数据结构:排序- 插入排序(插入排序and希尔排序) , 选择排序(选择排序and堆排序) , 交换排序(冒泡排序and快速排序) , 归并排序
目录
前言
复杂度总结
预备代码
插入排序
1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1)
复杂度(空间/时间):
2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1)
复杂度(空间/时间):
选择排序
1.直接选择排序 时间复杂度O(N^2)/空间复杂度O(1)
复杂度(空间/时间):
2.堆排序: 时间复杂度O(N*logN) /空间复杂度O(1)
复杂度(空间/时间):
交换排序
1.冒泡排序: 时间复杂度O(N^2)/空间复杂度O(1)
复杂度(空间/时间):
2.快速排序
2.1. hoare版本 时间复杂度为O(n)/空间复杂度为O(1)编辑
2.2. 挖坑法 相比hoare本质上并没有简化复杂度编辑
2.3. 前后指针法编辑
2.4三数取中:
2.5快排主体 &&小区间优化
快排主体 &&小区间优化
复杂度(空间/时间):
将快速排序改为非递归
归并排序
复杂度(空间/时间):
归并排序非递归实现
方法一 :修正边界法编辑
方法二 :
全部功能测试
全部代码
头文件
1.Sort.h
2.Stack.h
函数实现文件
1.Sort.c
2.QuickSort.c
3.Heap.c
4.Stack.c
测试函数
test.c
前言
在数据结果中:常见排序一共分为四种
- 插入排序(直接插入排序,希尔排序)
- 选择排序(选择排序,堆排序)
- 交换排序(冒泡排序,快速排序)
- 归并排序
排序的概念:
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起
来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记
录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍
在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据
的排序。
插入,选择,交换都为内部排序
而 归并排序 即为内部排序也为外部排序
本文将对这些排序进行详细讲解
复杂度总结
表中 平均情况and最好情况and最坏情况都是讨论时间复杂度:
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 直接选择排序 | O(N^2) | O(N^2) | O(N^2) | O(1) | 不稳定 |
| 直接插入排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 希尔排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(N^2) | O(logn)~O(n) | 不稳定 |
预备代码
//打印
void PrintArry(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ",a[i]);printf("\n");
}//交换
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
插入排序
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐
个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1)
直接插入排序的思想是将待排序的元素逐个插入已经排好序的序列中,直到全部元素都插入完毕。它通过比较元素大小,找到正确的插入位置,并插入到该位置。这样不断重复,直到完成排序。它是一种简单且稳定的排序算法,适用于小规模数据或已经基本有序的数据。
-
思想:
1.先将第0个记录,组成一个有序子表
2.然后依次将后面的记录插入到这个子表中,且一直保持它的有序性。 -
步骤
在r[0…i-1]中查找r[i]的插入位置,r[0…j].key ≤r[i].key < r[j+1…i-1].key
将r[j+1 … i-1] 中的所有记录均后移一个位置
将r[i]插入到r[j+1]的位置上
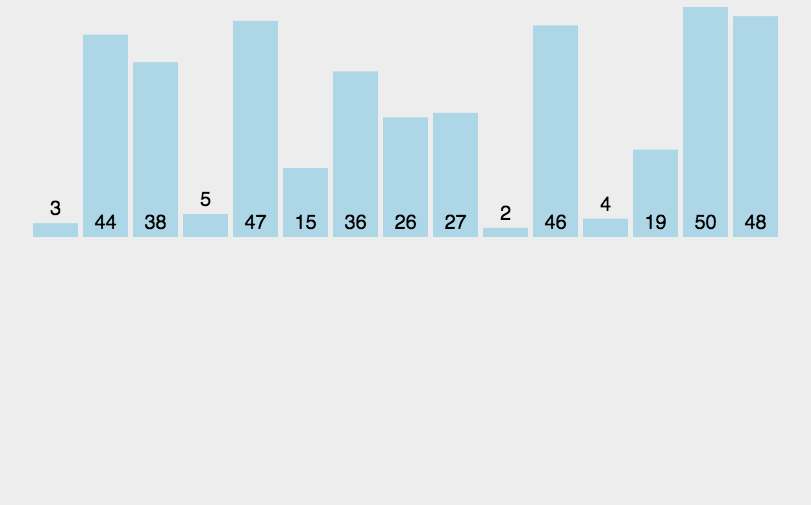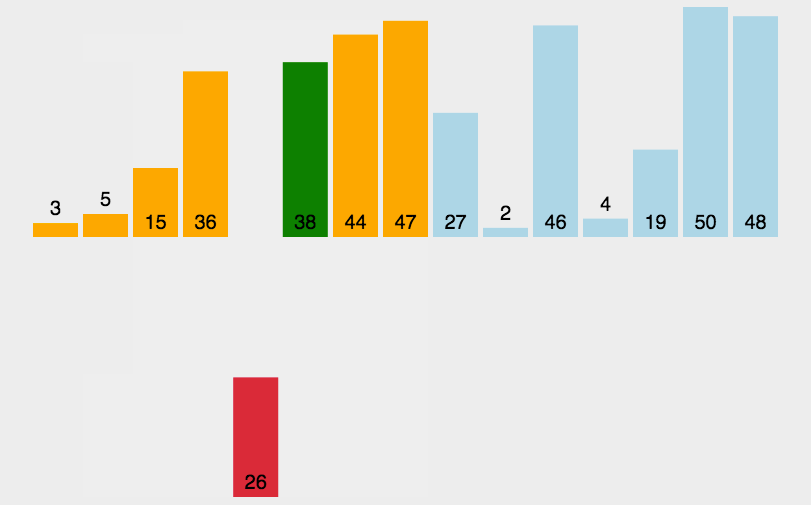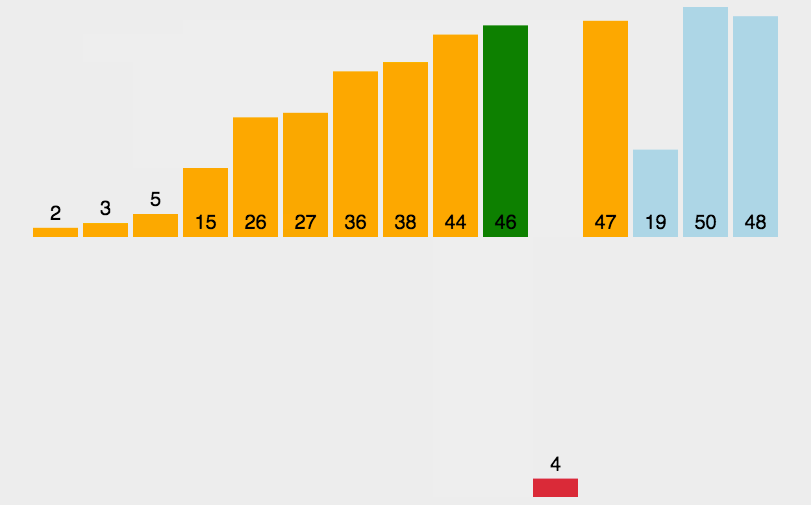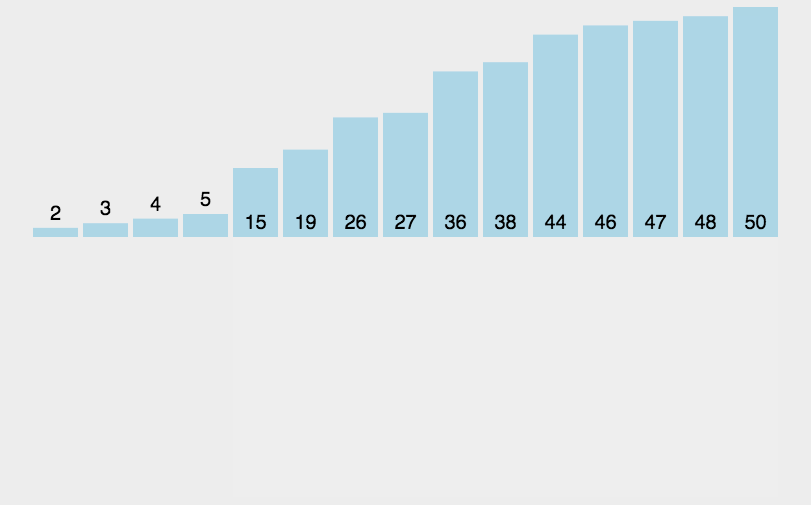 算法实现:
算法实现:
//直接插入排序
// 一个数一次向后比较一个元素,当比该数字小时,后面元素后移,后插入该数
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){// [0,end]有序,吧end+1 位置的值插入,保持有序int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end])//要交换的数字更大{//指针指向元素后移,end指针前移a[end + 1] = a[end];--end;}else{//要交换的数字更小,退出循环break;}}//开始交换a[end + 1] = tmp;}
}
测试:
void TestInsertSort()
{int a[] = { 9,1,2,5,7,4,8,6,3,5 };int sz = sizeof(a) / sizeof(a[0]);InsertSort(a, sz);PrintArry(a, sz);
}直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定
复杂度(空间/时间):
时间复杂度:
- 最好情况下,即输入序列已经按升序排好顺序,直接插入排序的时间复杂度为O(n),其中n是待排序序列的长度。因为此时插入一个元素时,只需比较一次即可确定插入位置。
- 最坏情况下,即输入序列是降序排列,直接插入排序的时间复杂度为O(n^2)。因为此时每个元素都需要与前面的所有元素比较,找到正确的插入位置。
- 平均情况下,直接插入排序的时间复杂度也是O(n^2)。这是因为每个元素的平均比较次数为n/2,而平均移动次数为n/4。
空间复杂度:
直接插入排序的空间复杂度为O(1)。直接插入排序是一种原地排序算法,它只需要常数级别的额外空间来存储临时变量,不需要开辟额外的存储空间。
需要注意的是,直接插入排序是一种稳定的排序算法。相等元素的相对顺序不会被改变。虽然直接插入排序的时间复杂度较高,但在对小规模数据或基本有序的数据进行排序时,它是一种简单而有效的选择。
2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1)
希尔排序是一种改进的插入排序算法。它通过将待排序的元素按一定间隔分组,对每个分组进行插入排序,然后逐步缩小间隔,重复这个过程,直到间隔为1。希尔排序通过跳跃式的比较和移动元素,可以在某种程度上提前将较小的元素移动到前面,从而大致有序,最后再进行一次插入排序完成排序。希尔排序的时间复杂度不是固定的,但通常情况下具有较高的效率。
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
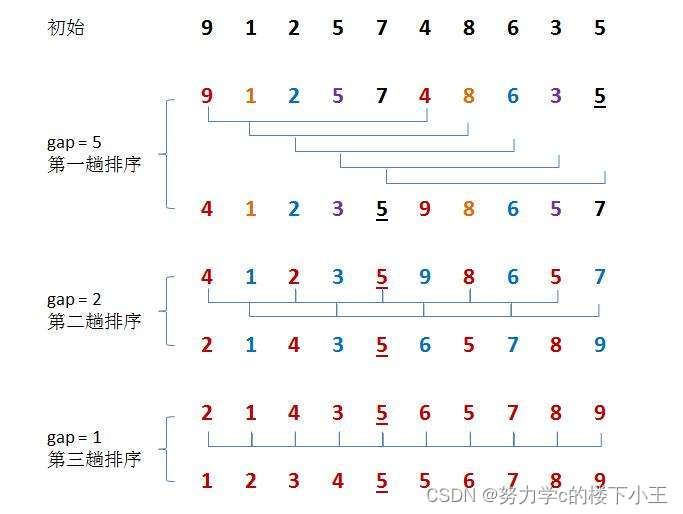
gap越大,所排列的有序性越差,故gap不易过大
算法实现:
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;// gap/3:保证每次跳跃的间隔. +1:保证不为0//gap组交替进行排序/*gap越大大的数更快到后面,小的数可以更快到前面排升序,gap越小,越接近有序,当gap==1,就是插入排序*/for (int i = 0; i < n - gap; i++)//往前走一位,gap另一部分 {int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){//排序a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;//交换元素值}}
}
测试
void TestShellSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);ShellSort(a, sz);PrintArry(a, sz);
}
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的
了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的
对比。 - 希尔排序的时间复杂度不好计算,需要进行推导,推导出来平均时间复杂度: O(N^1.3—
N^2) - 稳定性:不稳定
复杂度(空间/时间):
时间复杂度:
希尔排序的时间复杂度取决于所选择的增量序列。在最坏的情况下,希尔排序的时间复杂度为O(n^2){ O(N^1.3~ N^2)},其中n是待排序序列的长度。但是在一般情况下,希尔排序的时间复杂度可以达到O(nlogn)。这是因为希尔排序通过逐步缩小增量,先对较远距离的元素进行比较和移动,使得序列整体趋于有序,然后再逐步缩小增量,最后进行一次增量为1的插入排序,这样减少了比较和移动的次数,提高了排序效率。
空间复杂度:
希尔排序的空间复杂度为O(1),即常数级别的额外空间。希尔排序是一种原地排序算法,不需要额外开辟新的空间来存储临时变量或中间结果。所有的操作都是在输入序列上进行的,所以空间复杂度非常低。
选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全
部待排序的数据元素排完 。
1.直接选择排序 时间复杂度O(N^2)/空间复杂度O(1)
直接选择排序是一种简单的排序算法,通过不断选择最小(或最大)的元素,并将其放到已排序部分的末尾。这个过程在每次遍历中交换元素位置,直到整个序列有序。
步骤:
- 在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
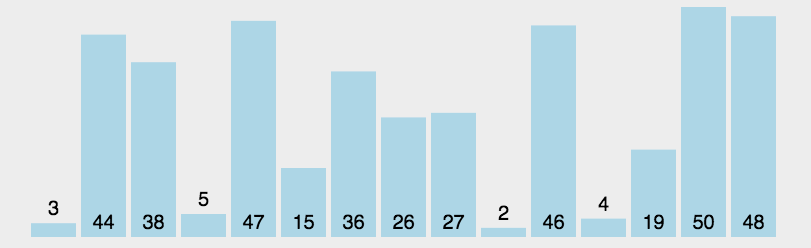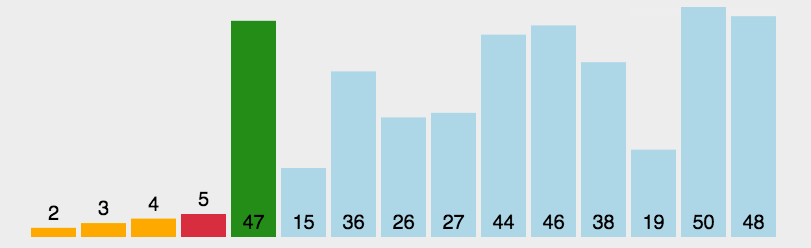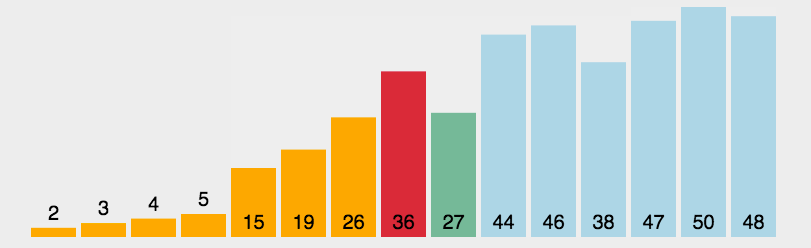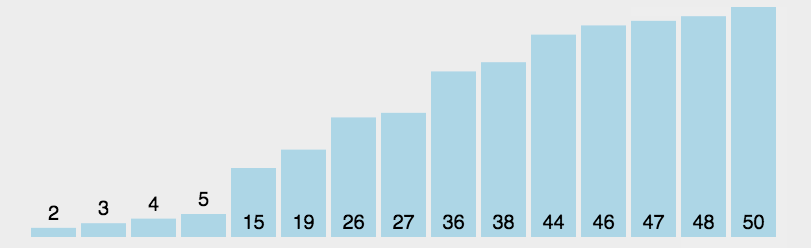
算法实现:
//对比插入排序,还是插入排序更优
void SelectSort(int* a, int n)
