Elasticsearch:时间点 API
Elasticsearch:时间点 API-CSDN博客
在今天的文章中,我将着重介绍 Point in time API。在接下来的文章中,我将介绍如何运用 PIT 来对搜索结果进行分页。这也是被推荐使用的方法。
Point in time API
默认情况下,搜索请求针对目标索引的最新可见数据执行,这称为时间点。 Elasticsearch pit(时间点)是一个轻量级的视图,可以查看数据在启动时的状态。 在某些情况下,最好使用同一时间点执行多个搜索请求。 例如,如果在 search_after 请求之间发生刷新,则这些请求的结果可能不一致,因为搜索之间发生的更改仅在最近的时间点可见。
先决条件
如果启用了 Elasticsearch 安全特性,你必须具有目标数据流、索引或别名的读取索引权限。要在某个时间点 (PIT) 中搜索别名,你必须具有该别名的数据流或索引的读取索引权限。
下面,我们将以一些例子来展示如何使用 PIT 来进行搜索。我们首先来导入我们的索引:
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}
我们使用上面的 bulk 命令导入6个数据。它将创建一个叫做 twitter 的索引。
在搜索请求中使用之前,必须明确打开时间点。 keep_alive 参数告诉 Elasticsearch 它应该保持一个时间点存活多久,例如 ?keep_alive=5m。
POST /twitter/_pit?keep_alive=2m
上面的命令将返回如下的结果:
{
"id" : "g-azAwEHdHdpdHRlchZIck44aVdSNlFMNnEyTmVMUGJEVm9RABZxNnpoTVIxQVFIeTRkci1MSGlibU9BAAAAAAAAARtiFldSS2x2LVZJUU5xajU1ZkxCN2dyMUEAARZIck44aVdSNlFMNnEyTmVMUGJEVm9RAAA="
}
接下来,我们可以使用如下的命令来对我们的索引进行搜索:
GET _search
{
"query": {
"match": {
"city": "北京"
}
},
"pit": {
"id" : "g-azAwEHdHdpdHRlchZIck44aVdSNlFMNnEyTmVMUGJEVm9RABZxNnpoTVIxQVFIeTRkci1MSGlibU9BAAAAAAAAARtiFldSS2x2LVZJUU5xajU1ZkxCN2dyMUEAARZIck44aVdSNlFMNnEyTmVMUGJEVm9RAAA=",
"keep_alive": "2m"
}
}
在使用上面的搜索时必须注意的一点是:我们不能使用如下的格式:
GET /twitter/_search
也就是说,我们不能使用索引名作为请求的一部分。我们必须注意一下的几个方面:
带有 pit 参数的搜索请求不得指定 index、routing 和 preference,因为这些参数是从时间点复制的。
id 参数告诉 Elasticsearch 从这个时间点使用上下文执行请求。
keep_alive 参数告诉 Elasticsearch 应该将时间点的生存时间延长多长时间。
在上面,我们设置 keep_alive 为2分钟。当我们在2分钟后再执行上面的搜索时,我们可以看到如下的错误信息:
{
"error" : {
"root_cause" : [
{
"type" : "search_context_missing_exception",
"reason" : "No search context found for id [72546]"
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "twitter",
"node" : "q6zhMR1AQHy4dr-LHibmOA",
"reason" : {
"type" : "search_context_missing_exception",
"reason" : "No search context found for id [72546]"
}
}
]
},
"status" : 404
}
重要:开放时间点请求和后续的每个搜索请求可以返回不同的 id; 因此对于下一个搜索请求总是使用最近收到的 id。
我们接下来做另外一个实验。我们首先再次运行如下的命令:
POST /twitter/_pit?keep_alive=2m
运行完后,我们得到一个不一样的 id,尽管这个新的 id 和上次返回的值长的非常像。
我们使用最新的 id 来做如下的查询:
GET _search
{
"query": {
"match": {
"city": "北京"
}
},
"pit": {
