【目标检测】大图包括标签切分,并转换成txt格式
前言
遥感图像比较大,通常需要切分成小块再进行训练,之前写过一篇关于大图裁切和拼接的文章【目标检测】图像裁剪/标签可视化/图像拼接处理脚本,不过当时的工作流是先将大图切分成小图,再在小图上进行标注,于是就不考虑标签变换的问题。
最近项目遇到的问题是,一批大图已经做好标注,需要将其裁切,同时标签也要进行同步裁切。本文讲解如何实现这一需求,同时将labelimg直出的xml格式标签转换成yolov5等模型需要的txt标签。
图片裁剪
图片裁剪还是沿用了一套之前博文提到的编码规则,即将图片裁成1280x1280的图像块,裁剪后通过文件名来标记图像块在原始图像中的位置。
import configparser
import shutil
import yaml
import os.path
from pathlib import Path
from PIL import Image
from tqdm import tqdmrootdir = r"E:\Dataset\数据集\可见光数据\原始未裁剪\img"
savedir = r'E:\Dataset\数据集\可见光数据\裁剪后数据\img' # 保存图片文件夹dis = 1280
leap = 1280def main():# 创建输出文件夹if Path(savedir).exists():shutil.rmtree(savedir)os.mkdir(savedir)num_dir = len(os.listdir(rootdir)) # 得到文件夹下数量num = 0for parent, dirnames, filenames in os.walk(rootdir): # 遍历每一张图片filenames.sort()for filename in tqdm(filenames):currentPath = os.path.join(parent, filename)suffix = currentPath.split('.')[-1]if suffix == 'jpg' or suffix == 'png' or suffix == 'JPG' or suffix == 'PNG':img = Image.open(currentPath)width = img.size[0]height = img.size[1]i = j = 0for i in range(0, width, leap):for j in range(0, height, leap):box = (i, j, i + dis, j + dis)image = img.crop(box) # 图像裁剪image.save(savedir + '/' + filename.split(suffix)[0][:-1] + "__" + str(i) + "__" + str(j) + ".jpg")if __name__ == '__main__':main()
标签裁剪
标签读取
首先需要通过lxml库对xml格式的数据进行解析,主要提取两个信息,1是目标类别,2是目标bbox坐标。
通过递归形式,将xml转换成字典形式,然后就可以获取到需要的信息。
def parse_xml_to_dict(xml):"""将xml文件解析成字典形式"""if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息return {xml.tag: xml.text}result = {}for child in xml:child_result = parse_xml_to_dict(child) # 递归遍历标签信息if child.tag != 'object':result[child.tag] = child_result[child.tag]else:if child.tag not in result:result[child.tag] = []result[child.tag].append(child_result[child.tag])return {xml.tag: result}def main():xml_path = r"label.xml"with open(xml_path, encoding="utf-8") as fid:xml_str = fid.read()xml = etree.fromstring(xml_str)data = parse_xml_to_dict(xml)["annotation"]for obj in data["object"]:# 获取每个object的box信息xmin = float(obj["bndbox"]["xmin"])xmax = float(obj["bndbox"]["xmax"])ymin = float(obj["bndbox"]["ymin"])ymax = float(obj["bndbox"]["ymax"])class_name = obj["name"]
标签位置重置
由于图像裁剪成小的图像块,标签也要转换成图像块对应的bbox。不过,对于裁剪的图像,存在的一个问题是,如果标签被切分成两半,该如何进行处理。
下面是我的处理思路,通过对图像块的位置编码,可以分成四种情况。
第一种情况,标签四个角全在图像块中,此时不用做过多处理。
(下图仅为示意,实际尺寸比例未精确,黑色为bbox,红色为切割线)

