【Redis】基础数据结构-字典
Redis 字典
基本语法
字典是Redis中的一种数据结构,底层使用哈希表实现,一个哈希表中可以存储多个键值对,它的语法如下,其中KEY为键,field和value为值(也是一个键值对):
HSET key field value
根据Key和field获取value:
HGET key field
哈希表
数据结构
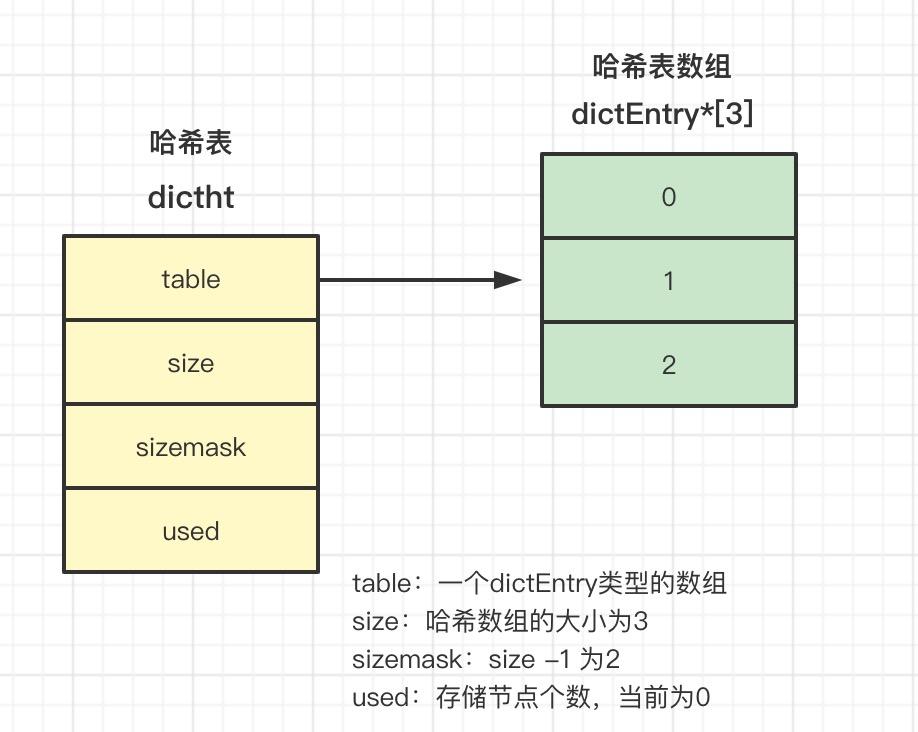
dictht
dictht是哈希表的数据结构定义:
- table:哈希表数组,数组中的元素是dictEntry类型的
- size:哈希表数组的大小
- sizemask:哈希表大小掩码,一般等于size-1
- used:已有节点的数量(存储键值对的数量)
typedef struct dictht {dictEntry **table;unsigned long size;unsigned long sizemask;unsigned long used;
} dictht;
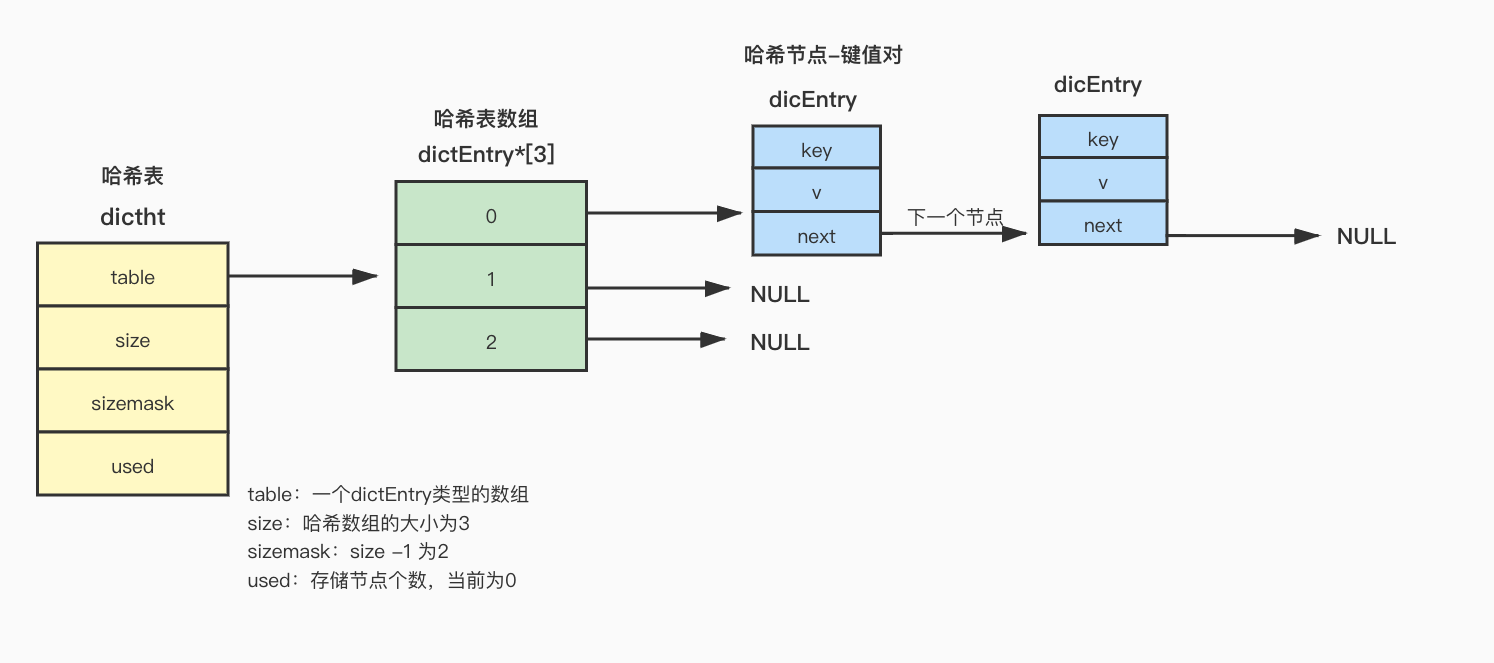
dictEntry
dictEntry是哈希表节点的结构定义:
- key:键值对中的键
- v:键值对中的值
- next:由于会出现哈希冲突,所以next是指向下一个节点的指针
typedef struct dictEntry {void *key; // 键union {void *val;uint64_t u64;int64_t s64;double d;} v; // 值struct dictEntry *next; // 指向下一个节点的指针
} dictEntry;
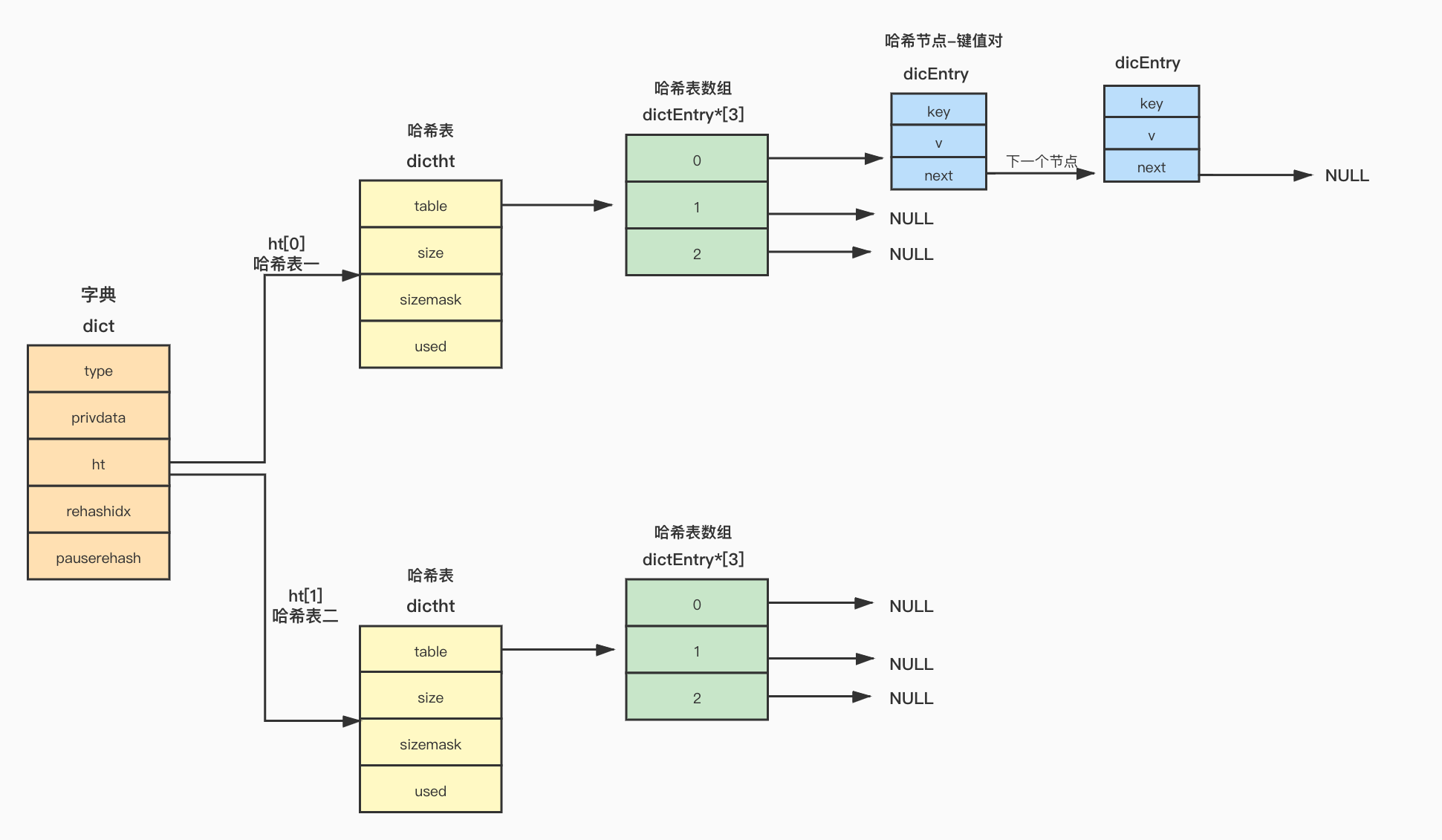
dict
dict是Redis中字典的结构定义:
- type:指向dictType的指针
- privdata
- ht[2]:一个dictht类型的数组,数组大小为2,保存了两个哈希表,rehash时使用
- rehashidx:记录了当前rehash的进度
- pauserehash:rehash暂停标记,大于0表示没有进行rehash
typedef struct dict {dictType *type; // void *privdata; // 私有数据dictht ht[2]; // 保存了两个哈希表long rehashidx; // rehash的进度标记int16_t pauserehash;
} dict;typedef struct dictType {uint64_t (*hashFunction)(const void *key);void *(*keyDup)(void *privdata, const void *key);void *(*valDup)(void *privdata, const void *obj);int (*keyCompare)(void *privdata, const void *key1, const void *key2);void (*keyDestructor)(void *privdata, void *key);void (*valDestructor)(void *privdata, void *obj);int (*expandAllowed)(size_t moreMem, double usedRatio);
} dictType;
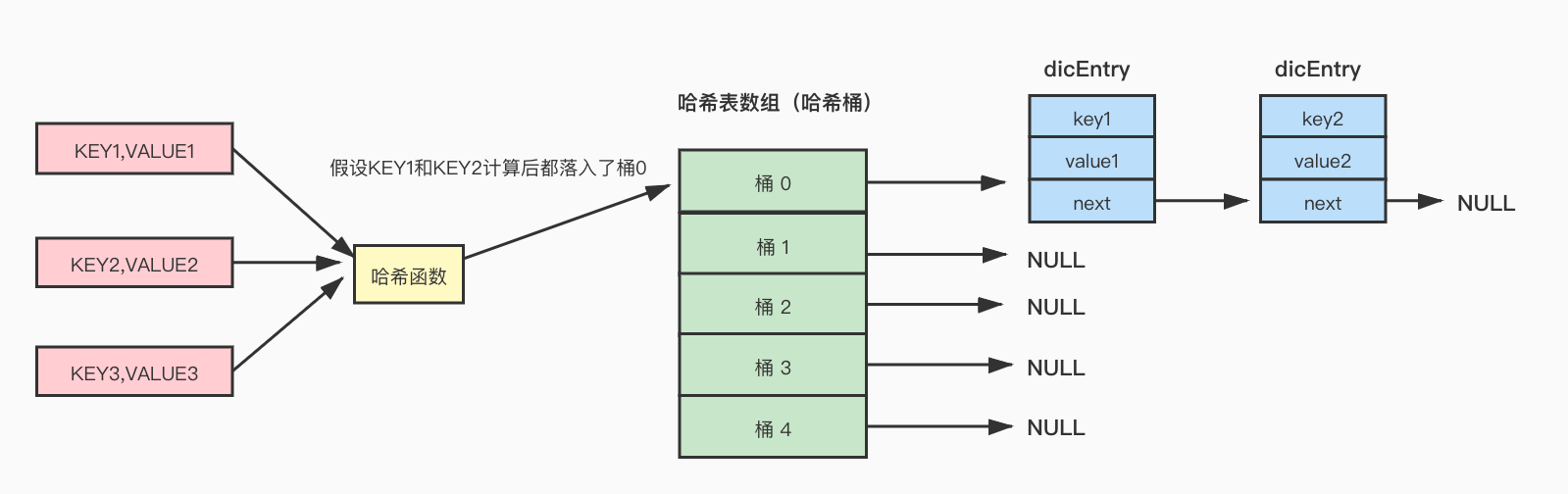
哈希冲突
一个键值对放入哈希表的时候,会根据key的值,计算一个hash值,然后根据hash值与哈希表大小掩码做与运算得到一个索引值,索引值决定元素放入哪个哈希桶中(落入哈希表数组哪个索引位置处)。
// 计算hash值hash = dictHashKey(d,key)// 计算索引idx = hash & d->ht[table].sizemask;
在进行哈希计算的时候,不可避免会出现哈希冲突,出现哈希冲突的时候,Redis采用链式哈希解决冲突,也就是落入同一个桶中的元素,使用链表将这些冲突的元素链起来(dictEntry中的next指针)。
rehash
由于Redis采用链式哈希解决冲突,那么在冲突频繁的场景下,链表会变得越来越长,这种情况下查找效率是比较低下的,需要遍历链表对比KEY的值来获取数据,为了处理效率低下的问题,需要对哈希表进行扩容,扩容的过程称为rehash。
