仅用61行代码,你也能从零训练大模型
本文并非基于微调训练模型,而是从头开始训练出一个全新的大语言模型的硬核教程。看完本篇,你将了解训练出一个大模型的环境准备、数据准备,生成分词,模型训练、测试模型等环节分别需要做什么。AI 小白友好~文中代码可以直接实操运行。
通过这篇文章,你可以预训练一个全新大语言模型。注意是全新的模型,不是微调。
全新训练的好处是训练的数据、训练的参数都是可修改的,通过调试运行我们可以更好的理解大模型训练过程。我们可以用特定类型数据的训练,来完成特定类型数据的输出。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群
关于大模型已经有很多文章,微调模型的文章比较多,全新预训练全新模型的文章很少。个人觉得有的也讲的很复杂,代码也很难跑通。本文不会讲的很复杂,代码也很容易运行。仅用61行代码,就能训练出一个全新大语言模型。

本文以代码为主,运行代码需要 Python 环境。
01 准备训练环境
我的训练环境基于腾讯云的 GPU 机器。
地址:https://cloud.tencent.com/product/gpu
|
tokenizers==0.13.3
torch==2.0.1
transformers==4.30.
02 准备训练数据
首先我们要为训练准备数据,比如我就想基于《三国演义》训练一个模型。三国演义下载地址:
https://raw.githubusercontent.com/xinzhanguo/hellollm/main/text/sanguoyanyi.txt

03 训练分词器
分词(tokenization)是把输入文本切分成有意义的子单元(tokens)。通过以下代码,根据我们的数据生成一个新的分词器:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.normalizers import NFKC, Sequence
from tokenizers.pre_tokenizers import ByteLevel
from tokenizers.decoders import ByteLevel as ByteLevelDecoder
from transformers import GPT2TokenizerFast# 构建分词器 GPT2 基于 BPE 算法实现
tokenizer = Tokenizer(BPE(unk_token="<unk>"))
tokenizer.normalizer = Sequence([NFKC()])
tokenizer.pre_tokenizer = ByteLevel()
tokenizer.decoder = ByteLevelDecoder()special_tokens = ["<s>","<pad>","</s>","<unk>","<mask>"]
trainer = BpeTrainer(vocab_size=50000, show_progress=True, inital_alphabet=ByteLevel.alphabet(), special_tokens=special_tokens)
# 创建 text 文件夹,并把 sanguoyanyi.txt 下载,放到目录里
files = ["text/sanguoyanyi.txt"]
# 开始训练了
tokenizer.train(files, trainer)
# 把训练的分词通过GPT2保存起来,以方便后续使用
newtokenizer = GPT2TokenizerFast(tokenizer_object=tokenizer)
newtokenizer.save_pretrained("./sanguo")
运行时显示如下图:

成功运行代码后,我们在 sanguo 目录生成如下文件:
merges.txt
special_tokens_map.json
tokenizer.json
tokenizer_config.json
vocab.json
现在我们已经成功训练了一个大语言模型的分词器。
04 训练模型
利用下面代码进行模型训练:
from transformers import GPT2Config, GPT2LMHeadModel, GPT2Tokenizer
# 加载分词器
tokenizer = GPT2Tokenizer.from_pretrained("./sanguo")
tokenizer.add_special_tokens({"eos_token": "</s>","bos_token": "<s>","unk_token": "<unk>","pad_token": "<pad>","mask_token": "<mask>"
})
# 配置GPT2模型参数
config = GPT2Config(vocab_size=tokenizer.vocab_size,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id
)
# 创建模型
model = GPT2LMHeadModel(config)
# 训练数据我们用按行分割
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(tokenizer=tokenizer,file_path="./text/sanguoyanyi.txt",block_size=32,# 如果训练时你的显存不够# 可以适当调小 block_size
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, mlm_probability=0.15
)from transformers import Trainer, TrainingArguments
# 配置训练参数
training_args = TrainingArguments(output_dir="./output",overwrite_output_dir=True,num_train_epochs=20,per_gpu_train_batch_size=16,save_steps=2000,save_total_limit=2,
)
trainer = Trainer(model=model,args=training_args,data_collator=data_collator,train_dataset=dataset,
)
trainer.train()
# 保存模型
model.save_pretrained('./sanguo')
运行比较耗时,显示训练数据如下图:

成功运行代码,我们发现 sanguo 目录下面多了三个文件:
config.json
generation_config.json
pytorch_model.bin
现在我们就成功生成训练出基于《三国演义》的一个大语言模型。
05 测试模型
我们用文本生成,对模型进行测试代码如下:
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='./sanguo')
set_seed(42)
txt = generator("吕布", max_length=10)
print(txt)
运行显示模型输出了三国相关的文本:“吕布十二回 张翼德 张翼德时曹操 武侯计计计”

再测试一条:
txt = generator("接着奏乐", max_length=10)
print(txt)
“接着奏乐\u3000却说曹操引军因二人”

这内容不忍直视,如果想优化,我们也可以基于全新的模型进行微调训练;我们也可以适当地调整下训练参数,以达到较好的效果。
06 完整代码
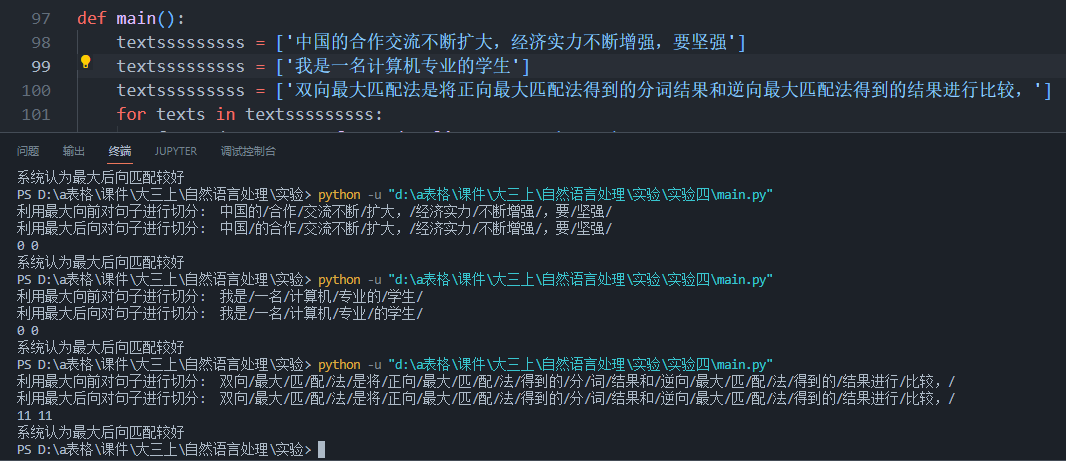
以下是完整代码,代码地址:
https://github.com/xinzhanguo/hellollm/blob/main/sanguo.py
linux 中运行方法:
# 创建环境
python3 -m venv ~/.env
# 加载环境
source ~/.env/bin/activate
# 下载代码
git clone git@github.com:xinzhanguo/hellollm.git
cd hellollm
# 安装依赖
pip install -r requirements.txt
# 运行代码
python sanguo.py
以上我们就完成一个全新的模型训练。代码去除注释空行总共61行。
本文代码模型是基于 GPT2 的,当然你也可以基于 LLama 或者 Bert 等模型去实现全新的大语言模型。
代码虽然不是很多,但是如果初次尝试运行的话你也许会遇到很多问题,比如环境搭建。为了避免其他烦恼,我建议用 docker 方式运行代码:
# 下载代码
git clone git@github.com:xinzhanguo/hellollm.git
cd hellollm
# 编译镜像
docker build -t hellollm:beta .
# 可以选择以GPU方式运行
# docker run -it --gpus all hellollm:beta sh
docker run -it hellollm:beta sh
python sanguo.py
更多代码可以参考:Hello LLM!
https://github.com/xinzhanguo/hellollm
以上就是本篇文章的全部内容,欢迎转发分享。
相关文章:
仅用61行代码,你也能从零训练大模型
本文并非基于微调训练模型,而是从头开始训练出一个全新的大语言模型的硬核教程。看完本篇,你将了解训练出一个大模型的环境准备、数据准备,生成分词,模型训练、测试模型等环节分别需要做什么。AI 小白友好~文中代码可以直接实操运…...
Vue3目录结构与Yarn.lock 的版本锁定
Vue目录结构与Yarn.lock 的版本锁定 一、Vue3.0目录结构图总览 举个例子看vue的目录,一开始不知道该目录是什么意思目录里各个文件包里安放有什么,程序员在哪里操作该如何操作。 下图目录看Vue新项目 VS Code 打开文件包后出现一列目录 二、目录结构 1…...
内网渗透之哈希传递
文章目录 哈希传递(NTLM哈希)概念LMNTLM 原理利用hash传递获取域控RDP 总结 哈希传递(NTLM哈希) 内网渗透中找到域控IP后使用什么攻击手法拿下域控: 扫描域控开放端口。因为域控会开放远程连接:windows开…...

