【手写数字识别】数据挖掘实验二
文章目录
- Ⅰ、项目任务要求
- 任务描述:
- 主要任务要求(必须完成以下内容但不限于这些内容):
- II、实现过程
- 数据集描述
- 实验运行环境描述
- KNN模型
- 决策树模型
- 朴素贝叶斯模型
- SVM模型
- 不同方法对MNIST数据集分类识别结果分析(不同方法识别对比率表及结果分析)
- 完整代码
用PyTorch实现MNIST手写数字识别(最新,非常详细)
Ⅰ、项目任务要求
任务描述:
-
图像识别(Image Recognition)是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术。 图像识别的发展经历了三个阶段:文字识别、数字图像处理与识别、物体识别。机器学习领域一般将此类识别问题转化为分类问题。
-
手写识别是常见的图像识别任务。计算机通过手写体图片来识别出图片中的字,与印刷字体不同的是,不同人的手写体风格迥异,大小不一,造成了计算机对手写识别任务的一些困难。 数字手写体识别由于其有限的类别(0~9共10个数字)成为了相对简单的手写识别任务。
-
此实验内容:分别采用决策树、KNN、朴素贝叶斯、SVM、BP、softmax、adaboost、袋装八种浅层学习分类方法中的任意二种方法(适于二人组)或 三种(适于三人组)对MNIST公共数据集、HWDG私有数据集进行分类,并写出实验结果分析。
-
说明:也可以多选方法做,比如四种、五种等。
主要任务要求(必须完成以下内容但不限于这些内容):
- 1、采用MNIST公共数据集;
或采用HWDG数据集为私有数据集,用爬虫工具或手工制作,有0-9手写数字共10类,样本总数不少于60个(相当于找60个人,每人都手写0-9数字,分别做好标签存成图片后再制成样本集。) - 2、简述算法思想和实现原理。
- 3、写出实验结果分析:
-
(1) 数据集描述。包括数据集介绍、训练集和测试集介绍等。
-
(2) 实验运行环境描述。如开发平台、编程语言、调参情况等。
-
(3) 不同方法对MNIST数据集分类识别结果分析(不同方法识别对比率表及结果分析),例如:
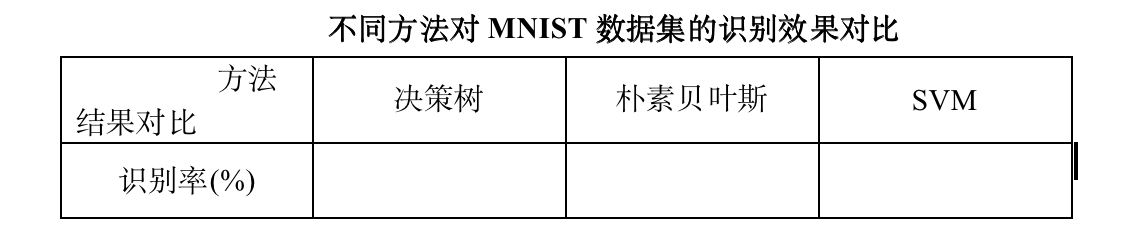
-
(4) 不同方法对HWDG数据集分类识别结果分析(不同方法识别率对比表及结果分析)。结果对比表如上表格式所示。
-
II、实现过程
数据集描述
- MNIST是一个包含数字0~9的手写体图片数据集,图片已归一化为以手写数 字为中心的28*28规格的图片。
- MNIST由训练集与测试集两个部分组成,各部分 规模如下:
- 训练集:60,000个手写体图片及对应标签
- 测试集:10,000个手写体图片及对应标签