在dict结构替中ht保存了两个哈希表,ht[0]用于数据正常的增删改查,ht[1]用于rehash:
(1)正常情况下,所有的增删改查操作都在ht[0]中进行;
(2)需要进行rehash时,会使用ht[1]建立新的哈希表,并将ht[0]中的数据迁移到ht[1]中;
(3)迁移完成后,ht[0]的空间被释放,然后将ht[1]地址赋给ht[0],ht[1]的大小被设为0,ht[0]重新接收正常的请求,回到了第(1)步的状态;
rehash的触发条件
/* 判断是否需要扩容 */
static int _dictExpandIfNeeded(dict *d)
{/* 如果已经处于rehash状态中直接返回 */if (dictIsRehashing(d)) return DICT_OK;/* 如果ht[0]的大小为0,意味着哈希表为空,此时做初始化操作 */if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);/*如果已经存储的节点数量大于或等于哈希表数组的大小,并且跨域扩容或者(节点数量/哈希表数组大小)大于一个比例,同时根据字典的类型判断是否允许分配内存*/if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio) &&dictTypeExpandAllowed(d)){ // 进行扩容return dictExpand(d, d->ht[0].used + 1);}return DICT_OK;
}/* 由于扩容需要分配内存,这里检查字典类型分配是否被允许*/
static int dictTypeExpandAllowed(dict *d) {if (d->type->expandAllowed == NULL) return 1;return d->type->expandAllowed(_dictNextPower(d->ht[0].used + 1) * sizeof(dictEntry*),(double)d->ht[0].used / d->ht[0].size);
}
d->ht[0].used/d->ht[0].size : 节点数量与哈希表数组大小的比例,称作负载因子。
dict_force_resize_ratio 的默认值是 5。
- ht[0]的大小为0,此时哈希表是空的,相当于对哈希表做一个初始化的操作。
- 如果哈希表中存储的节点数量大于或者等于哈希表数组的大小,并且哈希表可以扩容或者负载因子大于dict_force_resize_ratio(默认值为5),根据字典的类型判断允许分配内存,满足这三个条件开始扩容。
dict_can_resize
dict_can_resize用来判断哈希表是否可以扩容,有两种状态,值分别为1和0,1代表可以扩容,0代表禁用扩容:
void dictEnableResize(void) {dict_can_resize = 1;
}void dictDisableResize(void) {dict_can_resize = 0;
}
updateDictResizePolicy中对dict_can_resize的状态进行了控制,当前没有RDB子进程并且也没有AOF子进程时设置dict_can_resize状态为可扩容:
void updateDictResizePolicy(void) {// 没有RDB子进程并且也没有AOF子进程if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)dictEnableResize(); // 启用扩容elsedictDisableResize(); // 禁用扩容
}
扩容大小
从代码中可以看到,扩容后哈希表数组的大小为已经存储的节点数量+1:
// 进行扩容
return dictExpand(d, d->ht[0].used + 1);
一些旧版本中扩容后的大小为已存储节点数量的2倍:
dictExpand(d, d->ht[0].used*2);
渐进式hash
当哈希表存储节点内容比较多时,需要将原来的节点一个一个拷贝到新的哈希表中,此时Redis主线程无法执行其他请求,造成阻塞,影响性能,为了解决这个问题,引入了渐进式hash。
渐进式hash并不会一次把旧节点全部拷贝到新的哈希表中,而是分多次渐进式的完成拷贝,其中rehashidx记录了迁移进度,每一次迁移的过程中会更新rehashidx的值,下一次进行数据迁移的时候,从rehashidx的位置开始迁移,在dictRehash中可以看到迁移的处理:
