【pytorch】多GPU同时训练模型
文章目录
- 1. 基本原理
- 单机多卡训练教程——DP模式
- 2. Pytorch进行单机多卡训练步骤
- 1. 指定GPU
- 2. 更改模型训练方式
- 3. 更改权重保存方式
摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。
1. 基本原理
单机多卡训练教程——DP模式
(1)将模型复制到各个GPU中,并将一个batch的数据划分成mini_batch(平均分配) 并分发给每个GPU;
注意:这里的batch_size要大于device数。
(2)各个GPU独自完成mini_batch的前向传播,并把获得的output传递给GPU_0(主GPU) ;
(3) GPU_0整合各个GPU传递过来的output,并计算loss。此时GPU_0可以对这些loss进行一些聚合操作;
(4) GPU_0归并loss之后,并进行后向传播以及梯度下降从而完成模型参数的更新(此时只有GPU_0上的模型参数得到了更新),GPU_0将更新好的模型参数又传递给其余GPU;
以上就是DP模式下多卡GPU进行训练的方式。其实可以看到GPU_0不仅承担了前向传播的任务,还承担了收集loss,并进行梯度下降。因此在使用DP模式进行单机多卡GPU训练的时候会有一张卡的显存利用会比其他卡更多,那就是你设置的GPU_0。
2. Pytorch进行单机多卡训练步骤
只需要在你的代码中改三个地方就可实现
1. 指定GPU

如上所示,在导入各种库下面使用os.environ["CUDA_VISIBLE_DEVICES"]来指定可识别的GPU,该语句在程序开始前使用。
代码如下:
import torch.nn as nn
import os
os.environ["CUDA_VISIBLE_DEVICES"]= 2,3,1'#指定该程序可以识别的物理GPU编号,这里的你主机上的2号GPU就是训练程序中的主GPUO,这里最好—定要自己指定你自己可以用的gpu号。
2. 更改模型训练方式