第二种情况,标签被左右裁开。此时,将左右两部分都当作一个label分给相应的图像块。

第三种情况,标签被上下裁开。此时,将上下两部分都当作一个label分给相应的图像块。

第四种情况,标签被四块裁开,此时,每一块都过于细小,对于小目标而言,这种情况比较少见,因此舍弃该标签。

对应代码:
xmin_index = int(xmin / leap)
xmax_index = int(xmax / leap)
ymin_index = int(ymin / leap)
ymax_index = int(ymax / leap)xmin = xmin % leap
xmax = xmax % leap
ymin = ymin % leap
ymax = ymax % leap# 第一种情况,两个点在相同的图像块中
if xmin_index == xmax_index and ymin_index == ymax_index:info = xml2txt(xmin, xmax, ymin, ymax, class_name, img_width, img_height)file_name = img_name + "__" + str(xmin_index * leap) + "__" + str(ymin_index * leap) + ".txt"write_txt(info, file_name)
# 第二种情况,目标横跨左右两幅图
elif xmin_index + 1 == xmax_index and ymin_index == ymax_index:# 保存左半目标info = xml2txt(xmin, leap, ymin, ymax, class_name, img_width, img_height)file_name = img_name + "__" + str(xmin_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)# 保存右半目标info = xml2txt(0, xmax, ymin, ymax, class_name, img_width, img_height)file_name = img_name + "__" + str(xmax_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)
# 第三种情况,目标纵跨上下两幅图
elif xmin_index == xmax_index and ymin_index + 1 == ymax_index:# 保存上半目标info = xml2txt(xmin, xmax, ymin, leap, class_name, img_width, img_height)file_name = img_name + "__" + str(xmin_index * leap) + "__" + str(ymin_index * leap) + ".txt"write_txt(info, file_name)# 保存下半目标info = xml2txt(xmin, xmax, 0, ymax, class_name, img_width, img_height)file_name = img_name + "__" + str(xmin_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)
标签转换成txt格式
xml格式是 xmin,ymin,xmax,ymax,对应左上角和左下角矩形框的全局像素点坐标。
txt格式是 class, xcenter, ycenter, w, h, 对应中心点和bbox的宽和高,不过该坐标是相对坐标,这里转换时需要除以小图的宽高。
相关代码:
def xml2txt(xmin, xmax, ymin, ymax, class_name, img_width, img_height):# 类别索引class_index = class_dict.index(class_name)# 将box信息转换到yolo格式xcenter = xmin + (xmax - xmin) / 2ycenter = ymin + (ymax - ymin) / 2w = xmax - xminh = ymax - ymin# 绝对坐标转相对坐标,保存6位小数xcenter = round(xcenter / img_width, 6)ycenter = round(ycenter / img_height, 6)w = round(w / img_width, 6)h = round(h / img_height, 6)info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]return info
完整代码
最后附上批量处理的完整代码:
import os
from tqdm import tqdm
from lxml import etreexml_file_path = "E:/Dataset/数据集/可见光数据/原始未裁剪/labels"
output_txt_path = "E:/Dataset/数据集/可见光数据/裁剪后数据/labels"class_dict = ['class1', 'class2']
leap = 1280def parse_xml_to_dict(xml):"""将xml文件解析成字典形式"""if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息return {xml.tag: xml.text}result = {}for child in xml:child_result = parse_xml_to_dict(child) # 递归遍历标签信息if child.tag != 'object':result[child.tag] = child_result[child.tag]else:if child.tag not in result:result[child.tag] = []result[child.tag].append(child_result[child.tag])return {xml.tag: result}def xml2txt(xmin, xmax, ymin, ymax, class_name, img_width, img_height):# 类别索引class_index = class_dict.index(class_name)# 将box信息转换到yolo格式xcenter = xmin + (xmax - xmin) / 2ycenter = ymin + (ymax - ymin) / 2w = xmax - xminh = ymax - ymin# 绝对坐标转相对坐标,保存6位小数xcenter = round(xcenter / img_width, 6)ycenter = round(ycenter / img_height, 6)w = round(w / img_width, 6)h = round(h / img_height, 6)info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]return infodef write_txt(info, file_name):with open(file_name, encoding="utf-8", mode="a") as f:# 若文件不为空,添加换行if os.path.getsize(file_name):f.write("\n" + " ".join(info))else:f.write(" ".join(info))def main():for xml_file in os.listdir(xml_file_path):with open(os.path.join(xml_file_path, xml_file), encoding="utf-8") as fid:xml_str = fid.read()xml = etree.fromstring(xml_str)data = parse_xml_to_dict(xml)["annotation"]# img_height = int(data["size"]["height"])# img_width = int(data["size"]["width"])img_height = leapimg_width = leapimg_name = xml_file[:-4]for obj in data["object"]:# 获取每个object的box信息xmin = float(obj["bndbox"]["xmin"])xmax = float(obj["bndbox"]["xmax"])ymin = float(obj["bndbox"]["ymin"])ymax = float(obj["bndbox"]["ymax"])class_name = obj["name"]xmin_index = int(xmin / leap)xmax_index = int(xmax / leap)ymin_index = int(ymin / leap)ymax_index = int(ymax / leap)xmin = xmin % leapxmax = xmax % leapymin = ymin % leapymax = ymax % leap# 第一种情况,两个点在相同的图像块中if xmin_index == xmax_index and ymin_index == ymax_index:info = xml2txt(xmin, xmax, ymin, ymax, class_name, img_width, img_height)file_name = output_txt_path + "/" + img_name + "__" + str(xmin_index * leap) + "__" + str(ymin_index * leap) + ".txt"write_txt(info, file_name)# 第二种情况,目标横跨左右两幅图elif xmin_index + 1 == xmax_index and ymin_index == ymax_index:# 保存左半目标info = xml2txt(xmin, leap, ymin, ymax, class_name, img_width, img_height)file_name = output_txt_path + "/" + img_name + "__" + str(xmin_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)# 保存右半目标info = xml2txt(0, xmax, ymin, ymax, class_name, img_width, img_height)file_name = output_txt_path + "/" + img_name + "__" + str(xmax_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)# 第三种情况,目标纵跨上下两幅图elif xmin_index == xmax_index and ymin_index + 1 == ymax_index:# 保存上半目标info = xml2txt(xmin, xmax, ymin, leap, class_name, img_width, img_height)file_name = output_txt_path + "/" + img_name + "__" + str(xmin_index * leap) + "__" + str(ymin_index * leap) + ".txt"write_txt(info, file_name)# 保存下半目标info = xml2txt(xmin, xmax, 0, ymax, class_name, img_width, img_height)file_name = output_txt_path + "/" + img_name + "__" + str(xmin_index * leap) + "__" + str(ymax_index * leap) + ".txt"write_txt(info, file_name)if __name__ == "__main__":main()相关文章:
【目标检测】大图包括标签切分,并转换成txt格式
前言 遥感图像比较大,通常需要切分成小块再进行训练,之前写过一篇关于大图裁切和拼接的文章【目标检测】图像裁剪/标签可视化/图像拼接处理脚本,不过当时的工作流是先将大图切分成小图,再在小图上进行标注,于是就不考…...
gitlab登录出现的Invalid login or password问题
前提 我是在一个项目里创建的gitlab账号,想在别的项目里登录或者官网登录发现怎么都登陆不上 原因 在GitLab中,有两种不同的账号类型:项目账号和个人账号(官网账号)。 项目账号:项目账号是在特定GitLab…...