- 方法传入了一个参数n,代表本次需要迁移几个哈希桶
- 根据需要迁移哈希桶的数量,循环处理每一个哈希桶:
- 如果当前哈希桶中为空,继续下一个桶的处理rehashidx++
- 如果当前哈希桶不为空,将当前桶中的所有节点迁移到新的哈希表中,然后更新rehashidx的值继续处理下一个桶
- 如果已经处理够了n个桶,或者哈希表的所有数据已经迁移完毕,则结束迁移。
int dictRehash(dict *d, int n) {int empty_visits = n*10; /* Max number of empty buckets to visit. */if (!dictIsRehashing(d)) return 0;// 循环处理每一个哈希桶,n为需要迁移哈希桶的数量while(n-- && d->ht[0].used != 0) {dictEntry *de, *nextde;assert(d->ht[0].size > (unsigned long)d->rehashidx);// 如果当前哈希桶没有存储数据while(d->ht[0].table[d->rehashidx] == NULL) {// rehashidx的值是哈希表数组的某个索引值(指向了某个哈希桶),意味着当前迁移到数组的哪个索引位置处d->rehashidx++; // 继续下一个桶if (--empty_visits == 0) return 1;}de = d->ht[0].table[d->rehashidx];// 如果当前的哈希桶中存储着数据,将哈希桶存储的所有数据迁移到新的哈希表中while(de) {uint64_t h;nextde = de->next;/* Get the index in the new hash table */h = dictHashKey(d, de->key) & d->ht[1].sizemask;de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}d->ht[0].table[d->rehashidx] = NULL;// rehashidx,继续迁移下一个哈希桶d->rehashidx++;}/* 判断ht[0]的节点是否迁移完成 */if (d->ht[0].used == 0) {// 释放ht[0]的空间zfree(d->ht[0].table);// 将ht[0]指向ht[1]d->ht[0] = d->ht[1];// 重置ht[1]的大小为0_dictReset(&d->ht[1]);// 设置rehashidx,-1代表rehash结束d->rehashidx = -1;return 0;}/* More to rehash... */return 1;
}
_dictRehashStep
_dictRehashStep中可以看到调用dictRehash时,每次迁移哈希桶的数量为1:
static void _dictRehashStep(dict *d) {if (d->pauserehash == 0) dictRehash(d,1);
}
总结
-
Redis字典底层使用哈希表实现。
-
键值对放入哈希表的时候,会根据key的值,计算hash值,出现哈希冲突的时候,Redis采用链式哈希解决冲突,使用链表将这些冲突的元素链起来。
-
由于Redis采用链式哈希解决冲突,那么在冲突频繁的场景下,链表会变得越来越长,这种情况下查找效率是比较低下的,需要遍历链表对比KEY的值来获取数据,为了处理效率低下的问题,需要对哈希表进行扩容,扩容的过程称为rehash。
-
当哈希表存储节点内容比较多时,进行rehas的时候主线程无法执行其他请求,造成阻塞,影响性能,所以采用了渐进式hash,渐进式hash并不会一次把旧节点全部拷贝到新的哈希表中,而是分多次渐进式的完成拷贝。
参考
黄健宏《Redis设计与实现》
极客时间 - Redis源码剖析与实战(蒋德钧)
美团针对Redis Rehash机制的探索和实践
Redis版本:redis-6.2.5
相关文章:
【Redis】基础数据结构-字典
Redis 字典 基本语法 字典是Redis中的一种数据结构,底层使用哈希表实现,一个哈希表中可以存储多个键值对,它的语法如下,其中KEY为键,field和value为值(也是一个键值对): HSET key…...