平常的模型训练方式只需要model.cuda()语句即可,在单机多卡训练中,只需要在该语句下面添加一行nn.DataParallel语句即可。
代码如下
model.cuda()
model = nn.DataParallel(model,devise =[0,1,2])#在执行该语句之前最好加上model.cuda(),保证你的模型存在GPU上即可
3. 更改权重保存方式
对于数据,我们只需要按照平常的方式使用.cuda()放置在GPU上即可,内部batch的拆分已经被封装在了DataPanallel模块中。要注意的是,由于我们的model被nn.DataPanallel()包裹住了,所以如果想要储存模型的参数,需要使用:model.module.state_dict()的方式才能取出(不能直接是model.state_dict())
代码如下:
'''
使用单机多卡训练的模型权重保存方式
'''
torch.save(model.module.state_dict(),f'best.pth')
作为参考,将平常的权重保存方式也写上:
'''
平常的权重保存方式
'''
torch.save(model.state_dict(),f'best.pth')
相关文章:
【pytorch】多GPU同时训练模型
文章目录 1. 基本原理单机多卡训练教程——DP模式 2. Pytorch进行单机多卡训练步骤1. 指定GPU2. 更改模型训练方式3. 更改权重保存方式 摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。 1. 基本原理 单机多卡训练教程—…...
Git 学习笔记 | Git 基本理论
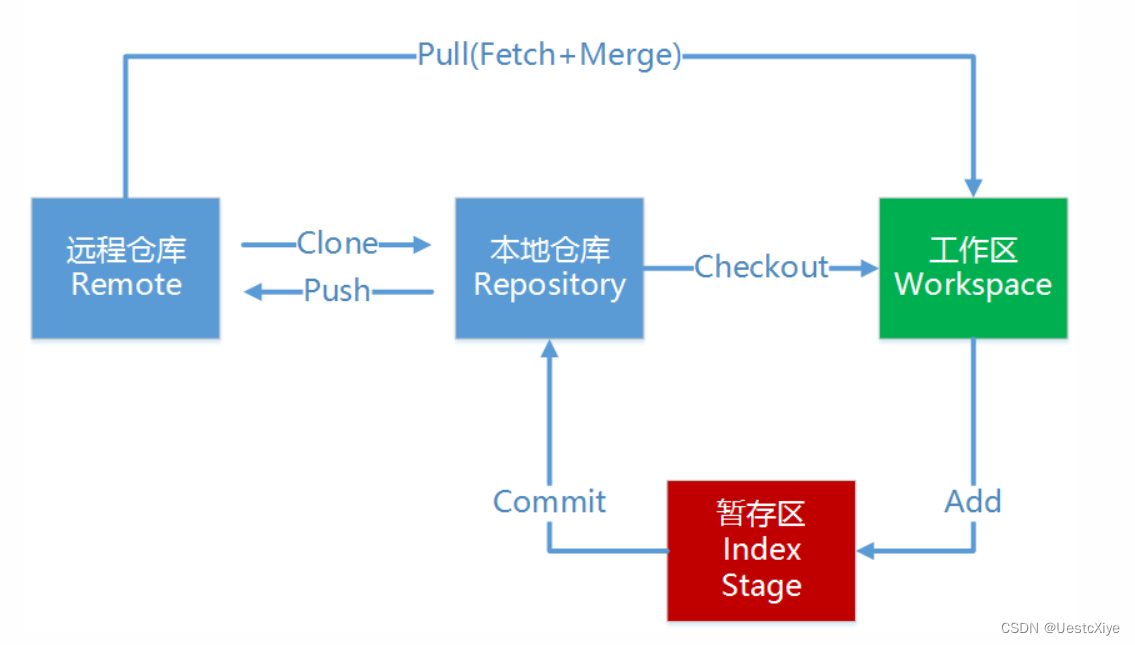
Git 学习笔记 | Git 基本理论 Git 学习笔记 | Git 基本理论Git 工作区域Git 工作流程 Git 学习笔记 | Git 基本理论 在开始使用 Git 创建项目前,我们先学习一下 Git 的基础理论。 Git 工作区域 Git本地有三个工作区域:工作目录(Working Di…...

