mysql基础语法速成版
mysql基础语法速成版
- 一、前言
- 二、基础语法
- 2.1 数据库操作
- 2.2 MySQL数据类型
- 2.3 表操作
- 2.3.1 表的创建、删除,及表结构的改变
- 2.3.2表数据的增删改查
- 2.3.4 like模糊查询
- 2.3.5 UNION 操作符
- 2.3.6 order by排序
- 2.3.7 group by分组
- 2.3.8 join连接
- 2.3.9 null处理
- 2.3.10 mysql正则表达式
- 2.3.10 mysql事务
- 2.3.10 mysql索引
- 普通索引
- 三、临时表
- 四、mysql序列
- 五、重复数据处理
- 六、sql注入
一、前言
这里对mysql基础语法进行总结,以便用于复习回顾,对于需要安装教程的可以参看下面的文章。
MySQL8安装教程
二、基础语法
2.1 数据库操作
- 创建数据库
create database 数据库名# 示例
create database mydata
# 或者,但不存在的时候创建数据库
create database if not exists mydata
- 删除数据库
drop database 数据库名# 示例
drop database test
# 或者 但数据存在时删除
drop database if exists test
- 使用数据库
use 数据库名
#eg:
use mydata
2.2 MySQL数据类型
mysql常用数据类型
| 类型 | 大小 | 用途 |
|---|---|---|
| TINYINT | 1 Bytes | 小整数值 |
| INT或INTEGER | 4 Bytes | 大整数值 |
| FLOAT | 4 Bytes | 单精度 |
| 浮点数值 | ||
| DOUBLE | 8 Bytes | 双精度 |
| 浮点数值 | ||
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 小数值 |
| DATE | 3 Bytes | 日期值 |
| TIME | 3 Bytes | 时间值或持续时间 |
| DATETIME | 8 Bytes | 混合日期和时间值 |
| TIMESTAMP | 4 Bytes | 混合日期和时间值,时间戳 |
| CHAR | 0-255 Bytes | 定长字符串 |
| VARCHAR | 0-65535 Bytes | 变长字符串 |
| TEXT | 0-65535 Bytes | 长文本数据 |
2.3 表操作
2.3.1 表的创建、删除,及表结构的改变
- 创建表
CREATE TABLE IF NOT EXISTS `test`(`id` INT UNSIGNED AUTO_INCREMENT, # 设置唯一性约束和自增`title` VARCHAR(100) NOT NULL, # 设置字段不为空`author` VARCHAR(40) NOT NULL,`date` DATE,PRIMARY KEY ( `id` ) # 设置为主键
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 设置引擎为innoDB 默认编码方式为utf8
- 删除表
DROP TABLE table_name ;
DROP TABLE if exists table_name
#eg
DROP TABLE if exists test
- alter命令修改表结构
MySQL 的 ALTER 命令用于修改数据库、表和索引等对象的结构。
ALTER 命令可以添加、修改或删除数据库对象,并且可以用于更改表的列定义、添加约束、创建和删除索引等操作。
- 修改表结构
添加新列:
ALTER TABLE table_name
ADD column_name data_type;
- 修改列定义
ALTER TABLE table_name
MODIFY column_name new_data_type;# 修改默认值ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;# 删除默认值ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
- 修改列名称:
ALTER TABLE table_name
CHANGE old_column_name new_column_name data_type;
- 删除列:
ALTER TABLE table_name
DROP column_name;
如果表只剩一个字段则无法使用drop进行删除
5. 添加约束
添加主键:
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);
- 添加外键:
ALTER TABLE table_name
ADD FOREIGN KEY (column_name) REFERENCES referenced_table(ref_column_name);
- 添加唯一约束:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE (column_name);
- 创建索引
创建普通索引:
ALTER TABLE table_name
ADD INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
- 创建唯一索引:
ALTER TABLE table_name
ADD UNIQUE INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
- 删除索引:
ALTER TABLE table_name
DROP INDEX index_name;
- 重命名表:
ALTER TABLE old_table_name
RENAME TO new_table_name;
- 修改表存储引擎
ALTER TABLE table_name ENGINE = new_storage_engine;
2.3.2表数据的增删改查
- 插入数据
# 语法1
INSERT INTO table_name ( field1, field2,...fieldN )VALUES( value1, value2,...valueN );
# 语法2
INSERT INTO table_name values( value1, value2,...valueN );
- 删除数据
# 方式1
DELETE FROM table_name [WHERE Clause]
# 方式2 清空表的数据,
TRUNCATE TABLE employees;- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
- 可以在 WHERE 子句中指定任何条件
- 可以在单个表中一次性删除记录。
TRUNCATE关键字用于清空表中的所有数据,但不会删除表结构。它比DELETE关键字更快,因为它不记录任何删除操作,也不会在REDO日志中记录任何信息- 需要注意的是,TRUNCATE关键字比DELETE关键字更危险,因为它不记录任何删除操作,因此无法撤销。
- 查询数据
# 语法1
SELECT 列名