平板第三方电容笔怎么样?便宜的ipad触控笔推荐
苹果原装的电容笔与国产的平替电容笔最大的区别在于,平替电容笔只有一个斜面压力感应,而苹果电容笔既有斜面压力感应,又有重力压力感应。但是,如果你不经常使用它来进行绘画的话,你也不必买选择这款苹果电容笔…...
pytorch_神经网络构建3
文章目录 卷积神经网络实现卷积层,池化层池化层:数据标准化AlexNet卷积网络深层网络结构vgggoogleNet网络结构ResNet网络结构DensNet网络结构训练卷积神经网络会遇到的一些问题学习率衰减 卷积神经网络 前面讲述了逻辑回归分类,模拟函数回归问题,单层,深层网络,它们以点和向量…...
遗传算法入门笔记
目录 一、大体实现过程 二、开始我们的进化(具体实现细节) 2.1 先从编码说起 2.1.1 二进制编码法 2.1.2 浮点编码法 2.1.3 符号编码法 2.2 为我们的袋鼠染色体编码 2.3 评价个体的适应度 2.4 射杀一些袋鼠 2.5 遗传--染色体交叉(crossover) 2.6 变异--基…...

【golang】go 返回参数 以及go中 裸返
一、Go 返回参数命名 在Golang中,命名返回参数通常称为命名参数。 Golang允许在函数签名或定义中为函数的返回或结果参数指定名称。或者可以说这是函数定义中返回变量的显式命名。基本上,它解决了在return语句中提及变量名称的要求。 通过使用命名返回参…...