{assert(a);//遍历一遍选出最小and最大的,分别放在左右边int begin = 0, end = n - 1;int mini = begin, maxi = begin;while (begin<end){for (int i = 0; i <= end; i++){//选最小if (a[i] < a[mini])mini = i;//选最大if (a[i] > a[maxi])maxi = i;}Swap(&a[begin], &a[mini]);//交换元素//如果begin和maxi重叠,那么需要修正位置if (begin == maxi)maxi = mini;Swap(&a[end], &a[maxi]);//交换元素++begin;--end;}
}
直接选择排序的特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N2)
- 空间复杂度:O(1)
- 稳定性:不稳定
复杂度(空间/时间):
直接选择排序的时间复杂度是O(n^2),其中n是待排序序列的长度。具体来说,每次在未排序部分中查找最小元素,需要进行n-1次比较;然后将最小元素与已排序部分的最后一个元素交换位置,需要进行n-1次交换操作。因此,总共需要进行(n-1) + (n-2) + … + 2 + 1 = n(n-1)/2 次比较和交换,即时间复杂度为O(n^2)。
直接选择排序的空间复杂度是O(1),即只需要存储少量的辅助变量来进行比较和交换操作,不需要额外开辟存储空间。
需要注意的是,直接选择排序是一种不稳定的排序算法,因为相等元素之间的相对顺序可能发生改变。在实际应用中,如果对稳定性有要求,可能会选择其他排序算法。
2.堆排序: 时间复杂度O(N*logN) /空间复杂度O(1)
堆排序详细讲解:# 数据结构:树和二叉树之-堆排列 (万字详解)
1, 将数据插入堆中,造成大堆
2,Pop k次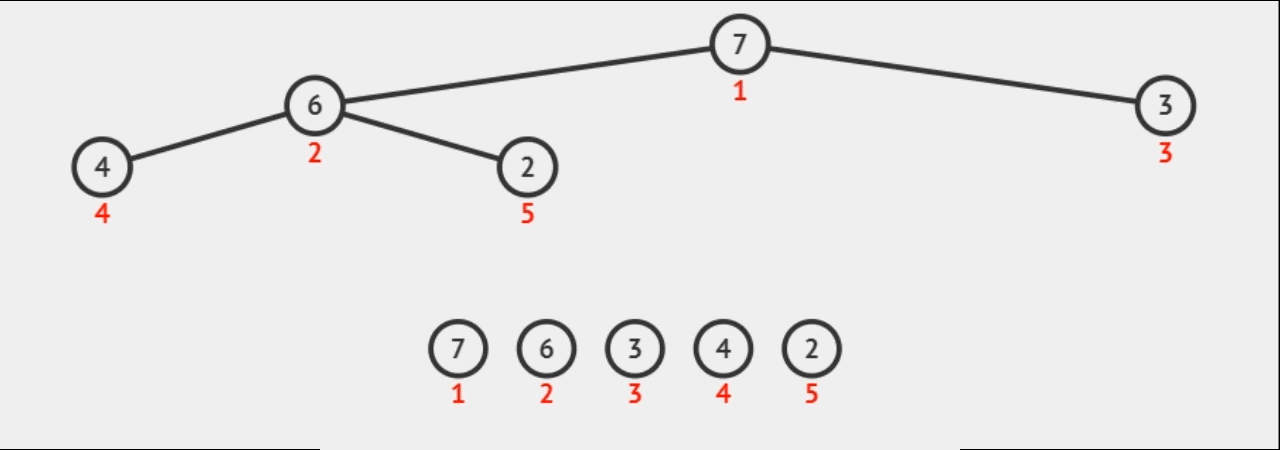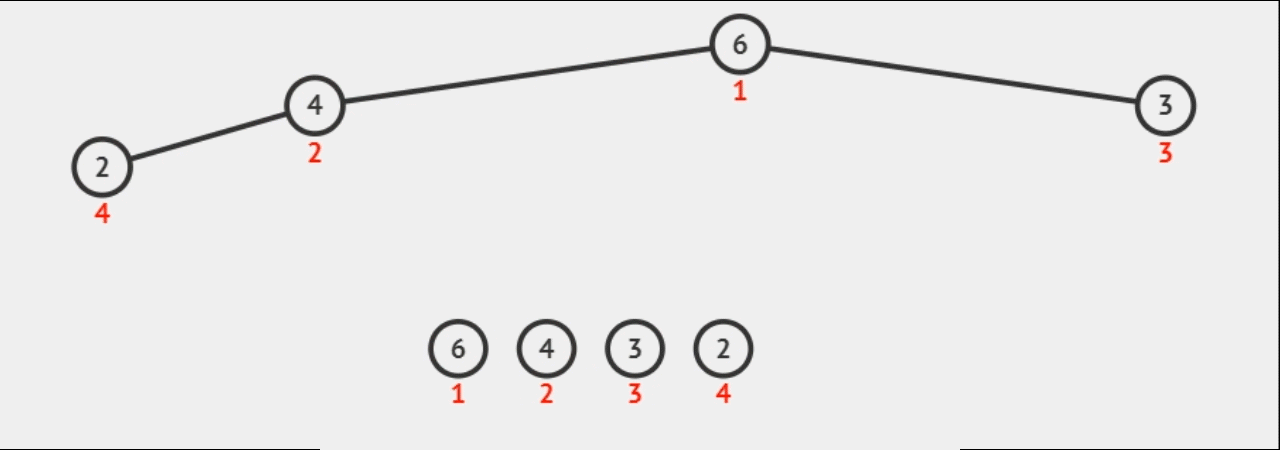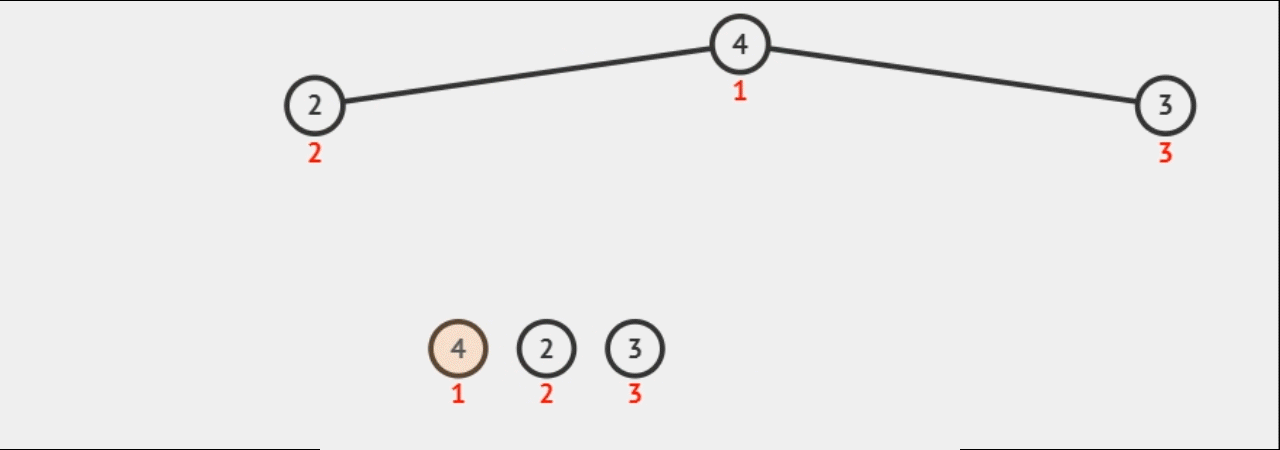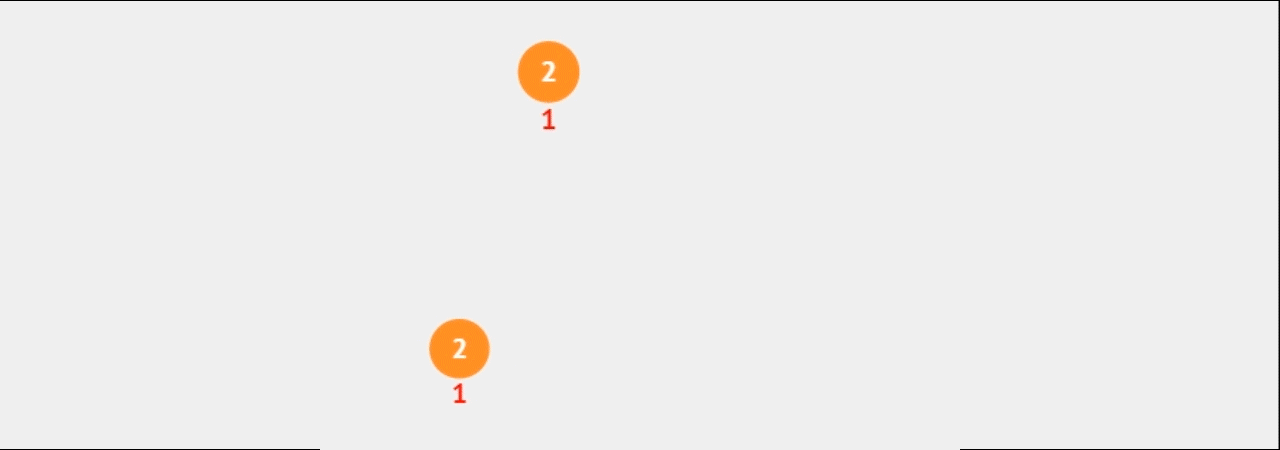
算法实现:
//向下调整
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){if (child + 1 < size && a[child + 1] > a[child])++child;//跟孩子父亲比较if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{//左右孩子都大于/小于父亲,结束交换break;}}
}//堆排序
void HeapSort(int* a, int n)
{//时间复杂度:O(N)for (int i = (n - 1) / 2; i >= 0; i--)AdjustDown(a, n, i);int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
测试:
void TestHeapSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);HeapSort(a, sz);PrintArry(a, sz);
}
堆排序的特性总结:
- 堆排序使用堆来选数,效率就高了很多。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
复杂度(空间/时间):
堆排序的时间复杂度为O(nlogn),其中n是待排序序列的长度。
- 建立最大堆的过程需要进行(n/2)次向下调整操作,每次调整的时间复杂度是O(logn),所以 建立最大堆的过程需要进行(n/2)次向下调整操作,每次调整的时间复杂度是O(logn),所以建立最大堆的时间复杂度是O(nlogn/2),即简化为O(nlogn)。
- 接下来,需要进行n-1次交换和调整堆的操作。每次交换后需要向下调整堆,调整的时间复杂度为O(logn)。所以这部分的时间复杂度也是O(nlogn)。
- 综上所述,堆排序的时间复杂度为O(nlogn)。
堆排序的空间复杂度为O(1),因为它只需要使用常数级别的额外空间进行排序操作,不需要额外开辟存储空间。
交换排序
基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
1.冒泡排序: 时间复杂度O(N^2)/空间复杂度O(1)
冒泡排序是一种简单而直观的排序算法。它重复地比较相邻的两个元素,并将它们交换位置,直到整个序列按照从小到大(或从大到小)的顺序排列。
冒泡排序的基本思想是通过不断地交换相邻元素的位置,将最大(或最小)的元素逐渐“冒泡”到序列的末尾。在每一轮的比较过程中,如果发现相邻元素的顺序错误,就将它们交换位置。这样,经过多轮的比较和交换,最终整个序列就会排序完成。
算法实现:
//冒泡排序 时间复杂度O(N^2),最坏情况还为O(N^2)
//对比插入排序哪个更好?--接近有序或局部有序时,插入排序能更好适应
void Bubblesort(int* a, int n)
{assert(a);for (int j = 0; j < n; j++){int exchange = 0;for (int i = 0; i < n - j; i++){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}
测试:
void TestBubbleSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);Bubblesort(a, sz);PrintArry(a, sz);
}
冒泡排序的特性总结:
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
复杂度(空间/时间):
冒泡排序的时间复杂度是O(n2),其中n表示待排序序列的长度。这是因为冒泡排序在最坏的情况下需要进行n-1轮的比较和交换操作,每一轮需要比较n-i次,其中i为当前轮数。因此,总的比较次数为(n-1)+(n-2)+…+1,等于(n2 - n)/2,即O(n2)。
冒泡排序的空间复杂度是O(1),因为它只需要使用常量级的额外空间来存储临时变量和进行元素交换
2.快速排序
快速排序是一种排序算法,它通过不断地将序列分割成较小的部分并进行递归排序,最终实现整个序列的排序。它的核心思想是通过选择基准元素,并将比基准小的元素放在左边,比基准大的元素放在右边,然后对左右两个子序列进行递归排序。最终,所有子序列排序完成后,整个序列就有序了。
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序
元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有
元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所
有元素都排列在相应位置上为止。
三种方法:
- hoare版本
- 挖坑法 相比hoare本质上并没有简化复杂度
- 前后指针法
2.1. hoare版本 时间复杂度为O(n)/空间复杂度为O(1)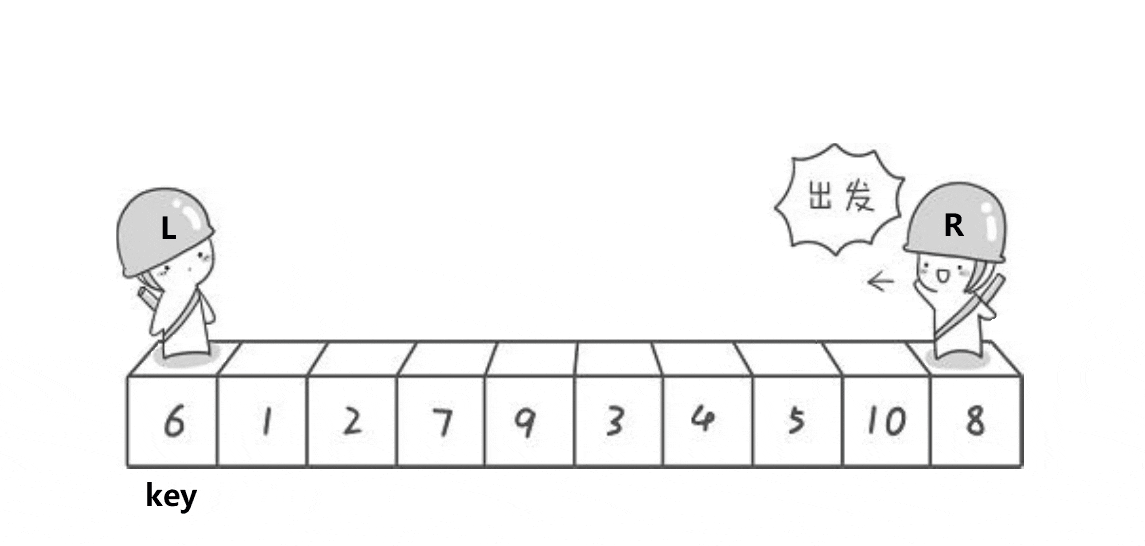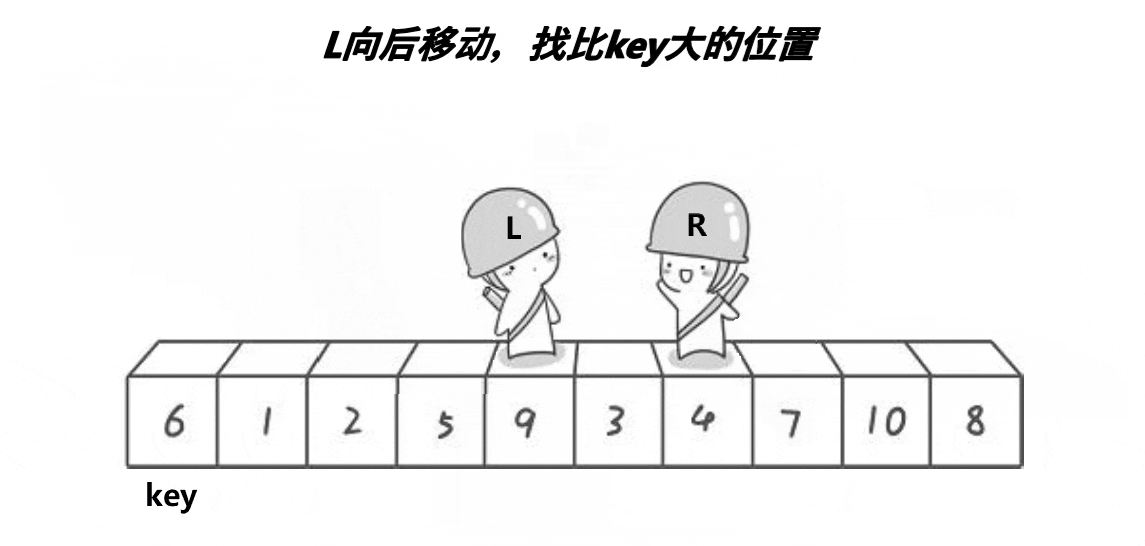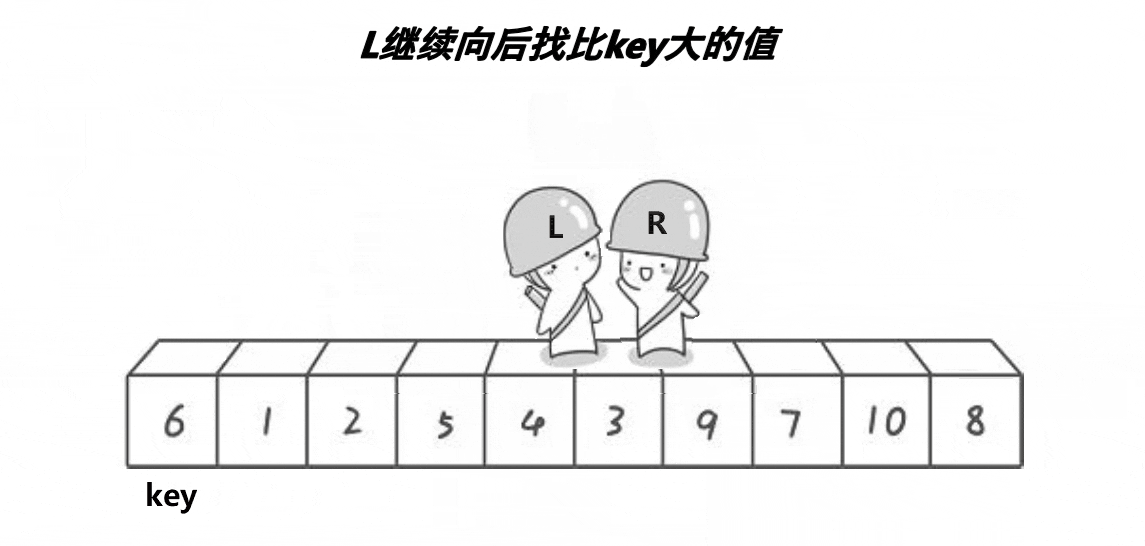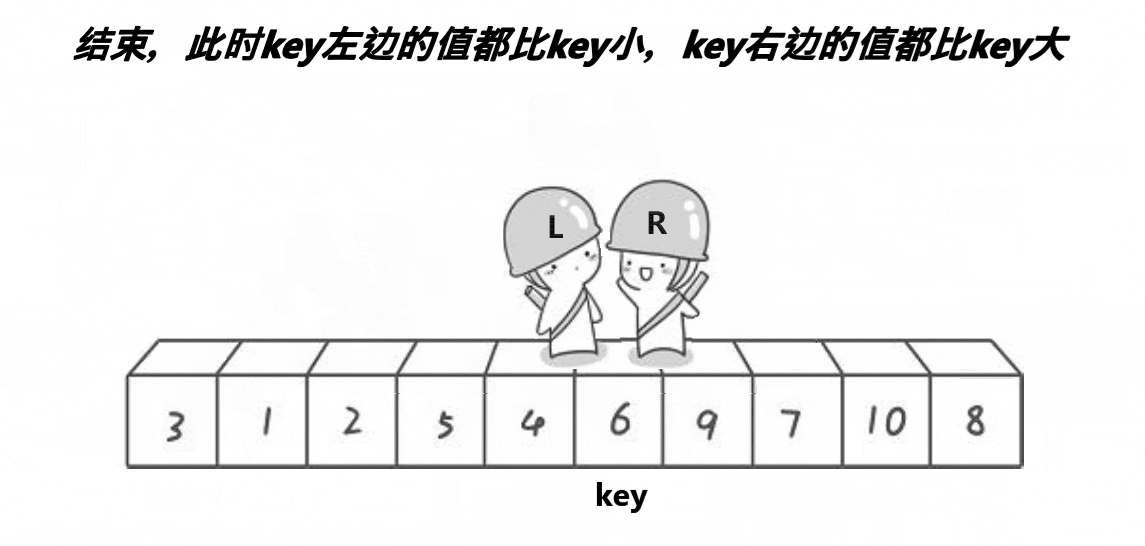
int PartSort1(int* a, int begin, int end)
{// 区间不存在,或者只有一个值则不需要再处理if (begin >= end)return; // 返回值类型应该是void,不需要返回具体的值int left = begin, right = end;int keyi = left; // 取begin作为基准元素的下标while (left < right){// 右边先走,找小while (left < right && a[right] >= a[keyi])--right;// 左边再走,找大while (left < right && a[left] <= a[keyi])++left;Swap(&a[left], &a[right]); // 交换左右指针所指向的元素}Swap(&a[keyi], &a[left]); // 将基准元素放到正确的位置上keyi = left; // 更新基准元素的下标return keyi; // 返回基准元素的下标
}
2.2. 挖坑法 相比hoare本质上并没有简化复杂度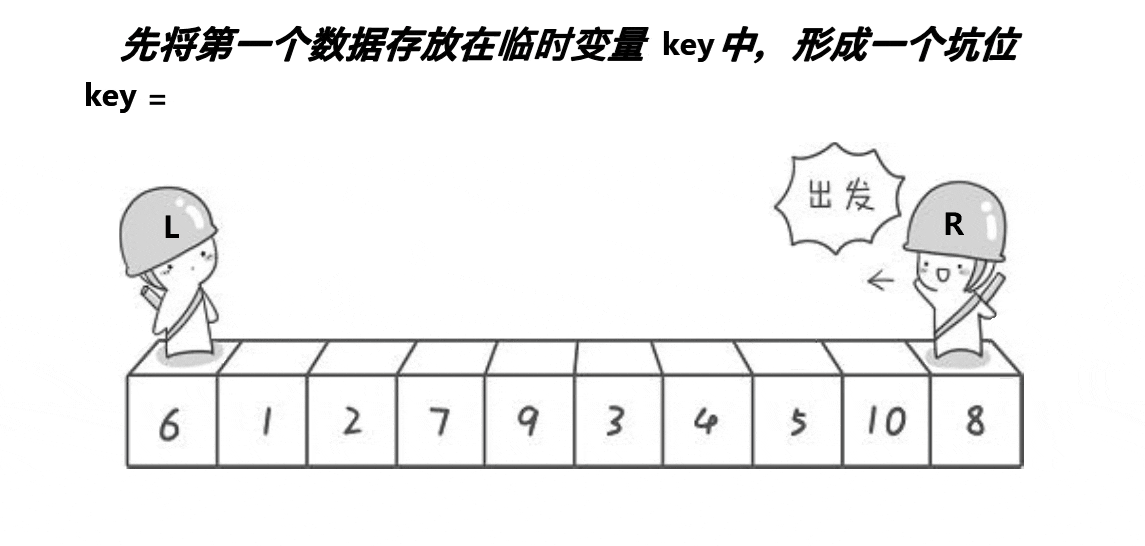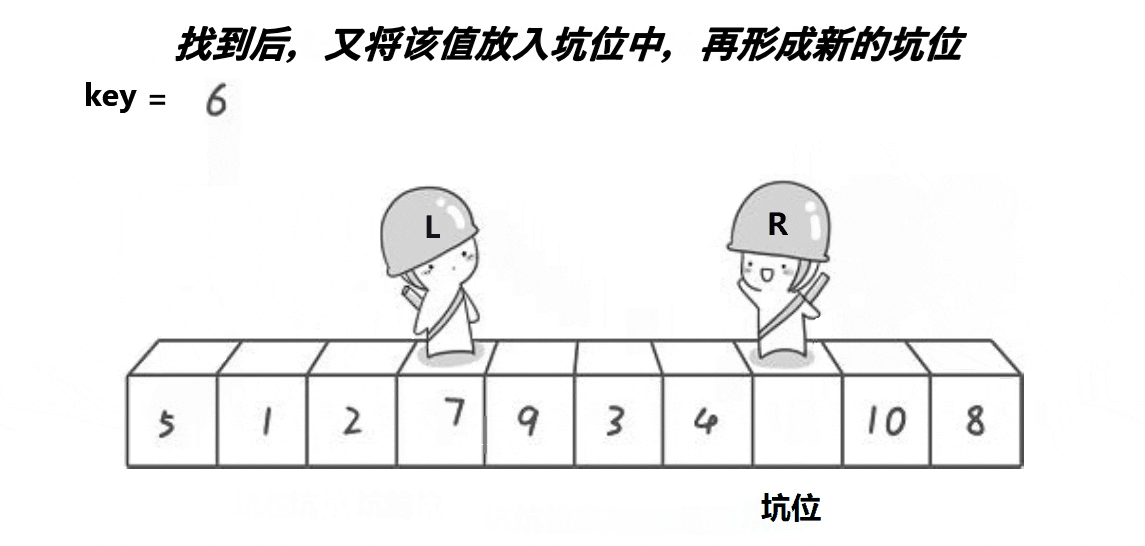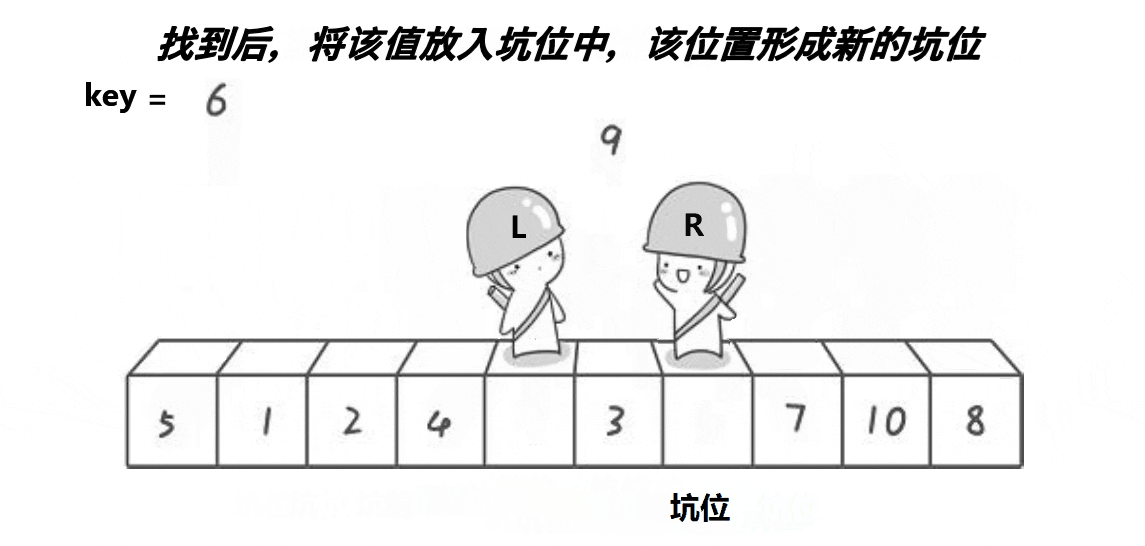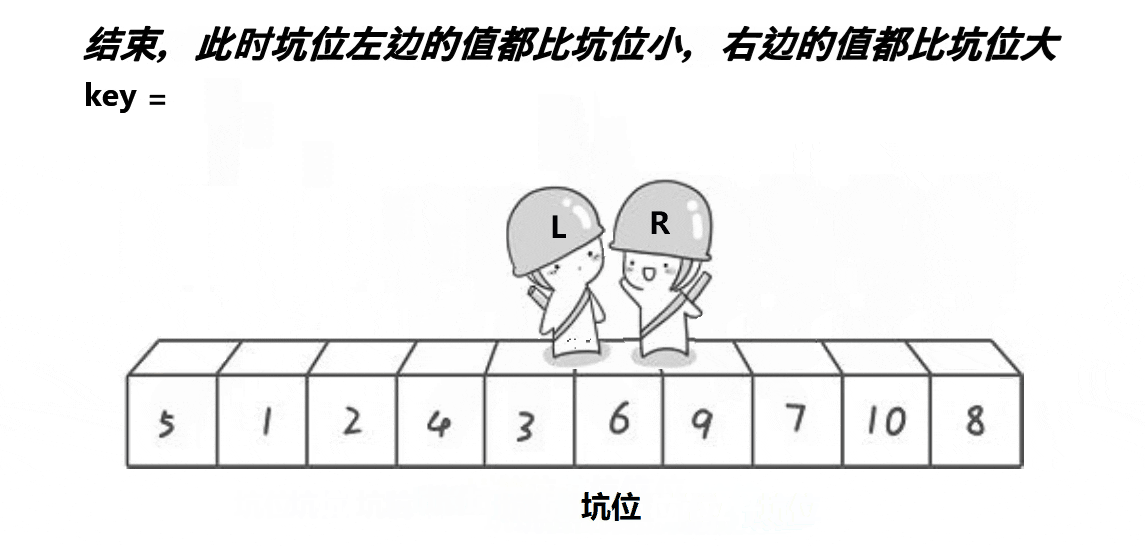
int PartSort2(int* a, int begin, int end)
{int key = a[begin]; // 选择第一个元素为基准值int piti = begin; // 初始化挖坑位置while (begin < end){// 右边找小,填到左边的坑里面去。这个位置形成新的坑while (begin < end && a[end] >= key) // 从右边开始找比基准值小的元素--end;a[piti] = a[end]; // 将小元素填入左边的坑里piti = end; // 更新当前坑的位置// 左边找大,填到右边的坑里面去。这个位置形成新的坑while (begin < end && a[begin] <= key) // 从左边开始找比基准值大的元素++begin;a[piti] = a[begin]; // 将大元素填入右边的坑里piti = begin; // 更新当前坑的位置}a[piti] = key; // 将基准值放入最后形成的坑中return piti; // 返回基准值的最终位置
2.3. 前后指针法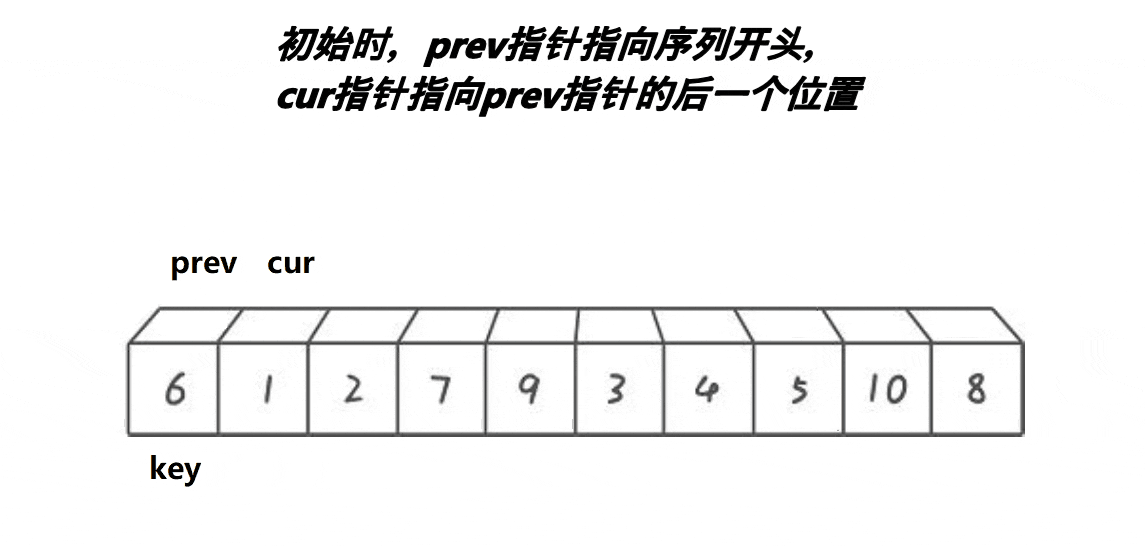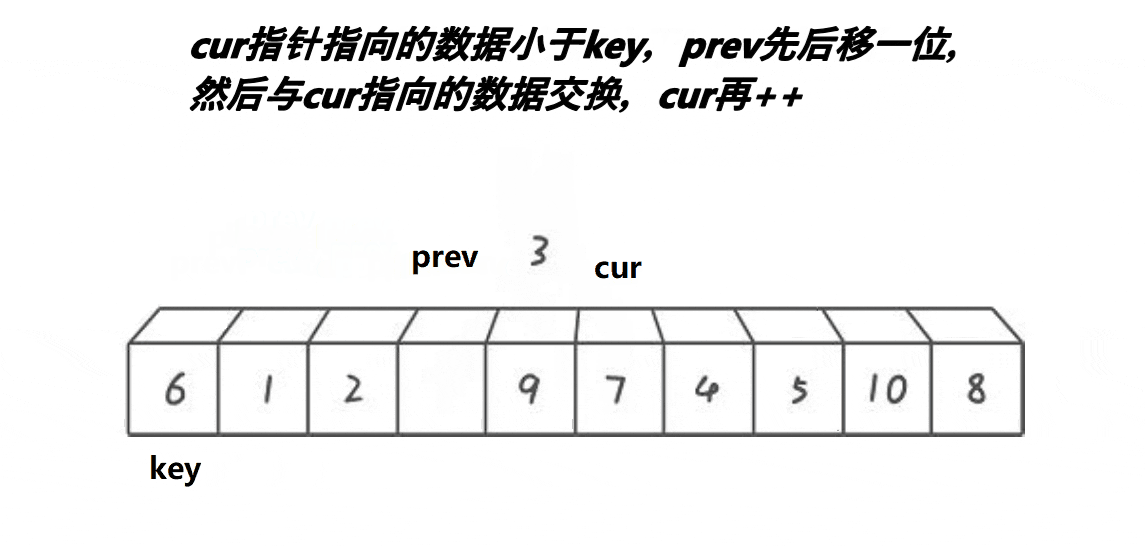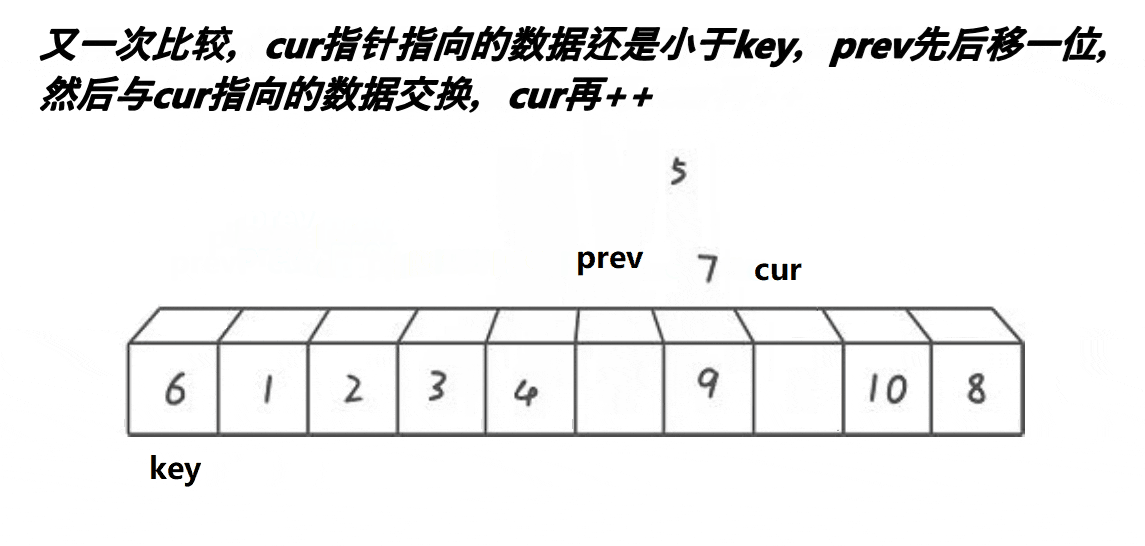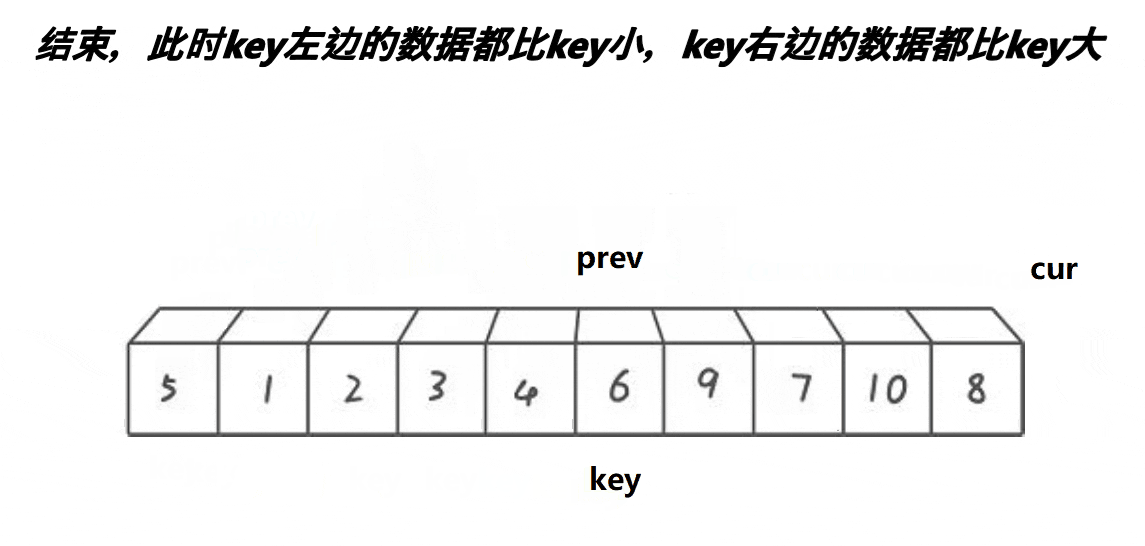
key非常影响效率:
- 当key每次选的都为该数组从小到大的中间值,每次排序为二分,效率更高但当key选的为最 小/大 时为最坏情况 每次递归都是将key后面的数进行递归:N-1+N-2…=O(N^2),且会出现栈溢出
解决方法:
- 1.随机选key(但存在巧合)
- 2.三数取中(头中尾三个数对比选其中一个中间值)
- 小区间优化:在每次递归都接近二分基础上(例:有10个数,最后一层要递归13次)减小最后一层递归,当区间较小时就不 在递归去分化去排序这个小区间,可以考虑用其他排序对小区建处理(插入排序)