import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_scoreimport torch
import numpy as np
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.nn.functional as F"""
卷积运算 使用mnist数据集,和10-4,11类似的,只是这里:1.输出训练轮的acc 2.模型上使用torch.nn.Sequential
"""
# Super parameter ------------------------------------------------------------------------------------
batch_size = 64
learning_rate = 0.01
momentum = 0.5
EPOCH = 10# Todo:数据集准备 ------------------------------------------------------------------------------------
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# softmax归一化指数函数(https://blog.csdn.net/lz_peter/article/details/84574716),其中0.1307是mean均值和0.3081是std标准差train_dataset = datasets.MNIST(root='./data/demo2', train=True, transform=transform,download=True) # 本地没有就加上download=True
test_dataset = datasets.MNIST(root='./data/demo2', train=False, transform=transform,download=True) # train=True训练集,=False测试集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 展示数据(12个)
fig = plt.figure()
for i in range(12):plt.subplot(3, 4, i + 1)plt.tight_layout()plt.imshow(train_dataset.train_data[i], cmap='gray', interpolation='none')plt.title("Labels: {}".format(train_dataset.train_labels[i]))plt.xticks([])plt.yticks([])
plt.show()
实验运行环境描述
- 开发平台
- 编程语言
- 调参情况
KNN模型
KNN模型简介
KNN(K-Nearest Neighbors)算法是一种基本的机器学习方法,用于分类和回归问题。它的核心思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法的步骤包括:计算待分类样本与训练集中样本的距离,选取距离最近的k个样本,根据这k个样本的类别进行投票(分类问题)或求平均(回归问题),将得票最多的类别或平均值作为待分类样本的预测类别或值。
- 优点:简单易懂,适用于小规模数据集,不需要训练过程,适用于多种类型的数据(数值型、离散型等)。
- 缺点:计算复杂度高,尤其在高维数据集上,存储空间大,对异常值敏感。
总之,KNN是一种直观、易于理解的算法,但在处理大规模高维度数据时性能可能受限。
调整的参数
KNN模型主要用到一个参数,即K值,它表示在预测时要考虑多少个最近邻居的信息。K值的选择对KNN模型的性能有很大影响。较小的K值会使模型更加敏感,容易受到噪声的影响,而较大的K值会使模型更加平滑,减小了波动。
- 选择合适的K值通常使用交叉验证(Cross Validation)的方法。在交叉验证中,将训练数据分成多个折叠(folds),然后使用其中一部分数据作为验证集,剩余的部分作为训练集,多次训练模型并计算模型在验证集上的性能。
- 通过比较不同K值下模型的性能,选择在验证集上性能最好的K值。
除了K值,KNN模型还可以使用不同的距离度量方法。在默认情况下,通常使用欧氏距离(Euclidean distance)作为距离度量,但可以根据具体问题选择其他距离度量方法,例如曼哈顿距离(Manhattan distance)或闵可夫斯基距离(Minkowski distance)等。不同的距离度量方法会影响模型的性能,因此在选择距离度量方法时也需要进行实验和比较。
# 准备数据
X_train = train_dataset.train_data.numpy().reshape(-1, 28 * 28) # 将图像展平成一维数组
y_train = train_dataset.train_labels.numpy()
X_test = test_dataset.test_data.numpy().reshape(-1, 28 * 28)
y_test = test_dataset.test_labels.numpy()# 初始化并训练KNN模型
knn_classifier = KNeighborsClassifier(n_neighbors=3) # 选择邻居数为3
knn_classifier.fit(X_train, y_train)# 预测并评估模型
y_pred = knn_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("KNN 模型在测试集上的准确率: {:.2f}%".format(accuracy * 100))
决策树模型
决策树模型简介
决策树模型是一种用于解决分类和回归问题的机器学习算法,模拟人类决策过程。它通过一系列特征判断将数据集分割成不同子集,最终确定数据属于哪个类别或预测数值。决策树由节点、边和叶节点组成,通过选择特征、递归划分和叶节点分类或回归构建。具有易解释性和适用性广泛的特点,但需要注意防止过拟合问题。
调整的参数
决策树模型有许多参数可以调整,不同的参数设置可以影响模型的性能和泛化能力。以下是一些常见的决策树模型参数,你可以根据具体的问题和数据集来调整它们:
-
树的深度(max_depth): 决定树的最大深度。如果设置得太大,容易过拟合;设置得太小,容易欠拟合。
-
最小分割样本数(min_samples_split): 一个节点在分裂前必须有的最小样本数。如果节点的样本数少于这个值,就不会再分裂。
-
叶节点的最小样本数(min_samples_leaf): 一个叶节点必须有的最小样本数。如果一个叶节点的样本数少于这个值,该叶节点会和兄弟节点一起被剪枝。
-
最大特征数(max_features): 在寻找最佳分割时考虑的特征数。可以是固定的整数,也可以是一个比例。
-
节点分裂的标准(criterion): 衡量节点纯度的方法,可以是基尼指数(‘gini’)或信息增益(‘entropy’)。
-
决策树数量(n_estimators): 仅在集成方法(如随机森林)中使用,指定树的数量。
-
学习率(learning_rate): 仅在梯度提升树(Gradient Boosting Trees)中使用,控制每棵树的贡献程度。
-
子采样比例(subsample): 仅在梯度提升树中使用,表示每棵树所使用的样本比例。
-
正则化参数(alpha): 控制树的复杂度,用于防止过拟合。
这些参数的最佳取值通常依赖于具体的数据集和问题。可以使用交叉验证等技术来选择最佳的参数组合,以提高模型的性能和泛化能力。
print("Training Decision Tree Classifier...")
decision_tree_classifier = DecisionTreeClassifier(random_state=42)
decision_tree_classifier.fit(X_train, y_train)# Predict and evaluate the model
y_pred = decision_tree_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Decision Tree Classifier Accuracy: {:.2f}%".format(accuracy * 100))
朴素贝叶斯模型
SVM模型
不同方法对MNIST数据集分类识别结果分析(不同方法识别对比率表及结果分析)
评估模型方法(准确率)
分类结果分析
完整代码
相关文章:
【手写数字识别】数据挖掘实验二
文章目录 Ⅰ、项目任务要求任务描述:主要任务要求(必须完成以下内容但不限于这些内容): II、实现过程数据集描述实验运行环境描述KNN模型决策树模型朴素贝叶斯模型SVM模型不同方法对MNIST数据集分类识别结果分析(不同方法识别对比率表及结果分析) 完整代…...