elasticsearch深度分页问题
一、深度分页方式from size es 默认采用的分页方式是 from size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询 1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all":…...
32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

Java练习题-用冒泡排序法实现数组排序
✅作者简介:CSDN内容合伙人、阿里云专家博主、51CTO专家博主、新星计划第三季python赛道Top1🏆 📃个人主页:hacker707的csdn博客 🔥系列专栏:Java练习题 💬个人格言:不断的翻越一座又…...

【SV中的多线程fork...join/join_any/join_none】
SV中fork_join/fork_join_any/fork_join_none 1 一目了然1.1 fork...join1.2 fork...join_any1.3 fork...join_none 2 总结 SV中fork_join和fork_join_any和fork_join_none; Note: fork_join在Verilog中也有,只有其他的两个是SV中独有的; 1 一目了然 1.…...
翻译:网站整站翻译 / 网站国际化 / 极简实现
一、本文目标 以极简单的方法实现整站翻译,轻松实现国际化。 二、js 文件 https://res.zvo.cn/translate/translate.js 三、代码 代码放在浏览器控制台即可实现 var head document.getElementsByTagName(head)[0];var script document.createElement(script);sc…...
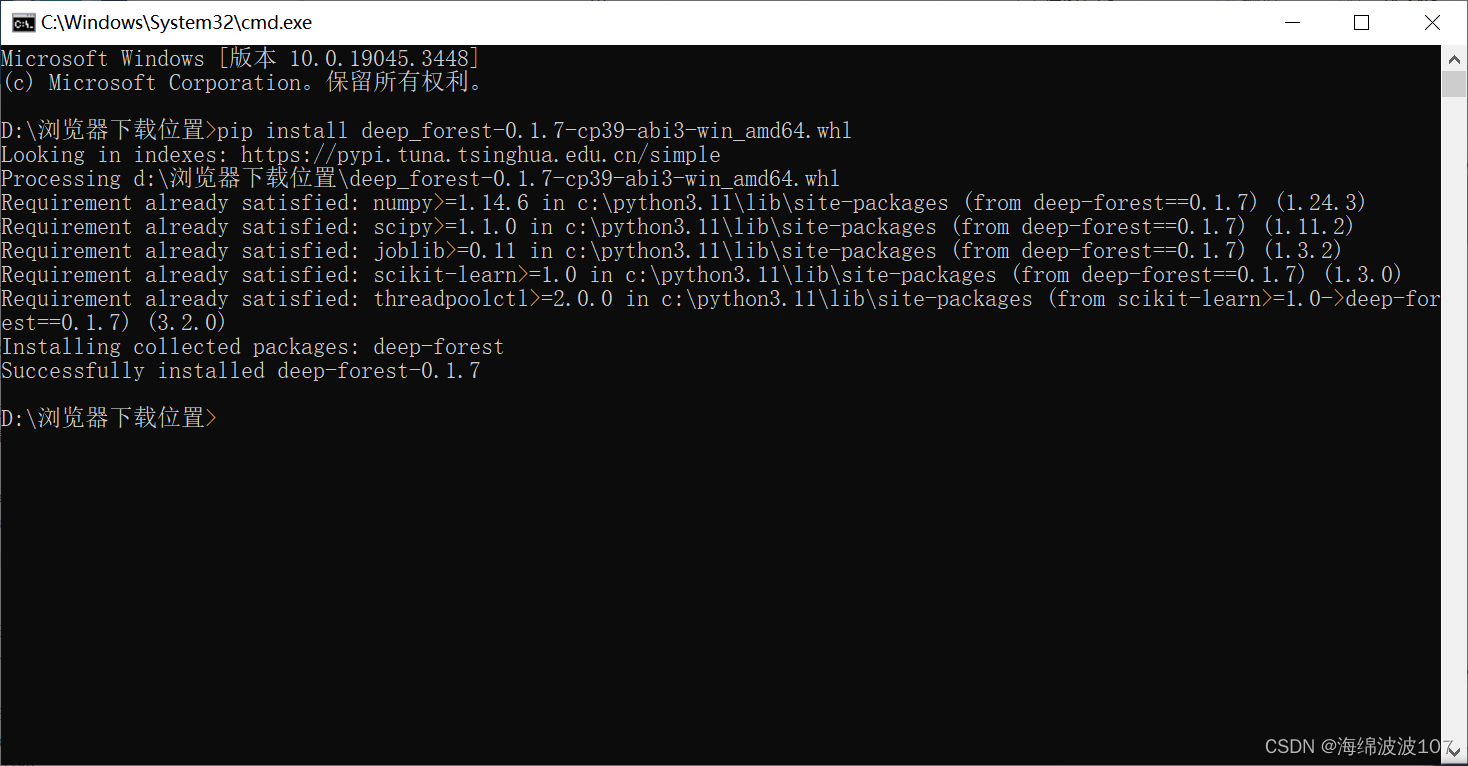
深度森林(deep-forest)安装
深度森林(deep-forest)安装 1、打开https://pypi.org/,搜索deep-forest,下载wheel文件 在下载好之后,打开文件下载的位置 首先对下载好的wheel文件进行改名,原名是: deep_forest-0.1.7-cp39-c…...