2.4三数取中:
// 计算中间索引值
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2; // 计算数组中间的索引if (a[begin] < a[mid]){if (a[mid] < a[end]) // 中间值在 begin 和 end 之间return mid;else if (a[begin] < a[end]) // 中间值在 begin 和 mid 之间return end;else // 中间值在 end 和 begin 之间return begin;}else // a[begin] > a[mid]{if (a[mid] > a[end]) // 中间值在 begin 和 end 之间return mid;else if (a[begin] < a[end]) // 中间值在 begin 和 mid 之间return begin;else // 中间值在 end 和 begin 之间return end;}
}
// 前后指针法进行分割
int PartSort3(int* a, int begin, int end)
{int prev = begin; // 前指针int cur = begin + 1; // 后指针int keyi = begin; // 基准值索引int midi = GetMidIndex(a, begin, end); // 获取中间索引Swap(&a[begin], &a[midi]); // 将中间值与第一个元素交换while (cur <= end){// 当后指针位置的值小于基准值时,前指针向前移动一位,并交换前指针和后指针位置的元素if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur; // 后指针移动到下一个位置}Swap(&a[prev], &a[keyi]); // 将基准值放入合适的位置keyi = prev; // 更新基准值的索引return keyi; // 返回基准值的索引
}
2.5快排主体 &&小区间优化
头文件中定义:
//直接定义 int callCount=0; 在Sort.和Heap.c 在编译的链接过程中产生冲突,导致输出callCount时会出现错误输出
// static int callCount=0; 为仅该文件可用,错误
//extern : 声明变量
extern int callCount;//快排执行次数
快排主体 &&小区间优化
小区间优化:在每次递归都接近二分基础上(例:有10个数,最后一层要递归13次)减小最后一层递归,当区间较小时就不 在递归去分化去排序这个小区间,可以考虑用其他排序对小区建处理(插入排序)
假设递归深度为h->最后一层的调用次数为2(h-1),倒数第二层为2(h-2)…总调用次数为2h -1
若区间不再调用最后一层,总调用次数大约会减少50%。(最后一层越50%,倒二层25%,倒三层12.5%)
假设区间小于10时,不再递归区间->减少80%以上递归次数
void QuickSort(int* a, int begin, int end)
{callCount++;//区间不存在,或者只有一个值则不需要再处理if (begin >= end)return;if (end - begin > 10){//单趟排序int keyi = PartSort3(a, begin, end);//区间: [begin,keyi-1] keyi [keyi+1,right]QuickSort(a, begin, keyi - 1);//左区间QuickSort(a, keyi + 1, end);//右区间}else{//小区间优化InsertSort(a + begin, end - begin + 1); //目前QuickSort为左右闭区间故+1}
}
测试:
void TestQuickSortNonRSort()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);QuickSortNonR(a, 0, sz - 1);PrintArry(a, sz);
}
用插入排序优化的具体原因:
选择插入排序作为小区间优化的方法可以提高性能,并且不会影响整体排序的准确性。当待排序的区间较小时,快速排序使用插入排序进行优化,以获得更好的排序效果和执行效率。
- 相对较小的数据规模:当待排序的小区间长度较小时,插入排序的性能通常比快速排序更好。插入排序的时间复杂度为 O(n^2),但在小规模数据上的操作是高效的。因为插入排序是一种稳定的排序算法,它的元素交换操作相对较少,适用于小规模的数据排序。
- 递归调用开销较小:快速排序的核心是递归地对子区间排序,并且递归调用的开销会随着区间大小的增加而增加。对于小区间,递归调用可能会产生不必要的开销。而插入排序是一种原地排序算法,不需要额外的递归调用,因此在小区间上的排序效果更好。
- 算法实现的简洁性和可读性:插入排序的实现非常简单,只需要对小区间内的元素进行遍历和比较,然后逐步插入到正确的位置。它的代码逻辑简单清晰,易于理解和维护。
复杂度(空间/时间):
时间复杂度:
- 最好情况下,当每次选取的基准值都能均匀地将待排序序列划分为相等的两部分时,快速排序的时间复杂度为 O(nlogn)。
- 最坏情况下,当每次选取的基准值都为当前序列的最小值或最大值时,快速排序的时间复杂度为 O(n^2)。
- 平均情况下,快速排序的时间复杂度为 O(nlogn)。
空间复杂度:
-
快速排序是一种原地排序算法,不需要额外的空间来存储待排序序列,因此空间复杂度为 O(1)。
-
小区间优化部分使用了插入排序算法来处理较小规模的区间,在该部分中,插入排序的时间复杂度为 O(k^2),其中 k 表示小规模区间的长度。
综上所述,该排序算法的时间复杂度为 O(nlogn),空间复杂度为 O(1),并通过小区间优化进一步提高了算法在处理小规模区间时的性能
将快速排序改为非递归
递归在极端问题下,递归太深,会出现栈溢出
1.直接该循环–比如斐波那契数列,归并排序
2.用数据结构栈模拟递归过程
栈:
//初始化
void StackInit(ST* ps)
{ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);//先创建4个STDataType大小的内存if (ps->a == NULL){printf("malloc fail!\n");exit(-1);}ps->top = 0;//top初始为0时,top指向的就不是栈尾元素,而是栈尾的下一个元素ps->capacity = 4;//数组的空间大小为4
}//销毁
void StackDestory(ST* ps)
{assert(ps);//判断ps是否为空,如果他为空就说明栈还没有创建,也就不用销毁free(ps->a);//释放数组a的空间ps->a = NULL;//让指针*a 指向空ps->top = ps->capacity = 0;
}//入栈
void StackPush(ST* ps, int x)
{assert(ps);//满了,得增容if (ps->top == ps->capacity)//注意:top从0开始的。并且top指向栈尾元素的下一个地址{STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);//设置tmp,申请空间成功后,将其赋给ps->a//如果直接用ps->a,申请内存失败后,ps->a就不对劲了if (tmp == NULL)//判断是否申请成功{printf("realloc fail\n");exit(-1);}else{ps->a = tmp;ps->capacity *= 2;//扩大为原来的2倍}}ps->a[ps->top] = x;ps->top++;
}//出栈
void StackPop(ST* ps)
{assert(ps);assert(ps->top > 0);//判断是否栈空ps->top--;
}//取栈顶元素(并不删除栈顶元素)
STDataType StackTop(ST* ps)
{assert(ps);assert(ps->top > 0);//判断是否栈空return ps->a[ps->top - 1];
}//求栈中元素个数
int StackSize(ST* ps)
{assert(ps);return ps->top;
}//判断是否为空
bool StackEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}
非递归代码实现:
void QuickSortNonR(int* a, int begin, int end)
{ST st;StackInit(&st);//先入左再入右边,出栈时先出右再出左StackPush(&st,end);StackPush(&st,begin);while (!StackEmpty(&st))//无子区间时停止{int left = StackTop(&st);StackPop(&st);int right = StackTop(&st);StackPop(&st);int keyi = PartSort3(a, left, right);//[left,keyi-1] keyi [keyi+1,right]//左区间类递归if (left<keyi-1){StackPush(&st, keyi-1);StackPush(&st, begin);}//右区间类递归if (keyi + 1 < right){StackPush(&st, right);StackPush(&st, keyi+1);}}StackDestory(&st);
}
归并排序
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法
(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序
列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二
路归并。 归并排序核心步骤: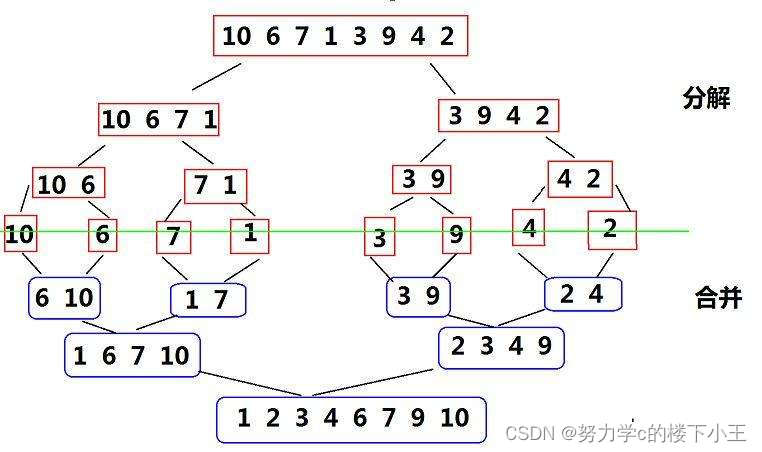
void _MergeSort(int* a, int begin, int end, int* tmp)//temp:第三方数组
