SQL sever中的视图
目录
一、视图概述:
二、视图好处
三、创建视图
法一:
法二:
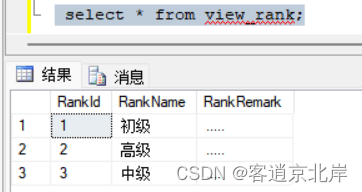
四、查看视图信息
五、视图插入数据
六、视图修改数据
七、视图删除数据
八、删除视图
法一:
法二:
一、视图概述:
视图是一种常用的数据库对象,它将查询的结果以虚拟表的形式存储在数据中。视图并不在数据库中以存储数据集的形式存在。视图的结构和内容是建立在对表的查询基础之上的,和表一样包括行和列,这些行列数据都来源于其所引用的表,并且是在引用视图过程中动态生成的。
视图中的内容是由查询定义来的,并且视图和查询都是通过SQL语句定义的,它们有着许多相同和不同之处,具体如下。
- ☑存储:视图存储为数据库设计的一部分,而查询则不是。视图可以禁止所有用户访问数据库中的基表,而要求用户只能通过视图操作数据。这种方法可以保护用户和应用程序不受某些数据库修改的影响,同样也可以保护数据表的安全性。
- ☑排序:可以排序任何查询结果,但是只有当视图包括TOP子句时才能排序视图。
总之,视图是由一个或多个表(或其他视图)派生的虚拟表。视图是基于查询结果集的命名查询,它包含了从一个或多个表中选择的特定列和行。因此视图可以被认为是一种虚拟表,其内容并不实际存储在数据库中,而是在查询时动态生成。通过创建视图,我们可以隐藏底层表的复杂性,简化复杂查询,并提供一种方便和安全的方式来访问数据。视图只是定义了一个查询,并根据查询的结果生成数据。
视图为数据呈现提供了多样的表现形式,用户可以通过它浏览表中感兴趣的数据。在SQL Server
2008中视图分为以下3类。
- ☑标准视图:保存在数据库中的SELECT查询语句,即通常意义上理解的视图。
- ☑索引视图:创建有索引的视图称为索引视图。它经过计算并存储有自己的数据,可以提高某些类型查询的性能,尤其适用于聚合许多行的查询,但不太适用于经常更新的基本数据集。
- ☑分区视图:是在一台或多台服务器间水平联结一组表中的分区数据,以使数据看上去来源于一个表。
二、视图好处
使用视图的好处包括:
- 简化复杂的查询:视图可以根据具体的业务需求和逻辑将复杂的查询操作进行封装,提供更简洁易懂的查询语句。
- 提高性能:视图可以对查询结果进行缓存,当查询相同的数据时,可以减少查询时间和数据库负载。
- 数据安全性:通过视图,可以控制用户对数据的访问权限,限制他们只能查看和操作特定的列或行,从而保护数据的安全性。
三、创建视图
法一:
使用SQL Server Management Studio创建视图 ,具体操作步骤如下:
(1)启动SQL Server Management Studio,并连接到SQL Server2008中的数据库。
(2)在“对象资源浏览器”中展开“数据库”节点,展开指定的数据库,比如我选择的是SJCX。
(3)右击“视图”选项,在弹出的快捷菜单中选择“新建视图”命令,如图所示。
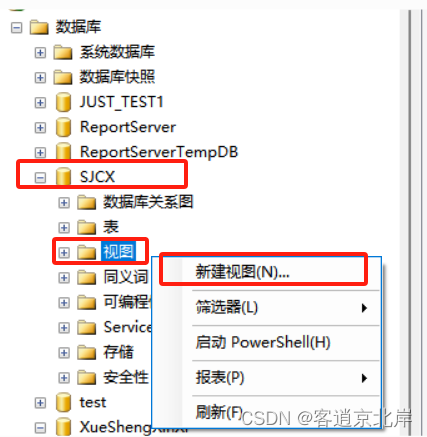
(4)打开“添加表”对话框,如图所示。在列表框中选择表rank,单击“添
加”按钮,然后单击“关闭”按钮关闭该对话框。