ping.pe ping 检测IP全球延迟
可以把结果保存为照片 https://ping.pe/全球ping ping ip端口检测 IP:PORT路由追踪 mtr IP 参考 ping.pe...

nodejs 16版本
Index of /download/release/latest-v16.x/...
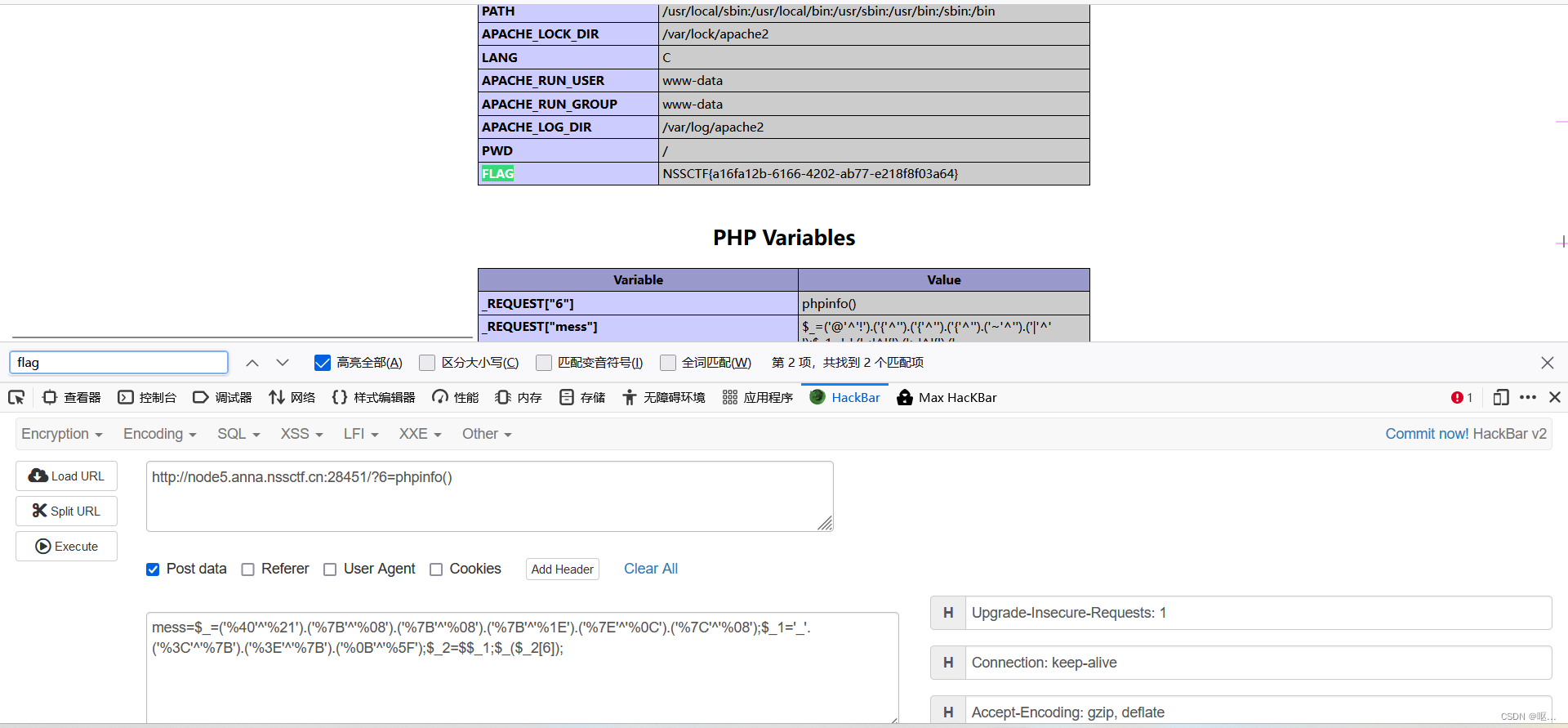
NSSCTF做题(7)
[第五空间 2021]pklovecloud 反序列化 <?php include flag.php; class pkshow { function echo_name() { return "Pk very safe^.^"; } } class acp { protected $cinder; public $neutron; …...