{if (begin >= end)return;int mid = (begin + end) / 2;// 对左区间进行递归排序_MergeSort(a, begin, mid, tmp);// 对右区间进行递归排序_MergeSort(a, mid + 1, end, tmp);// 归并左右区间int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin1;// 将两个有序区间合并到临时数组 tmp 中while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}// 处理左区间剩余的元素while (begin1 <= end1){tmp[i++] = a[begin1++];}// 处理右区间剩余的元素while (begin2 <= end2){tmp[i++] = a[begin2++];}// 将归并结果拷贝回原数组 a 中memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}// 归并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}_MergeSort(a, 0, n - 1, tmp); // 初始调用归并排序free(tmp);
}
归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问
题。 - 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
复杂度(空间/时间):
时间复杂度:
- 最好情况下,归并排序的时间复杂度为 O(nlogn)。无论数组的初始顺序如何,归并排序总是将数组对半分割,然后合并,这个过程的时间复杂度是稳定的。
- 最坏情况下,归并排序的时间复杂度仍然是 O(nlogn)。无论数组的初始顺序如何,归并排序都需要对数组进行完全的分割和合并操作。
- 平均情况下,归并排序的时间复杂度为 O(nlogn)。归并排序将数组分割为相等大小的子数组,然后对子数组进行合并,因此平均情况下的时间复杂度和最坏情况下相同。
空间复杂度:
- 归并排序的空间复杂度为 O(n)。在归并排序的过程中,需要使用一个临时数组来存储归并操作的中间结果。临时数组的长度与待排序数组的长度相同,因此空间复杂度为 O(n)。
综上所述,这段代码的时间复杂度为 O(nlogn),空间复杂度为 O(n)。归并排序是一种稳定的、高效的排序算法,适用于各种规模的数据集。
归并排序非递归实现
两种实现方法:
- 方法一 :修正边界法
- 方法二: 越界只有可能在[begin2,end2] end1,最后一组越界时停止递归而对end1进行修正(建立在方法一基础之上进行更改)
主体:
void MergeSortNonR(int* a, int n)
{_MergeSortNonR2(a, n);//方法一_MergeSortNonR2(a, n);//方法二
}
主函数错误写法:
改写法没考虑边界问题,会导致越界从而报错
若选择直接修正begin2即,不进行类递归: 这将导致该数组begin2照样会越界且最后进行memcpy时末尾元素可能会出现随机值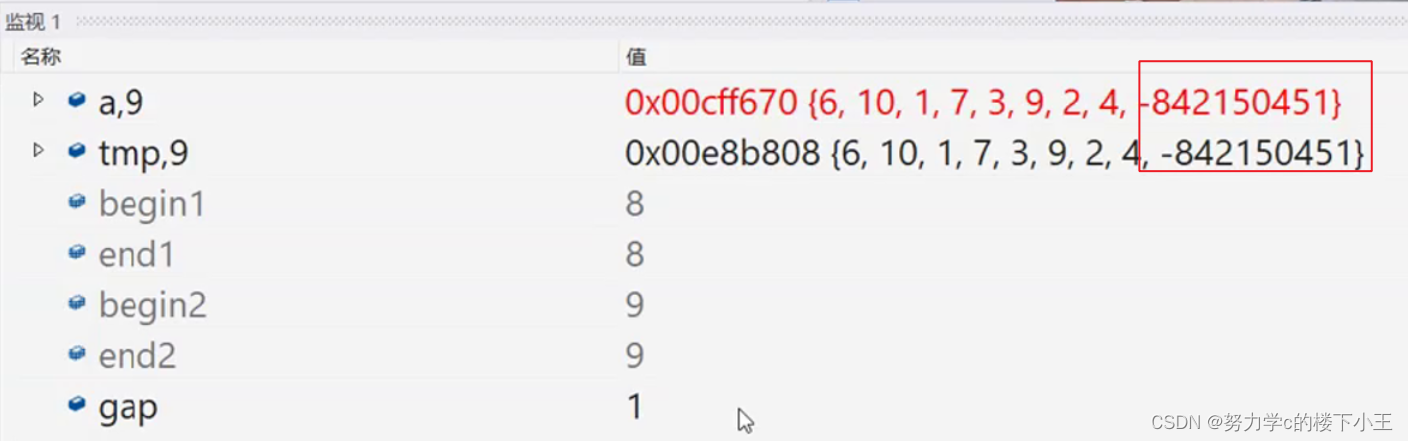
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n){printf("gap->%d", gap);for (int i = 0; i < n; i += 2 * gap){//[imi+gap-1][i+gap,i+2*gap-1] //此时数组长度不为2的次方就会出现越界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//修正边界(阻止越界) /*若选择直接修正begin2即,不进行类递归:if (begin2>=2)break;这将导致该数组begin2照样会越界且最后进行memcpy时末尾元素可能会出现随机值*/if (end1 >= n)//end1越界{end1 = n - 1;/*修正end1后,将begin2和end2修正为一个不存在的区间再用if语句进行判断是否越界若是直接退出该次类递归*///[begin2,end2]begin2 = n;end2 = n - 1;}else if (begin2 >= n){begin2 = n;end2 = n - 1;}else if (end2 >= n)end2 = n - 1;printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];}printf("\n");memcpy(a, tmp, n * sizeof(int));gap *= 2;}free(tmp);
}
方法一 :修正边界法
void _MergeSortNonR1(int* a, int n)
{// 分配临时数组 tmpint* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n) // 在 gap 小于数组长度时执行循环{printf("gap->%d", gap);for (int i = 0; i < n; i += 2 * gap) // 对数组进行多趟归并{// 获取当前归并的两个子区间的边界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 修正边界,防止越界if (end1 >= n) // end1 越界,修正为数组最后一个元素的索引{end1 = n - 1;// 修正 begin2 和 end2,将它们修正为不存在的区间begin2 = n;end2 = n - 1;}else if (begin2 >= n) // begin2 越界,修正为数组最后一个元素的索引加 1{begin2 = n;end2 = n - 1;}else if (end2 >= n) // end2 越界,修正为数组最后一个元素的索引end2 = n - 1;printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);// 将两个有序区间合并到临时数组 tmp 中int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}// 处理左区间剩余的元素while (begin1 <= end1)tmp[j++] = a[begin1++];// 处理右区间剩余的元素while (begin2 <= end2)tmp[j++] = a[begin2++];}printf("\n");// 将归并结果拷贝回原数组 amemcpy(a, tmp, n * sizeof(int));// 调整 gap 的大小,以进行下一轮归并操作gap *= 2;}free(tmp); // 释放临时数组的内存空间
}
方法二 :
越界只有可能在[begin2,end2] end1,最后一组越界时停止递归而对end1进行修正
void _MergeSortNonR2(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n) // 在 gap 小于数组长度时执行循环{printf("gap->%d ", gap);for (int i = 0; i < n; i += 2 * gap) // 对数组进行多趟归并{// 获取当前归并的两个子区间的边界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;// 如果 end1 越界或 begin2 越界,则可以不执行归并操作了if (end1 >= n || begin2 >= n)break;else if (end2 >= n)end2 = n - 1;//printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);int m = end2 - begin1 + 1; // 计算归并元素的个数int j = begin1;// 将两个有序子区间合并到临时数组 tmp 中while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}// 处理左区间剩余的元素while (begin1 <= end1)tmp[j++] = a[begin1++];// 处理右区间剩余的元素while (begin2 <= end2)tmp[j++] = a[begin2++];// 将归并结果从临时数组 tmp 拷贝回原数组 amemcpy(a + i, tmp + i, sizeof(int) * m);}// 调整 gap 的大小,将其扩大两倍,以进行下一轮归并操作gap *= 2;}free(tmp); // 释放临时数组的内存空间
}
测试:
void TestMergeSortNonR()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);MergeSortNonR(a, sz);PrintArry(a, sz);
}
![]()
全部功能测试
test.c:
调试时最好切换为Release版本,否则可能导致计算效率不是很准确
void TestOP()
{srand(time(0));const int N = 10000;//可自行更改,但部分排序算法效率太低可能运行时间会很久int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();//Bubblesort(a7, N);int end7 = clock();printf("直接插入排序InsertSort:%d\n", end1 - begin1);printf("希尔排序ShellSort:%d\n", end2 - begin2);printf("选择排序SelectSort:%d\n", end3 - begin3);printf("堆排序HeapSort:%d\n", end4 - begin4);//printf("冒泡排序Bubblesort:%d\n", end7 - begin7);printf("快速排序QuickSort:%d\n", end5 - begin5);printf("归并排序MergeSort:%d\n", end6 - begin6);printf("callCount:%d\n", callCount);printf("%p\n", &callCount);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);//free(a7);
}int main()
{TestOP();
}
全部代码
将展现书写本文的所有代码以供参考
头文件
1.Sort.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <time.h>
#include <string.h>void PrintArry(int* a, int n);//直接插入排序
void InsertSort(int* a, int n);//希尔排序
void ShellSort(int* a, int n);//选择排序
void SelectSort(int* a, int n);void Swap(int* p1, int* p2);void AdjustDown(int* a, int size, int parent);//堆排序
