redis的持久化消息队列
Redis Stream
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
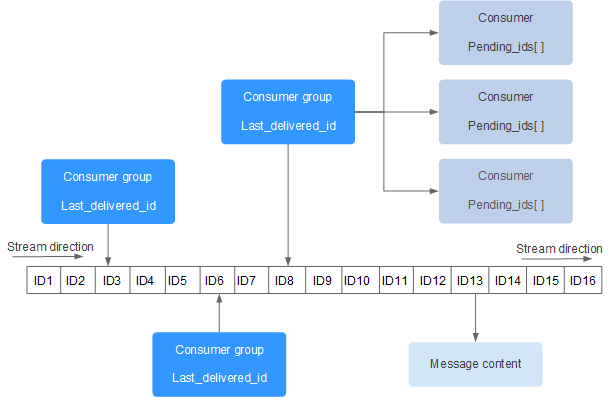
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
上图解析:
- Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
XADD
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
XADD key ID field value [field value ...]
- key :队列名称,如果不存在就创建
- ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。
- field value : 记录。
实例
redis> XADD mystream * name Sara surname OConnor
"1601372323627-0"
redis> XADD mystream * field1 value1 field2 value2 field3 value3
"1601372323627-1"
redis> XLEN mystream
(integer) 2
redis> XRANGE mystream - +
1) 1) "1601372323627-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
2) 1) "1601372323627-1"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis>
XTRIM
使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count
- key :队列名称
- MAXLEN :长度
- count :数量
实例
127.0.0.1:6379> XADD mystream * field1 A field2 B field3 C field4 D
"1601372434568-0"
127.0.0.1:6379> XTRIM mystream MAXLEN 2
(integer) 0
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1601372434568-0"
2) 1) "field1"
2) "A"
3) "field2"
4) "B"
5) "field3"
6) "C"
7) "field4"
8) "D"
127.0.0.1:6379>
redis>
XDEL
使用 XDEL 删除消息,语法格式:
XDEL key ID [ID ...]
- key:队列名称
- ID :消息 ID
实例
> XADD mystream * a 1
1538561698944-0
> XADD mystream * b 2
1538561700640-0
> XADD mystream * c 3
1538561701744-0
> XDEL mystream 1538561700640-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) 1538561698944-0
2) 1) "a"
2) "1"
2) 1) 1538561701744-0
2) 1) "c"
2) "3"
XLEN
使用 XLEN 获取流包含的元素数量,即消息长度,语法格式:
XLEN key
- key:队列名称
实例
redis> XADD mystream * item 1
"1601372563177-0"
redis> XADD mystream * item 2
"1601372563178-0"
redis> XADD mystream * item 3
"1601372563178-1"
redis> XLEN mystream
(integer) 3
redis>
XRANGE
使用 XRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XRANGE key start end [COUNT count]
- key :队列名
- start :开始值, - 表示最小值
- end :结束值, + 表示最大值
- count :数量
实例
redis> XADD writers * name Virginia surname Woolf
"1601372577811-0"
redis> XADD writers * name Jane surname Austen
"1601372577811-1"
redis> XADD writers * name Toni surname Morrison
"1601372577811-2"
redis> XADD writers * name Agatha surname Christie
"1601372577812-0"
redis> XADD writers * name Ngozi surname Adichie
"1601372577812-1"
redis> XLEN writers
(integer) 5
redis> XRANGE writers - + COUNT 2
1) 1) "1601372577811-0"
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) "1601372577811-1"
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
redis>
XREVRANGE
使用 XREVRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XREVRANGE key end start [COUNT count]
- key :队列名
- end :结束值, + 表示最大值
- start :开始值, - 表示最小值
- count :数量
实例
redis> XADD writers * name Virginia surname Woolf
"1601372731458-0"
redis> XADD writers * name Jane surname Austen
"1601372731459-0"
redis> XADD writers * name Toni surname Morrison
"1601372731459-1"
redis> XADD writers * name Agatha surname Christie
"1601372731459-2"
redis> XADD writers * name Ngozi surname Adichie
"1601372731459-3"
redis> XLEN writers
(integer) 5
redis> XREVRANGE writers + - COUNT 1
1) 1) "1601372731459-3"
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
redis>
XREAD
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count :数量
- milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
- key :队列名
- id :消息 ID
实例
# 从 Stream 头部读取两条消息
> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
2) 1) 1526999352406-0
2) 1) "duration"
2) "812"
3) "event-id"
4) "9"
5) "user-id"
6) "388234"
2) 1) "writers"
2) 1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
XGROUP CREATE
使用 XGROUP CREATE 创建消费者组,语法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key :队列名称,如果不存在就创建
- groupname :组名。
- $ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
从头开始消费:
XGROUP CREATE mystream consumer-group-name 0-0
从尾部开始消费:
XGROUP CREATE mystream consumer-group-name $
XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group :消费组名
- consumer :消费者名。
- count : 读取数量。
- milliseconds : 阻塞毫秒数。
- key : 队列名。
- ID : 消息 ID。
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >
相关文章:
redis的持久化消息队列
Redis Stream Redis Stream 是 Redis 5.0 版本新增加的数据结构。 Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法…...