【GIT版本控制】--高级分支策略
一、分支合并策略 在Git中,高级分支策略是为了有效地管理和整合分支而设计的。其中一个关键方面是分支合并策略,它定义了如何将一个分支的更改合并到另一个分支。以下是几种常见的分支合并策略: 合并提交策略(Merge Commit Stra…...

【Qt控件之QDialog】使用及技巧
简介 QDialog是Qt中的一个类,继承自QWidget类,用于创建对话框窗口,可以显示模态(阻塞当前窗口)或非模态的对话框。对话框可以包含各种控件,如按钮、文本框等,用于与用户进行交互。 主要函数说…...
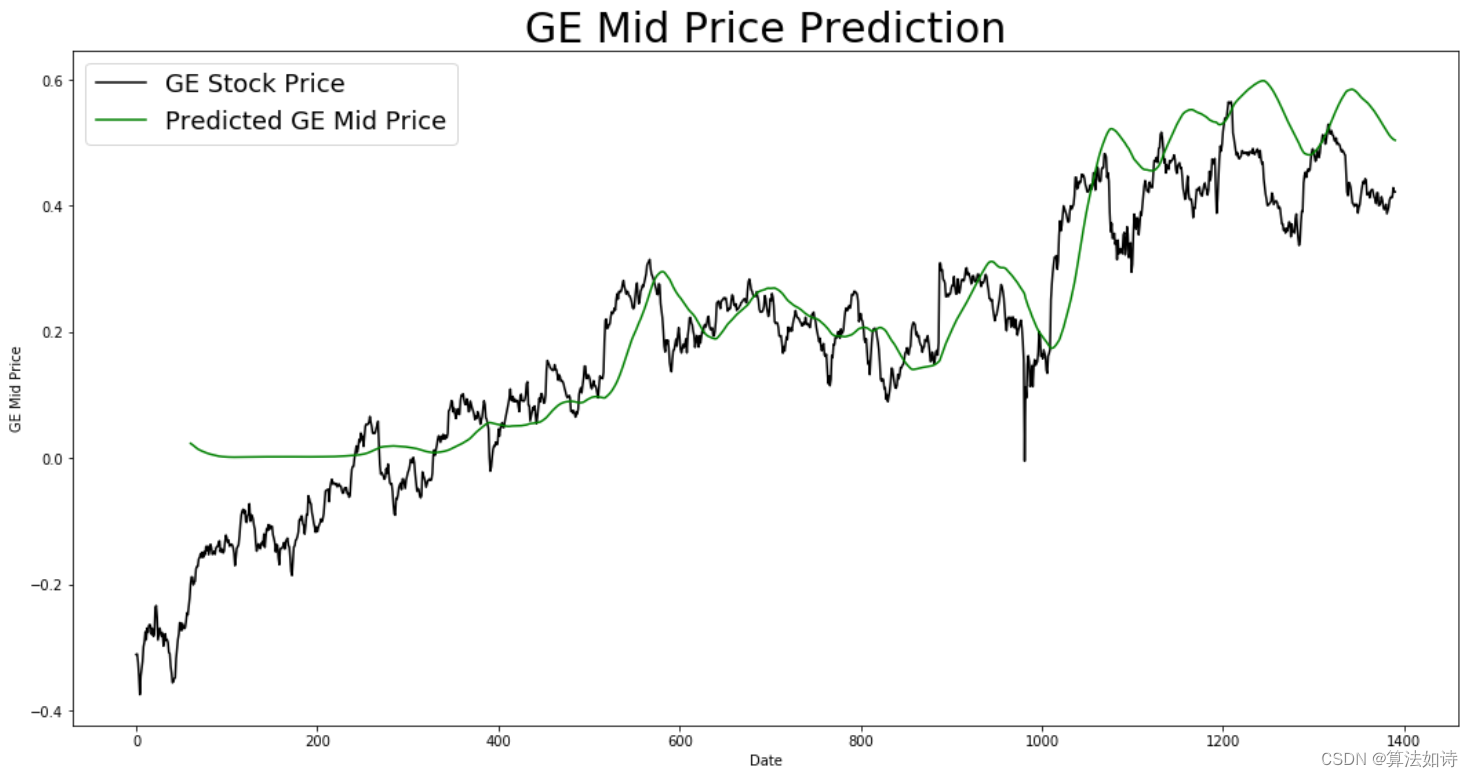
Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow) 程序设计 import numpy as np import matplotlib.pyplot...