(5)进入视图设计器界面,如图所示。在“表选择区”中选择“所有列”选项,单击执行按
钮,视图结果区中自动显示视图结果。

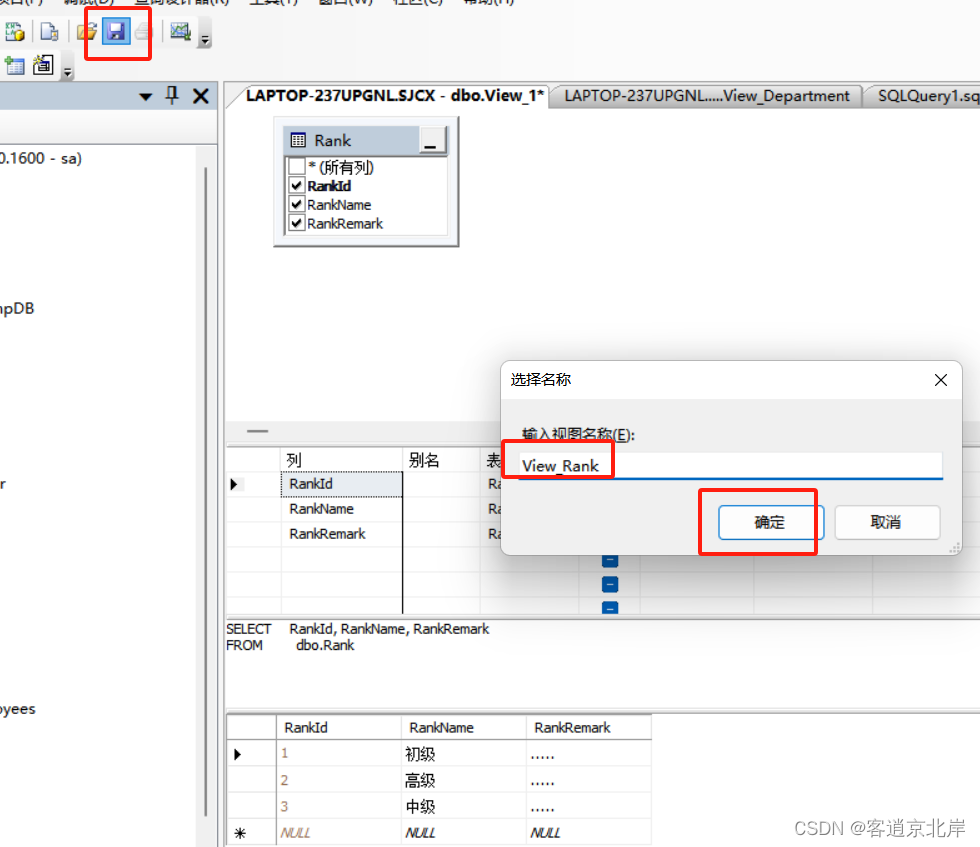
(6)单击工具栏中的“保存”按钮口,弹出“选择名称”对话框,如图所示。在“输入视图名称”文本框中输入视图名称View_Rank,单击“确定”按钮即可保存该视图。
法二:
使用 CREATE VIEW 语句,具体语法如下:
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table(s)
WHERE condition;
比如选择数据库SJCX,创建视图View_people,则SQL语句为:
CREATE VIEW view_people AS
SELECT [DepartmentId],[RankId],[PeopleId],[PeopleName],[PeopleGender],[PeopleBirth],[PeopleSalary],[PeoplePhone],[PeopleAddress],[peopleAddTime],[PeopleMail]FROM [SJCX].[dbo].[People];执行该SQL语句后即创建成功。这是最常用的创建视图的方法,使用 CREATE VIEW 语句指定视图的名称(view_name),然后在 SELECT 子句中定义视图所选择的列和表(或其他视图),并可以包含一个可选的 WHERE 子句来筛选数据。