分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测
分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测࿰…...

用 Pytorch 自己构建一个Transformer
一、说明 用pytorch自己构建一个transformer并不是难事,本篇使用pytorch随机生成五千个32位数的词向量做为源语言词表,再生成五千个32位数的词向量做为目标语言词表,让它们模拟翻译过程,transformer全部用pytorch实现,具备一定实战意义。 二、论文和概要 …...

Docker安装ActiveMQ
ActiveMQ简介 官网地址:https://activemq.apache.org/ 简介: ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,…...
【二】spring boot-设计思想
spring boot-设计思想 简介:现在越来越多的人开始分析spring boot源码,拿到项目之后就有点无从下手了,这里介绍一下springboot源码的项目结构 一、项目结构 从上图可以看到,源码分为两个模块: spring-boot-project&a…...

系统架构设计:7 论企业集成架构设计及应用
目录 一 企业集成 1 企业集成分类:按照集成点分 (1)界面集成(表示集成)...

【pytorch】多GPU同时训练模型
文章目录 1. 基本原理单机多卡训练教程——DP模式 2. Pytorch进行单机多卡训练步骤1. 指定GPU2. 更改模型训练方式3. 更改权重保存方式 摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。 1. 基本原理 单机多卡训练教程—…...
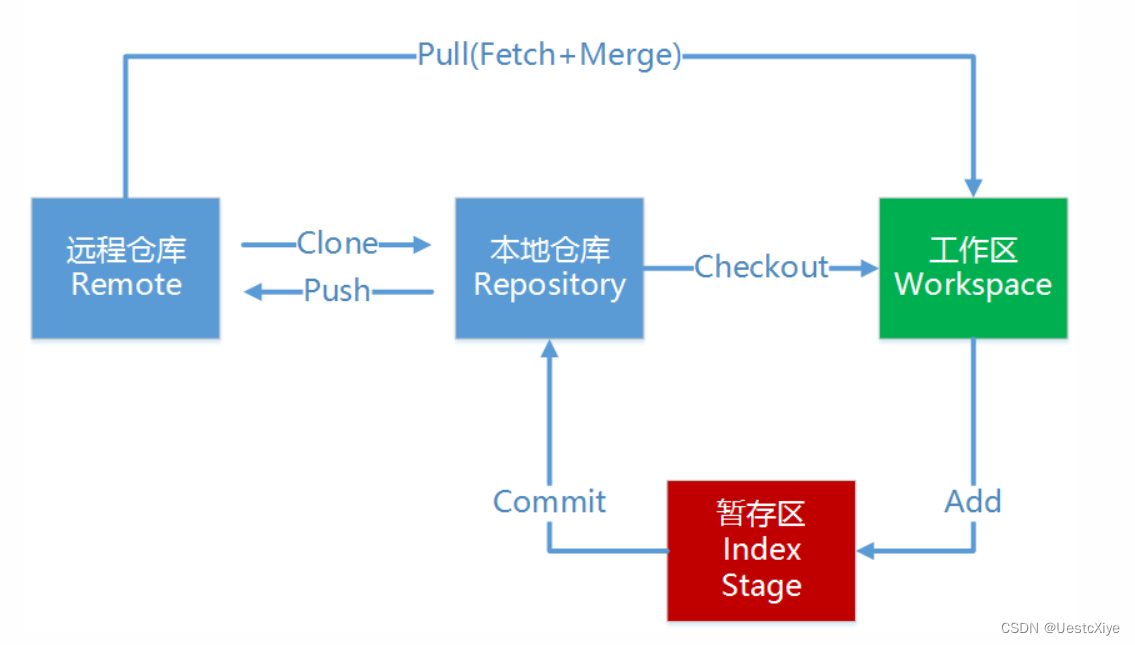
Git 学习笔记 | Git 基本理论
Git 学习笔记 | Git 基本理论 Git 学习笔记 | Git 基本理论Git 工作区域Git 工作流程 Git 学习笔记 | Git 基本理论 在开始使用 Git 创建项目前,我们先学习一下 Git 的基础理论。 Git 工作区域 Git本地有三个工作区域:工作目录(Working Di…...