spark sql如何行转列
在数据仓库中,行转列通常称为”变形”(Pivoting) 或 “透视”(Pivoting),可使用Spark SQL的pivot语句实现。下面是一个简单的示例: 假设我们有如下表格: -------------------- | name | brand | year | -------------------- |…...
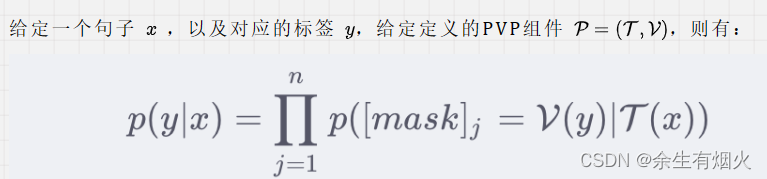
Prompt-Tuning(一)
一、预训练语言模型的发展过程 第一阶段的模型主要是基于自监督学习的训练目标,其中常见的目标包括掩码语言模型(MLM)和下一句预测(NSP)。这些模型采用了Transformer架构,并遵循了Pre-training和Fine-tuni…...
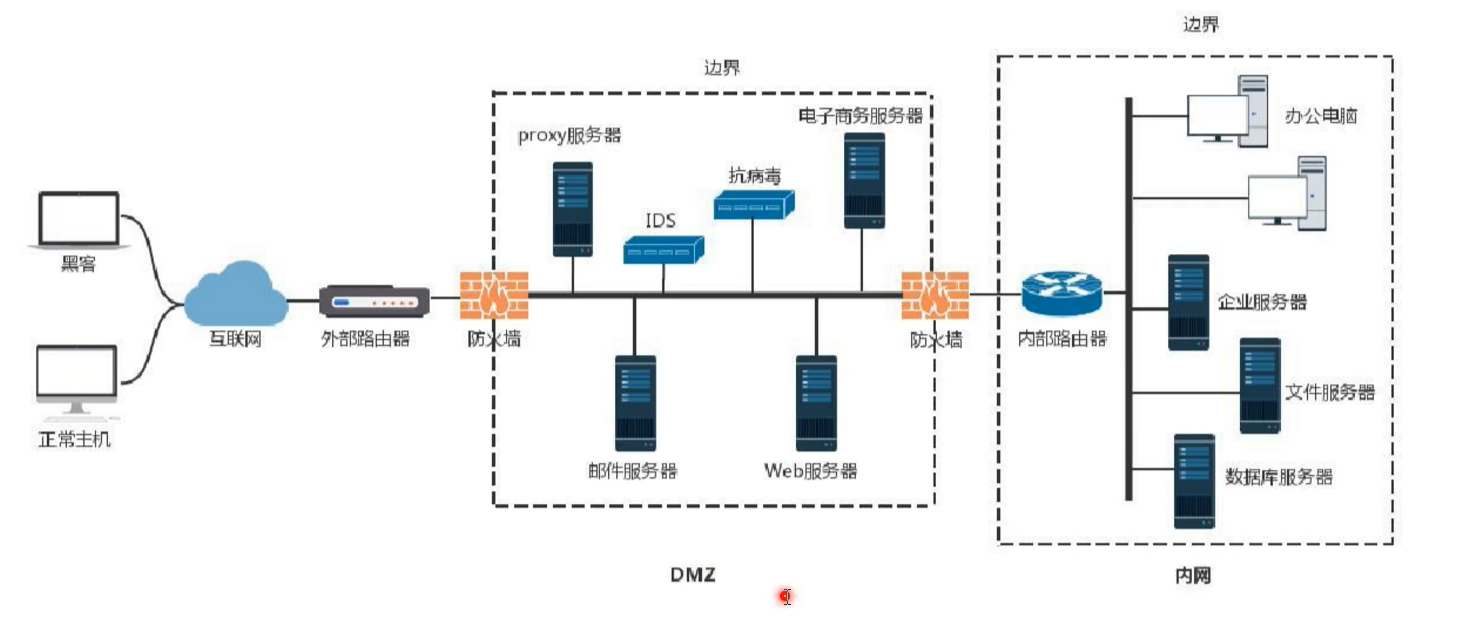
域信息收集
DMZ,是英文“demilitarized zone”的缩写,中文名称为“隔离区”,也称“非军事化区”。它是为了解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区。该缓冲区位于企业…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南
Windows Android子系统深度优化:WSABuilds项目架构解析与实战部署指南 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ker…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

Grad-CAM实战:用热力图透视神经网络的决策焦点
1. Grad-CAM技术初探:为什么我们需要热力图? 当你训练了一个图像分类模型,准确率高达95%,但你真的了解它是如何做出判断的吗?我曾在项目中遇到过这样的尴尬:模型把一只坐在草地上的哈士奇误判为"狼&qu…...

Bun用Rust重写核心代码,百万行新增代码直接把GitHub干爆了!
Bun 项目刚刚完成了一次惊人的技术跨越。5月14日,Bun 正式宣布其核心运行时已从 Zig 重写为 Rust——这个版本包含 6755 个 commit,二进制文件体积缩小 3-8 MB,性能测试在各个平台上均达到或超越原有水平。Jarred Sumner(Bun 的创…...

私有化部署智能助手:基于开源项目smarty-gpt的本地化AI对话平台搭建指南
1. 项目概述:当智能助手遇上本地化部署最近在折腾一个挺有意思的开源项目,叫citiususc/smarty-gpt。乍一看名字,你可能觉得这又是一个基于GPT的聊天机器人,没什么新意。但如果你深入了解一下,就会发现它的定位非常独特…...

Linux光标主题管理工具x-cursor-help:从原理到实战
1. 项目概述:一个被低估的鼠标光标辅助工具如果你在Linux桌面环境下工作,尤其是使用像GNOME、KDE Plasma这类现代化的桌面环境,你可能会遇到一个不大不小但很恼人的问题:鼠标光标主题的安装和管理。从网上下载了一个漂亮的.tar.gz…...

在 1688、阿里国际站上,怎么分清哪些是真工厂、哪些是贸易商?一份采购辨别清单
跨境卖家和采购最常踩的坑,就是把贸易商当成了源头工厂。结果是:报价里多了一手差价、打样要等贸易商再转给后面的厂、出了质量问题没人能进车间整改。 平台上的"工厂认证"“源头工厂”"工厂直供"标签,看起来像是替你做了…...