滚动表格封装
滚动表格封装 我们先设定接收的参数 需要表头内容columns,表格数据data,需要currentSlides来控制当前页展示几行 const props defineProps({// 表头内容columns: {type: Array,default: () > [],required: true,},// 表格数据data: {type: Array,d…...

【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题
文章目录 【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题⛅前言 平均售价🔒题目🔑题解 项目员工I🔒题目🔑题解 各赛事的用户注册率🔒题目🔑题解 查询结果的质量和占比🔒题目&am…...

系统压力测试:保障系统性能与稳定的重要措施
压力测试简介 在当今数字化时代,各种系统和应用程序扮演着重要角色,从企业的核心业务系统到在线服务平台,都需要具备高性能和稳定性,以满足用户的需求。然而,随着用户数量和业务负载的增加,系统可能会面临…...

常用数据结构和算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、时间复杂度二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 这里面有10个数据结构࿱…...

C++中使用引用避免内存复制
C中使用引用避免内存复制 引用让您能够访问相应变量所在的内存单元,这使得编写函数时引用很有用。典型的函数声明类似于下面这样: ReturnType DoSomething(Type parameter);调用函数 DoSomething() 的代码类似于下面这样: ReturnType Resu…...
计算机网络(第8版)-第4章 网络层
4.1 网络层的几个重要概念 4.1.1 网络层提供的两种服务 如果主机(即端系统)进程之间需要进行可靠的通信,那么就由主机中的运输层负责(包括差错处理、流量控制等)。 4.1.2 网络层的两个层面 4.2 网际协议 IP 图4-4 网…...
chromadb 0.4.0 后的改动
本文基于一篇上次写的博客:[开源项目推荐]privateGPT使用体验和修改 文章目录 一.上次改好的ingest.py用不了了,折腾了一会儿二.发现privateGPT官方更新了总结下变化效果 三.others 一.上次改好的ingest.py用不了了,折腾了一会儿 pydantic和c…...
Windows环境下下载安装Elasticsearch和Kibana
Windows环境下下载安装Elasticsearch和Kibana 首先说明这里选择的版本都是7.17 ,为什么不选择新版本,新版本有很多坑,要去踩,就用7就够了。 Elasticsearch下载 Elasticsearch是一个开源的分布式搜索和分析引擎,最初由…...
机器学习:随机森林
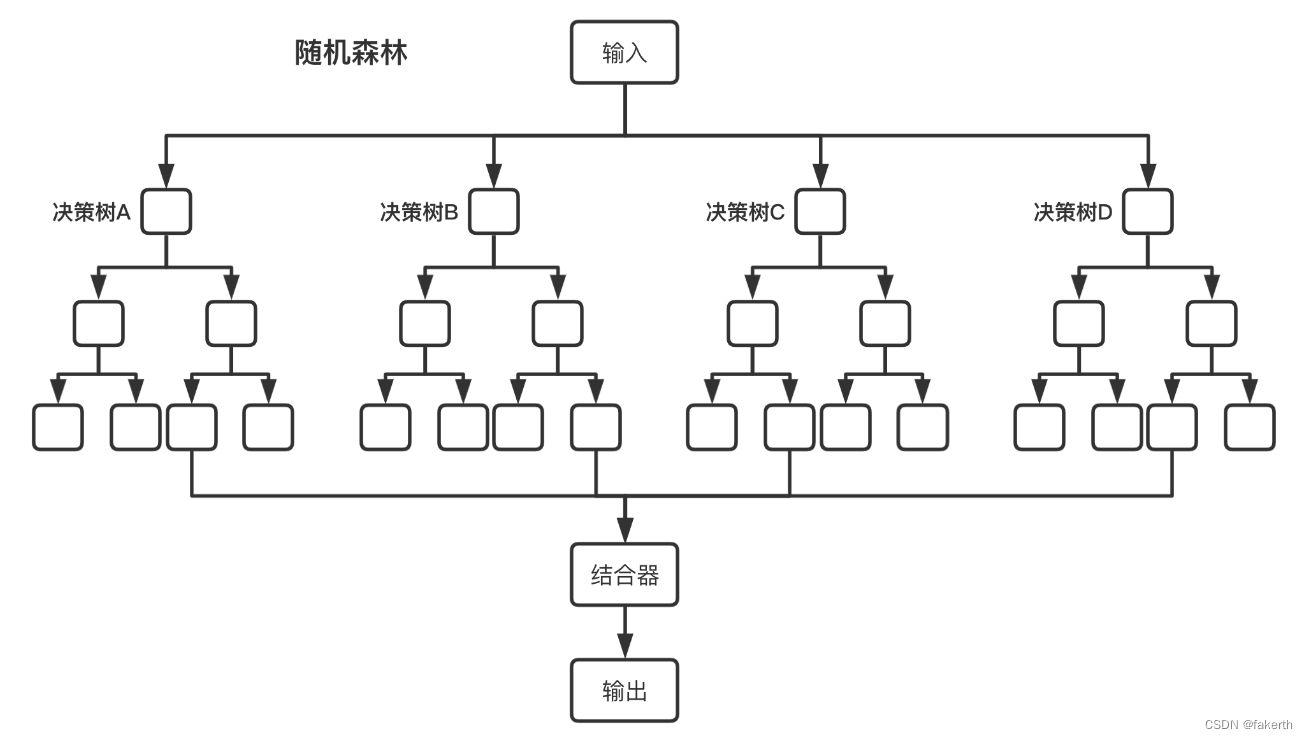
集成学习 集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本学习算法的预测结果进行组合,以获得更好的预测性能。集成学习的基本思想是通过结合多个弱分类器或回归器的预测结果,来构建一个更强大的集成模…...
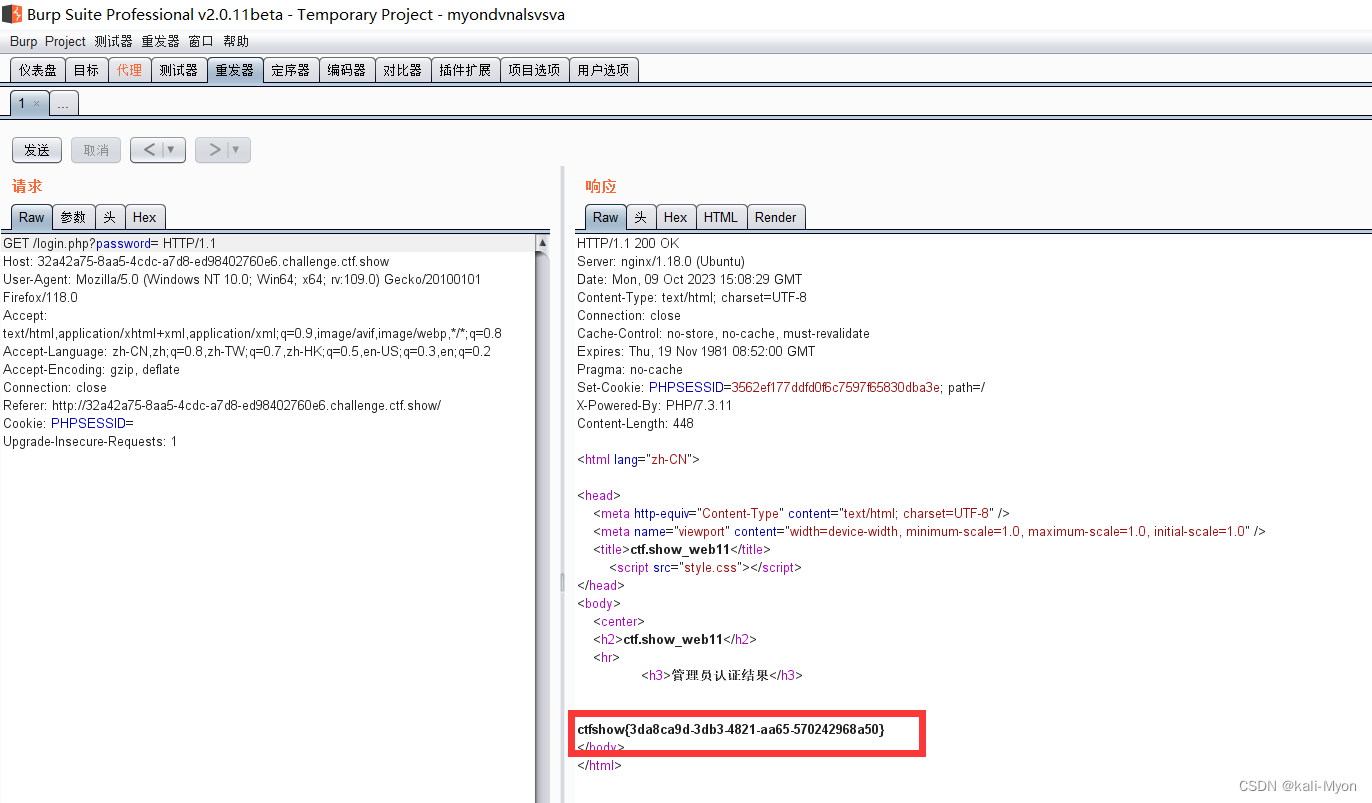
ctfshow-web11(session绕过)
php代码审计: function replaceSpecialChar($strParam){$regex "/(select|from|where|join|sleep|and|\s|union|,)/i";return preg_replace($regex,"",$strParam);} 首先定义了一个函数,主要是使用preg_replace函数对我们提交的内…...