四、查看视图信息
下面在SQL Server Management Studio中查看视图View Stu的信息,具体操作步骤如下。
(1)启动SQL Server Management Studio,并连接到SQL Server2008中的数据库。
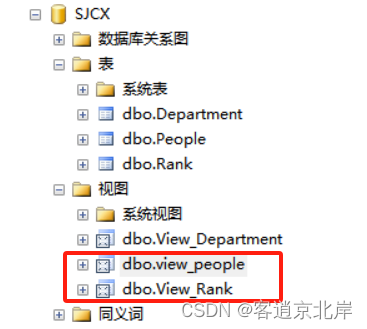
(2)在“对象资源浏览器”中展开“数据库”节点,展开指定的数据库SJCX。
(3)再依次展开“视图”节点,就会显示出当前数据库中的所有视图,右击要查看信息的视图。
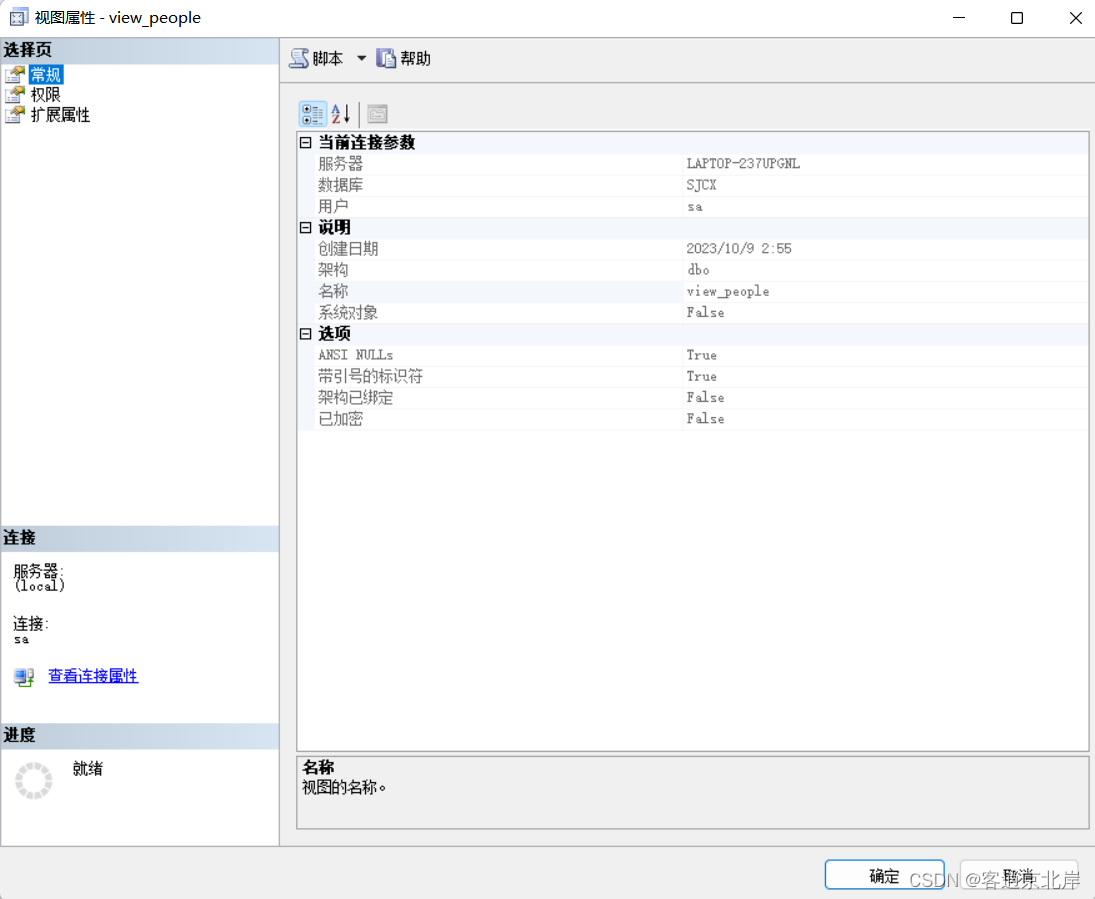
(4)在弹出的快捷菜单中,如果想要查看视图的属性,选择“属性”选项,弹出“视图属性”对话框,如图所示:
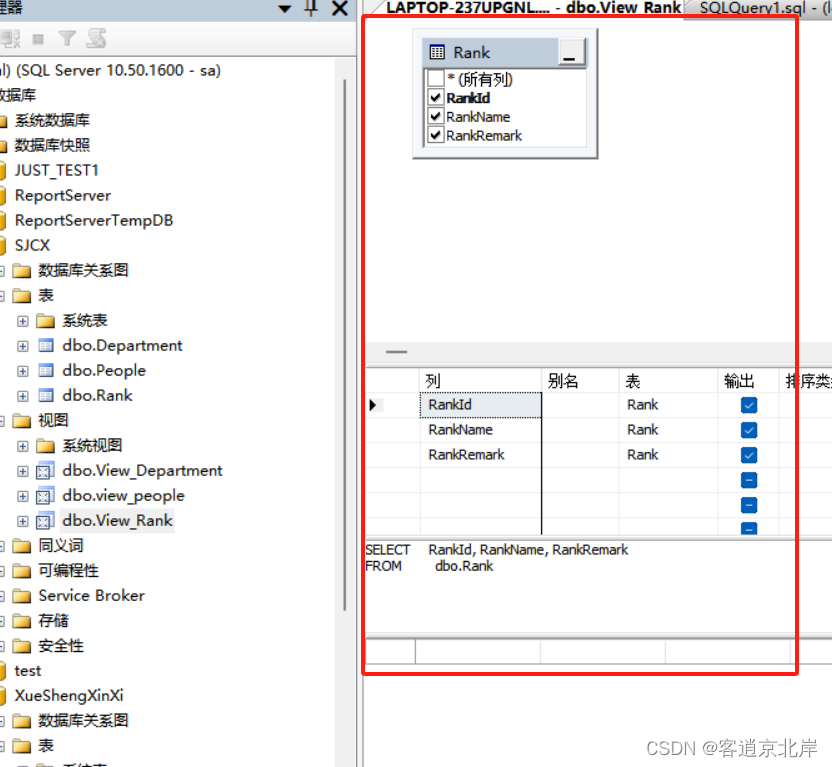
(5)如果想要查看视图中的内容,可在图所示的快捷菜单中选择“编辑前200行”选项,在右侧即可显示视图中的内容。
(6)如果想要重新设置视图,可在快捷菜单中选择“设计”选项,打开视图的设计界面,如图所示。在此界面中可对视图重新进行设置。
五、视图插入数据
使用视图可以插入新的记录,但应该注意的是,新插入的数据实际上是存储在与视图相关的表中。
示例:
向视图View_Rank中插入信息“4,顶级”。
