GPT系列论文解读:GPT-1
GPT系列
GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型:
-
GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer编码器层和1.5亿个参数。GPT-1的训练数据包括了互联网上的大量文本。
-
GPT-2:GPT-2于2019年发布,是GPT系列的第二个版本。它比GPT-1更大更强大,使用了24个Transformer编码器层和1.5亿到15亿个参数之间的不同配置。GPT-2在生成文本方面表现出色,但由于担心滥用风险,OpenAI最初选择限制了其训练模型的发布。
-
GPT-3:GPT-3于2020年发布,是GPT系列的第三个版本,也是目前最先进和最强大的版本。它采用了1750亿个参数,拥有1750亿个可调节的权重。GPT-3在自然语言处理(NLP)任务中表现出色,可以生成连贯的文本、回答问题、进行对话等。
-
GPT-3.5:GPT-3.5是在GPT-3基础上进行微调和改进的一个变种,它是对GPT-3的进一步优化和性能改进。
GPT系列的模型在自然语言处理领域取得了巨大的成功,并在多个任务上展示出了强大的生成和理解能力。它们被广泛用于文本生成、对话系统、机器翻译、摘要生成等各种应用中,对自然语言处理和人工智能领域的发展有着重要的影响。
GPT系列是当前自然语言处理领域下最流行,也是商业化效果最好的自然语言大模型,并且他的论文也对NLP的领域产生巨大影响,GPT首次将预训练-微调模型真正带入NLP领域,同时提出了多种具有前瞻性的训练方法,被后来的BERT等有重大影响的NLP论文所借鉴。
目录
- GPT系列
- GPT-1模型架构
- 1. 无监督的预训练部分
- 2. 有监督的微调部分
- 3. 特定于任务的输入转换
GPT-1模型架构
GPT的训练过程由两个阶段组成。第一阶段是在大型文本语料库上学习高容量语言模型。接下来是微调阶段,我们使模型适应带有标记数据的判别任务。
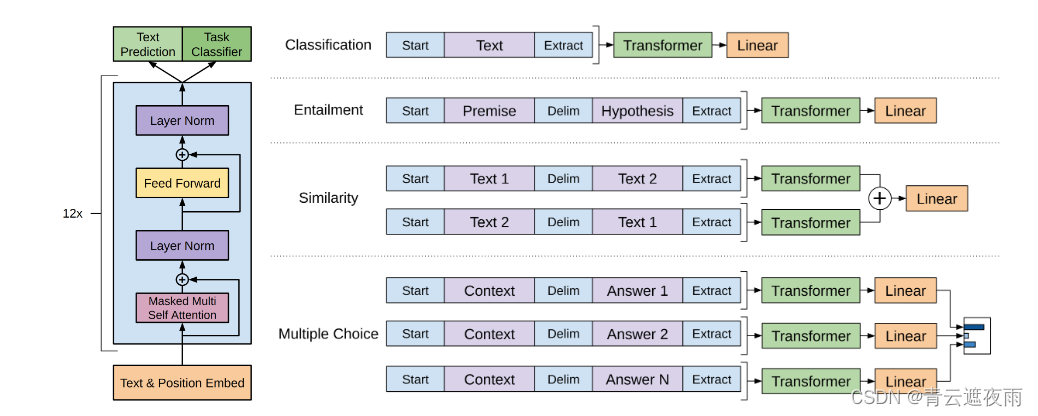
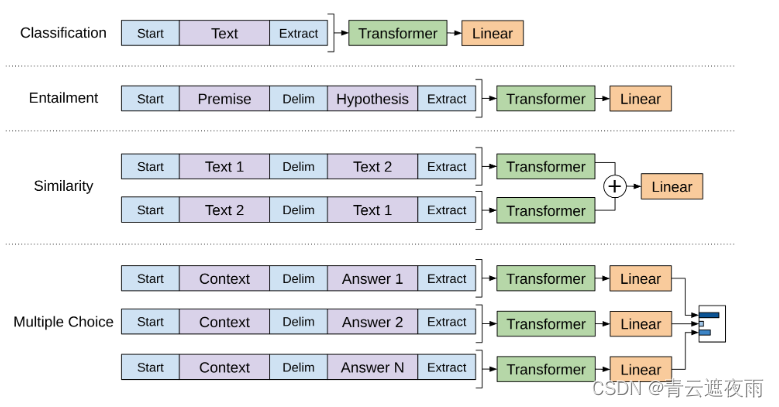
上图是GPT架构的整体示意图,左图是论文中所使用的 Transformer 架构,右图表示了用于对不同任务进行微调的输入转换。我们将所有结构化输入转换为Tokens序列,以便由我们的预训练模型进行处理,然后是线性+softmax层。
1. 无监督的预训练部分
给定一个无监督的标记语料库 U = u 1 , . . . , u n U = {u_1,. . . , u_n} U=u1,...,un,我们使用标准语言建模目标来最大化以下可能性:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(U)=\sum_{i}logP(u_i|u_{i-k},...,u_{i-1};\theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;θ)
其中 k 是上下文窗口的大小,条件概率 P 使用参数为 θ 的神经网络进行建模。这些参数使用随机梯度下降进行训练。
在GPT的论文中,使用多层 Transformer 解码器作为语言模型,它是 Transformer的变体。该模型对输入上下文标记应用多头自注意力操作,然后是位置前馈层,以生成目标标记的输出分布:
h 0 = U W e + W p h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) i ∈ [ 1 , n ] P ( u ) = s o f t m a x ( h n W e T ) h_0=UW_{e}+W_p \\ h_l=transformer\_block(h_{l-1}) i\in[1,n]\\ P(u)=softmax(h_nW_e^T) h0=UWe+Wphl=transformer_block(hl−1)i∈[1,n]P(u)=softmax(hnWeT)
其中 U = ( u − k , . . . , u − 1 ) U = (u_{−k}, ..., u_{−1}) U=(u−k,...,u−1) 是标记的上下文向量,n 是层数, W e W_e We 是标记嵌入矩阵, W p W_p Wp 是位置嵌入矩阵。,对于所有的U,得到的所有的 P P P的对数和就是我们需要优化的目标,即上面说的 L 1 L_1 L1
2. 有监督的微调部分
当语言模型训练结束后,就可以将其迁移到具体的NLP任务中,假设将其迁移到一个文本分类任务中,记此时的数据集为 C C C,对于每一个样本,其输入为 x 1 , . . , x m x_1,..,x_m x1,..,xm ,输出为 y y y。对于每一个输入,经过预训练后的语言模型后,可以直接选取最后一层Transformer最后一个时间步的输出向量 h l m h_l^m hlm,然后在其后面接一层全连接层,即可得到最后的预测标签概率:
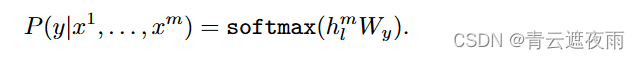
其中, W y W_y Wy为引入的全来凝结层的参数矩阵。因此,可以得到在分类任务中的目标函数:
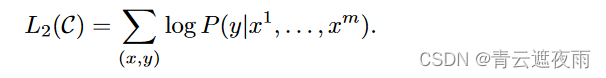
在具体的NLP任务中,作者在fine-tuning时也把语言模型的目标引入到目标函数中,作为辅助函数,作者发现这样操作可以提高模型的通用能力,并且加速模型手来你,其形式如下:
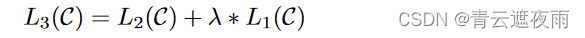
其中 λ一般取0.5。
3. 特定于任务的输入转换
不过,上面这个例子知识对与文本分类任务,如果是对于其他任务,比如文本蕴涵、问答、文本相似度等,那么GPT该如何进行微调呢?
文本蕴涵:对于文本蕴涵任务(文本间的推理关系,问题-答案),作者用一个$负号将文本和假设进行拼接,并在拼接后的文本前后加入开始符 start 和结束符 end,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
文本相似度:对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用“$”进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量表示 h l m h_l^m hlm,将这两个向量进行元素相加,然后再接如线性层和softmax层。
问答和尝试推理:对于问答和尝试推理任务,首先将本经信息与问题进行拼接,然后再将拼接后的文本一次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得到每个输入的预测值。
具体的方法可以查看下图,可以发现,对这些任务的微调主要是:
- 增加线性层的参数
- 增加起始符、结束符和分隔符三种特殊符号的向量参数
注意:GPT1主要还是针对文本分类任务和标注性任务,对于生成式任务,比如问答,机器翻译之类的任务,其实并没有做到太好效果的迁移,但是GPT-2的提出主要针对生成式的任务。我们放到下期再讲。
相关文章:
GPT系列论文解读:GPT-1
GPT系列 GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型: GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer…...