状态模式:对象状态的变化
欢迎来到设计模式系列的第十七篇文章。在本文中,我们将深入探讨状态模式,这是一种行为型设计模式,用于管理对象的状态以及状态之间的变化。 什么是状态模式? 状态模式是一种允许对象在内部状态发生变化时改变其行为的设计模式。…...

解耦常用方法
1、类别 DIP依赖倒置、IoC控制反转、DI依赖注入(Dependency Injection) c11 实现依赖注入 控制反转、依赖注入、依赖倒置傻傻分不清楚? 我曾想深入了解的:依赖倒置、控制反转、依赖注入 2、方法 解耦基本方法 step1:…...
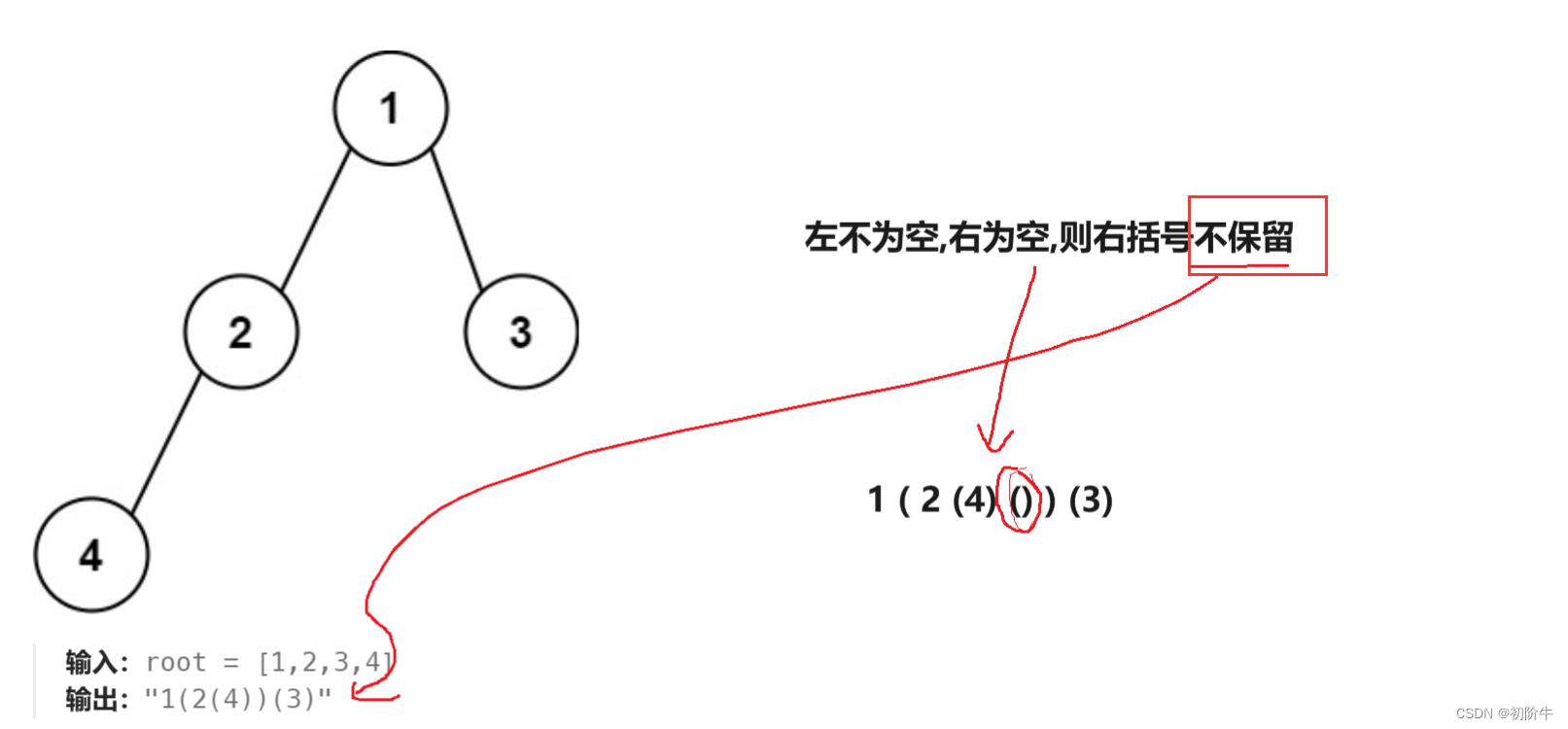
根据二叉树创建字符串--力扣
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻强烈推荐优质专栏: 🍔🍟🌯C的世界(持续更新中) 🐻推荐专栏1: 🍔🍟🌯C语言初阶 🐻推荐专栏2: 🍔…...
)
代码事件派发机制(观察者模式)
事件派发机制主要用来解决: 代码解耦和维护,一般在代码中会要管理一些闭包函数 然后在指定的业务中触发运行闭包函数逻辑用了事件派发机制 就可以先把要处理的事件 挂在在一个事件管理类中 上面挂满要处理的闭包函数然后通过dispatch 出发要执行的任务 也就是闭包1. PHP中实…...