步骤如下:
(1)右击要插入记录的视图,在弹出的快捷菜单中选择“设计”命令,显示视图的设计界面。
(2)在显示视图结果的最下面一行直接输入新记录即可,如图所示。
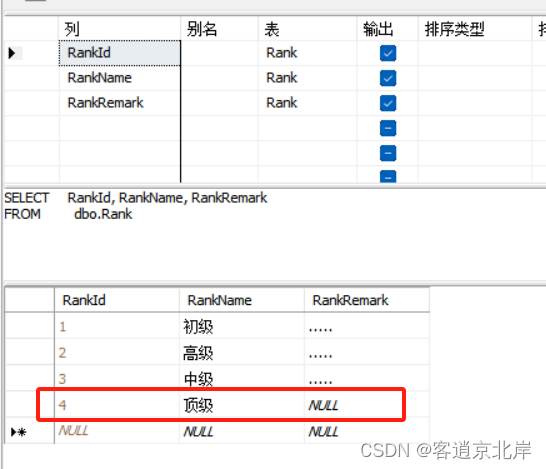
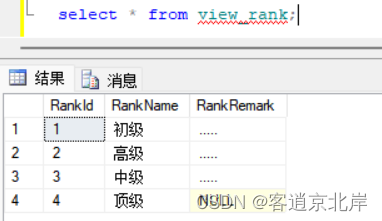
(3)然后按下Enter键,即可把信息插入到视图中。
(4)单击!按钮,完成新记录的添加,如图所示:
六、视图修改数据
使用视图可以修改数据记录,但是与插入记录相同,修改的是数据表中的数据记录。
示例:
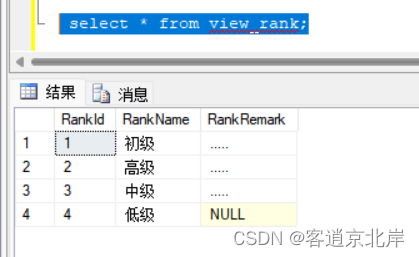
修改视图View_Rank中的记录,将“顶级”修改为“低级”。
步骤如下:
(1)右击要修改记录的视图,在弹出的快捷菜单中选择“设计”命令,显示视图的设计界面。
(2)在显示的视图结果中,选择要修改的内容,直接修改即可。
(3)最后按下Enter键,即可把信息保存到视图中。
七、视图删除数据
使用视图可以删除数据记录,但是与插入记录相同,删除的是数据表中的数据记录。
示例:
删除视图View_Rank中的记录“低级”。
步骤如下:
(1)右击要删除记录的视图,在弹出的快捷菜单中选择“设计”命令,显示视图的设计界面。
(2)在显示视图的结果中,右击要删除的行“低级”,在弹出的快捷菜单中选择“删除”命令,弹出“删除”对话框,如图所示。