void HeapSort(int* a, int n);//冒泡排序
void Bubblesort(int* a, int n);//快速排序
void QuickSort(int* a, int begin, int end);
//直接定义 int callCount=0; 在Sort.和Heap.c 在编译的链接过程中产生冲突,导致输出callCount时会出现错误输出
// static int callCount=0; 为仅该文件可用,错误
//extern : 声明变量
extern int callCount;//快排执行次数//将快速排序改为非递归
void QuickSortNonR(int* a, int begin, int end);//归并排序
void MergeSort(int* a, int n);//非递归 归并排序
void MergeSortNonR(int* a, int n);2.Stack.h
#pragma once
#include<stdio.h>
#include<stdbool.h>
#include<stdlib.h>
#include<assert.h>typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;//初始化
void StackInit(ST* ps);//销毁
void StackDestory(ST* ps);//入栈
void StackPush(ST* ps, int x);//出栈
void StackPop(ST* ps);//取栈顶元素(并不删除栈顶元素)
STDataType StackTop(ST* ps);//求栈中元素个数
int StackSize(ST* ps);//判断是否为空
bool StackEmpty(ST* ps);
函数实现文件
1.Sort.c
#include "Sort.h"
#include "Stack.h"void PrintArry(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ",a[i]);printf("\n");
}//直接插入排序
//1,直接插入排序(单趟排序) 一个数一次向后比较一个元素,当比该数字小时,后面元素后移,后插入该数
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){// [0,end]有序,吧end+1 位置的值插入,保持有序int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end])//要交换的数字更大{//指针指向元素后移,end指针前移a[end + 1] = a[end];--end;}else{//要交换的数字更小,退出循环break;}}//开始交换a[end + 1] = tmp;}
}//希尔排序
/*1,预排序(接近顺序有序)2,直接插入排序(有序)
*/
//void ShellSort(int* a, int n)
//{
// int gap = 3;
// //gap组交替进行排序
// /*
// gap越大大的数更快到后面,小的数可以更快到前面
// 排升序,gap越小,越接近有序,当gap==1,就是插入排序
// */
// for (int i = 0; i < n-gap; i++)
// {
// int end = i;
// int tmp = a[end + gap];
//
// while (end >= 0)
// {
// if (tmp < a[end])
// {
// //排序
// a[end + gap] = a[end];
// end -= gap;
// }
// else
// break;
// }
// a[end + gap] = tmp;
// }//for (int j = 0; j < gap; j++)//往前走一位,gap另一部分//{// for (int i = 0; i < n - gap; i += gap)// {// int end = i;// int tmp = a[end + gap];// while (end >= 0)// {// if (tmp < a[end])// {// //排序// a[end + gap] = a[end];// end -= gap;// }// else// break;// }// a[end + gap] = tmp;// }//}
//}void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;// /3:保证每次跳跃的间隔. 1:保证不为0//gap组交替进行排序/*gap越大大的数更快到后面,小的数可以更快到前面排升序,gap越小,越接近有序,当gap==1,就是插入排序*/for (int i = 0; i < n - gap; i++)//往前走一位,gap另一部分 {int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){//排序a[end + gap] = a[end];end -= gap;}elsebreak;}a[end + gap] = tmp;}}
}//选择排序 o(N^2)
//对比插入排序,还是插入排序更优
void SelectSort(int* a, int n)
{assert(a);//遍历一遍选出最小and最大的,分别放在左右边int begin = 0, end = n - 1;int mini = begin, maxi = begin;while (begin<end){for (int i = 0; i <= end; i++){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}Swap(&a[begin], &a[mini]);//如果begin和maxi重叠,那么需要修正位置if (begin == maxi)maxi = mini;Swap(&a[end], &a[maxi]);++begin;--end;}
} //冒泡排序 时间复杂度O(N^2),最坏情况还为O(N^2)
//对比插入排序哪个更好?--接近有序或局部有序时,插入排序能更好适应
void Bubblesort(int* a, int n)
{assert(a);for (int j = 0; j < n; j++){int exchange = 0;for (int i = 0; i < n - j; i++){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0)break;}
}void _MergeSort(int* a, int begin, int end,int* tmp)//temp:第三方数组
{if (begin >= end)return;int mid=(begin + end) / 2;//[begin,mid][mid+1,end]分值递归,让子区间有序_MergeSort(a, begin, mid, tmp); // 递归 左区间_MergeSort(a, mid + 1, end, tmp);//递归 右边区间//归并[begin,mid][mid+1,end]int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin1;while (begin1<=end1 && begin2<=end2){if (a[begin1]< a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1<=end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//把归并拷贝回原数组memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}//归并排序
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}_MergeSort(a, 0, n - 1, tmp);free(tmp);
}非递归 归并排序
//void MergeSortNonR(int* a, int n)
//{
// int* tmp = (int*)malloc(sizeof(int) * n);
// if (tmp == NULL)
// {
// printf("malloc fail\n");
// exit(-1);
// }
// int gap = 1;
// while (gap<n)
// {
// printf("gap->%d",gap);
// for (int i = 0; i < n; i += 2 * gap)
// {
// //[imi+gap-1][i+gap,i+2*gap-1] //此时数组长度不为2的次方就会出现越界
// int begin1 = i, end1 = i + gap - 1;
// int begin2 = i + gap, end2 = i + 2 * gap - 1;
// printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);
//
// int j = begin1;
// while (begin1 <= end1 && begin2 <= end2)
// {
// if (a[begin1] < a[begin2])
// {
// tmp[j++] = a[begin1++];
// }
// else
// {
// tmp[j++] = a[begin2++];
// }
// }
// while (begin1 <= end1)
// {
// tmp[j++] = a[begin1++];
//
// }
//
// while (begin2 <= end2)
// {
// tmp[j++] = a[begin2++];
// }
// }
// printf("\n");
// memcpy(a, tmp, n * sizeof(int));
// gap *= 2;
// }
// free(tmp);
//}
//非递归 归并排序
/* end1 begin2 end2 皆有可能出现越界故应该修正边界
*///方法一 修正边界法