git本地创建分支并推送到远程
1. 创建本地分支并切换到该分支 比如我创建dev分支。git checkout -b相当于把两条命令git branch 分支名、git checkout分支名合成一条,来实现一条命令新建分支切换分支。 git checkout -b dev 2. 将dev分支推送到远程 -u参数与--set-upstream这一串是一个意思&am…...

手机待办事项app哪个好?
手机是日常很多人随身携带的设备,手机除了拥有通讯功能外,还能帮助大家高效管理日常工作,借助手机上的待办事项提醒APP可以快速地帮助大家规划日常事务,提高工作的效率。 过去,我也曾经在寻找一款能够将工作任务清晰罗…...
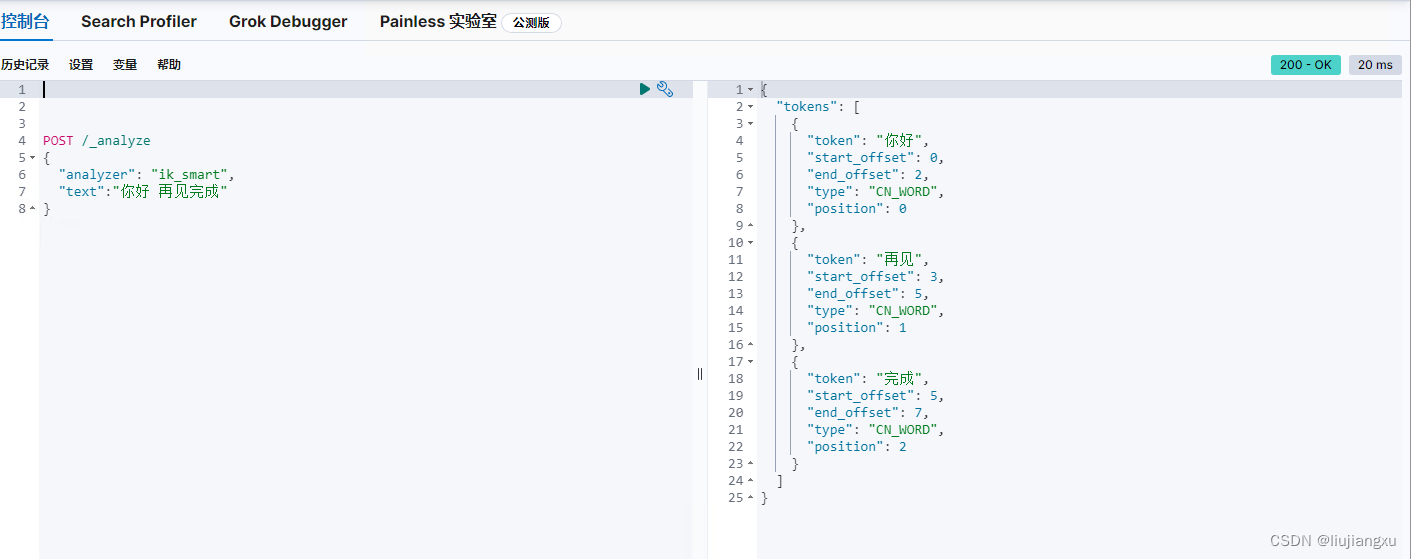
容器运行elasticsearch安装ik分词非root权限安装报错问题
有些应用默认不允许root用户运行,来确保应用的安全性,这也会导致我们使用docker run后一些操作问题,用es安装ik分词器举例(es版本8.9.0,analysis-ik版本8.9.0) 1. 容器启动elasticsearch 如挂载方式&…...

UE4游戏客户端开发进阶学习指南
前言 两年多前写过一篇入门指南,教大家在短时间内快速入门UE4的使用,在知乎被很多人收藏了。如今鸡佬使用UE快三年了,是时候更新一下进阶版本的学习指南。本文对于读者的要求: 有一定的C基础已经入门UE,能够用蓝图和…...

