零基础Linux_14(基础IO_文件)缓冲区+文件系统inode等
目录
1. 缓冲区
1.1 缓冲区的存在
1.2 缓冲区的刷新策略
1.3 模拟C标准库中的文件操作
完整代码及验证:
1.4 重看缓冲区
1.5 stdout和stderr的区别
2. 文件系统
2.1 磁盘的物理结构CHS等
2.2 磁盘的抽象结构LBA等
2.3 文件管理inode等
2.4 对文件的操作
本篇完。
1. 缓冲区
对于缓冲区的概念,我们在前面的学习有做探讨,但只是一个简单的讲解。
我们对缓冲区有一个共识,也知道它的存在,但我们还没有去深入理解它。
① 什么是缓冲区?缓冲区的本质就是一段内存。
② 为什么要有缓冲区?为了 解放使用缓冲区的进程时间。
缓冲区的存在可以集中处理数据刷新,减少 IO 的次数,从而达到提高整机的效率的目的。
1.1 缓冲区的存在
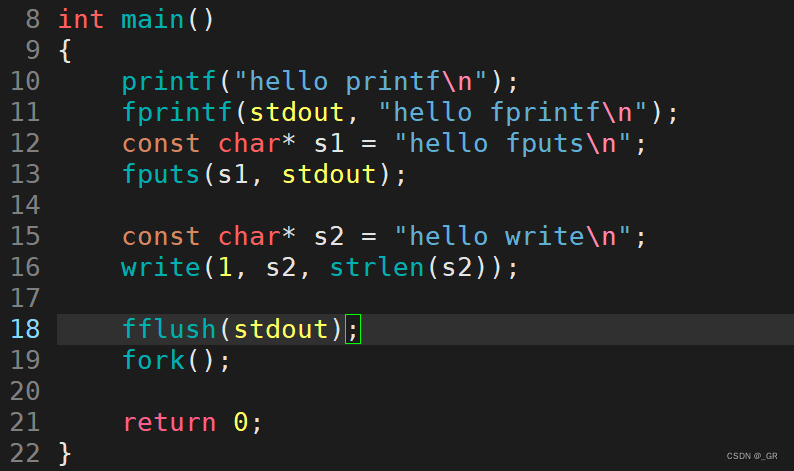
用 C语言的接口 和 write 各自打印一段话:
编译运行:

在代码后加个fork创建子进程:
编译运行重复上面操作:

发现除了系统调用的接口都打印了两遍,为什么呢?
这个现象首先得出两个结论:
- 这个现象肯定是和缓冲区有关。(write先刷新出来)
- 缓冲区必然不在操作系统内核中。(如果在,那么不会出现打印次数不同的结果)
既然缓冲区不在操作系统内核中,也就是不是由操作系统来维护的,那么它只能有进程去维护,也就是编程语言本身来维护。
拿C语言来说,和文件相关的操作,FILE*类型的指针是至关重要的,我们已经知道,FILE是一个结构体,它里面有文件描述符fd,在结构体中定义的变量名是_fileno。
来大概看看Linux的源码:
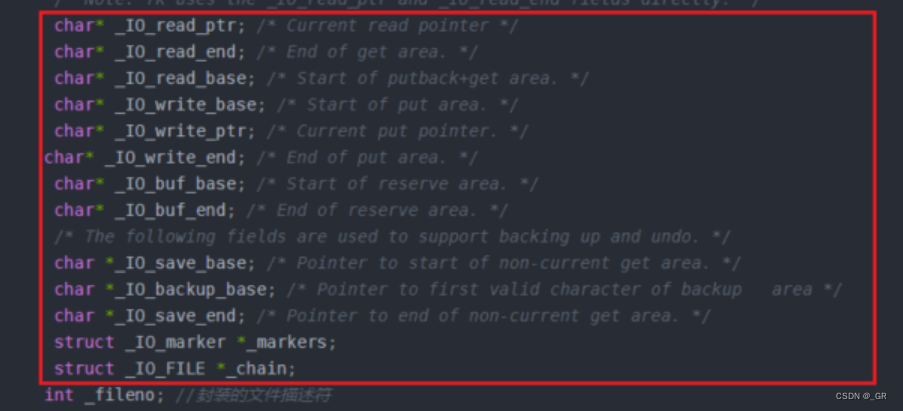
在源码中,和文件有关的结构体中有很多的指针变量,如上图中红色框所示,这些指针就是在维护缓冲区。此时我们就可以知道,缓冲区是由要打卡文件的进程申请的,也是由这个进程来维护的,缓冲区存在于FILE结构体中。
1.2 缓冲区的刷新策略
刷新策略,即什么时候刷新,刷新策略分为常规策略和特殊情况。
常规策略:
- 无缓冲 (立即刷新)
- 行缓冲 (逐行刷新)
- 全缓冲 (缓冲区打满,再刷新)
特殊情况:
- 进程退出
- 用户强制刷新(即调用 fflush)
上一篇5.1 中的代码,当我们重定向后,本来要显示到显示器的内容经过重定向显示到了文件里,
- 如果对应的是显示器文件,刷新策略就是行缓冲。
- 如果是磁盘文件,那就是全缓冲,即写满才刷新。(这里log.txt就是磁盘文件)
重定向,由显示器重定向到了文件,缓冲区的刷新策略由 "行缓冲" 转变为 "全缓冲"。
fork 要创建子进程,之后父子进程无论谁先退出,它们都要面临的问题是:
父子进程刷新缓冲区。
刷新的本质:把缓冲区的数据 write 到 OS 内部,清空缓冲区。
这里的 "缓冲区" 是自己的 FILE 内部维护的,属于父进程内部的数据区域。
所以当我们刷新时,代码和数据要发生写实拷贝,即父进程刷一份,子进程刷一份,
因而导致上面的现象,printf, fprintf, fputs 刷了 2 次到了 log.txt 中。
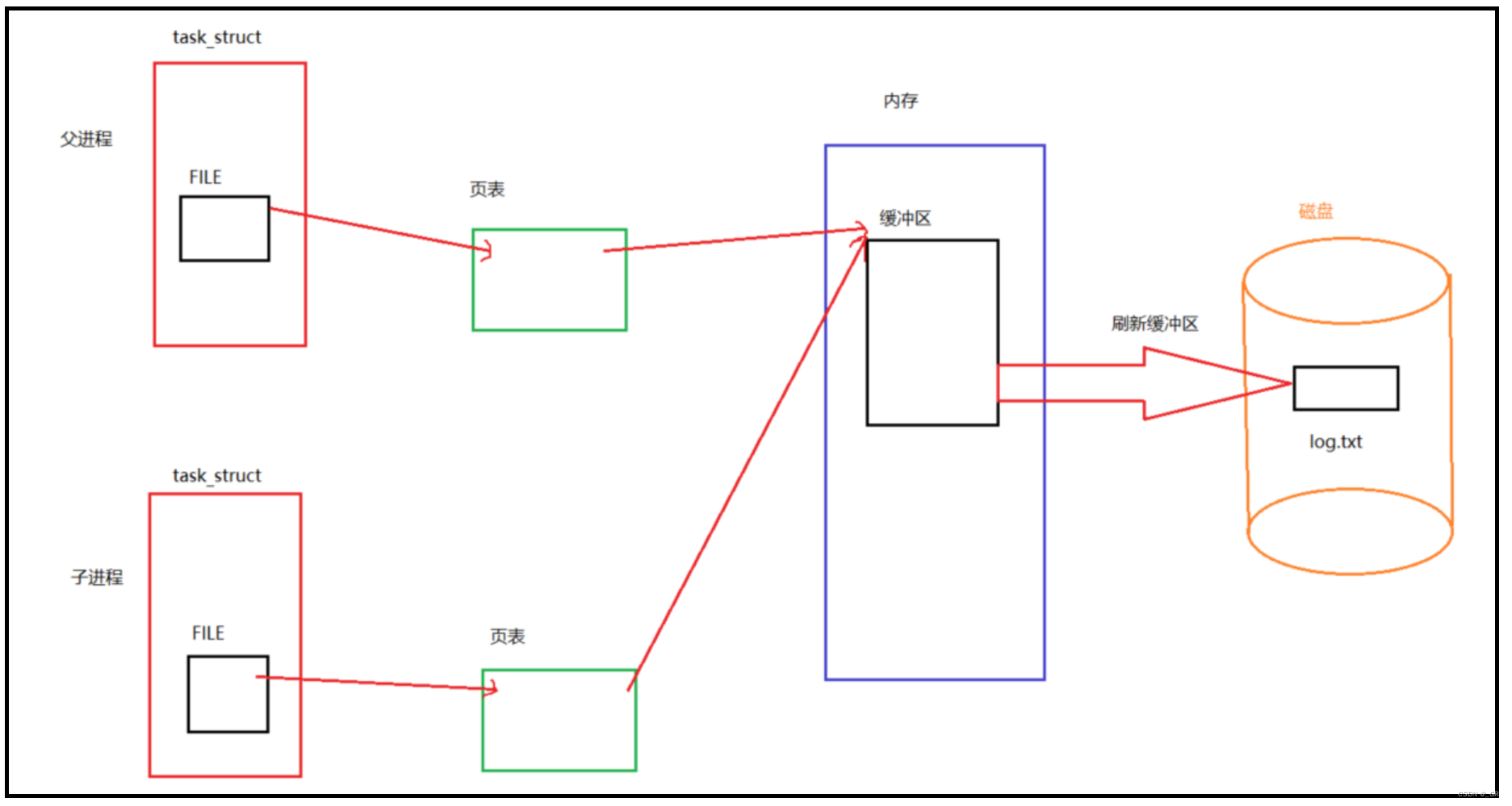
在没有重定向的程序中,打印终端是显示器,采用的是行缓冲的方式,每个C接口打印的字符串中都有换行符,所以每次调用完C接口后都会刷新缓存区中的内容。
在fork之前,父进程的缓冲区已经被刷新了,在fork之后,父子两个进程各自的缓冲区中什么都没有,都已经被刷新走了,所以它们两在结束的时候也不会再次刷新缓冲区,所以表现出来各自打印一次。
在有重定向的程序中,打印终端是log.txt这个磁盘文件,是全缓存的方式,父进程创建以后,在调用C接口时,将数据写到了它的缓冲区中,并且通过页表在内存中映射了一段物理空间。因为是全缓冲,\n失效了,所以缓冲区并没有刷新。
在执行到return 0 之前的fork时,创建了子进程,子进程会拷贝父进程缓冲区中的全部内容(写时拷贝),并且通过页表映射到相同的物理空间。
在fork之后,父子两个进程什么都没有干进程将结束了,在进程结束的时候会刷新它们各自缓冲区中的数据到磁盘文件中。
因为有两个进程要结束,所以缓冲区就会刷新两次,而且内容是一样的。
在fork前加上一句代码:
重复上次操作:
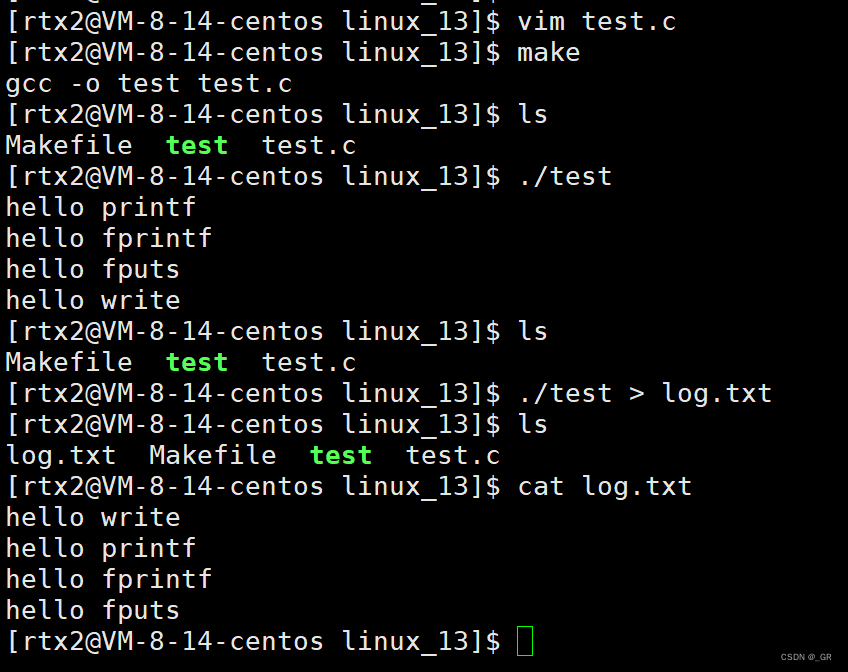
使缓冲区在fork之前刷新,为什么传stdout就行了?这也说明了缓冲区存在于FILE结构体中。
1.3 模拟C标准库中的文件操作
为了能够对缓冲区有更深的了解,下面带大家简单的用C语言模拟实现一下用户缓冲区。
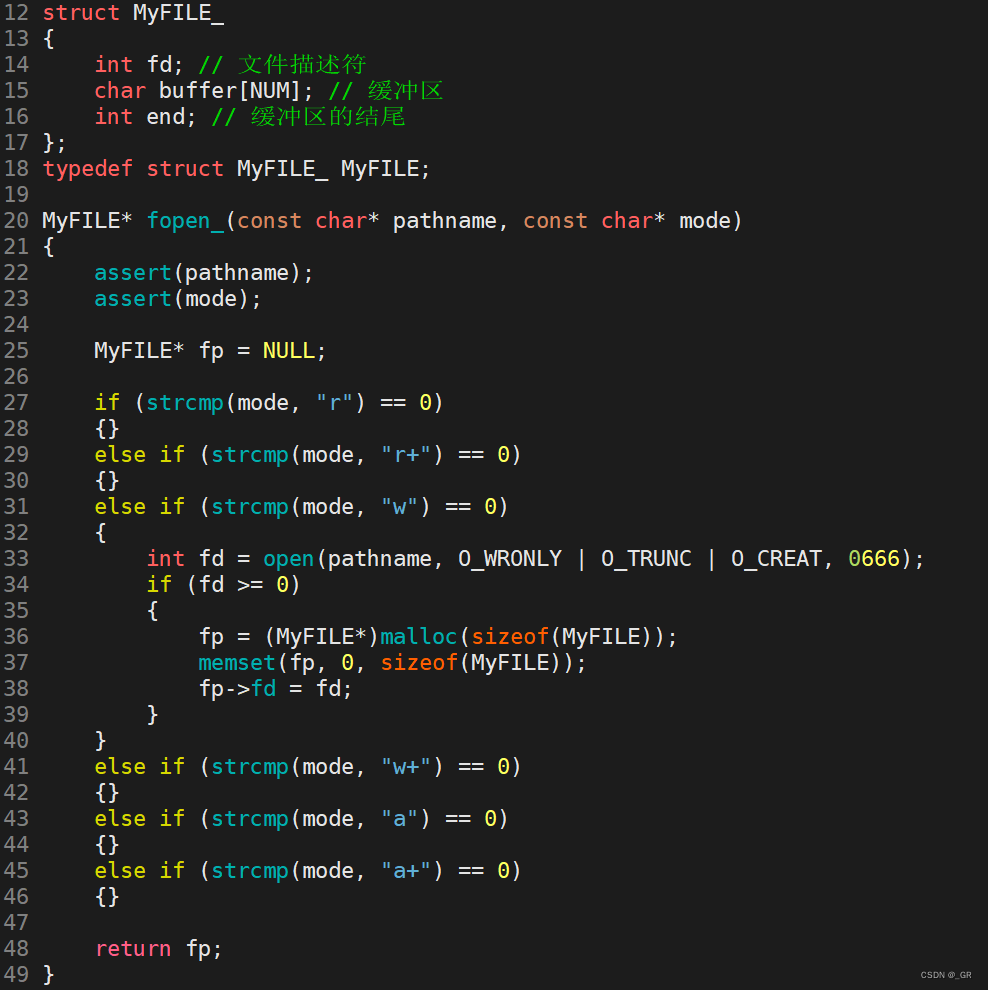
首先需要简历FILE结构体,根据我们学习到的内容,有文件描述符fd,缓冲区,其它的先不考虑。这里仅仅是模拟一个缓冲区,实际的缓冲区肯定不是一个数组。
这里创建linux_14目录然后在里面写Makefile和myfile.c:

先是想着实现前一篇类似的功能,然后自己实现这三个C语言的文件操作函数:

下面实现打开文件函数fopen_:
首先参数是路径和打开方式,返回值是文件指针,然后这里只实现w的方式打开:
根据C库里的fopen,open传参除了O_WRONLY 和 O_CREAT还需要传O_TRUNC截断清空。
这里也可以看出,无论上层语言是什么,打开文件时最终都会调用系统调用open函数。
下面实现fputs_:

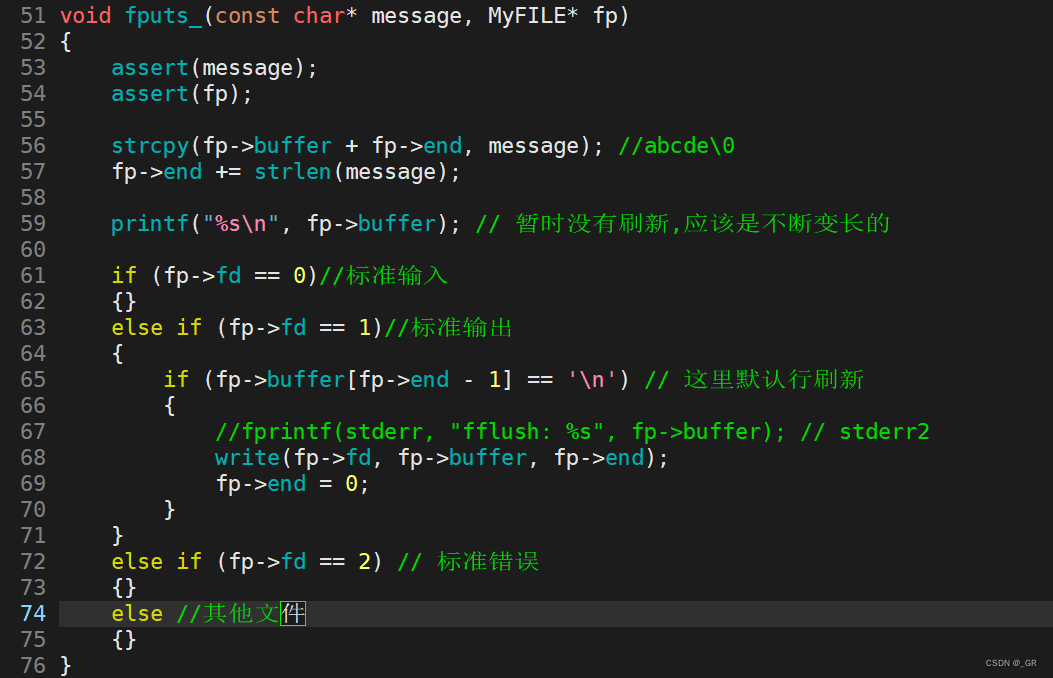
- 使用write系统调用后,与其认为将数据写入到了文件中,不如认为是将数据复制到了文件中。
期间可以用打印的方式测试代码,这里就不演示了。
刷新函数:
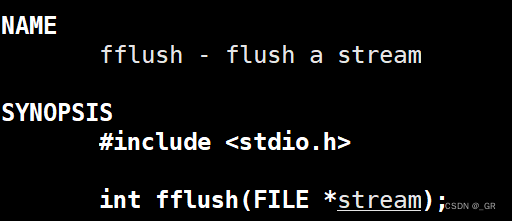
如果缓冲区中有数据,调用该函数时,立刻将缓冲区中的数据写到Linux内核中。再将内核中的数据写入到文件中。
这里调用了一个fsync函数,该函数的作用就将内核缓冲区中的数据刷新到文件描述符fd所执行的文件中。
- 我们使用系统调用write时,其实是将数据写入到了内核缓冲区中,而不是直接写入到了文件中。
- 操作系统会将内核缓冲区中的数据再写入到文件中。
这里使用该函数来强制刷新内核缓冲区中的数据,而没有让操作系统自主去刷新数据,是为了防止内核缓冲区中的数据还没有刷新出去的时候系统就宕机了,此时会导致数据的丢失。
至于操作系统是如何将内核缓冲区中的数据刷新到文件中的,这是操作系统的事情了,我们不需要再了解,我们要掌握的是用户层语言所维护的缓冲区。
关闭函数:


在关闭文件时,将缓冲区中的数据刷新到内核中,然后再通过系统调用关闭文件描述符所指向的文件。最后再释放my_FILE结构体,以防造成内存泄露。
完整代码及验证:
myfile.c:
#include <stdio.h>
#include <assert.h>
#include <string.h>
#include <stdlib.h> // malloc
#include <unistd.h> // fork write close
#include <sys/types.h> // 三个open的头文件
#include <sys/stat.h>
#include <fcntl.h>#define NUM 1024struct MyFILE_
{int fd; // 文件描述符char buffer[NUM]; // 缓冲区int end; // 缓冲区的结尾
};typedef struct MyFILE_ MyFILE;MyFILE* fopen_(const char* pathname, const char* mode)
{assert(pathname);assert(mode);MyFILE* fp = NULL;if (strcmp(mode, "r") == 0){}else if (strcmp(mode, "r+") == 0){}else if (strcmp(mode, "w") == 0){int fd = open(pathname, O_WRONLY | O_TRUNC | O_CREAT, 0666);if (fd >= 0){fp = (MyFILE*)malloc(sizeof(MyFILE));memset(fp, 0, sizeof(MyFILE));fp->fd = fd;}}else if (strcmp(mode, "w+") == 0){}else if (strcmp(mode, "a") == 0){}else if (strcmp(mode, "a+") == 0){}return fp;
}void fputs_(const char* message, MyFILE* fp)
{assert(message);assert(fp);strcpy(fp->buffer + fp->end, message); //abcde\0fp->end += strlen(message);printf("%s\n", fp->buffer); // 暂时没有刷新,应该是不断变长的if (fp->fd == 0)//标准输入{}else if (fp->fd == 1)//标准输出{if (fp->buffer[fp->end - 1] == '\n') // 这里默认行刷新{//fprintf(stderr, "fflush: %s", fp->buffer); // stderr2write(fp->fd, fp->buffer, fp->end);fp->end = 0;}}else if (fp->fd == 2) // 标准错误{}else //其他文件{}
}void fflush_(MyFILE* fp)
{assert(fp);if (fp->end != 0){write(fp->fd, fp->buffer, fp->end); //把数据写到了内核syncfs(fp->fd); //将数据写入到磁盘,知道有这个函数就行了fp->end = 0;}
}void fclose_(MyFILE* fp)
{assert(fp);fflush_(fp);close(fp->fd);free(fp);
}int main()
{MyFILE* fp = fopen_("./log.txt", "w");if (fp == NULL){printf("open file error");return 1;}fputs_("hello world", fp);fork();fclose_(fp);return 0;
}linux下编译运行:
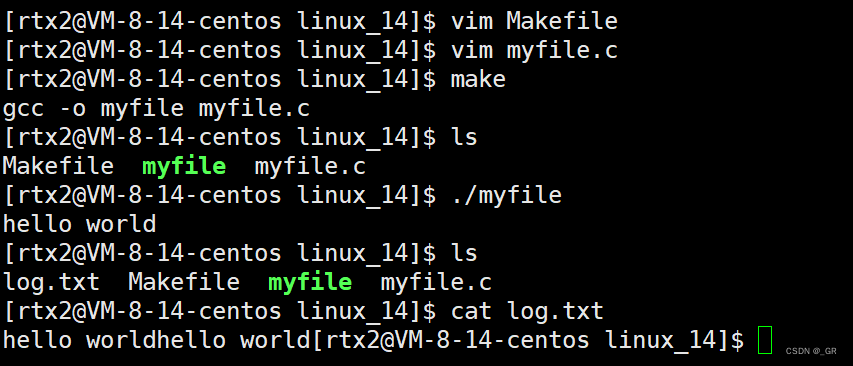
完成咯,关于打印还可以多加几行,分着加几个\n试试,这里就不演示了。
1.4 重看缓冲区
先看一段前面学过类似的代码:(这里创建个test.c)

编译运行:

此时是意料之中的,我们在代码前close(1)试试:

编译运行:打印
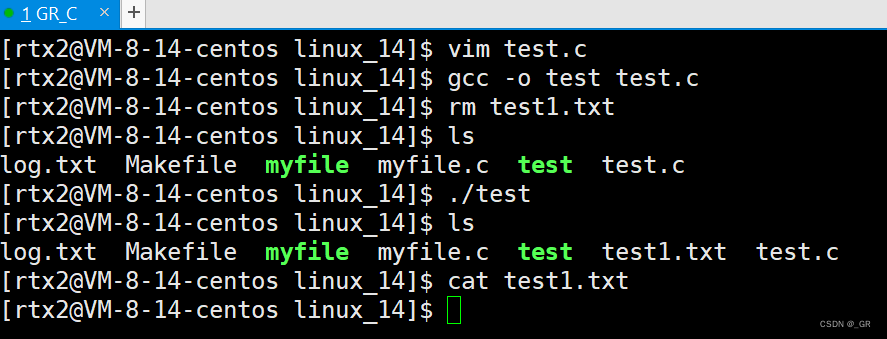
这里为什么屏幕和文件里都没有打印内容?close之前fflush一下:

这里为什么fflush(stdout);就行了?学到这我们已经知道了,printf的时候,内容会暂存在stdout的缓冲区中,没有fflush(stdout);时,关闭文件,内容就刷新不出来了,fflush(stdout);后,内容就成功地刷新出来。
1.5 stdout和stderr的区别
stdout和stderr是标准输入和标准错误输出的缩写,是与命令行相关的两个重要概念。其中:
stdout表示标准输出(文件),它是命令或程序正常输出的数据流,通常是在终端或标准输出文件中显示或写入输出内容。
stderr表示标准错误(文件),它是命令或程序输出错误消息的数据流,通常是在终端或标准错误文件中显示或写入错误信息。
两者默认向屏幕输出。
但如果用转向标准输出到磁盘文件,则可看出两者区别:
这两者之间的主要区别在于,stdout输出到磁盘文件,stderr在屏幕。stdout用于标准的程序输出,而stderr用于错误输出。因此,当程序运行时遇到错误时,错误消息会被发送到stderr,而不是stdout。这使得错误消息和标准输出数据流分离,方便我们识别和处理程序运行中的错误和异常情况。
在默认情况下,stdout是行缓冲的,他的输出会放在一个buffer里面,只有到换行的时候,才会输出到屏幕。而stderr是无缓冲的,会直接输出。
代码演示:
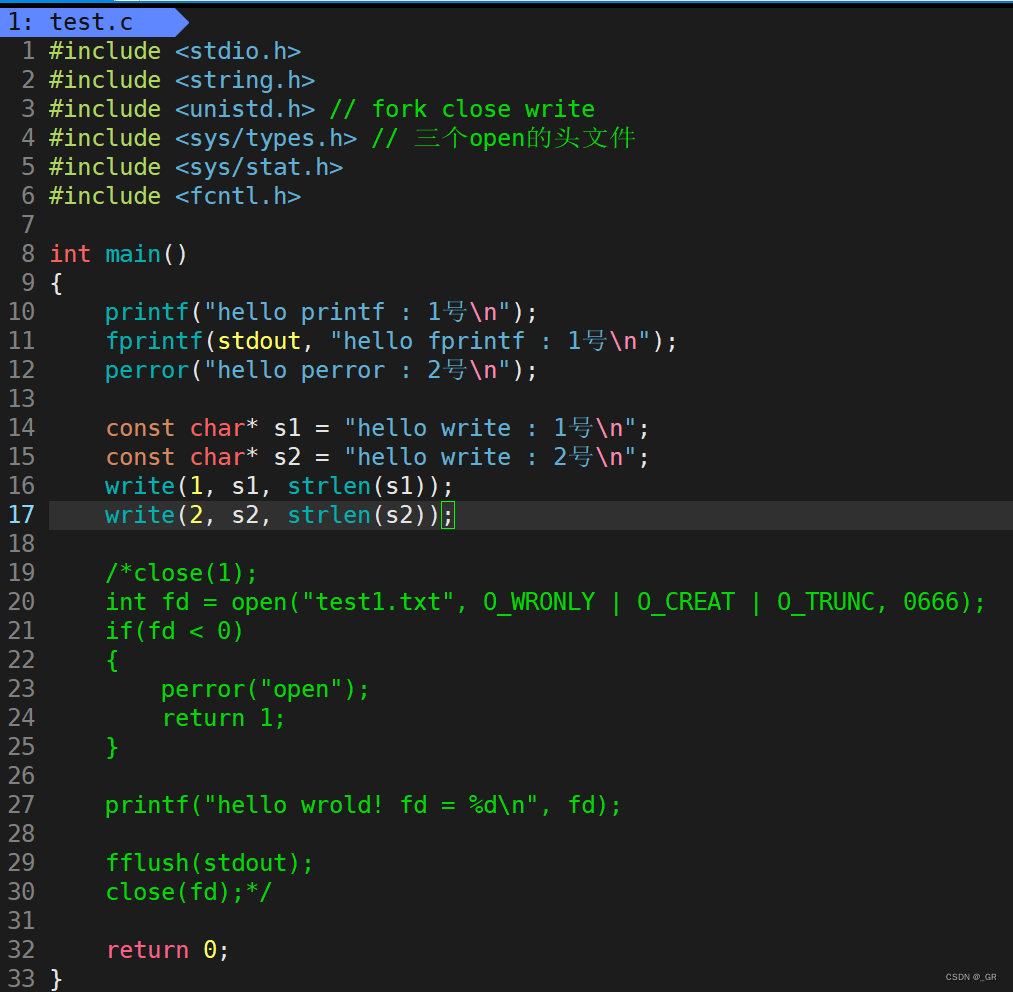
编译运行:

所以:stdout输出到磁盘文件,stderr在屏幕。
这也证明了1和2对应的都是显示器文件,都是向显示器打印,但是两个是不同的,相当于一个显示器文件被打开了两次。
据此特点,就有了下面的使用:
在Linux中,可以使用shell符号和重定向操作来分别控制stdout和stderr。例如,可以使用>符号将标准输出重定向到文件中,而2>符号将标准错误重定向到文件中。
例如,下面的命令将标准输出重定向到ok.txt文件中,而将标准错误重定向到error.txt文件中:

另外,我们也可以将错误消息和普通输出信息写到同一输出流中,通过在命令中使用2>&1语法,将错误信息发送到标准输出流。例如:
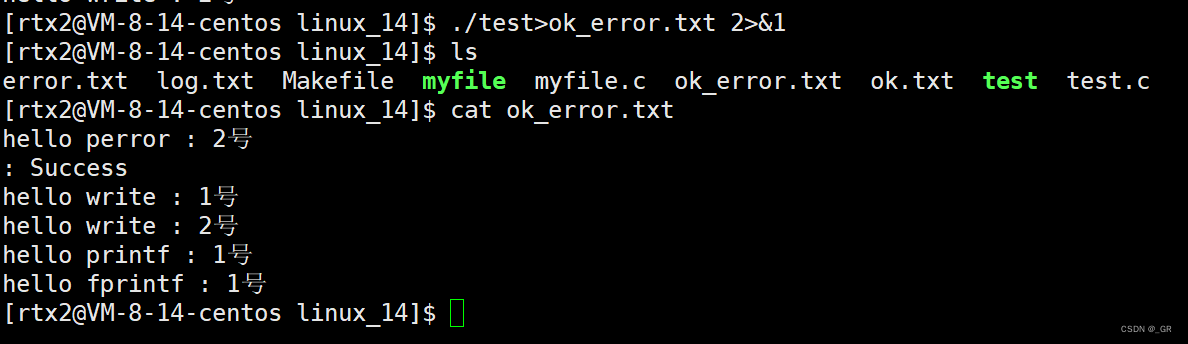
这里再看perror:perror应该是不用加\n的,上面写顺手了,后面打印的Success就是errno:

编译运行:

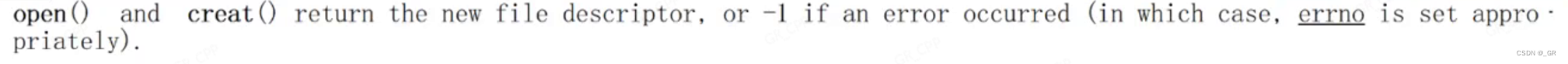
所以一些打开文件的函数接口,fopen等就是封装的open,open打开失败,errno被设置。
在平时我们看不见摸不着的缓冲区,此时便揭下了它神秘的面纱,它的位置,刷新策略,以及因为它而导致的种种异常现象,此时便都明白了。
2. 文件系统
前面学了打开文件,没有被打开的文件在哪呢?没有被打开的文件在磁盘上,称为磁盘级文件。
这些在磁盘上静静 "躺着" 的文件,又杂又乱,我们为什么要让它们躺在那占用磁盘空间呢?
因为这些文件还有可能被打开,磁盘级别的文件管理,本质工作和快递驿站的老板做的工作是一样的,对磁盘这个大空间的合理划分,让我们能快速定位查找到指定文件,乃至进行相关后续访问操作。这就是文件系统。
2.1 磁盘的物理结构CHS等
如果要理解文件系统,我们可以先看看磁盘。
磁盘是我们电脑上的唯一的一个机械设备,目前我们的笔记本上可能已经不用磁盘了,而是固态硬盘(SSD)。相对而言用起来更快,效率更高。固态硬盘是另一种存储的方案,和磁盘的存储差别很大,单价比磁盘大很多。一般的固态基本上比同等的磁盘要贵1倍。

