用idea工具scala 和 Java开发 spark案例:WordCount
目录
一 环境准备
二 scala代码编写
三 java 代码编写
一 环境准备
创建一个 maven 工程
添加下列依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-graphx_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency>原本就下载过这些依赖的没必要再下一遍,可以用之前的,比如 json,mysql,mysq 这里版本是 mysql 5 ,不一样的注意修改
二 scala代码编写
首先准备好数据,即一个 txt 文本里面加一些单词,可以放在 hdfs 或本地或其它地方,读取的时候注意改代码,这里是读取 hdfs 上的 txt 文本,注意改成自己的地址
新建一个 scala 的 object,编写代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}object WordCountDemo {def main(args: Array[String]): Unit = {val conf : SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount")val sc : SparkContext = SparkContext.getOrCreate(conf)var spark : SparkSession = SparkSession.builder().config(conf).getOrCreate()// val rdd1: RDD[String] = sc.textFile("hdfs://101.200.63.3:9000/kb23/tmp/*.txt")
// val rdd2: RDD[String] = rdd1.flatMap(x => x.split(" "))
// val rdd3: RDD[(String, Int)] = rdd2.map(x => (x, 1))
// val result: RDD[(String, Int)] = rdd3.reduceByKey(_ + _)val result2: RDD[(String, Int)] = sc.textFile("hdfs://101.200.63.3:9000/kb23/tmp/*.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y)//打印到 console// result2.glom().collect.foreach(x=>println(x.toList))//保存到 hdfsresult2.saveAsTextFile("hdfs://101.200.63.3:9000/kb23/sparkoutput/wordcount")}}这里稍微解释一下代码中的一些函数:
map:转换函数,数据集合中每个元素进行一次我们定义的方法
flatMap: 与map类似,但是映射为0个或多个
collect:以数组的形式返回数据集中的所有元素
glom:将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变。
云服务器的朋友可能有的报错
22/05/0305:48:53 WARN DFSClient: Failed to connect to /10.0.24.10:9866 for block, add to deadNodes and continue. org.apache.hadoop.net.ConnectTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/10.0.24.10:9866]
org.apache.hadoop.net.ConnectTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/10.0.24.10:9866]出现这种错误看字面意思就很容易明白,这是本地与 datanode 通信时,namenode 给的是 datanode 的内网 ip,所以本地找不到
解决方法也很简单,设置一下让 namenode 传过来的是服务器名而不是 ip
在 idea 中,resource 文件夹中添加文件 hdfs-site.xml
hdfs-site.xml内容:
<!-- datanode 通信是否使用域名,默认为false,改为true --><property><name>dfs.client.use.datanode.hostname</name><value>true</value><description>Whether datanodes should use datanode hostnames whenconnecting to other datanodes for data transfer.</description></property>三 java 代码编写
这里原数据存储在本地,文件名为 input.txt
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.Map;public class WordCount {public static void main(String[] args) {// 创建SparkConf对象SparkConf conf = new SparkConf().setAppName("WordCount").setMaster("local");// 创建JavaSparkContext对象JavaSparkContext sc = new JavaSparkContext(conf);// 读取文本文件JavaRDD<String> lines = sc.textFile("input.txt");// 计算单词出现次数JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());JavaRDD<String> filteredWords = words.filter(word -> !word.isEmpty());JavaPairRDD<String, Integer> wordCounts = filteredWords.mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((x, y) -> x + y);Map<String, Integer> wordCountsMap = wordCounts.collectAsMap();// 输出结果for (Map.Entry<String, Integer> entry : wordCountsMap.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());}// 关闭JavaSparkContext对象sc.close();}
}
相关文章:

用idea工具scala 和 Java开发 spark案例:WordCount
目录 一 环境准备 二 scala代码编写 三 java 代码编写 一 环境准备 创建一个 maven 工程 添加下列依赖 <dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</vers…...