Haar cascade+opencv检测算法
Harr特征识别人脸 Haar cascade opencv步骤 读取包含人脸的图片使用haar模型识别人脸将识别的结果用矩形框画出来 构造haar检测器 :cv2.CascadeClassifier(具体检测模型文件) # 构造Haar检测器 # 级联分级机,cv2.CascadeClassifier():cv2的内置方法࿰…...

跨域请求方案整理实践
项目场景: 调用接口进行手机验证提示,项目需要调用其它域名的接口,导致前端提示跨域问题 问题描述 前端调用其他域名接口时报错提示: index.html#/StatisticalAnalysisOfVacancy:1 Access to XMLHttpRequest at http://xxxxx/CustomerService/template/examineMes…...
Git Pull failure 【add/commit】
操作页面 操作步骤 1. 打开项目所在 在.git目录下右击打开Git Bssh Here 2. git add . 3. git commit -m "提交" 4. 成功提交到本地, 这下就可以拉取代码了...
单链表习题(对应章节chapter2)
题目1:链表的中间结点 题目来源:leetcode链表的中间结点 第一种思路分析:考虑指针移动到相应的位置来做 参考代码:位置(/chapter2/c/middle-link-list-node/lc1.cc) #include <stdio.h> extern &qu…...

SQL创建新表
表的创建、修改与删除: 1.1 直接创建表:CREATE TABLE [IF NOT EXISTS] tb_name – 不存在才创建,存在就跳过 (column_name1 data_type1 – 列名和类型必选 [ PRIMARY KEY – 可选的约束,主键 | FOREIGN KEY – 外键,引…...

Python视频剪辑-Moviepy视频尺寸和颜色调整技巧
在视频编辑中,尺寸和颜色是两个不能忽视的重要因素。本文将从专业角度深入探讨如何通过MoviePy进行视频尺寸和颜色的调整,以及遮罩透明度的应用。 文章目录 视频尺寸变换函数裁剪视频指定区域裁剪视频像素为偶数视频增加边框缩小、放大视频视频颜色变换函数blackwhite 视频变…...

前端笔记:Create React App 初始化项目的几个关键文件解读
1 介绍 Create React App 是一个官方支持的方式,用于创建单页应用的 React 设置用于构建用户界面的 JAVASCRIPT 库主要用于构建 UI 2 项目结构 一个典型的 Create React App 项目结构如下: ├── package.json ├── public # 这…...

提高工作效率!本地部署Stackedit Markdown编辑器,并实现远程访问
文章目录 1. docker部署Stackedit2. 本地访问3. Linux 安装cpolar4. 配置Stackedit公网访问地址5. 公网远程访问Stackedit6. 固定Stackedit公网地址 StackEdit是一个受欢迎的Markdown编辑器,在GitHub上拥有20.7k Star!,它支持将Markdown笔记保…...

visual studio解决bug封装dll库
1.速度最大化 O2 2.设置输出目录 配置属性/常规/输出目录 链接器/常规/输出dll文件 链接器/调试/输出程序数据库pdb文件 链接器/高级/导入库 3.输出X86 X64分别对应的dll、lib、pdb 然后修改更新说明 更新说明格式如下: 4.将库提交到FTP每日更新库文档下 和测试交接…...
合肥工业大学自然语言处理实验报告
工程报告 目录 1 研究背景 4 2 工程目标 7 2.1 工程一 7 2.2 工程二 7 2.3 工程三 7 2.4 工程四 7 3 实验环境与工具 7 4 模型方法 8 4.1 n-gram模型 8 4.2 模型的平滑 9 4.2.1 Add-one 9 4.2.2 Add-k 9 4.2.3 Backoff 10 4.2.4 Interpolation 10 4.2.5 Absolute discounting 1…...
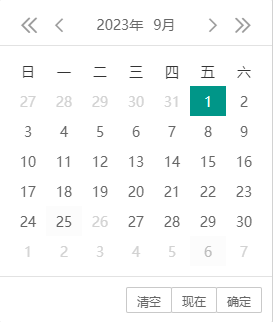
layui laydate实现日期选择并禁用指定的时间
最终实现禁用2023-9-26这天的效果 官网地址 日期和时间组件文档 - layui.laydate 下面是实现的代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>layDate快速使用</title><link rel"stylesheet"…...

scala数组函数合集
目录 1. 添加类函数 2.生成类函数 3.删除类函数 4.查找类函数 5.统计类函数 6.修改类函数 7.判断类函数 8.获取集合元素 9.集合操作类函数 10.转换类函数 11.工具类函数 12.集合内与集合间计算函数 在 scala 中Array数组是一种可变的、可索引的数据集合 创建数组…...