来看它的物理结构,如上图所示,之所以叫做磁盘,是因为它是盘状的,而且不止一片,有很多片叠放在一起。右上图:
- 主轴和马达电机:在主轴上套着多张盘片,它们和轴相固定,通过马达电机来驱动这些盘片一起转动。
- 磁头:每一张盘片都有两个盘面,每一个盘面上都有一个磁头,该磁头是用来向磁盘中读写数据的。多个磁头也是叠放在一起的,它们的运动是一致的。
- 音圈马达:该马达驱动磁头组进行摆动,它可以从盘片的内圈滑到外圈,再结合盘片自身的转动,从而向磁盘读写数据。
CHS寻址:
以前硬盘容量比较小,人们采用软盘的设计结构来设计生产硬盘,
硬盘盘片的每一条磁道都具备相同的扇区数量,由此就产生了 CSH 3D 参数 (Disk Geomentry)
即 磁头数 (Heads),柱面数 (Cylinders) 和 扇区数 (Sectors) ,以及对应的 CHS 寻址模式。CHS 寻址模式是将硬盘划分为三个部分:磁头 (Heads)、柱面 (Cylinder)、扇区 (Sector) 。
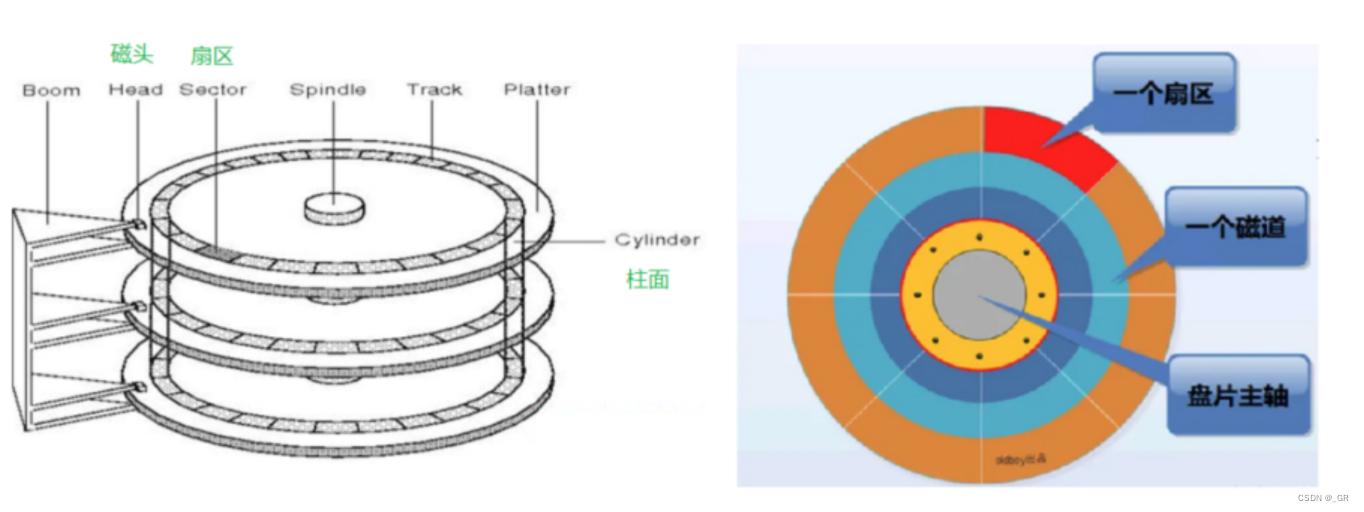
- 磁头:每张磁盘的正面和反面都有一个磁头,一个磁头对应着一张磁盘的一个面,因此,用第几个磁头就能表示数据在哪个盘面。
- 柱面:由所有磁盘中半径相同的同心磁道构成,在这一系列的磁道水质叠放在一起,就形成了一个柱面的形状。所以:柱面数 = 磁道数。
- 扇区:就是将磁盘划分为若干个小的区段,每个扇区虽然很小,但是看上去就像是一个 "扇子",所以称之为扇区。
每个扇区的大小是512K字节,所以内磁道的扇区密度高,外磁道的扇区密度低。
这样一来,我们就可以定位任意一个扇区,然后进行读写数据。比如,0号磁头,0号柱面,0号扇区,此时,磁头就会摆动到0号柱面处,当0号磁头对应的盘面中的0号磁道里的0号扇区旋转到磁头位置时,就可以向磁盘中读写数据。
CHS 寻址的最大容量由 CHS 三个参数所决定:
- 磁头数最大为 255,用 8 个二进制位存储,从 0 开始编号
- 柱面数最大为 1023,用 10 个二进制位存储,从 0 开始编号
- 扇区数最大数为 63,用 6 个二进制位存储,从 1 开始编号
磁盘上存储的基本单位是 扇区 (Sector),一般是 512 字节的。近三十年来,扇区的大小一直是 512 字节,但最近几年正迁移到更大、更高效的 4096 字节扇区,通常称为 4K 扇区。
读写磁盘的时侯,磁头找的是某一个面的某一个 磁道 (Traker),的某一个扇区 。
- 某一个面 → 哪一个磁头 (Head)
- 磁道指的是哪一个柱面 → 距离圆心的半径 → 哪一个磁头
- 扇区是磁道上的一段 → 盘面旋转决定的。
文件系统:什么文件,对应了几个磁盘块。
只要我们能找到磁盘上的盘面,柱面 (磁道) 和扇区,我们就能找到一个存储单元了。
用同样的方法,我们可以找到所有的基本单元。
所以,我们这种在物理上查找某一个扇区的寻址方式,叫做CHS地址。
机械式 + 外设 = 磁盘一定是很慢的 (CPU, 内存)
磁盘存储数据,磁性 N/S,改变 NS 极,就是改变了0/1。
你的文件数据就在这个盘面上。
2.2 磁盘的抽象结构LBA等
我们可以把对应的盘片,想象成为线性的结构,如同磁带被拉开:

我们把盘片想象成为线性的结构,当做数组:
定位一个 sector,只要找到下标就行了。对于磁盘的管理,转化成为了对数组空间的管理。类似于数组。磁盘上的每个扇区可以被看作是数组中的一个元素,而扇区的编号可以被看作是数组的索引。在这种情况下,可以使用索引来定位一个特定的扇区,就像在数组中使用索引来访问数组元素一样。磁盘管理的任务就变成了对这个线性结构(即盘片)的管理,包括读取和写入特定扇区的数据。例如,如果要读取或写入磁盘上的第5个扇区,就相当于访问数组中的第5个元素。通过索引,可以准确定位到特定的扇区,并进行相应的读取或写入操作。
这个抽象过程,仍然是 "先描述在组织"。
而这个下标,就是LBA (logic block arrays), 这是操作系统认为磁盘基本单元的地址,它是一种逻辑块地址。所以,未来你想在磁盘中写入:只需要将LBA地址映射转化成CHS地址,然后将该内存中的数据配合CHS地址写入到磁盘里,至此就完成了写入。
每个磁面上都有多个磁道,每个磁道上有多个扇区,类比磁带,扇区就可以看成一圈一圈缠绕在一起的。将缠绕在一起的扇区,像拉磁带一样全部拉出来,拉成一条直线。
多个磁面可以拉成多个直线,将所有面拉成的直线首尾相连组成一条长直线。
这条长直线可以看成一个数组,这个数组是以扇区为单位的,所以每个数组元素的大小是512K。
此时,磁盘就被我们抽象成了上图所示的数组,并且给每一个扇区进行编号。站在操作系统的角度,操作系统访问这个数组就是在访问磁盘。
那么这个数组的下标是怎么和磁盘的CHS对应起来的呢?

如上图所示,可以根据给定的逻辑数组下标转换成CHS定位法,定位到磁盘上具体的某个扇区。
其中,数组的下标被叫做逻辑块地址,就是LBA。操作系统使用的就是逻辑块地址来访问磁盘的。
在系统管理文件时记录繁琐的 CHS 是件很费力的事情,效果较低。
然而使用 逻辑扇区 (LBA) 后,可在磁盘读写操作时可以摆脱柱面、磁头等硬件参数的限制。
逻辑扇区,是为了方便操作系统读取写入硬盘数据而设置的,其大小与具体地址,都可以通过一定的公式与物理地址对应。操作系统可以根据 LBA 来读取和写入数据,而无需关心物理地址的具体映射方式。
在 LBA 模式下,操作系统可以把所有的物理扇区都按照某种方式或规则看作是一个线性编号的扇区,从 0 到某个最大值方式排列,并连成一条线。把 LBA 作为一个整体来看待,而不是具体到实际的 CHS 值,这样就只需要用一个序数就能确定唯一的物理扇区,这就是线性地址的由来。显然,线性地址是物理扇区的逻辑地址。
IO 的基本单位是 4 kb(blocks大小),磁盘的基本单位是 扇区 (常规为 512 字节),文件系统访问磁盘的基本单位是4 kb(为什么不是512字节?因为512字节太小了,会导致多次IO),整体 IO 效率提高,将磁盘的数据拷贝到内存花费的时间并不多,花费多的是在磁盘内部寻找位置的过程,该过程是寻址过程。不管磁盘是多少转,是永远无法比得上光电信号的。
采用LBA而不用CHS的原因:
- 便于管理,因为数组管理起来更加方便。
- 不想让操作系统的代码和硬件强耦合。
对如何管理文件,变成了对一个小组数据的管理。那么如何对一个组做管理?
2.3 文件管理inode等
我们使用 ll 命令时,除了能看到文件名,还能看到文件元数据:

每行包含七列,分别是:
模式、硬连接数、文件所有者、所属组、大小、最后修改时间和文件名。
ll 命令做的就是读取存储在磁盘上的文件信息,然后把它们显示出来。
这个信息除了通过这个方式来读取,还有可以通过 stat 命令看到更多的信息。
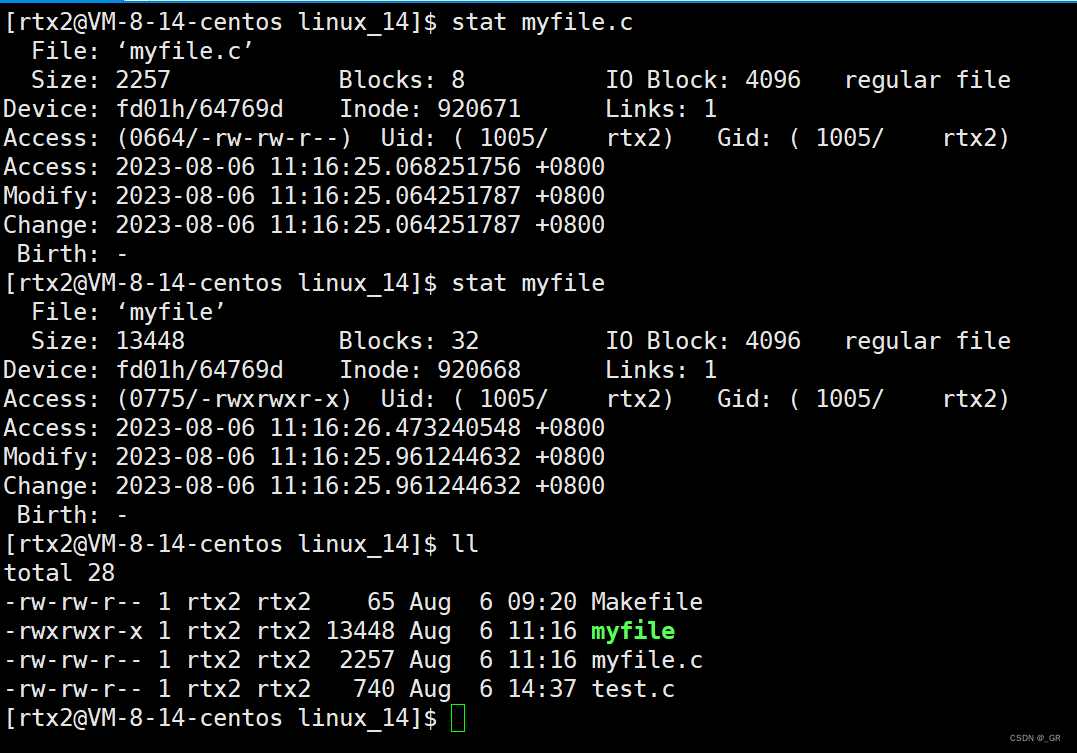
在讲解上面这些信息前,我们需要了解 inode等概念。
上面提到:对如何管理文件,变成了对一个小组数据的管理。那么如何对一个组做管理?
文件 = 内容 + 属性。其中内容和属性是分开管理的。
对一大块数据管理是很慢的,像管理国家一样,Linux采用分治的思想,慢慢地分成下面的小块:
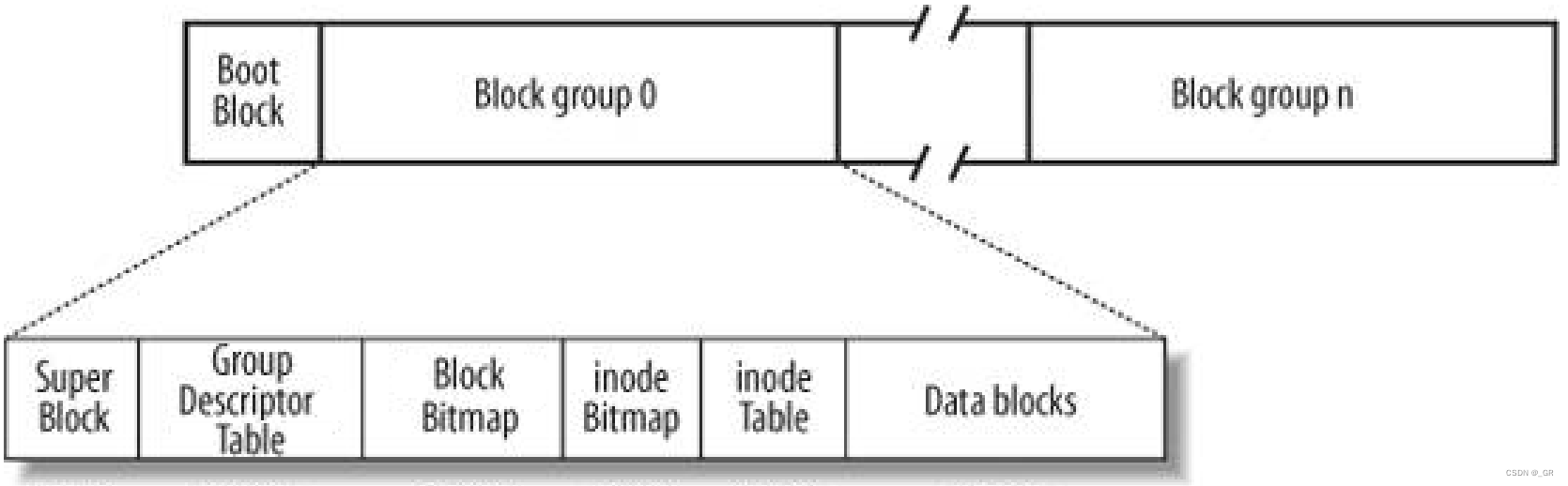
Linux ext2 文件系统,上图为磁盘文件系统图(内核中内存映像肯定有所不同):
磁盘是典型的块设备(IO 的基本单位是4kb即block大小),磁盘分区被划分为一个个小的 block。
一个 block 的大小是由格式化时决定的,并且不可修改。
例如 mke2fs 的 -b 选项可以设定 block 大小为 1024, 2048 或 4096 字节。
(mke2fs 是一个语法,用于建立 ext2 文件系统。(make ext2 file system))
上图中,启动块 (Boot Block) 的大小是确定的。
① 块组 (Block Group) :ext2 文件系统会根据分区的大小划分 Block Group。
每个 Block Group 都有着相同的结构组成。
② 超级块 (Super Block):存放文件系统本身的结构信息。记录的信息主要有:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。如果 Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了。
③ 块组描述符 (Group Descripter Table):GDT,描述块组(Block Group) 的属性信息。④ 块位图 (Block Bitmap):Block Bitmap 中记录 Data block中哪个数据块已经被占用,哪个数据块没有被占用。
⑤ inode 位图 (inode Bitmap) :每个 bit 标识一个 inode 是否空闲可用。
⑥ i 节点表(inode Table) :存放 "文件属性" 和 "文件大小","所有者"、"最近修改时间" 等。(inode是一个128字节的空间)
⑦ 数据区(Data blocks):多个4kb大小的集合,存放文件内容。
查看一个文件的 inode:ll -i

