐怕很少有人能预见它会在今天的SoC设计中占据如此核心的地位。从最初的AHB到如今的CHI,AMBA总线的每一次迭代都精准…...

从ABL项目看激光武器发展:技术挑战、工程突破与未来转型
1. 项目背景与核心争议十几年前,当美国国防部(DoD)最终决定为YAL-1机载激光试验台(ABL)项目画上句号时,在军事与航空航天工程圈子里引发的讨论,远比一份简单的项目终止公告要复杂得多。这个项目…...

不想注册Nvidia账户?手把手教你修改app.js文件,让GeForce Experience直接进主界面
免登录畅享GeForce Experience:技术流修改指南 每次打开GeForce Experience都要面对那个恼人的登录窗口?作为资深PC玩家,我完全理解这种困扰。重装系统后最烦人的就是各种强制登录,尤其是当我们只想快速使用屏幕录制或游戏优化功能…...

3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍!
3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍! 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 还在为桌面杂乱无章的纸质便利贴烦恼吗?Sti…...

runtime.js实战部署:从本地QEMU到云端KVM的完整流程指南
runtime.js实战部署:从本地QEMU到云端KVM的完整流程指南 【免费下载链接】runtime [not maintained] Lightweight JavaScript library operating system for the cloud 项目地址: https://gitcode.com/gh_mirrors/runt/runtime runtime.js是一个革命性的Java…...

巧用frp与nginx反向代理,实现安全远程访问内网ESXi管理界面
1. 为什么需要远程访问ESXi管理界面 对于运维人员来说,能够随时随地访问ESXi管理界面是刚需。想象一下,当你正在出差或者在家休息时,突然需要检查虚拟机状态或者处理紧急故障,如果只能跑到机房操作,那简直是噩梦。我遇…...

终极指南:华为光猫配置解密工具深度解析与应用实践
终极指南:华为光猫配置解密工具深度解析与应用实践 【免费下载链接】HuaWei-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/hu/HuaWei-Optical-Network-Terminal-Decoder 华为光猫配置解密工具(HuaWei-Optical-Ne…...