FROM 表名
[WHERE 条件] # 条件查询
[LIMIT N][ OFFSET M] # 设置查询记录条数,以及开始查询的位置
# eg
# 查询全部数据
select * from 表名
# 条件查询 查询id大于10的八条记录
select * from 表名 where id > 10 limit 8 - 查询语句中可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 可以在 WHERE 子句中指定任何条件。
- 可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
- 更新数据
UPDATE table_name SET field1=new-value1, field2=new-value2
[WHERE Clause] # 根据条件修改数据
- 可以同时更新一个或多个字段。
- 可以在 WHERE 子句中指定任何条件。
- 可以在一个单独表中同时更新数据。
2.3.4 like模糊查询
LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
SELECT * from tbl WHERE author LIKE '%COM';
- 可以在 WHERE 子句中指定任何条件。
- 可以在 WHERE 子句中使用LIKE子句。
- 可以使用LIKE子句代替等号 =。
LIKE 通常与 % 一同使用,类似于一个元字符的搜索。 - 可以使用 AND 或者 OR 指定一个或多个条件。
- 可以在 DELETE 或 UPDATE 命令中使用 WHERE…LIKE 子句来指定条件。
2.3.5 UNION 操作符
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
SELECT expression1, expression2, ... expression_n # 数据列
FROM tables # 查询的表
[WHERE conditions] # 条件
UNION [ALL | DISTINCT] # all 返回所有数据包括重复数据,distinct相反
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];2.3.6 order by排序
SELECT field1, field2,...fieldN FROM table_name1, table_name2...
ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]# asc 升序 desc 降序,默认排序为升序#eg
SELECT * from tbl ORDER BY submission_date ASC;
- 可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
- 可以设定多个字段来排序。
- 可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
- 可以添加 WHERE…LIKE 子句来设置条件。
2.3.7 group by分组
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;#egSELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
# having一般于group by 一起使用,用来对分组后的集合进行操作SELECT name, COUNT(*) FROM employee_tbl GROUP BY name having age >30;
使用 WITH ROLLUP
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数:
mysql> SELECT name, SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
+--------+--------------+
| name | signin_count |
+--------+--------------+
| 小丽 | 2 |
| 小明 | 7 |
| 小王 | 7 |
| NULL | 16 |
+--------+--------------+
4 rows in set (0.00 sec)其中记录 NULL 表示所有人的登录次数。
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
# 参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
mysql> SELECT coalesce(name, '总数'), SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
+--------------------------+--------------+
| coalesce(name, '总数') | signin_count |
+--------------------------+--------------+
| 小丽 | 2 |
| 小明 | 7 |
| 小王 | 7 |
| 总数 | 16 |
+--------------------------+--------------+
4 rows in set (0.01 sec)2.3.8 join连接
使用 MySQL 的 JOIN 在两个或多个表中查询数据。
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
mysql> use RUNOOB;
Database changed
mysql> SELECT * FROM tcount_tbl;
+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| 菜鸟教程 | 10 |
| RUNOOB.COM | 20 |
| Google | 22 |
+---------------+--------------+
3 rows in set (0.01 sec)mysql> SELECT * from runoob_tbl;
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 |
| 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 |
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
| 5 | 学习 C | FK | 2017-04-05 |
+-----------+---------------+---------------+-----------------+
5 rows in set (0.01 sec)
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
+-------------+-----------------+----------------+
4 rows in set (0.00 sec)