void _MergeSortNonR1(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n){printf("gap->%d", gap);for (int i = 0; i < n; i += 2 * gap){//[imi+gap-1][i+gap,i+2*gap-1] //此时数组长度不为2的次方就会出现越界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//修正边界(阻止越界) /*若选择直接修正begin2即,不进行类递归:if (begin2>=2)break;这将导致该数组begin2照样会越界且最后进行memcpy时末尾元素可能会出现随机值*/if (end1 >= n)//end1越界{end1 = n - 1;/*修正end1后,将begin2和end2修正为一个不存在的区间再用if语句进行判断是否越界若是直接退出该次类递归*///[begin2,end2]begin2 = n;end2 = n - 1;}else if (begin2 >= n){begin2 = n;end2 = n - 1;}else if (end2 >= n)end2 = n - 1;printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];}printf("\n");memcpy(a, tmp, n * sizeof(int));gap *= 2;}free(tmp);
}//方法二 越界只有可能在[begin2,end2] end1,最后一组越界时停止递归而对end1进行修正
void _MergeSortNonR2(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n){printf("gap->%d ", gap);for (int i = 0; i < n; i += 2 * gap){//[imi+gap-1][i+gap,i+2*gap-1] //此时数组长度不为2的次方就会出现越界int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//end1越界或begin2越界。则可以不归并了if (end1 >= n || begin2 >= n)break;else if (end2 >= n)end2 = n - 1;//printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);int m = end2 - begin1+1;//元素个数int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];//每类递归依次,进行一次拷贝 memcpy(a + i, tmp + i, sizeof(int) * m);}gap *= 2;}free(tmp);
}void MergeSortNonR(int* a, int n)
{_MergeSortNonR2(a, n);
}//void MergeSortNonR(int* a, int n)
//{
// int* tmp = (int*)malloc(sizeof(int) * n);
// if (tmp == NULL)
// {
// printf("malloc fail\n");
// exit(-1);
// }
//
// int gap = 1;
// while (gap < n)
// {
// printf("gap->%d", gap);
// for (int i = 0; i < n; i += 2 * gap)
// {
// //[imi+gap-1][i+gap,i+2*gap-1] //此时数组长度不为2的次方就会出现越界
// int begin1 = i, end1 = i + gap - 1;
// int begin2 = i + gap, end2 = i + 2 * gap - 1;
//
// //修正边界(阻止越界)
// /*
// 若选择直接修正begin2即,不进行类递归:
// if (begin2>=2)
// break;
// 这将导致该数组begin2照样会越界且最后进行memcpy时末尾元素可能会出现随机值
// */
// if (end1 >= n)//end1越界
// {
// end1 = n - 1;
// /*
// 修正end1后,将begin2和end2修正为一个不存在的区间
// 再用if语句进行判断是否越界若是直接退出该次类递归
// */
// //[begin2,end2]
// begin2 = n;
// end2 = n - 1;
// }
// else if (begin2 >= n)
// {
// begin2 = n;
// end2 = n - 1;
// }
// else if (end2 >= n)
// end2 = n - 1;
//
// printf("[%d,%d] [%d,%d]--", begin1, end1, begin2, end2);
//
// int j = begin1;
// while (begin1 <= end1 && begin2 <= end2)
// {
// if (a[begin1] < a[begin2])
// tmp[j++] = a[begin1++];
// else
// tmp[j++] = a[begin2++];
// }
//
// while (begin1 <= end1)
// tmp[j++] = a[begin1++];
//
// while (begin2 <= end2)
// tmp[j++] = a[begin2++];
// }
// printf("\n");
// memcpy(a, tmp, n * sizeof(int));
// gap *= 2;
// }
// free(tmp);
//}
2.QuickSort.c
#include "Sort.h"
#include "Stack.h"//调试时最好切换为Release版本//快速排序//进行声明并初始化 ,此时当前文件callCount 与Sort.h中的为同一变量
int callCount = 0;//1,hoare版本
int PartSort1(int* a, int begin, int end)
{//区间不存在,或者只有一个值则不需要再处理if (begin >= end)return;int left = begin, right = end;int keyi = left;while (left < right){//右边先走,找小while (left < right && a[right] >= a[keyi])--right;// 左边再走,找大while (left < right && a[left] <= a[keyi])++left;Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);keyi = left;return keyi;
}//2,挖坑法 相比hoare本质上并没有简化复杂度
int PartSort2(int* a, int begin, int end)
{int key = a[begin]; // 选择第一个元素为基准值int piti = begin; // 初始化挖坑位置while (begin < end){// 右边找小,填到左边的坑里面去。这个位置形成新的坑while (begin < end && a[end] >= key) // 从右边开始找比基准值小的元素--end;a[piti] = a[end]; // 将小元素填入左边的坑里piti = end; // 更新当前坑的位置// 左边找大,填到右边的坑里面去。这个位置形成新的坑while (begin < end && a[begin] <= key) // 从左边开始找比基准值大的元素++begin;a[piti] = a[begin]; // 将大元素填入右边的坑里piti = begin; // 更新当前坑的位置}a[piti] = key; // 将基准值放入最后形成的坑中return piti; // 返回基准值的最终位置
}//计算中间值
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end])return mid;else if (a[begin] < a[end])return end;elsereturn begin;}else //a[begin]>a[mid]{if (a[mid] > a[end])return mid;else if (a[begin] < a[end])return begin;elsereturn end;}
}//前后指针法
int PartSort3(int* a, int begin, int end)
{int prev = begin;int cur = begin + 1;int keyi = begin;int midi = GetMidIndex(a, begin, end);Swap(&a[begin], &a[midi]);while (cur<=end){//cur位置的值小于keyi位置的值if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}
/*key非常影响效率:1.当key每次选的都为该数组从小到大的中间值,每次排序为二分,效率更高但当key选的为最 小/大 时为最坏情况 每次递归都是将key后面的数进行递归:N-1+N-2...=O(N^2),且会出现栈溢出解决方法:1.随机选key(但存在巧合)2,三数取中(头中尾三个数对比选其中一个中间值)2.小区间优化:在每次递归都接近二分基础上(例:有10个数,最后一层要递归13次)减小最后一层递归,当区间较小时就不在递归去分化去排序这个小区间,可以考虑用其他排序对小区建处理(插入排序)假设递归深度为h->最后一层的调用次数为2^(h-1),倒数第二层为2^(h-2)...总调用次数为2^h - 1若区间不再调用最后一层,总调用次数大约会减少50%。(最后一层越50%,倒二层25%,倒三层12.5%)假设区间小于10时,不再递归区间->减少80%以上递归次数
*/void QuickSort(int* a, int begin, int end)
{callCount++;//区间不存在,或者只有一个值则不需要再处理if (begin >= end)return;if (end - begin > 10){//单趟排序int keyi = PartSort3(a, begin, end);//区间: [begin,keyi-1] keyi [keyi+1,right]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{//小区间优化InsertSort(a + begin, end - begin + 1); //目前QuickSort为左右闭区间故+1}
}//将快速排序改为非递归 ->递归在极端问题下,递归太深,会出现栈溢出
//1.直接该循环--比如斐波那契数列,归并排序
//2.用数据结构栈模拟递归过程
void QuickSortNonR(int* a, int begin, int end)