"id" : "g-azAwEHdHdpdHRlchZIck44aVdSNlFMNnEyTmVMUGJEVm9RABZxNnpoTVIxQVFIeTRkci1MSGlibU9BAAAAAAAAAR8tFldSS2x2LVZJUU5xajU1ZkxCN2dyMUEAARZIck44aVdSNlFMNnEyTmVMUGJEVm9RAAA=",
"keep_alive": "2m"
}
}
我们可以看到有5个这样的文档:
我们接下来,使用如下的命令来添加一个新的文档:
PUT twitter/_doc/7
{
"user": "张三",
"message": "今天天气真好",
"uid": 8,
"age": 35,
"city": "北京",
"province": "北京",
"country": "中国",
"address": "中国北京市朝阳区",
"location": {
"lat": "31.175927",
"lon": "121.383328"
}
}
请注意这个文档的 city 字段也是 “北京”,那么在新增加一个文档后,再次来做如下的查询:
GET _search
{
"query": {
"match": {
"city": "北京"
}
},
"pit": {
"id" : "g-azAwEHdHdpdHRlchZIck44aVdSNlFMNnEyTmVMUGJEVm9RABZxNnpoTVIxQVFIeTRkci1MSGlibU9BAAAAAAAAAR8tFldSS2x2LVZJUU5xajU1ZkxCN2dyMUEAARZIck44aVdSNlFMNnEyTmVMUGJEVm9RAAA=",
"keep_alive": "2m"
}
}
我们可以看到和之前一模一样的结果,还是5个文档。
然后,当我们做如下的查询:
GET /twitter/_search
{
"query": {
"match": {
"city": "北京"
}
}
}
我们可以清楚地看到有6个文档的 city 是 “北京”
这到底是怎么回事呢?究其原因就是当我们查询时使用 pit 参数时,它只能查询在那个时间点之前的所有文档,而后面新增加的文档不能被查询到。这个在实际的很多应用中非常有用。比如针对一个快速变化的索引来说,我们想对它进行表格化,我们不希望在我们进行分页时每次得到的数据集是不同的。
保持时间点活着
传递给开放时间点请求和搜索请求的 keep_alive 参数延长了相应时间点的生存时间。 该值(例如 1m,参见时间单位)不需要足够长来处理所有数据 — 它只需要足够长以用于下一个请求。
通常,后台合并过程通过将较小的段合并在一起以创建新的更大的段来优化索引。 一旦不再需要较小的段,它们就会被删除。 但是,开放时间点会阻止删除旧段,因为它们仍在使用中。
提示:保持旧段(segment)处于活动状态意味着需要更多的磁盘空间和文件句柄。 确保你已将节点配置为具有充足的空闲文件句柄。 请参阅文件描述符。
此外,如果一个段(segment)包含已删除或更新的文档,那么该时间点必须跟踪该段中的每个文档在初始搜索请求时是否处于活动状态。 如果索引上有许多打开的时间点,并且会受到持续删除或更新的影响,请确保你的节点有足够的堆空间。
你可以使用节点统计 API 检查有多少时间点(即搜索上下文)打开:
GET /_nodes/stats/indices/search
关闭时间点 API
时间点在其 keep_alive 结束后自动关闭。 然而,保持时间点是有代价的,如上一节所述。 一旦不再用于搜索请求,就应关闭时间点。我们可以通过如下的命令来对它进行关闭:
DELETE /_pit
{
"id" : "g-azAwEHdHdpdHRlchZIck44aVdSNlFMNnEyTmVMUGJEVm9RABZxNnpoTVIxQVFIeTRkci1MSGlibU9BAAAAAAAAASLCFldSS2x2LVZJUU5xajU1ZkxCN2dyMUEAARZIck44aVdSNlFMNnEyTmVMUGJEVm9RAAA="
}
如果该 id 还是 alive 的状态,那么它将返回:
{
"succeeded" : true,
"num_freed" : 1
}
在上面,如果返回 true,则与时间点 ID 关联的所有搜索上下文都将成功关闭。num_freed 表示多少个搜索上下文数量已成功关闭。
参考:
【1】https://www.elastic.co/guide/en/elasticsearch/reference/current/point-in-time-api.html
————————————————
版权声明:本文为CSDN博主「Elastic 中国社区官方博客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/UbuntuTouch/article/details/119926953
相关文章:

Elasticsearch:时间点 API
Elasticsearch:时间点 API-CSDN博客 在今天的文章中,我将着重介绍 Point in time API。在接下来的文章中,我将介绍如何运用 PIT 来对搜索结果进行分页。这也是被推荐使用的方法。 Point in time API 默认情况下,搜索请求针对目标…...

hive数据表定义
分隔符 CREATE TABLE emp( userid bigint, emp_name array<string>, emp_date map<string,date>, other_info struct<deptname:string, gender:string>) ROW FORMAT DELIMITED FIELDS TERMINATED BY \t COLLECTION ITEMS TERMINATED BY , MAP KEYS TERMINAT…...

OpenMesh 网格简化之顶点聚类
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 顶点聚类方法将落在给定大小体素中的所有顶点集中到单个顶点之上,其过程有点类似于点云体素下采样,之后再基于聚类之后的顶点重新连接面片,以达到网格简化的目的。 二、实现代码 #define _USE_MATH_DEFINES #in…...

C++ 类和对象篇(八) const成员函数和取地址运算符重载
目录 一、const成员函数 1. const成员函数是什么? 2. 为什么有const成员函数? 3. 什么时候需要使用const修饰成员函数? 二、取地址运算符重载 1. 为什么需要重载取地址运算符? 2. 默认取地址运算符重载函数 3. 默认const取地址运…...

k8s 集群安装(vagrant + virtualbox + CentOS8)
主机环境:windows 11 k8s版本:v1.25 dashboard版本:v2.7.0 calico版本: v3.26.1 CentOS8版本:4.18.0-348.7.1.el8_5.x86_64 用到的脚本: https://gitcode.net/sundongsdu/k8s_cluster 1. Vagrant创建…...
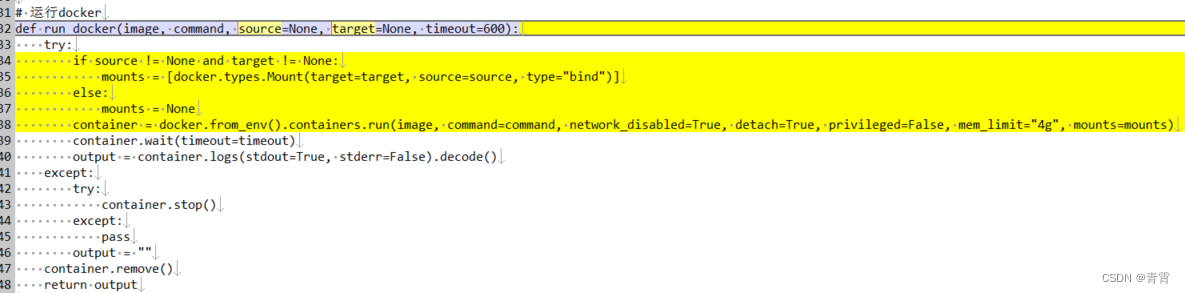
8、Docker数据卷与数据卷容器
一、数据卷(Data Volumes) 为了很好的实现数据保存和数据共享,Docker提出了Volume这个概念,简单的说就是绕过默认的联合文件系统,而以正常的文件或者目录的形式存在于宿主机上。又被称作数据卷。 数据卷 是一个可供一个或多个容器使用的特殊目…...
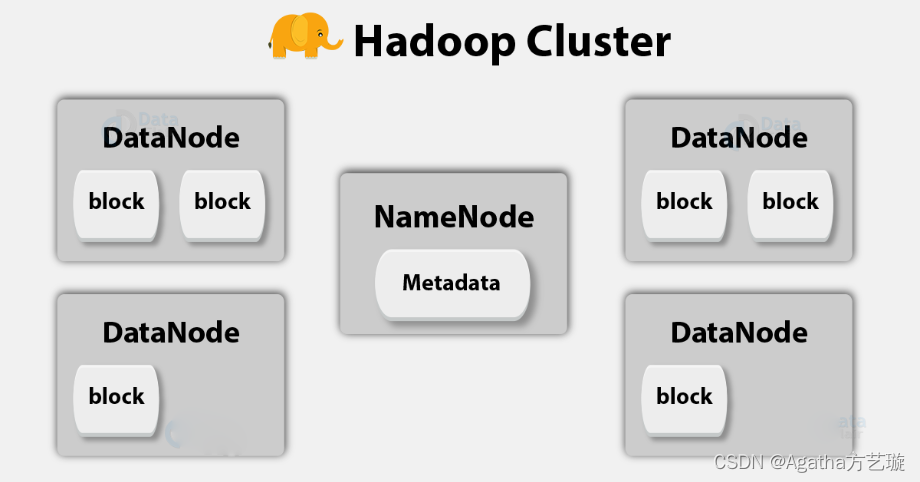
大数据与Hadoop入门理论
一、大数据的3种数据类型 1、结构化数据 可定义,有类型、格式、结构的强制约束 如:RDBMS(关系型数据库管理系统) 2、非结构化数据 没有规律没有数据约束可言,很复杂难以解析 如:文本文件,视…...