(3)单击“是”按钮,便可将该记录删除。
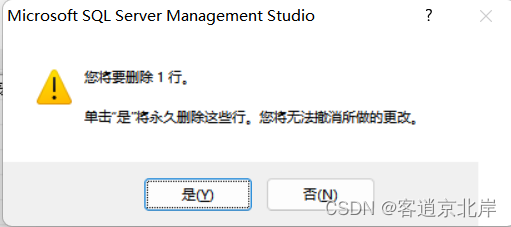
(4)检查结果,如图所示:
八、删除视图
对于数据库中不需要的视图可以将其删除,以释放存储空间。可以使用企业管理器将其删除,也
可以使用SQL语句将其删除。
法一:
使用企业管理器删除视图的步骤如下:
(1)启动SQL Server Management Studio,.并连接到SQL Server2008中的数据库。
(2)在“对象资源管理器”中依次展开“数据库”指定的数据库/“视图”节点。
(3)右击要删除的视图,在弹出的快捷菜单中选择“删除”命令,弹出“删除对象”对话框,如图所示。 在“删除对象”对话框中,单击“显示依赖关系”按钮,可以显示与该视图有关的数据表和视图,单击“确定”按钮,便可将该视图删除。
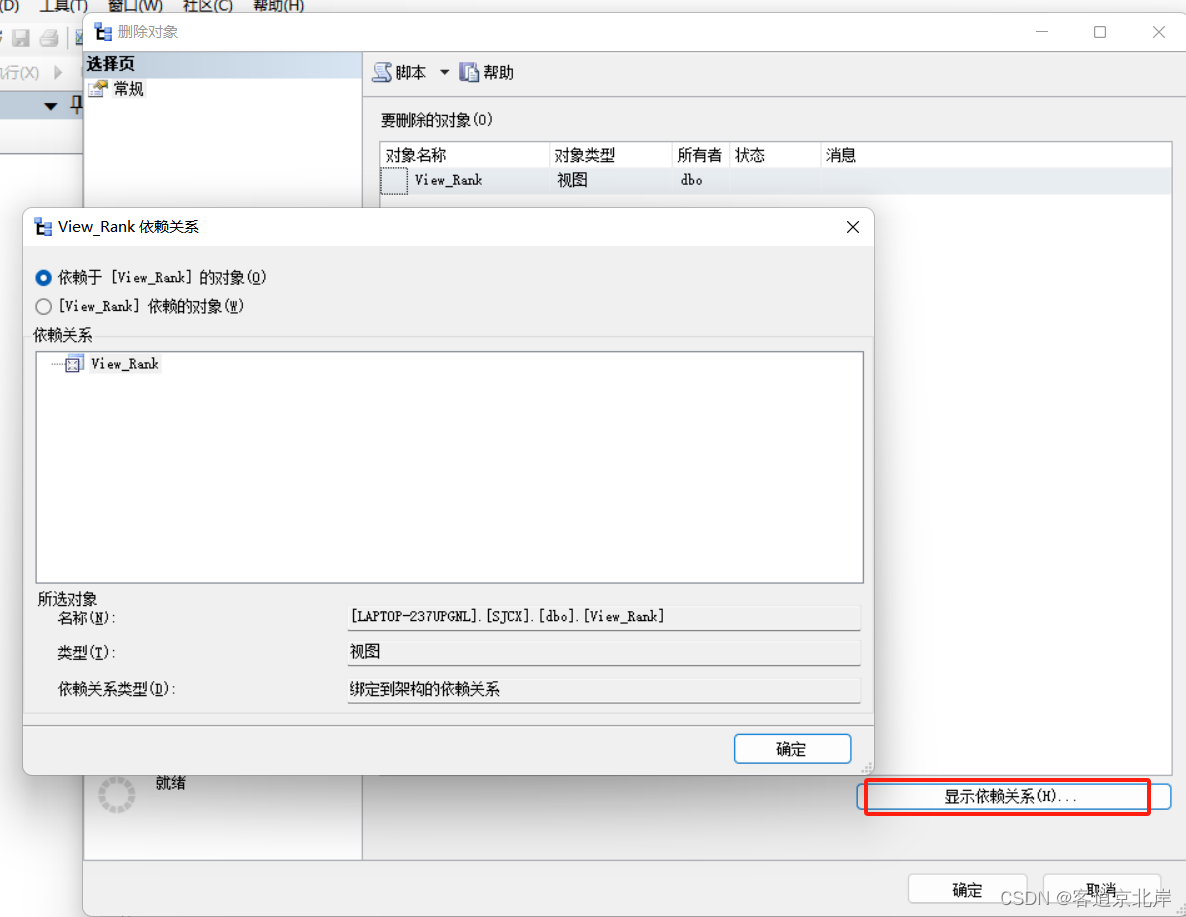
注意:
在删除之前,应该先查看视图的依赖关系,如果有对象依赖于要删除的视图,那么要确
定是否要保存该对象,如果不保存,则可以直接将该视图删除,否则将不能删除该视图。
法二:
使用 DROP VIEW 语句来删除视图。下面是删除视图的语法:
DROP VIEW [IF EXISTS] view_name;--或者
IF OBJECT_ID('view_name', 'V') IS NOT NULLDROP VIEW view_name;可选的 IF EXISTS 子句用于检查视图是否存在。如果视图不存在,执行语句时不会引发错误。
使用 OBJECT_ID 函数检查视图是否存在(V 表示视图),如果存在则执行 DROP VIEW 语句进行删除。
注意:
从 SQL Server 2016 版本开始,引入了
DROP VIEW IF EXISTS语法。因此,如果使用的是 SQL Server 2016 及其更高版本,可以直接使用该语法来删除视图。
示例:
删除视图view_people:
-- 删除视图
DROP VIEW view_people;-- 删除视图(如果存在)
DROP VIEW IF EXISTS view_people;--或者
IF OBJECT_ID('view_people', 'V') IS NOT NULLDROP VIEW view_people;
相关文章:
SQL sever中的视图
目录 一、视图概述: 二、视图好处 三、创建视图 法一: 法二: 四、查看视图信息 五、视图插入数据 六、视图修改数据 七、视图删除数据 八、删除视图 法一: 法二: 一、视图概述: 视图是一种常用…...