javaee SpringMVC 乱码问题解决
方法一 在web.xml文件中注册过滤器 <!-- 注册过滤器 设置编码 --><filter><filter-name>CharacterEncodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><init-param&…...
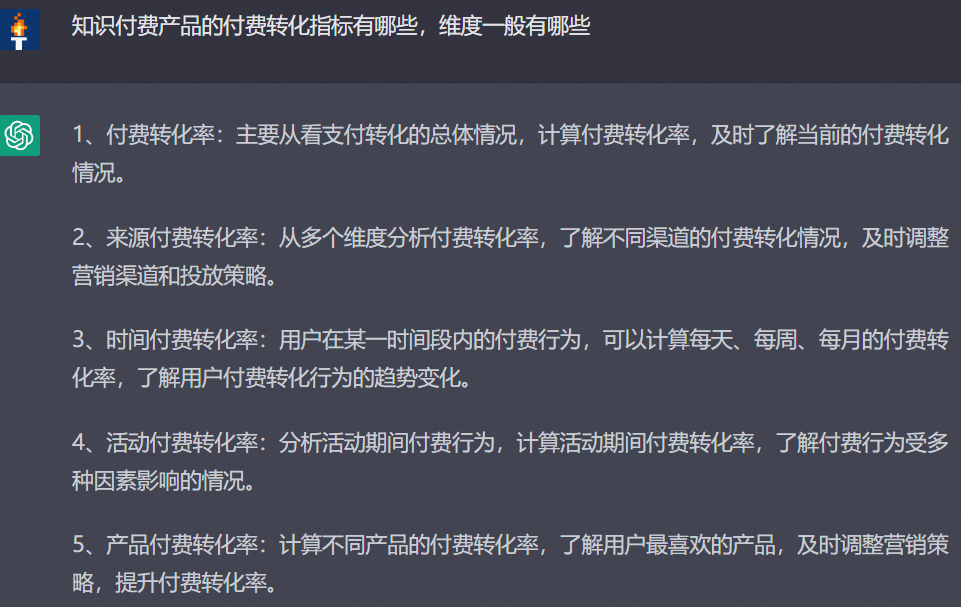
用ChatGPT做数据分析,提升10倍工作效率
目录 写报告分析框架报告框架指标体系设计 Excel 写报告 分析框架 拿到一个专题不知道怎么做?没关系,用ChatGPT列一下框架。 以上分析框架挺像那么回事,如果没思路的话,问问ChatGPT能起到找灵感的作用。 报告框架 报告的框架…...
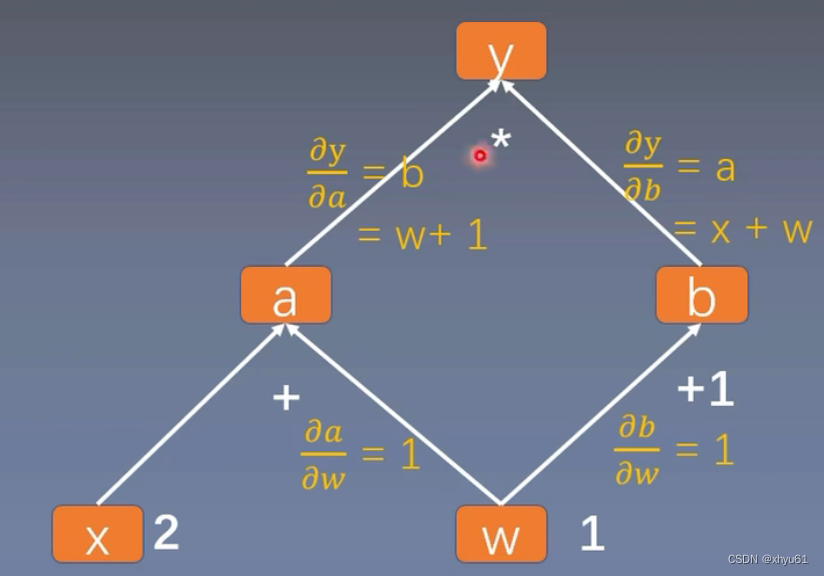
【Pytorch笔记】4.梯度计算
深度之眼官方账号 - 01-04-mp4-计算图与动态图机制 前置知识:计算图 可以参考我的笔记: 【学习笔记】计算机视觉与深度学习(2.全连接神经网络) 计算图 以这棵计算图为例。这个计算图中,叶子节点为x和w。 import torchw torch.tensor([1.]…...
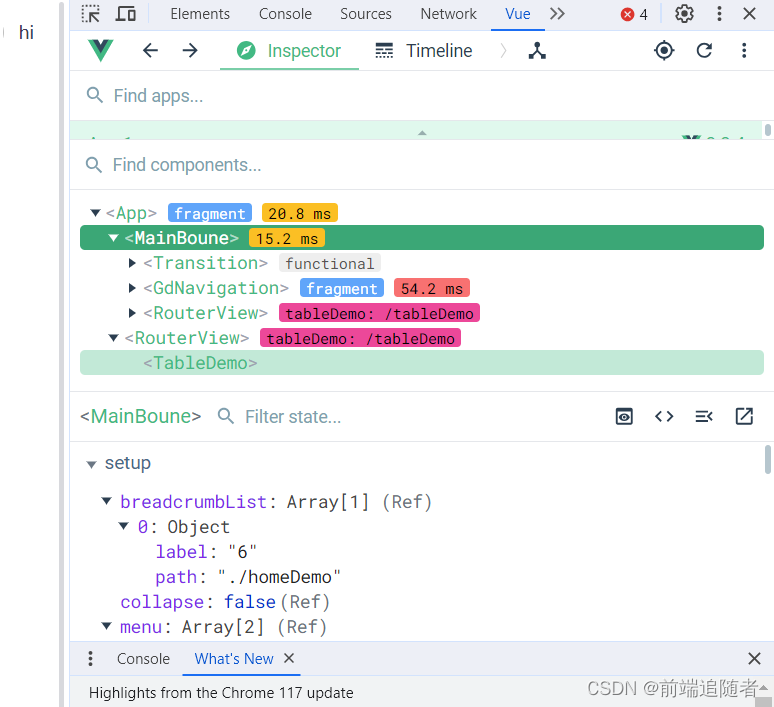
浏览器安装vue调试工具
下载扩展程序文件 下载链接:链接: 下载连接网盘地址, 提取码: 0u46,里面有两个crx,一个适用于vue2,一个适用于vue3,可根据vue版本选择不同的调试工具 crx安装扩展程序不成功,将文件改为rar文件然后解压 安装…...