持续集成部署-k8s-深入了解 Pod:探针
持续集成部署-k8s-深入了解 Pod:探针 1. 探针分类2. 探针探测方式3. 探针参数配置4. 启动探针的应用5. Liveness 探针的应用6. Readiness 探针的应用1. 探针分类 Kubernetes 中的探针是指容器内的进程用于告知 Kubernetes 组件其自身状态的机制; Readiness Probe:就绪探针用…...
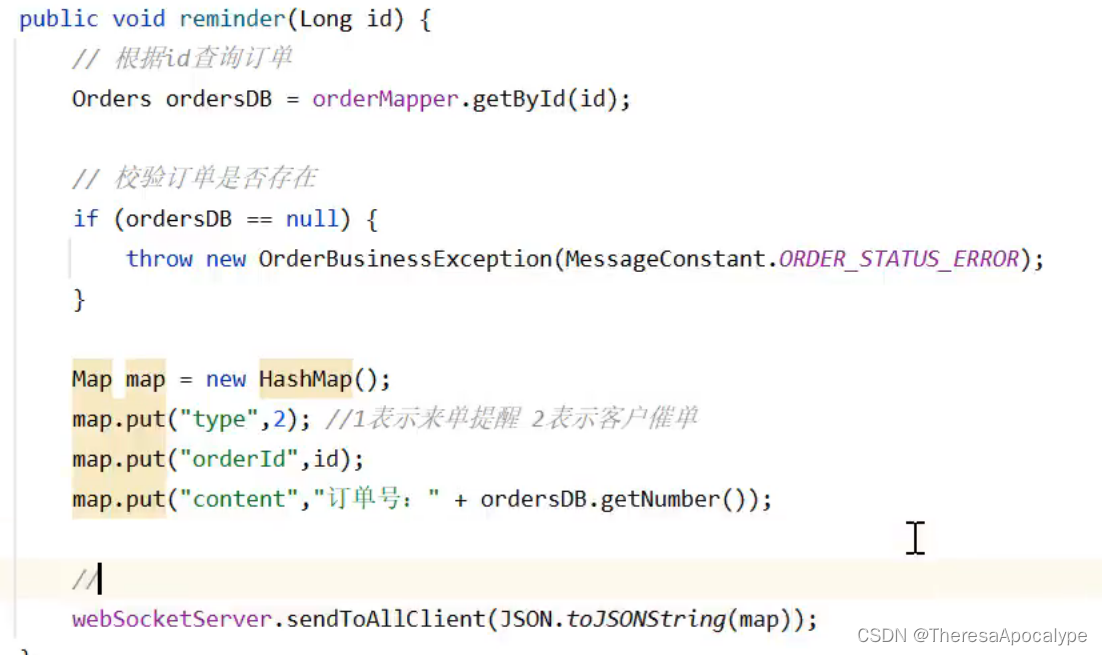
来单提醒/客户催单 ----苍穹外卖day9
来单提醒 需求分析 代码开发 注意:前端请求的并不是8080端口;而是先请求Nginx,Nginx进行反向代理以后转发到8080端口 这段代码首先创建了一个orders类用于更新订单状态 并且在更新状态后使用websocket发送给后端提醒 将信息放在map后,使用json的string化方式传给一个接收对象,…...
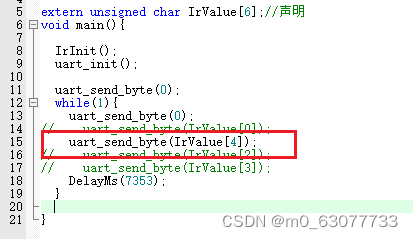
【单片机】18-红外线遥控
一、红外遥控背景知识 1.人机界面 (1)当面操作:按键,旋转/触摸按键,触摸屏 (2)遥控操作:红外遥控,433M/2.4G无线通信【穿墙能力强】,蓝牙-WIFI-Zigbee-LoRa等…...

【Node.js】module 模块化
认识 node.js Node.js 是一个独立的 JavaScript 运行环境,能独立执行 JS 代码,可以用来编写服务器后端的应用程序。基于Chrome V8 引擎封装,但是没有 DOM 和 BOM。Node.js 没有图形化界面。node -v 检查是否安装成功。node index.js 执行该文…...