滚动表格封装
滚动表格封装 我们先设定接收的参数 需要表头内容columns,表格数据data,需要currentSlides来控制当前页展示几行 const props defineProps({// 表头内容columns: {type: Array,default: () > [],required: true,},// 表格数据data: {type: Array,d…...

【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题
文章目录 【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题⛅前言 平均售价🔒题目🔑题解 项目员工I🔒题目🔑题解 各赛事的用户注册率🔒题目🔑题解 查询结果的质量和占比🔒题目&am…...

系统压力测试:保障系统性能与稳定的重要措施
压力测试简介 在当今数字化时代,各种系统和应用程序扮演着重要角色,从企业的核心业务系统到在线服务平台,都需要具备高性能和稳定性,以满足用户的需求。然而,随着用户数量和业务负载的增加,系统可能会面临…...

常用数据结构和算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、时间复杂度二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 这里面有10个数据结构࿱…...

C++中使用引用避免内存复制
C中使用引用避免内存复制 引用让您能够访问相应变量所在的内存单元,这使得编写函数时引用很有用。典型的函数声明类似于下面这样: ReturnType DoSomething(Type parameter);调用函数 DoSomething() 的代码类似于下面这样: ReturnType Resu…...
计算机网络(第8版)-第4章 网络层
4.1 网络层的几个重要概念 4.1.1 网络层提供的两种服务 如果主机(即端系统)进程之间需要进行可靠的通信,那么就由主机中的运输层负责(包括差错处理、流量控制等)。 4.1.2 网络层的两个层面 4.2 网际协议 IP 图4-4 网…...
chromadb 0.4.0 后的改动
本文基于一篇上次写的博客:[开源项目推荐]privateGPT使用体验和修改 文章目录 一.上次改好的ingest.py用不了了,折腾了一会儿二.发现privateGPT官方更新了总结下变化效果 三.others 一.上次改好的ingest.py用不了了,折腾了一会儿 pydantic和c…...
Windows环境下下载安装Elasticsearch和Kibana
Windows环境下下载安装Elasticsearch和Kibana 首先说明这里选择的版本都是7.17 ,为什么不选择新版本,新版本有很多坑,要去踩,就用7就够了。 Elasticsearch下载 Elasticsearch是一个开源的分布式搜索和分析引擎,最初由…...
机器学习:随机森林
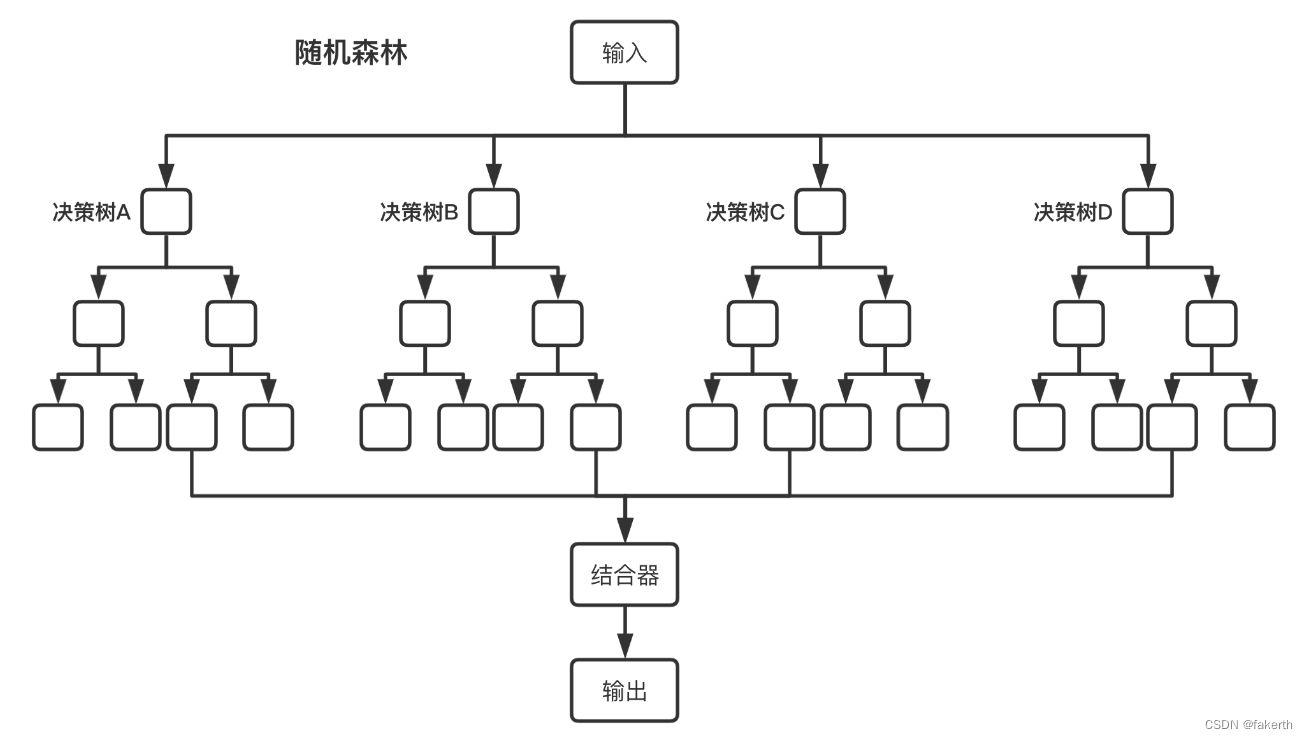
集成学习 集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本学习算法的预测结果进行组合,以获得更好的预测性能。集成学习的基本思想是通过结合多个弱分类器或回归器的预测结果,来构建一个更强大的集成模…...
ctfshow-web11(session绕过)
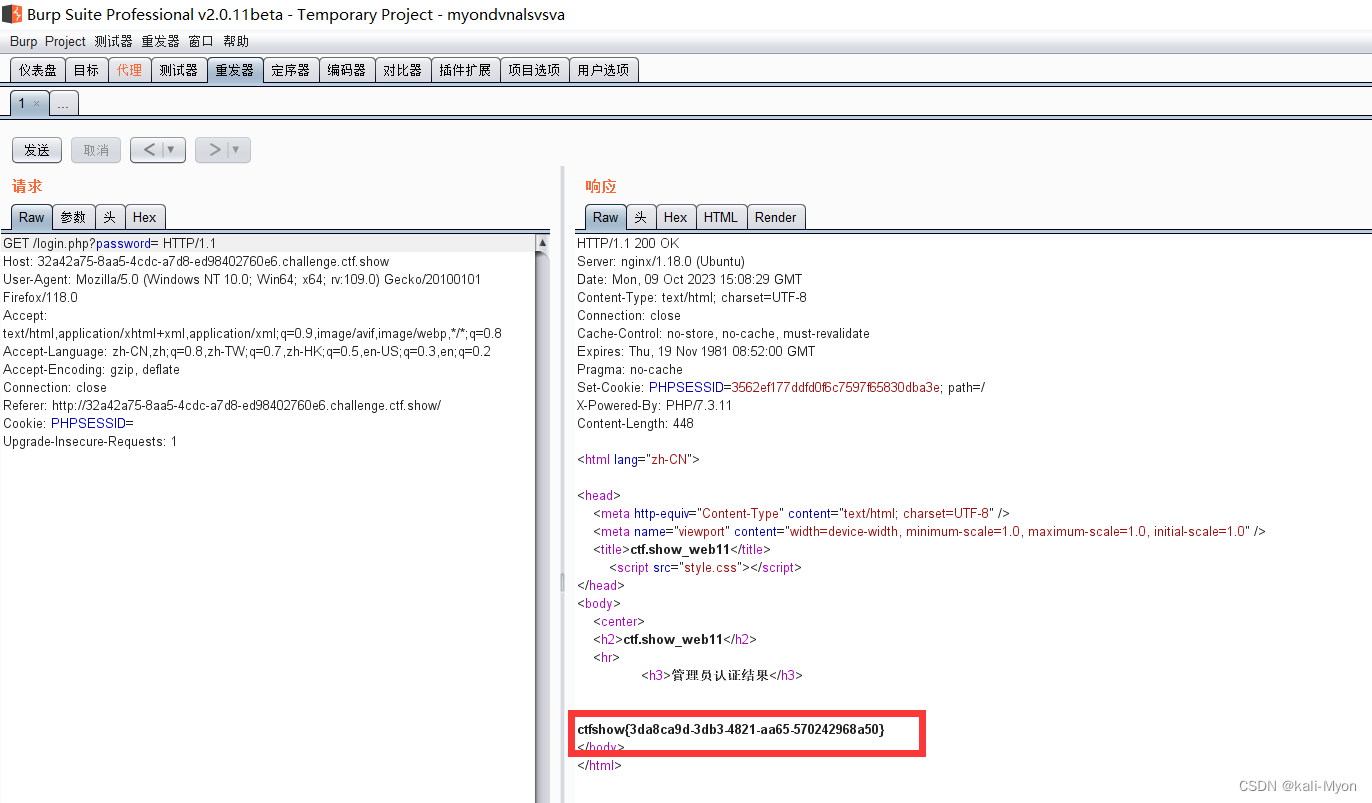
php代码审计: function replaceSpecialChar($strParam){$regex "/(select|from|where|join|sleep|and|\s|union|,)/i";return preg_replace($regex,"",$strParam);} 首先定义了一个函数,主要是使用preg_replace函数对我们提交的内…...