{ST st;StackInit(&st);//先入左再入右边,出栈时先出右再出左StackPush(&st,end);StackPush(&st,begin);while (!StackEmpty(&st))//无子区间时停止{int left = StackTop(&st);StackPop(&st);int right = StackTop(&st);StackPop(&st);int keyi = PartSort3(a, left, right);//[left,keyi-1] keyi [keyi+1,right]//左区间类递归if (left<keyi-1){StackPush(&st, keyi-1);StackPush(&st, begin);}//右区间类递归if (keyi + 1 < right){StackPush(&st, right);StackPush(&st, keyi+1);}}StackDestory(&st);
}
3.Heap.c
#include "Sort.h"//向下调整
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){if (child + 1 < size && a[child + 1] > a[child])++child;//跟孩子父亲比较if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{//左右孩子都大于/小于父亲,结束交换break;}}
}//堆排序
void HeapSort(int* a, int n)
{//时间复杂度:O(N)for (int i = (n - 1) / 2; i >= 0; i--)AdjustDown(a, n, i);int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}4.Stack.c
#include "Stack.h"//初始化
void StackInit(ST* ps)
{ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);//先创建4个STDataType大小的内存if (ps->a == NULL){printf("malloc fail!\n");exit(-1);}ps->top = 0;//top初始为0时,top指向的就不是栈尾元素,而是栈尾的下一个元素ps->capacity = 4;//数组的空间大小为4
}//销毁
void StackDestory(ST* ps)
{assert(ps);//判断ps是否为空,如果他为空就说明栈还没有创建,也就不用销毁free(ps->a);//释放数组a的空间ps->a = NULL;//让指针*a 指向空ps->top = ps->capacity = 0;
}//入栈
void StackPush(ST* ps, int x)
{assert(ps);//满了,得增容if (ps->top == ps->capacity)//注意:top从0开始的。并且top指向栈尾元素的下一个地址{STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);//设置tmp,申请空间成功后,将其赋给ps->a//如果直接用ps->a,申请内存失败后,ps->a就不对劲了if (tmp == NULL)//判断是否申请成功{printf("realloc fail\n");exit(-1);}else{ps->a = tmp;ps->capacity *= 2;//扩大为原来的2倍}}ps->a[ps->top] = x;ps->top++;
}//出栈
void StackPop(ST* ps)
{assert(ps);assert(ps->top > 0);//判断是否栈空ps->top--;
}//取栈顶元素(并不删除栈顶元素)
STDataType StackTop(ST* ps)
{assert(ps);assert(ps->top > 0);//判断是否栈空return ps->a[ps->top - 1];
}//求栈中元素个数
int StackSize(ST* ps)
{assert(ps);return ps->top;
}//判断是否为空
bool StackEmpty(ST* ps)
{assert(ps);return ps->top == 0;
}
测试函数
test.c
#include "Sort.h"void TestOP()
{srand(time(0));const int N = 10000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();//Bubblesort(a7, N);int end7 = clock();printf("直接插入排序InsertSort:%d\n", end1 - begin1);printf("希尔排序ShellSort:%d\n", end2 - begin2);printf("选择排序SelectSort:%d\n", end3 - begin3);printf("堆排序HeapSort:%d\n", end4 - begin4);//printf("冒泡排序Bubblesort:%d\n", end7 - begin7);printf("快速排序QuickSort:%d\n", end5 - begin5);printf("归并排序MergeSort:%d\n", end6 - begin6);printf("快速排序次数callCount:%d\n", callCount);printf("%p\n", &callCount);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);//free(a7);
}void TestInsertSort()
{int a[] = { 9,1,2,5,7,4,8,6,3,5 };int sz = sizeof(a) / sizeof(a[0]);InsertSort(a, sz);PrintArry(a, sz);}
void TestShellSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);ShellSort(a, sz);PrintArry(a, sz);
}void TestSelectSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);SelectSort(a, sz);PrintArry(a, sz);
}void TestHeapSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);HeapSort(a, sz);PrintArry(a, sz);
}void TestBubbleSort()
{int a[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(a) / sizeof(a[0]);Bubblesort(a, sz);PrintArry(a, sz);
}void TestQuickSortSort()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);QuickSort(a, 0, sz-1);PrintArry(a, sz);
}void TestQuickSortNonRSort()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);QuickSortNonR(a, 0, sz - 1);PrintArry(a, sz);
}void TestMergeSortSort()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);MergeSort(a, sz);PrintArry(a, sz);}void TestMergeSortNonR()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };int sz = sizeof(a) / sizeof(a[0]);MergeSortNonR(a, sz);PrintArry(a, sz);
}int main()
{//TestInsertSort();//TestBubbleSort();//TestQuickSortSort();//TestQuickSortNonRSort();//TestHeapSort();//TestMergeSortSort();//estMergeSortNonR();TestOP();return 0;
}
本文讲解完毕啦,本文字数:4.2w。创作不易,喜欢的话留下一个免费的赞吧 ╰(°▽°)╯
感谢阅读
相关文章:

数据结构:排序- 插入排序(插入排序and希尔排序) , 选择排序(选择排序and堆排序) , 交换排序(冒泡排序and快速排序) , 归并排序
目录 前言 复杂度总结 预备代码 插入排序 1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1) 复杂度(空间/时间): 2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1) 复杂度(空间/时间&#…...

IOT 围炉札记
文章目录 一、蓝牙二、PAN1080三、IOT OS四、通讯 一、蓝牙 树莓派上的蓝牙协议 BlueZ 官网 BlueZ 官方 Linux Bluetooth 栈 oschina 二、PAN1080 pan1080 文档 三、IOT OS Zephyr 官网 Zephyr oschina Zephyr github Zephyr docs 第1章 Zephyr简介 第2章 Zephyr 编译环…...
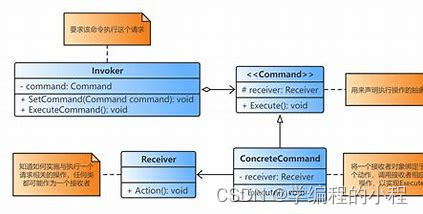
小谈设计模式(24)—命令模式
小谈设计模式(24)—命令模式 专栏介绍专栏地址专栏介绍 命令模式角色分析命令(Command)具体命令(ConcreteCommand)接收者(Receiver)调用者(Invoker)客户端&am…...
9.HTML
文章目录 1.HTML 常见标签1.1注释标签1.2标题标签: h1-h61.3段落标签: p1.4换行标签: br1.5综合案例: 展示博客1.6格式化标签1.7图片标签: img1.8超链接标签: a1.9综合案例: 展示博客21.10表格标签1.10.1基本使用1.10.2合并单元格 1.11列表标签1.12表单标签1.13无语义标签: div…...
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
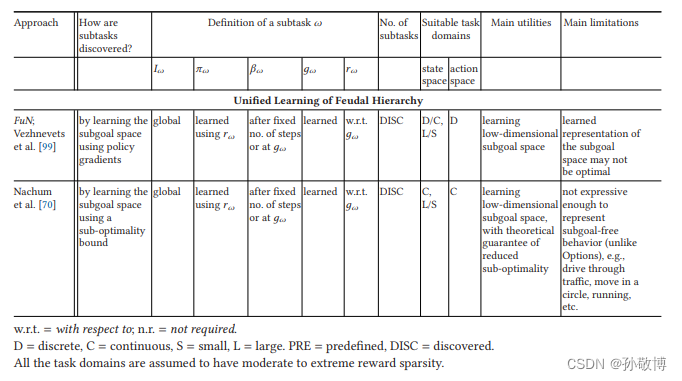
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…...