数学分析:含参变量的积分
同样很多收敛性的证明不是重点,但里面的知识还是需要适当掌握,知道中间的大致思考和解决路径即可。 本质还是极限的可交换性,求导可以换到积分里面去操作。 这里要注意变量的区别,首先积分的被积变量是x,但是函数的变量…...

关于一篇ElementUI之CUD+表单验证
目录 一.CUD增删改查简述 1.1.增删改功能实现 二.表单验证 前端所有代码: 好啦今天就分享到这了,希望能帮到你哦!!! 以下的代码基于我博客中的代码进行续写 : 关于ElementUI之动态树数据表格分页实例 一.CUD增删改…...

VUE模板编译的实现原理
前言 在Vue.js 2.0中,模板编译是通过将模板转换为渲染函数来实现的。渲染函数是一个函数,它返回虚拟DOM节点,用于渲染实际的DOM。Vue.js的模板编译过程可以分为以下几个步骤: 将模板解析为抽象语法树(AST)…...

基础算法之——【动态规划之路径问题】1
今天更新动态规划路径问题1,后续会继续更新其他有关动态规划的问题!动态规划的路径问题,顾名思义,就是和路径相关的问题。当然,我们是从最简单的找路径开始! 动态规划的使用方法: 1.确定状态并…...
三十三、【进阶】索引的分类
1、索引的分类 (1)总分类 主键索引、唯一索引、常规索引、全文索引 (2)InnoDB存储引擎中的索引分类 2、 索引的选取规则(InnoDB存储引擎) 如果存在主键,主键索引就是聚集索引; 如果不存在主键ÿ…...
VBox启动失败、Genymotion启动失败、Vagrant迁移
VBox启动失败、Genymotion启动失败、Vagrant迁移 2023.10.9 最新版本vbox7.0.10、Genymotion3.5.0 Vbox启动失败 1、查看日志 Error -610 in supR3HardenedMainInitRuntime! (enmWhat4) Failed to locate ‘vcruntime140.dll’ 日志信息查看方法->找到虚拟机所在位置->…...
一篇短小精悍的文章让你彻底明白KMP算法中next数组的原理
以后保持每日一更,由于兴趣较多,更新内容不限于数据结构,计算机组成原理,数论,拓扑学......,所谓:深度围绕职业发展,广度围绕兴趣爱好。往下看今日内容 一.什么是KMP算法 KMP&#x…...
CSS盒子定位的扩张
定位的扩展 绝对定位(固定定位)会完全压住盒子 浮动元素不会压住下面标准流的文字,而绝对定位或固定位会压住下面标准流的所有内容 如果一个盒子既有向左又有向右,则执行左,同理执行上 显示隐藏 display: none&…...
SpringBoot整合POI实现Excel文件读写操作
1.环境准备 1、导入sql脚本: create database if not exists springboot default charset utf8mb4;use springboot;create table if not exists user (id bigint(20) primary key auto_increment comment 主键id,username varchar(255) not null comment 用…...

从零开始的力扣刷题记录-第八十七天
力扣每日四题 129. 求根节点到叶节点数字之和-中等130. 被围绕的区域-中等437. 路径总和 III-中等376. 摆动序列-中等总结 129. 求根节点到叶节点数字之和-中等 题目描述: 给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。 …...

【1】c++设计模式——>UML类图的画法
UML介绍 UML:unified modeling language 统一建模语言 面向对象设计主要就是使用UML类图,类图用于描述系统中所包含的类以及他们之间的相互关系,帮助人们简化对系统的理解,他是系统分析和设计阶段的重要产物,也是系统编码和测试的…...

SAP UI5 指定 / 变更版本
SAP UI5 指定 / 变更版本 Currently, SAP Fiori tools support SAP Fiori elements and SAPUI5 freestyle projects with minimum SAPUI5 versions 1.65 or higher. In case there’s a need to test an existing projects with a lower SAPUI5 version, the following worka…...