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
+-------------+-----------------+----------------+
4 rows in set (0.01 sec)
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| 5 | FK | NULL |
+-------------+-----------------+----------------+
5 rows in set (0.01 sec)
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| NULL | NULL | 22 |
+-------------+-----------------+----------------+
5 rows in set (0.01 sec)
2.3.9 null处理
IS NULL: 当列的值是 NULL,此运算符返回 true。
IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
<=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 NULL,即 NULL = NULL 返回 NULL 。
MySQL 中处理 NULL 使用 IS NULL 和 IS NOT NULL 运算符。
select * , columnName1+ifnull(columnName2,0) from tableName;
2.3.10 mysql正则表达式
MySQL 同样也支持其他正则表达式的匹配, MySQL中使用 REGEXP 操作符来进行正则表达式匹配。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
#查找name字段中以'st'为开头的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st';
# 查找name字段中以'ok'为结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
#查找name字段中包含'mar'字符串的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar';
# 查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
2.3.10 mysql事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务控制语句:
BEGIN 或 START TRANSACTION 显式地开启一个事务;
COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier 把事务回滚到标记点;
SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
mysql> use RUNOOB;
Database changed
mysql> CREATE TABLE runoob_transaction_test( id int(5)) engine=innodb; # 创建数据表
Query OK, 0 rows affected (0.04 sec)mysql> select * from runoob_transaction_test;
Empty set (0.01 sec)mysql> begin; # 开始事务
Query OK, 0 rows affected (0.00 sec)mysql> insert into runoob_transaction_test value(5);
Query OK, 1 rows affected (0.01 sec)mysql> insert into runoob_transaction_test value(6);
Query OK, 1 rows affected (0.00 sec)mysql> commit; # 提交事务
Query OK, 0 rows affected (0.01 sec)mysql> select * from runoob_transaction_test;
+------+
| id |
+------+
| 5 |
| 6 |
+------+
2 rows in set (0.01 sec)mysql> begin; # 开始事务
Query OK, 0 rows affected (0.00 sec)mysql> insert into runoob_transaction_test values(7);
Query OK, 1 rows affected (0.00 sec)mysql> rollback; # 回滚
Query OK, 0 rows affected (0.00 sec)mysql> select * from runoob_transaction_test; # 因为回滚所以数据没有插入
+------+
| id |
+------+
| 5 |
| 6 |
+------+
2 rows in set (0.01 sec)mysql>
2.3.10 mysql索引
MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能。MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
索引分单列索引和组合索引:
- 单列索引,即一个索引只包含单个列,一个表可以有多个单列索引。
- 组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
索引虽然能够提高查询性能,但也需要注意以下几点:
索引需要占用额外的存储空间。
对表进行插入、更新和删除操作时,索引需要维护,可能会影响性能。
过多或不合理的索引可能会导致性能下降,因此需要谨慎选择和规划索引。
普通索引
创建索引
使用 CREATE INDEX 语句可以创建普通索引。
普通索引是最常见的索引类型,用于加速对表中数据的查询。
# index_name: 指定要创建的索引的名称。索引名称在表中必须是唯一的。
CREATE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
#指定要索引的表列名。你可以指定一个或多个列作为索引的组合。这些列的数据类型通常是数值、文本或日期。我们可以在创建表的时候,你可以在 CREATE TABLE 语句中直接指定索引,以创建表和索引的组合。
删除索引的语法
我们可以使用 DROP INDEX 语句来删除索引。
DROP INDEX index_name ON table_name;唯一索引
在 MySQL 中,你可以使用 CREATE UNIQUE INDEX 语句来创建唯一索引。
唯一索引确保索引中的值是唯一的,不允许有重复值。
CREATE UNIQUE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);有四种方式来添加数据表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL;
mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;显示索引信息
你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。
可以通过添加 \G 来格式化输出信息。
SHOW INDEX 语句::
mysql> SHOW INDEX FROM table_name\G
........三、临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
- 创建临时表
CREATE TEMPORARY TABLE SalesSummary (product_name VARCHAR(50) NOT NULL, total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00, avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00 , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
- 删除临时表
DROP TABLE SalesSummary;
四、mysql序列
MySQL 序列是一组整数:1, 2, 3, …,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现。
- 使用自增组件
MySQL 中最简单使用序列的方法就是使用 MySQL AUTO_INCREMENT 来定义序列。
mysql> CREATE TABLE insect-> (-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,-> PRIMARY KEY (id),-> name VARCHAR(30) NOT NULL, # type of insect-> date DATE NOT NULL, # date collected-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO insect (id,name,date,origin) VALUES-> (NULL,'housefly','2001-09-10','kitchen'),-> (NULL,'millipede','2001-09-10','driveway'),-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM insect ORDER BY id;
+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)在MySQL的客户端中你可以使用 SQL中的LAST_INSERT_ID( ) 函数来获取最后的插入表中的自增列的值。
如果你删除了数据表中的多条记录,并希望对剩下数据的AUTO_INCREMENT列进行重新排列,那么你可以通过删除自增的列,然后重新添加来实现。 不过该操作要非常小心,如果在删除的同时又有新记录添加,有可能会出现数据混乱。
mysql> CREATE TABLE insect-> (-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,-> PRIMARY KEY (id),-> name VARCHAR(30) NOT NULL, -> date DATE NOT NULL,-> origin VARCHAR(30) NOT NULL
)engine=innodb auto_increment=100 charset=utf8;五、重复数据处理
MySQL 数据表中可能存在重复的记录,有些情况我们允许重复数据的存在,但有时候我们也需要删除这些重复的数据。
防止表中出现重复数据
你可以在 MySQL 数据表中设置指定的字段为 PRIMARY KEY(主键) 或者 UNIQUE(唯一) 索引来保证数据的唯一性。
让我们尝试一个实例:下表中无索引及主键,所以该表允许出现多条重复记录。
CREATE TABLE person_tbl
(first_name CHAR(20),last_name CHAR(20),sex CHAR(10)
);如果我们设置了唯一索引,那么在插入重复数据时,SQL 语句将无法执行成功,并抛出错。
INSERT IGNORE INTO 与 INSERT INTO 的区别就是 INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
以下实例使用了 INSERT IGNORE INTO,执行后不会出错,也不会向数据表中插入重复数据:
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)-> VALUES( 'Jay', 'Thomas');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)-> VALUES( 'Jay', 'Thomas');
Query OK, 0 rows affected (0.00 sec)而 REPLACE INTO 如果存在 primary 或 unique 相同的记录,则先删除掉。再插入新记录。
另一种设置数据的唯一性方法是添加一个 UNIQUE 索引,如下所示:
CREATE TABLE person_tbl
(first_name CHAR(20) NOT NULL,last_name CHAR(20) NOT NULL,sex CHAR(10),UNIQUE (last_name, first_name)
);以下我们将统计表中 first_name 和 last_name的重复记录数:
mysql> SELECT COUNT(*) as repetitions, last_name, first_name-> FROM person_tbl-> GROUP BY last_name, first_name-> HAVING repetitions > 1;过滤重复数据
如果你需要读取不重复的数据可以在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。
mysql> SELECT DISTINCT last_name, first_name-> FROM person_tbl;
mysql> SELECT last_name, first_name-> FROM person_tbl-> GROUP BY (last_name, first_name);mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex);
mysql> DROP TABLE person_tbl;
mysql> ALTER TABLE tmp RENAME TO person_tbl;六、sql注入
SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
我们永远不要信任用户的输入,我们必须认定用户输入的数据都是不安全的,我们都需要对用户输入的数据进行过滤处理。
相关文章:

mysql基础语法速成版
mysql基础语法速成版 一、前言二、基础语法2.1 数据库操作2.2 MySQL数据类型2.3 表操作2.3.1 表的创建、删除,及表结构的改变2.3.2表数据的增删改查2.3.4 like模糊查询2.3.5 UNION 操作符2.3.6 order by排序2.3.7 group by分组2.3.8 join连接2.3.9 null处理2.3.10 m…...

Docker镜像 配置ssh
安装 1.安装ssh 2.设置root密码 RUN echo root:123456 | chpasswd 3.设置sshd config RUN echo Port 22 >> /etc/ssh/sshd_config RUN echo PermitRootLogin yes >> /etc/ssh/sshd_config4.设置开机启动 RUN mkdir /var/run/sshd #没有这个目录,s…...
12.2 实现键盘模拟按键
本节将向读者介绍如何使用键盘鼠标操控模拟技术,键盘鼠标操控模拟技术是一种非常实用的技术,可以自动化执行一些重复性的任务,提高工作效率,在Windows系统下,通过使用各种键盘鼠标控制函数实现动态捕捉和模拟特定功能的…...
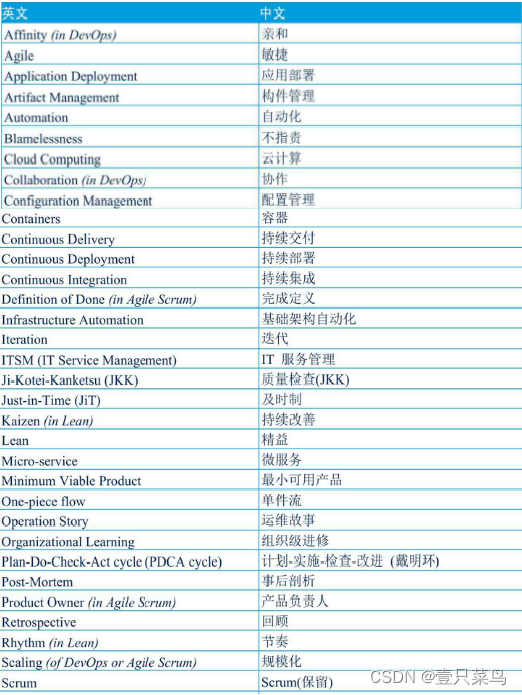
《DevOps 精要:业务视角》- 读书笔记(七)
DevOps 精要:业务视角(七) DevOps历程什么是企业体系的DevOps?DevOps的目标是什么? DevOps的知识体系规范敏捷持续交付IT服务管理以TPS理念为基础 DevOps团队角色流程主管(Process Master)服务主管…...
)
【随想】每日两题Day.12(实则一题)
题目:15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不…...
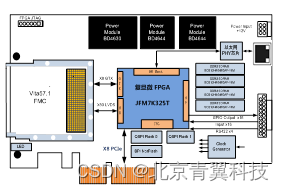
基于复旦微JFM7K325T FPGA的高性能PCIe总线数据预处理载板(100%国产化)
PCIE711是一款基于PCIE总线架构的高性能数据预处理FMC载板,板卡采用复旦微的JFM7K325T FPGA作为实时处理器,实现各个接口之间的互联。该板卡可以实现100%国产化。 板卡具有1个FMC(HPC)接口,1路PCIe x8主机接口&#x…...