状态模式:对象状态的变化
欢迎来到设计模式系列的第十七篇文章。在本文中,我们将深入探讨状态模式,这是一种行为型设计模式,用于管理对象的状态以及状态之间的变化。 什么是状态模式? 状态模式是一种允许对象在内部状态发生变化时改变其行为的设计模式。…...

解耦常用方法
1、类别 DIP依赖倒置、IoC控制反转、DI依赖注入(Dependency Injection) c11 实现依赖注入 控制反转、依赖注入、依赖倒置傻傻分不清楚? 我曾想深入了解的:依赖倒置、控制反转、依赖注入 2、方法 解耦基本方法 step1:…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

VHD2VL:破解硬件描述语言转换难题的开源解决方案
VHD2VL:破解硬件描述语言转换难题的开源解决方案 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,技术团队常常面临VHDL与Verilog两种硬件描述语言之间的转换挑战。当项目需要跨语言协作、工…...

Nix构建确定性AI编程环境:解决Cursor编辑器依赖冲突难题
1. 项目概述:当代码编辑器遇上Nix的确定性魔法 最近在折腾开发环境时,我遇到了一个老生常谈但又无比头疼的问题:团队里新来的同事怎么也跑不起来我本地运行得好好的一个代码辅助工具链。依赖版本冲突、系统库路径不对、甚至是因为他用的macO…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

合宙Air153C看门狗芯片:嵌入式系统可靠性的硬件守护方案
1. 项目概述:一颗“小而美”的国产看门狗芯片最近在做一个低功耗的户外监测设备项目,主控用的就是合宙的Air系列MCU。在调试过程中,最让我头疼的就是系统偶尔的“死机”问题。设备部署在野外,不可能每次都跑过去手动重启。正当我琢…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...