如何理解数据序列化
数据序列化是一个将数据结构或对象状态转换为一个可以存储或传输的格式的过程。序列化后的数据可以存放在文件中、数据库中或通过网络传输。反序列化是将序列化数据恢复为原始数据结构或对象的过程。 数据序列化格式可以理解为一种约定或规范,它定义了如何表示和编码数据以便…...
07_项目开发_用户信息列表
1 用户信息列表内容展示 用户信息列表,主要完成用户信息的添加、删除、修改和查找功能。 用户列表页面效果: 单击“添加用户”按钮,进入添加用户页面。 填写正确的信息后,单击“添加用户”按钮,会直接跳转到用户列表…...

flutter ios打包
在 Flutter 中打包 iOS 应用程序分为两步: 生成 iOS 项目文件 在 Flutter 项目根目录下执行以下命令: flutter create --ios-language swift .这个命令会在当前目录下生成 iOS 项目文件,并且默认使用 Swift 语言编写。 使用 Xcode 打包 …...

【无公网IP内网穿透】基于NATAPP搭建Web站点
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《.内网穿透》。🎯🎯 &#…...
智能AI创作系统ChatGPT详细搭建教程/AI绘画系统/支持GPT联网提问/支持Prompt应用/支持国内AI模型
一、智能AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统,支持OpenAI GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作…...

【技能树笔记】网络篇——练习题解析(五)
目录 前言 一、应用层的作用 1.1 应用层的作用 二、HTTP协议 2.1 HTTP协议 三、FTP协议 3.1 FTP协议 四、DNS协议 4.1 DNS协议 五、DHCP协议 5.1 DHCP协议 六、邮件协议 6.1 电子邮件协议 总结 前言 本篇文章给出了CSDN网络技能树中的部分练习题解析,…...
--- 集合元素的遍历操作Iterator以及foreach)
Java集合(二)--- 集合元素的遍历操作Iterator以及foreach
文章目录 一、使用迭代器Iterator接口1.说明2.代码 二、foreach循环,用于遍历集合、数组 提示:以下是本篇文章正文内容,下面案例可供参考 一、使用迭代器Iterator接口 1.说明 1.内部的方法: hasNext() 和 next() 2.集合对象每次调iterator…...

数据结构:排序- 插入排序(插入排序and希尔排序) , 选择排序(选择排序and堆排序) , 交换排序(冒泡排序and快速排序) , 归并排序
目录 前言 复杂度总结 预备代码 插入排序 1.直接插入排序: 时间复杂度O(N^2) \空间复杂度O(1) 复杂度(空间/时间): 2.希尔排序: 时间复杂度 O(N^1.3~ N^2) 空间复杂度为O(1) 复杂度(空间/时间&#…...