SpringMVC中异常处理详解
单个控制器异常处理 // 添加ExceptionHandler,表示该方法是处理异常的方法,属性为处理的异常类ExceptionHandler({java.lang.NullPointerException.class,java.lang.ArithmeticException.class})public String exceptionHandle1(Exception ex, Model mo…...
PPT课件培训视频生成系统实现全自动化
前言 困扰全动自化的重要环节,AI语音合成功能,终于可以实现自动化流程,在此要感谢团队不懈的努力和韧性的精神! 实现原理 请参照我的文章《Craneoffice云PPT课件培训视频生成系统》 基本流程 演示视频 PPT全自动 总结 过去实…...
基于腾讯云的OTA远程升级
一、OTA OTA即over the air,是一种远程固件升级技术,它允许在设备已经部署在现场运行时通过网络远程更新其固件或软件。OTA技术有许多优点,比如我们手机系统有个地方做了优化,使用OTA技术我们就不用召回每部手机,直接通过云端就可…...
如何在VS2022中进行调试bug,调试的快捷键,debug与release之间有什么区别
什么是bug 在学习编程的过程中,应该都听说过bug吧,那么bug这个词究竟是怎么来的呢? 其实Bug的本意是“虫子”或者“昆虫”,在1947年9月9日,格蕾丝赫柏,一位为美国海军工作的电脑专家,也是最早…...

初识jmeter及简单使用
目录 1、打开页面: 2、添加线程组: 3、线程组中设置参数: 4、添加请求 5、添加一个http请求后,设置请求内容 6、添加察看结果树 7、执行,查看结果 一般步骤是:在测试计划下面新建一个线程组…...
Spring 在多线程环境下如何确保事务一致性
问题在现 如何解决异步执行 多线程环境下如何确保事务一致性 事务王国回顾 事务实现方式回顾 编程式事务 利用编程式事务解决问题 问题分析完了,那么如何解决问题呢? 小结 问题在现 我先把问题抛出来,大家就明白本文目的在于解决什…...

DIY改造:为Hakko FX-901烙铁打造USB-C充电电池包
1. 项目概述:打造你的专属USB充电无线烙铁 如果你和我一样,经常需要带着烙铁跑现场——无论是调试RC模型、在Maker Faire上修复作品,还是在户外临时搭建一个电子装置——那你一定对传统无线烙铁的痛点深有体会。四节AA电池,用不了…...

终极GitHub加速方案:3步让你的下载速度飙升10倍
终极GitHub加速方案:3步让你的下载速度飙升10倍 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的龟速下载…...

终极Python通达信数据读取指南:5分钟快速入门量化分析
终极Python通达信数据读取指南:5分钟快速入门量化分析 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信数据读取一直是Python开发者面临…...

Taotoken的Token Plan套餐相比按量计费能为长期项目节省多少
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐相比按量计费能为长期项目节省多少 对于需要长期、稳定调用大模型API的项目而言,成本的可预测…...

健康160自动挂号脚本:Python自动化预约医院专家号的终极解决方案
健康160自动挂号脚本:Python自动化预约医院专家号的终极解决方案 【免费下载链接】health160 健康160自动挂号脚本,用魔法对抗魔法,禁止商用🖖 项目地址: https://gitcode.com/gh_mirrors/he/health160 还在为抢不到医院专…...

APK Installer完整指南:在Windows电脑上快速安装Android应用的终极解决方案
APK Installer完整指南:在Windows电脑上快速安装Android应用的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直…...

基于改进型PCNN的不规则图像自适应分割算法研究
基于改进型PCNN的不规则图像自适应分割算法研究根据论文中的相关内容,以下是使用不同方法解决图像分割问题并进行改进的研究:冯登超等人提出了基于改进型脉冲耦合神经网络(PCNN)的自适应分割算法。他们在原有PCNN模型的基础上对神…...

DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能
DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为NVIDIA、AMD和Intel显卡用户设计的智能超采样文件管理工…...

Gemini3.1Pro数据分析报告自动化实战
用 Gemini 3.1 Pro 快速生成数据分析报告并自动可视化:端到端闭环(生成—验证—反思—修正—回归) 门控降级 4周MVP路线图要“快速生成数据分析报告并可视化”,真正难点不是生成文字,而是把报告做成可核验、可复用、可…...

彻底释放Mac磁盘空间:Pearcleaner如何智能清理应用残留文件
彻底释放Mac磁盘空间:Pearcleaner如何智能清理应用残留文件 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾将应用拖入废纸篓后…...