Vue中如何进行分布式日志收集与日志分析(如ELK Stack)
在Vue中实现分布式日志收集与日志分析(使用ELK Stack) 日志收集和分析在现代应用程序中是至关重要的,它们可以帮助开发人员监视和诊断应用程序的行为,从而提高应用程序的稳定性和性能。ELK Stack(Elasticsearch、Logs…...
)
java学习--day23(线程池)
1.线程池Pool 线程池一个容纳了多个线程的容器,其中的线程可以反复的使用。省去了频繁创建线程的对象的操作,无需反复创建线程而消耗更多的资源 在 Java 语言中,并发编程都是通过创建线程池来实现的,而线程池的创建方式也有很多种…...

Unity Golang教程-Shader编写一个流动的云效果
创建目录 一个友好的项目,项目目录结构是很重要的。我们先导入一个登录界面模型资源。 我们先创建Art表示是美术类的资源,资源是模型创建Model文件夹,由于是在登录界面所以创建Login文件夹,下面依次是模型对应的资源,…...

Python数据攻略-Pandas与地理空间数据分析
地理空间数据分析已经成为数据分析不可或缺的一部分。无论是在城市规划、交通分析,还是在环境科学中,地理空间数据都发挥着关键作用。 本文将为初学者和新手提供一个详细的指南,通过使用Python的Pandas库和Geopandas库,来进行地理空间数据分析。 文章目录 用Pandas处理地理…...

sourceTree无法启动
前几天win10系统自动更新后,sourceTree就无法打开了,双击只是图标闪一下,电脑重启后还是无法打开。找到了网上几种方法进行尝试: 方法一:修改配置信息 在自己的电脑路径下: C:\Users\你的用户名\AppData…...

【ARM Coresight 系列文章19 -- Performance Monitoring Unit(性能监测单元)
文章目录 1.1 PMU 介绍1.2 PMU 寄存器1.2.1 PMU 管理寄存器1.2.2 PMU 外设识别寄存器1.2.3 PMU 组件识别寄存器1.3 性能监控事件1.3.1 Cortex-A9 特定事件1.1 PMU 介绍 许多体系结构都包含 PMU(Performance Monitoring Unit)硬件,用于跟踪、计数系统内部的一些底层硬件事件…...
前端学习| 第二章
CSS学习|第一章 前言一、概述1. 语法规定2. 代码风格 二、选择器1. 基础选择器标签选择器类选择器id选择器通配符选择器 2. 复合选择器后代选择器子元素选择器并集选择器伪类选择器链接伪类选择器focus 伪类选择器 三、引入方式四、显示模式1. 块元素2. 行内元素3. 行内块元素4…...
Unity中Shader光强与环境色
文章目录 前言一、实现下图中的小球接受环境光照实现思路:1、在Pass中使用前向渲染模式2、使用系统变量 _LightColor0 获取场景中的主平行灯 二、返回环境中主环境光的rgb固定a(亮度),小球亮度还随之改变的原因三、获取Unity中的环境光的颜色1、Color模式…...

Android9 查看连接多个蓝牙耳机查看使用中的蓝牙耳机
#Android9 查看连接多个蓝牙耳机查看使用中的蓝牙耳机 文章目录 一、主要api:二、BluetoothA2dp 对象的获取三、获取 BluetoothDevice 对象,四、其他: Android 9.0之后,支持一台手机可以同时连接多个蓝牙设备。 但是判断那个蓝牙…...
)
保姆级教程:用Arduino IDE 2 + STM32Duino点亮你的第一块STM32开发板(附ST-Link驱动与CubeProgrammer配置)
从零开始:用Arduino IDE 2与STM32Duino打造STM32开发环境实战指南 当你第一次拿到STM32开发板时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我深知一个清晰、完整的入门指南对新手有多重要。本文将带你一步步搭建开发环境,避…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

开源智能体技术解析:从LangChain到自主抓取,构建自动化工作流
1. 项目概述:从“Awesome”列表看开源智能体生态的演进 最近在梳理一些前沿的自动化工具链时,又翻到了 mergisi/awesome-openclaw-agents 这个仓库。对于长期关注AI Agent(智能体)和自动化工作流开发的同行来说,这类…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

MTKClient终极指南:解锁联发科芯片调试的专业解决方案
MTKClient终极指南:解锁联发科芯片调试的专业解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient作为一款专为联发科(MediaTek)芯片设计的…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...