微服务技术栈-Nacos配置管理和Feign远程调用
文章目录 前言一、统一配置管理1.添加配置文件2.微服务拉取配置3.配置共享 三、Feign远程调用总结 前言 在上篇文章中介绍了微服务技术栈中Nacos这个组件的概念,Nacos除了可以做注册中心,同样可以做配置管理来使用。同时我们将学习一种新的远程调用方式…...
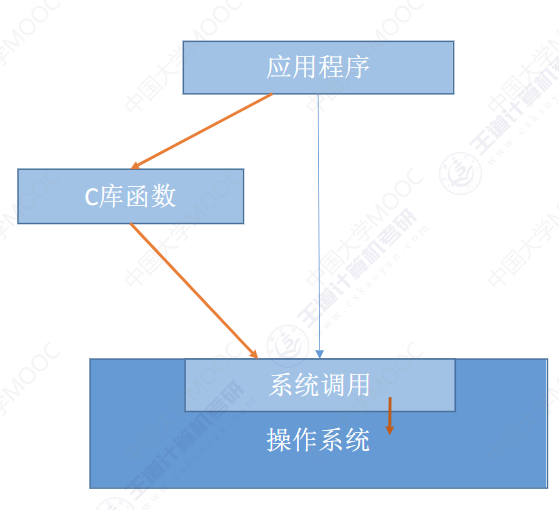
操作系统 OS
本文章是学习《操作系统》慕课版 和 王道《2024年 操作系统 考研复习指导》后所做的笔记,其中一些图片来源于学习资料。 目录 概念(定义) 目标 方便性 有效性 可扩充性 开放性 作用 OS 作为用户与计算机硬件系统之间的接口 — 人机交…...

基于ffmpeg给视频添加时间字幕
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,我们可以基于ffmpeg对视频进行各种操作。本文主要介绍基于ffmpeg给视频添加字幕,字幕的内容为视频所播放的时间(故需要安装ffmpeg,具…...

爬虫基础知识点快速入门
以下是一个包含注释的Python示例,演示了基本的网页爬取过程,以及一些常见的爬虫知识点: # 导入必要的库 import requests # 用于发送HTTP请求 from bs4 import BeautifulSoup # 用于解析HTML import csv # 用于数据存储# 1. 指定目标网站…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...
NeoPixel光剑制作全攻略:从WS2812B原理到实战装配
1. 项目概述:从零件到光剑的旅程如果你和我一样,是个对《星球大战》里的光剑毫无抵抗力,同时又喜欢动手折腾电子玩意儿的人,那么用NeoPixel灯带自制一把会发光、能变色的光剑,绝对是件充满成就感的事。这不仅仅是把灯塞…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

DeepLake:AI原生数据湖统一管理多模态数据与向量嵌入
1. 项目概述:当数据湖遇上AI向量化如果你正在构建一个AI应用,无论是RAG检索增强生成系统、多模态模型训练,还是复杂的语义搜索,数据管理环节的复杂性往往会让你头疼不已。传统的文件系统、数据库,甚至是对象存储&#…...

如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了!
如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了! 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ado…...

多机驱动振动系统同步控制理论【附模型】
✨ 长期致力于振动机械、自同步、控制同步、GA-BP PID、定速比研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)GA-BP神经网络PID控制器设计及其参数自…...

CircuitPython HID设备模拟:从键盘鼠标到数据记录实战指南
1. 项目概述:从微控制器到智能交互设备在嵌入式开发的世界里,让一块小小的开发板“假装”成键盘或鼠标,直接控制你的电脑,这听起来像是极客的魔法,但其实是基于一个非常成熟且标准化的协议:HID。HID&#x…...

VTube Studio API完全指南:5个核心场景教你打造个性化虚拟主播互动
VTube Studio API完全指南:5个核心场景教你打造个性化虚拟主播互动 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 想要为你的虚拟主播形象添加更多互动功能,却不知道…...