【git merge/rebase】详解合并代码、解决冲突
目录 1.概述 2.merge 3.rebase 4.merge和rabase的区别 5.解决冲突 1.概述 在实际开发中,一个项目往往是多个人一起协作的,头天下班前大家把代码交到远端仓库,第二天工作的第一件事情都是从服务器上拉最新的代码,保证代码版本…...

nrm,npm源的管理工具
npm手动切换淘宝源 查看当前的仓库 npm config get registry设置成淘宝源 npm config set registry https://registry.npmmirror.com/设置回官方源 npm config set registry https://registry.npmjs.org/手动切换不免不太方便,而且网上很多资料淘宝源还是过期的链接…...

HarmonyOS/OpenHarmony原生应用-ArkTS万能卡片组件Stack
堆叠容器,子组件按照顺序依次入栈,后一个子组件覆盖前一个子组件。该组件从API Version 7开始支持。可以包含子组件。 一、接口 Stack(value?: { alignContent?: Alignment }) 从API version 9开始,该接口支持在ArkTS卡片中使用。 二、…...

腾讯云2核4G服务器一年和三年价格性能测评
腾讯云轻量2核4G5M服务器:CPU内存流量带宽系统盘性能测评:轻量应用服务器2核4G5M带宽,免费500GB月流量,60GB系统盘SSD盘,5M带宽下载速度可达640KB/秒,流量超额按照0.8元每GB的价格支付流量费,轻…...
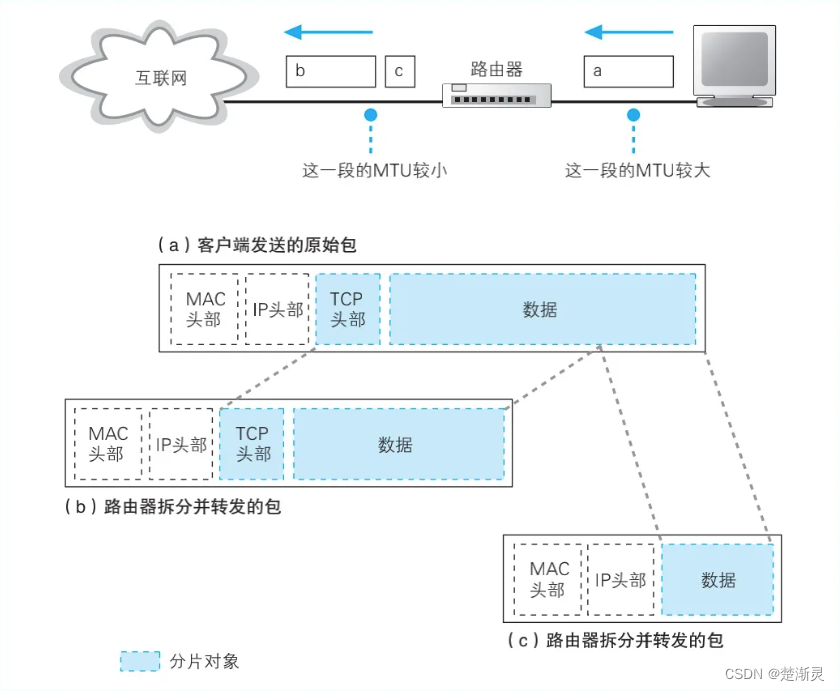
集线器、交换机、路由器是如何转发包的
集线器、交换机、路由器是如何转发包的 集线器交换机MAC地址表的维护 路由器路由表中的信息路由器的包接收操作查询路由表确定输出端口找不到匹配路由时选择默认路由包的有效期通过分片功能拆分大网络包路由器发送操作中的一些特点 参考文档 集线器 集线器是一层(物…...
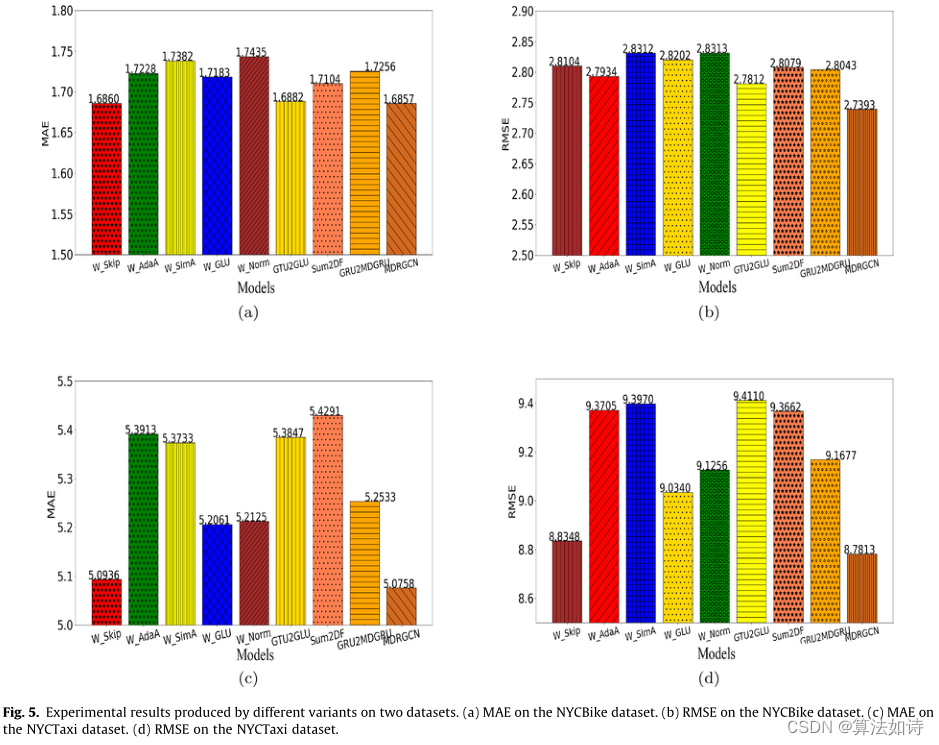
交通物流模型 | MDRGCN:用于多模式交通客流预测的深度学习模型
城市交通拥堵是造成交通事故的重要原因,也是城市发展的主要障碍。通过学习历史交通流数据,我们可以预测未来一些区域的交通流,这对城市道路规划、交通管理、交通控制等都有重要意义。然而,由于交通网络拓扑结构的复杂性和影响交通流的因素的多样性,交通模式往往是复杂多变…...