什么是原型链(prototype chain)?如何实现继承?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

RabbitMQ 5种工作模式介绍和Springboot具体实现
RabbitMQ有5中工作模式:简单模式、工作队列模式、发布/订阅模式、路由模式和主题模式 简单模式(Simple Mode) 简单模式是最基本的工作模式,也是最简单的模式。在简单模式中,生产者将消息发送到一个队列中,…...

C++ - 可变模版参数 - emplace相关接口函数 - 移动构造函数 和 移动赋值运算符重载 的 默认成员函数
可变模版参数 我们先来了解一下,可变参数。可变参数就是在定义函数的时候,某一个参数位置使用 "..." 的方式来写的,在库当中有一个经典的函数系列就是用的 可变参数:printf()系列就是用的可变参…...
总结三:计算机网络面经
文章目录 1、简述静态路由和动态路由?2、说说有哪些路由协议,都是如何更新的?3、简述域名解析过程,本机如何干预域名解析?4、简述 DNS 查询服务器的基本流程是什么?DNS 劫持是什么?5、简述网关的…...

服务器数据恢复-VMWARE ESX SERVER虚拟机数据恢复案例
服务器数据恢复环境: 几台VMware ESX SERVER共享一台某品牌存储,共有几十组虚拟机。 服务器故障: 虚拟机在工作过程中突然被发现不可用,管理员将设备进行了重启,重启后虚拟机依然不可用,虚拟磁盘丢失&#…...

COCI 2021-2022 #1 - Set 题解
思路 我们将原题中的数的每一位减一,此时问题等价。 下面的异或都是在三进制下的异或。(相当于不进位的加法) 我们考虑原题中的条件,对于每一位,如果相同,则异或值为 0 0 0,如果为 1 1 1&a…...

分享40个极具商业价值的chatGPT提问prompt
原文:分享40个极具商业价值的chatGPT提问prompt | 秋天的童话博客 1、分析并改善定价策略 提示: "分析我当前的[插入产品或服务]定价策略。提出改进建议,并帮助我制定新的定价策略,以最大化利润和客户满意度。" Analyze and Imp…...

一文搞懂到底什么是元宇宙
一、背景 2021年,“元宇宙”是科技界的开端。 2021”元宇宙”这个词在Facebook更名后被点燃了,无疑是21世纪科技界最爆的起点。各式各样的定义、解读都出现了,有人说它是炒作,甚至是骗局,但也有人说它就是互联网的未…...

【重拾C语言】六、批量数据组织(四)线性表—栈和队列
目录 前言 六、批量数据组织——数组 6.1~3 数组基础知识 6.4 线性表——分类与检索 6.5~7 数组初值;字符串、字符数组、字符串数组;类型定义 typedef 6.8 线性表—栈和队列 6.8.1 栈(Stack) 全局变量 isEmpty() isFull…...

力扣刷题-哈希表-一个字符串是否能够由另一个字符串中的字符组成
383 赎金信 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每个字符只能在 ransomNote 中使用一次。ransomNote 和 magazin…...

Android使用AOP切面编程
在Android应用程序中,AOP可以被用于许多不同的场景,例如日志记录、权限控制、性能分析等。下面是一个简单的例子,说明如何在Android应用程序中使用AOP切面编程。 首先,我们需要在应用程序中引入AspectJ库。我们可以使用Gradle来完…...

Flutter学习笔记
此篇文章用来记录学习Flutter 和 Dart 相关知识 零.Dart基本数据类型 Dart 是一种静态类型的编程语言,它提供了一系列基本数据类型,用于存储和操作不同种类的数据。以下是 Dart 中的一些基本数据类型以及它们的详细介绍: 1. 整数类型&#…...