C/C++学习 -- RSA算法
概述 RSA算法是一种广泛应用于数据加密与解密的非对称加密算法。它由三位数学家(Rivest、Shamir和Adleman)在1977年提出,因此得名。RSA算法的核心原理是基于大素数的数学问题的难解性,利用两个密钥来完成加密和解密操作。 特点 …...
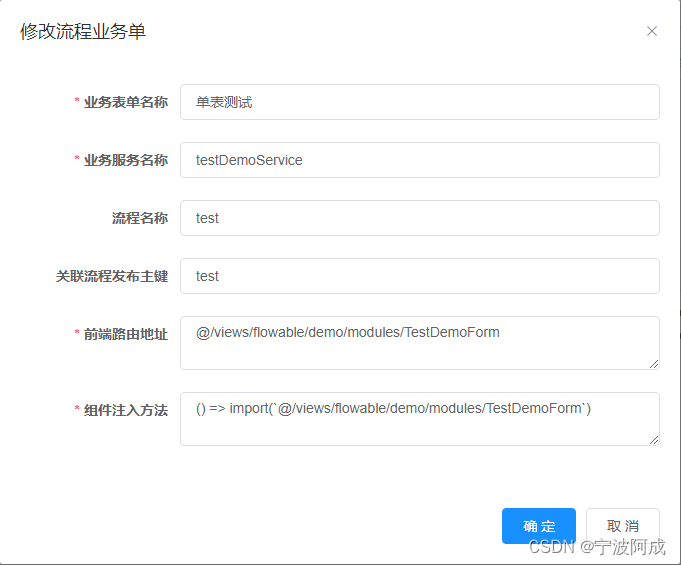
基于若依ruoyi-nbcio支持flowable流程增加自定义业务表单(一)
因为需要支持自定义业务表单的相关流程,所以需要建立相应的关联表 1、首先先建表wf_custom_form -- ---------------------------- -- Table structure for wf_custom_form -- ---------------------------- DROP TABLE IF EXISTS wf_custom_form; CREATE TABLE wf…...