保研经历分享(一)
这个系列的文章主要是想记录一下自己大学期间最重要的一件事(保研!!)的经历、过程,外加一些保研流程介绍、面试经验、院校投递、踩坑经历,主要给学弟学妹们避雷,也做一些借鉴吧~ 这一篇主要是对保研过程的一些介绍&…...

【手写数字识别】数据挖掘实验二
文章目录 Ⅰ、项目任务要求任务描述:主要任务要求(必须完成以下内容但不限于这些内容): II、实现过程数据集描述实验运行环境描述KNN模型决策树模型朴素贝叶斯模型SVM模型不同方法对MNIST数据集分类识别结果分析(不同方法识别对比率表及结果分析) 完整代…...

什么是云计算?云计算简介
其实“云计算”作为一个名词而言,那是相当成功滴。很多人都有听过。但提及云计算”具体是什么?很多人,知其然,却不知其所以然! 利用软件将这些成千上万不可靠的硬件组织成一个稳定可靠的IT系统,以此支撑其公司的IT基础服务。这家…...
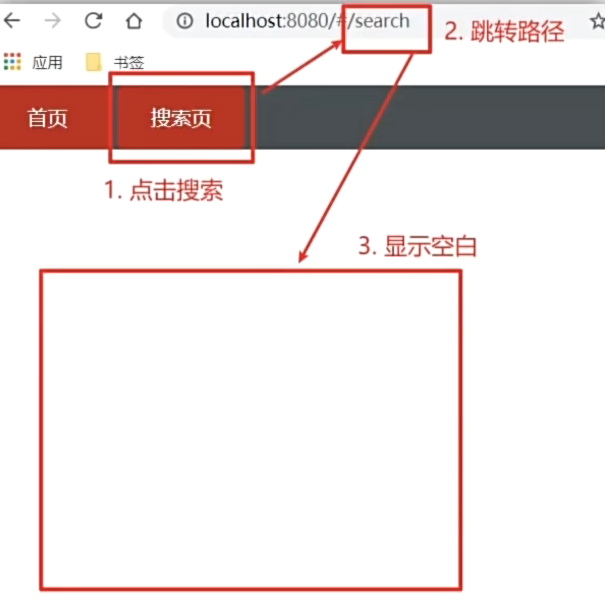
Vue路由进阶--VueRouter声明式导航
Vue路由进阶–VueRouter声明式导航 文章目录 Vue路由进阶--VueRouter声明式导航1、声明式导航1.1、导航链接1.2、高亮类名1.3、跳转传参1.4、动态路由参数可选符 1、声明式导航 1.1、导航链接 需求:实现导航高亮效果 vue-router提供了一个全局组件router-link(取…...
Oracle 云服务即将支持 PostgreSQL!
2023 年 9 月 19 日,Oracle 产品团队发布了一篇文章,宣布 Oracle 云基础架构(OCI)开始提供 PostgreSQL 服务。目前支持的版本为 PostgreSQL 14.9,提供有限支持,12 月份将会提供正式版本。 众所周知&#x…...

数字孪生项目:突破技术难关,引领未来发展
项目背景 数字孪生技术一直在不断发展,为企业提供了无限的潜力和机会。在这个数字时代,公司需要不断进化,以适应市场的需求和客户的期望。北京智汇云舟一直以“视频孪生”为标签,是数字孪生领域的头部企业,拥有强大的…...

MySQL 如何使用离线模式维护服务器
离线模式 作为 DBA,最常见的任务之一就是批量处理 MySQL 服务的启停或其他一些活动。在停止 MySQL 服务前,我们可能需要检查是否有活动连接;如果有,我们可能需要把它们全部杀死。通常,我们使用 pt-kill 杀死应用连接或…...

期权开户流程合集——期权开户的操作步骤
最详细的期权开户流程介绍是怎样的,下文为大家介绍期权开户流程合集——期权开户的操作步骤的知识点,希望对读者有所帮助,期权开户流程和方式分两种,一种券商,一种期权分仓平台,有啥区别下文揭秘。本文来自…...

mysql改造oracle,以及项目改造
mysql改造oracle,以及springboot项目改造 oracle改造说明 这次的任务是springboot mysql版本改造为oracle版本,mysql5.7,oracle11.2,springboot2.0.2(springboot版本无所谓,都差不多,自己记录…...

利用互斥锁实现多个线程写一个文件
代码 #include <stdio.h> #include <pthread.h> #include <string.h> #include <unistd.h>FILE *fp;//线程函数1 void *wrfunc1(void *arg); //线程函数2 void *wrfunc2(void *arg); //线程函数3 void *wrfunc3(void *arg);//静态创建互斥锁 pthread_…...

【m98】视频缓存PacketBuffer 1 : SeqNumUnwrapper int64映射、ForwardDiff
视频缓存PacketBuffer 对rtp包进行接收处理。 rtp序号 相关 【mediasoup】RtpStreamRecv 对rtp 序号的验证 与这里的处理有不同。...