IOT 围炉札记
文章目录 一、蓝牙二、PAN1080三、IOT OS四、通讯 一、蓝牙 树莓派上的蓝牙协议 BlueZ 官网 BlueZ 官方 Linux Bluetooth 栈 oschina 二、PAN1080 pan1080 文档 三、IOT OS Zephyr 官网 Zephyr oschina Zephyr github Zephyr docs 第1章 Zephyr简介 第2章 Zephyr 编译环…...
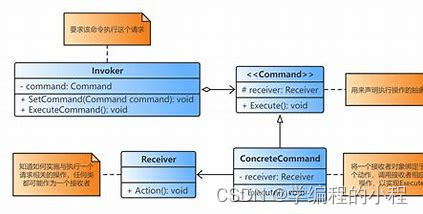
小谈设计模式(24)—命令模式
小谈设计模式(24)—命令模式 专栏介绍专栏地址专栏介绍 命令模式角色分析命令(Command)具体命令(ConcreteCommand)接收者(Receiver)调用者(Invoker)客户端&am…...
9.HTML
文章目录 1.HTML 常见标签1.1注释标签1.2标题标签: h1-h61.3段落标签: p1.4换行标签: br1.5综合案例: 展示博客1.6格式化标签1.7图片标签: img1.8超链接标签: a1.9综合案例: 展示博客21.10表格标签1.10.1基本使用1.10.2合并单元格 1.11列表标签1.12表单标签1.13无语义标签: div…...
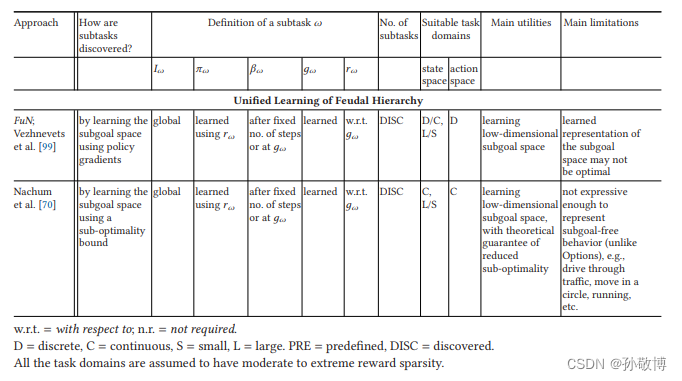
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey
分层强化学习 综述论文阅读 Hierarchical Reinforcement Learning: A Comprehensive Survey 摘要一、介绍二、基础知识回顾2.1 强化学习2.2 分层强化学习2.2.1 子任务符号2.2.2 基于半马尔可夫决策过程的HRL符号 2.3 通用项定义 三、分层强化学习方法3.1 学习分层策略 (LHP)3.1…...
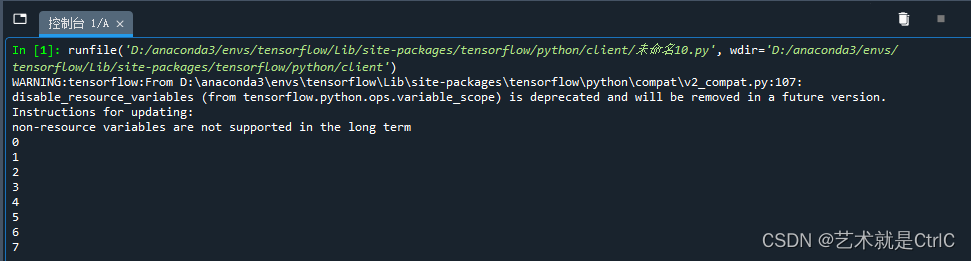
TensorFlow入门(十五、数据读取机制(2))
使用Dataset创建和读取数据集,作为TensorFlow模型创建输入管道的新方式,使用性能比使用feed_dict或队列式管道的性能高很多,使用也更加简洁容易。也是google强烈推荐的数据读取方式,对于TensorFlow而言,十分重要。 Dataset是什么? Dataset的定义 : 它是一个含有相同类型元素且…...
Linux系统中实现便捷运维管理和远程访问的1Panel部署方法
文章目录 前言1. Linux 安装1Panel2. 安装cpolar内网穿透3. 配置1Panel公网访问地址4. 公网远程访问1Panel管理界面5. 固定1Panel公网地址 前言 1Panel 是一个现代化、开源的 Linux 服务器运维管理面板。高效管理,通过 Web 端轻松管理 Linux 服务器,包括主机监控、…...

Rancher清理节点
本节介绍如何从一个 Rancher 创建的 Kubernetes 集群中断开一个节点,并从该节点中删除所有 Kubernetes 组件。此过程允许您将释放节点资源,将节点用于其他用途。 当您使用 Rancher 创建集群节点 时,将创建资源(容器/虚拟网络接口)和配置项(证…...
C++-Mongoose(1)-http-server
Mongoose is a network library for C/C. It implements event-driven non-blocking APIs for TCP, UDP, HTTP, WebSocket, MQTT. mongoose很小巧,只有两个文件mongoose.h/cpp,拿来就可以用. 下载地址: https://github.com/cesanta/mongoo…...