可以看到,每个文件都有一个独一无二的编号,这就是inode编号,这个编号其实就是一个结构体对象。每创建一个文件,就会在inode Table中申请一个未被使用的inode,并且将对应的位图置1。一个 inode (文件, 属性) 如何和属于自己的内容关联起来呢?在 inode table 内包括了文件的所有属性,其中有一个 blocks 数组,直接保存了该文件对应的 blocks 编号,我们 通过 blocks 编号就可以找到自己文件的内容。
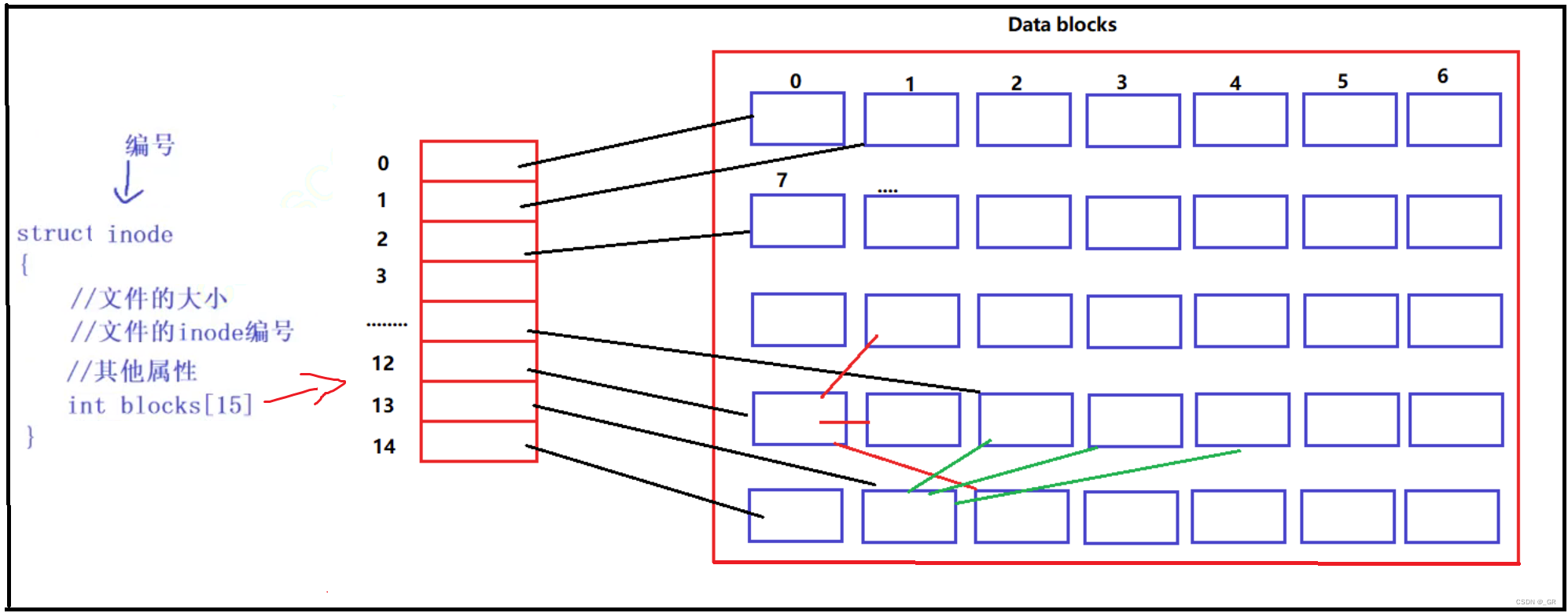
文件的内存就存储在这个Data blocks中,而这个块区中又有多个数据块,并且有相应的编号。
现在属性被存放好了,内容也被存放好了,下面就是将一个文件的属性和内容对应起来。
inode结构体中的数字blocks[15]就是干这个事情的。
数组中每个元素存放着一个一个数据块的block id(编号)。
每个数据块中存放着内容数据。
一个文件对应着一个ionde,该文件的内容存放在多个数据块中,所以inode中的数组中记录着这些数据块的block id。
这个数组一共才能放15个编号,如果这个文件的内容有很多呢,需要很多的数据块(超出了15个)呢?
数组最后的三个位置,下标为12,13,14,它们存放的数据块编号所指向的数据块中存放的不是文件内容,同样是属于该文件数据块的编号。
虽然一个数组中的一个元素只能存放一个数据块的下标,但是指向的数据块中可以存放多个数据块的下标,这样一来,再大的文件也能存放的下。
每使用一个数据块,就会将它所对应的位图置1。
现在我们知道了文件在磁盘上是如何存放的,以及操作系统是如何管理它们的。根据前面所讲,inode是文件的唯一标识,但是我们在使用文件的时候并没有使用inode啊,我们使用的是文件名,这是为什么?
一个目录中,可以包含多个文件,但是这些文件的名字不能重。
目录也是文件,它也有自己的inode,也有自己的数据块。
目录的data blocks中存放的是:它所包含文件的文件名和inode之间的映射关系。所以我们在使用一个文件的文件名时,就会自动映射到它的inode,本质上还是在使用一个文件的inode。
此时我们就清楚了为什么inode中包含文件的所有属性,但是就是没有文件名了,因为文件的文件名和它对应的inode存在上级目录的data blocks中。
所以,文件名:inode 编号的映射关系。文件名和 inode 编号是数据,最终保存在了目录内容中。Linux 同一个目录下可以创建多个同名文件吗?不行。所以,文件名本身就是一个具有Key值的东西(其实文件名和inode是互为Key值的),是一对一的关系
2.4 对文件的操作
当我们创建一个文件,操作系统做了什么?
操作系统在创建文件的时候,会向inode Table中申请为被使用的inode,
并且将相应的inode Bitmap置1,然后将该文件的各种属性存入到inode中。
还会将这个文件的文件名和inode的映射关系写入到上级目录的data blocks中。
创建一个新文件,操作系统主要会做如下四个操作:
① 存储属性:内核找到一个空闲的 i 结点 (这里是 263466),内核把文件信息记录到其中。
② 存储数据:该文件需要存储在三个磁盘块,内核找到了三个空闲块,300,500,800。将内核缓冲区的第一块数据复制到300,下一块复制到500,最后复制到800,以此类推。
③ 记录分配情况:文件内容按顺序 300,500,800 存放,内核在 inode 上的磁盘分布区记录了上述块列表。
④ 添加文件名到目录:新的文件名 abc。Linux 在当前目录中记录该文件,通过内核将入口 (263466, abc) 添加到目录文件,文件名和 inode 之间的对应关系将文件名和文件的内容及属性链接起来。
当我们向文件中写入,操作系统做了什么?
操作系统根据文件名和inode的映射关系,找到文件对应的inode。
根据inode中blocks数组,找到存放文件内容的数据块进行数据的写入,如果发生数据块数量上的变化,还要将对应的Blocks Bitmap位图的相应位改变。
再改变inode中对应的属性信息。
当我们读取文件内容时,操作系统做了什么?
操作系统根据文件名和inode的映射关系,找到文件对应的inode。
再从inode中找到文件对应的数据块。
将数据块中内容加载到内存中供进程使用。
当我们删除一个文件,操作系统做了什么?
操作系统根据文件名和inode的映射关系,找到文件对应的inode。
再根据inode找到数据块所对应的Blocks Bitmap,将对应位清0。
最后再将inode对应的inode Bitmap清0。
文件的删除并不会去清理磁盘上数据块中的内容,只是将对应的位图清0,后续再来的内容进行覆盖就可以。这也是为什么拷贝一个文件比较慢,但是删除一个文件很快的原因。当你误删一个文件的时候,最好的做法就是什么都不要做,只要对应的inode和data blocks没有被覆盖,这个文件时可以恢复的。
所以,这实际上是一个伪删除。
如果我们把文件删了,我们可以恢复这个文件,如果要 恢复文件只需要搞到曾经删除的 inode 值就行了。通过一些工具,将 bitmap 从 0 恢复成 1 就可以了。
此外,在某些情况下,操作系统也可能使用一些特殊的工具来覆盖文件的数据,以确保文件内容不可恢复。这种覆盖方式被称为安全删除或彻底删除。
恢复的最大难点:文件都删掉了,你怎么知道 inode 是多少呢?Linux 系统为了支持恢复,inode 编号会保存在系统的日志文件中的。恢复有点难度。
实际上 Windows 也是这样的,几乎所有的文件系统删文件都不会真的删文件。
学了软硬链接回来看:
当我们执行删除文件操作时,操作系统实际上会在文件系统的目录结构中删除该文件的目录项,并将该文件的 inode 节点中的链接数减 1。如果链接数变为 0,则该文件的数据块将被释放,并将 inode 节点标记为可用状态。
然而,删除文件并不意味着文件的数据就被立即清除,因为该文件可能被其他进程或操作系统本身仍然使用或打开。因此,只有当该文件的所有链接数都为 0 时,文件的数据才会被完全清除。
如此一来,磁盘的一个分组就能被操作系统井井有条的管理好了,这也意味着整个磁盘也就被管理好了。虽然文件系统的讲解更多的是理论,但是这对于我们更好的理解文件系统有很大的帮助,尤其是每个分组中的那个六个区域至关重要。
本篇完。
文件系统的知识对下一篇的内容还是挺重要的。
下一篇:零基础Linux_15(基础IO_文件)软硬链接+动静态库详解+基础IO相关题目
相关文章:

零基础Linux_14(基础IO_文件)缓冲区+文件系统inode等
目录 1. 缓冲区 1.1 缓冲区的存在 1.2 缓冲区的刷新策略 1.3 模拟C标准库中的文件操作 完整代码及验证: 1.4 重看缓冲区 1.5 stdout和stderr的区别 2. 文件系统 2.1 磁盘的物理结构CHS等 2.2 磁盘的抽象结构LBA等 2.3 文件管理inode等 2.4 对文件的操作…...

Vue中的router路由的介绍(快速入门)
路由的介绍 文章目录 路由的介绍1、VueRouter的介绍2、VueRouter的使用(52)2.1、5个基础步骤(固定)2.2、两个核心步骤 3、组件存放的目录(组件分类) 生活中的路由:设备和ip的映射关系(路由器) V…...

ESP-07S进行TCP 通信测试
一,TCP Server 为 AP 模式,TCP Client 为 Station 模式。 这里电脑pc作为TCP Server,ESP-07S作为TCP Client 。 二,电脑端配置。 1,开启热点。 2,转到“设置”,编辑热点信息。 3,关闭…...

如何找到新媒体矩阵中存在的问题?
随着数字媒体的发展,企业的新媒体矩阵已成为品牌推广和营销的重要手段之一。 然而,很多企业在搭建新媒体矩阵的过程中,往往会忽略一些问题,导致矩阵发展存在潜在风险,影响整个矩阵运营效果。 因此,找到目前…...

MongoDB-基本常用命令
基本常用命令 MongoDB常用命令a) 案例需求b) 数据库操作b.1) 选择和创建数据库b.2) 删除数据库 c) 集合操作c.1) 集合的显示创建c.2) 集合的隐式创建c.3) 集合的删除 d) 文档基本CRUDd.1) 文档的插入(1) 单个文档的插入(2) 批量插入 d.2) 文档的基本查询(1) 查询所有(2) 投影查…...