面试经典 150 题 1 —(数组 / 字符串)— 88. 合并两个有序数组
88. 合并两个有序数组 方法一: class Solution { public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {for(int i 0; i<n;i){nums1[mi] nums2[i];}sort(nums1.begin(),nums1.end());} };方法二: clas…...

【大数据 | 综合实践】大数据技术基础综合项目 - 基于GitHub API的数据采集与分析平台
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
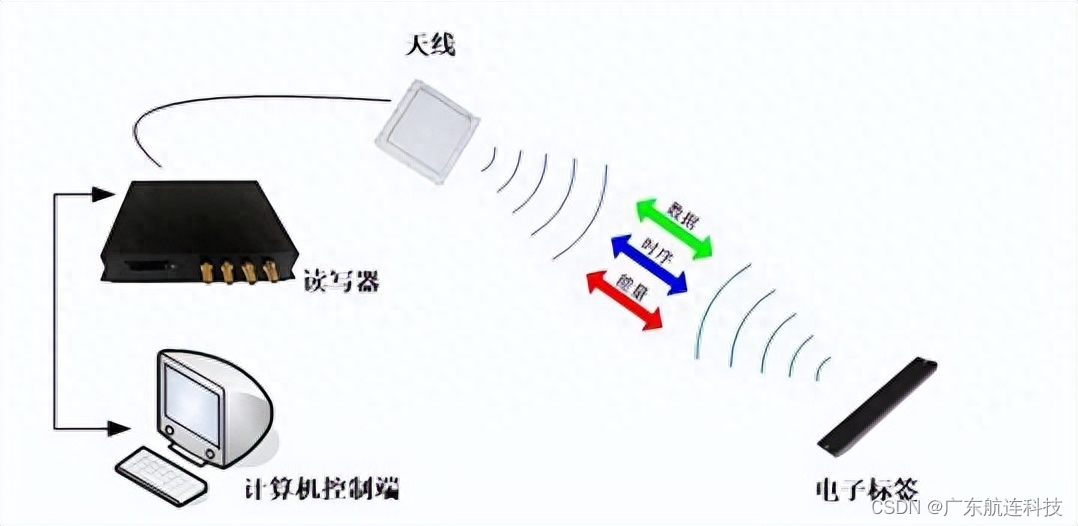
超高频RFID模具精细化生产管理方案
近二十年来,我国的模具行业经历了快速发展的阶段,然而,模具行业作为一个传统、复杂且竞争激烈的行业,企业往往以订单为导向,每个订单都需要进行新产品的开发,从客户需求分析、结构确定、报价、设计、物料准…...

FP-Growth算法全解析:理论基础与实战指导
目录 一、简介什么是频繁项集?什么是关联规则挖掘?FP-Growth算法与传统方法的对比Apriori算法Eclat算法 FP树:心脏部分 二、算法原理FP树的结构构建FP树第一步:扫描数据库并排序第二步:构建树 挖掘频繁项集优化&#x…...

Jmeter 分布式压测,你的系统能否承受高负载?
你可以使用 JMeter 来模拟高并发秒杀场景下的压力测试。这里有一个例子,它模拟了同时有 5000 个用户,循环 10 次的情况。 请求默认配置 token 配置 秒杀接口 结果分析 但是,实际企业中,这种压测方式根本不满足实际需求。下…...

什么是浮动密封?
浮动密封也称为机械面密封或双锥密封,是一种用于各种行业和应用的特殊类型的密封装置。它旨在提供有效的密封和保护,防止污染物的进入以及旋转设备中润滑剂或液体的润滑剂泄漏。 浮动密封件由相同的金属环组成,这些金属环称为密封环…...

浅析前端单元测试
对于前端来说,测试主要是对HTML、CSS、JavaScript进行测试,以确保代码的正常运行。 常见的测试有单元测试、集成测试、端到端(e2e)的测试。 单元测试:对程序中最小可测试单元进行测试。我们可以类比对汽车的测试&…...