Linux中openvswitch配置网桥详解
以下是对给出的命令进行逐行解释和注释: # 安装openvswitch软件包,并自动确认所有提示信息使用默认值(-y参数) dnf install openvswitch -y# 启动openvswitch服务 systemctl start openvswitch# 设置openvswitch服务开机启动 sys…...
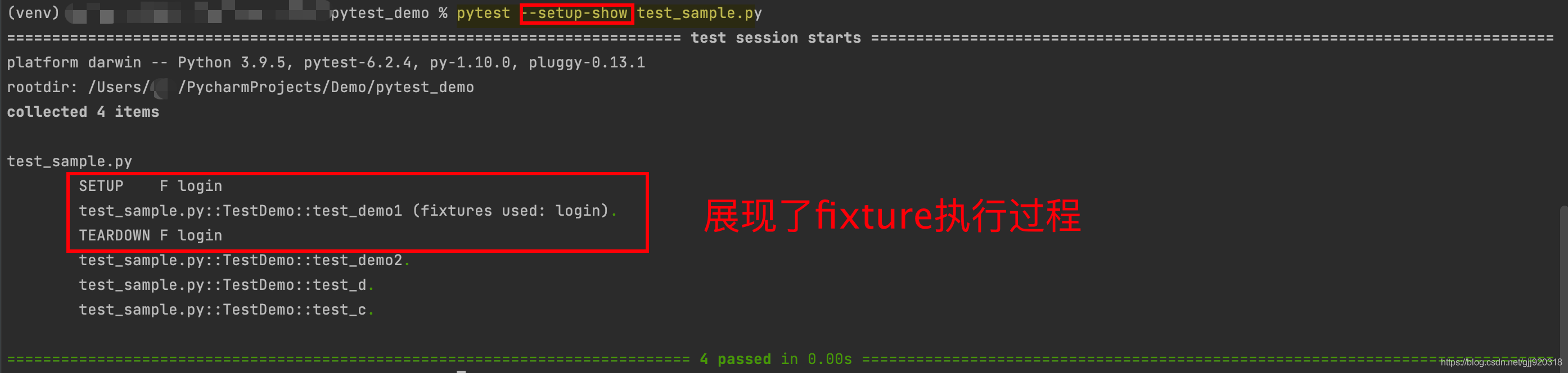
Python自动化测试框架pytest的详解安装与运行
这篇文章主要为大家介绍了Python自动化测试框架pytest的简介以及安装与运行,有需要的朋友可以借鉴参考下希望能够有所帮助,祝大家多多进步 1. pytest的介绍 pytest是一个非常成熟的全功能的python测试工具,它主要有以下特征: 简…...

23种设计模式详解
设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模…...

从8K游戏到HDR电影:拆解Xilinx HDMI 2.1 IP如何支持VRR、ALLM和动态HDR这些炫酷特性
从8K游戏到HDR电影:Xilinx HDMI 2.1 IP如何重塑视听体验 当PS5玩家在《战神:诸神黄昏》中感受到无撕裂的流畅战斗画面,或是家庭影院爱好者在《沙丘》中看到沙漠场景的每一粒沙粒都呈现出惊人的动态范围时,背后都离不开HDMI 2.1的关…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

CircuitPython状态灯、安全模式与文件系统故障排查实战指南
1. 项目概述与核心价值 如果你正在用CircuitPython做项目,无论是物联网传感器节点、智能穿戴设备还是互动艺术装置,大概率都遇到过这样的瞬间:板子上的RGB状态灯突然开始闪烁诡异的颜色,或者电脑上那个熟悉的 CIRCUITPY U盘图标…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

Arm Iris组件参数化建模与调试实践
1. Arm Iris组件概述与核心价值Arm Iris组件是Fast Models仿真平台中的关键模块,它为芯片设计验证和软件开发提供了高度参数化的虚拟原型环境。作为一名长期从事Arm架构开发的工程师,我发现Iris组件的设计理念完美体现了"配置即硬件"的思想——…...

Windows Terminal 预览版:从安装到深度配置,打造现代化命令行工作流
1. 项目概述:为什么我们需要一个现代化的Windows终端?如果你和我一样,在Windows上敲了十几年命令行,从古老的cmd.exe到后来的PowerShell,一个绕不开的痛点就是:这终端工具,用起来总感觉差点意思…...