什么是云计算?云计算简介
其实“云计算”作为一个名词而言,那是相当成功滴。很多人都有听过。但提及云计算”具体是什么?很多人,知其然,却不知其所以然! 利用软件将这些成千上万不可靠的硬件组织成一个稳定可靠的IT系统,以此支撑其公司的IT基础服务。这家…...
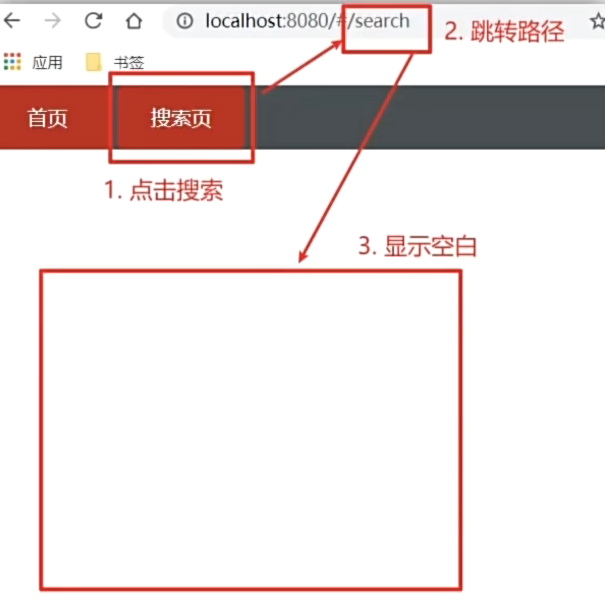
Vue路由进阶--VueRouter声明式导航
Vue路由进阶–VueRouter声明式导航 文章目录 Vue路由进阶--VueRouter声明式导航1、声明式导航1.1、导航链接1.2、高亮类名1.3、跳转传参1.4、动态路由参数可选符 1、声明式导航 1.1、导航链接 需求:实现导航高亮效果 vue-router提供了一个全局组件router-link(取…...
Oracle 云服务即将支持 PostgreSQL!
2023 年 9 月 19 日,Oracle 产品团队发布了一篇文章,宣布 Oracle 云基础架构(OCI)开始提供 PostgreSQL 服务。目前支持的版本为 PostgreSQL 14.9,提供有限支持,12 月份将会提供正式版本。 众所周知&#x…...

数字孪生项目:突破技术难关,引领未来发展
项目背景 数字孪生技术一直在不断发展,为企业提供了无限的潜力和机会。在这个数字时代,公司需要不断进化,以适应市场的需求和客户的期望。北京智汇云舟一直以“视频孪生”为标签,是数字孪生领域的头部企业,拥有强大的…...

MySQL 如何使用离线模式维护服务器
离线模式 作为 DBA,最常见的任务之一就是批量处理 MySQL 服务的启停或其他一些活动。在停止 MySQL 服务前,我们可能需要检查是否有活动连接;如果有,我们可能需要把它们全部杀死。通常,我们使用 pt-kill 杀死应用连接或…...