Linux 常用systemctl service 脚本
文章目录 1. jar 包部署 service 脚本2. nginx 服务安装 脚本3.artemis 服务安装脚本 1. jar 包部署 service 脚本 默认jdk 执行: [Service] Typesimple Userroot WorkingDirectory/opt/app/webserver ExecStart/usr/bin/java -Xms512m -Xss256k -jar /opt/app/we…...

flask-sqlalchemy实现读写分离完整版
1. 依赖版本: alembic==1.6.5 click==8.0.1 colorama==0.4.4 Flask==1.1.2 Flask-Migrate==2.7.0 Flask-Script==2.0.6 Flask-SQLAlchemy==2.4.4 greenlet==1.1.0 itsdangerous==2.0.1 Jinja2==3.0.1 Mako==1.1.4 MarkupSafe==2.0.1 protobuf==3.17.3 PyMySQL==1.0.2 python-…...
windows下在cmd和git bash中执行bash download.sh失败
cmd报错信息: 解决办法: win64-wget-1.21.4 安装软件wget,如下这是64位的包,解压后,下面有个wget.exe,拷贝到C:\Windows\System32、 然后打开cmd,执行wget -V 如上,有版本信息就O…...

rust流程控制
一、分支 (一)if 1.if 语法格式 if boolean_expression { }例子 fn main(){let num:i32 5;if num > 0 {println!("正数");} }条件表达式不需要用小括号。 条件表达式必须是bool类型。 2.if else 语法格式 if boolean_expression { } …...
虚拟机软件Parallels Desktop 19 mac功能介绍
Parallels Desktop 19 mac是一款虚拟机软件,它允许用户在Mac电脑上同时运行Windows、Linux和其他操作系统。Parallels Desktop提供了直观易用的界面,使用户可以轻松创建、配置和管理虚拟机。 PD19虚拟机软件具有快速启动和关闭虚拟机的能力,让…...

在工业机器视觉领域中应用钡铼技术有限公司的EtherCAT网关
钡铼技术有限公司作为一家专注于业物联网关、工业智能网关、边缘计算网关、ARM嵌入式工业计算机、PLC远程采集网关、Modbus转MQTT网关、OPC UA网关、BACnet网关路由器、Lora网关、工业4G边缘路由器、4G无线远程数据采集模块、4G DTU RTU、以太网远程IO模块、工业总线分布式I/O模…...

ssh指定的密钥协商方式以及Ansible的hosts文件修改密钥协商方式
一、首先你要知道用什么加密协商。 [WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details 10.10.2.190 | UNREACHABLE! > {"changed": false,"msg": "Failed to connect to the host via ssh: U…...

NLP 项目:维基百科文章爬虫和分类【01】 - 语料库阅读器
自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。 一、说明 该文是系列文章,揭示如何对爬取文…...

QT sqlite的简单用法
1、相关头文件 #include <QSqlDatabase> #include <QSqlError> #include <QSqlQuery> #include <QSqlRecord> #include <QSqlIndex> #include <QSqlField> #include <QFile> #include <QDebug> 2、数据库对象 QSqlDatabas…...
大模型部署手记(12)LLaMa2+Chinese-LLaMA-Plus-2-7B+Windows+text-gen+中文对话
1.简介: 组织机构:Meta(Facebook) 代码仓:https://github.com/facebookresearch/llama 模型:chinese-alpaca-2-7b-hf 下载:使用百度网盘下载 硬件环境:暗影精灵7Plus Windows版…...

C#导出本机Win32native dll
C# 使用 "3f/DllExport" 工具导出C风格的本机函数 [文 / 张赐荣] 首先,让我们来了解一下什么是争渡读屏软件,以及什么是争渡文本预处理API。争渡读屏软件是一款屏幕朗读软件,用于协助视力障碍人士操作电脑。 争渡文本预处理API是一…...
express-generator快速构建node后端项目
express-generator是express官方团队开发者准备的一个快速生成工具,可以非常快速的生成一个基于express开发的框架基础应用。 npm安装 npm install express-generator -g初始化应用 express my_node_test 创建了一个名为 my_node_test 的express骨架项目通过 Exp…...
视频监控系统/视频汇聚平台EasyCVR如何反向代理进行后端保活?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
金融信创黄金三年:小程序生态+跨端技术框架构建
小程序应用场景生态的发展,受益于开源技术的发展,以及响应快速开发的实际业务需求,一些跨端框架如:Electron、wxPython、FinClip、Tauri、Flutter等发展也非常迅速,小程序生态跨端技术框架,不仅能满足自有超…...
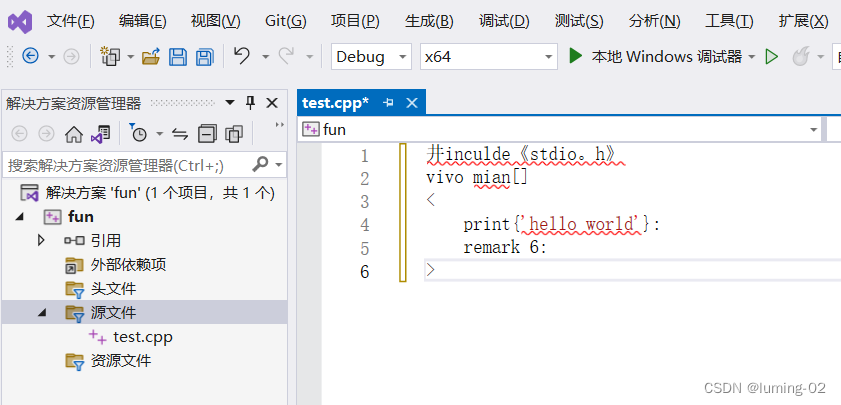
这短短 6 行代码你能数出几个bug?
前言:本文仅仅只是分享笔者一年前见到的诡异代码,大家可以看看乐子,随便数一数一共有多少个bug,这数bug多少还是要点水平的 在初学编程的时候,写的第一个代码大多都是 hello world,可是就算是 hello world…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

AI攻防时间差:当漏洞发现速度碾压修复速度— 聚焦技术核心
AI攻防时间差:当漏洞发现速度碾压修复速度 — 聚焦技术核心 引言:当两个世界碰撞 2026年5月,对于网络安全领域而言,是一个具有分水岭意义的月份。 一边是360人工智能安全研究院在5月12日发布的重磅报告,首次提出**“AI…...

OpenClaw量化回测性能调优指南:从数据加载到并行计算的实战优化
1. 项目概述:从开源工具到性能调优的艺术最近在跟几个做量化交易的朋友聊天,他们都在为一个问题头疼:策略回测和实盘执行的速度。动辄几十个G的历史数据,复杂的因子计算,加上高频的模拟交易,一套流程跑下来…...
,法务已验证)
企业采购必读:ElevenLabs合同中6处关键条款陷阱(含地域限制、转授权失效、审计权模糊等),法务已验证
更多请点击: https://intelliparadigm.com 第一章:企业采购必读:ElevenLabs合同中6处关键条款陷阱(含地域限制、转授权失效、审计权模糊等),法务已验证 地域限制条款的隐性封锁效应 ElevenLabs服务协议第…...

AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来!
AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来! 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Tab…...

面向科学计算Agent的Harness数值稳定性校验
面向科学计算Agent的Harness数值稳定性校验关键词:科学计算Agent、Harness框架、数值稳定性校验、数值误差溯源、Agent-数值系统交互、可复现科学、边界条件自动化测试摘要:随着大语言模型(LLM)与多模态AI的崛起,科学计…...

qt中自定义槽函数 内部继承逻辑、GUI+CLI协同1.0
bit::Shadow✧(≖ ◡ ≖✿ 目录 qt配置环境 QWidget父类 子类构造函数内显示调用父类构造函数 QT内核分析 自定义槽函数 GUI(图形化实现) Ⅰ按钮 Ⅱ右键按钮转到槽函数实现 CLI(命令行界面) Ⅲ功能槽(slot&a…...

嵌入式TFT屏幕LVGL驱动适配:从硬件抽象到性能优化的全流程实践
1. 项目概述与核心价值最近在几个嵌入式显示项目里,我深度折腾了TFT屏幕与LVGL的适配工作。这活儿听起来像是把两个现成的轮子装到一起,但真上手了才发现,从点亮屏幕到丝滑流畅的UI交互,中间隔着不少“坑”。如果你也在为STM32、E…...
Transit Map:让公共交通可视化变得简单有趣的工具
Transit Map:让公共交通可视化变得简单有趣的工具 【免费下载链接】transit-map The server and client used in transit map simulations like swisstrains.ch 项目地址: https://gitcode.com/gh_mirrors/tr/transit-map 还在为复杂的交通网络数据可视化而烦…...

高性能小程序跨框架迁移方案:miniprogram-to-vue3自动化转换架构设计与最佳实践
高性能小程序跨框架迁移方案:miniprogram-to-vue3自动化转换架构设计与最佳实践 【免费下载链接】miniprogram-to-vue3 项目地址: https://gitcode.com/gh_mirrors/mi/miniprogram-to-vue3 随着前端技术生态的快速发展,微信小程序向Vue3/Uniapp3…...