day58:ARMday5,GPIO流水灯实验
汇编指令: .text .global _start _start: 1.设置GPIOE GPIOF寄存器的时钟使能 RCC_MP_AHB4ENSETR[5:4]->1 0x50000a28 LDR R0,0x50000a28 LDR R1,[R0] ORR R1,R1,#(0x3<<4) STR R1,[R0]2.设置PE10、PF10、PE8管脚为输出模式,GPIOE_MODER[21…...
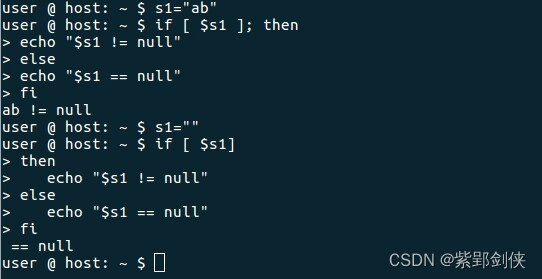
Linux shell编程学习笔记9:字符串运算 和 if语句
Linux Shell 脚本编程和其他编程语言一样,支持算数、关系、布尔、字符串、文件测试等多种运算,同样也需要进行根据条件进行流程控制,提供了if、for、while、until等语句。 上期学习笔记中我们研究了字符串数据的使用,今天我们研…...

AI驱动命令行工具:用自然语言生成Shell命令,提升开发运维效率
1. 项目概述:一个能“读懂”你意图的智能命令行工具如果你和我一样,每天有大量时间泡在终端里,那么对命令行工具的效率追求几乎是永无止境的。敲命令、查参数、记路径、处理错误……这些琐碎的操作虽然基础,却实实在在地消耗着我们…...

构建高质量Awesome教程库:从Claude Code实战到开发者知识体系搭建
1. 项目概述:一个为Claude Code打造的开发者知识库 最近在GitHub上看到一个挺有意思的项目,叫“awesome-claudcode-tutorial”。光看名字,你可能会有点懵——“Claude Code”是什么?这其实是一个由开发者社区推动的、围绕特定AI编…...
基于GEMMA与NeoPixel制作智能可穿戴首饰:从硬件选型到代码实现
1. 项目概述:当微型控制器遇见珠宝设计几年前,当我第一次把一块微控制器塞进一个首饰盒里,看着它驱动一圈LED发出柔和的光晕时,我就知道,电子制作和个性化穿戴的结合,远不止于智能手表或健身手环。我们今天…...

Logseq Full House Templates 终极指南:如何用智能模板提升知识管理效率
Logseq Full House Templates 终极指南:如何用智能模板提升知识管理效率 【免费下载链接】logseq13-full-house-plugin Logseq Templates you will really love ❤️ 🏛️ 项目地址: https://gitcode.com/gh_mirrors/lo/logseq13-full-house-plugin …...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...

百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南
百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载而烦…...

Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍
更多请点击: https://intelliparadigm.com 第一章:Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍 该方案通过在 Claude API 请求链路中注入轻量级 RAG 中间件,无需修改业务侧任何模型…...

Hugging Face Tokenizer的padding、truncation参数详解:如何让你的BERT/RoBERTa输入不出错?
Hugging Face Tokenizer的padding与truncation实战指南:BERT输入处理的深度解析 当你第一次将文本输入BERT模型时,是否遇到过这样的报错:"RuntimeError: The size of tensor a (512) must match the size of tensor b (128)"&#…...
)
ORB-SLAM3地图保存新思路:手把手教你将.osa地图转成PCD点云(附完整代码)
ORB-SLAM3地图数据解放指南:从封闭格式到通用点云的全链路实践 当你在昏暗的实验室调试ORB-SLAM3运行整夜后,终于得到那个珍贵的.osa地图文件时,却发现无法用熟悉的点云工具打开分析——这种挫败感或许正是促使你阅读本文的原因。作为三维视觉…...

从零到一:UniApp CLI 实战入门与避坑指南
1. 为什么需要UniApp CLI? 第一次接触UniApp的开发者可能会疑惑:明明有HBuilderX这样完善的图形化工具,为什么还要学习CLI?这个问题我也曾经纠结过。经过多个项目的实战验证,我发现CLI在以下场景中优势明显:…...