期权开户流程合集——期权开户的操作步骤
最详细的期权开户流程介绍是怎样的,下文为大家介绍期权开户流程合集——期权开户的操作步骤的知识点,希望对读者有所帮助,期权开户流程和方式分两种,一种券商,一种期权分仓平台,有啥区别下文揭秘。本文来自…...

mysql改造oracle,以及项目改造
mysql改造oracle,以及springboot项目改造 oracle改造说明 这次的任务是springboot mysql版本改造为oracle版本,mysql5.7,oracle11.2,springboot2.0.2(springboot版本无所谓,都差不多,自己记录…...

利用互斥锁实现多个线程写一个文件
代码 #include <stdio.h> #include <pthread.h> #include <string.h> #include <unistd.h>FILE *fp;//线程函数1 void *wrfunc1(void *arg); //线程函数2 void *wrfunc2(void *arg); //线程函数3 void *wrfunc3(void *arg);//静态创建互斥锁 pthread_…...

【m98】视频缓存PacketBuffer 1 : SeqNumUnwrapper int64映射、ForwardDiff
视频缓存PacketBuffer 对rtp包进行接收处理。 rtp序号 相关 【mediasoup】RtpStreamRecv 对rtp 序号的验证 与这里的处理有不同。...

day58:ARMday5,GPIO流水灯实验
汇编指令: .text .global _start _start: 1.设置GPIOE GPIOF寄存器的时钟使能 RCC_MP_AHB4ENSETR[5:4]->1 0x50000a28 LDR R0,0x50000a28 LDR R1,[R0] ORR R1,R1,#(0x3<<4) STR R1,[R0]2.设置PE10、PF10、PE8管脚为输出模式,GPIOE_MODER[21…...
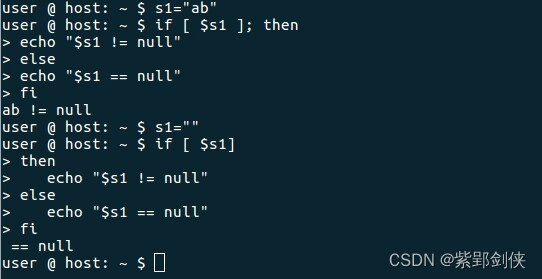
Linux shell编程学习笔记9:字符串运算 和 if语句
Linux Shell 脚本编程和其他编程语言一样,支持算数、关系、布尔、字符串、文件测试等多种运算,同样也需要进行根据条件进行流程控制,提供了if、for、while、until等语句。 上期学习笔记中我们研究了字符串数据的使用,今天我们研…...

【分享】xpath的属性表达式
在XPath中,要选择HTML文档中具有特定类的元素,您通常需要使用属性选择器 [attribute-nameattribute-value] 来选择元素,其中 attribute-name 是属性名称,attribute-value 是要匹配的属性值。对于HTML元素的类选择器,您…...
)
Oracle Dataguard跨版本数据迁移(11.2.0.4~19.13.0.0)
一、前期准备 按照DG部署步骤修改DG参数、添加standby redo log、配置静态监听、配置tnsnames文件、备端修改参数文件、创建所需目录等配置好部署环境,这里不再赘述,跟正常部署DG无区别。 环境配置好后,进行后面的操作。 二、使用RMAN备份复…...

零基础Linux_14(基础IO_文件)缓冲区+文件系统inode等
目录 1. 缓冲区 1.1 缓冲区的存在 1.2 缓冲区的刷新策略 1.3 模拟C标准库中的文件操作 完整代码及验证: 1.4 重看缓冲区 1.5 stdout和stderr的区别 2. 文件系统 2.1 磁盘的物理结构CHS等 2.2 磁盘的抽象结构LBA等 2.3 文件管理inode等 2.4 对文件的操作…...

Vue中的router路由的介绍(快速入门)
路由的介绍 文章目录 路由的介绍1、VueRouter的介绍2、VueRouter的使用(52)2.1、5个基础步骤(固定)2.2、两个核心步骤 3、组件存放的目录(组件分类) 生活中的路由:设备和ip的映射关系(路由器) V…...

ESP-07S进行TCP 通信测试
一,TCP Server 为 AP 模式,TCP Client 为 Station 模式。 这里电脑pc作为TCP Server,ESP-07S作为TCP Client 。 二,电脑端配置。 1,开启热点。 2,转到“设置”,编辑热点信息。 3,关闭…...