软件测试「转行」答疑(未完更新中)
软件测试行业「转行」答疑(未完更新中) ⭐文章简介一、2023年「互联网」行业现状!二、0基础转行「互联网」的5句大实话建议!三、互联网有哪些「职业」,可以选择?四、这些职业之间的优缺点介绍。 ⭐文章简介…...

计算机网络---TCP/UDP
TCP/UDP 1、TCP三次握手 四次挥手? TCP是一种面向连接的、可靠的字节流服务。在建立TCP连接时,需要进行三次握手,而在关闭TCP连接时,需要进行四次挥手。具体来说,TCP三次握手的过程如下: 客户端向服务端发送SYN报文,表示请求建立连接。服务端收到SYN报文后,向客户端发…...

Docker私有仓库打开2375端口(linux)
前言 在我们开发测试过程中,需要频繁的更新docker镜像,然而默认情况下,docker的2375端口是关闭的,下面介绍如何打开端口。 1、打开步骤 1.1、修改配置 登录docker所在服务器,修改docker.service文件 vi /usr/lib/sys…...
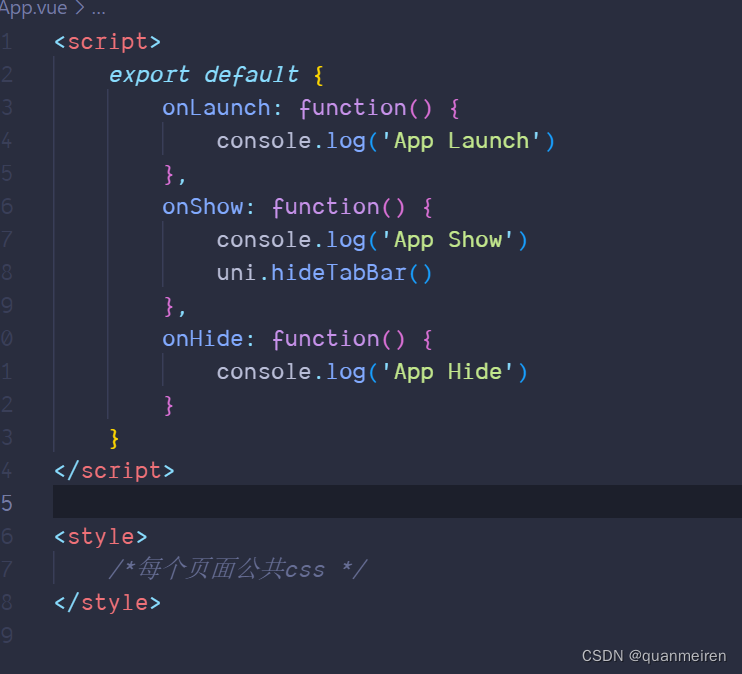
底部Taber的抽取
1.会抽取一个布局样式 2.布局样式里面抽取一个底部样式 这个是layout的代码 <template><view class"layout-wrapper"><view class"layout-content"><slot></slot></view><!-- 底部 --><Tabbar :activeInde…...

Bootstrap中固定某一个元素不随滚动条滚动
可以利用类sticky-top实现固定某个元素在顶部的效果,示例代码如下: <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>固定某一个元素不随滚动条滚动</title><meta name"viewport&quo…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

基于轨道模型构建现代化流程编排系统:从概念到实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫s4kuraN4gi/orbit-app。乍一看这个仓库名,可能很多人会有点懵,不知道它具体是做什么的。我花了一些时间深入研究,发现这是一个围绕“轨道”概念构建的现代化应用。这…...

Apex Legends进阶指南:结构化训练框架与技能模块化拆解
1. 项目概述:一个面向Apex Legends玩家的成长型技能库如果你是一位《Apex Legends》的玩家,并且对提升自己的游戏水平有持续的热情,那么你很可能和我一样,经历过一个漫长的摸索期。从最初落地成盒,到逐渐熟悉地图、枪械…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...