软件生命周期中的概念设计和详细设计的主要任务是什么
基础概念 在软件生命周期中,概念设计和详细设计是软件设计阶段中的两个重要环节。 概念设计阶段的主要任务是从业务需求出发,将系统的基本概念、主要功能和关键特性进行抽象和定义。概念设计旨在确定系统的整体架构和关键模块,包括以下主要…...
大数据学习(2)Hadoop-分布式资源计算hive(1)
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…...
问题)
Python实战:用图论算法解决外卖骑手路径规划(VRP)问题
Python实战:用图论算法解决外卖骑手路径规划(VRP)问题 外卖配送效率直接影响用户体验和平台运营成本。当3名骑手需要处理10个订单时,如何科学分配任务并规划最优路径?本文将构建一个包含时间窗口约束的VRP模型…...

06_Cursor之上下文管理与代码库理解
关键字:上下文管理, 代码库理解, 符号引用, Git集成, 图像上下文, Cursor 06_Cursor之上下文管理与代码库理解 Cursor知识体系 Cursor知识体系(续) | -- 上下文管理层 | -- 代码库级理解 | | -- 项目结构分析 | | -- 依赖关系追…...

FastBle终极指南:如何快速开发智能家电蓝牙遥控器
FastBle终极指南:如何快速开发智能家电蓝牙遥控器 【免费下载链接】FastBle Android Bluetooth Low Energy (BLE) Fast Development Framework. It uses simple ways to filter, scan, connect, read ,write, notify, readRssi, setMTU, and multiConnection. 项目…...

如何基于OpenAI进行Function Calling调用
基于LLM进行工具调用或技能执行,是近期最热门的话题之一。 目前已经有很多LLM工具调用框架,比如langchain、openclaw、owl等。 然而,工具调用过程一般被封装在框架内,用户一般只能接触到各种配置,窥探不到调用细节。…...

隐私优先方案:OpenClaw+Qwen3-14B镜像处理敏感数据的5层防护
隐私优先方案:OpenClawQwen3-14B镜像处理敏感数据的5层防护 1. 为什么需要本地化隐私方案 去年处理一批客户调研数据时,我犯过一个致命错误——把包含联系方式的原始表格上传到某公有云AI平台进行清洗。三天后,公司邮箱突然收到匿名勒索邮件…...

数字IC设计的未来:ChatGPT能否颠覆十大核心领域?
1. ChatGPT在数字IC设计中的定位 最近两年AI工具的发展确实让人眼前一亮,特别是ChatGPT这种大语言模型,在代码生成、技术问答方面展现出了惊人的能力。作为一名在数字IC设计领域摸爬滚打多年的工程师,我也第一时间测试了它在芯片设计各个环节…...

嵌入式系统接口技术详解与应用实践
1. 嵌入式系统接口技术概述在嵌入式系统开发中,接口技术是连接处理器与外部设备的关键桥梁。作为一名嵌入式开发工程师,我经常需要根据项目需求选择合适的接口方案。本文将基于多年实战经验,深入解析各类嵌入式接口的工作原理、应用场景和选型…...
)
LangChain-AI应用开发框架(四)
目录 一.LangChain软件包安装 二.LangChain能力详解 1.本章节环境说明 2.目标与内容 三.详细过程 1.步骤1: a.申请API key并配置环境变量 b.配置环境变量 步骤2:定义大模型 a.安装OpenAI包 b.定义大模型 步骤3:定义消息列表 步骤4ÿ…...

IP离线库每周更新一次够用吗?企业风控建议多久更新?
在风控体系中,IP数据的时效性直接决定了拦截效果。当攻击者使用秒拨IP或住宅代理发起攻击时,IP地址的轮换速度可以达到分钟级。如果依赖的IP库更新周期过长,就等于在防御上留下了数天的空窗期。 周更不够用。秒拨IP平均存活3-5分钟ÿ…...

mtkclient-gui技术指南:联发科设备深度控制与系统修复实战
mtkclient-gui技术指南:联发科设备深度控制与系统修复实战 【免费下载链接】mtkclient-gui GUI tool for unlocking bootloader and bypassing authorization on Mediatek devices (Not maintained anymore) 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclie…...