如何找到新媒体矩阵中存在的问题?
随着数字媒体的发展,企业的新媒体矩阵已成为品牌推广和营销的重要手段之一。 然而,很多企业在搭建新媒体矩阵的过程中,往往会忽略一些问题,导致矩阵发展存在潜在风险,影响整个矩阵运营效果。 因此,找到目前…...

MongoDB-基本常用命令
基本常用命令 MongoDB常用命令a) 案例需求b) 数据库操作b.1) 选择和创建数据库b.2) 删除数据库 c) 集合操作c.1) 集合的显示创建c.2) 集合的隐式创建c.3) 集合的删除 d) 文档基本CRUDd.1) 文档的插入(1) 单个文档的插入(2) 批量插入 d.2) 文档的基本查询(1) 查询所有(2) 投影查…...

Linux 常用systemctl service 脚本
文章目录 1. jar 包部署 service 脚本2. nginx 服务安装 脚本3.artemis 服务安装脚本 1. jar 包部署 service 脚本 默认jdk 执行: [Service] Typesimple Userroot WorkingDirectory/opt/app/webserver ExecStart/usr/bin/java -Xms512m -Xss256k -jar /opt/app/we…...

101. 如何通过 Rancher Manager 收集指标
Environment 环境 Rancher 2.10 牧场主 2.10 Procedure 程序Rancher support might ask you to collect the Prometheus metrics for the cattle-cluster-agent. 牧场主支持可能会让你收集牛群集群代理的普罗米修斯指标。 They are available through the Rancher local clu…...

如何高效突破Cursor试用限制:全功能AI编程助手解锁指南
如何高效突破Cursor试用限制:全功能AI编程助手解锁指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...
)
手把手教你用llama.cpp在树莓派上跑大模型(附完整配置流程)
在树莓派上部署llama.cpp的完整实践指南 树莓派作为一款价格亲民且功能强大的微型计算机,近年来在边缘计算和嵌入式AI领域崭露头角。本文将详细介绍如何在树莓派上部署llama.cpp这一轻量级大语言模型推理框架,让开发者能够在资源受限的环境中体验前沿AI技…...

S2-Pro模型推理服务高可用部署:基于Docker与Kubernetes的架构
S2-Pro模型推理服务高可用部署:基于Docker与Kubernetes的架构 1. 为什么需要高可用部署 在实际生产环境中,AI模型推理服务的稳定性直接影响业务连续性。想象一下,当你的电商平台正在举行大促活动,AI推荐系统突然宕机,…...

忍者像素绘卷多场景应用:微信小程序插图、游戏素材、社交配图一站式生成
忍者像素绘卷多场景应用:微信小程序插图、游戏素材、社交配图一站式生成 1. 像素艺术的新纪元 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,它将传统像素艺术与现代AI技术完美结合。这款工具特别适合需要快速生成高质量像素风格图像…...

AI艺术创作大赛:Shadow Sound Hunter生成作品展示
AI艺术创作大赛:Shadow & Sound Hunter生成作品展示 1. 引言 最近参加了一场AI艺术创作大赛,用Shadow & Sound Hunter模型生成了不少有意思的作品。这个模型在数字绘画、诗歌创作和音乐编曲方面都表现出色,让我看到了AI在艺术创作领…...

PingFangSC字体专业配置与高效应用实践指南
PingFangSC字体专业配置与高效应用实践指南 【免费下载链接】PingFangSC PingFangSC字体包文件、苹果平方字体文件,包含ttf和woff2格式 项目地址: https://gitcode.com/gh_mirrors/pi/PingFangSC 在数字设计领域,字体选择直接影响用户体验与信息传…...

XiaoMusic:让小爱音箱突破音乐限制的开源解决方案
XiaoMusic:让小爱音箱突破音乐限制的开源解决方案 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否遇到过这样的困扰:想听的歌曲在各大…...

学术场景实战:DeepSeek-OCR-2驱动深求·墨鉴实现论文公式精准提取
学术场景实战:DeepSeek-OCR-2驱动深求墨鉴实现论文公式精准提取 1. 引言:学术研究中的公式提取痛点 如果你是一名理工科的研究生、科研工作者,或者经常需要阅读学术论文,你一定遇到过这样的场景:在PDF论文里看到一个…...

Visual C++运行库一键修复终极指南:快速解决系统依赖问题
Visual C运行库一键修复终极指南:快速解决系统依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中不可或缺的组件…...