TensorFlow入门(十五、数据读取机制(2))
使用Dataset创建和读取数据集,作为TensorFlow模型创建输入管道的新方式,使用性能比使用feed_dict或队列式管道的性能高很多,使用也更加简洁容易。也是google强烈推荐的数据读取方式,对于TensorFlow而言,十分重要。 Dataset是什么? Dataset的定义 : 它是一个含有相同类型元素且…...
Linux系统中实现便捷运维管理和远程访问的1Panel部署方法
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...

Rancher清理节点
本节介绍如何从一个 Rancher 创建的 Kubernetes 集群中断开一个节点,并从该节点中删除所有 Kubernetes 组件。此过程允许您将释放节点资源,将节点用于其他用途。 当您使用 Rancher 创建集群节点 时,将创建资源(容器/虚拟网络接口)和配置项(证…...
C++-Mongoose(1)-http-server
Mongoose is a network library for C/C. It implements event-driven non-blocking APIs for TCP, UDP, HTTP, WebSocket, MQTT. mongoose很小巧,只有两个文件mongoose.h/cpp,拿来就可以用. 下载地址: https://github.com/cesanta/mongoo…...

Linux中openvswitch配置网桥详解
以下是对给出的命令进行逐行解释和注释: # 安装openvswitch软件包,并自动确认所有提示信息使用默认值(-y参数) dnf install openvswitch -y# 启动openvswitch服务 systemctl start openvswitch# 设置openvswitch服务开机启动 sys…...
Python自动化测试框架pytest的详解安装与运行
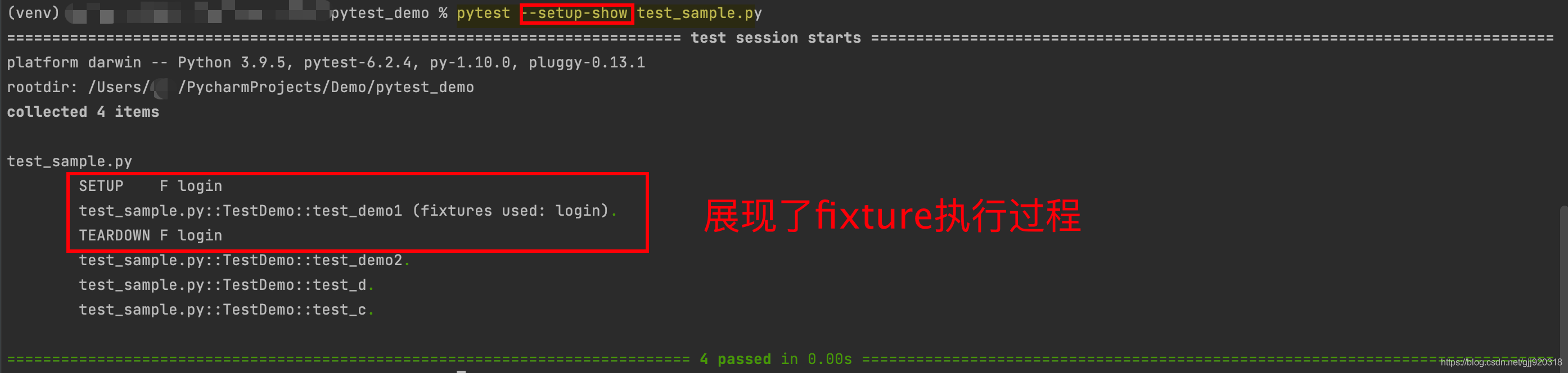
这篇文章主要为大家介绍了Python自动化测试框架pytest的简介以及安装与运行,有需要的朋友可以借鉴参考下希望能够有所帮助,祝大家多多进步 1. pytest的介绍 pytest是一个非常成熟的全功能的python测试工具,它主要有以下特征: 简…...

23种设计模式详解
设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模…...
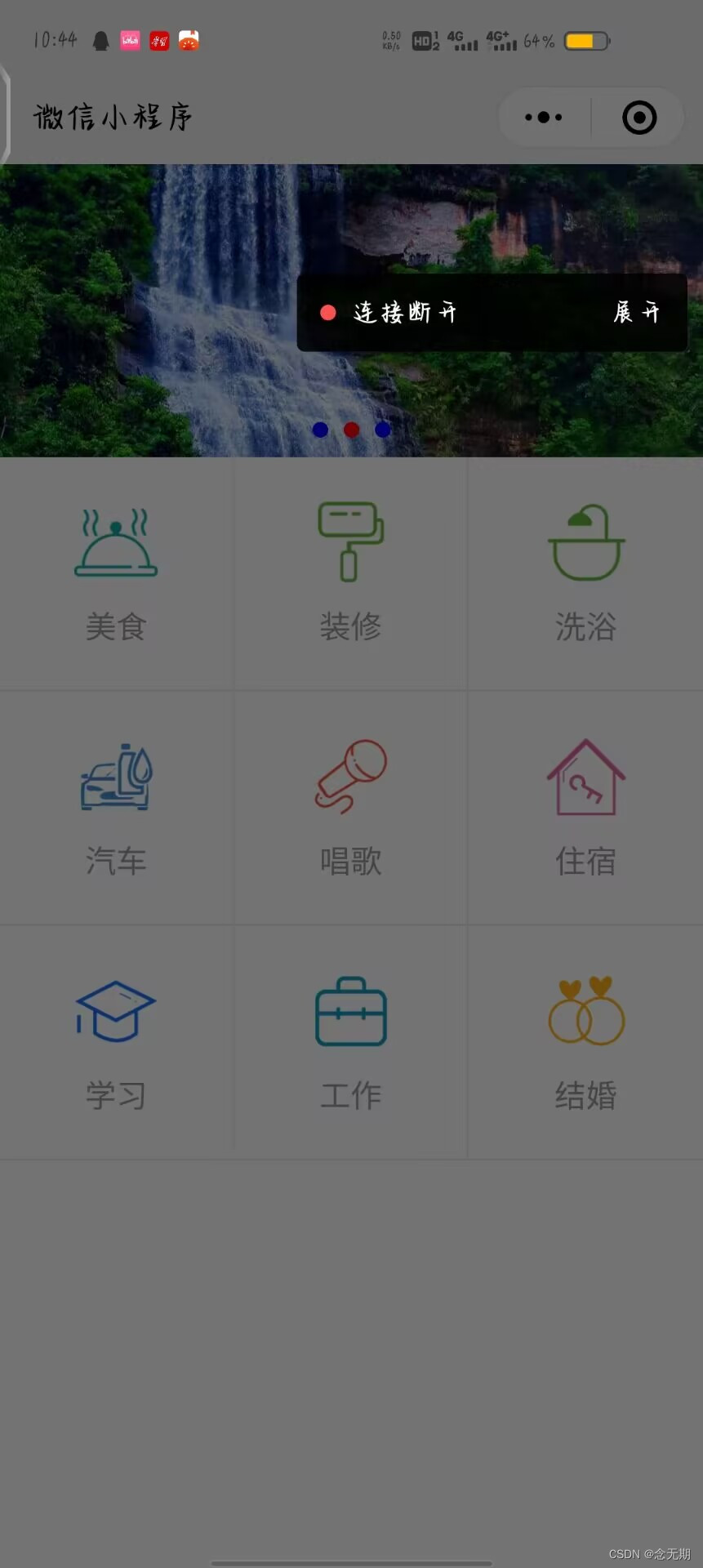
微信小程序案例:2-2本地生活
文章目录 一、实现步骤(一)创建项目(二)创建页面(三)准备图片素材(四)编写页面结构1、编写轮播区域页面结构2、编写九宫格区域页面结构 (五)编写页面样式1、编…...

机器学习论文中常用的数学符号以及Latex
A数据集:通常用 D A \mathcal{D}_A DA表示。 B数据集:通常用 D B \mathcal{D}_B DB表示。 C数据集:通常用 D C \mathcal{D}_C DC表示。 在机器学习中,损失函数通常用 L L L表示,即: L ( θ , D ) …...
【iOS】Fastlane一键打包上传到TestFlight、蒲公英
Fastlane一键打包上传到TestFlight、蒲公英 前言一、准备二、探索一、Fastlane配置1、Fastlane安装2、Fastlane更新3、Fastlane卸载4、查看Fastlane版本5、查看Fastlane位置6、Fastlane初始化 二、Fastlane安装蒲公英插件三、Fastlane文件编辑1、Gemfile文件2、Appfile文件3、F…...
绝地求生大吃鸡攻略,让你成为顶级战士!
近年来,绝地求生越来越受到玩家们的喜爱,吃鸡成为了很多人的娱乐方式。作为一个资深吃鸡玩家,今天我要和大家分享一些提高战斗力的干货,以及一些方便吃鸡作图与查询的实用工具。 首先,提高战斗力是吃鸡游戏中最重要的一…...
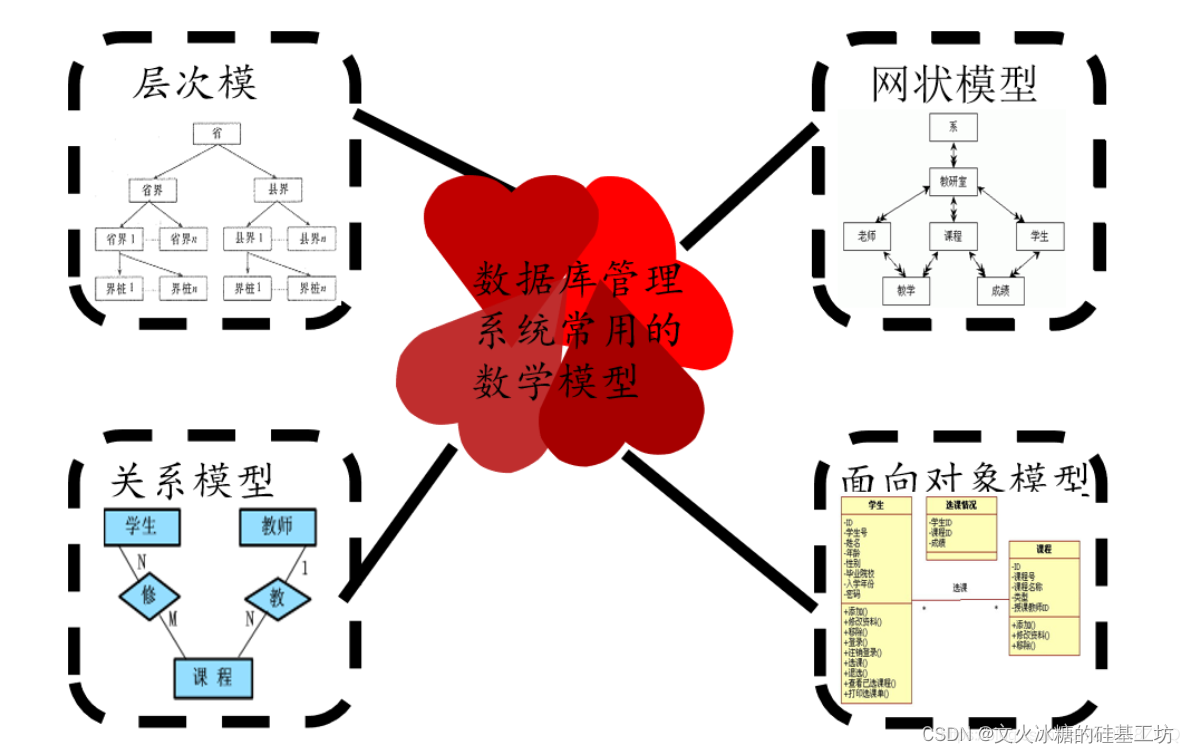
[架构之路-235]:目标系统 - 纵向分层 - 数据库 - 数据库系统基础与概述(快速入门、了解核心概念):概念模型、逻辑模型、物理模型
目录 一、核心概念 1.1 什么是数据与信息 1.2 数据与数据库的关系 1.3 什么是数据库 1.4 数据库中的数据的特点 1.5 数据库与数据结构的关系 1.6 什么是数据库管理系统 1.7 什么是数据库系统 1.8 数据库的主要功能 1.9 Excel表格是数据库吗? 1.10 Excel表…...

小程序, 多选项
小程序, 多选项 <view class"my-filter-btnwrap"><block wx:for"{{archiveList}}" wx:key"index"><view class"my-filter-btnitem text-ellipsis {{item.checked ? active : }}" data-index"{{index}}" wx…...

华为云云耀云服务器L实例评测|使用redis事务和lua脚本
文章目录 云服务器的类型云服务优点redis一,关系型数据库(sqlserver,mysql,oracle)的事务隔离机制说明:redis事务机制 lualua脚本好处:一,怎么在redis中使用lua脚本二,脚…...

vue2项目中使用element ui组件库的table,制作表格,改表格的背景颜色为透明的
el-table背景颜色变成透明_el-table背景透明_讲礼貌的博客-CSDN博客 之前是白色的,现在变透明了,背景颜色是蓝色...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

迪拜塔幕墙设计
迪拜塔幕墙设计 【作 者】:罗永增 【关键词】:迪拜塔,幕墙,设计,系统。 前言:...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

三维重建实时映射技术在智慧水利中的核心应用
三维重建实时映射技术在智慧水利中的核心应用在国家大力推进数字孪生水利建设、实现水安全精准保障的背景下,智慧水利已从传统监测、调度向全域感知、智能预判、协同处置、一屏统管升级。智慧水利的核心目标,是实现对江河湖库、灌区、泵站、堤坝、闸站等…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...