线上mysql表字段加不了Fail to get MDL on replica during DDL synchronize,排查记录
某天接近业务高峰期想往表里加字段加不了,报错:Fail to get MDL on replica during DDL synchronize 遂等到业务空闲时操作、还是加不了, 最后怀疑是相关表被锁了,或者有事务一直进行(可能这俩是一个意思)&…...

AI编程助手色彩科学技能库:从OKLCH到APCA的现代色彩实践
1. 项目概述:一个为AI编程助手打造的“色彩科学专家”技能库如果你和我一样,经常在开发与色彩相关的工具、设计系统,或者需要向团队解释为什么某个颜色方案行不通时,总得反复查阅同一堆资料——那个讲解OKLAB色彩空间的视频、那篇…...

深入解析dlsym的RTLD_NEXT:从符号查找到全局介入的实战指南
1. 揭开RTLD_NEXT的神秘面纱:符号查找的"接力赛" 第一次在代码里看到dlsym(RTLD_NEXT, "printf")这种写法时,我盯着屏幕发了五分钟呆——这行代码就像Linux系统中的魔法咒语,明明每个字母都认识,组合起来却让…...
从龟速到极速:如何用trackerslist项目彻底解决BT下载瓶颈
从龟速到极速:如何用trackerslist项目彻底解决BT下载瓶颈 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾经面对BT下载时那令人沮丧的进度条࿱…...
)
若依框架实战:参数验证异常处理(手机号码格式验证案例)
一、前言在后端开发中,参数校验是保证接口健壮性的第一道防线。若依(Ruoyi)框架作为主流的 Java 后台管理系统框架,内置了完善的参数验证与全局异常处理机制。本文将以用户管理模块的手机号码格式验证为例,从触发验证、…...
)
从「LLM 使用者」到「LLM 驾驭者」:小白程序员必备的大模型核心知识体系与实战指南(收藏版)
本文将从底层原理、工程落地、应用优化三个维度,系统拆解大语言模型的核心知识体系,既保证技术深度,又用通俗的语言和实战案例降低理解门槛,适合所有想要从「LLM 使用者」进阶为「LLM 驾驭者」的读者。 一、LLM 核心原理入门&…...

CM-GAI:融合最优传输与连续介质力学的物理约束生成模型
1. 项目概述:当连续介质力学遇见最优传输在工程与材料科学的深水区,我们常常面临一个令人头疼的“数据荒”问题:极端条件下的物理场数据,比如材料在接近熔点的应力-应变行为,或者结构在超高冲击速度下的瞬态变形&#…...

革命性HTTP API设计指南:Heroku实战经验全解析
革命性HTTP API设计指南:Heroku实战经验全解析 【免费下载链接】http-api-design HTTP API design guide extracted from work on the Heroku Platform API 项目地址: https://gitcode.com/gh_mirrors/ht/http-api-design GitHub 加速计划 / ht / http-api-d…...

2024 Q2全球AI搜索基准测试TOP3结果泄露:Perplexity在长尾专业查询中胜率68.4%,但ChatGPT在模糊意图理解上反超——你的团队该押注哪条技术路径?
更多请点击: https://intelliparadigm.com 第一章:2024 Q2全球AI搜索基准测试TOP3结果深度解读 本季度由MLPerf与AI Index联合发布的AI搜索基准测试(SearchBench v2.1)覆盖了17个主流模型,在真实网页索引、多跳推理、…...

地下水位监测仪:实现深井水位远程自动观测
设备是什么地下水位监测仪是一种用于测量地下水、矿山井或地热井中水位高度的仪器。它采用投入式探头设计,基于静水压力原理工作:当传感器探头固定在水下某一点时,通过感知该点上方水柱产生的压力,结合安装高程,即可换…...

从零构建高频无线传输系统:调幅技术实战解析
1. 调幅无线传输系统入门指南 第一次接触调幅无线传输系统时,我也被各种专业术语搞得一头雾水。简单来说,调幅(AM)就是通过改变载波信号的幅度来传递信息的技术。想象一下快递员送包裹:载波就像快递车,而我们要发送的信息就是包裹…...